Rust入门系列:11、万字长文,一次性说透Rust中的字符串和切片
- Louis
- 发布于 2024-06-29 14:52
- 阅读 3290
字符串在其他语言中,字符串往往是送分题,因为实在是太简单了,例如"hello,world"就是字符串章节的几乎全部内容了,但是如果你带着同样的想法来学Rust,我保证,绝对会栽跟头,因为在Rust中,它有很多不一样的东西。
theme: channing-cyan
字符串
在其他语言中,字符串往往是送分题,因为实在是太简单了,例如 "hello, world" 就是字符串章节的几乎全部内容了,但是如果你带着同样的想法来学Rust,我保证,绝对会栽跟头,因为在Rust中,它有很多不一样的东西。
首先来看段很简单的代码:
fn main() {
let my_name = "Pascal";
greet(my_name);
}
fn greet(name: String) {
println!("Hello, {}!", name);
}greet 函数接受一个字符串类型的 name 参数,然后打印到终端控制台中,非常好理解,你们猜猜,这段代码能否通过编译?
error[E0308]: mismatched types
--> src/main.rs:3:11
|
3 | greet(my_name);
| ^^^^^^^
| |
| expected struct `std::string::String`, found `&str`
| help: try using a conversion method: `my_name.to_string()`
error: aborting due to previous error果然报错了,编译器提示 greet 函数需要一个 String 类型的字符串,却传入了一个 &str 类型的字符串,相信此刻你心中一定很疑惑,怎么字符串也能整出这么多花活?
在讲解字符串之前,先来看看什么是切片
切片
切片并不是Rust独有的概念,在Go语言中就非常流行,它允许你引用集合中部分连续的元素序列,而不是引用整个集合。
对于字符串而言,切片就是对 String 类型中某一部分的引用,它看起来像这样:
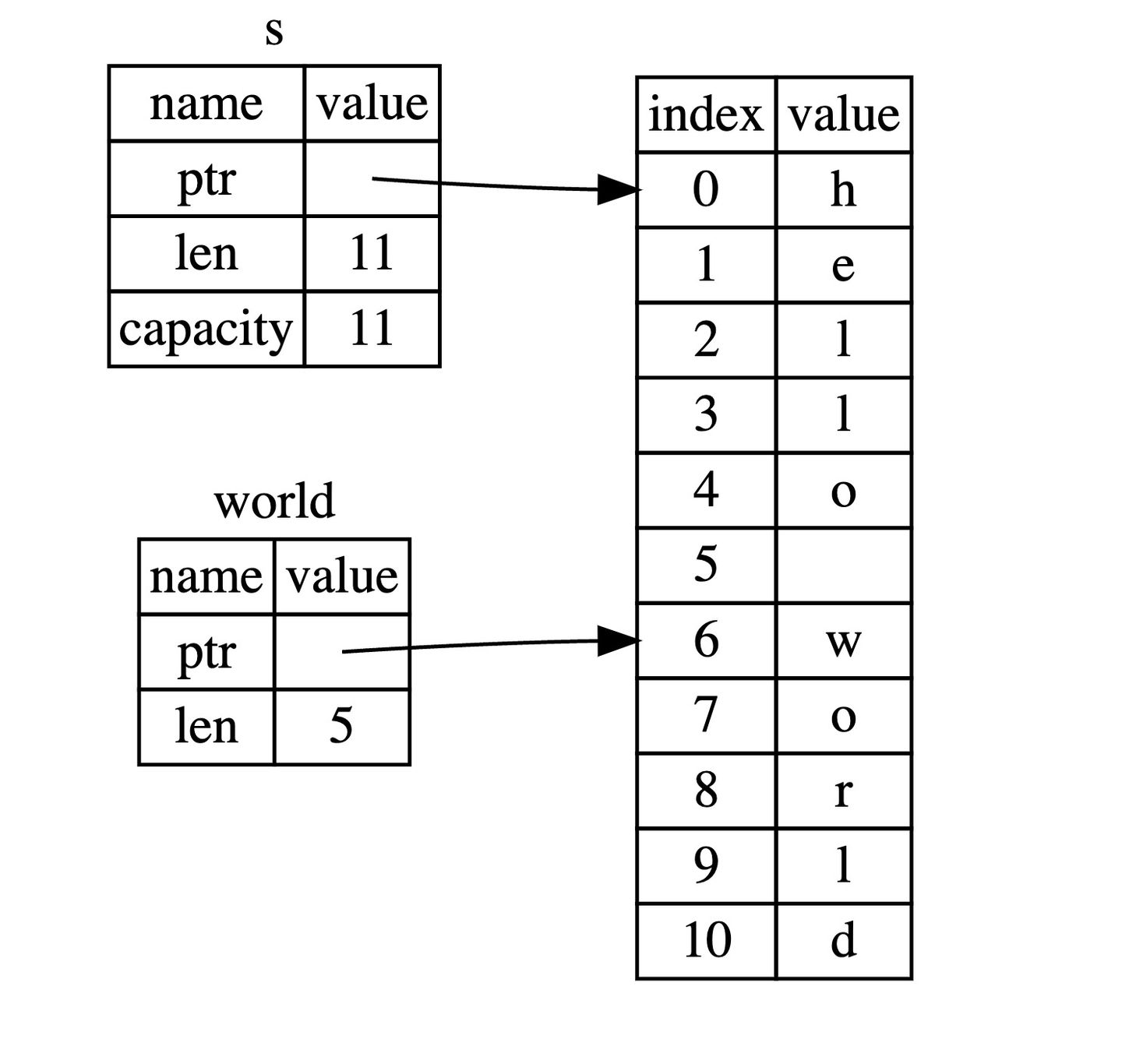
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];hello 没有引用整个 String s,而是引用了 s 的一部分内容,通过 [0..5] 的方式来指定。
这就是创建切片的语法,使用方括号包括的一个序列: [开始索引..终止索引] ,其中开始索引是切片中第一个元素的索引位置,而终止索引是最后一个元素后面的索引位置。换句话说,这是一个 右半开区间(或者左闭右开区间)。在切片数据结构内部会保存开始的位置和切片的长度,其中长度是通过 终止索引 - 开始索引 的方式计算得来的。
对于 let world = &s[6..11]; 来说,world 是一个切片,该切片的指针指向 s 的第 7 个字节(索引从 0 开始, 6 是第 7 个字节),且该切片的长度是 5 个字节。
在使用 Rust 的 .. range 序列语法时,如果你想从索引 0 开始,可以使用如下的方式,这两个是等效的:
let s = String::from("hello");
let slice = &s[0..2];
let slice = &s[..2];同样的,如果你的切片想要包含 String 的最后一个字节,则可以这样使用:
let s = String::from("hello");
let len = s.len();
let slice = &s[4..len];
let slice = &s[4..];你也可以截取完整的 String 切片:
let s = String::from("hello");
let len = s.len();
let slice = &s[0..len];
let slice = &s[..];在对字符串使用切片语法时需要格外小心,切片的索引必须落在字符之间的边界位置,也就是 UTF-8 字符的边界,例如中文在 UTF-8 中占用三个字节,下面的代码就会崩溃:
let s = "中国人"; let a = &s[0..2]; println!("{}",a);因为我们只取
s字符串的前两个字节,但是本例中每个汉字占用三个字节,因此没有落在边界处,也就是连中字都取不完整,此时程序会直接崩溃退出,如果改成&s[0..3],则可以正常通过编译。
字符串切片的类型标识是 &str,因此我们可以这样声明一个函数,输入 String 类型,返回它的切片: fn first_word(s: &String) -> &str 。
有了切片就可以写出这样的代码:
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // error!
println!("the first word is: {}", word);
}
fn first_word(s: &String) -> &str {
&s[..1]
}编译器报错如下:
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:18:5
|
16 | let word = first_word(&s);
| -- immutable borrow occurs here
17 |
18 | s.clear(); // error!
| ^^^^^^^^^ mutable borrow occurs here
19 |
20 | println!("the first word is: {}", word);
| ---- immutable borrow later used here
回忆一下借用的规则:当我们已经有了可变借用时,就无法再拥有不可变的借用。因为 clear 需要清空改变 String,因此它需要一个可变借用(利用 VSCode 可以看到该方法的声明是 pub fn clear(&mut self) ,参数是对自身的可变借用 );而之后的 println! 又使用了不可变借用,也就是在 s.clear() 处可变借用与不可变借用试图同时生效,因此编译无法通过。
从上述代码可以看出,Rust不仅让我们的 API 更加容易使用,而且也在编译期就消除了大量错误!
其它切片
因为切片是对集合的部分引用,因此不仅仅字符串有切片,其它集合类型也有,例如数组:
let a = [1, 2, 3, 4, 5];
let slice = &a[1..3];
assert_eq!(slice, &[2, 3]);该数组切片的类型是 &[i32],数组切片和字符串切片的工作方式是一样的,例如持有一个引用指向原始数组的某个元素和长度。
字符串字面量是切片
之前提到过字符串字面量,但是没有提到它的类型:
let s = "Hello, world!";实际上,s 的类型是 &str,因此你也可以这样声明:
let s: &str = "Hello, world!";该切片指向了程序可执行文件中的某个点,这也是为什么字符串字面量是不可变的,因为 &str 是一个不可变引用。
什么是字符串
字符串是由字符组成的连续集合,Rust中的字符是 Unicode 类型,因此每个字符占据 4 个字节内存空间,但是在字符串中不一样,字符串是 UTF-8 编码,也就是字符串中的字符所占的字节数是变化的(1 - 4) ,这样有助于大幅降低字符串所占用的内存空间。
Rust 在语言级别,只有一种字符串类型: str,它通常是以引用类型出现 &str,也就是上文提到的字符串切片。虽然语言级别只有上述的 str 类型,但是在标准库里,还有多种不同用途的字符串类型,其中使用最广的即是 String 类型。
str 类型是硬编码进可执行文件,也无法被修改,但是 String 则是一个可增长、可改变且具有所有权的 UTF-8 编码字符串,当 Rust 用户提到字符串时,往往指的就是 String 类型和 &str 字符串切片类型,这两个类型都是 UTF-8 编码。
除了 String 类型的字符串,Rust 的标准库还提供了其他类型的字符串,例如 OsString, OsStr, CsString 和 CsStr 等,注意到这些名字都以 String 或者 Str 结尾了吗?它们分别对应的是具有所有权和被借用的变量。
String和&str的转换
在之前的代码中,已经见到好几种从 &str 类型生成 String 类型的操作:
String::from("hello,world")"hello,world".to_string()
那么如何将 String 类型转为 &str 类型呢?答案很简单,取引用即可:
fn main() {
let s = String::from("hello,world!");
say_hello(&s);
say_hello(&s[..]);
say_hello(s.as_str());
}
fn say_hello(s: &str) {
println!("{}",s);
}实际上这种灵活用法是因为 deref 隐式强制转换,具体我们会在后面的小节中进行详细讲解。
字符串索引
在其它语言中,使用索引的方式访问字符串的某个字符或者子串是很正常的行为,但是在 Rust 中就会报错:
let s1 = String::from("hello");
let h = s1[0];该代码会产生如下错误:
3 | let h = s1[0];
| ^^^^^ `String` cannot be indexed by `{integer}`
|
= help: the trait `Index<{integer}>` is not implemented for `String`深入字符串内部
字符串的底层的数据存储格式实际上是[ u8 ],一个字节数组。对于 let hello = String::from("Hola"); 这行代码来说,Hola 的长度是 4 个字节,因为 "Hola" 中的每个字母在 UTF-8 编码中仅占用 1 个字节,但是对于下面的代码呢?
let hello = String::from("中国人");如果问你该字符串多长,你可能会说 3,但是实际上是 9 个字节的长度,因为大部分常用汉字在 UTF-8 中的长度是 3 个字节,因此这种情况下对 hello 进行索引,访问 &hello[0] 没有任何意义,因为你取不到 中 这个字符,而是取到了这个字符三个字节中的第一个字节,这是一个非常奇怪而且难以理解的返回值。
字符串切片
前文提到过,字符串切片是非常危险的操作,因为切片的索引是通过字节来进行,但是字符串又是 UTF-8 编码,因此你无法保证索引的字节刚好落在字符的边界上,例如:
let hello = "中国人";
let s = &hello[0..2];运行上面的程序,会直接造成崩溃:
thread 'main' panicked at 'byte index 2 is not a char boundary; it is inside '中' (bytes 0..3) of `中国人`', src/main.rs:4:14
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace这里提示的很清楚,我们索引的字节落在了 中 字符的内部,这种返回没有任何意义。
因此在通过索引区间来访问字符串时,需要格外的小心,一不注意,就会导致你程序的崩溃!
操作字符串
由于 String 是可变字符串,下面介绍 Rust 字符串的修改,添加,删除等常用方法:
追加(push)
在字符串尾部可以使用 push() 方法追加字符 char,也可以使用 push_str() 方法追加字符串字面量。这两个方法都是在原有的字符串上追加,并不会返回新的字符串。由于字符串追加操作要修改原来的字符串,则该字符串必须是可变的,即字符串变量必须由 mut 关键字修饰。
示例代码如下:
fn main() {
let mut s = String::from("Hello ");
s.push_str("rust");
println!("追加字符串 push_str() -> {}", s);
s.push('!');
println!("追加字符 push() -> {}", s);
}代码运行结果:
追加字符串 push_str() -> Hello rust
追加字符 push() -> Hello rust!插入(Insert)
可以使用 insert() 方法插入单个字符 char,也可以使用 insert_str() 方法插入字符串字面量,与 push() 方法不同,这俩方法需要传入两个参数,第一个参数是字符(串)插入位置的索引,第二个参数是要插入的字符(串),索引从 0 开始计数,如果越界则会发生错误。由于字符串插入操作要修改原来的字符串,则该字符串必须是可变的,即字符串变量必须由 mut 关键字修饰。
代码示例:
fn main() {
let mut s = String::from("Hello rust!");
s.insert(5, ',');
println!("插入字符 insert() -> {}", s);
s.insert_str(6, " I like");
println!("插入字符串 insert_str() -> {}", s);
}运行结果
插入字符 insert() -> Hello, rust!
插入字符串 insert_str() -> Hello, I like rust!替换(Replace)
如果想要把字符串中的某个字符串替换成其它的字符串,那可以使用 replace() 方法。与替换有关的方法有三个。
1、replace
该方法可适用于 String 和 &str 类型。replace() 方法接收两个参数,第一个参数是要被替换的字符串,第二个参数是新的字符串。该方法会替换所有匹配到的字符串。该方法是返回一个新的字符串,而不是操作原来的字符串。
示例代码如下:
fn main() {
let string_replace = String::from("I like rust. Learning rust is my favorite!");
let new_string_replace = string_replace.replace("rust", "RUST");
dbg!(new_string_replace);
}代码运行结果:
new_string_replace = "I like RUST. Learning RUST is my favorite!"2、replacen
该方法可适用于 String 和 &str 类型。replacen() 方法接收三个参数,前两个参数与 replace() 方法一样,第三个参数则表示替换的个数。该方法是返回一个新的字符串,而不是操作原来的字符串。
示例代码如下:
fn main() {
let string_replace = "I like rust. Learning rust is my favorite!";
let new_string_replacen = string_replace.replacen("rust", "RUST", 1);
dbg!(new_string_replacen);
}代码运行结果:
new_string_replacen = "I like RUST. Learning rust is my favorite!"3、replace_range
该方法仅适用于 String 类型。replace_range 接收两个参数,第一个参数是要替换字符串的范围(Range),第二个参数是新的字符串。该方法是直接操作原来的字符串,不会返回新的字符串。该方法需要使用 mut 关键字修饰。
示例代码如下:
fn main() {
let mut string_replace_range = String::from("I like rust!");
string_replace_range.replace_range(7..8, "R");
dbg!(string_replace_range);
}代码运行结果:
string_replace_range = "I like Rust!"删除(Delete)
与字符串删除相关的方法有 4 个,他们分别是 pop(),remove(),truncate(),clear()。这四个方法仅适用于 String 类型。
1、 pop —— 删除并返回字符串的最后一个字符
该方法是直接操作原来的字符串。但是存在返回值,其返回值是一个 Option 类型,如果字符串为空,则返回 None。
示例代码如下:
fn main() {
let mut string_pop = String::from("rust pop 中文!");
let p1 = string_pop.pop();
let p2 = string_pop.pop();
dbg!(p1);
dbg!(p2);
dbg!(string_pop);
}代码运行结果:
p1 = Some(
'!',
)
p2 = Some(
'文',
)
string_pop = "rust pop 中"2、 remove —— 删除并返回字符串中指定位置的字符
该方法是直接操作原来的字符串。但是存在返回值,其返回值是删除位置的字符串,只接收一个参数,表示该字符起始索引位置。remove() 方法是按照字节来处理字符串的,如果参数所给的位置不是合法的字符边界,则会发生错误。
示例代码如下:
fn main() {
let mut string_remove = String::from("测试remove方法");
println!(
"string_remove 占 {} 个字节",
std::mem::size_of_val(string_remove.as_str())
);
// 删除第一个汉字
string_remove.remove(0);
// 下面代码会发生错误
// string_remove.remove(1);
// 直接删除第二个汉字
// string_remove.remove(3);
dbg!(string_remove);
}代码运行结果:
string_remove 占 18 个字节
string_remove = "试remove方法"3、truncate —— 删除字符串中从指定位置开始到结尾的全部字符
该方法是直接操作原来的字符串。无返回值。该方法 truncate() 方法是按照字节来处理字符串的,如果参数所给的位置不是合法的字符边界,则会发生错误。
示例代码如下:
fn main() {
let mut string_truncate = String::from("测试truncate");
string_truncate.truncate(3);
dbg!(string_truncate);
}代码运行结果:
string_truncate = "测"4、clear —— 清空字符串
该方法是直接操作原来的字符串。调用后,删除字符串中的所有字符,相当于 truncate() 方法参数为 0 的时候。
示例代码如下:
fn main() {
let mut string_clear = String::from("string clear");
string_clear.clear();
dbg!(string_clear);
}代码运行结果:
string_clear = ""连接(concatenate)
1、使用 + 或者 += 连接字符串
使用 + 或者 += 连接字符串,要求右边的参数必须为字符串的切片引用(Slice)类型。其实当调用 + 的操作符时,相当于调用了 std::string 标准库中的add()方法,这里 add() 方法的第二个参数是一个引用的类型。因此我们在使用 + 时, 必须传递切片引用类型。不能直接传递 String 类型。 + 是返回一个新的字符串,所以变量声明可以不需要 mut 关键字修饰。
示例代码如下:
fn main() {
let string_append = String::from("hello ");
let string_rust = String::from("rust");
// &string_rust会自动解引用为&str
let result = string_append + &string_rust;
let mut result = result + "!"; // `result + "!"` 中的 `result` 是不可变的
result += "!!!";
println!("连接字符串 + -> {}", result);
}代码运行结果:
连接字符串 + -> hello rust!!!!字符串转义
我们可以通过转义的方式 \ 输出 ASCII 和 Unicode 字符。
fn main() {
// 通过 \ + 字符的十六进制表示,转义输出一个字符
let byte_escape = "I'm writing \x52\x75\x73\x74!";
println!("What are you doing\x3F (\\x3F means ?) {}", byte_escape);
// \u 可以输出一个 unicode 字符
let unicode_codepoint = "\u{211D}";
let character_name = "\"DOUBLE-STRUCK CAPITAL R\"";
println!(
"Unicode character {} (U+211D) is called {}",
unicode_codepoint, character_name
);
// 换行了也会保持之前的字符串格式
// 使用\忽略换行符
let long_string = "String literals
can span multiple lines.
The linebreak and indentation here ->\
<- can be escaped too!";
println!("{}", long_string);
}当然,在某些情况下,可能你会希望保持字符串的原样,不要转义:
fn main() {
println!("{}", "hello \\x52\\x75\\x73\\x74");
let raw_str = r"Escapes don't work here: \x3F \u{211D}";
println!("{}", raw_str);
// 如果字符串包含双引号,可以在开头和结尾加 #
let quotes = r#"And then I said: "There is no escape!""#;
println!("{}", quotes);
// 如果还是有歧义,可以继续增加,没有限制
let longer_delimiter = r###"A string with "# in it. And even "##!"###;
println!("{}", longer_delimiter);
}字符串深度剖析
那么问题来了,为啥 String 可变,而字符串字面值 str 却不可以?
就字符串字面值来说,我们在编译时就知道其内容,最终字面值文本被直接硬编码进可执行文件中,这使得字符串字面值快速且高效,这主要得益于字符串字面值的不可变性。不幸的是,我们不能为了获得这种性能,而把每一个在编译时大小未知的文本都放进内存中(你也做不到!),因为有的字符串是在程序运行得过程中动态生成的。
对于 String 类型,为了支持一个可变、可增长的文本片段,需要在堆上分配一块在编译时未知大小的内存来存放内容,这些都是在程序运行时完成的:
- 首先向操作系统请求内存来存放
String对象 - 在使用完成后,将内存释放,归还给操作系统
其中第一部分由 String::from 完成,它创建了一个全新的 String。
重点来了,到了第二部分,就是百家齐放的环节,在有垃圾回收 GC 的语言中,GC 来负责标记并清除这些不再使用的内存对象,这个过程都是自动完成,无需开发者关心,非常简单好用;但是在无 GC 的语言中,需要开发者手动去释放这些内存对象,就像创建对象需要通过编写代码来完成一样,未能正确释放对象造成的后果简直不可估量。
对于 Rust 而言,安全和性能是写到骨子里的核心特性,如果使用 GC,那么会牺牲性能;如果使用手动管理内存,那么会牺牲安全,这该怎么办?为此,Rust 的开发者想出了一个无比惊艳的办法:变量在离开作用域后,就自动释放其占用的内存:
{
let s = String::from("hello"); // 从此处起,s 是有效的
// 使用 s
} // 此作用域已结束,
// s 不再有效,内存被释放与其它系统编程语言的 free 函数相同,Rust 也提供了一个释放内存的函数: drop,但是不同的是,其它语言要手动调用 free 来释放每一个变量占用的内存,而 Rust 则在变量离开作用域时,自动调用 drop 函数: 上面代码中,Rust 在结尾的 } 处自动调用 drop。
其实,在 C++ 中,也有这种概念: Resource Acquisition Is Initialization (RAII) 。如果你使用过 RAII 模式的话应该对 Rust 的
drop函数并不陌生。
这个模式对编写 Rust 代码的方式有着深远的影响,在后面的文章中我们会进行更深入的介绍。
最后
写文章不易,如果文章对您有帮助,欢迎点个赞,您的支持是我写作的最大动力。
相关资料、源码已同步github:https://github.com/MagicalBridge/Blog 欢迎star



