如何回填 Solana 交易数据
- QuickNode
- 发布于 2024-12-20 20:46
- 阅读 1594
本文介绍了如何使用QuickNode的Streams工具从Solana区块链中提取和过滤历史数据,并将其存储到Postgres数据库中。文章详细讲解了如何创建Stream、过滤数据、设置数据库以及配置Stream的目标。
概述
获取 Solana 的历史数据可能是一个挑战,而且通常你只需要特定子集的区块数据(例如,给定税务年度内的钱包转账)。Streams 是一个强大的工具,允许你从 Solana 检索和过滤实时或历史数据,并将其发送到你选择的目的地(例如,Webhooks、Postgres 数据库、Snowflake、AWS)。本指南将向你展示如何使用 Streams 回填历史 Solana 数据,这些数据经过过滤以选择性解析你所需的数据,并将其发送到 Postgres 数据库。
查看快速视频演示,了解 Solana Streams 的实际操作。
Solana Streams 演示 - YouTube
QuickNode
131K 订阅者
QuickNode
搜索
信息
购物
点击取消静音
如果播放没有立即开始,请尝试重新启动你的设备。
你已退出登录
你观看的视频可能会被添加到电视的观看历史记录中,并影响电视推荐。为避免这种情况,请取消并在电脑上登录 YouTube。
取消确认
分享
包括播放列表
检索共享信息时出错。请稍后再试。
稍后观看
分享
复制链接
在 YouTube 上观看
0:00
/ •直播
•
订阅我们的 YouTube 频道以获取更多视频!订阅
让我们开始吧!
你将做什么
- 在 QuickNode 上创建一个 Stream
- 过滤指定的 Solana 区块历史范围,以检索指定钱包的 SOL 转账
- 创建一个 Supabase Postgres 数据库来存储过滤后的数据
- 将过滤后的数据路由到你的数据库
- 在你的数据库中创建一个包含解析后的交易数据的表
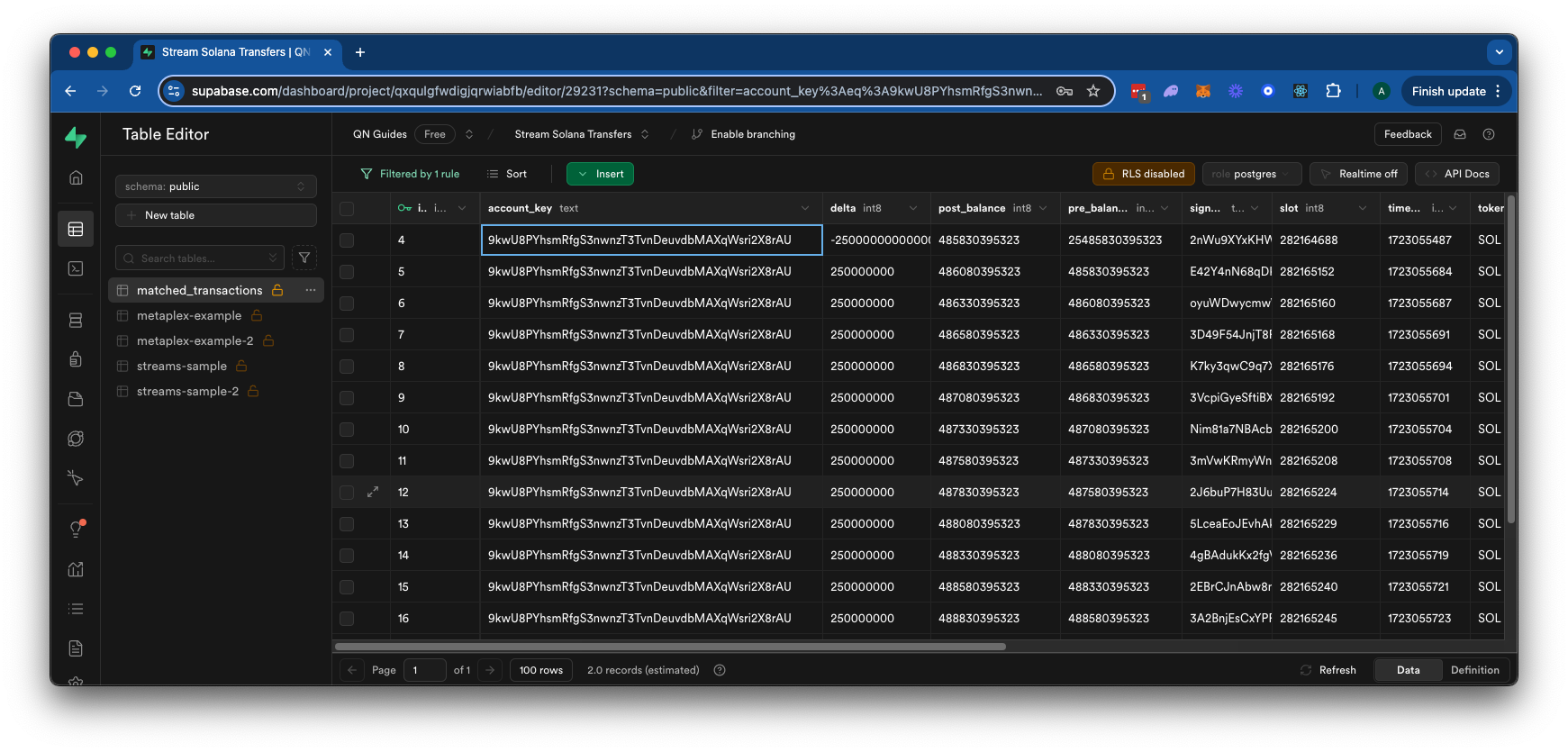
在本指南结束时,你将拥有一个 Postgres 数据库,其中包含特定钱包的过滤后的 Solana 交易数据,如下所示:
你将需要什么
- 一个 QuickNode 账户
- Solana 基础知识
- 一个 Postgres 数据库 - 在本指南中我们将使用 Supabase,但你可以自由选择任何 Postgres 数据库
步骤 1:创建 Stream
从你的 QuickNode 仪表板导航到 Streams 页面,点击“+ 创建 Stream”按钮,或在此处创建一个 这里。
从设置卡中选择“Solana”和“Mainnet”:
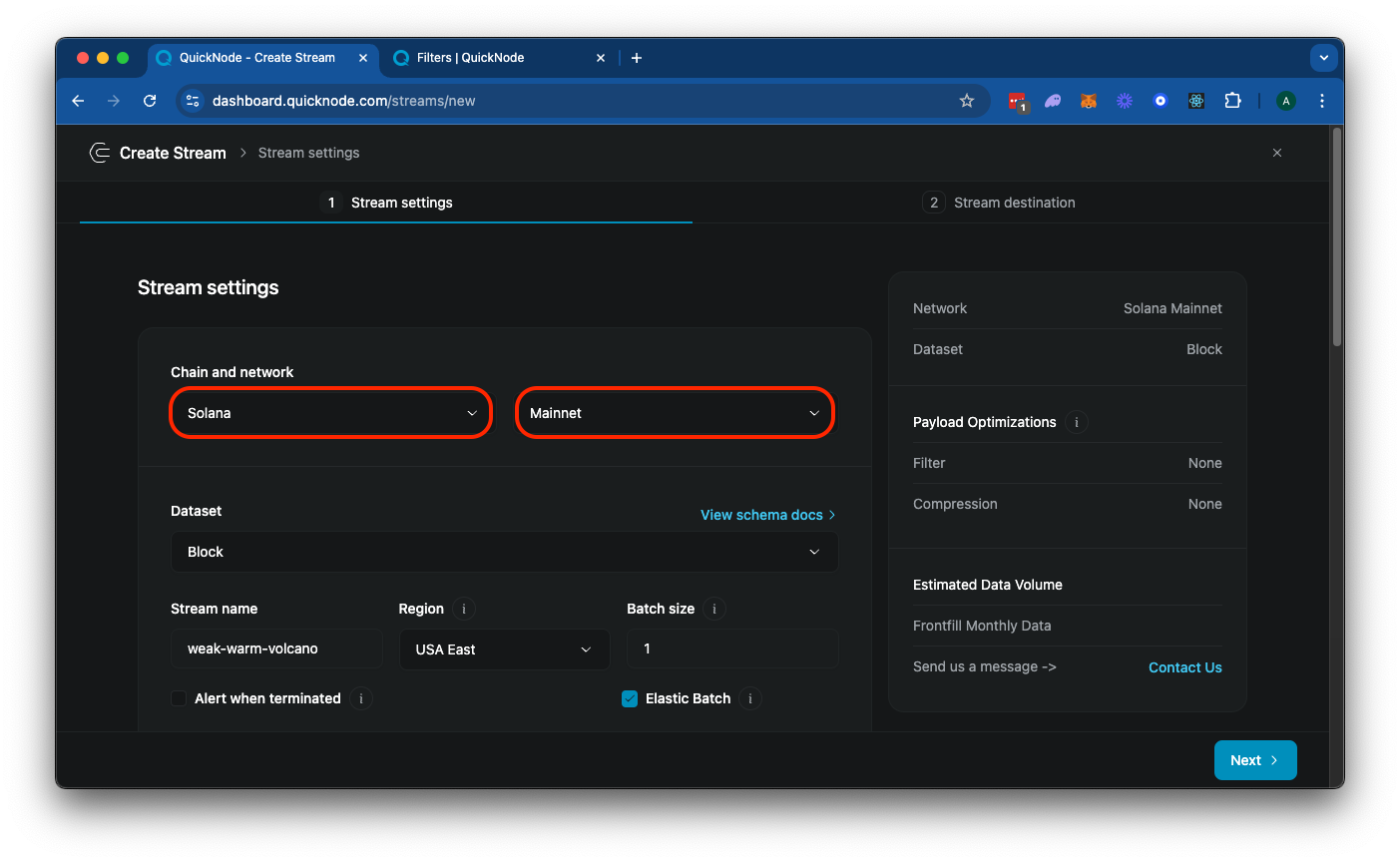
你可以为你的 Stream 添加一个唯一的名称,或者直接使用随机生成的名称。你还会注意到一个选项来批量处理你的 Stream 数据。默认设置 1 针对实时数据流进行了优化。根据你的数据量和数据处理能力,适合你的用例的值可能会有所不同。对于此示例,尝试使用批量大小为 10 并根据需要调整,以最好地服务于你的用例和操作环境。
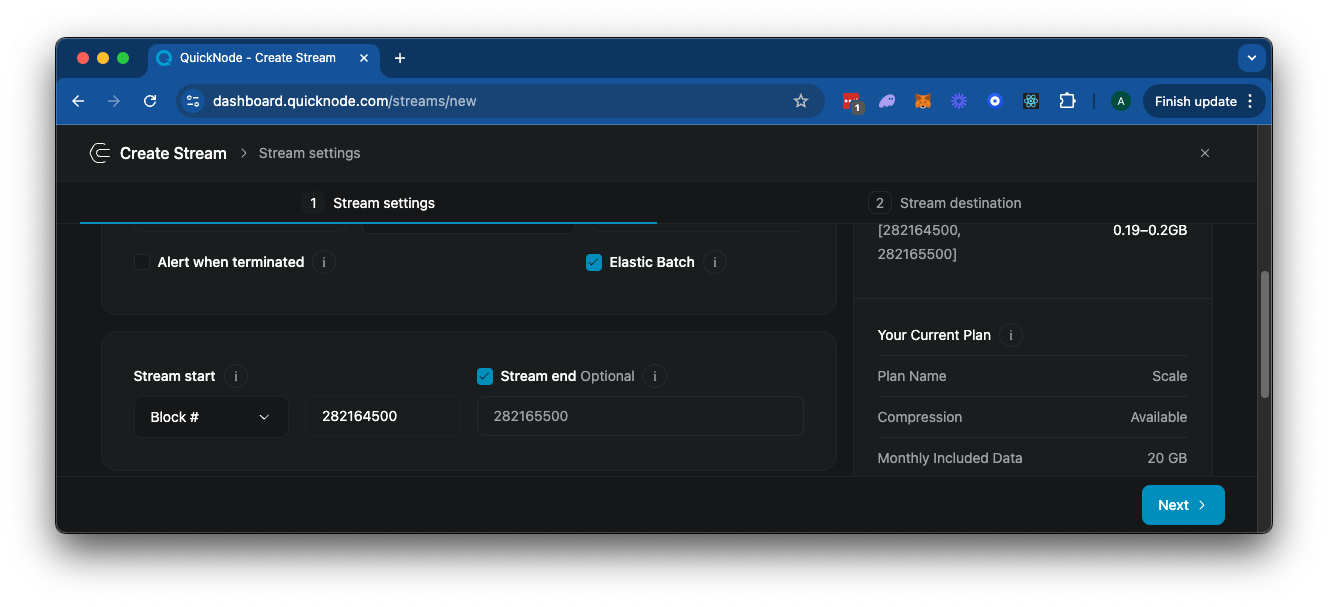
接下来,向下滚动到“Stream Start”选项,确保选择“Block #”(用于历史数据)。输入你要开始的区块高度(我们将在此演示中使用 282164500 到 282165500)。由于我们希望指定一个固定的结束区块,请切换该选项并指定结束区块。
接下来,选择“在流式传输之前修改有效负载”。这是一个非常重要的步骤,因为你只需为你发送到目的地的数据量付费。我们的过滤器将允许我们:
- 仅过滤你所需的数据(在这种情况下,我们将过滤包含指定钱包地址并包含 SOL 余额变化的交易)
- 根据需要修改返回的数据(在这种情况下,我们将仅返回有关交易的一些详细信息,包括余额变化前后的数据)
或者,如果你不过滤数据,你将收到每个区块的所有区块数据,这可能会非常庞大且昂贵。返回的区块数据来自 Solana 的 getBlock RPC 方法,并返回一个 JSON 对象,如下所示:
{
"blockHeight": 270646103,
"blockTime": 1727197869,
"blockhash": "52egMfezPu8MfzMc1ZPzZAaR6o7ZuJ4633VQPCyDbotJ",
"parentSlot": 291763038,
"previousBlockhash": "GG8Y7BEvZf3CRixX5k8GraDSkofcMLC9mXAqteuwKR7d",
"transactions": [\
/* ... 区块中的所有交易 ... */\
],
}
接下来,你应该会看到一个 JavaScript 代码编辑器,用于你的 main 函数。这是你的 Stream 过滤器的入口点(查看我们的 文档 以获取有关过滤器的更多信息)。默认代码如下:
function main(stream) {
const data = stream.data
return data;
}
stream 对象包括 data 和 metadata 字段。data 字段包含有效负载数据,metadata 字段包含 Stream 的元数据。点击“▶️ 运行测试”来测试你的 Stream。由于 Solana 区块非常大,这将需要几秒钟来加载。最终,它应该会有效地返回指定“测试区块”的区块数据:
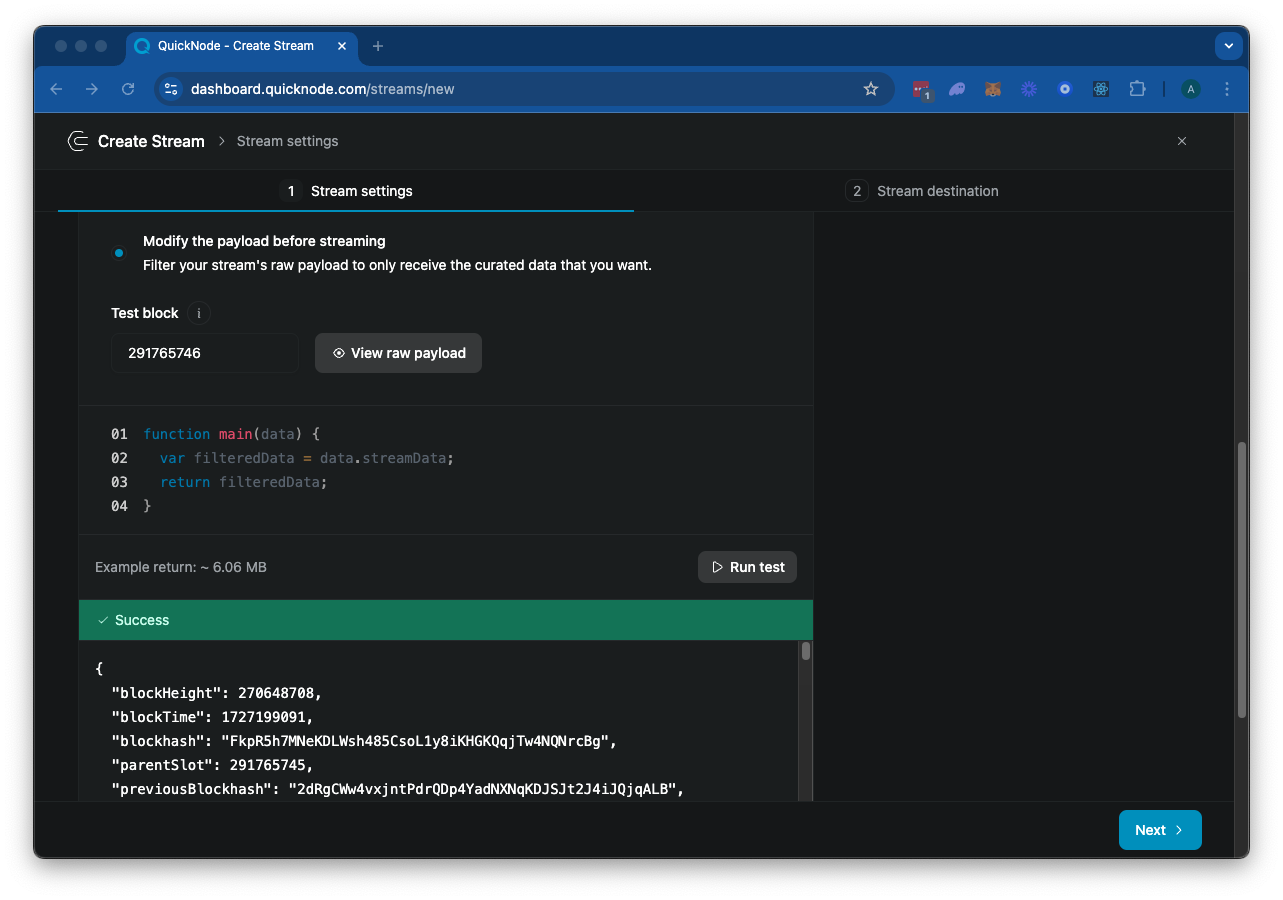
你可以自由滚动浏览响应。那里有很多内容——让我们看看是否可以将其过滤到我们所需的数据。
步骤 2:过滤 Stream 数据
我们的区块中有大量数据。让我们思考一下如何将其过滤到仅显示我们想要看到的数据。对于此示例,我们计划我们的有效负载包含一个 matchedTransactions 数组,其中包含每个交易的 signature、timeStamp、slot、delta(SOL 余额变化)、token(在本例中仅为 SOL)、accountKey、preBalance 和 postBalance:
{
"matchedTransactions": [\
{\
"slot": "number",\
"delta": "number",\
"token": "SOL",\
"signature": "string",\
"timeStamp": "number",\
"accountKey": "string",\
"preBalance": "number",\
"postBalance": "number"\
}\
]
}
所以,让我们思考一下我们的过滤器需要做什么:
- 过滤掉失败的交易(原始区块数据将包括失败的交易)
- 过滤包含我们指定钱包地址的交易
- 过滤这些交易,仅包括那些包含目标钱包的 SOL 余额变化的交易
- 最后,在过滤完我们的数据后,我们需要格式化交易数据以适应我们的有效负载
让我们来创建它。
创建入口点
在你的 Streams 页面中,将现有的 main 函数替换为以下内容:
const FILTER_CONFIG = {
accountId: '9kwU8PYhsmRfgS3nwnzT3TvnDeuvdbMAXqWsri2X8rAU',
skipFailed: true,
};
function main(stream) {
try {
const data = stream.data[0]
if (!data?.transactions?.length) {
return { error: 'Invalid or missing stream' };
}
const matchedTransactions = data.transactions
.map(tx => processTransaction(tx, data))
.filter(Boolean);
return { matchedTransactions };
} catch (error) {
return { error: error.message, stack: error.stack };
}
}
我们在这里做的是:
- 首先,我们定义一个
FILTER_CONFIG对象,其中包含要搜索的账户 ID 以及是否跳过失败的交易 - 然后,我们通过在没有收到数据时抛出错误来确保 Stream 数据有效
- 然后我们通过使用
processTransaction函数来过滤和格式化交易 - 最后,如果有的话,我们将返回
matchedTransactions数组中的格式化交易
很好。现在,我们只需要定义 processTransaction 来过滤和清理我们的交易数据。
定义处理交易函数
让我们将 processTransaction 函数添加到你的代码块底部:
function processTransaction(transactionWithMeta, stream) {
const { meta, transaction } = transactionWithMeta;
if (FILTER_CONFIG.skipFailed && meta.err !== null) {
return null;
}
const accountIndex = transaction.message.accountKeys.findIndex(account =>
account.pubkey === FILTER_CONFIG.accountId
);
if (accountIndex === -1) {
return null;
}
const preBalance = meta.preBalances[accountIndex];
const postBalance = meta.postBalances[accountIndex];
const delta = postBalance - preBalance;
if (delta === 0) {
return null;
}
return {
signature: transaction.signatures[0],
slot: stream.parentSlot + 1,
timeStamp: stream.blockTime,
accountKey: FILTER_CONFIG.accountId,
preBalance,
postBalance,
delta,
token: "SOL"
};
}
这个函数的作用是:
- 首先,我们检查交易是否失败,如果是,则返回
null以跳过该交易 - 然后,我们在
transaction.message.accountKeys数组中找到与FILTER_CONFIG.accountId匹配的账户索引 - 如果账户索引为 -1(未找到),我们返回
null以跳过该交易 - 我们使用
meta.preBalances和meta.postBalances获取账户的余额变化前后的数据 - 我们计算余额变化前后的差值
- 如果差值为 0,我们返回
null以跳过该交易 - 最后,我们返回一个包含签名、插槽、时间戳、账户密钥、余额变化前后的数据、差值和代币的对象
测试你的 Stream
如果你向上滚动到代码块上方,你会看到一个“测试区块”字段。这是我们将用于测试我们的 Stream 的区块号。在这种情况下,我找到了一个我知道包含成功_创建_交易的区块。将该字段更改为“282164688”,然后点击“▶️ 运行测试”。如果你使用了与我们相同的账户 ID(9kwU8PYhsmRfgS3nwnzT3TvnDeuvdbMAXqWsri2X8rAU),你应该会看到以下响应:
{
"matchedTransactions": [\
{\
"accountKey": "9kwU8PYhsmRfgS3nwnzT3TvnDeuvdbMAXqWsri2X8rAU",\
"delta": -25000000000000,\
"postBalance": 485830395323,\
"preBalance": 25485830395323,\
"signature": "2nWu9XYxKHWNiwGDHLnHYqrF3uGZCN5subE3rbuFqnxwoGQ11FxSEoz6CffmssYhqC43ewDyhiAhvPZNMSzbqVMC",\
"slot": 282164688,\
"timeStamp": 1723055487,\
"token": "SOL"\
}\
]
}
干得好!这表明在我们的测试区块中,有一笔交易改变了指定账户的余额。你会注意到这里的返回数据大小约为 300 B,而未过滤的区块数据约为 4.5 MB!点击右下角的“下一步”继续下一步。
步骤 3:设置你的数据库
在部署我们的 Stream 之前,我们需要一个目的地来发送数据。如果你想使用 webhook,你可以查看我们的指南 如何流式传输实时 Solana 程序数据,但在本演示中,我们将把数据发送到 Postgres 数据库。
为此,我们需要设置一个 Postgres 数据库。如果你还没有,你可以在此处创建一个 这里。确保在创建时记下你的数据库密码——你在配置 Stream 时将需要它。
我们的 Stream 实际上会在你的表中初始化一个表来存储数据,所以我们不需要担心这一点。我们只需要获取数据库连接信息并将其发送到你的 Stream。如果你使用的是 Supabase,你可以在“项目设置”页面的“数据库”选项卡中找到连接信息:
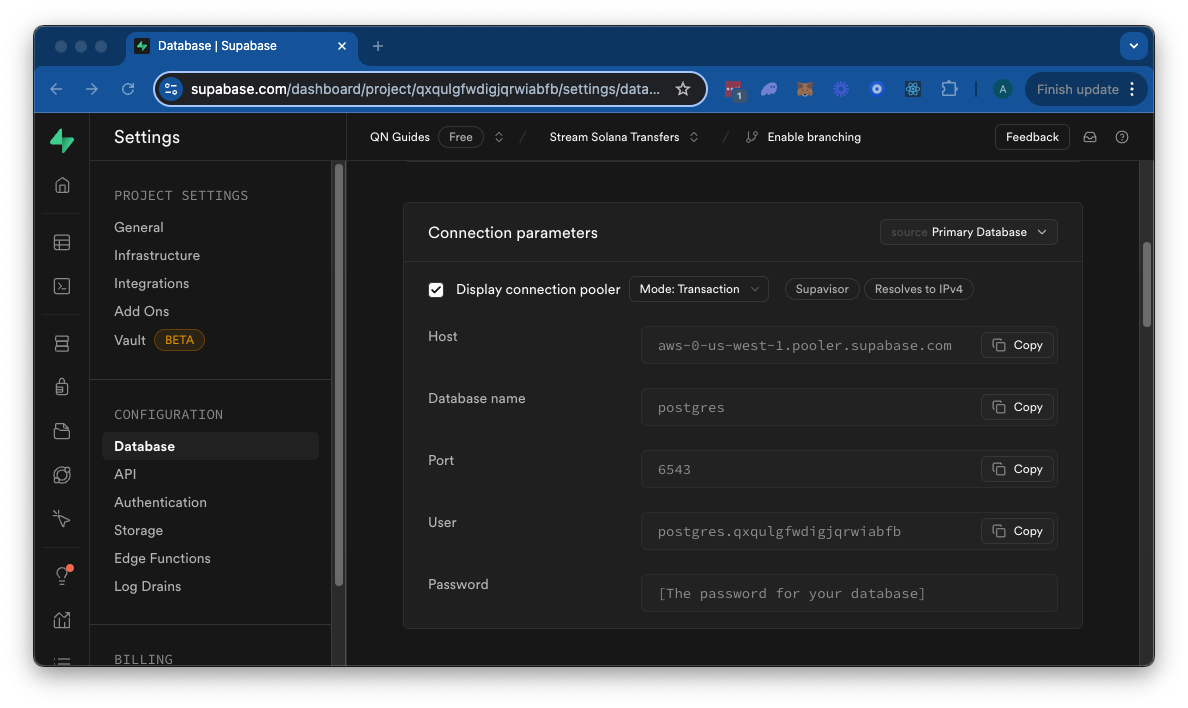
保留这些信息,让我们回到我们的 Stream 配置页面。
步骤 4:配置你的 Stream 的目的地
现在我们的服务器已经运行并暴露在互联网上,让我们配置我们的 Stream 以将数据发送到它:
- 回到你的 Stream 配置页面。
- 在“目的地类型”部分,选择“PostgreSQL”。
- 输入你的 Postgres 数据库的数据库连接信息。你可以为表命名——我们将使用
metaplex-example。
你的 Stream 配置应该如下所示:
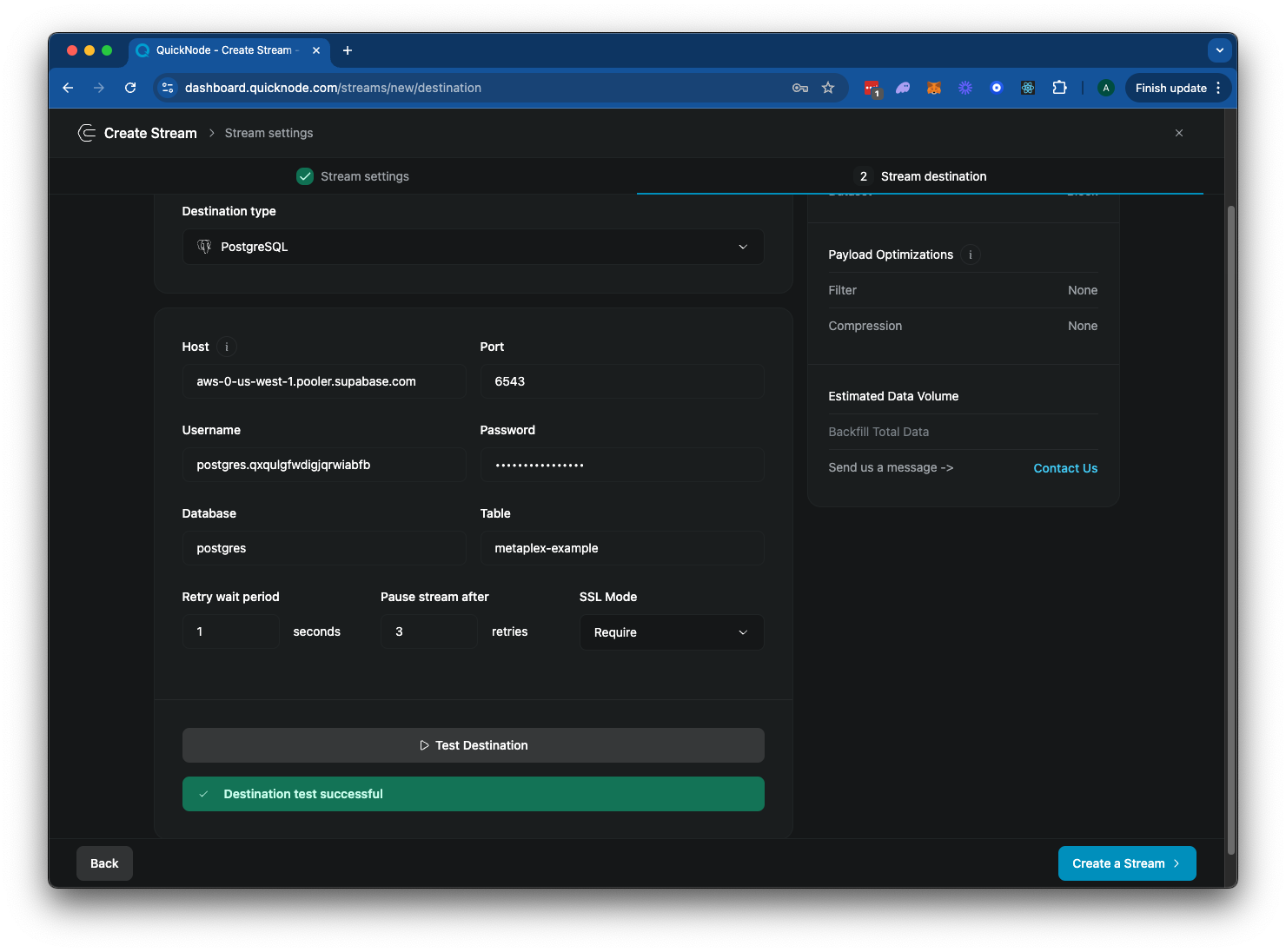
点击“▶️ 测试目的地”以确保你的连接凭据正确。然后点击“创建 Stream”以完成你的配置。
在几分钟内,我们过滤后的区块数据应该会开始出现在你的数据库中。如果你导航到 Supabase 的表查看器,你应该会看到数据正在填充:
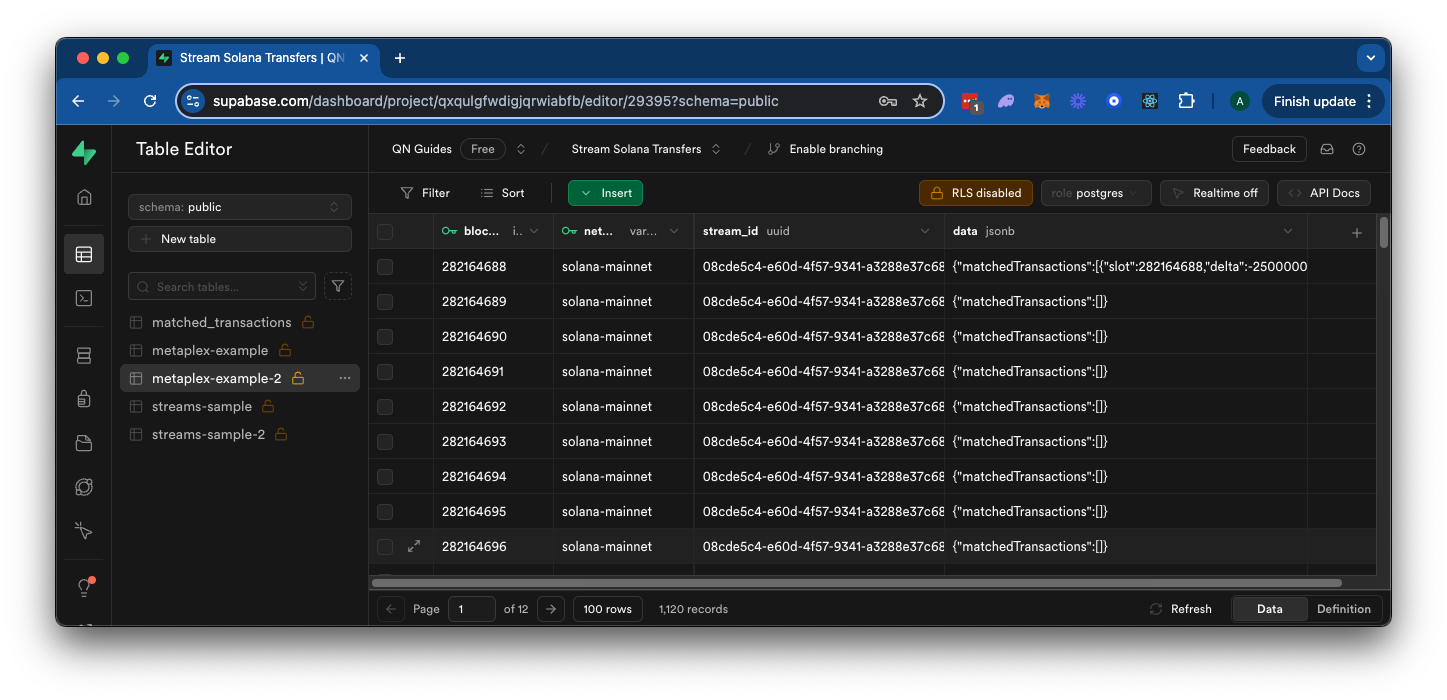
干得好!你的 Stream 现在已设置为过滤新的 Solana 交易并将数据发送到你的本地 Postgres 数据库。如果你愿意,你可以向你的数据库添加一些自定义 SQL 以解析返回的数据并将其存储在不同的格式中。以下是你可能如何做到这一点的示例:
在 SQL 编辑器中,添加以下代码:
CREATE TABLE IF NOT EXISTS matched_transactions (
id SERIAL PRIMARY KEY,
account_key TEXT NOT NULL,
delta BIGINT NOT NULL,
post_balance BIGINT NOT NULL,
pre_balance BIGINT NOT NULL,
signature TEXT UNIQUE NOT NULL,
slot BIGINT NOT NULL,
time_stamp BIGINT NOT NULL,
token TEXT NOT NULL,
block_number BIGINT NOT NULL,
network TEXT NOT NULL,
stream_id TEXT NOT NULL,
created_on TIMESTAMPTZ DEFAULT NOW()
);
-- 在签名上创建索引以加快查找速度
CREATE INDEX IF NOT EXISTS idx_matched_transactions_signature ON matched_transactions(signature);
然后按“运行”。这应该会在你的数据库中创建一个新表,其结构与我们在 Stream 中创建的表相同。现在,让我们运行一个脚本来用我们的数据填充该表:
INSERT INTO matched_transactions (
account_key,
delta,
post_balance,
pre_balance,
signature,
slot,
time_stamp,
token,
block_number,
network,
stream_id
)
SELECT
(transaction_data->>'accountKey')::TEXT,
(transaction_data->>'delta')::BIGINT,
(transaction_data->>'postBalance')::BIGINT,
(transaction_data->>'preBalance')::BIGINT,
(transaction_data->>'signature')::TEXT,
(transaction_data->>'slot')::BIGINT,
(transaction_data->>'timeStamp')::BIGINT,
(transaction_data->>'token')::TEXT,
se.block_number,
se.network,
se.stream_id
FROM
-- 确保将表名替换为你在 Stream 中创建的表名 👇
"metaplex-example" se,
jsonb_array_elements(
CASE
WHEN se.data->>'error' IS NOT NULL THEN '[]'::jsonb
ELSE se.data->'matchedTransactions'
END
) as transaction_data
WHERE
se.data->>'error' IS NULL
ON CONFLICT (signature) DO NOTHING;
此脚本将我们 Stream 表中的所有交易插入到我们创建的新表中。你可以通过在 Supabase 的 SQL 编辑器中点击“运行”来运行此脚本。你应该会得到响应,“成功。没有返回行。”这意味着脚本成功运行。然后你可以导航到你的表编辑器,并在新表中看到解析后的数据:
继续构建!
你现在拥有了使用 Streams 构建自己的应用程序的工具。请记住,我们创建的过滤器只是一个示例——你可以想到的可能性是无限的。随意修改过滤器逻辑以查找不同的程序、账户或指令。你还可以向你的服务器添加更复杂的处理逻辑。祝你流式传输愉快!
寻找一些继续构建的灵感?查看这些资源:
- 使用 QuickNode 的键值存储 来跟踪多个钱包或程序
- 创建自定义 QuickNode 函数 以自动化工作流并进一步处理你的数据(例如,也许可以自动化我们刚刚运行的 SQL 过程)
无论你在构建什么,我们都希望听到你的消息。
- 原文链接: quicknode.com/guides/qui...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





