分布式一致性协议之RAFT
- 清源
- 发布于 2019-07-18 20:41
- 阅读 19729
Raft算法解决的核心问题是在分布式环境下如何保持集群状态的一致性,简而言之就是一组服务,给定一组操作,最后得到一致的结果。
Raft算法解决的核心问题是在分布式环境下如何保持集群状态的一致性,简而言之就是一组服务,给定一组操作,最后得到一致的结果。
Raft算法通过选举领导人(leader),由领导人复制日志(log)到跟随者(follower),跟随者执行日志指令来达到最后集群状态的一致,整个算法也分成了两部分,领导人如何选举和跟随者如何安全的执行日志指令。
领导人选举
Raft算法中一个节点在任意时刻只能处在领导人(leader),候选人(candidate),跟随者(follower),同时强调强领导来简化整个流程,所以他的日志数据流只能从领导人复制到跟随者,跟随者之间也不能传递日志。
通常情况下,系统中只有一个领导人并且其他节点全部都是跟随者,跟随者都是被动的,他们不会发送任何请求,只是简单的响应来自领导者或者候选人的请求
下面是三个状态的状态转换图;
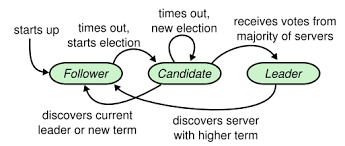
节点启动的时候,都是跟随者状态,在一段时间没有收到来自领导者的心跳,就从跟随者转变为候选人,发起选举;如果收到含自己的多数选票则转换到领导者;如果发现其他节点比自己更新,则切换到跟随者状态。为了确定其他节点比自己更新,Raft又引入了任期(term)的概念。
算法起始,任期是0,当有节点当选领导者时,任期号为1,新领导人选出后,任期在之前的任期号加1。当节点从跟随者转化为候选人的时候,任期号也要增加1。
任期起到逻辑时钟的作用
选举流程
当一个跟随者节点长时间没有收到领导者心跳包,猜测领导者节点可能挂了,发起新领导者节点选举。
- 增加自己当前的
任期,转换状态到候选人; - 投自己一票,并且给其他节点发送请求给自己投票的请求;
- 等待其他节点回复,在等待过程中又可能发生下面的情况
- 赢得选举,成为领导者;
- 被告知其他节点当选领导者,自己退回跟随者状态;
- 超时时间没有收到足够多的选票,则重复整个选举过程;
下面的这个gif就展示了这个过程;
日志复制
当选出了领导人系统就可以对外提供服务,客户端把请求发送给集群,如果是跟随者收到则转发给领导者,由领导者统一处理,领导人会调度这些请求,顺序告知所有跟随者,保证所有节点的状态一致。
Raft是基于复制状态机实现的,其核心思想就是相同的初始状态 + 相同的输入 = 一致的最终状态,领导者将客户端请求打包到一个个log entry,将这些log entries发送到所有跟随者节点,然后大家按相同顺序应用log entry中的命令,则状态肯定是一致的。
复制流程
- 领导者接收请求打包到
log entry; - 领导者并行发送
log entry到集群所有节点; - 领导者收到大多数跟随者收到
log entry的回复; - 领导者应用
log entry里面的命令到自己的状态机中,也就是执行命令; - 领导者回复跟随者,并且让他们也执行
log entry中命令,达到和自己一致的状态机;
每个log entry中,除了需要执行的命令之外还有领导者节点的任期号,用于处理异常情况;同时我们也可以看到,当日志被复制到大多数节点,即可向客户端返回成功的消息,一旦返回了结果,就必须保证系统在任何异常情况都不会发送回滚。
Raft通过第一个阶段的commited和第二个阶段的apply,保证了状态机的一致性。
当然还有各种异常情况,我们下面讨论当节点崩溃的情况下会有一些异常,影响状态机顺序的执行相同的指令。
领导人选举安全(Election safety)
选举安全性,即在一个任期内最多一个领导人被选出,如果有多余的领导人被选出,则被称为脑裂(brain split),如果出现脑裂会导致数据的丢失或者覆盖。Raft通过下面两点保证了不会出现脑裂的情况;
- 一个节点某一任期内最多只能投一票;
- 只有获得大多数选票才能成为领导人;
通过增加约束避免了脑裂的情况出现,保证了同一时间集群中只有一个领导者。但是当一个节点崩溃了一段时间,他的状态机已经落后其他节点很多,突然他重启恢复被选举为领导者,这个时候,客户端发来的请求再经由他复制给其他节点的状态机执行,就会出现集群状态机状态不一致的问题。
其他算法可能会同步落后的日志给领导者,然后在由领导者复制日志给其他节点,但是Raft认为这样会增加算法的复杂性,直接放弃了这种方法,而是采用拒绝投票给那些日志没有自己新的节点。
通过比较两份日志中,最后一条日志条目的索引值和任期号,来定义谁的日志比较新。如果两份日志最后的条目的任期号不同,那么任期号大的日志更新。如果两份日志最后的条目任期号相同,那么日志比索引大的日志新。
拒绝日志比自己旧节点投票是基于这样一种思考,要当选领导者,就必须获得大多数节点的选票,意味着他必须至少比大多数节点的日志新或者一致,这样拒绝比自己旧日志节点的投票请求,就保证了状态比大多数节点落后的节点是不会当选领导者。
如果一个领导者把日志复制到大多数其他节点,在应用到状态机之前崩溃了,新选出的领导者,是不知道被复制到大多数节点的日志是否应用到了状态机。
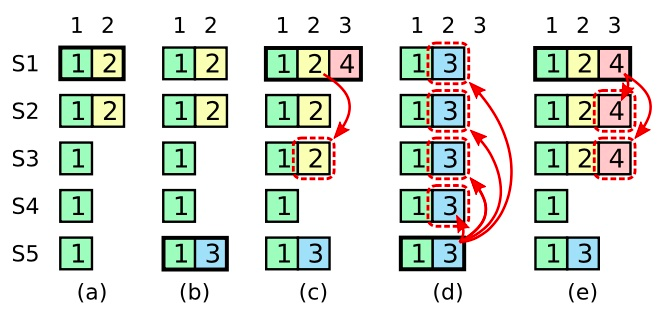
(a) 中,S1 是领导者,部分的复制了索引位置 2 的日志条目;
(b) 中,S1 崩溃了,然后 S5 在任期 3 里通过 S3、S4 和自己的选票赢得选举,然后从客户端接收了一条不一样的日志条目放在了索引 2 处;
(c)中,S5 又崩溃了;S1 重新启动,选举成功,开始复制日志。在这时,来自任期 2 的那条日志已经被复制到了集群中的大多数机器上,但是还没有被提交;
(d) 中,S1又崩溃了,S5 可以重新被选举成功(通过来自 S2,S3 和 S4 的选票),然后覆盖了他们在索引 2 处的日志。注意:虽然s2复制日志过半,但是S5节点的任期号大,日志新,是可以接收S2选票;反之S1在崩溃前把新接收到的日志复制到大多数机器中,如(e)所示的情况。
(e) 中那样,那么在后面任期里面这些新的日志条目就会被提交(因为S5 就不可能选举成功)。 这样在同一时刻就同时保证了,之前的所有老的日志条目就会被提交。
候选者和跟随者安全性
候选者,跟随者奔溃以后,领导者就是简单的周期性的发送RPC请求,如果重启发生在节点处理完日志复制,响RPC请求之前,收到一样的RPC请求正常返回即可,没有任何问题。如果崩溃时间太长,重启以后落后其他节点日志太多,将会采取快照的方式进行恢复。
Raft的RPC请求是幂等的。
可用性
Raft的要求之一就是安全性不能依赖时间:整个系统不能因为某些事件运行的比预期快一点或者慢一点就产生了错误的结果。但是,可用性(系统可以及时的响应客户端)不可避免的要依赖于时间。这个时候就又会有一些限制;
-
服务器故障的时间必须比消息交换的时间长,否则每当一个节点要收集到足够多选票的时候就宕机了,新一轮的投票又重复这个过程,导致足够的时间选出领导人。
-
广播的世界必须小于选举超时时间一个数量级,这样领导者才能发送稳定的心跳阻止跟随者进入候选人状态。
-
当领导者崩溃后,整个系统在大约等于选举超时时间中不可用,所以平均故障间隔时间要大于选举超时时间几个数量级,系统可用性才比较高。
一般来说,广播时间在10毫秒左右,选举超时时间在300毫秒左右,服务器平均故障时间都大于一个月。
在前面文章中介绍了Raft算法的正常流程和对异常的处理,但是还有一些问题没有解决,比如当集群中有新的节点加入或者退出的时候,集群又该如何保证安全的提供服务呢?
增删集群节点
最容易想到的方法就是暂停整个集群,更新配置,然后重启集群。但是问题显而易见,在更新配置期间集群是不可用的,而手工操作配置文件,而且是操作多个节点的配置文件,也会造成很大的风险。为了避免发生这些风险,Raft算法添加了自动化配置变更的内容。
从旧的配置直接变更到新的配置的各种方法都是不安全的,其中最大的问题就是容易出现脑裂集群分裂,举个例子;
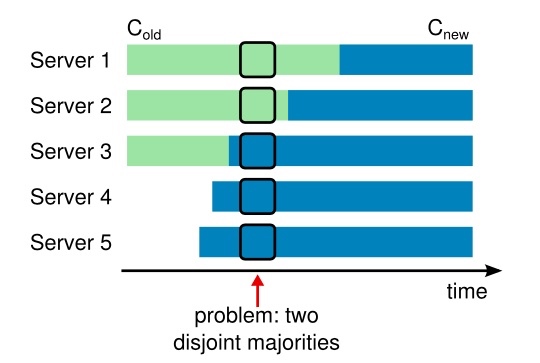
旧配置有 1, 2, 3号节点,候选人只需要两张选票就可以变为领导者,除了自己的一张选票,还需要等待一个节点投票给自己即可,但是当集群增加2个节点的时候,旧节点之间是无法感知有几个节点加入网络的,所以还会按照旧配置投票,即收集到两张选票就可以成为候选人。而新节点是可以感知到集群中是有5个节点的,所以新节点要成为领导者需要3张选票,必然有一个时间点,既可满足旧节点的候选人选举要求,又可满足新节点的选举要求,脑裂就这样发生了。
显而易见,出现脑裂的问题是由于同一时间新旧配置节点各自单方面的作出了选领导者的决定。
停集群,更新配置,重启集群其实目的就是保证了同一时间只有一种状态,为了解决集群的可用性,Raft采取了两段提交来保证安全的变更日志。
配置变更流程
首先当一个领导者收到一个改变配置从C-old到C-new的请求时,它会merge(C-old, C-new)并且保存到自己的日志中,然后复制到集群中的其他节点,在C-new提交之前,所有节点的决定都会基于C-old,new的配置做决定。
在C-old, new被提交以后,领导者创建一条C-new的配置复制到集群,当C-new被提交以后,就旧配置指定的节点就无关紧要了,在集群中不可见了,可以从集群移除。
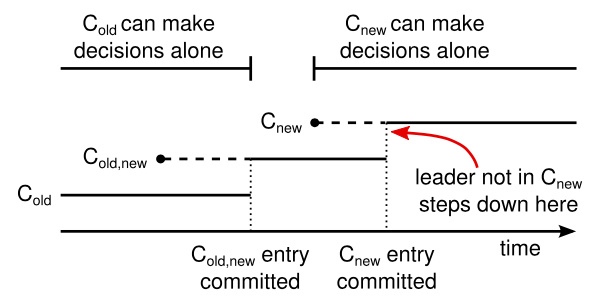
异常处理流程
节点宕机
但是在这个过程中还是会有节点宕机的异常情况发生,Raft又是如何保证整个增删节点过程的安全性呢?
如果领导者在复制包含配置文件的日志时候崩溃了,跟随者节点只有两种配置状态,C-old,new或者C-old,主要观察C-old,new是否能被复制到了大多数节点。但是无论哪种状态,C-new都不会单方面做出决定。
空白节点加入
当一个新的服务器加入集群,新服务器本身是没有存储任何日志,是无法提交集群中的任何一条日志的,需要一段时间来追赶,Raft为了避免这种可用性的时间间隔太长,采取了节点静默加入集群,但是没有投票权,只是同步日志,当新节点已经可以跟上集群日志的时候再投票加入集群。
旧节点干扰
当C-new被提交以后,就需要移除不在C-new中的节点。在C-new被提交后,需要移除的节点就接收不到领导者的心跳消息,这个时候这些节点认为领导者可能出现了故障,会发起选举,正常执行的领导者收到投票请求后会退回到跟随者状态等待新领导者被选出,虽然最终正确的领导者会被选出,但是频繁的选举流程会扰乱集群的可用性。
为了避免这个问题,Raft采用了最小选举超时时间的机制,当服务器在当前最小选举超时时间内收到一个请求投票 RPC,他不会更新当前的任期号或者投出选票,这样就避免了频繁的状态切换。
领导者不在新集群中
还有一种可能是领导者不在新集群中,当配置文件从C-old,new变更到C-new时,领导者不在C-new中,这个时候就会在一段时间内发生旧节点管理新集群的情况。
Raft中解决方法很简单,当提交C-new成功的时候,自己的状态变为跟随者,这样领导者节点就只能在新集群中选出。
日志压缩
Raft算法在运行的过程中,日志是不断累积的,但是在实际的系统中,无论是从日志占用的磁盘空间,还是新节点加入集群,同步日志的网络消耗来看,日志都不能无限的增长。
Raft采用快照的方法来压缩日志,快照时间点前的日志全部丢弃。
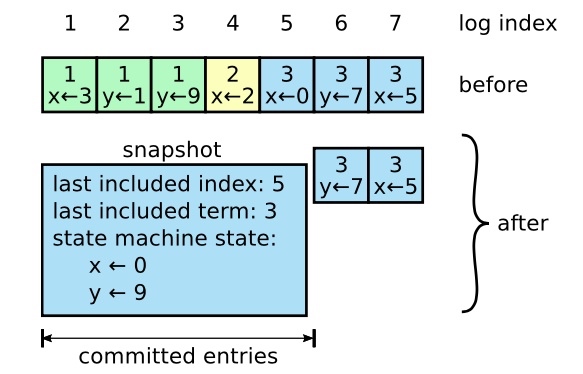
每个服务器根据已经提交的日志,独立创建快照,快照中包含;
- 状态机最后应用的日志;
- 状态机最后应用日志的任期号;
- 状态机最后应用的配置文件内容;
领导者周期性的发送一些快照给跟随者,与领导者,保持同步的节点已经提交了快照的内容,会直接丢弃,而运行缓慢或者新加入集群的服务器则不会有这个条目,就会接受并且应用的自己的状态机中。
本文作者是深入浅出区块链共建者清源,欢迎关注清源的博客,不定期分享一些区块链底层技术文章。





