UniFi:重新思考以太坊的汇总方法
- 2077 Research
- 发布于 2024-07-13 16:21
- 阅读 1590
本文详细探讨了以太坊的滚动解决方案及其在生态系统中的重要性,强调了滚动的核心价值主张以及对L1和L2在可扩展性和价值累积方面的影响。作者分析了智能合约滚动的设计、数据压缩方法、证明机制和经济模式,提出了基于Puffer的改进方案,旨在更好地实现以太坊的可扩展性和去中心化,展示了未来解决方案的潜力。
自从 Ethereum 采用了垂直扩展的方法,已经过去了四年,该方法利用被称为 layer twos(以及 threes,甚至 fours)的互联堆栈,每个堆栈在其属性上具有一定的灵活性,以提供无穷计算的最佳环境。
在加密年份中,这已经是几十年,而一个可组合生态系统的承诺尚未实现。这最近导致某些倡导者对其提出了很多不愉快的批评,他们认为放弃 L1 执行优化是为了追求截至目前尚未符合预期的 L2 梦想付出的代价太大。
然而,Ethereum 在 L2 的道路上依然坚定不移,这并不令人意外,因为在其实现过程中消耗了大量资源;而且没有其他实际的解决方案能够在不妨碍网络所珍视的去中心化指标的情况下实现可扩展性。
在本文中,我们将对 rollups(每个人最喜欢的 L2 方案)在 Ethereum 上进行较为全面的概述;在垂直扩展体制下向 L1 的预期价值获取;以及迄今为止可扩展性和价值获取的现实情况。
这是为了理解 Puffer 对 rollups - 基于增强重抵押的 rollups 的方法所隐藏的价值主张。
理论化的 rollup 为中心的路线图
任何通用区块链的主要目的都是能够以确定性方式处理有效交易,从而导致其状态发生变化。该状态存储在其节点上,并提供了有关从创世区块开始该链持有的所有计算数据(主要由账户和交易组成)的见解。
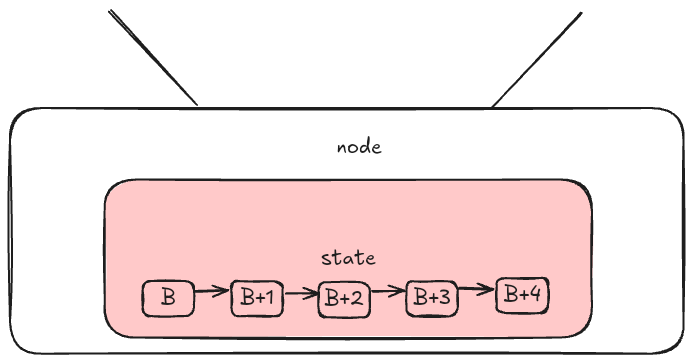
区块链状态的极简表示,由区块构成并存储在节点内
随着经济活动的改善及链条达到逃逸速度,其状态按比例增长,开始影响节点跟上的计算速度。这直接导致区块验证成本增加,用户通过更高的交易费用来承担这些成本;而更高的交易费用则对经济活动形成了抑制。
在这个阶段,链条可以选择增加单个节点的计算能力并“横向扩展”。这意味着生成和验证新块(并处理新状态)的能力被高昂的进入成本所限制。高额的进入成本导致网络中心化,并可能建立寡头垄断。这在 Ethereum 中是我们不希望看到的,因为去中心化是网络的核心承诺。
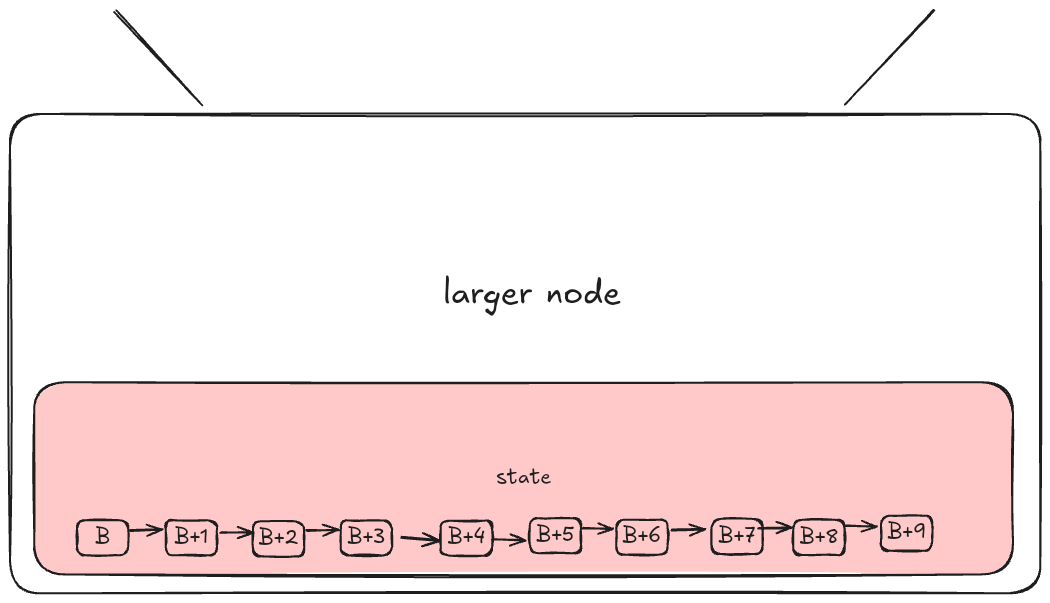
横向扩展——增加单个节点的计算能力,以便它们可以存储更多的状态
另一种选择是将计算工作转移到不同的堆栈,这种堆栈更好地优化了计算和处理接收到的输入的任务。通过某种机制使该堆栈与原始链兼容,前者可以在保持高度灵活的同时从后者的安全保障中受益。
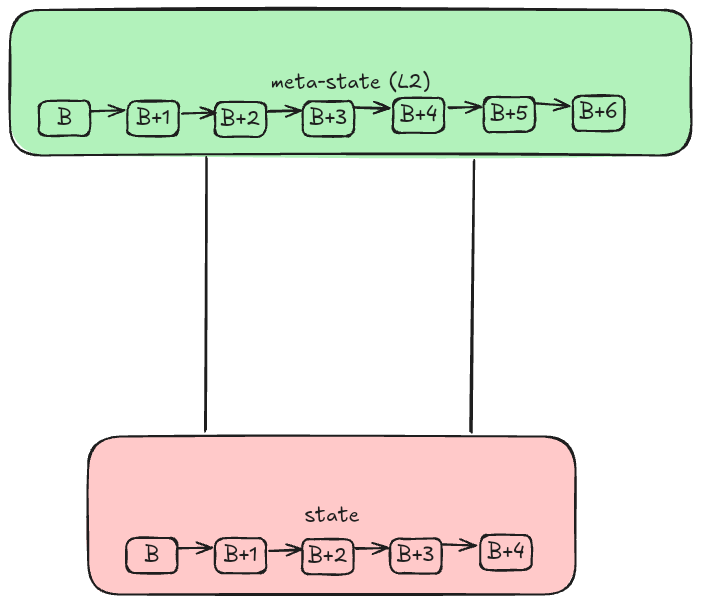
垂直扩展——引入新的兼容执行环境以增加计算能力
这正是 Ethereum 通过其分层架构采用的方法;它允许在网络之上部署不同的执行环境,提供更大的计算能力,这种计算能力的下限受到 Ethereum 自身计算能力的限制。
这种实现有多种变体,但最受欢迎的是 rollups,它采用了混合的方法来处理数据计算和存储。Rollups 将大部分计算工作和相关状态转移到链外,远离 L1;因此只在 L1 上最小存储数据,以确保其可用于验证。
正如 Prestwich 简洁定义的那样:Rollup 是一个自愿选择的、另一个共识的子集,通过自定义状态转换函数来保持其状态的超集合。
在接下来的小节中,我们将扩展这个定义,评估 rollup 实施的决定性属性。
智能合约 rollups
这里使用智能合约 rollups 作为 umbrella term,指的是为 rollup L2 概念而设计的初步设计,这些设计主要集中于执行。
这些 rollups 提供了一个与其母链分离的非常优化的通用执行环境,而且只偶尔通过桥接将其活动发布到母链上的一个预部署合约中,以实现最终性/共识和可用性。
智能合约 rollups 的各种变体是由于其设计者在以下几个方面的权衡能力:
- Rollup 的数据压缩/证明生成方法
- Rollup 的证明提交/验证系统
- Rollup 的排序模型
- Rollup 的执行模型
- Rollup 的最终性保证
这些特性并不难定义,问题在于它们重叠得很严重,因此很容易混淆,但别担心——我们要继续前进。
数据压缩
正如我们之前讨论的,rollups 预计会偶尔将其状态发布到母链,以便与之保持某种可组合性。
这可以通过将其整个状态转移到母链的区块中,获得后者的验证共识/最终性来完成,但这对于两个网络来说都是非常不划算的。由于它们的状态可能会占用更多的母链区块空间,rollup 必须为此支付更多费用;而母链的节点将会遭受更大的压力,必须跟上其上的执行,同时同步 rollup 的状态。
因此,它们必须使用这些被称为 Merkle Trees(或任何其他数据结构,我们使用 Merkle 仅为简便)来压缩其状态,并将结果“状态根”发布到母链上的智能合约(L1 合约),作为其在特定时间段内状态的摘要。
在某个预定时期,rollup 上执行的一批交易被压缩到相关结构中,并通过一个经过批准的代理以单笔交易的形式发布到母链。该交易还包括 rollup 最后提交的状态根(如果你愿意,也可以称为之前的状态根),L1 合约检查以确保其与上一个提交的交易中提交的状态根相对应。
证明、证明过程和证明验证
在这个背景下,证明就是某种活动发生的加密证明,允许任何人从这种简化结构中推导出原始活动。
更严格地说,证明是 rollup 提交到母链的内容,以允许后者计算(和验证)其整个状态或特定的状态转换(如果需要的话)。
虽然 rollups 总是意识到其母链的状态——它们通过双向桥接与之保持同步——但母链仅通过 rollup 使用我们讨论过的证明报告其状态。
这使得 rollup 处于一个可以在其母链上发布和最终化不正确或欺诈状态转换的情况。
为了防止这种情况,期望 rollups 应该具有某种机制,以在后者最终化任何人发布的状态之前,向其母链报告不一致性。
有两种证明发布机制:
故障证明
这些被作为 rollup 上发生异常的证据发布。这可能是因为某个参与者违反了其特权,或执行错误;无论如何,故障证明被发布是为了证明欺诈,即“这不应该发生,但确实发生了,这里是证明它确实发生了,请撤销它”。
这种实现是乐观的,所以产生了乐观 rollups,因为其基本假设是,提交的状态根中的操作在被质疑之前都是有效的。
有效证明
这些证明被发布以允许 L1,或甚至任何人,验证在 rollup 上发生的特定操作。在这种情况下,操作的逻辑无关紧要,唯一重要的是它是否发生。
这种实现产生了零知识 rollups,它强制要求在 sequencer 发送给 L1 合约的交易中包含证明,表明由于其内容导致的状态转换是有效的。
排序和排序模型
我们谈到了状态根(和证明)的生成及其发布,现在让我们讨论一下谁来进行发布。排序是一个比较敏感的话题,所以我们将在这里小心谨慎。
Sequencer 负责将 rollup 上的交易进行排序和批处理,形成更简单的数据结构,并将该数据结构与证明一起发布(在某些情况下)。
因此,sequencer 生成了一个在 rollup 上执行的交易集的确定性排序,(可能)对其进行压缩,然后将其发送给 L1 合约进行最终化。
在某些实现中,sequencer 是一个完整的节点,负责排序有效载荷并确保该有效载荷将以该顺序执行;而其他的可能会选择将状态根的生成和发布转移给其他代理。
在乐观 rollups 中,挑战已发布状态根的能力也是一个受限角色,这是出于欺诈证明游戏的机制。
执行模型
通用 rollups 具有将其计算能力扩展超出其母链的能力;它们可以选择让其执行环境与后者向后兼容,或完全放弃以采用新的智能合约虚拟机。
这是大部分魔法发生的地方,因为 rollup 团队会尽力实现更好的虚拟机。目前我们有 OVM、WASM、各种 zkVM 的变种;所有这些都具有不同级别的 EVM 等价性或一致性,以使智能合约更好地运行。
最终性和共识
根据其设置和母链的设置,rollups 能够为其用户提供某种软最终性(也称为预确认),在它们能够在母链上获得共识之前。这种保证的程度显然取决于系统的设置以及错误预确认的成本。
无论如何,母链的共识始终是优越的,并且是 rollup 交易获得真正最终性的唯一方式。
这些是技术细节,但仍然有“为什么”以及讨厌的经济学的问题;为何潜在的替代 L1 区块链会选择以费用从 Ethereum 获得最终性;Ethereum 为什么会考虑支持潜在的吸血网络。
完整的细节由 Barnabé 在 这里 提供,但关键在于:
- L2 的社会主权和数据可用性
- L1 的可扩展性和数据可用性费用
L2 从 Ethereum 既有的社会层中获得了一些社会主权。这是隐含的,因为我们看到许多知名的 Ethereum 贡献者和研究人员对 rollups 的支持;还有那脆弱但值得注意的“以太坊联盟”指标。
同时,它还保证其数据/状态始终可在不可篡改的层上可用,因此其节点可以放弃状态存储,完全致力于提高网络的计算能力。
另一方面,Ethereum 得以以无干预的方式扩展,通过让新团队利用其安全框架和几乎不可逾越的总攻击成本(TCA)。
L1 还预计将因 L2 对其存储的使用而获得某种经济利益(这使事情变得有点复杂)。这里的收入来源于通过 EIP-4844 的 blobs 向 rollups 提供数据可用性服务。
Rollups 的实际操作
在 l2beat 网站上可以看到,经过这么长时间,并且有超过五十个通用 rollups 在线,我们仍未见到任何一个能够完全兑现其承诺,更别提其倡导者的原始期望了。
这并不是说到目前为止这一切都是无用的;各个团队在整个技术栈上都取得了巨大的进步,但在 Ethereum 可扩展性的方法的技术和经济模型中,仍然存在各种持续的问题。
以下我们将在技术和经济框架下评估最重要的问题。
技术缺陷
- 堆栈之间的碎片化:由于其本地区块桥接的信任模型和各自的实现方法,团队最终构建复杂的堆栈,几乎无法与 Ethereum 以及其他 rollups 可组合。虽然基于意图的桥接作为一种可行的解决方案已崛起,但几乎没有任何疑问,rollup 本地桥接在经济安全性上会更高。
在追求特性独立的过程中,兼容性被舍弃,这导致了一种观点,即 L2 完全不同于其母链。如果你想要兼容性,必须首先确保兼容性。
- 中心化排序和验证:顺序交易的能力赋予了 sequencer 一个不受挑战的“最后查看”特权,使得它们可以随意审查交易并提取各种 MEV。这导致几乎每个高性能的 rollup 都采用由其团队维护的单个 sequencer。通过验证者授予软最终性的能力也是一种受限角色。
这些设计选择使用户的体验更好,但直接违背了 Ethereum 去中心化的理念。撇开理念,中心化排序也是一个非平凡的单点故障,任何时候的停机都将对 rollup 造成灾难性后果。
经济缺陷
- 一直以来都已经建立了一个事实,即数据在相对于计算/执行方面并不是一种特别有价值的商品。Rollups 进一步利用链外交易执行以实施压缩方案,并减少其发布负载的尺寸,从而进一步降低其使用母链数据可用性的费用。
Ethereum 通过 EIP-4844 进一步压低边际,以建立多维费用市场,以便它的 DA 服务允许 rollups 以更低的成本获取最终性。
所有这一切意味着 rollups 没有支付“足够的费用”;如果 Ethereum 不将其数据可用性职责优先于其对自己的用户和应用的执行职责,这也没关系,即便是短期。不管怎么说,我们接下来要说的正是这一点。
- 将大部分执行推向 rollups 意味着将会在这些 rollups 上构建更多的应用,这将导致现有(和即将到来的)用户和价值会重新分配(并累计)到少数几個几乎不兼容的 rollups,导致 Ethereum 上的经济活动逐渐消退。
此外,Ethereum 直接从其 rollups 的经济活动中并不受益,除非以一种善意的方式。
最终,rollup 领域在很长一段时间内表现不佳(#L222 是一个例子),“异议”声音现在强烈统一地要求重视 L1 执行,并将 rollups 留给自己的命运。然而,我们相信仍然有希望;垂直扩展仍然是提供更多吞吐量而不显著妨碍去中心化和安全性的良好方法,但它必须采取一种 较少讨论的方法,该方法刚刚开始在新术语下显现。
Based Rollups; 原语崛起?
一位智者曾写道 “非常关键的是,Ethereum 的 rollup 收费不是脱离其本地 L1 执行,而是依附于它”。那么,让 L1 从 L2 的执行和经济活动中受益怎么样呢?如果做得好,这也可能行得通,并且在短期到中期内并不一定会妨碍更好基础的后续执行环境的发展。
这就是获得认可的、助推的 Based Rollups 的整个意义。
智能合约 rollups 通常在 L1 的共识设备之外实现;L1 对其状态没有写入访问权限,仅依赖于读取并存储其报告的状态。 Based Rollups 反转了这种动态,使 L1 上的代理能够通过与 rollup 的共享环境实施状态转移函数,而不是仅次于其状态的报告以实现最终化。
直观上,这意味着 L1 上的代理可以直接从 rollup 的经济活动中受益,从而将 L1 的收入和职责扩大到数据可用性之外。它成为一个 sequencer,偶尔为 rollup 执行事务!
除了简化经济模型外,L1 排序还为Based Rollups 提供了某些技术优势,相较于智能合约 rollups:
- 它们具有更好的存活保证,因为它们的存活与 L1 的存活完全一致。这也转化为更好的安全保证,因为它们直接受到 L1 的 TCA 保护,而不必通过使用证明来争议/防止错误。
- 它们与 L1 一样去中心化,这使得它们在远远领先于大多数基于信任模型运行的智能合约 rollups 的使用上遥遥领先。
虽然这种实现对 L1 大有裨益,但却在潜在 rollups 的边际成本中放大了机会成本;因而后者在相对有限的设计选择中不得不放弃其收入的一大部分,因为它们必须与 L1 的共识设备直接兼容。
然而,这些缺点可以由任何时候负责发布 rollup 块的验证器轻松克服,只要他们愿意。
采用选择在提议的 rollup 块中提供一部分可提取价值的验证器集允许后者重新捕获一些 MEV;而可以为 rollup 的有效载荷提供经济保障的乐观预确认的验证器集实质上消除了共识设备的约束。
这正是 Puffer 的 UniFi 的意义所在:建立验证器集,使 L1 排序的 rollups 能够无需信任地规避其限制,利用 Eigenlayer 的服务。
Puffer 的Based Rollups;结合原语
Puffer 是一个以 Eigenlayer 为基础的原生流动重抵押协议,旨在使用户能够在 ETH 中聚集资本,并为多种主动作验证服务(AVS)启动模块。
Eigenlayer 的 AVS 在不同的上下文中为各种生态系统和协议提供多种服务;其底层价值在于,任何协议都可以通过激励选择参与 AVS 的验证人,以提高其质押的收益,承受 Ethereum 基于 PoS 支持的经济安全设置。
Puffer 通过降低参与 Ethereum 网络作为验证者节点的进入成本来加强这一点。它通过允许多个用户在 Puffer 模块中聚集其 ETH 来降低每个验证者最低 32 ETH 的要求。
Puffer 模块被设置为,当聚集的 ETH 满足最低要求时,将其用于通过 NoOp 函数设置一个验证者;因此,指定的节点操作员将一些 ETH 锁定在 验证者票证合约,并铸造相应价值的验证者票证,然后将这些票证与一定数量的 ETH 一起存入 Puffer 合约,以开始提供验证服务并获得收益。
在验证者设置完成后,协议雇佣一名重抵押操作员来监督模块选择的 AVS 的管理。
因此,Puffer 通过其模块提供两个功能:
- 流动质押:类似于 Lido、Rocket Pool 和其他流动质押服务,这些服务允许用户 ETH 聚集以进行 Ethereum 本地验证。
- 流动重抵押:允许用户将其提款凭证设置为 EigenPod,使其验证服务能够扩展到更复杂的 AVS 之中。
此设置允许 Puffer 建立多种验证器集,其资本被用于保护特定 AVS,前提是后者获得 Puffer 治理的批准。这些验证器集的存在使得 Puffer 在推动Based Rollups 克服当前挑战方面处于独特位置。
重抵押与Based Rollups 之间的协同作用
正如前面提到的,各种类型的协议可以选择在 Eigenlayer 上作为 AVS,以便受益于 Ethereum 通过其 TCA 提供的经济保障。
这一服务的一个显然应用是使 rollups 更加简化地受益于 Ethereum 的经济安全,不那么麻烦。我们甚至可以更进一步,定义 AVS 期望验证者满足的保证,以实施对齐的机制;如果 L1 被期望在 rollup 上拥有更大的自由度,情况会更好。
Puffer 通过 UniFi 的Based Rollups
UniFi 是一个 Eigenlayer AVS,允许用户通过 Puffer 降低参与 Ethereum 网络作为验证节点的费用;同时允许用户通过让参与的验证者向用户发出凭证承诺,让他们受益于更好的排序、执行和最终性保证,通过 Commit-Boost 提供这一服务。
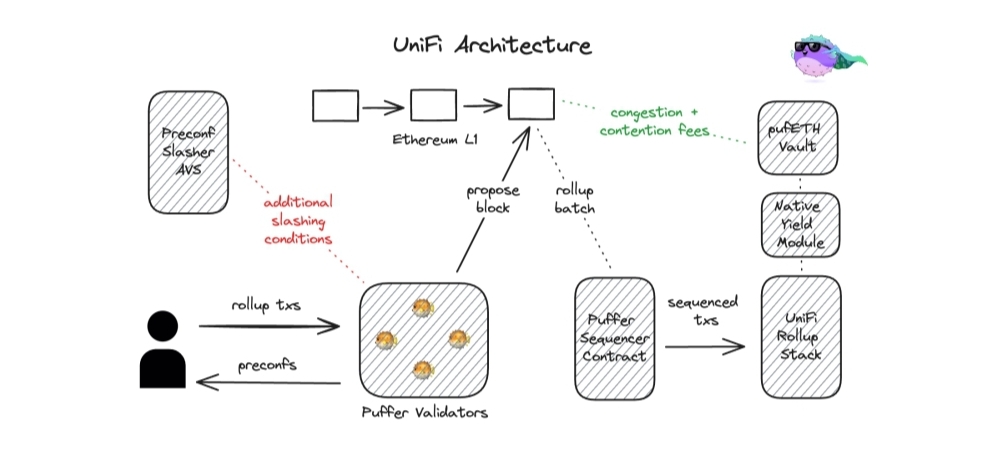
这些凭证承诺类似于对用户交易的特定结果的最终性保证,并在经济安全性上严格超过没有欺诈证明系统的乐观 rollup 约定,因为偏离该承诺会导致相关的验证者通过 Eigenlayer 被削减。
UniFi 与 Commit-Boost 的集成——这是 MEV-Boost 系统的标准化组件提案——使得选择参与系统的提议者(和其他交易执行者)能够向用户做出承诺,为他们提供某些功能集,通过限制执行者的能力。
其预期用途包括:
- 承诺交换(和一般交易)结果,以确保用户的交易免受有毒 MEV 的影响。
- 承诺每个可执行有效载荷提取的一部分 MEV,以便 rollup 不会在每次 L1 操作员负责排序时完全放弃其 MEV 收入。
这些原语的结合使 UniFi 在相对普通的Based Rollups 中获得了显著的竞争优势。它可以利用 Ethereum 的去中心化,而不会过度牺牲收入,同时能够提供预确认。因此,解决了与Based Rollups 相关的两个最大问题:
- 它们受到 L1 共识设备的限制;Puffer 通过与 Commit-Boost 的集成解决了这一问题,允许 L1 操作员对用户交易的所需结果提供可信承诺。
- 每次 L1 排序块都会将交易执行收入转由 L1 操作员所有;Puffer 通过其 Eigenlayer 集成解决了这个问题,要求 L1 操作员获取的部分价值要返回给 rollup,否则操作员面临被削减的风险。
结论
将所有内容联系在一起;将 rollups 作为“迎接下一个十亿”加密用户的途径面临许多成长的痛苦,特别是考虑到其对 Ethereum 的经济不一致性,这被认为是基础资产价格停滞的原因。虽然我们不认同这种推理,但在实现无信任互操作性方面,仍然需要进行很多变化,但必须推动社区范围的标准化。
Puffer 的架构提供了一种轻松摆脱价值积累困境的方法,而不使其自身与现有生态系统隔绝。它在标准化组件和显著原语上以新颖的方式进行构建和集成,使其成为一个“可证明对齐”的 rollup,其对 Ethereum 的价值显而易见。
- 原文链接: research.2077.xyz/unifi-...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





