深入探讨 Solana 的 AccountsDB
- Anza
- 发布于 2024-08-14 20:45
- 阅读 2090
文章涵盖了快照的组成部分、账户文件的存储及读取方法,并探讨了账户索引的构建与数据压缩策略。尤其强调了各个后台线程(如刷新、清理、缩减和清除)如何有效管理内存,确保信息高效存储与访问。整体内容逻辑清晰,技术细节深入,对于区块链数据管理的理解提供了重要的视角。
AccountsDB是什么
在 Solana 中,所有数据都存储在称为“帐户”中。在Solana上组织数据的方式类似于键 - 值存储,其中数据库中的每个条目都称为“帐户”。AccountsDB是由验证者存储的帐户数据库,该数据库由验证者存储,用于跟踪帐户数据。因此,它是Solana的关键组成部分。
快照
当新的验证者启动时,它必须首先跟上区块链的当前状态;在 Solana 中,这通过快照实现。快照包含特定槽位下区块链的完整状态(包括所有账户)。它们是从网络中现有的验证者请求/下载的,旨在为新的验证者提供引导(而不是从创世块开始)。
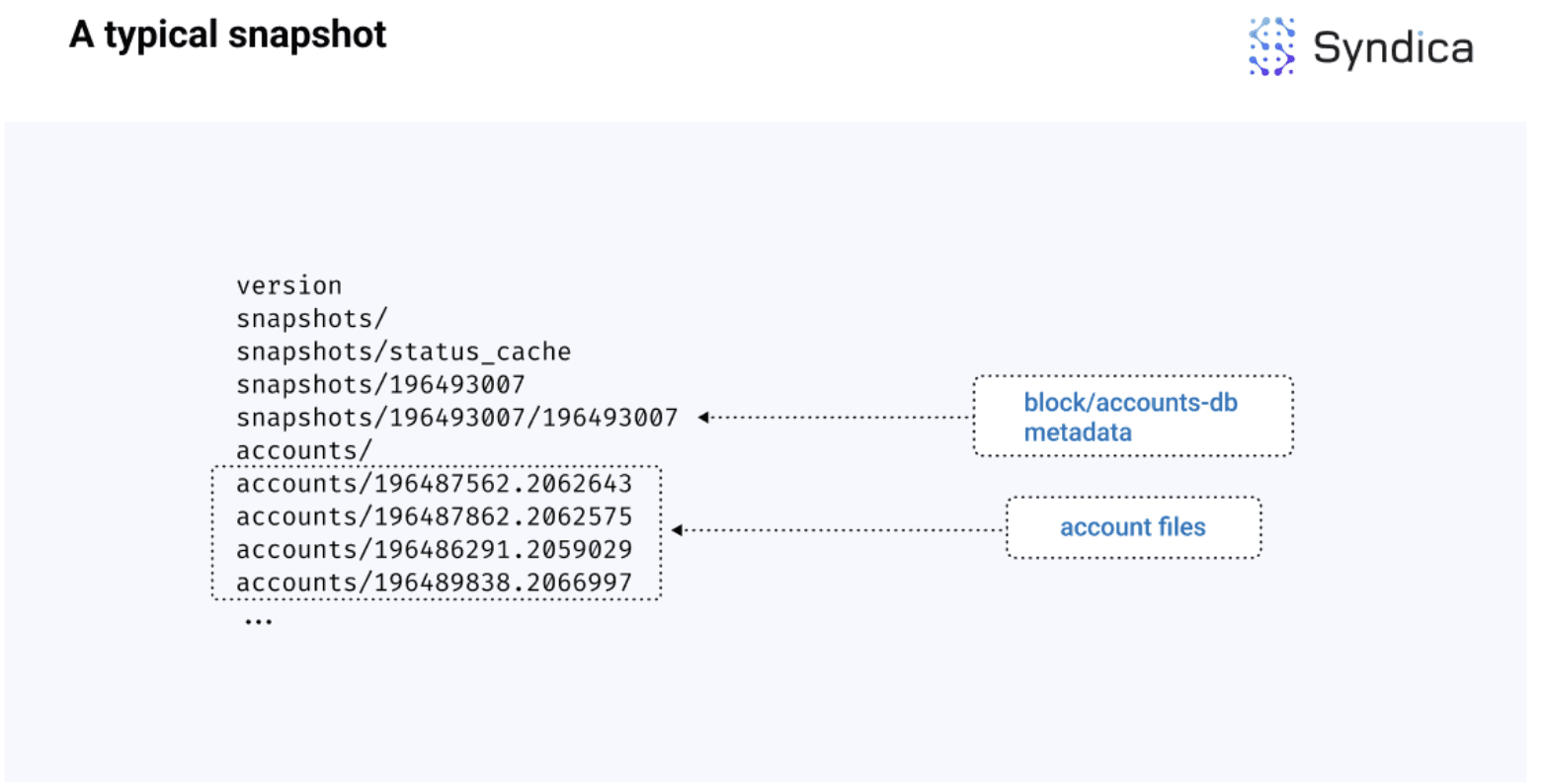
快照包含两个主要组成部分:
-
一个元数据文件,其中包含关于最新区块和数据库状态的信息
-
一个账户文件夹,包含存储账户数据的文件。
下面是一个标准的 Solana 快照在槽位 196493007 时的图示,其中高亮显示了这两个组件。
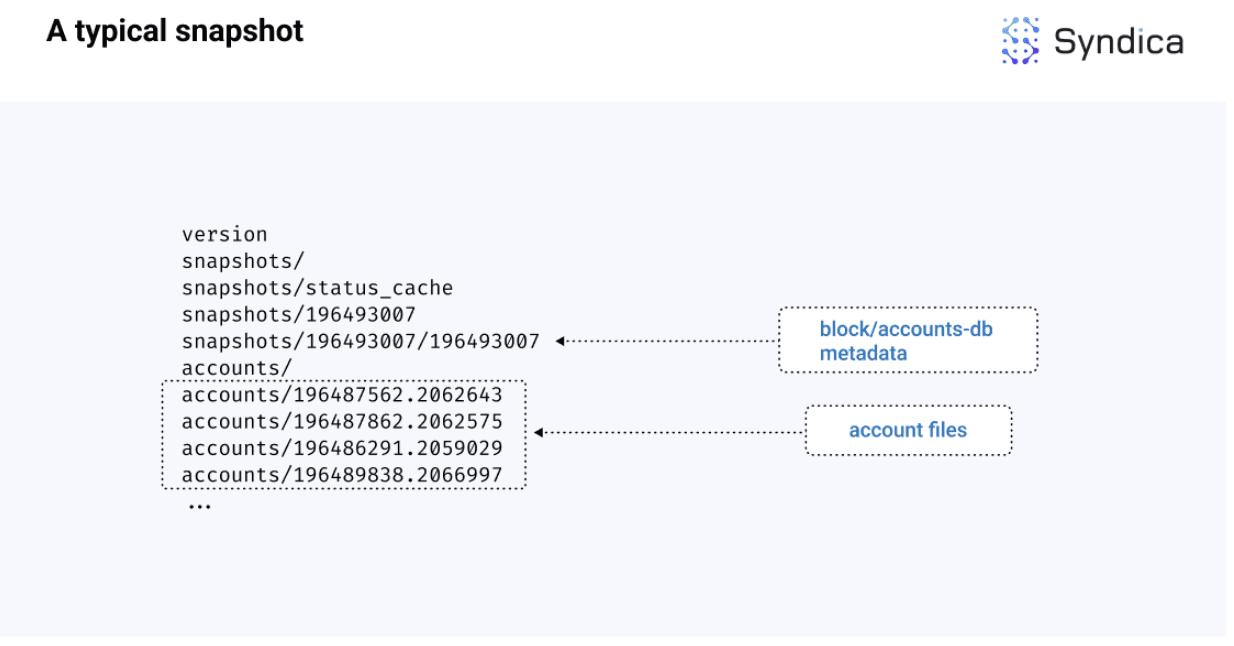
注意:快照是构建并下载为压缩的 tar 存档,采用 Zstandard 格式,因此文件扩展名通常为
.tar.zst。从快照加载时的第一步是将其解压缩并解档到如上所示的目录布局中。
账户文件
快照中的一个主要组成部分是账户文件,其中包含特定槽位的所有账户数据。每个文件都作为账户字节的列表组织。
注意:在 Rust 实现中,包含账户的文件称为 AppendVecs。然而,这个名称已经过时,因为代码库中不再使用追加,因此我们将在本文中称其为
账户文件。
读取这些数据涉及:
-
解压缩并解档快照到单独的账户文件中
-
单独将每个账户文件加载到内存中(通过
mmap系统调用) -
读取每个文件的整个长度,并将其组织成可供 AccountsDB 代码使用的结构
账户文件格式如下所示:
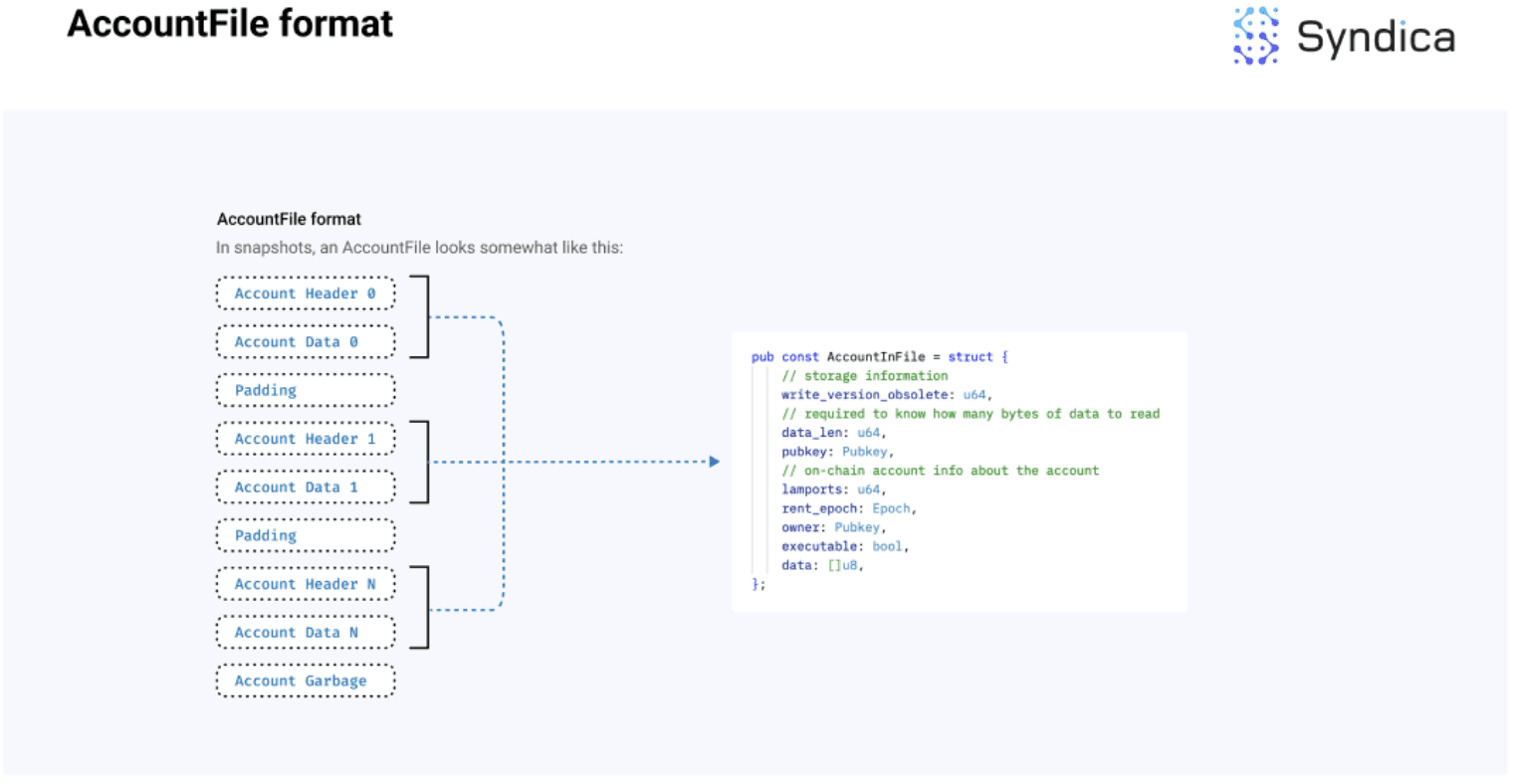
注意:由于账户的数据是变长数组,我们首先需要读取
data_len变量,以便知道需要读取多少字节到数据字段。在图中,账户头部存储了有关账户的有用元数据(包括data_len),而账户数据包含实际的数据字节。
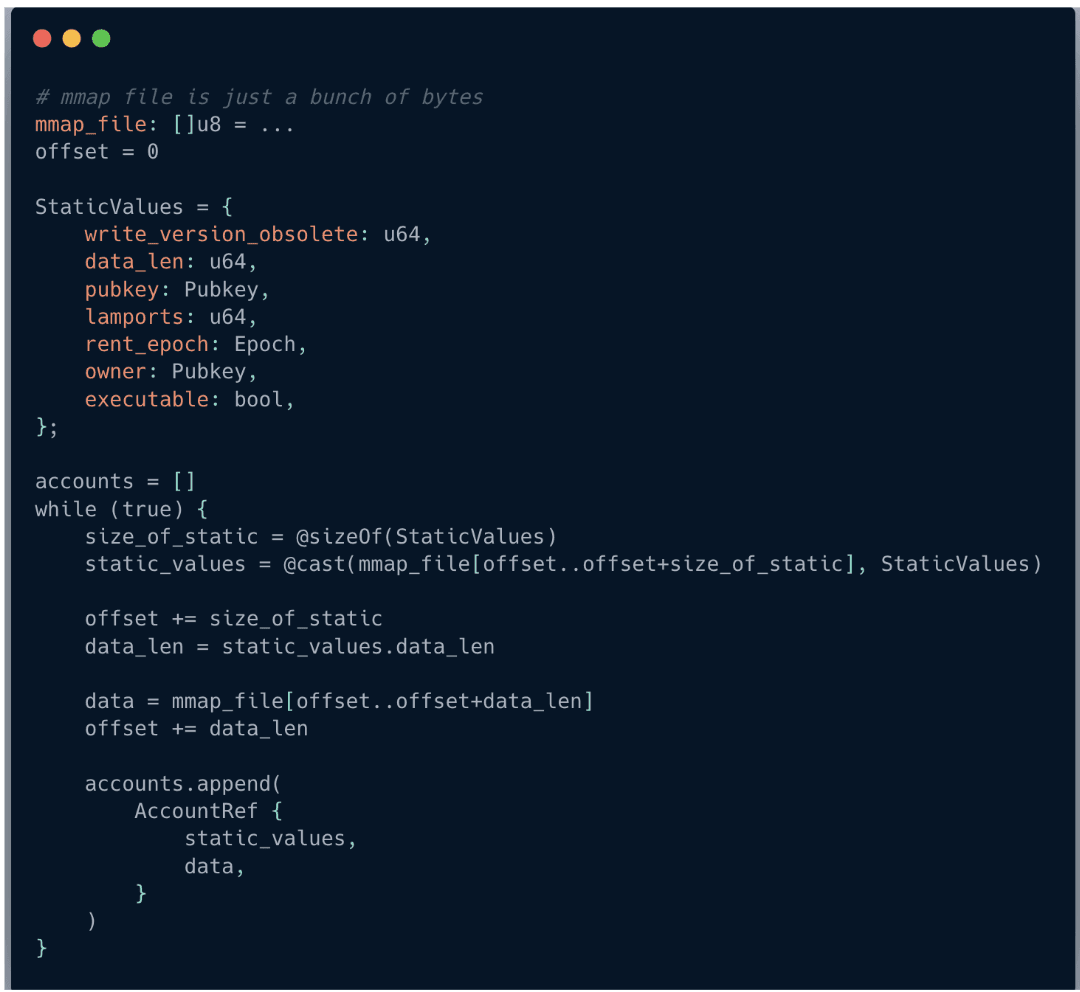
解析文件中所有账户的伪代码如下所示:
账户索引
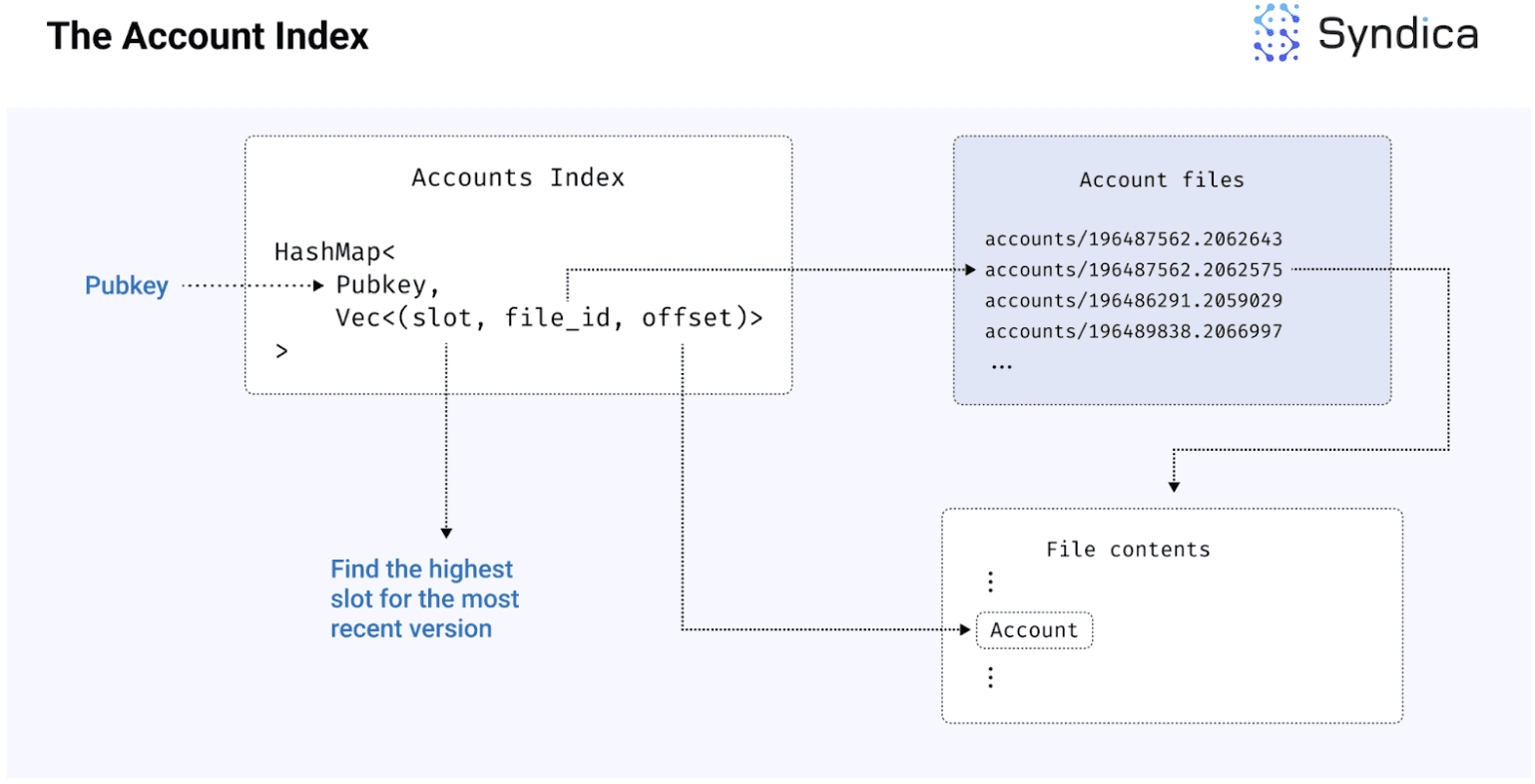
现在我们理解了如何组织账户文件以存储账户数据,我们还需要按账户的公钥组织这些数据,即,我们需要建立从给定 pubkey 到文件中相应账户位置的映射。这种映射也称为账户索引。
更具体地说,我们需要一个从 pubkey 到 (file_id, offset) 元组的映射,其中 file_id 是读取的账户文件的名称,而 offset 是文件中账户字节的索引。通过这个映射,我们可以通过打开与 file_id 相关的文件,并从 offset 开始读取字节,来访问 pubkey 的关联账户。
账户在槽位之间也可能发生变化(例如,快照可能会包含在不同槽位中相同账户的多个版本)。为了将每个账户的 Pubkey 与多个文件位置的集合(或 “Vec”)关联起来。在 Agave 中,每个槽位只会有单个账户文件。这意味着我们可以将账户索引结构化为 Map<Pubkey, Vec<(file_id, offset)>>,它将 pubkey 映射到一个账户引用集合。
要读取账户的最新状态,我们还需要找到具有最高槽位的引用,因此我们还可以跟踪与每个 file_id 相关的槽位。
因为 Solana 上有如此多的账户,索引可能变得非常大,这可能会导致较大的内存需求。为减少这些需求,Solana 使用基于磁盘的哈希映射。
账户引用默认存储在磁盘上。当访问 pubkey 并从磁盘读取时,其账户引用将缓存到基于 RAM 的哈希映射中,以便后续更快的访问。
在读取给定 pubkey 的账户时,通常的流程是:
-
首先检查 RAM 索引,
-
如果 pubkey 不在,则检查基于磁盘的索引,
-
如果也不在,则表示账户不存在。
读取账户
如果我们想从特定账户读取数据,并且知道账户的 pubkey,我们通过在账户索引中查找其 pubkey 来找到它在账户文件中的位置。我们将选择最新槽位的账户引用,然后从账户文件中的该位置读取数据。此数据可以被验证器直接解释为账户结构。
写入账户
AccountsDB 的另一个关键组成部分是跟踪新的账户状态。例如,当验证者处理一批新交易时,结果是在特定槽位下的一批新的账户状态。这些新状态随后需要写入数据库。
写入这些账户的两大主要步骤包括:
-
将账户数据写入与槽位相关的新账户文件中
-
更新索引以指向这些新账户的位置(即,为文件中每个账户附加一个新的 (slot, file_id, offset) 项)
后台线程
随着新账户状态写入数据库,我们必须确保通过执行 4 项关键任务来有效利用内存:
-
刷新,
-
清理,
-
收缩,
-
和清除
-
刷新
为减少内存需求,数据会定期从 RAM 刷新到磁盘。
例如,索引的基于 RAM 的哈希映射充当最近访问数据的缓存,当这些数据一段时间没有被使用时,它会被刷新到磁盘以为更新的账户索引腾出空间。
另一个例子是新账户状态首先存储在 RAM 中,直到相关的槽位被直连后才刷新到磁盘。这种方法减少了(缓慢的)磁盘写入次数,仅写入已根植的数据。
-
清理
为了限制内存增长,我们必须清理旧数据。
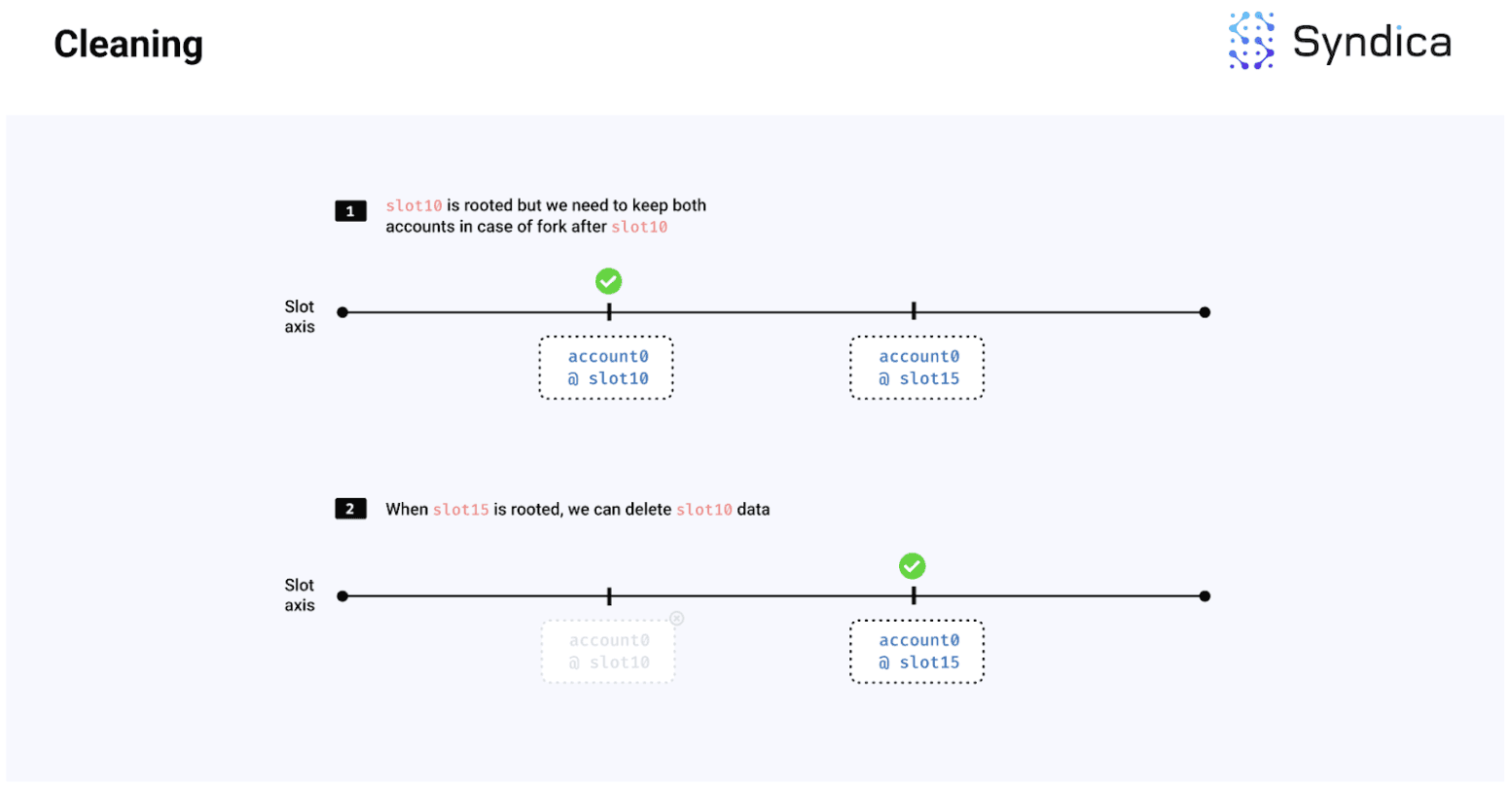
例如,如果我们有两个账户版本,一个在槽位 10,另一个在槽位 15,并且槽位 15 已根植(即不会回滚),那么我们可以删除与槽位 10 相关联的账户和索引数据。
清理的另一个例子是当一个账户的 lamports 为零时,此时我们可以删除整个账户。
注意:清理阶段会清除索引条目,但不会回收账户文件中曾被账户数据占用的存储区域。清理后,这一区域被视为在账户文件中的垃圾数据,浪费存储空间和网络带宽。
-
收缩
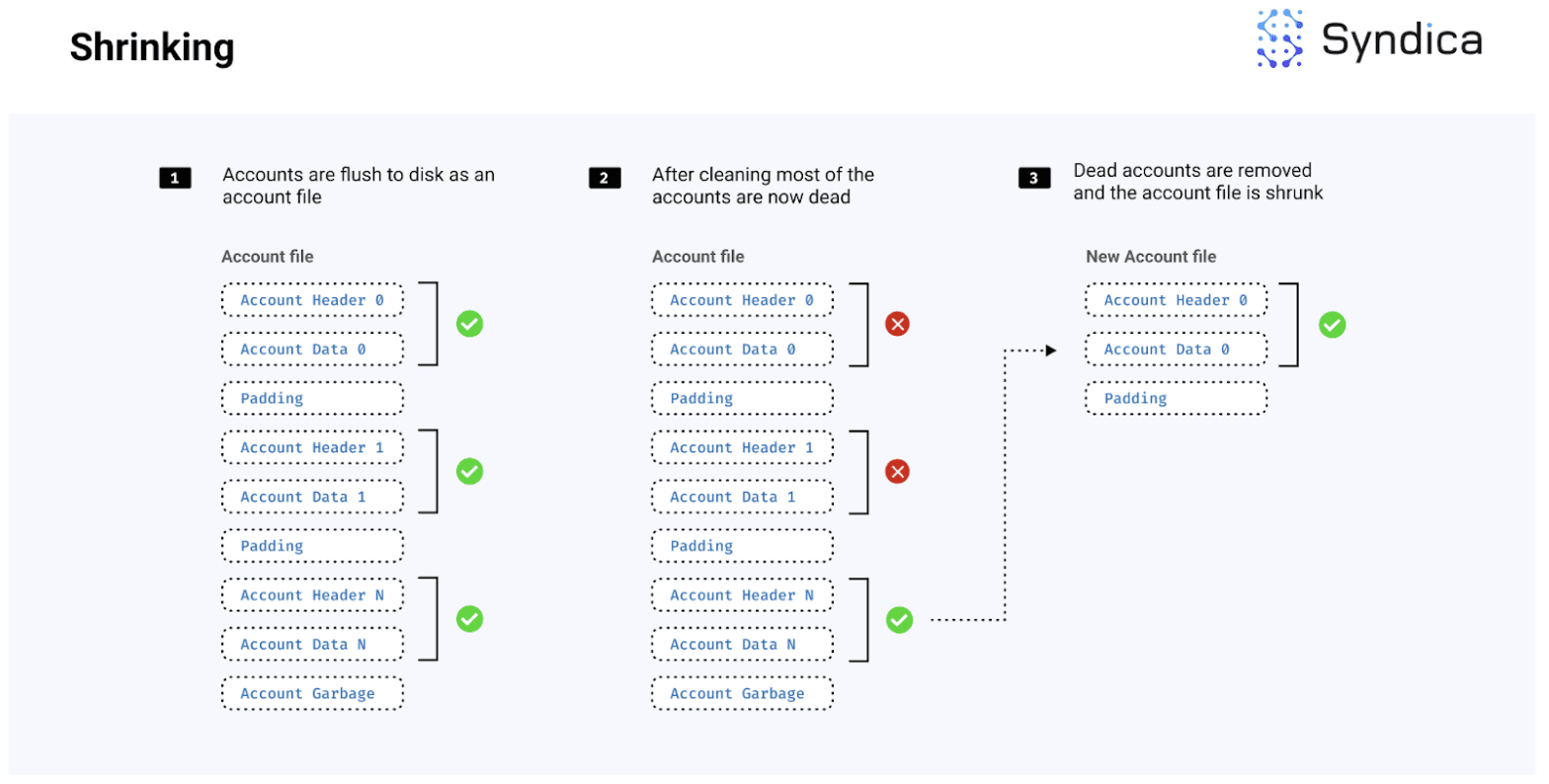
在账户被清理后,账户文件将包含“存活”和“已死”账户,其中“已死”账户已经被“清理”并因此不再需要。当一个账户文件中的存活账户数量很少时,可以将存活账户复制到一个更小的文件中,而不包括已死账户,从而节省磁盘内存。这被称为收缩。
-
清除
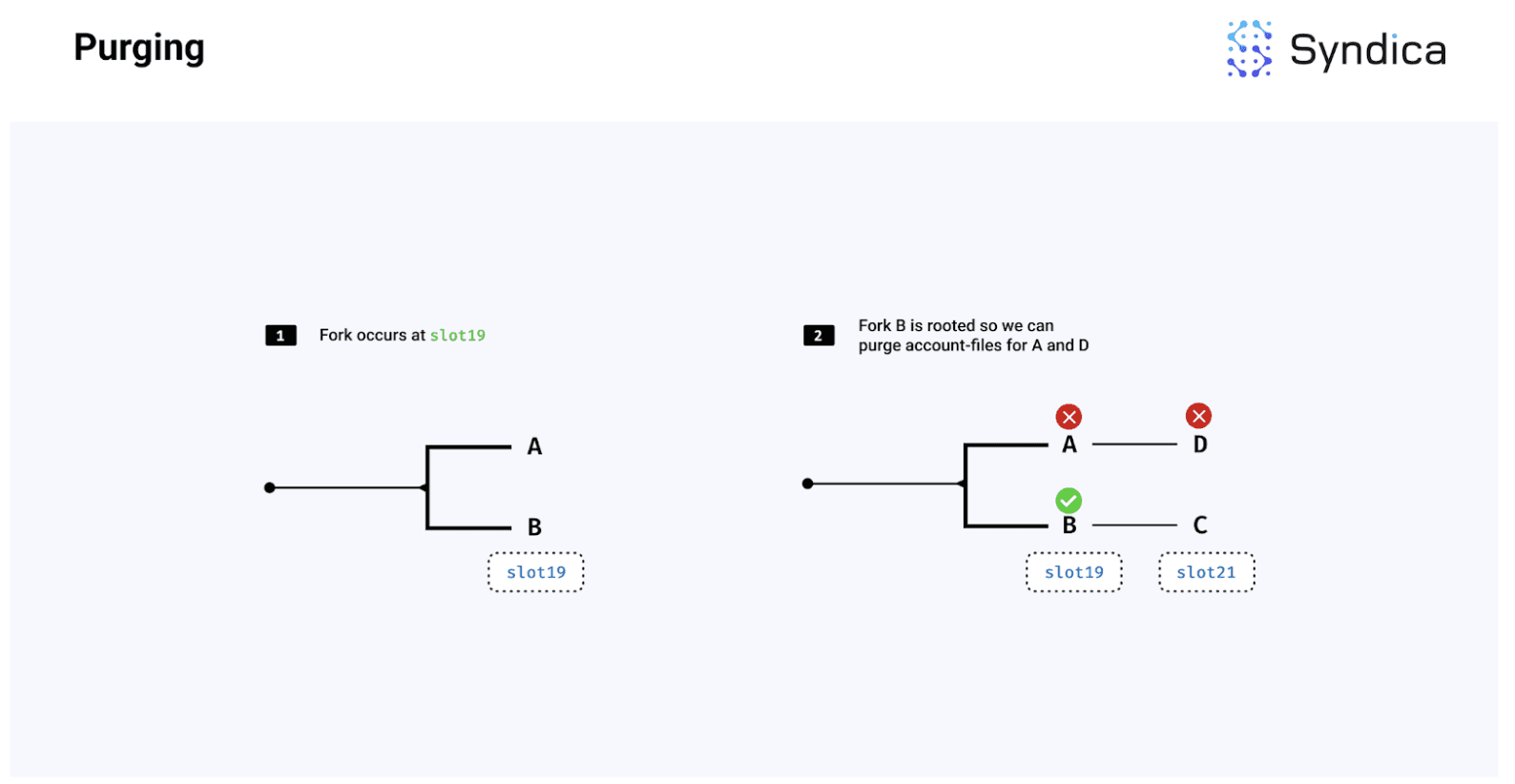
最后,我们也可以清除来自根区块链的分叉槽的整账户文件。例如,如果一个分叉的某条分支变得根植,那么我们可以删除与非根分支相关的所有账户文件。
实现细节
在概述了 AccountsDB 工作的高层组件后,接下来我们将深入实现细节。
从快照加载
我们将从描述验证者如何从快照加载的更详细的大纲开始。
解包快照
从网络中的对等方下载快照通常将包括:
1. 完整的快照,以及
2. 增量快照。
完整快照包括网络中在某个特定槽位下的所有账户。增量快照则是更小的快照,仅包含从完整快照中更改的账户。例如,如果网络处于槽位 100,完整快照可能包含在槽位 75 时的所有账户,而一个匹配的增量快照可能包含在槽位 75 和槽位 100 之间变化的所有账户。
完整快照生成往往代价不菲,因为它们包含网络中所有账户,而增量快照则相对便宜,因为它们只包含网络账户的一个子集。鉴于这一现实,验证者的典型做法是定期生成完整快照,同时更频繁地生成/更新增量快照。
完整快照遵循以下命名约定格式:
snapshot-{FULL-SLOT}-{HASH}.tar.zst
例如,snapshot-10-6ExseAZAVJsAZjhimxHTR7N8p6VGXiDNdsajYh1ipjAD.tar.zst 是槽位 10 的完整快照,哈希为 6ExseAZAVJsAZjhimxHTR7N8p6VGXiDNdsajYh1ipjAD。
增量快照遵循的命名约定格式:
incremental-snapshot-{FULL-SLOT}-{INCREMENTAL-SLOT}-{HASH}.tar.zst.
例如,incremental-snapshot-10-25-GXgKvm3NMAPgGdv2verVaNXmKTHQgfy2TAxLVEfAvdCS.tar.zst 是基于槽位 10 的完整快照的增量快照,包含直到槽位 25 的账户更改,哈希为 GXgKvm3NMAPgGdv2verVaNXmKTHQgfy2TAxLVEfAvdCS。
匹配的快照和增量快照将具有相同的 {FULL-SLOT} 值。当验证者启动时,由于验证者可以同时下载多个快照,它将找到最新的快照和匹配的增量快照以加载和启动。
下载快照
为了下载快照,验证者开始参与 gossip 加入网络并识别其他节点。过了一段时间后,我们寻找:
-
具有匹配的分片版本(即我们的网络版本/硬分叉与它们匹配)
-
具有有效的 RPC 套接字(即我们可以从中下载)
-
通过 gossip 分享了快照数据类型的节点
快照哈希结构是一种 gossip 数据类型,包含:
-
最大可用完整快照的槽位和哈希
-
可用增量快照的槽位和哈希列表
注意:快照哈希结构可以在这里查看。
验证者随后开始下载快照,优先选择来自更高槽位的快照。如果我们有一个 trusted 验证者的列表(通过 CLI 启动时提供),我们仅下载哈希与可信验证者哈希匹配的快照。
然后,对于这些节点中的每一个,根据快照哈希结构中的信息,我们构造快照的文件名:
-
完整:
snapshot-{slot}-{hash}.tar.zstd -
增量:
incremental-snapshot-{base_slot}-{slot}-{hash}.tar.zstd
使用节点的 IP 地址、RPC 端口和文件路径,我们开始下载快照。我们定期检查下载速度,并确保其足够快,否则我们会尝试从其他节点下载。
一旦验证者找到可用快照,它将首先解压并解档,展示如下所述的目录布局。
解包快照并构建相应银行和 AccountsDB 的主代码路径开始通过运行名为 bank_from_snapshot_archives 的函数。
注意:银行是表示单个区块/槽位的数据结构,存储包括父银行、其槽位、其哈希、区块高度等信息。
注意:快照的规范详见 Richard Patel 的 Solana 快照非正式指南。
加载账户文件
解包快照的第一步是解压缩并 加载账户文件,这发生在 verify_and_unarchive_snapshots 函数中。
在此函数中,多个线程被生成以解压缩并从存档中解包快照。在解包快照后,每个账户文件都会被消毒,以确保它们包含有效的账户、被 mmap 创建到内存中,并在数据库中进行跟踪。
注意:当验证者为某个槽位构建快照并打包这些账户文件时,由于实现的原因,验证者将继续向账户文件写入更近期槽位的账户数据。因为这些数据与快照的槽位不对应,因此应该忽略这些数据。这意味着在从文件读取账户时,我们需要从快照元数据文件(更具体地是 AccountsDB 元数据)中读取长度,以知道要读取的有用数据的最后索引。
注意:在旧的快照版本中,每个槽位可能存在多个账户文件,但在新版本中,每个槽位只会有一个文件。
注意:账户文件在 Rust 实现中也被称为
storages和stores。
加载快照元数据
在加载账户文件后,验证者从快照元数据文件中使用 Bincode 格式加载 AccountsDB 和银行元数据,这在 rebuild_bank_from_unarchived_snapshots 函数中完成。
注意:Bincode 是一个编码方案( https://github.com/bincode-org/bincode)
银行元数据包括诸如纪元计划、质押信息、区块高度等信息。AccountsDB 元数据包括关于每个账户文件中使用的数据长度、识别数据损坏的所有账户的累积哈希等信息。
注意:快照元数据文件的路径是
/snapshots/{slot}/{slot},在解档的快照中,其中{slot}是快照的槽位。注意:有关完整字段的列表,请参见 Sig 仓库中的
src/core/snapshot_fields.zig或 Rust 实现中的BankFieldsToDeserialize和AccountsDbFields。
生成账户索引
使用 AccountsDB 元数据,验证者使用 reconstruct_accountsdb_from_fields 函数 构建 AccountsDB 结构。然后,使用 AccountsDB :: initialize 将账户文件加载到数据库,并使用 AccountsDB :: generate_index 生成索引。
索引的架构将索引划分为多个桶。每个桶是一个小型索引,仅代表一小部分账户。每个 pubkey 都与特定的桶相关联,基于 pubkey 的前 N 位。每个桶同时包含 RAM(使用一个简单的 HashMap - 在代码库中称为 InMemAccountsIndex)和磁盘存储(在代码库中使用 mmap 文件称为 Bucket)
注意: RAM 映射使用 Vec<(Slot, File_id, Offset)> 作为其键,在 Rust 代码库中也被称为 slot list。
注意:基于前 N 位进行分桶的方式与他们的 crds-shards 方法是相似的(如本系列第 1 部分中讨论的 gossip 协议)。
注意:Rust 代码中使用的默认桶数是 8192。
完整架构在下图中描述:
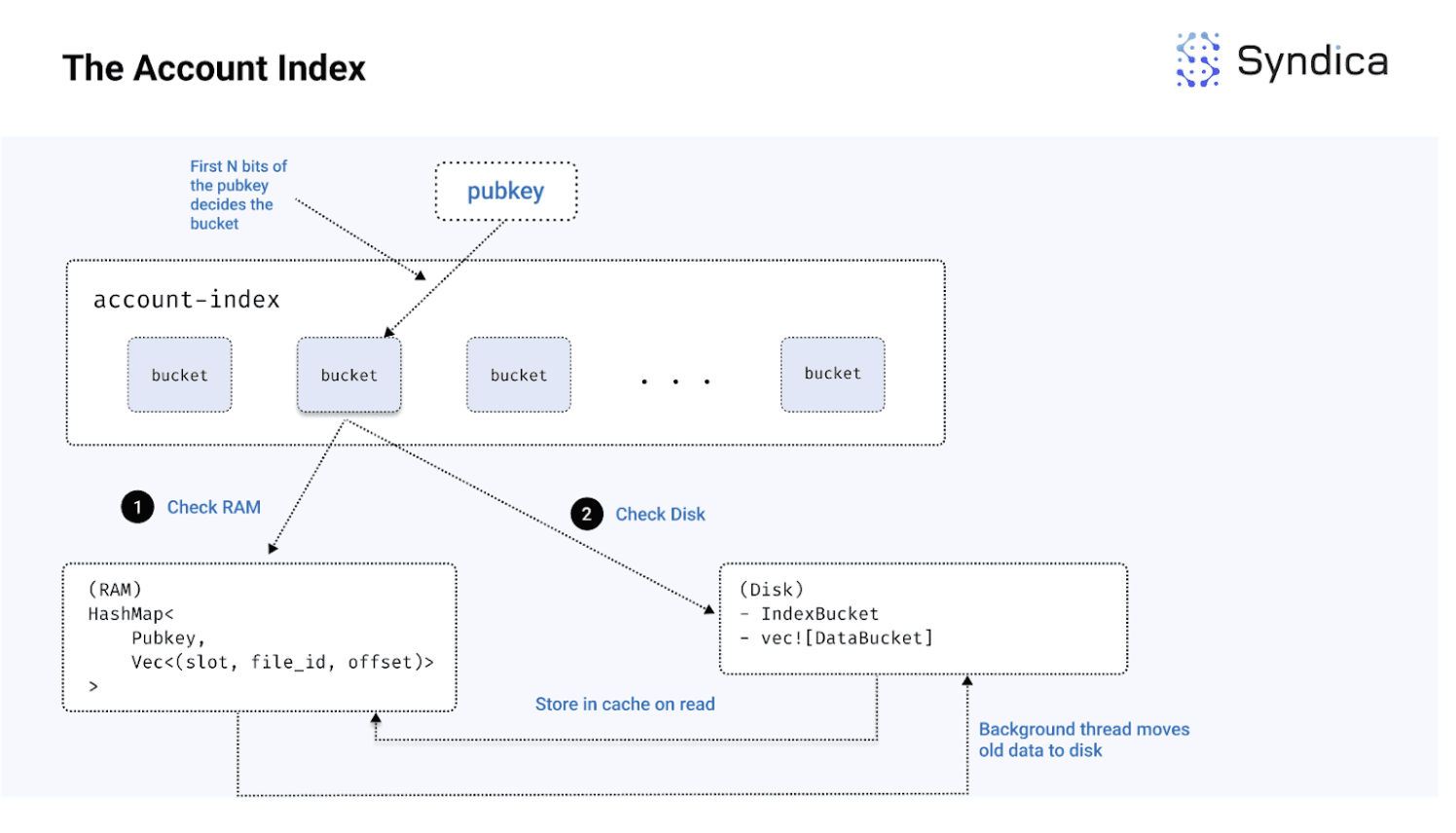
注意:通过运行验证者时,确保所有索引保存在 RAM 中,你可以使用
--disable-accounts-disk-index。
这些组件存储在 AccountsDB 结构中布局如下:

后台线程:刷新数据
由于基于 RAM 的索引存储着最近访问的索引数据,为了释放更多存储空间,使用后台线程(在代码库中称为 BgThreads)将旧的索引数据刷新到磁盘中。这一刷新逻辑使用 AccountsInMemIndex :: flush_internal 函数完成。基于 RAM 的索引项一旦“老化”便会被刷新到磁盘/桶内存中。老化参数根据我们希望将索引项刷新到磁盘的频率进行配置,且与其槽位是否被根植等因素相关联。
基于磁盘的索引
而同 RAM 索引是由 RAM 内存支持的哈希映射,磁盘索引则是由磁盘内存支持的哈希映射。尽管它们都是哈希映射实现,但磁盘索引是从头开始在 Rust 仓库中实现的,且其解释相对复杂。
磁盘索引的主要结构是 Bucket 结构,包含一个 BucketStorage 结构,存储基于文件的 mmap 文件。这个 mmap 文件将是哈希映射的背后内存。
为了支持 put、get 和 delete 方法,BucketStorage 需要实现一个名为 BucketOccupied 的特性,来识别哪个内存是空闲的,哪个是已占用的。
这意味着 BucketStorage 存储:
-
一个 mmap 文件(图中
mmap变量),和 -
一个实现 BucketOccupied 的结构体跟踪哪个索引是空闲/占用的(图中
contents变量)
在代码库中有两个实现了 BucketOccupied 特性的实例:
-
IndexBucket
-
DataBucket
每个 Bucket 实例包含一个 IndexBucket 和多个 DataBuckets,如下图所示:

当账户只有一个槽位版本时,索引存储于 IndexBucket 中。当多个槽位版本的账户存在时,索引数据存储于 DataBucket。
索引桶
IndexBucket 在 mmap 文件中存储一系列 IndexEntries 以表示索引数据,并使用 BitVec 来存储每个索引的枚举,以识别其是否为空闲。
每个索引的可能枚举值包括:
-
Free:索引未被使用
-
ZeroSlots:索引已被占用但尚未写入
-
SingleElement:仅存储设备的单一槽位,索引数据存储在直接
-
MultipleSlots:为公钥存储多个槽位(且索引信息存储于一个 DataBucket 中)
IndexBucket 的组织结构在下面的图中解释:
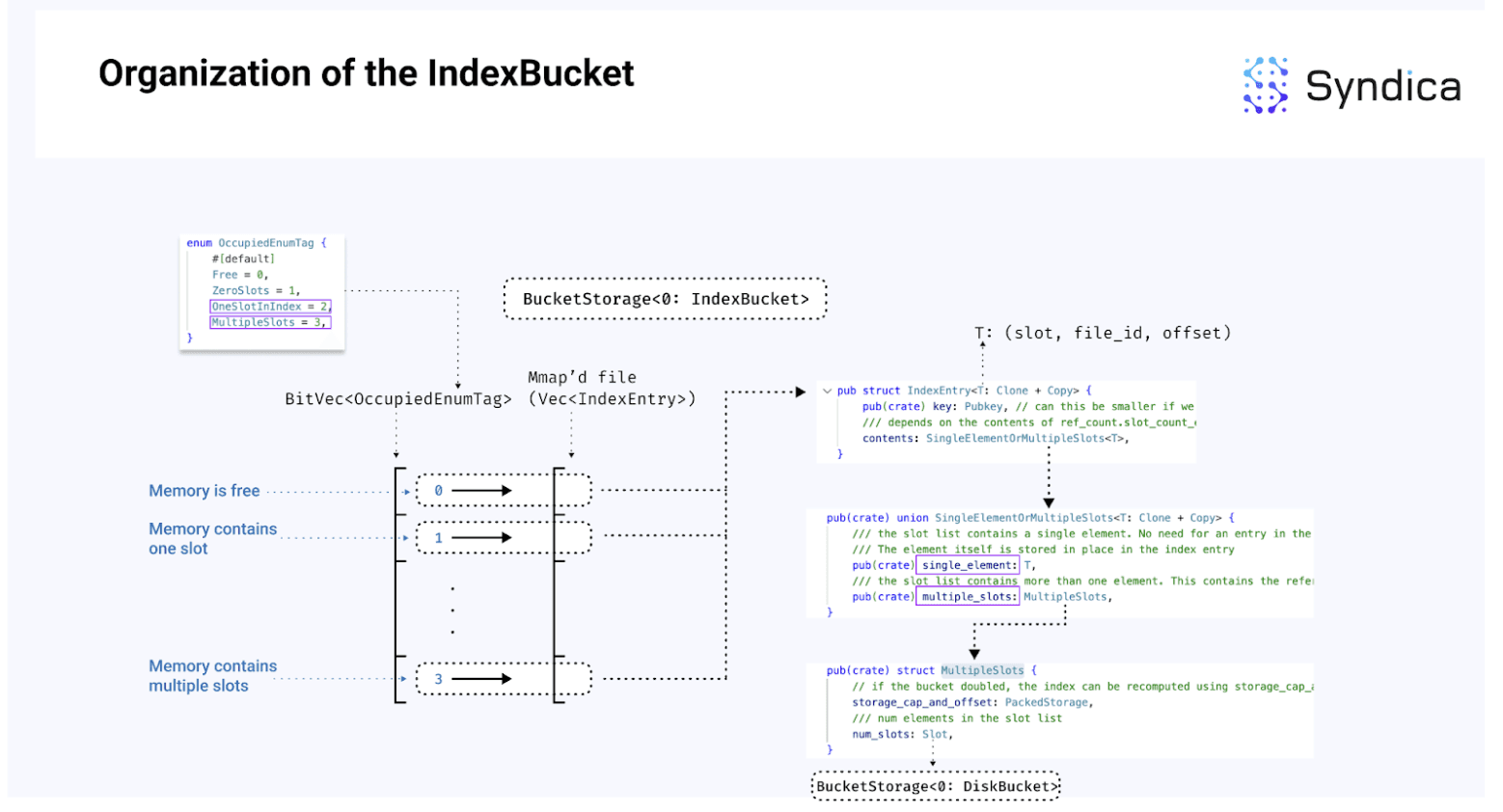
注意 mmap 文件包含一系列 IndexEntries,而 BitVec 确定如何读取内容:
-
在图中第二个条目时,BitVec 的值为 2,表示
OneSlotInIndex,因此直接读取 IndexEntry 中的single_element字段,以访问账户引用值。 -
在图中最后一条目时,BitVec 的值为 3,表示
MultipleSlots,因此读取 IndexEntry 中的multiple_slots字段,用于从下一步的 data buckets 中读取账户引用。
注意:由于有 4 种不同的枚举值能高效地表示它们,因此我们只需要 2 位,这意味着我们可以使用一个 u64 来表示 64 / 2 = 32 个不同的索引。这就是
BitVec结构所实现的。注意:完整实现类似于一个基于磁盘内存的平面哈希映射。公钥哈希化以获取开始查找的索引,然后线性探测以查找匹配键,然而,由于实现相对简单,尽管依然慢于 RAM 哈希映射。
数据桶
在读取 IndexBucket 时,如果 BitVec 的值为 MultipleSlots,这表示该公钥的索引数据存储于 DataBuckets 中。 MultipleSlots 结构存储:
-
1)存储在索引中的槽位数(在
num_slots字段中),用于计算应从哪个DataBucket中进行读取。 -
2)用于读取的
DataBucket偏移(在offset字段中),代码如下所示:

由于 BucketStorage 结构包含 N 个 DataBuckets,如何决定将给定索引存储在哪个 DataBucket 是根据公钥所包含的槽位数量的二次幂积分。例如:
-
包含 0-1 个槽位的索引数据存储在第一个
DataBucket -
包含 2-3 个槽位的索引数据存储在第二个
DataBucket -
包含 4-7 个槽位的索引数据存储在第三个
DataBucket -
…
查找公钥的索引并读取相应值的逻辑在 Bucket :: read_value 中编写,下面是读取相应值的代码示例:

生成索引
当验证者启动时,使用函数 generate_index_for_slot 在每个账户文件上生成索引(并行执行),以提取文件中的所有账户并将每个账户引用放入各自的索引小桶中。
这也是生成二级索引的地方。
二级索引
假设你想要从数据库中获取具有特定所有者的所有账户。要做到这一点,你需要遍历索引中的所有公钥,访问账户文件中的账户,并对账户的所有者字段做等值检查。这就是臭名昭著的 RPC 调用 getProgramAccounts 在代码中所做的。
在有很多账户的情况下,这种线性搜索既非常昂贵又非常缓慢。
由于这种搜索非常常见,二级索引存储具有特定所有者的公钥列表。这使你能够仅访问你知道具有特定所有者的公钥的完整账户数据,这样可以使该过程更高效。
功能、内置程序和系统调用
在所有账户被索引后,银行基于元数据创建,存储对完整 AccountsDB 的引用,并通过调用 Bank :: finish_init 函数完成,这会激活功能并加载内置程序和系统调用。
只有在快照槽位高于功能激活槽位时,功能才会被激活。这一逻辑在 Bank :: apply_feature_activations 中处理。
一些示例功能包括:
-
blake3_syscall_enabled -
disable_fees_sysvar -
等等。
完整功能列表可以在代码库中的 FEATURE_NAMES 变量下找到,或者在 GitHub Wiki 页面上查看。
内置程序也通过 Bank :: add_builtin 添加到银行,所有内置程序都可以在 BUILTINS 变量下找到,包括如下程序:
-
系统程序
-
投票程序
-
质押程序
最后,sysvars 通过函数 Bank :: fill_missing_sysvar_cache_entries 加载,其中加载时钟、纪元计划、租金等变量。
读取和写入账户
在所有账户被索引后,接下来要理解的另一个重要组成部分是账户的读取和写入方式。
读取账户
在处理一个新的区块时,验证者首先根据交易中定义的 pubkeys 加载相关账户。当搜索 pubkey 的账户时,它执行以下操作:
-
通过考虑前 N 位计算 pubkey 应该属于的相应小桶
-
然后在该小桶的 RAM 内存中搜索
-
如果不在 RAM 中,则尝试在磁盘上查找
- 如果在磁盘上找到索引数据,则将该数据存储到 RAM 中,以便下次快速查找

在 Rust 代码中,读取账户的代码路径从 AccountsDB :: do_load_with_populate_read_cache 开始,该函数调用 AccountsDB :: read_index_for_accessor_or_load_slow 来查找与 pubkey 相对应的索引数据。
该函数首先查找相应的索引小桶,然后调用 InMemAccountsIndex:: get_internal 在 RAM 和磁盘中搜索索引数据。
主流程的代码片段如下所示:

在为 pubkey 找到索引数据后,由于这些数据是不同槽位的账户引用向量,使用最大的槽位来识别账户的最新版本。
索引数据可以指向三种可能的位置:
-
在磁盘上的账户文件中(可以使用
file_id和偏移量进行查找) -
读取缓存
-
写入缓存
我们已经讨论了如何从账户文件读取,但我们尚未讨论的两个位置是读取缓存和写入缓存。读取缓存是另一层缓存,在从账户文件读取账户后,用完整的账户数据(与索引缓存不同)更新。写入缓存包含尚未被根植的槽位中的完整账户数据(这将在下一节中讨论)。
在代码中,账户通过 retry_to_get_account_accessor 和 LoadedAccountAccessor :: check_and_get_loaded_account 读取,对于三种可能的位置分别加载账户。
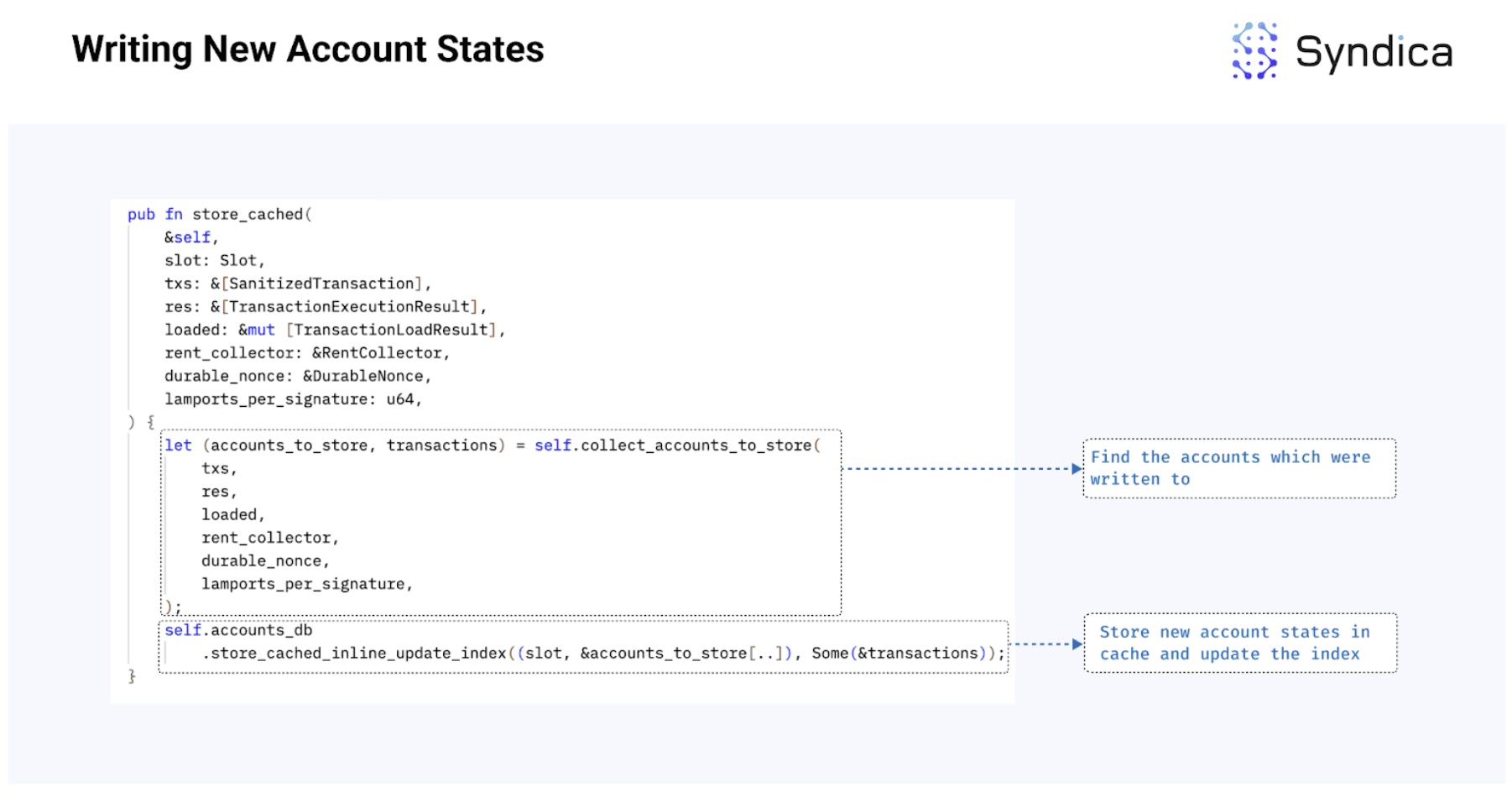
写入账户
在处理完一批交易后,我们现在有一组与特定槽位相对应的新账户,我们想要存储和索引。为此,我们首先将账户存储到称为 AccountsDB.accounts_cache 的 写入缓存 中,并更新索引以指向缓存位置。
定期将与根植槽位相对应的缓存中的账户数据,通过后台线程刷新到磁盘(在下一节中讨论)。
代码流程从 store_cached 开始,收集所有于块中被标记为 write 的账户,使用 collect_accounts_to_store 然后将其存储到缓存中并通过函数 store_cached_inline_update_index 索引。
AccountsDB 背景服务
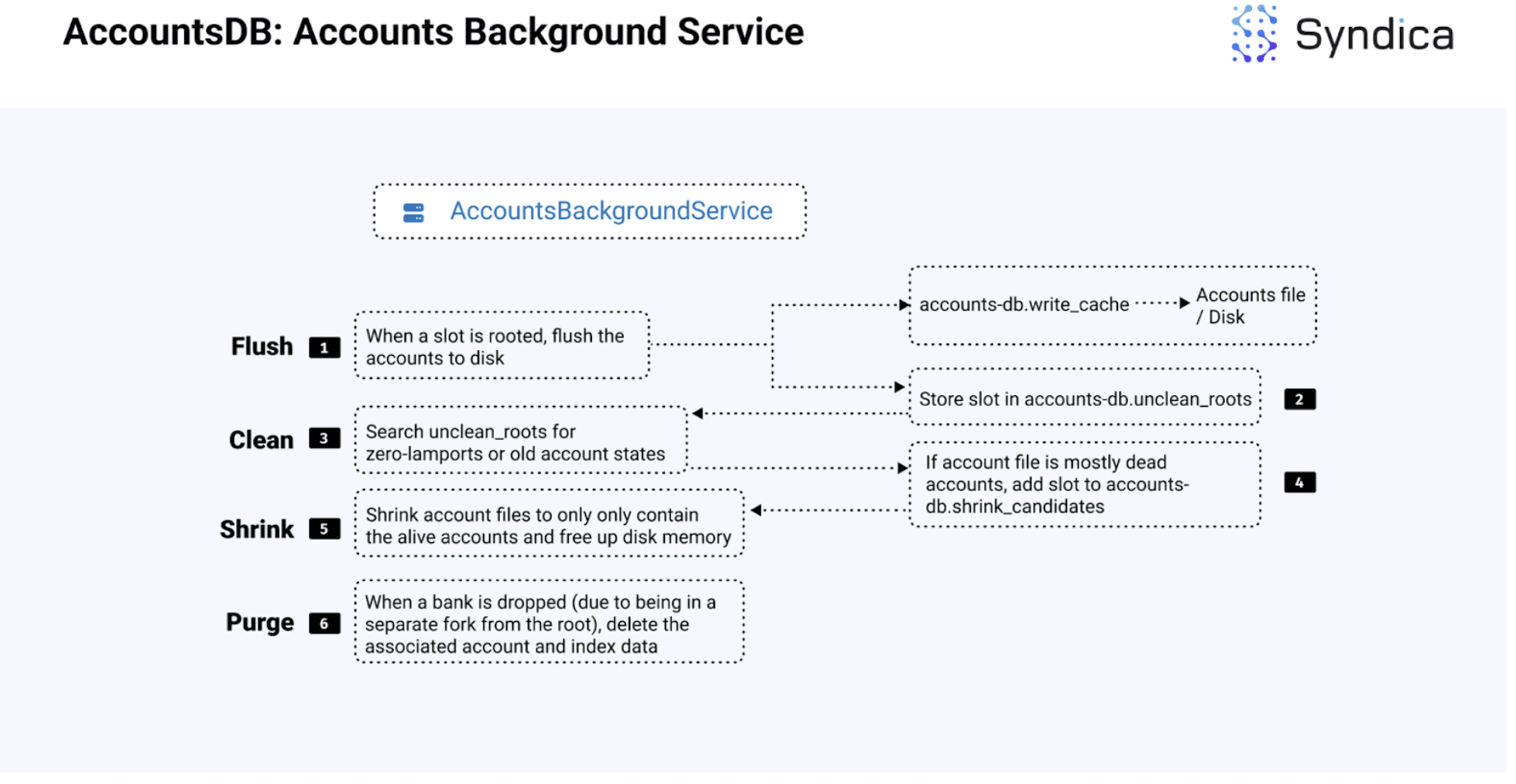
由于我们讨论了 AccountsDB 中的读取和写入是如何工作的,接下来我们将讨论 AccountsDB 如何确保有效使用内存。
这包括 4 项主要后台任务:
-
刷新:将数据从 RAM 写入磁盘
-
清理:查找旧账户或零 lamport 账户并释放内存
-
收缩:收缩具有大量已死账户的账户文件
-
清除:移除已分叉的账户文件
刷新、清理和收缩在 AccountsBackgroundService 结构中完成,该结构
-
获取当前根银行
-
定期刷新已根植的槽位
-
清理已刷新的账户
-
最后,运行收缩过程。
主要代码如下所示:

完整流程在下图中解释:
刷新
第一个后台任务是刷新,它从写入缓存读取并将与已根植槽位关联的账户推送到磁盘,生成一个新的账户文件。每个已根植的槽位将有一个相关的账户文件,包含该槽位中更改的账户。
收集已根植的槽位和将这些槽位刷新到磁盘的完整代码路径从 bank.flush_accounts_cache() 开始。
bank.flush_rooted_accounts_cache() 通过从 bank.maybe_unflushed_roots 读取未刷新根槽位来收集未刷新的根槽位,从反向迭代中刷新每一个槽位到磁盘,使用 flush_slot_cache_with_clean。
存储账户到磁盘的主要功能是 AccountsDB :: store_accounts_custom,其 store_to 参数设置为 Disk,它首先计算存储所有账户所需的总字节数,然后分配大小足够的新账户文件,最后将账户写入其中。
在账户写入磁盘后,索引更新指向新账户的位置信息,使用 AccountsDB :: update_index。
注意:请注意,上述函数
flush_slot_cache_with_clean以with_clean结尾。这暗示该函数在刷新时也执行清理的任务(将在下文中更全面的讨论)。注意:未刷新的根槽位以反向顺序进行迭代,因为我们只刷新 pubkey 的第一次出现。例如,如果
unflushed_roots = [12, 19]且在两个根槽位中存在同一 pubkey,则我们只会刷新槽位 19 中的 pubkey 账户。为此实现,代码在名为should_flush_f的闭包中使用了 pubkeys 的 HashSet,该闭包在槽位刷新时被填充。注意:这一清理仅考虑在缓存中的根,不是严格的完整清理。
在将根账户状态刷新到磁盘时,有时新的根状态可能导致已死的账户。在更新索引时,‘reclaims’ 数组填充被视为已死的旧账户数据。考虑账户文件被视为‘已死’并排队收缩的逻辑在 AccountsDB :: handle_reclaims 中。
根据清理的情况,可能会存在包含零或很少存活账户的账户文件。如果没有存活账户,则认为该账户文件已死,所有相关账户数据则会被删除。如果存在少量存活账户(‘少量’由存活账户的字节数量定义),则将该账户文件添加到 shrink_canidate 数组中进行收缩处理。
以下是对完整流程的伪代码解释:
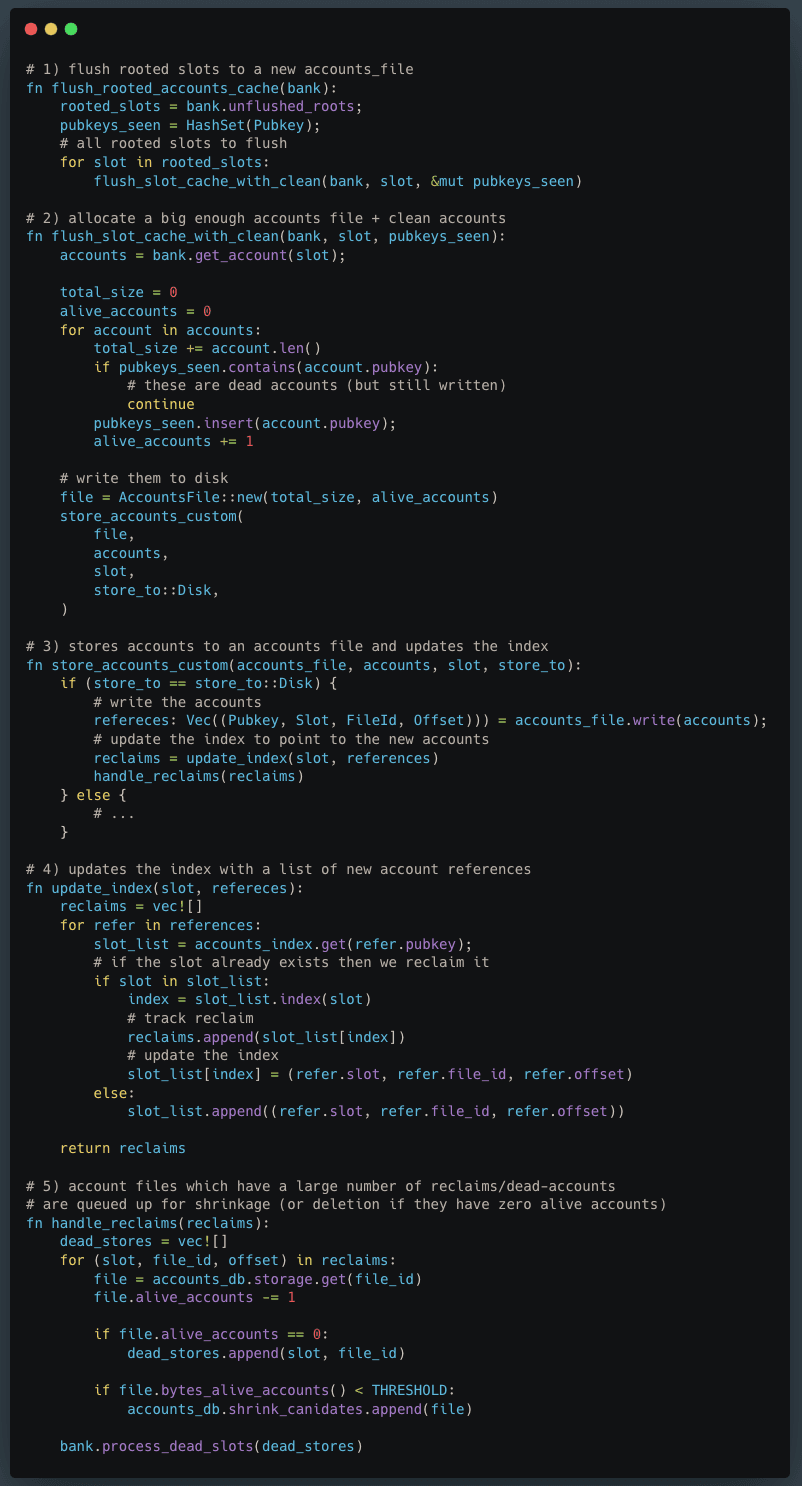
之后,将新槽添加到 uncleaned_roots,后者随后用于删除零 lamport 账户。
清理
清理查找零 lamport 账户或可移除的旧历史记录,删除这些账户索引,然后将足够小的账户文件队列到收缩中。
代码路径从 AccountsDB :: clean_accounts 开始,首先通过读取 uncleaned_pubkeys 变量收集所有需要清理的 pubkeys,该变量在 AccountsDB :: construct_candidate_clean_keys 函数中解析(pubkey, slot)元组。
关于 unclean_pubkeys 的更多信息:一旦新的区块被完全处理,银行会在使用 bank.freeze() 冻结,冻结过程中计算一个唯一识别该区块的 bank_hash。该哈希是其他哈希值的组合,包括在区块中修改所有账户的哈希,称为 account_delta_hash。在计算此值时,调用 calculate_accounts_delta_hash 函数,该函数还将所有账户的 pubkeys 添加到 uncleaned_pubkeys 变量中。由于清理流程仅在刷新后调用,这意味着该清理将处理最近刷新的所有账户。
对于所有这些 pubkeys,零 lamports 账户和旧账户分别处理。
为了处理旧账户,调用 clean_accounts_older_than_root,清除小于根槽位的槽位(除了最近的根槽位),从索引的槽位列表中移除其值。如果此过程后槽位列表为空,则从索引中移除其条目。
在此过程中,移除的索引值被标记为 reclaimed(与刷新过程相同),之后统计已在其各自账户文件中移除的账户为 dead ,这将导致他们的账户文件被视为已死或者是收缩候选者。
处理零 lamport 账户时,被包含账户的账户文件 alive_account_count 按 1 递减,以将账户定义为 已死,并删除该索引数据。
最后,与刷新流程的结束部分类似,对每个账户文件,如果文件仅包含少量 存活 账户,则将其添加到 shrink_canidates 变量,以便排队进行收缩。
收缩
收缩查找具有少量存活账户的账户文件并移除所有已死账户,通过重新分配文件来减少所使用的磁盘内存量。
收缩的代码路径从 shrink_candidate_slots 函数开始,读取存储在 shrink_candidate_slots 变量的所有槽位。对于每个槽位,调用 do_shrink_slot_store 函数,发现该槽位的账户文件中的 “存活” 账户。
要判断某个账户是否为存活,需在索引中查找 (pubkey, slot)。如果元组在索引中不存在,则该账户被视为 dead ,存储于 unrefed_pubkeys 变量中。否则,如果该账户存活(且元组在索引中被找到),则其被添加到 alive_accounts 变量中。
收集所有存活账户后,将其写入磁盘至一个新的账户文件,该账户文件被正确地调整到恰当的大小,之后删除旧的账户文件。
清除
最后,当新的槽位被根植时,属于分叉的银行从写入缓存中清除,索引数据通过实现 Drop 特性在银行结构中被删除。
- 原文链接: anza.xyz/blog/a-deep-div...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





