Blockstack:使用区块链实现分布式互联网
- 盖盖
- 发布于 2017-09-04 23:30
- 阅读 5247
本文将要介绍的Blockstack项目虽然还不成熟,但相比于其他区块链项目来说,已经算是一个“老人”了,它的核心理念就是通过建立基于区块链的命名和存储系统,打造分布式互联网平台。
本文将要介绍的Blockstack项目虽然还不成熟,但相比于其他区块链项目来说,已经算是一个“老人”了,它的核心理念就是通过建立基于区块链的命名和存储系统,打造分布式互联网平台。
Blockstack简介
Blockstack的野心很大,它的创始人号称它是一个新型的分布式互联网,这是相对于目前中心化的互联网而言的。
在当今的互联网环境下,用户数据存储在第三方应用开发者的数据中心,其中任何一个数据中心遭到入侵都会对用户数据的安全造成危害,163邮箱被“脱裤”,苹果的“艳照门”事件,这样的事件层出不穷。另外,这种中心化的互联网也造成了大公司的垄断现象,像Google、Microsoft这样的大公司将用户锁定在自己的平台内,依靠用户数据获得利润。用户在享受大公司带来的免费服务的同时,也像“温水煮青蛙”一般接受着压榨。对于初创公司而言,即使他们的技术再牛也很难跟巨头抢夺用户,难逃被收购,甚至倒闭的命运。
然而Blockstack正在试图改变这一现象。所谓分布式互联网,用户在此之上拥有对其身份的所有权,数据和身份绑定,存储在自己的私有设备,或者云端,从而取消了对第三方机构的依赖。而开发者可以开发分布式的应用本地运行,调用用户的API,在用户许可的情况下访问用户数据,从而不用考虑数据的存储问题。Blockstack通过这种方式将数据主权交还给用户,用户数据由用户保管,未经用户许可,任何第三方无法访问用户数据。由于用户拥有了数据主权,用户可以随心所欲转移,不用再受到平台限制。
比特币区块链的限制
原生的比特币区块链只能被当做公共账本使用,以比特币区块链为基础构建系统主要有以下几个挑战:
- 存储限制:比特币区块链中,单个区块记录所占存储是KB级,根本存不了多少数据。另外,每个加入区块链网络中的节点(排除SPV节点)都要获取从创世区块以来的整个区块链的副本,大概要占据上百GB的硬盘容量。
- 写入速度慢:受限于PoW共识算法,一个区块的产生速率大约在10分钟,因此一个交易需要经过数十分钟或者数个小时才能被确认。
- 有限带宽:每个区块中的交易记录总数受限于区块的大小。为了保证每个矿工都能在下一轮竞赛中获得记账权,每个节点收到新发布的区块的时间要求几乎是一样的。因此,这也使得区块的大小受限于全网节点的平均带宽。目前比特币的大小是1MB,大约包含1000个交易记录。
- 无限账本:区块链的完整性取决于任何节点都可以从创世区块开始对其进行审计。因此,当区块越来越多的时候,新加入的节点对已有区块审计所花费的时间也是线性增长的,这被称为“无限账本问题”(endless ledger)。新加入的节点需要花费数天的时间下载全部已有的区块,并且对其审计。
Blockstack项目在比特币区块链的基础上,克服了比特币区块链的限制,建立了新的分布式命名和存储系统。
Blockstack的实现原理
Blockstack在底层区块链之上构建了一个与之隔离的命名系统。底层的区块链用来记录“名-值(name-value)”对的状态变化,利用区块链的共识协议,命名系统中的各项操作(例如命名注册,更新,转让等)可以在全网达成共识,不可篡改。
和SDN类似,Blockstack也采用了数据平面与控制平面分离的思想,将命名控制和命名相关数据分离。控制平面包括底层区块链和之上的虚拟链(virtualchain,后文说明),定义了注册名字,创建名字-身份绑定的协议。
数据平面负责数据存储,主要包括(1)用来通过哈希值或URL找到数据的zone file和(2)外部存储(Dropbox,S3,IPFS等)。数据由与其绑定的名字所对应的密钥对签名。客户端从数据平面读取数据,并且通过zone file中的数据哈希和名字所有者的公钥对数据进行完整性和可靠性验证。
这种数据平面与控制平面相分离的思想使得Blockstack不依附于任何一种特定的区块链,也就是说用户可以根据自己的需求选择不同的区块链。实际上,Blockstack就是从Namecoin区块链上迁移过来的,之所以迁移的原因就是因为Namecoin在安全性上不如比特币区块链,据说Namecoin已经遭受了51%攻击。这一思想的另一好处是使得Blockstack具备了构建状态机的能力。在区块链之上构建的独立的逻辑层将底层区块链中产生的交易当做状态机的输入,在任意给定时间,状态机都会处于某个确定的状态。随着时间的变化,新区块不断被写入底层区块链,全局状态也不断发生改变。
Blockstack的层次
为了实现命名与存储功能,Blockstack具有四个层次:控制平面的区块链层和虚拟链层,以及数据平面的路由层和数据存储层。具体实现如下图所示。
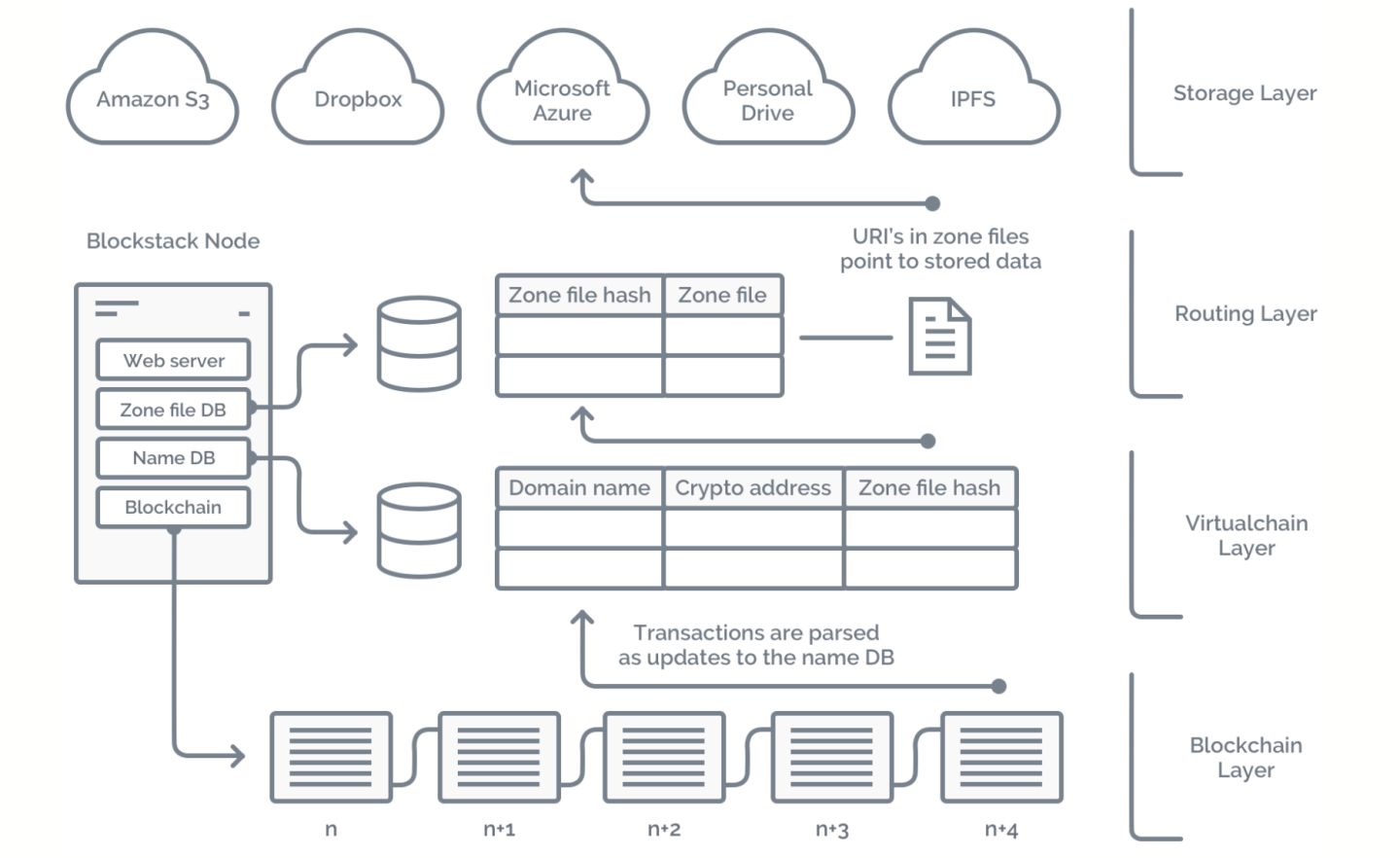
区块链层(Blockchain Layer)
区块链层处于最底层,主要提供两项服务:(1)Blockstack的各项操作是编码在底层区块链的交易记录中的,区块链层负责存储Blockstack的操作序列;(2)为写入区块链的操作的顺序提供共识。
虚拟链层(Virtualchain Layer)
虚拟链层是Blockstack的核心,定义了Blockstack节点的各种操作,且只有Blockstack节点能感知到这一层,单纯的区块链节点虽然能读取到操作的原文,但无法对其解析。
虚拟链层还定义了接收和拒绝Blockstack操作的规则。例如,注册命名操作被接收的条件是这个名字还没有其他用户注册。
路由层(Routing Layer)
Blockstack将路由请求(如何找到数据)与实际的数据存储分开,这样就给了用户可以选择数据存储的余地,用户既可以选择存在商用的云存储(如亚马逊S3,或者Dropbox)也可以选择自己的私有存储或者p2p存储系统。

路由信息存储在zone files里,这与DNS的zone file在形式上几乎相同,如上图所示。虚拟链将名字与zone file的哈希值绑定,存储在控制平面,而zone file本身是存储在路由层(目前的实现方式是存储在分布式哈希表中)。用户可以充分信任路由层,因为用户可以随时将zone file与控制平面的哈希值对比,来校验zone file是否被改动。
存储层(Storage Layer)
存储层是用户实际存放数据的地方。所有数据都会被名字所有者对应的密钥对签名。通过这种链外存储的方式,用户可以存储任意大小的数据,而且因为数据的哈希值是存储在控制层的,因此用户不用担心数据被篡改。
数据在存储层的存储方式有两种:多变存储和非多变存储。两者的区别主要在于在修改数据时是否同时修改zone file,分别适用于数据经常需要修改,以及数据几乎不会被修改的情况。
命名系统
Blockstack使用四层的结构实现了分布式命名系统。名字归属于底层区块链的地址以及相应的私钥。和Namecoin一样,用户需要先预定(preoder),之后才能注册(register)名字。最先将预定操作和注册操作成功写入区块链的用户可以获得对某个名字的所有权。名字被注册后,用户可以使用更新(update)命令像该名字下发送更新的数据。用户也可以使用转让(transfer)操作将名字转让给别的地址。撤销(revoke)命令可以暂时终止对这一名字的操作。
总结
区块链技术给互联网带来了激动人心的前景。分布式的命名与存储系统使得用户保有对身份与数据的绝对控制权,第三方的程序若想要访问用户的数据需要用户授权。Blockstack项目虽然目前还不是很成熟,但其设计的思想和理念十分贴合互联网未来的发展方向,也是区块链技术落地应用的典范。
扩展阅读
Blockstack官网是http://blockstack.org,网站上有白皮书和论文,论文曾发表在了2016年的USENIX ATC。项目源码托管在http://github.com/blockstack上,已经包含了55个子项目,社区十分活跃。
- 学分: 5
- 分类: 其他
- 标签: Blockstack





