Block-STM 与 Sealevel:并行执行引擎比较
- 2077 Research
- 发布于 2024-06-08 17:31
- 阅读 2195
本文探讨了Aptos的Block-STM与Solana的Sealevel在区块链执行并行化方面的不同方法,分别采用乐观并发控制和悲观并发控制。这两种方法在设计、性能和用户体验上各有利弊。Block-STM允许任意交易逻辑,但在高争用环境中表现不佳;而Sealevel则通过提前声明状态访问提高性能。文章最后对这两种TPU在实际世界中的表现进行了比较,认为Sealevel在现实情况下将更具优势。
Aptos 的 Block-STM 和 Solana 的 Sealevel 是对区块链执行并行化的对立方法。Block-STM 使用乐观并发控制(Optimistic Concurrency Control, OCC)方法,即事务处理单元(Transaction Processing Unit, TPU)(乐观地)假设不会有并发执行的事务发生冲突,并依赖内置检查和逻辑来识别和解决冲突。另一方面,Sealevel(悲观地)假设事务会发生冲突,并依赖基于锁的同步来防止冲突。
历史上,悲观并发控制(Pessimistic Concurrency Control, PCC)方法在分布式数据库系统中表现出更高的性能,这也是直观的原因——一种以防止冲突的方式调度事务的 TPU 应该比必须在事后解决冲突的 TPU 表现得更好。然而,得益于巧妙的设计和工程优化,Block-STM 的表现出人意料地好,其额外的好处是在允许任意逻辑的同时,扩展了更广泛的使用案例和更优秀的开发体验。
本文将考察并分析这两种 TPU 如何在相对较低的层面上接触并行化,并评估它们的性能和可扩展性。本文还将无偏地评估这两种 TPU 的优缺点。
本文假设读者对区块链概念如事务、区块和共识比较熟悉。对分布式数据库和计算机架构的熟悉将有助于理解某些概念,但词汇表解释了不熟悉的术语,主体和附录包含了不熟悉主题的“入门”。
常见术语
一些术语将频繁出现,因此我们快速分析它们在本文中的含义:
- 并发(concurrency)和 并行(parallelism): 并发指多个进程使用相同的资源。并行则是多个进程互相独立地运行。程序可以具有任意组合的特性,包括没有并发或并行特性,或两者皆有。
- 事务(transactions): 事务是执行逻辑操作的一组原子指令。此处提到的指令类似于低级计算机指令,但它们的功能超过了计算机指令。
- 冲突(conflict): 当两个或多个事务修改/访问同一部分状态时,称它们发生冲突。具体来说,当至少一个事务尝试写入争用的状态部分时,发生冲突;如果所有事务都是读取的,则它们不冲突。
- 状态(state): 状态描述某一时刻事物的条件。在区块链的背景下,状态是账户及其相关数据(余额和代码)集合。当提到内存访问/修改时,内存指的是状态。
- 依赖性(dependencies): 如果且仅当事务 B 与事务 A 冲突,并且事务 B 的优先级低于事务 A,则事务 B 被称为事务 A 的依赖性。(如果 B 的优先级高于 A,则 A 将是 B 的依赖性。)
- 锁(lock): 锁或
mutex是一种防止对内存位置并发访问的机制。当一个事务/进程希望在基于锁的系统中访问内存位置时,它尝试抓取与该位置相关联的锁;如果该位置已经被锁定,则锁的获取失败,事务必须等待。 - 锁粒度(locking granularity): 指的是内存锁的精细程度。想象一下,一个事务需要更改某个表中的元素;粗粒锁可能锁定整个表;更加精细的锁可以锁定感兴趣的行/列;而非常精细的锁可以仅锁定感兴趣的单元格。锁越精细,可以拥有的并发内存访问就越多,但高度精细的锁管理起来更难,因为它们需要更大的键值数据库来管理内存的部分。
- 可序列化性(serializability): 一组并发执行的事务被称为可序列化(serializable),如果存在对同一组合事务的顺序执行能产生相同结果的情况。
所有这些概念明确后,我们可以开始了。
引言
“区块链网络”是去中心化的拜占庭容错分布式数据库。事务处理单元(TPU)是负责计算状态转换的组件;它接收事务数据作为输入,并输出一个有序事务列表以及执行结果的(简洁)表示(通常是区块哈希)。
TPU 通常与虚拟机(Virtual Machine, VM)耦合,但又与之不同。像 EVM、SVM 和 MoveVM 这样的区块链 VM 是高层语言 VM。这意味着它们将高层语言(Solidity、Rust、Move)的字节码(编译的中间表示)转换成机器可执行代码。区块链 VM 基本上与更熟悉的仿真 VM 相同;它是一个沙盒环境,允许非本机指令集(区块链字节码)在实际硬件(x86/ARM)上执行。
TPU,特指 TPU,负责管理整个事务执行管道,包括创建和管理 VM 的实例。因此,上面提到的这些术语是相关但不同的。特别是 TPU 是本文的焦点。
TPU 有两种类型:顺序型(sequential)和并行型(parallel)。顺序 TPU 是最容易设计和实现的。顺序 TPU 以先进先出(FIFO)的方式处理事务。此方法非常简单,并且没有调度开销,但顺序 TPU 并没有充分利用计算机硬件设计的状态和趋势。
自 2000 年代中期以来,计算机硬件一直在接近单处理器性能的极限,且整个行业已开始转向通过增加核心数量来扩展。如果没有计算方面的突破,计算机将通过增加更多核心来持续改善性能,而不是通过 频率扩展。在这样的背景下,顺序 TPU 将未能最大化(甚至是消费级)硬件,执行时间将迅速成为瓶颈。
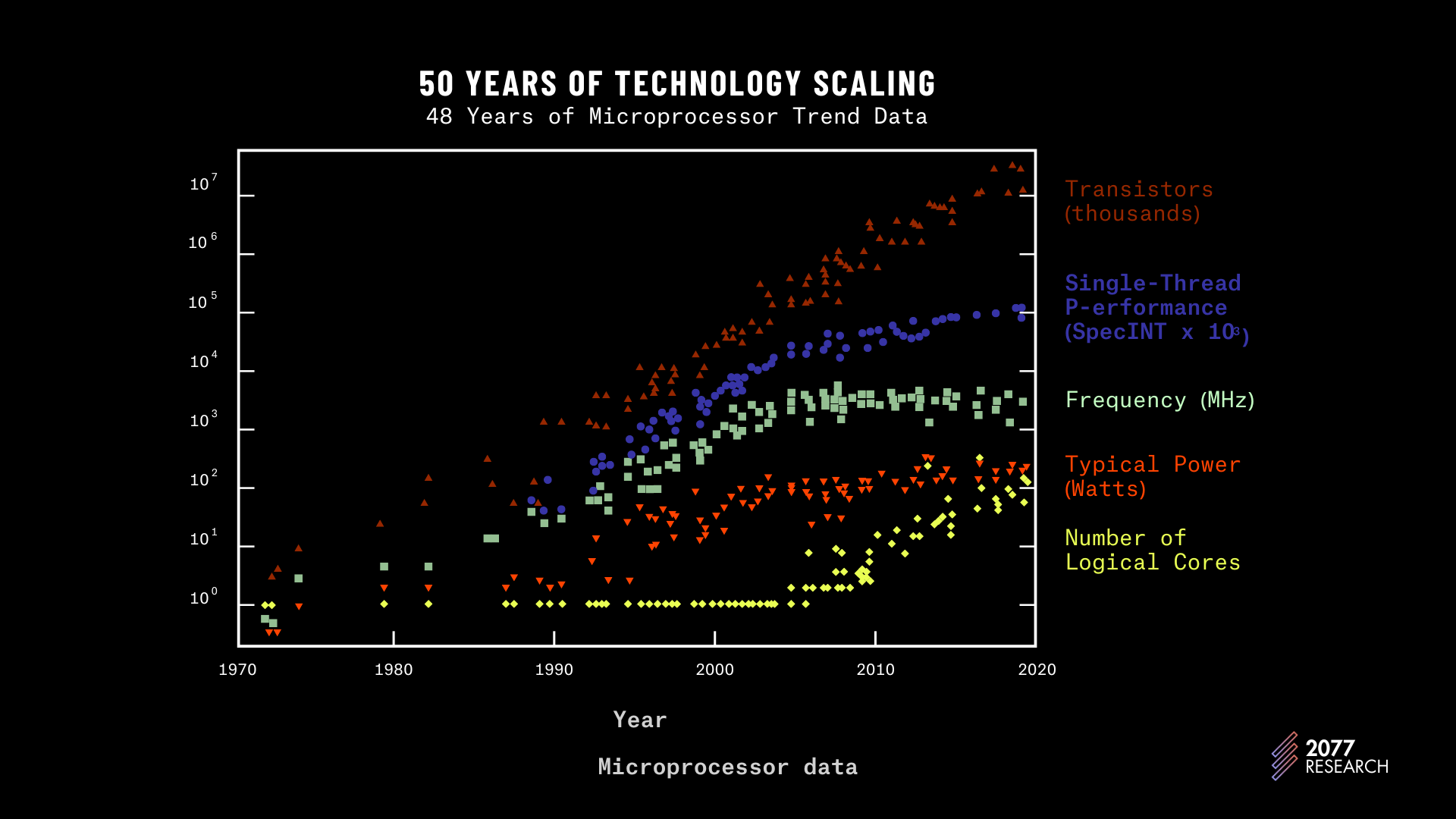
图 1: 微处理器趋势数据 | 源
图 1 显示了单线程性能(蓝点)和频率(绿方块)的趋势,这两者都放缓,并且看起来有所下滑。黄色菱形显示“逻辑核心”的数量,这个数字自 2000 年中期以来稳步增长。并行 TPU 旨在充分利用这一趋势。
并行 TPU 被设计为尽可能并行执行许多不冲突的事务。一个理想的并行 TPU 将执行尽可能多且不依赖于任何高级优先级事务的事务。比如,考虑“按优先级排序”的事务集合 {tx1 > tx2 > tx3...tx7 > tx8},其依赖图如下。箭头表示依赖关系,例如,tx4 是 tx1 的依赖关系。
tx1 → tx4 → tx5
tx2
tx3 → tx6
tx7
tx8
依赖关系图假设每个事务的执行时间单位是相同的,一个理想的四线程并行 TPU 将:
- 并行执行事务
tx1、tx2、tx3和tx7。 - 然后执行
tx4、tx6和tx8。 - 最后再执行
tx5。
设计和实现并行 TPU 的挑战在于设计一个并发控制系统,以确保及时执行的只有不冲突的事务,同时保持优先级并尽量减少开销。让我们看看这是如何在实践中实现的。
并行 TPU 的实现——并发控制——及其必要性。
我们很容易说,“...直接并行执行事务就行了,兄弟.. ”而不真正理解为什么这是一个如此困难的问题,因此我将给出一个简单的例子来阐述在尝试对共享资源进行并行访问时为什么并发控制是必要的。
考虑一个银行数据库的示例,其中:
- accountA 余额为 $50
- transaction1 希望从 accountA 向 accountB 转账 $50
- transaction2 希望从 accountA 向 accountC 转账 $50。
假设两个事务都被允许并行执行,
- 起初,两个交易都会将 accountA 的余额读取为 $50。
- 然后两个交易都将零 ($0) 写入存储 accountA 账户余额的内存位置。请注意,无论一个先写入另一个,两个账都将余额读取为 $50,并更新为(原始余额 - 转账金额),因此两个账户都会将账户余额写成 0。
- 两个事务都将读取 accountB 和 accountC 的账户余额并在余额储存的内存位置上再写入其他 $50,打印出$50如同凭空而来。
这是一个简单的例子,但足以表明当有未被协调的事务并发访问/修改共享资源时,执行结果是非确定性的(受到竞争条件影响)且不能序列化。由于缺乏并发控制,还有其他一些潜在问题可能会出现:
- 丢失更新问题:当一批事务并行执行时,存在较低优先级事务(例如 txk)覆盖实际需要高优先级事务(例如 txj)读取的内存位置的可能性。txj 应该在 txk 写入该位置之前读取值,但没有并发控制就无法强制执行这一行为。
- “脏读”问题:有时事务会被“回滚”,这意味着它们写入的所有数据都会被回滚;然而,此时另一个事务在回滚之前可能已经读取了这些(脏的)值,从而破坏了数据库的完整性。
由于简单并行化事务可能产生的更多潜在问题在这里未做讨论,以简洁为由。重要的观察是,在没有额外安全措施的情况下尝试并行化执行,将妨碍执行结果的完整性。此问题在分布式数据库管理系统(dDBMSs)中的解决方案被称为并发控制(Concurrency Control, CC)。
并发控制和并发控制的类型
并发控制是确保同时执行的操作不会发生冲突的过程。在 DBMS(以及由此延伸到区块链)中,存在两种主要的并发控制范式:乐观并发控制(Optimistic Concurrency Control, OCC)和悲观并发控制(Pessimistic Concurrency Control, PCC)。
- 悲观并发控制(PCC):在 PCC 中,如果事务需要访问的资源已经被另一个(通常是更高优先级的)事务使用,则该事务的执行将被阻塞。在 PCC 系统中,锁通常是强制“阻止”的选择工具。大多数 PCC 系统还要求事务预先声明将读取和/或写入的内存片段,因为动态获取锁仍将导致不可序列化的执行结果。
- 乐观并发控制(OCC):在 OCC 中,事务尝试在可用的尽量多的处理资源上进行执行。不过,与其直接写入或从持续内存中读取,事务通常写入到日志中。经过尝试执行后,验证该事务的执行是否违反了任何数据库完整性规则。如果验证失败,事务的影响将被回滚,并重新调度该事务进行执行。否则,事务将被提交,即写入持久内存。
有多种设计和实现 OCC 和 PCC 系统的方法,但在以下部分中,我们将查看这两种范式在区块链领域的领先实现,首先是领先的 OCC 实现:Block-STM。
区块链软件事务性内存(Block-STM)
Block-STM 是围绕事务性内存(Transactional Memory, TM)和分布式数据库进行多年研究与开发的结果,但在覆盖 Block-STM 之前,简要回顾几个概念,尤其是 Aptos 事务的生命周期。
Aptos 事务生命周期的简要描述
Aptos 事务的生命周期类似于其他区块链,但具有一些 Aptos 特定的细节以提高 Block-STM 的性能。
- 事务最初作为客户端的请求;该请求找到一个完整节点或验证节点。
- 完整节点将事务转发到网络上的其他节点。这些节点将这些事务保留在内存池中。
- 每个节点的内存池调用执行签名验证、最小账户余额验证以及使用序列号的重放阻力检查。账户的序列号相当于以太坊中的 nonce。它跟踪从该账户提交的事务数量。如果一个事务的序列号与账户的序列号不匹配,节点将拒绝该事务。这是 Aptos 用于防止重放攻击的方法,重放攻击是指恶意实体存储已签名事务并在执行后重新传播它。
- 检查完成后,当前区块的领导者从其内存池中获取一组事务(当前实现根据费用优先处理事务)并将未执行的区块作为下一组事务的拟定排序转发给其他节点。
- 领导者开始并行执行该区块,同时转发区块。
- 一旦领导者完成执行结果,签署执行结果并转发给其他验证者。
- 所有已接收到区块的验证者会重放并达成对执行结果的共识。
以下来自 Aptos 文档的插图展示了一个事务的生命周期。
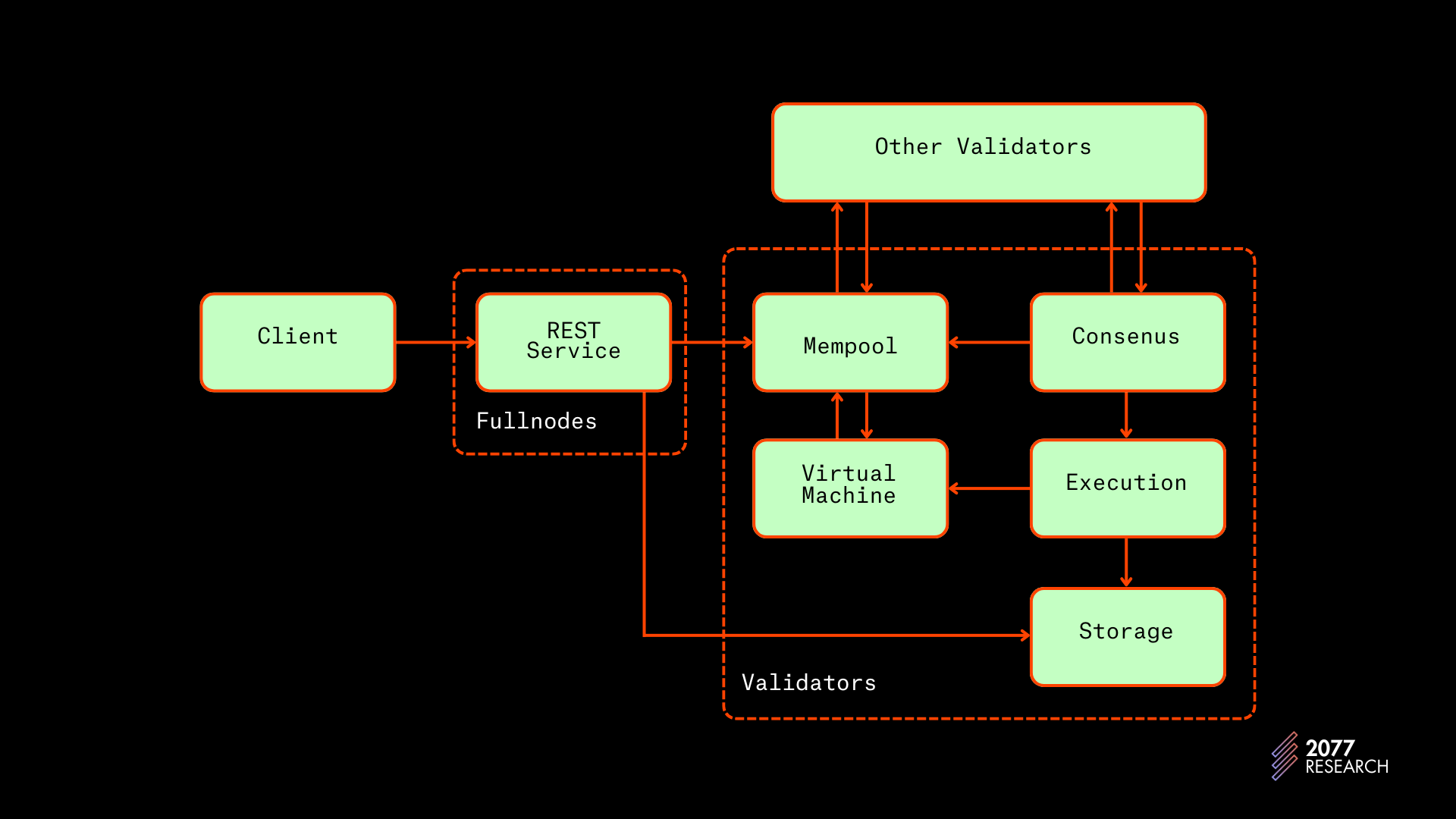
图 2: Aptos 事务的生命周期 | 源
Aptos 的事务生命周期与其他区块链的关键差异在于 Aptos 的区块是在执行之前被传播的。这与其他区块链截然不同,后者的执行结果与事务一起进行传递。这个设计选择有两个影响:
- 它分离了排序和执行。
- 它增加了额外的消息轮次。
Aptos 对排序和执行的解耦为异步执行奠定了基础,该原则已被 Monad 采用,并且也在 Solana 的路线图上。
另一个并不立即显现或更准确地说,是认为已内置于 cake 的变化是,在传统的共识协议中(包括 Aptos 的),领导者总是要承担过多的工作。为了克服这一问题,Aptos 现在使用 Quorum Store,这是一种实现了 Narwhal 的机制,目的是在所有验证者之间分摊带宽利用率。在附录中我简单地讨论了 Quorum Store。
解释完这一点后,覆盖 Block-STM 的最后一步就是简要讨论导致 Block-STM 之前的重要发展。
事务性内存(TM),软件事务性内存(STM),Calvin 和 BOHM。
如前所述,Block-STM 基于数十年的研究。最早的开发出现在 1993 年,提出了事务性内存(TM)论文,描述了“事务性内存访问”的硬件级解决方案。软件事务性内存(Software-only Transactional Memory, STM)在 2005 年被正式化,利用软件实现了 TM 的原理。其他两个显著发展是处理分布式数据库的并发事务性修改的“Calvin”和“BOHM”协议。为了提供 Block-STM 的背景,我们将对它们进行概述。
事务性内存(TM)
我觉得将事务性内存看作是 事务性内存访问 更容易。TM 的基本原则是允许并发程序以类似于数据库事务修改数据库的方式对共享内存进行修改(读和写),无需使用锁。更简单地说,TM 的目的在于允许并发程序以原子方式修改共享内存 并 产生可序列化结果,而无需使用锁。开发 TM 的原因是基于锁的同步技术需要管理锁所带来的开销,并且必须小心设计以抵抗 优先级反转、连锁、死锁、活锁等。TM 不需要担心这些问题,并且在理论上可能会超过基于锁的系统。
该论文提出了一种新的多处理器架构(不是指令集架构),以及一些允许事务性内存访问的新指令。这些附加指令允许程序员定义新的 读-修改-写操作,以便在不需要锁定这些内存位置的情况下,对一个或多个内存位置进行原子更新。
开发了少数(不到十个)TM 实现,但 TM 从未得到广泛使用。
仅软件事务性内存(STM)
STM 是一套软件仅实现事务性内存原理的实现。其目标与 TM 相同:允许并发进程无锁访问共享内存。
STMs 通常通过乐观的方式实现这种功能——线程在执行过程中对其他线程的活动不予关注,但在将其写入直接存储内存而非提交时,线程会将每次读取和写入记入日志(抽象数据结构)。
在一个线程执行结束后,结果将被验证,即在执行过程中读取的值与当前在同一内存位置的值进行比较。如果这些值不同,则线程将回滚其所有写入,因为读取集合的差异表明一个或多个并发进程修改了被验证的进程访问的内存区域,因此,执行结果是无法序列化的。STM 实现将重新执行(并重新验证)验证失败的事务,直到它们通过验证。STM 最大化了并发,因为线程无需等待访问所需资源,但在高竞争用例中存在大量的无用工作。
多年的研究表明,STM 实现比具有“细粒度”锁的同步方法在少量处理器上表现更差,这源于管理日志所带来的开销。出于这些原因,STM 实现并没有在实践中得到很多使用,而仅在一些针对特别用例进行了优化的情况下使用。
Calvin
在 Block-STM 之前的下一个重要发展出现在 2012 年的“Calvin”论文中,作者证明了与普遍观念相反,强制实施事务的预设顺序是提高分布式数据库执行吞吐量的有效方法。Calvin 之前的普遍看法认为,强制预设执行顺序会降低并发力,但 Calvin 明确确立了这一观点是错误的。
Calvin 和 Sealevel 一样,要求事务(在执行过程中)事先声明将要访问的所有内存位置。其他工作流程相对直接。
Calvin 节点(管理分布式数据库的分区的计算机)首先决定一组事务 {tx1 > tx2 …> txn} 的排序(优先级),并在达成共识推定之后,Calvin 的调度遵循简单的规则:
如果两个或多个事务请求访问相同的内存位置,则必须允许高优先级事务优先访问该内存位置。
有一个专门的线程负责锁管理,并且该线程遍历序列事务顺序,确保锁请求按顺序提交。当两个事务发生冲突时,它们根据优先级的顺序被顺序调度,但不冲突的事务可以并行调度。
Calvin 的设计还有很多细节,但关键的收获是 Calvin 确立了优先级强制管理能够提高吞吐量这一观点。
BOHM
接下来重要的发展是 2014 年的 BOHM。与 Calvin 一样,BOHM 也是为分布式数据库而设计的,但其关键的洞察同样易于扩展到区块链。BOHM 使用多版本并发控制(Multi-Version Concurrency Control, MVCC)机制,这是一种使用多版本日志管理对共享内存的读取和写入的辅助性并发控制形式。
简而言之,在 MVCC 数据库中,事务并不直接修改数据库;相反,日志为每个事务提供数据库的多个版本,也就是说,每个内存位置与已经写入它的所有事务值相关联,而不仅仅是最新的写入。
你可以把这个多版本数据结构想象成一个二维表,其中条目为 (transaction version, value) 的形式。这个二维表的每一片段都是一个特定内存位置的状态版本表。图 3 显示了一个可以帮助传递这一想法的插图。

图 3: 多版本数据结构的插图
在 MVCC 中记录数据的方式类似于 TM 的方法,但在 MVCC 中,每次对内存位置的写入,都会创建(或更新)与该事务相关的特定新版本,而不是覆盖当前值。MVCC 数据库允许比单版本数据库更多的并发,因为事务可以读取任何事务在某个内存位置写入的值,无论有多少个事务向该位置写入;其折中是内存复杂度的增加。
BOHM 显示,结合多版本并发控制与固定事务排序显著提高了数据库的执行吞吐量,同时保持完全可序列化性。BOHM 的工作方式简要如下:
BOHM 是一个两层协议——有一个并发层和一个执行层。当事务流送入并发层时,有一个独立的线程根据时间戳对事务进行排序。“并发线程”负责数据库的逻辑分区。BOHM 要求事务预先声明其读取和写入集合,使用这些信息,每个并发线程遍历有序集合,检查事务是否写入其分区。对于所有写入的事务,内容线程将在日志中为该事务创建一个未初始化的占位符。由于每个线程负责数据库的分区,BOHM 在创建占位符时通过事务内并行性增加了并发性。并发控制线程完成任务后,另一组线程,即“执行线程”,执行事务并填充占位符。
如前所述,有一个优先级顺序,因此当事务需要从某个内存位置读取时,它会检查高于自己的最低优先级事务写入的值。例如,如果事务 tx2 和 tx6 写入了 tx4 需要读取的内存位置,tx4 将读取 tx2 写入的值。
如果与该正确版本相关的占位符仍未初始化,即 tx2 尚未写入该位置,那么事务的执行(tx4)将被阻止,直到应对该位置进行写操作的事务(tx2)完成写入。 这种“读取永不阻塞写入”的设计使得 BOHM 在处理大型工作负载时极为高效,因为最大的成本——构建多版本数据结构在工作负载增加时得到分摊。
同样,某些细微差别并未纳入,但 BOHM 设计的关键收获是在牺牲产出的情况下,多版本数据结构有利于提升并发性。
除了上述四个协议外,2017 年的一篇论文也在区块链中开展了有关 STM 的一些工作。论文中,作者提出了经典 STM 设计和 动态 解锁收购,试图防止并发内存访问,并在执行后验证以识别冲突。
该设计相对简单:事务乐观地实验,试图在需要时抓取锁,并在后续的验证。如果发现冲突,则通过回滚事务并重新执行来解决冲突。该设计赋予领导者选择事务顺序的很大自由,但结果是非确定性的,因此其他节点不太可能达成与领导者相同的执行结果,除非领导者共享准确的执行路径。但该设计从未得到应用,主要是因为论文中呈现的性能结果显示该协议的性能仅略好于顺序执行,有时甚至更差。Block-STM 应用了 Calvin 和 BOHM 的洞察,并在2017年尚未命名的协议未能成功之处取得成功。搭建了适当的背景后,我们可以继续讨论 Block-STM。
Block-STM
传统的分布式数据库将 Calvin 和 BOHM 的见解视为约束,因为:
- 强制优先级排序要求节点之间达成某种共识,并且
- 在事务数据库中,逐个提交每个事务(与区块 düzey 事务相对)是常态。
但这两种属性在区块链中是固有的——区块链节点必须就事务的排序达成一致,即使领导者可以自由提出,并且通常发生在区块级别(或至少以 Solana 的形式进行批量提交)。本质上,传统数据库所认为的约束内置于 Block-STM 的规范中,Block-STM 利用这些约束改进了其性能。
下面简要概述了 Block-STM 的工作原理:
与 Calvin 类似,事务按优先级排序:{tx1 > tx2 > tx3 >... txn}。排序后,事务被调度执行。与 STM 类似,事务“尝试”使用所有可用资源进行执行,而不考虑冲突。与 BOHM 类似,执行线程不直接对内存进行读写。而是阅读或写入多版本数据结构(后文将称之为“数据结构”)。
沿袭 BOHM 的思路,当事务(例如 txj)从数据结构中读取时,它将读取由低于自身优先级的最高顺序事务写入的最新版本 的值(在此示例中,txj 将从写入该内存位置的某个事务 txi 中读取)。例如,如果 tx6 希望从 tx1 和 tx3 写入的内存位置读取, 则 tx6 将读取由 tx3 写入的值。 (请记住,阅读是 Block-STM 工作原理的核心。)
在事务执行过程中,跟踪其 读取集(read set),该 读取集 包含事务在执行过程中读取的内存位置和关联值。当事务(txj)完成执行后,将通过比较其 读取集 与它从中读取的内存位置的当前值进行验证(注意这里定义的读取)。如果读取集和当前内存位置的值之间存在任何差异,则意味着在该事务(txj)执行过程中,一个或多个高于 j 的优先级事务(例如 txi)已修改了 txj 读取的一个或多个内存位置。根据预设序列化顺序,txj 本应读取 txi 写入的值,因此 txj 写入的所有值都被认为是 脏数据。
但并未删除这些值,而是将其标记为估计,并且将 txj 安排为重新执行。因为值不会被删除,重新执行 txj 的可能性将写入一些位置并且任何(优先级低于 j 的)读取被标记为估计的值的事务将在 txj 重新执行和重新验证之前被延迟。由于这一启发式(heuristic),Block-STM 可以避免一波接一波的中断和重执行,这本来会发生如果数据结构彻底清除此过程。
如果没有差异,前提是当前正在验证的事务(txj)未向其参数中的读取集中写入更高优先级的内存位置,此时 txj 将被标记为有效,但尚不安全提交。事务尚不安全提交的原因是存在相对高优先级事务发生失败验证的可能性。例如,提高优先级的事务(例如 txi)将导致所有低于 txj (txk, txl, txm ...) 的已验证事务需要重新验证以确保它们未从长度任一级更低 txi 写入其数据位置。为此,在预设序列顺序之前的所有事务必须经过执行和验证,才可将其安全提交。
当 BLOCK 中的所有事务都已执行并验证,执行便完成。那是 Block-STM 的基本(可能有些令人困惑)工作原理;接下来我们将详细讨论该过程。
Block-STM 的技术细节
在查看 Block-STM 的技术细节之前,需要明确几点。
首先,Block-STM 的输入为一个有序集合,称为 BLOCK,包含 n 事务,按预设序列顺序排列:{tx1 > tx2 > … > txn}。Block-STM 的目标是利用尽可能多的并发性执行这一 BLOCK 的事务,而不破坏序列化。
如我之前所提到的,每个事务首先被执行,然后被验证。如果被执行的事务未通过验证,则该事务会被安排重新执行。为了跟踪事务被执行的次数,每个事务除了与 索引(index)号相关联外,还与一个 转生(incarnation)号相关联。可以将事务视为 txn, i 形式,其中 n 为索引号,i 为转生号。因此,BLOCK 最初等同于 {tx1, 1> tx2, 1> … > txn, 1}。事务的索引与其转生组合构成事务的 版本。例如, tx2, 5 的版本就是 (2, 5)。
最后,为了支持并发读取和写入,Block-STM 维护一个类 BOHM 讨论的多版本数据结构,它存储每个内存位置的最新写入,同时保持每个内存位置的事务版本。以下是早期实现的一段代码示例:
pub struct MVHashMap<K, V>{
DashMap<K, BTreeMap<TxnIndex, CachePadded<WriteCell<V>>>>MVHashMap 将每个内存位置映射到一个内部的 BTreeMap,该映射将写入该内存位置的事务的索引链接到相应的值。 DashMap 负责并发处理,它允许对 BTreeMap 进行线程安全的修改。数据结构实现的完整细节可在 这里查找。
接下来,我们将查看实际的线程逻辑。
线程逻辑
工作线程(执行和验证线程)的活动由一个 协作调度 线程协调,该线程跟踪和修改两个有序集合,我们称其为 E 和 V。 E 包含所有尚未执行的事务, V 跟踪所有尚未验证的事务。协作调度程序的实现利用原子计数器跟踪这些任务的状态,更多细节可见附录 A3。
每个工作线程循环此 3 步过程,如下所示:检查完成、寻找下一个任务以及执行任务。
检查完成
如果 V 和 E 都为空且没有其他线程在执行任务,则 BLOCK 的执行已经完成。否则:
寻找下一个任务
如果 E 和 V 里有任务,一个可用的工作线程将选择 V 和 E 之间索引最小的任务。例如,如果 V 包含 {tx1 和 tx3} 而 E 包含 {tx2 tx4},则工作线程会为 tx1 创建并执行验证任务。上面提到的原子计数器确保两个集合不会包含同一事务。选择索引最小的任务的原因在于,尽早验证或执行高优先级任务有助于尽早识别冲突,这是预设顺序改进性能的一种方式。
执行任务
如果下一个任务是:
-
执行任务:则执行下一个转生的
txn, i-
如果在执行
txn, i时发现读取了估计值,則:- 中止执行,
- 将所有由
txn, i写入的数据标记为估计,并 - 将
txn, i添加到E(并增加转生号,即txn, i+1)
-
否则(如未读取估计值):
- 检查
txn, i是否向先前的转生(txn, i -1)未写入的任何位置写入数据。 - 如果有新位置的写入,则需要为
txn, i任务创建验证以检查优先级较低的已执行或已验证事务。这一步是必要的,因为如果执行txn, i向先前转生尚未写入的新内存位置写入,则优先级较低的事务(即其标识优先级>n)可能已经从这些内存位置读取,这些都需要验证,而优先级较高的事务没有必要重新存验证,因为它们应该在txn写入之前从该位置读取数据。 - 为
txn, i创建一个验证任务 - 如果
txn, i没有向任何新位置写入任何数据,然后仅为txn, i创建验证任务。
- 检查
-
Loop back to Check done.
-
-
完成验证任务:则:验证
txn, i- 如果验证成功,则线程返回并检查完成。
- 否则(如果验证失败),
ABORT并:- 将
txn, i写入的所有值标记为估计。 - 为另一个优先级较低的验证器
txn, i创建验证任务,这些都未包含在 E 中,并将这些验证任务添加到 V。优先级低于txn, i的事务不会读取由txn, i写入的值,这可根据 Block-STM 读操作的定义得沾确认。 - 将
txn, i的执行任务安排为增加转生号(txn, i + 1)并将任务添加到 E。
- 将
此循环继续,直到 V 和 E 中没有更多的任务。在这之后, Check done 将返回 done,数据结构的最新版本可以安全持久化。完成后,垃圾收集器释放数据结构,事务处理单元准备等待下一个 BLOCK。以下是此过程在实践中的示例:
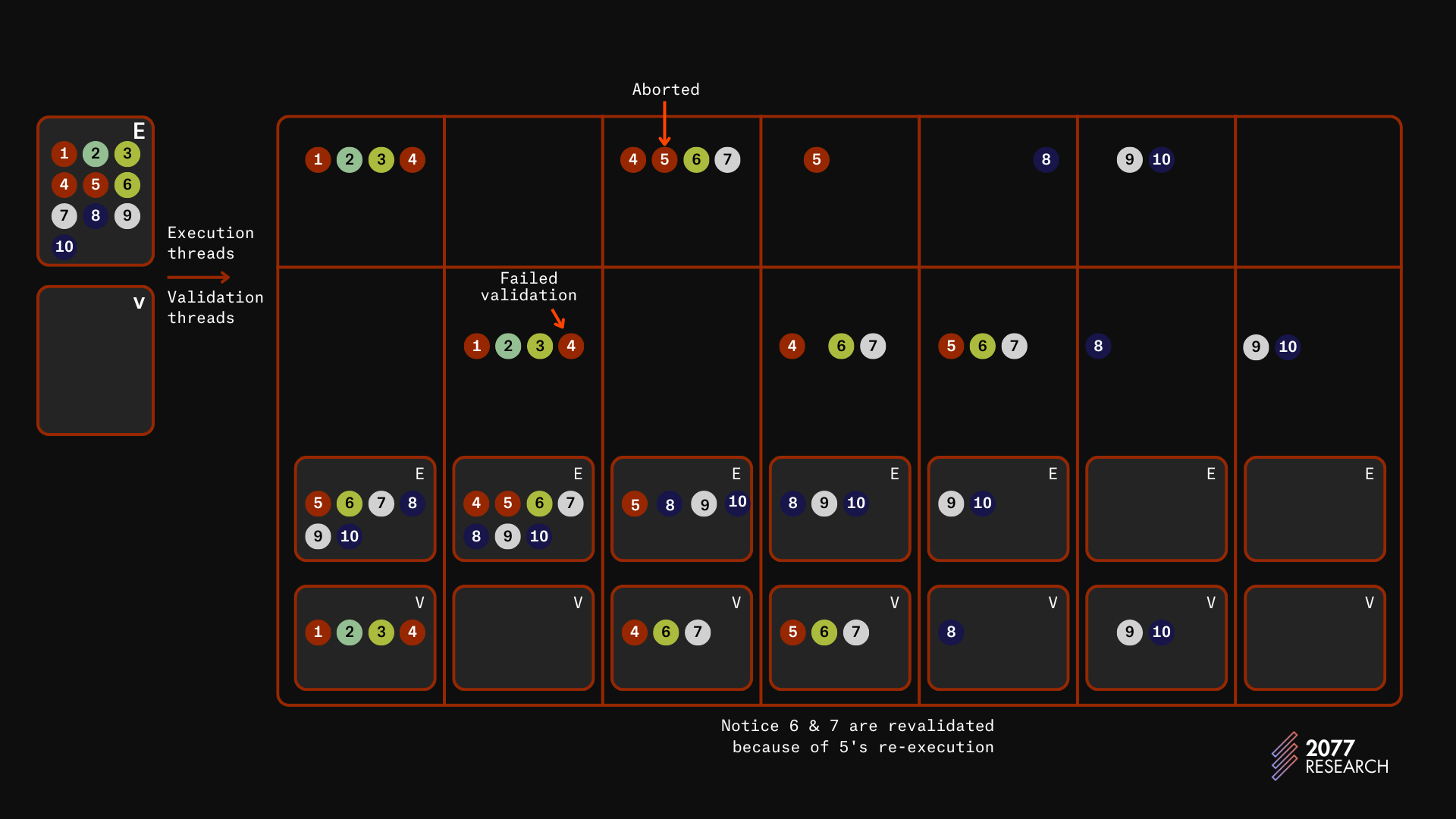
图 4: Block-STM 执行实例
上面的插图呈现的是一个四工作线程的计算机。E 和 V 分别表示执行和验证集合。节点(圆圈)表示事务,节点的颜色帮助识别与其冲突的其他事务。
主表的上层显示了执行线程,而下层则显示验证线程。在每一列中,E 和 V 的集合是每次迭代完成后的执行和验证集合。* 如图所示,E 最初包含所有交易,而 V 是空的。
- 在第一次迭代中,前四个交易被乐观地执行,并相应地更新 E 和 V。
- 在接下来的迭代中,所有四个已执行的交易被验证。事务 4 由于与事务 1 的冲突而未通过验证,必须重新执行。
- 在第三次迭代中,事务 4、5、6 和 7 被执行。事务 5 与事务 4 冲突,因此它将读取标记为估计的值,并且它的执行会在事务 4 完成执行之前暂停。
- 在第四次迭代中,事务 4、6 和 7 被验证,同时事务 5 的执行完成。
- 在第五次迭代中,事务 5、6 和 7 被验证。由于上述原因,6 和 7 被重新验证。事务 8 也被执行。
- 在接下来的迭代中,事务 8 被验证,而 9 和 10 被执行。
- 在最后一次迭代中,事务 9 和 10 被验证,区块被标记为安全提交。
虽然我描述了一个简单的工作流,但相同的过程可以应用于任何具有任何依赖关系结构的交易批次。
从本质上讲,Block-STM 是简单的,这种简单性结合区块链的特定属性——交易的固定顺序、区块级提交和区块链虚拟机的安全性——使 Block-STM 能够在不强制提前声明读/写依赖关系的情况下实现相对较高的吞吐量。Block-STM 论文中包含了生存性和安全性的正式证明。更详细的 Block-STM 分解——包含解释性注释的完整算法——可以在附录 A3 中找到。最后,TPU 的 Rust 实现可以在 这里 找到。
接下来,我们将看看 Block-STM 在实践中的表现。
Block-STM 性能
为了评估 Block-STM 的性能,我们分叉了 aptos 核心,并对现有基准进行了稍微修改,以评估其性能。我们用于测试的机器是 Latitude 的 m4.metal.large,具有 384 GB 的内存和 24 个物理核心的 AMD 9254 CPU。测试评估从获取 BLOCK 到执行和验证所有交易完成的执行过程。
此次评估中使用的交易是简单的 “P2P” 转账;两个账户之间的简单发送。评估的性能指标是吞吐量,表示数据的独立变量是线程数。用于评估性能的参数是区块大小和账户数(用于表示争用)。具有高度争用的工作负载,如 2 个账户,代理你在 NFT 铸造期间或特定市场“活跃”时可能会期望的流量。2 是最极端的可能性,因为这意味着区块中的所有交易都是两个账户之间的交易。没有争用的工作负载如 10000 个账户代理你在区块链用于 P2P 交易时可能期望的流量,即许多个人之间的简单发送。其他负载代理所有介于其间的情况。
图 5-8 显示了 Block-STM 随着线程数量的不同 “争用级别” 和区块大小的性能。
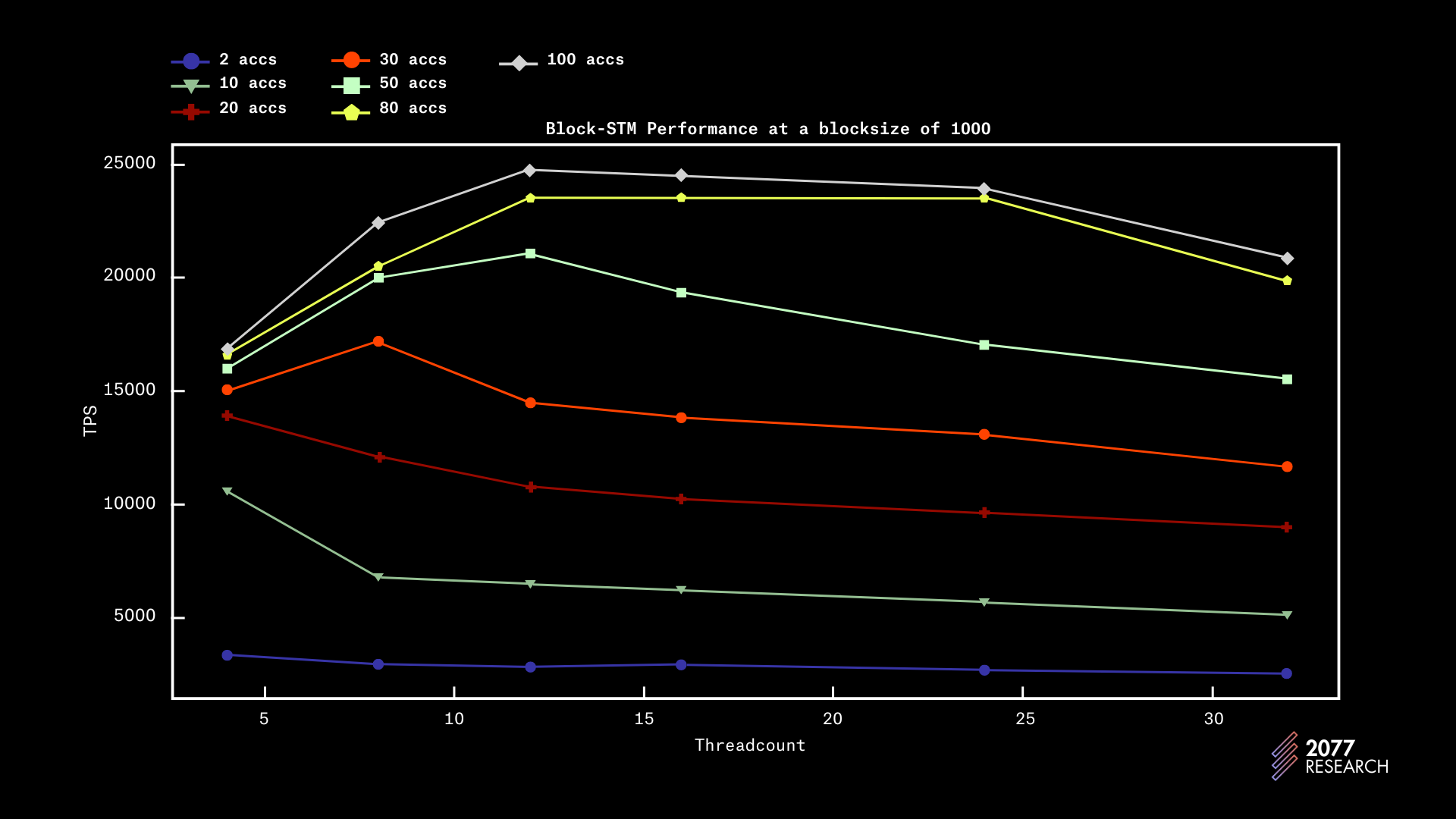
图 5:Block-STM 在不同账户数量和区块大小下的性能
根据数据,可以明显看出(如预期所示),Block-STM 在低争用情况下的表现更好。然而,在高争用情况下(<10 个账户),吞吐量仅略好于顺序执行。在完全顺序的情况下(2 个账户),Block-STM 的性能明显低于顺序执行(这也是可以预期的)。

图 6:Block-STM 吞吐量与不同争用水平和线程数量的区块大小关系
图 6 为 1k 区块大小下的性能提供了更多背景,数据表明在无争用工作负载中,吞吐量在 12 个线程时达到峰值。在高争用情况下,随着核心数量的增加,性能趋势略微下降,达到 8 个物理核心时趋于平稳。在非常高争用的情况下,性能在 4 个核心时达到峰值(这是我们测试的下限,表明使用更少的核心会使性能更好)。这种行为是可以理解的,因为在高度争用的环境中,更多的线程增加了账户同时写入的可能性以及验证失败的可能性。
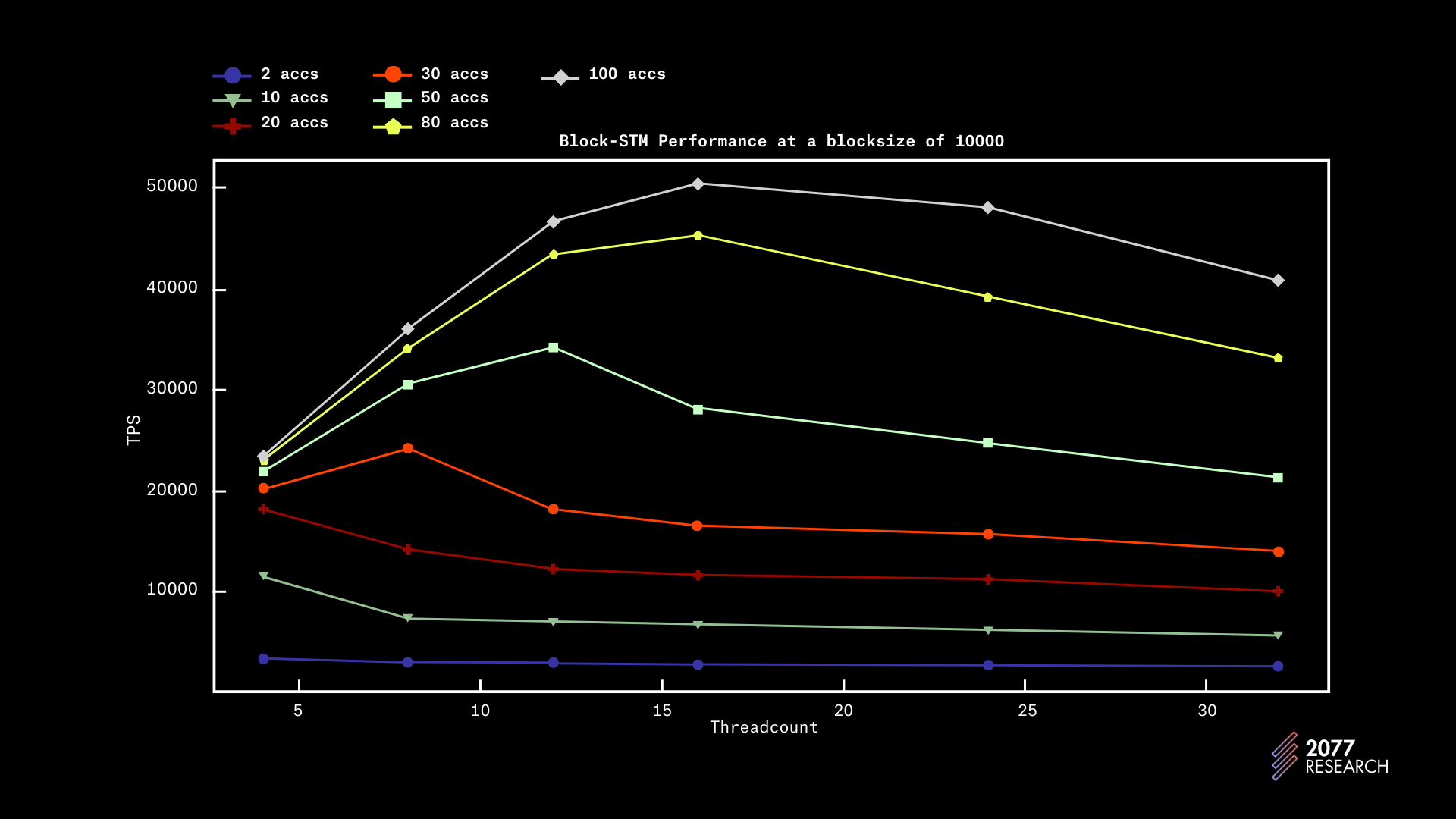
图 7:Block-STM 吞吐量与不同争用水平和线程数量的区块大小关系
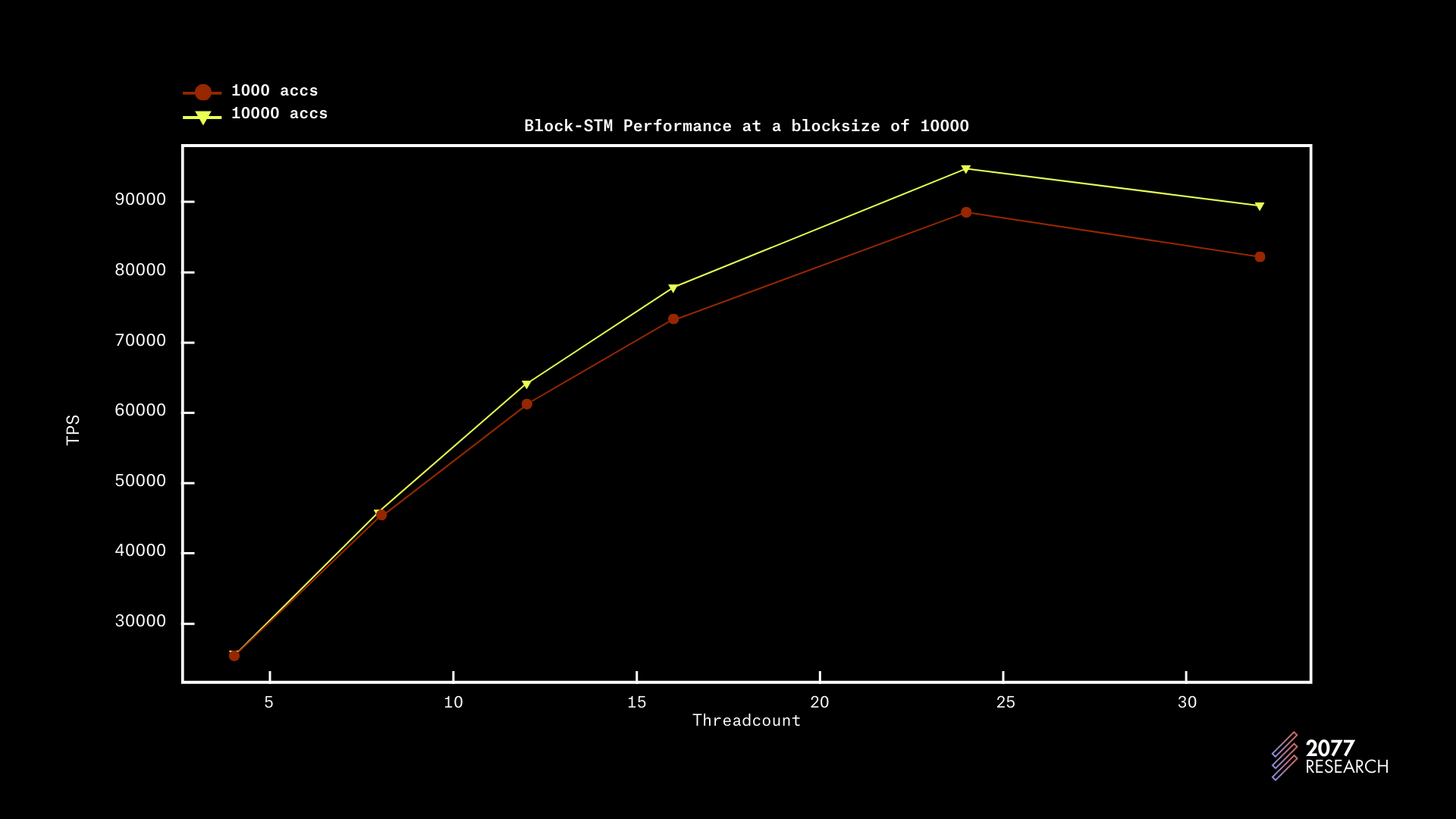
图 8:Block-STM 吞吐量与不同争用水平和线程数量的区块大小关系
图 7 和 8 提供了关于性能相对于区块大小的更多见解,数据与 1k 区块大小的数据非常相似。尽管在较大的区块大小上,性能增长更加线性。
为了简洁起见,我们省略了其他数据,但收集到的数据暗示 Block-STM 在较大区块下的表现更好。随着区块大小增大,性能提高可能是由于初始失败的摊销。随着执行时间的延长,越来越多的事务比其前身更早地 ABORT,从而摊销初始成本。
我们还发现,在 20k 区块大小以上没有明显的性能提升,并且在某个点之后,2020%降低争用也不起作用。一个很好的指示是 1000 个账户和 10000 个账户之间的性能差异微乎其微。实际上,如果线程数 >> 争用,则性能达到峰值。
重要的是要注意,线程数为 24 和 32 的性能并不是 Block-STM 在这些线程数下性能的可靠度量。如前所述,用于测试的机器只有 24 个物理核心。为了暴露 48 个逻辑核心,CPU 利用了超线程,这可能是导致性能波动的原因。
Block-STM 论文中包含了更多测试的结果,包括一个将 Block-STM 与 BOHM 实现进行比较的测试,后者略有优于 BOHM。考虑到 BOHM 事先具有所有交易的完整读写集,这一点令人惊讶,但超出性能很可能是由于在 BOHM 中构建多版本数据结构的开销。
总的来说,数据可靠表明 BlockSTM 的限制,并且不夸张地说,在低争用情况下,Block-STM 的性能远远超出任何顺序执行的运行时,并且几乎呈线性扩展,因此非常适合大型应用程序,例如 Rollup。
关于 Block-STM 的分析到此结束,接下来我们将考虑领先的 PCC 执行运行时——Sealevel——这是 Solana 的并行执行 TPU 的“市场营销术语”。
Sealevel
Sealevel 在设计上与 Block-STM 完全对立。Sealevel 使用基于锁的同步来进行并发控制,但最显著的是,它要求所有交易在执行过程中事先声明将读取和/或写入的状态部分。
Solana 的执行管道通过使用单指令多数据(SIMD)指令进一步优化。SIMD 指令是一种并行(而非并发)处理技术,它在多个数据点上执行单个操作。
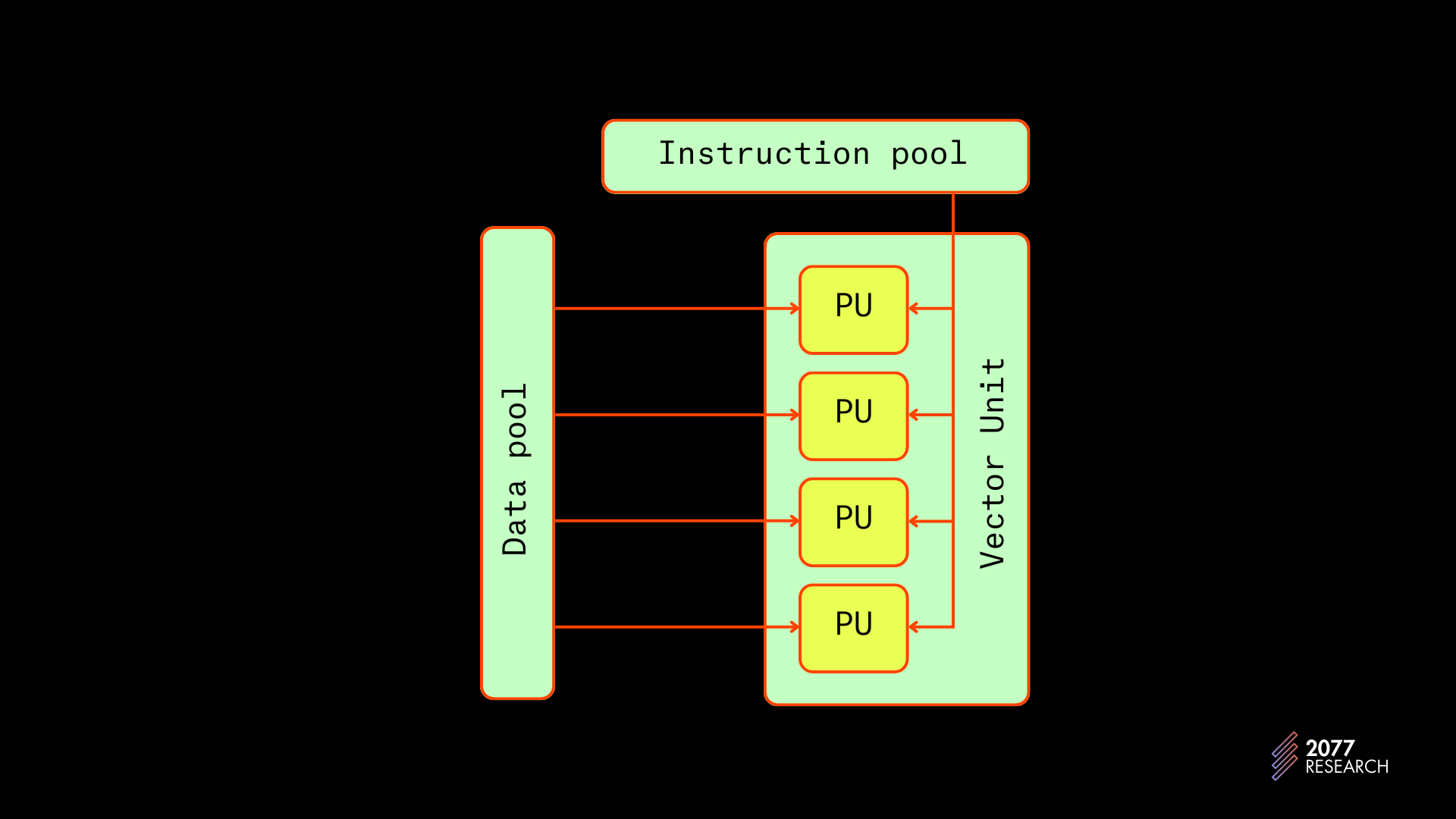
图 9:SIMD 指令 | 来源
关于运行时优化的讨论超出了本文的范围,但这个理念是可以根据调用的程序对事务指令进行排序,并且所有在程序内调用相同指令的指令可以和 SIMD 指令一起批量并行执行(再次强调,并非并发)。Toly 的一句话可能会提供更多的见解。
“所以,如果 Sealevel 加载的传入事务都调用相同的程序指令,比如 CryptoKitties::BreedCats,Solana 可以在所有可用的 CUDA 核上同时并行 执行所有事务。”
简而言之,Sealevel 旨在实现最大速度。接下来的部分将介绍 Sealevel 的工作原理及其性能。但首先,几点基础知识,首先简要描述 Solana 交易的生命周期和结构。
引言 #3:Solana 交易的结构和生命周期
交易结构
如前所述,Solana 交易必须事先声明将访问的状态部分。它们通过列出在执行过程中将使用的账户,并指定它们将是否从这些账户中读取或写入。基本的 Solana 交易结构如下:
"交易": { "消息": { "头": { "numReadonlySignedAccounts": , "numReadonlyUnsignedAccounts": , "numRequiredSignatures": }, "账户密钥": [], // 交易将使用的账户列表 "recentBlockhash": , // 最近的区块哈希 "指令": [ // 列出交易中的指令 { "accounts": [], // 详细说明如下 "data": "3Bxs4NN8M2Yn4TLb", // 包含指令逻辑的 eBPF 字节码 "programIdIndex": 2, // 被调用程序在 "账户密钥" 数组中的索引 "stackHeight": null } ], "indexToProgramIds": {} }, "签名": [] // 签名数组 }
交易指令列表中的“账户”列表是此处的主要焦点。该列表包含指令在执行过程中将使用的所有账户。该列表基于 AccountMeta 结构进行填充。
AccountMeta 结构包含一个账户列表和三个字段。
Pubkey:正在调用程序的公钥(一个 ed25519 密钥,用于识别账户)。is_signer: 一个布尔值,确定账户是否会对消息进行签名。is_writable: 一个布尔值,指示该账户在执行过程中是否会写入。
下面是一个名为 keys 的实例 AccountMeta 结构。
"keys": [ { "pubkey": "3z9vL1zjN6qyAFHhHQdWYRTFAcy69pJydkZmSFBKHg1R", "isSigner": true, "isWritable": true }, { "pubkey": "BpvxsLYKQZTH42jjtWHZpsVSa7s6JVwLKwBptPSHXuZc", "isSigner": false, "isWritable": true } ],
这里的关键是通过 AccountMeta 结构,TPU 可以识别在事务中将被写入的账户,并利用这一信息调度不冲突的交易。
交易的生命周期
Solana 交易的生命周期在很大程度上与大多数其他区块链相同,有一些主要的差异,主要是 Solana 没有内存池。让我们简要概述一下交易从创建到提交的过程。
- 交易创建后,交易被序列化、签名并转发至 RPC 节点。
- 当 RPC 节点接收数据包时,它们会经过 SigVerify,这一步检查签名是否与消息匹配。
- 在 SigVerify 后,数据包进入 BankingStage,此阶段是处理或转发它们的地方。
- 在 Solana 上,节点知道 leader schedule — 一个预生成的计划表,指示哪些验证者将成为哪些插槽的领导者。一个领导者分配了一组 4 个连续的插槽。基于此信息,不是领导者的节点会将交易直接转发给当前领导者和下一个 X (在 agave实现中为两个 (2)) 个领导者。请注意,由于这不是共识破坏的变化,有些节点将交易转发给更多或更少的领导者。
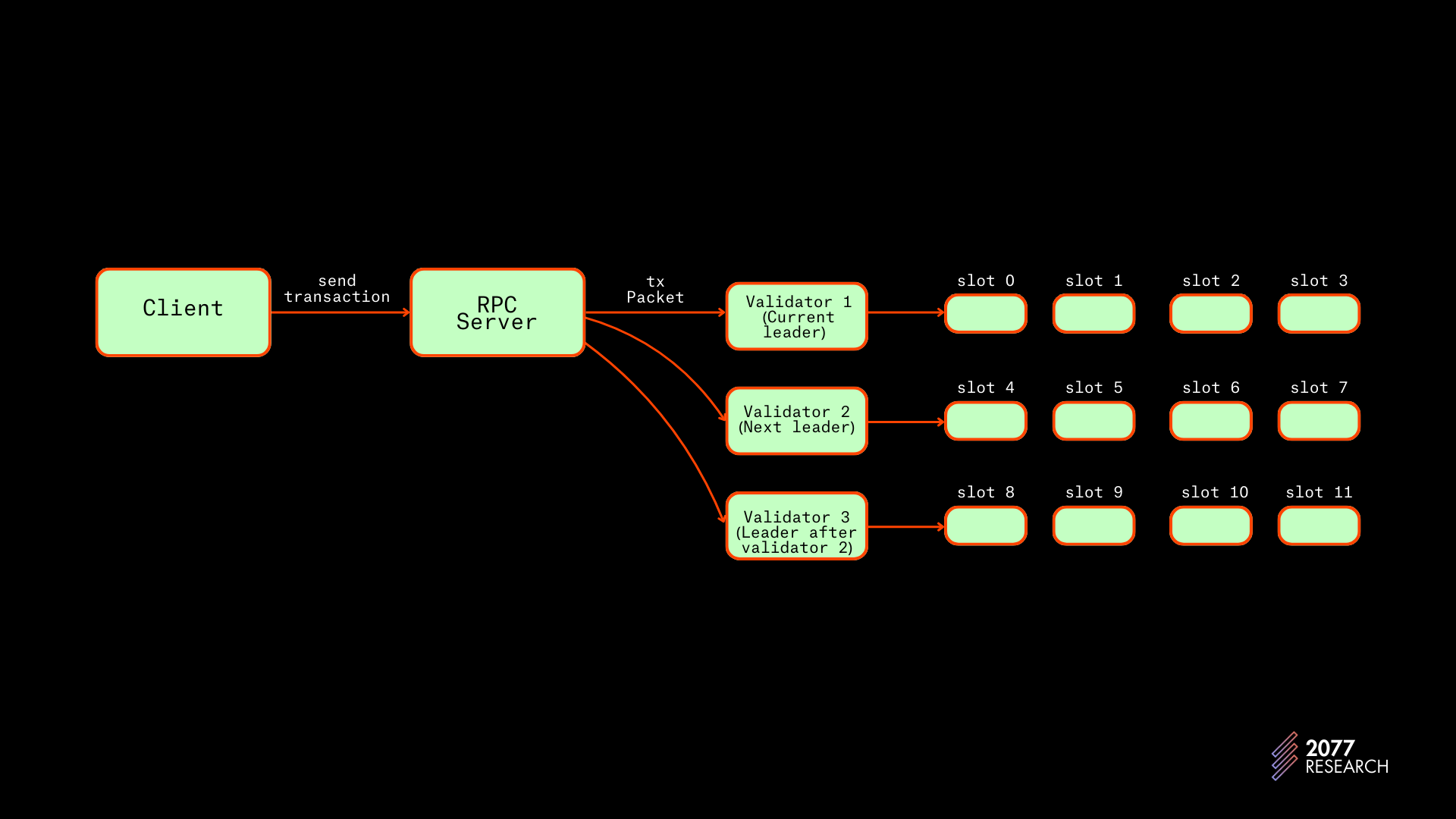
图 10:客户端到领导者应用流程图 | 来源
- 当领导者从其他节点接收到数据包后,它会对数据包运行 SigVerify,并将数据包发送至 BankingStage。
- 在 BankingStage 中,交易被反序列化、调度和执行。
- BankingStage 还与 历史证明 组件进行通信,以对交易批次进行时间戳。关于这一点稍后再做详细讨论。
- 根据设计,Solana 区块不断构建并以称为 shreds _的部分转发。
- 当其他节点接收到 shreds 后,它们会重播这些数据,当组成一个区块的所有 shreds 被接收时,验证者将比较执行结果与领导者提出的结果。
- 然后,验证者签署包含其投票块哈希的消息并发送其投票。投票可以作为交易传递或通过八卦传播,但 Solana 更倾向于将投票视为交易以加快共识。
- 当在一个分叉中达到验证者法定人数时,该分叉顶端的区块被确认。
- 当一个区块拥有 31 个或以上确认的区块时,该区块被 根植,几乎不可能被重组。
Solana 交易的生命周期与 Aptos 交易的生命周期之间的主要区别在于,在 Aptos 中,交易在节点收到区块顺序之前并不会执行。Solana 和 Monad 正在朝着这种类型执行的高级形式(称为 异步执行)迈进,最终目标是“无状态验证者节点”,但这一讨论超出了本文的范围。
在讨论交易执行的核心内容之前,复习一下历史证明概念是有帮助的,因为 PoH 与银行阶段过程密切相关。
引言 #4:历史证明与银行阶段
Solana 的历史证明是一个“去中心化的时钟”。PoH 的工作原理基于递归的 SHA-256 哈希。它使用周期来代理时间的流逝。
基本思路是某个 SHA-256 哈希:
- 是预成像抗性的,即,计算消息 (m) 的哈希 (h) 的唯一方法是将哈希函数 H 应用于 m,并且
- 在任何高性能计算机上的时间是相同的。
由于这两个属性,递归执行 SHA-256 哈希的节点可以根据计算的哈希数量达成相同的时间流逝共识。此外,验证高度可并行化,因为每个哈希都可以不依赖上一个哈希的结果进行检查。由于这些属性,PoH 允许 Solana 节点在没有同步或通信的情况下达成时间流逝的共识。以下是 PoH 哈希计算 的代码片段:
self.hash = hashv(&[self.hash.as_ref(), mixin.as_ref()]);
mix_in 是一条任意的信息(在此上下文中为交易哈希),其附加在之前的哈希上,以确保 mix_in 代表的事件在计算哈希之前发生,实质上对该事件进行了时间戳。
与银行阶段相关的其他 PoH 特定概念包括:
- ticks:tick 是一个时间度量,通过 X (目前为 12,500) 个哈希定义。tick 哈希是链中的第 12500 个哈希。
- entry:entry 是一个带时间戳的交易批。entry 被称为 entry,因为它们是 Solana 将交易提交到账本的方式。一个 entry 由三个组成部分构成:有两种类型的 entry:tick entries 和 transaction entries。tick entry 不包含任何交易并在每个 tick 生成。transaction entries 包含一批不冲突的交易。
num_hashes: 自上一个 entry 以来执行的哈希数量。hash: 是哈希前一 entry 进行 num_hashes 次哈希的结果。
Entry 限制
有许多规则决定一个区块是否有效,即使它包含的所有交易都是有效的。你可以在 这里 找到一些规则,但与本报告相关的规则是 entry 限制。该规则规定,entry 中的所有交易必须是非冲突的。如果一个 entry 包含冲突的交易,则整个区块无效并被验证者拒绝。通过强制所有数据包中的交易为非冲突的,验证者可以并行重放 entry 中的所有交易,而无需调度的开销。
然而,SIMD-0083 提出了解除这一限制,因为它限制了区块生成,并阻碍了 Solana 的异步执行。Andrew Fitzgerald 在他的这篇文章中讨论了这一限制及其认为 Solana 在朝间接执行的道路上的下一步。
讲清楚,这一限制并不完全决定交易如何调度,因为已执行的交易不必包括在下一个 entry 中,但它对于当前调度程序设计是一个重要的考虑因素。
以上讲完后,我们可以讨论交易执行的核心—Solana 的 BankingStage。
银行阶段
BankingStage 模块包含 Solana 的 TPU 和许多处理交易的其他逻辑。本文的重点是调度程序,但将简要讨论 BankingStage 以提供一些必要的背景。
Banking Stage 概述
BankingStage 位于 SigVerify 模块和 BroadcastStage 之间,而 PoH 模块则与之并行运行。如前所述,SigVerify 是验证交易签名的地方。BroadcastStage 是处理后的交易数据通过 Turbine 将其散布到网络上的其他节点,而 TPU_Forwarding 模块负责将清理过的交易数据包传播给领导节点。
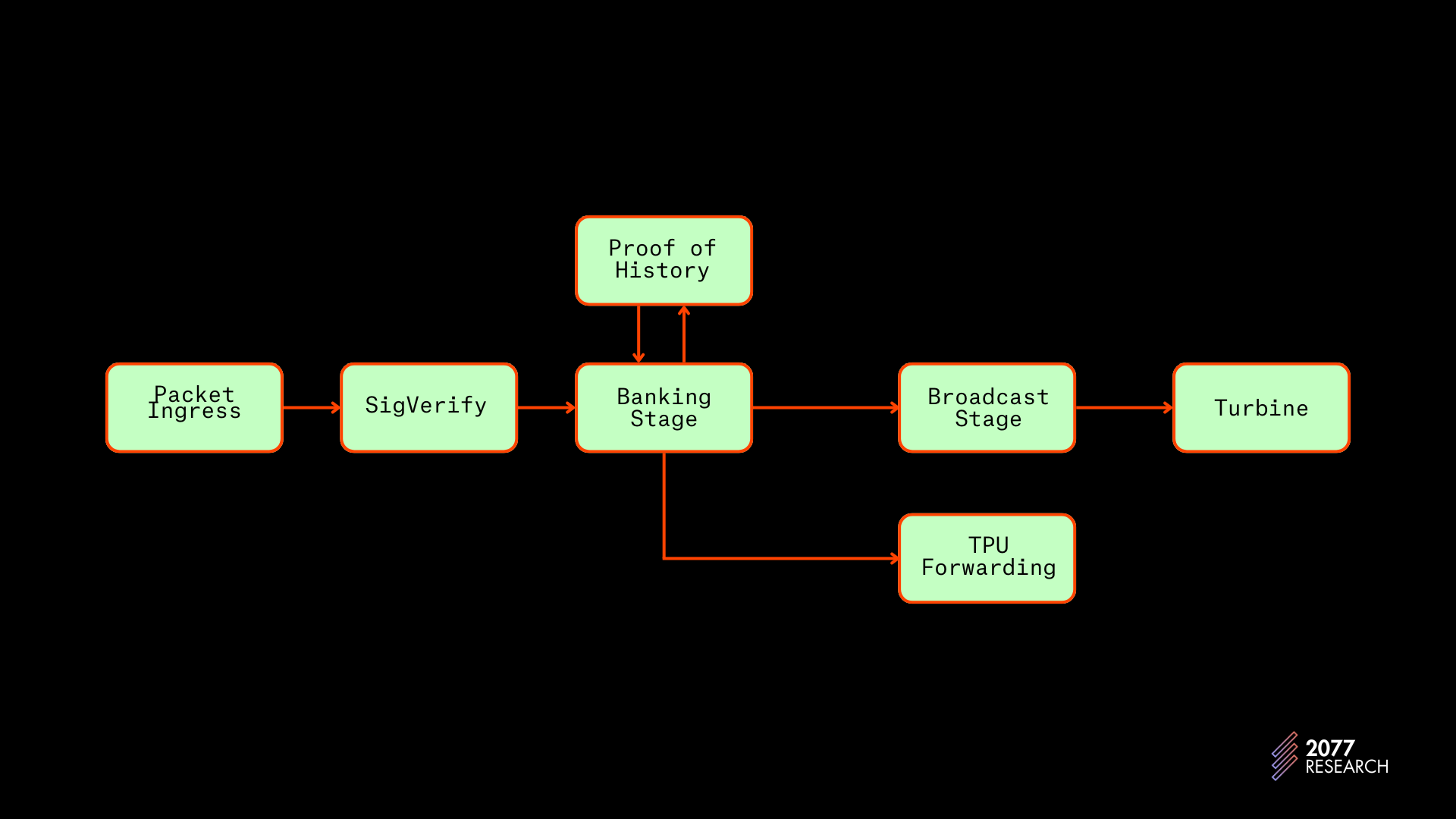
图 11:Solana 交易流程 | 改编自
在 BankingStage 中,来自 SigVerify 的交易数据包被缓冲并以适当的通道接收。投票交易在两个通道的末尾接收,即 Tpu_vote_receiver 和 gossip_vote_receiver ,而非投票交易则由 non_vote_receiver 接收。在缓冲后,数据包根据领导者安排进行转发或“消费”。如果节点不是领导者或即将成为领导者,则清洗的数据包被转发到适当的节点。当节点成为领导者时,它“消费”这些交易数据包,即这些数据包被反序列化、调度并执行。
调度是本文的主要重点,稍后将对此进行扩展。执行阶段相对直接;在一批交易被调度后,TPU 将:
- 运行检查:工作线程检查事务:
- 是否过期;通过检查引用的 blockhash 是否过于陈旧。
- 是否已经包含在之前的区块中。
- 抓取锁:工作线程尝试为批中的所有事务获取适当的读写锁。如果锁获取失败,稍后再尝试事务。
- 加载账户并验证签名者是否可以支付费用:线程检查加载的程序是否有效,加载执行所需的账户并检查签名者是否可以支付事务中指定的费用。
- 执行:工作线程创建 VM 实例并执行交易。
- 记录:将执行结果和发送到 PoH 线程的事务 ID 记录,PoH 线程将生成一个 entry;在此步骤中,entries 也会发送到 BroadcastStage。
- 提交:如果记录成功,更新状态并提交结果。
- 解锁:解除账户的锁。
以上是对 BankingStage 的完整概述。接下来,我们将深入探讨 Solana TPU 中的调度方式。这个部分经历了许多重要变化,但为简洁起见,我们只讨论两个最近的实现:线程局部多迭代器和中央调度器。
线程局部多迭代器
在线程局部多迭代器实现中,消费的交易数据包位于刚才提到的 non_vote_receiver 通道。每个非投票线程从共享通道中提取交易,根据优先级对其进行排序,并将有序的交易存储在本地缓冲区中。
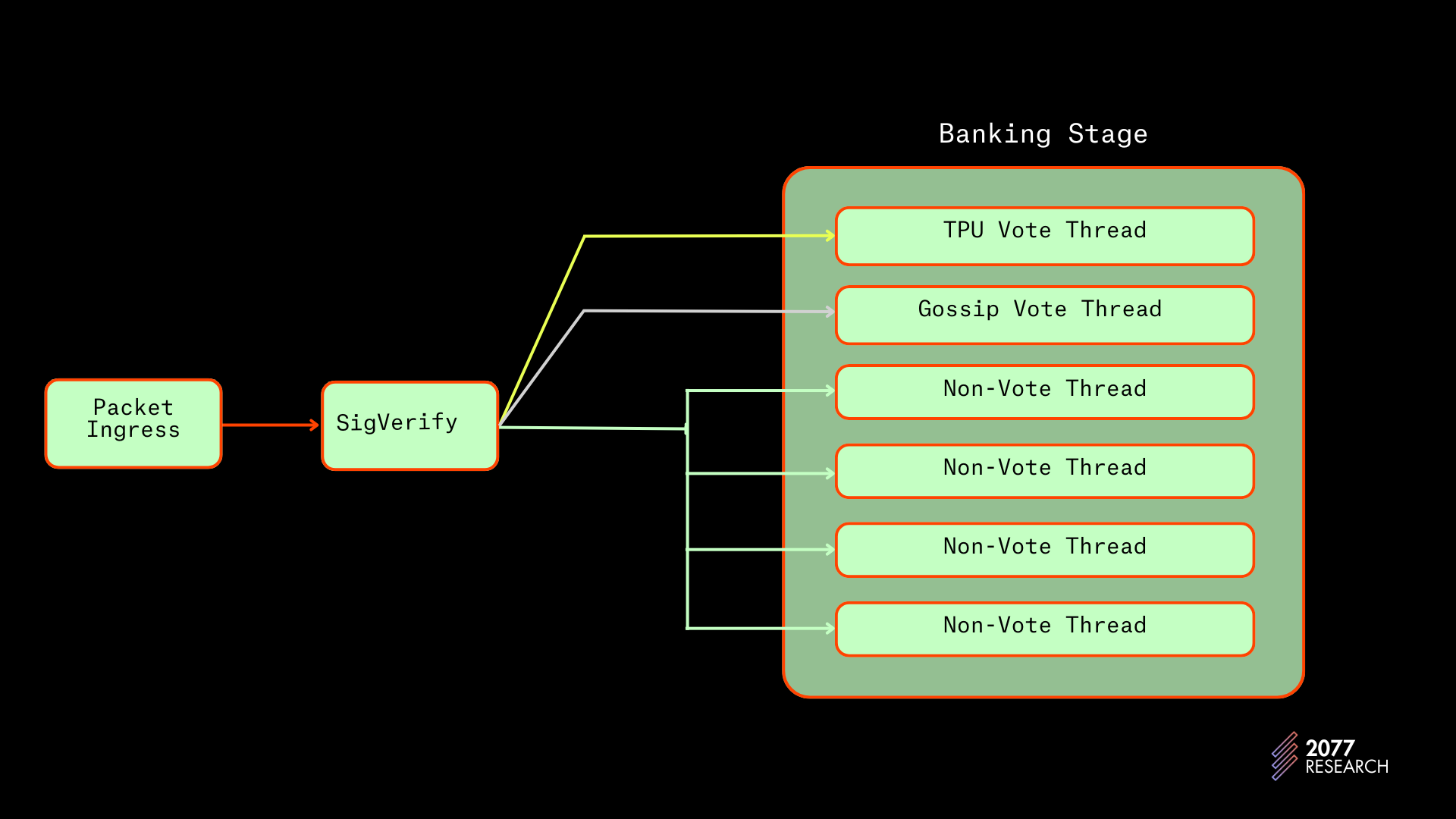
图 12:银行阶段的 TLMI 实现
TLMI 的本地缓冲区是双端优先队列,以便在移除最低优先级的同时快速添加新高优先级交易。然后,每个线程“通过”其缓冲区的 multi-iterator 遍历以创建一批 (128) 个不冲突的交易。
多迭代器是一种编程模式,允许多个迭代器对象通过数组运行;这些迭代器根据决策函数从数组中“选择”项目。多迭代器概念可能会抽象,所以在解释之前,这里有一个示例用户,展示 Solana 的 TLMI 是如何工作的:
假设有一组合共十个交易 [tx1 > tx2 > tx3 >...tx10] 以及如下依赖图:
tx1 → tx4 → tx5tx2tx3 → tx6
tx7→ tx9
Tx8 → tx10
假设 TLMI 创建了四个交易的批次,那么在这一组交易中,TLMI 将执行:
- 首先选择 tx1,然后是 tx2,然后是 tx3,最后是 tx7 作为第一批。tx4、tx5 和 tx6 会被跳过,因为它们与已选择的交易存在冲突。
- 下一个迭代器选择 tx4、tx6、tx8 和 tx9。
- 第三个迭代器选择 tx5 和 tx10。
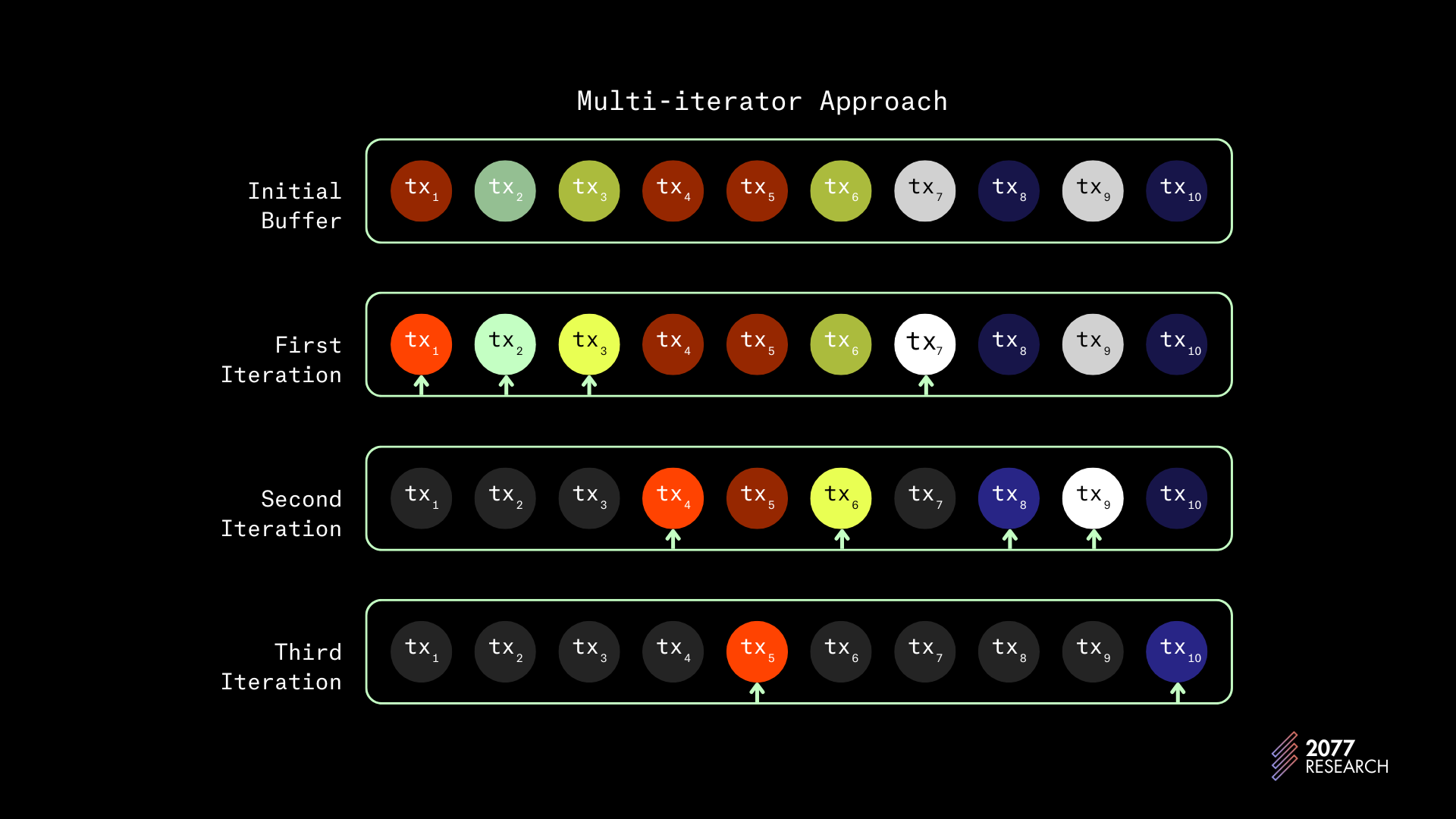
图 13:TLMI 调度 | 改编自
每个迭代器都将遵循此过程来创建批次的不冲突交易,并且由于在执行期间使用了锁,因此不论其他线程在做什么,交易都是安全执行的。
然而,这种设计带来了许多问题。
TLMI 实现中的问题
TLMI 方法的主要问题在于每个线程彼此孤立。
由于每个工作线程独立地从共享通道中提取交易,因此线程之间的交易分配大致相同。因此,即使线程创建的交易批次没有线程内冲突,线程间冲突仍然可能(并且可能发生),随着争用加剧,该问题会更严重。
此外,正因为 TLMI 的设计存在优先级反转的高倾向——由于两个冲突交易不能在批中,因此与更高优先级交易发生冲突的高优先级交易至多要等到下一批次才会被调度,而低优先级交易则会得以调度。
这些问题可以通过减少批量大小(从 128)来应对,但这会在其他地方造成瓶颈,例如增加线程的上下文切换。相反,调度算法完全重新设计,形成中央调度器实现。
中央调度器
Agave 1.18 客户端通过引入“中央调度器”来解决 Solana BankingStage 的“中央”问题,中央调度器的精神与 Block-STM 的协作调度器十分相似。中央调度器使用一个新的线程(除了之前的六个线程)来执行全局调度的任务。它工作的方式相对简单:
像以前一样,投票事务由投票线程处理,但现在所有非投票交易转到动态更新的缓冲区。由于该缓冲区直接从 SigVerify 提供,因此具有的全局优先级视图不同于 TLMI 设计中的本地缓冲区。
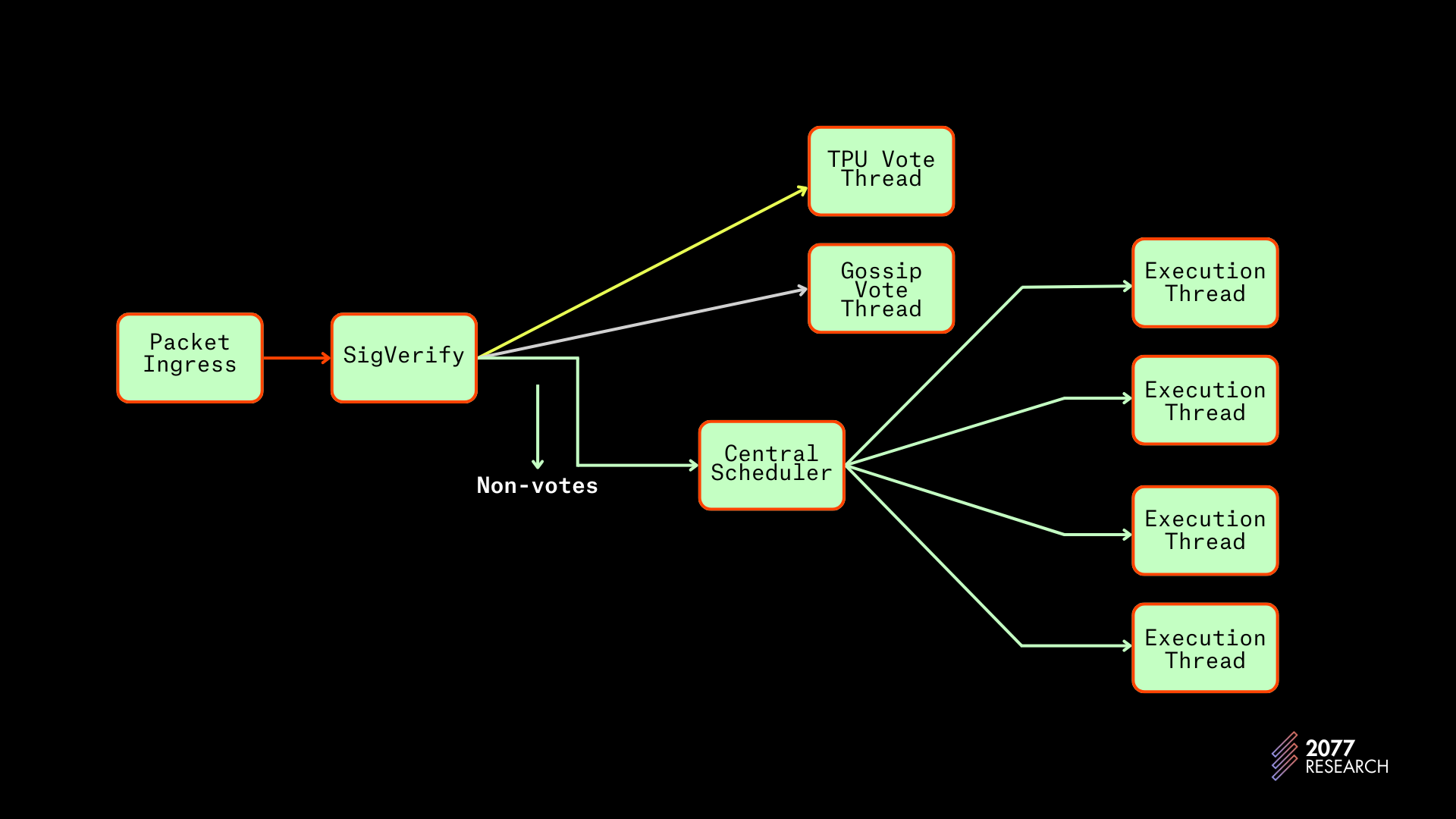
图 14:中央调度器的 Banking Stage 实现
中央调度器更新中的第二个重大变化是优先级图的增加。“优先级图” 是一个懒惰填充的有向无环图(DAG),能有效识别(和可视化)交易依赖关系。中央调度器扫描一批交易并通过将交易表示为节点、使用边(图论中的有向线)表示依赖关系来填充优先级图。
下面的图 15 显示了一个示例优先级图。节点(圆圈)表示交易,字母表示优先级(A 的优先级高于 B),数字表示交易使用的账户,箭头表示依赖。
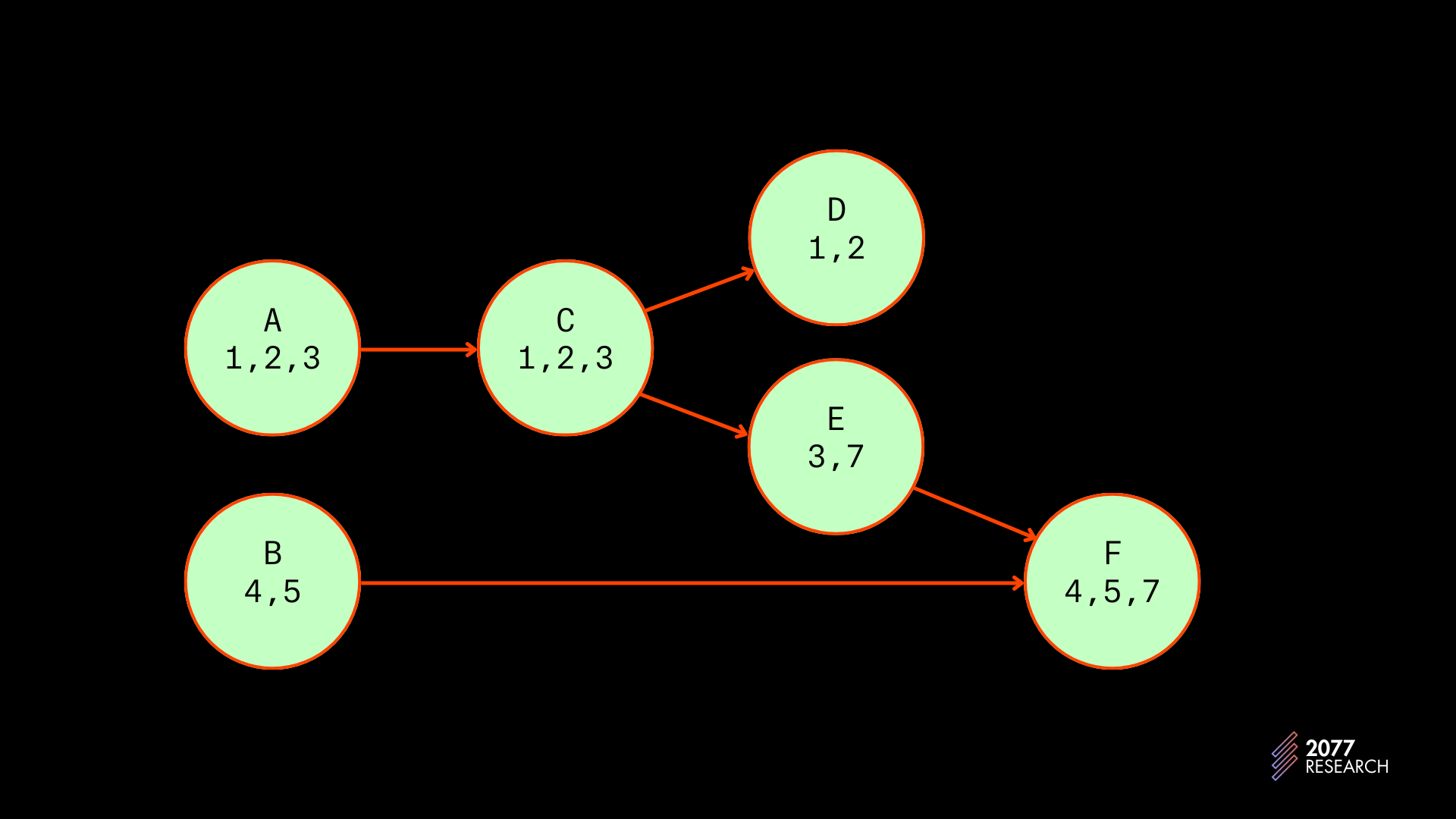
图 15:示例优先级图
在执行批量操作的情况下,优先级图是必要的。如果交易是随机(ad hoc)执行的,则无需优先级图,但由于交易是以批次执行的[1],因此需要优先级图以防止无法调度的交易。下面探讨的例子展示了问题:
假设中央调度器希望调度从 A 到 F 的所有交易,它将在一个线程中调度他们。虽然 A 和 B 不冲突,这看起来可能是无效的,但天真地下将交易调度到不同线程将导致将来出现无法调度的交易。原因如下:
如果没有优先级图调度交易(我们将通过每批两个快速移动,但这足以显示此问题):
- A 和 B 将首先在独立线程上调度,因为它们没有冲突。
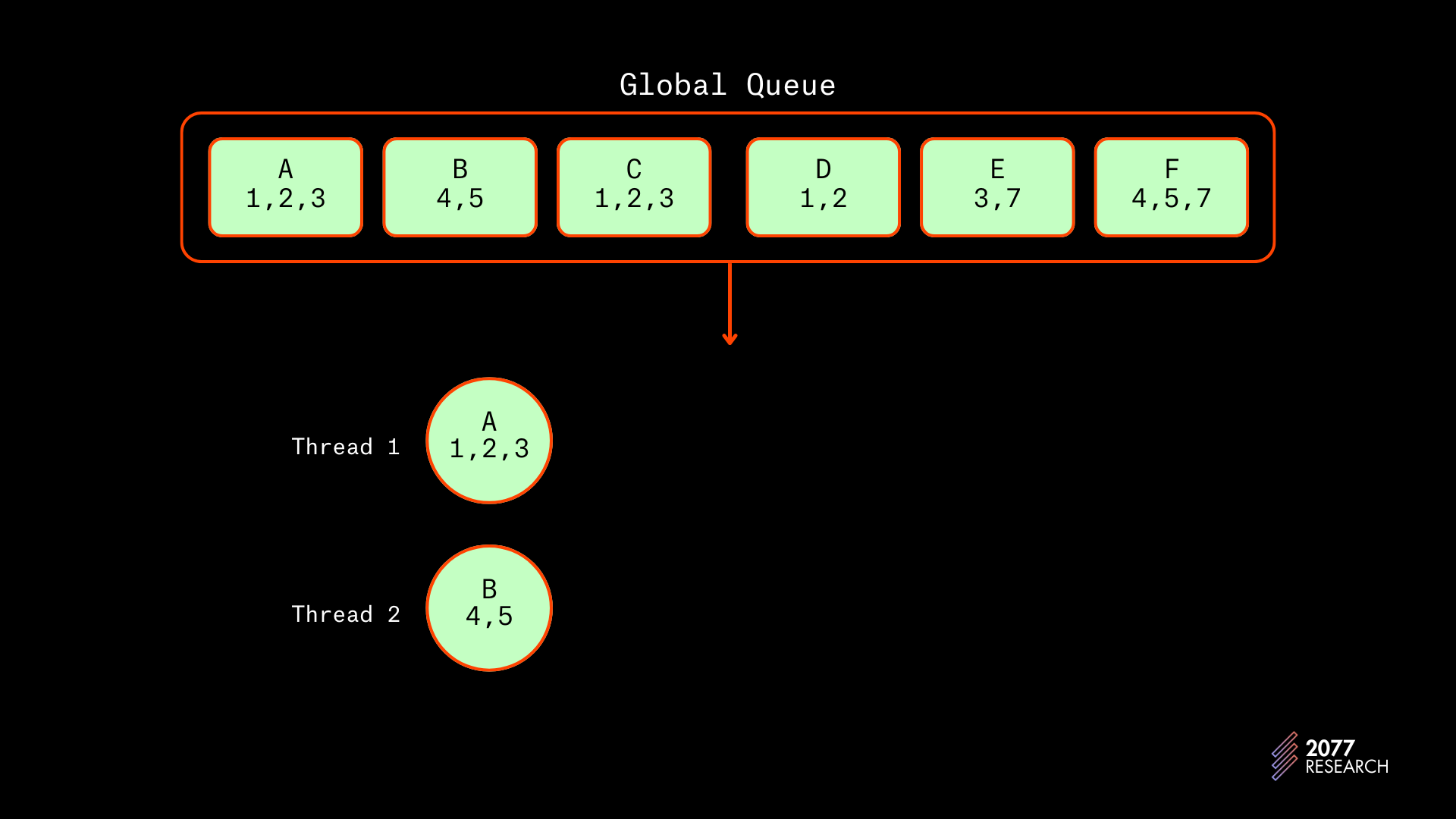
图 16:在 T1
接下来,C 和 D 将因为它们与 A 冲突而在 A 后面调度。
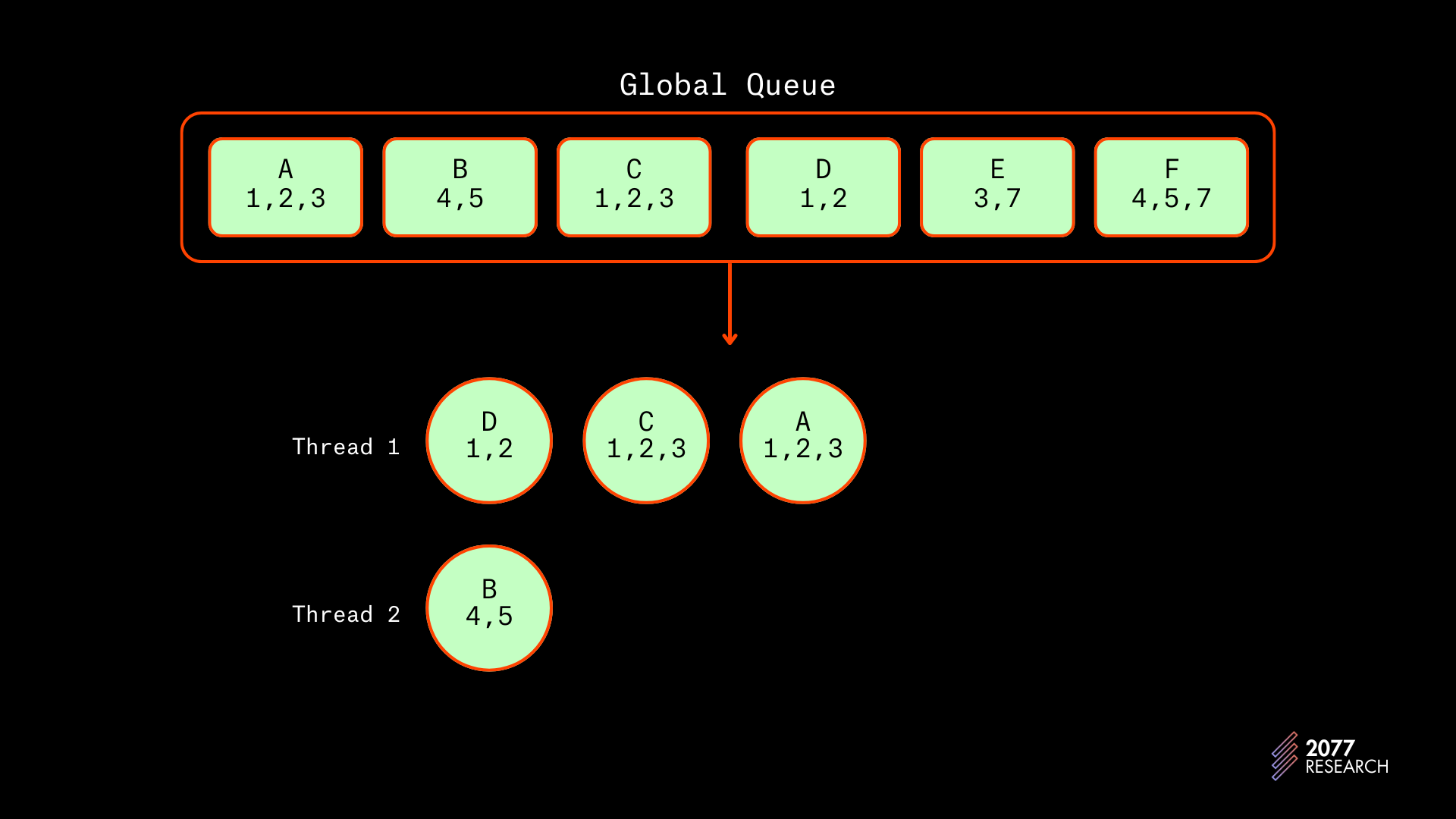
图 17:在 T2
- E 将在线程 1 上完美调度,但是 F 将因与两个线程冲突而无法调度。线程 1 持有账户 3 的锁,而线程 2 持有账户 7 的锁,因此 F 只能在两个线程完成后调度。
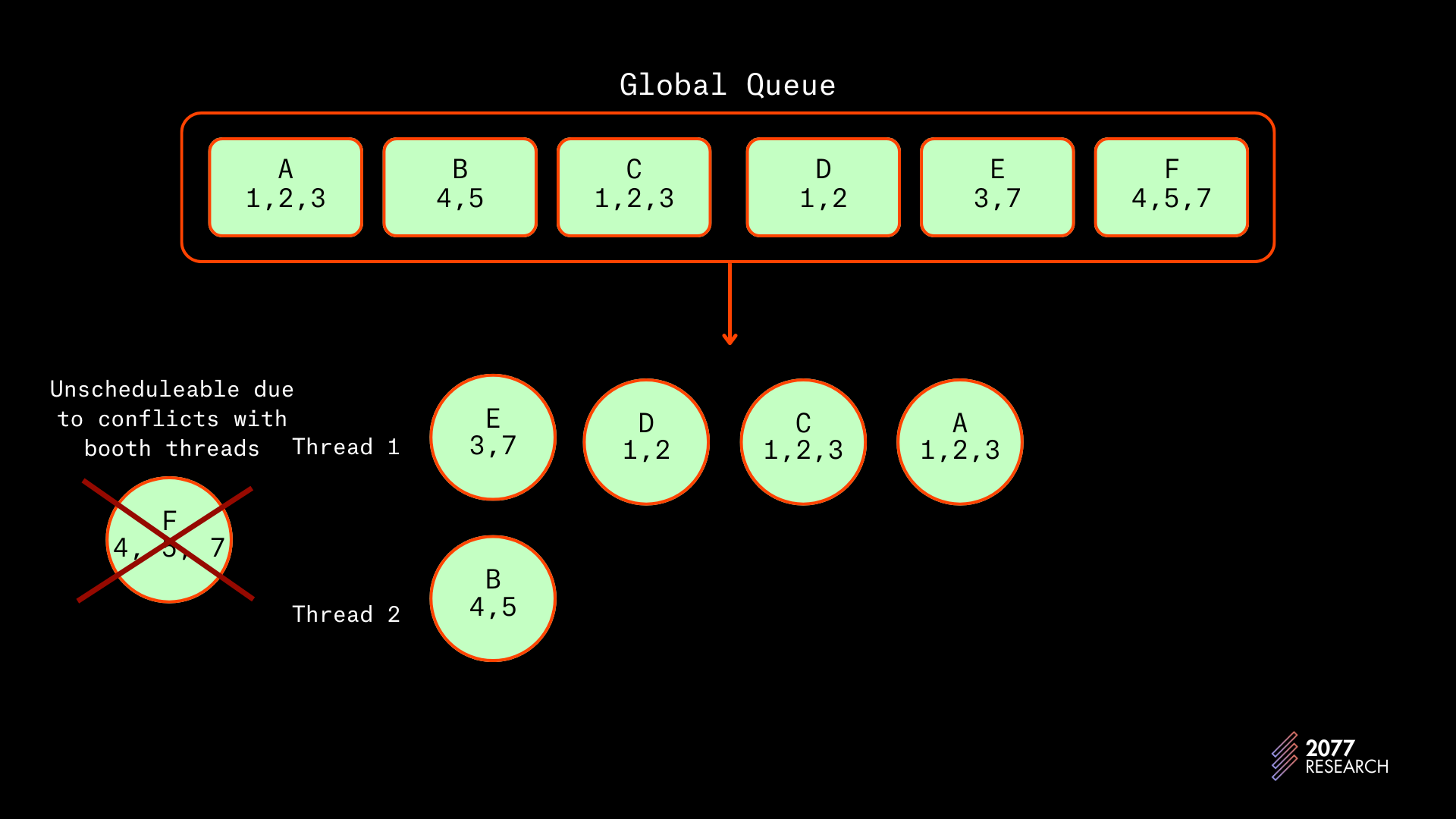
图 18:在 T3
出于这些冲突,调度器调度事务时需要优先级图。全局优先队列与优先级图的组合使中央调度器能够以避免线程间冲突的方式调度事务,并避免优先级反转。
中央调度器的工作方式
- 交易从 SigVerify 通道到达,并根据是否为投票事务进行拆分。
- 非投票交易转移到一个缓冲区,按优先级进行排序。
- 中央调度器扫描最高优先级的交易,对其进行过滤,然后将其“插入”到优先级图中,进行批量处理。
- 当达到目标大小或全局队列为空时,中央调度线程开始以避免线程间冲突的方式将交易调度到工作线程。
- 调度的交易批次将像以前一样执行。
以上是中央调度器所做工作的基本概述。现在是细节。
就像在 TLMI 实现中一样,来自 SigVerify 的交易数据包坐在同一个 700,000 容量的缓冲区中。然而,在中央调度器中,当节点是领导者时,数据包将被输入到另一个缓冲区,称为 TransactionStateContainer。TransactionStateContainer 有两个组件:
- 一个双端优先队列,特别是具有 bubble-up 功能的 MinMaxHeap,根据优先级对交易进行排序。
- 一个 HashMap,映射交易 ID 到“交易状态”。交易可以处于两种可能的状态:
- 未处理:交易可以被调度。
- 待处理:交易可供调度和处理使用。
为了创建一批交易,中央调度器从 TransactionStateContainer 中获取前 2048 个交易分组,每次 128 个,并对每批交易应用 PreGraphFilter。
PreGraphFilter:
- 将交易发送到银行,以检查交易是否已被处理。
- 检查交易是否可以支付费用,并从费用支付账户中扣除费用。
通过检查传入依赖关系,传入过滤器创建一个优先级图。优先级图是通过检查每笔交易与每个账户的下一交易的优先级依赖关系而构建的,即图构建检查该交易所接触的每个单独账户的冲突。这通过在一个 HashMap 中跟踪哪些交易最后接触了哪些账户来实现。这使得图构建者能够迅速识别依赖关系。
一旦优先级图构建完成,交易将经过一个 pre_lock_filter。pre_lock_filter 目前尚未实现,因此目前没有任何效果。但是理想的逻辑流是允许通过 pre_lock_filter 的交易逐一在适当的线程上调度。如果交易与任何线程或任何其他可能需要按序列执行链的类似交易没有冲突,它将被分配给工作量最少的线程(以 CUs 表示)。交易被调度,直到优先级图清空或每个线程:
- 达到分配给它的最大计算单元(当前为 1200 万 CUs),或者
- 分配给它批量 64 个交易。
如果满足任何条件,则工作线程开始执行该批次。当完成时,它与中央调度器线程通信,以及计划工作。这一过程不断重复,直到节点不再是领导者为止,此时银行阶段被视为结束。
我省略了提交和转发的细节,因为它们与此讨论无关,但核心理念已经讨论过。
这是中央调度器针对并行化的完整概述。从某些方面而言,这是比以前的 Sealevel 迭代的重大改进,因为它防止了内部和线程间的冲突。在 CS(其他条件相同)的情况下,应该决不会发生失效锁的获取,这也是其他各个迭代中性能降级的主要原因。此外,由于没有线程间冲突,中央调度器允许使用尽可能多的非投票线程进行执行。
中央调度器的最大权衡是调度期间产生的开销。与 Block-STM 或 TLMI 相比,它在调度交易时花费了相当多的时间,在执行时花费的时间较少。另一种权衡是,与 TLMI 不同,后者具有所有可用线程反序列化和解析交易,而现在只有一个线程(中央调度器)负责这些任务。
这结束了 CS 设计的讨论,进而触及 Solana 的 TPU。接下来,我们将查看它们的性能。
Sealevel 性能
市场上有许多 Solana 基准测试。但为了本报告的目的,我们修改了 agave 客户端代码库,并运行了“银行基准”测试。使用的 repo 的链接和重现结果的说明可以在附录中找到。测试在与评估 Block-STM 相同的机器上进行——Latitude 的 m4-metal-large,具有 384 GB 内存和 24 个物理核心以及 48 个逻辑核心的 AMD EPYC 9254 CPU。测试与用于评估 Block-STM 的测试完全相同。结果如下。
TLMI
TLMI 运行的数据在下面的图 18-21 中显示。观察到 TLMI 的最大吞吐量为 137k TPS,在 8 个线程下的区块大小为 10k且账户争用为 10k(实际上是极具平行性的)。TLMI 在高度争用的情况下相对表现良好,处理完全顺序的工作负载超过 15k TPS。
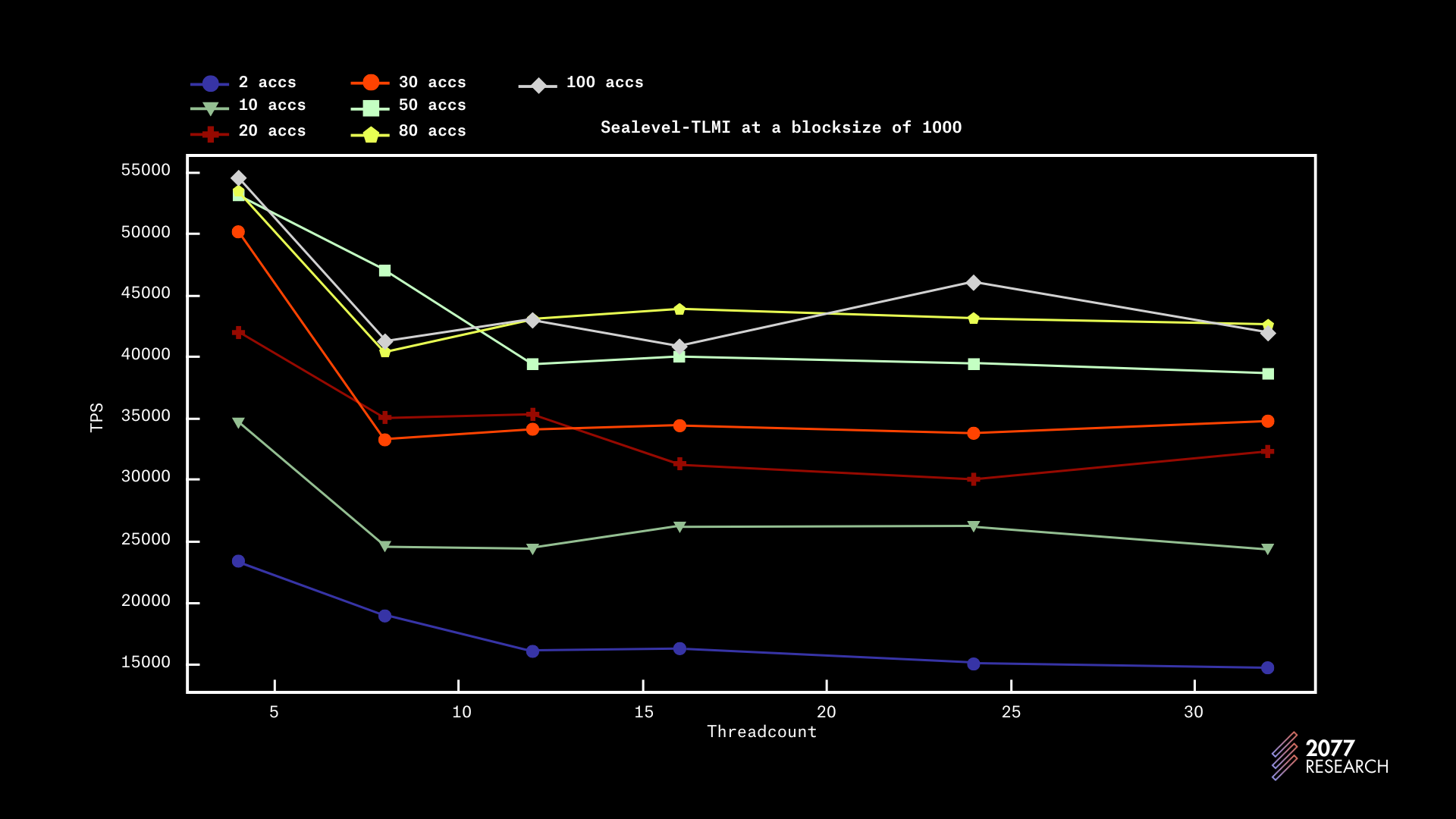
图 19:Sealevel-TLMI 性能根据线程数绘制(块大小 1000)
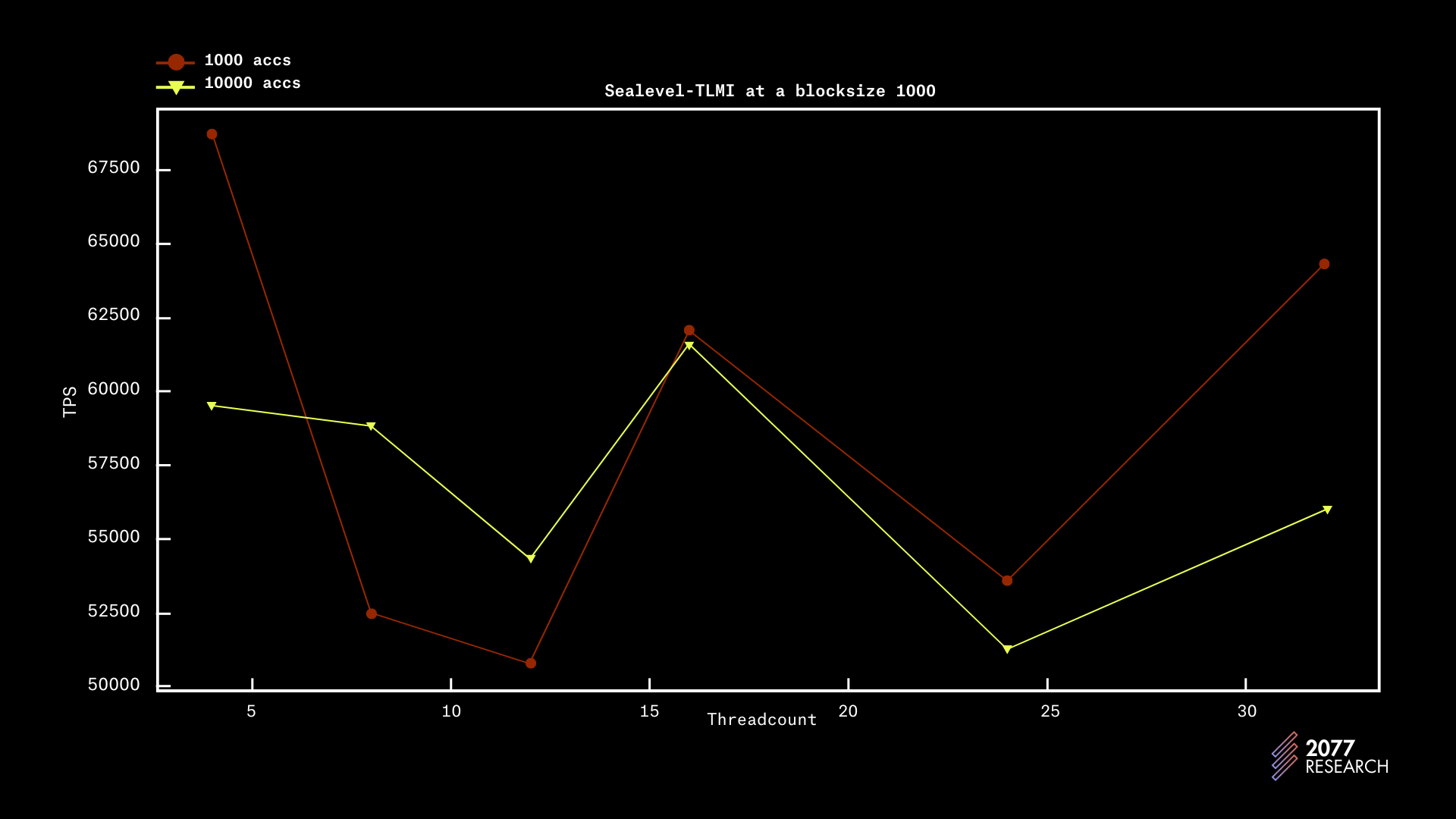
图 20:Sealevel-TLMI 性能根据线程数绘制(块大小 1000)
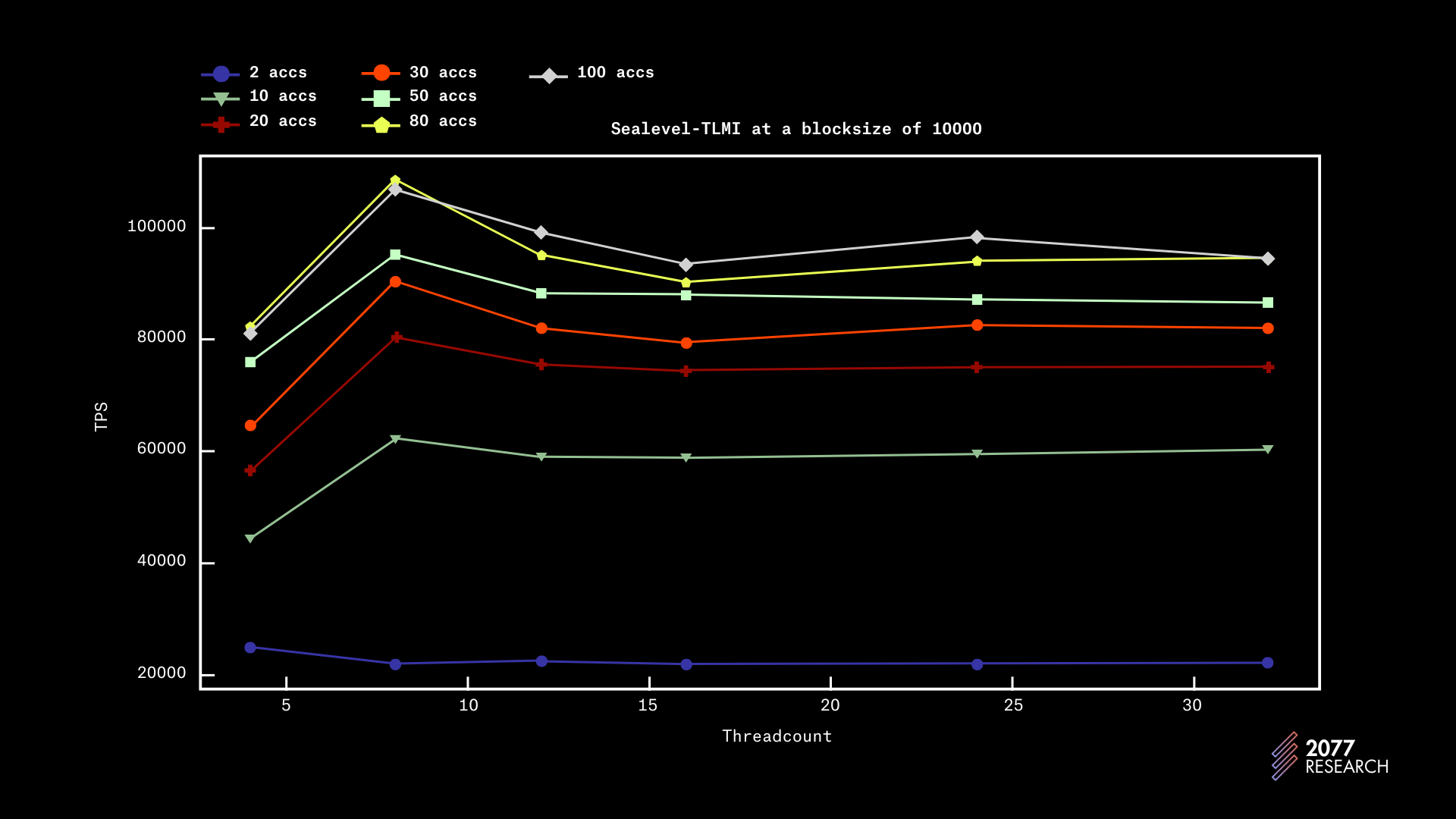
图 21:Sealevel-TLMI 性能根据线程数绘制(块大小 10000)

图 22:Sealevel-TLMI 性能根据线程数绘制(块大小 10000)
TLMI 的性能趋势相对较平坦(在账户争用为 10 时达到其最大吞吐量的约一半),即争用和非争用情况下的性能相似。这意味着 TLMI 在争用情况下不会经历显著的性能下降。
数据还包含一些令人惊讶的事实。其中之一是,在块大小为 1k 时(图 19 和 20),吞吐量在 4 个线程处达到峰值,而无论争用情况如何;在块大小为 10k(图 21 和 22)时,吞吐量始终达到 8 个线程的峰值,随着核心数量的增加,性能甚至稍微下降。
这一行为对 24 和 32 的线程数是可以理解的,因为在测试中使用的机器只有 24 个物理核心,并且后台运行着一些其他进程,例如 PoH。但对于线程数为 12 和 16 的行为却出人意料,并且与争用无关。目前没有足够的数据来断言趋势,但看起来 TLMI 的峰值吞吐量与区块大小相关。这表明在优化 TLMI 性能方面仍然有提升的空间。
但总体而言,TLMI 是一个性能优异的 TPU,在争用和非争用环境中表现良好。
中央调度器
决定排除中央调度器的性能,因为发现其结果不一致。我们的测试显示它在 10k 账户争用下最高约 107k TPS,在完全顺序工作负载下高达 70k TPS。在另一个实施的测试中,对于完全顺序的工作负载,得到 30k TPS,对于极具平行性的工作负载则约 90k TPS。
这些结果在“测试内部”是一致的,重新运行测试将产生相同的结果。但是,在各次测试间的不一致性表明,实施中仍存在需要关注的错误。因此,我们决定将评估和结果的呈现留给未来的研究。
无论如何,我们可以得出的几个结论是,中央调度器相对于 TLMI 在高度争用情况下的表现会更好,而在低争用情况下则(略)较差。
通过全面讨论 Sealevel,我们可以转到本报告的重点。
Block-STM 与 Sealevel
两者 TPU 已经被充分讨论和评估;是时候对它们进行比较了。我们将从两个 TPU 启用的手续费市场结构开始,然后转到性能。
手续费市场
合理定价区块空间是一个难以解决的挑战。更优雅地说:
“区块链协议设计中最具挑战性的问题之一是如何限制和定价被包含在链中的事务提交。”
对于手续费市场的适当讨论将填补一篇论文。但在比较 Block-STM 和 Sealevel 的主题上,提及由于两个 TPU 的设计,手续费市场结构完全不同,特别是 Sealevel 具有 伪本地 手续费市场,而 Block-STM 的手续费市场是 全局 的。在本地费用市场中,对状态部分的争夺不会影响到其他状态部分,而在全球费用市场中,区块空间的成本取决于对区块空间的总体需求,无论交易访问的是哪个状态部分。
从各个方面来看,本地费用市场显然更为理想:
- 对于用户而言,用户体验更佳,因为用户不必与访问不相关状态部分的交易进行竞争。
- 对于验证者和网络(其他条件相同),本地费用市场使区块空间的使用更加高效,因为失败的交易会更少。
简言之,本地费用市场是优越的,但它们实施起来非常困难。接下来我将解释每个 TPUs 的费用市场结构。
Block-STM 费用市场
如上所述,Block-STM 的费用市场是全球性的。讽刺的是,这反而是导致 Block-STM 性能提升的设计选择——预定义的交易排序。
在分析 Block-STM 的设计时讨论过,当 Block-STM 想要执行一批交易时,它会从内存池(或新设计中的 Quorum Store)中提取已排序的交易集并执行这批交易。因为该批交易在执行之前已经构建,并且包含在区块内的基础是基于Gas费用,因此保证包含在区块内完全依赖于Gas费用。
例如,在 NFT 发行高度竞争的情况下,优先级最高的交易正争夺同一个账户,则打包进该批交易的大部分(如果不是全部)交易将争夺同一个状态。这会:
- 显著降低 Block-STM 的性能(因为它在高争夺情境下表现不佳)。
- 阻止无冲突交易的包含,并不必要地推高区块空间的价格,这在像以太坊和其他兼容 EVM 的链等单线程 TPU 网络中尤为明显。
我们在本节中更关注后一点及其暗示——所有 Block-STM 网络上的用户将被迫相互竞争区块空间。考虑到以太坊等网络的历史数据,在高活动时间段内,区块空间的成本可能会变得不必要地高昂。在持续活动期间,所有用户的收费都会更高。这是个问题,因为这表明,BSTM 网络的区块空间必须比 Sealevel 网络便宜且更为丰富,才能让用户支付类似的费用。
Sealevel 费用市场
Sealevel 的所有版本始终具有某种形式的费用市场局部性,但由于上述原因(优先级的局部视图),这些费用市场几乎是无效的。在 中央调度器 之后,Sealevel 的费用市场功能正常并且是“伪局部”的。交易竞标的包含和优先权仅需与竞争希望访问的账户的其他交易竞标。
例如,如果交易 tx1 到 tx4 都在竞标相同的状态部分,tx5 不必与所有之前的交易竞争。在当前调度程序设计中,它将被安排在第二位,而交易 tx2 到 tx4 都在 tx1 后面排队。这个例子非常简单,但对于任何类型的交易依赖的交易批次都是适用的。
重要的是要理解,由于区块大小限制(目前为4800万计算单元(CUs)),始终存在一些区块空间的全球定价。与区块内其他交易不冲突的交易可能永远无法进入区块,仅仅因为它们的绝对优先级不够高。但一旦交易可以支付一些“最低包含费用(𝚽)”,费用市场就是局部的。
Solana 通过限制一个账户在一个区块中可以占用的最大计算单元数进一步提高了其费用市场的局部性(当前实现为1200万计算单元)。这确保了竞争高度争夺账户的交易无法阻止其他交易的包含,即使前一组交易由于某种原因执行得更快。
在这项研究中收集到的数据表明,相对于区块空间降低限制可能会带来好处,但那是另一个议题。
总之,Sealevel 隐式地使局部费用市场成为可能,并且局部性通过账户限制得到了增强。
接下来我们将转向两个 TPU 的实际吞吐量。
性能
在讨论了所有必要的背景信息后,现在是回答哪个 TPU 性能更好的问题了。图 24 和图 25 显示了不同情况下区块大小为 1k 和 10k 的两个 TPU 的性能。结果显示,Sealevel 在所有方面的表现要显著优于 Block-STM。为了便于阅读,仅显示 2、10、50 和 10000 个账户的数据,因为它们足以代表大多数场景。
图 24 显示了在 1k 区块大小下的性能,Sealevel 完全胜过 Block-STM。在完全顺序的工作负载下,性能差异约为 7 倍,而在高度可并行的工作负载下(10k accs),性能差异为 2.4 倍。
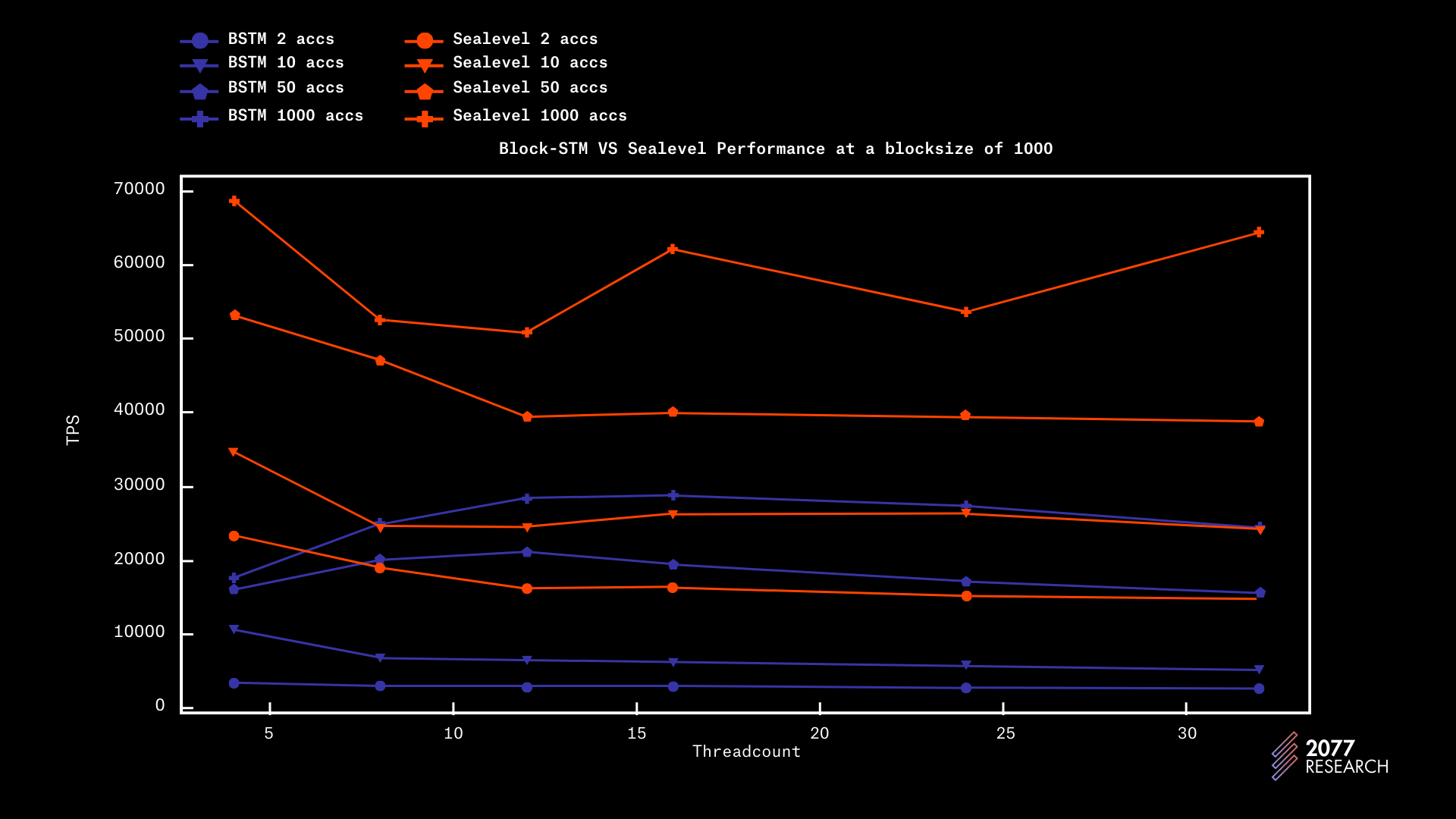
图 24: Block-STM 与 Sealevel 在 1k 区块大小下的对比
在 10k 的区块大小下,Sealevel 对 Block-STM 分别有 45%、53% 和 118% 的性能提升,账户竞争为 100、1k 和 10k。这些结果比 1k 测试要好,主要归因于之前讨论的原因。
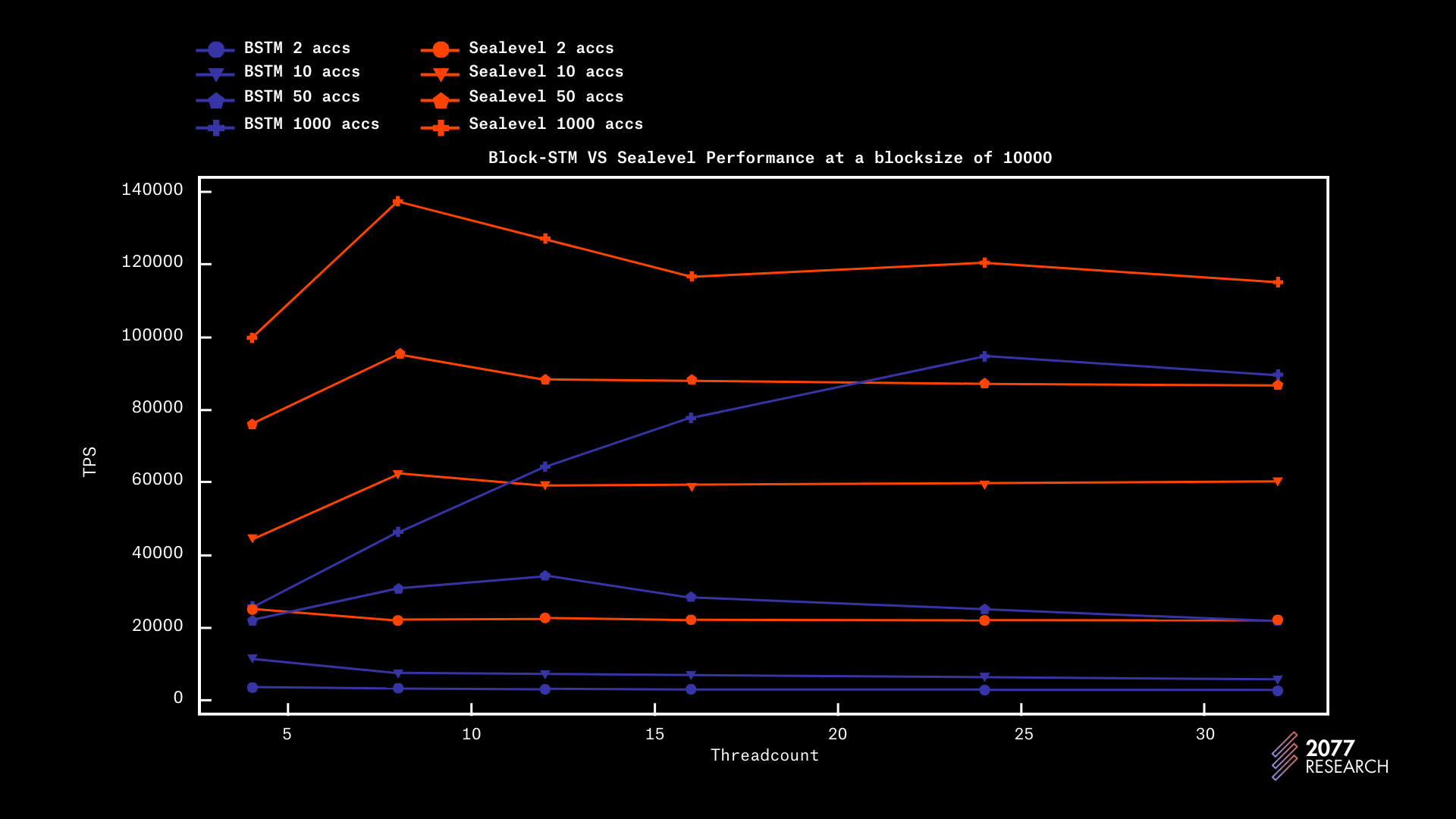
图 25: Block-STM 与 Sealevel 在 10k 区块大小下的对比
这些结果出人意料,因为多年的并发控制研究得出的结论是,OCC 非常适合低竞争的工作负载,而 PCC 适合高竞争的工作负载[2]。
从孤立状态来看,Block-STM 符合这一标准,随着竞争的降低,其性能显著提升。然而,无论竞争如何,与 Sealevel 相比,Block-STM 的表现显著落后。我们对此进行了调查,并与 Aptos Labs 的成员进行了交谈,并找到了潜在的解释。我们在下面提供了一些背景信息和我们的发现。
在测试过程中,我们使用了早期版本的 MoveVM 对 Block-STM 进行基准测试,观察到的吞吐量超过了所呈现结果的两倍(我们在区块大小: 10k、账户竞争: 10k 的情况下获得的吞吐量高达 193k TPS),而总体而言,Block-STM 在竞争密集场景中的表现要比 Sealevel 差,而在非竞争场景更优。
尽管这些测试中 Block-STM 的性能是合理的,但这些数字不能用于公正的比较,因为执行 VM 和用于获得这些数字的基础程序部分并未准备好用于生产。在与 Aptos Labs 团队讨论后,我们了解到,这一降级是由于 MoveVM 中添加的额外检查造成的。
这表明 Block-STM 的真正潜力可能受到 MoveVM 复杂性的限制。我们使用“可能”是因为,将 Block-STM 与 Diem Move 进行基准测试产生的结果与所展示的结果相似,这表明所展示的结果可能是 Block-STM 在生产就绪的虚拟机下的真实极限。
另一个可以解释性能差距的因素是,Sealevel 在批量执行交易,而 Block-STM 的执行则是按需的。按需执行带来的上下文切换增加可能会带来一些开销。
至于什么 TPU 在现实世界情况下表现更好,确实很难用一个数字描述现实世界中的竞争。然而,无论竞争如何,Block-STM 都落后得太远。然而,仅为了彻底起见,我们将简要尝试通过查看历史区块链数据及其竞争激烈程度来估算现实世界的竞争。
区块链竞争的可视化
竞争可以使用 中央调度器 用于识别交易依赖性的相同优先图可视化。在描述中央调度器时显示的优先图相对简单。真实的优先图,在图 26-33 显示的要复杂得多。以下优先图是以太坊和 Solana 区块的优先图,这两者是唯一可以准确建模竞争的数据充分的网络。

图 26: 优先图 1 | 来源
图 26 显示了 Solana 插槽 229666043 的优先图。该图包括 89 个组件(不同的交易子图)。大部分组件具有简单结构,许多没有依赖交易或具有简单的顺序依赖关系。然而,大量交易则是复杂树中的一部分。
放大以查看依赖关系,同时要记住,交易的优先级由节点的颜色指示。还要记住,交易距离 组件 的中心越远,其依赖关系越少。位于 组件 中心的节点依赖于中心向外的所有交易;在各个方向上。
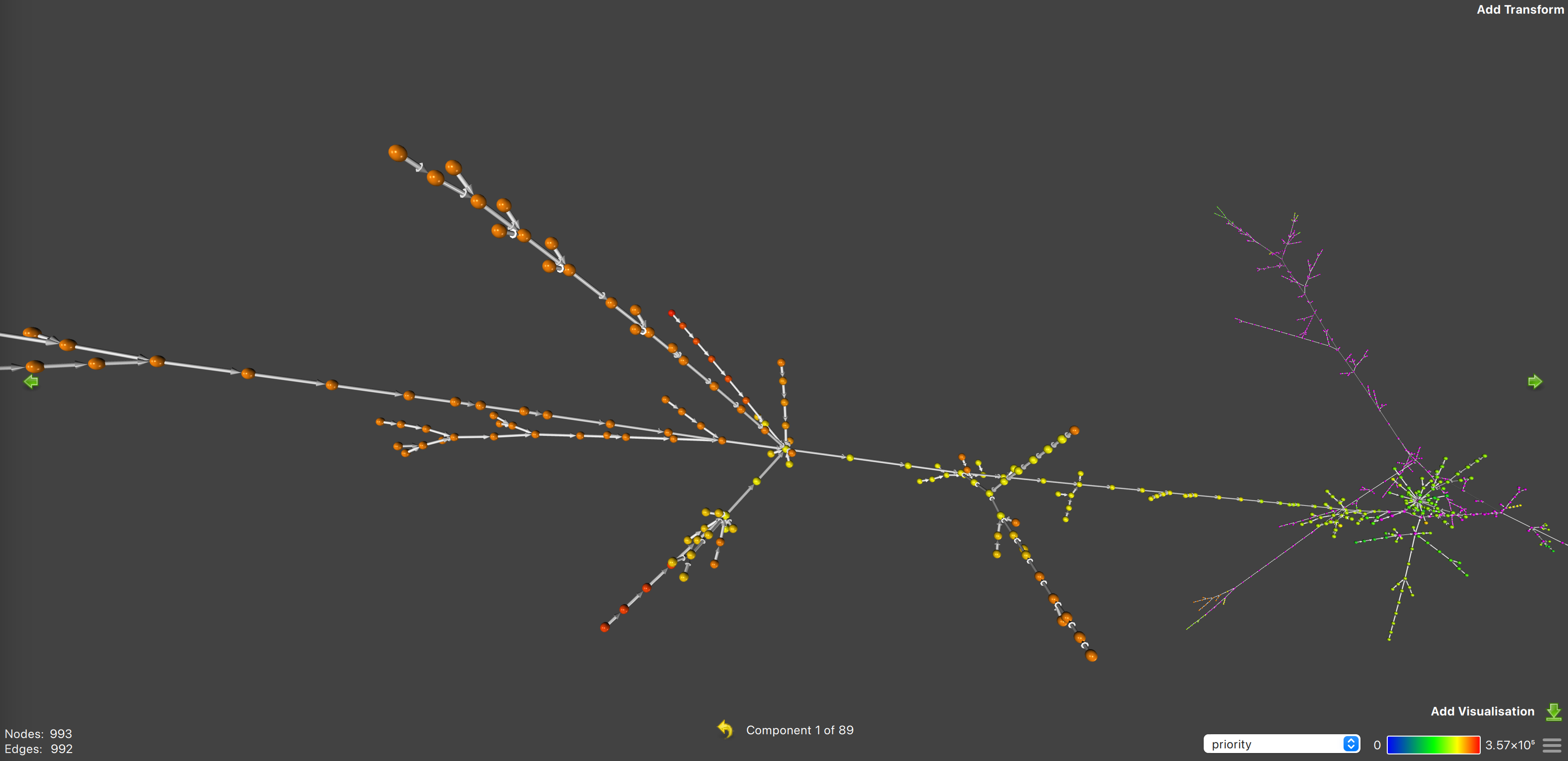
图 27: 优先图 1 的特写 | 来源
图 27 显示了最大树的更近拍摄,结构相当复杂。
上述数据表明区块链交易的竞争非常激烈——相当大的一组账户的竞争较低,但绝大多数交易则集中在非常大树的直且长的分支上。这些直且长的分支表明交易争夺同一账户,而这些树相对于较小的簇的大小则表明大多数交易是有竞争的。但更有趣的是,分支数量表明许多账户是有竞争的,而不仅仅是一小部分。
更多的优先图也讲述了相同的故事:
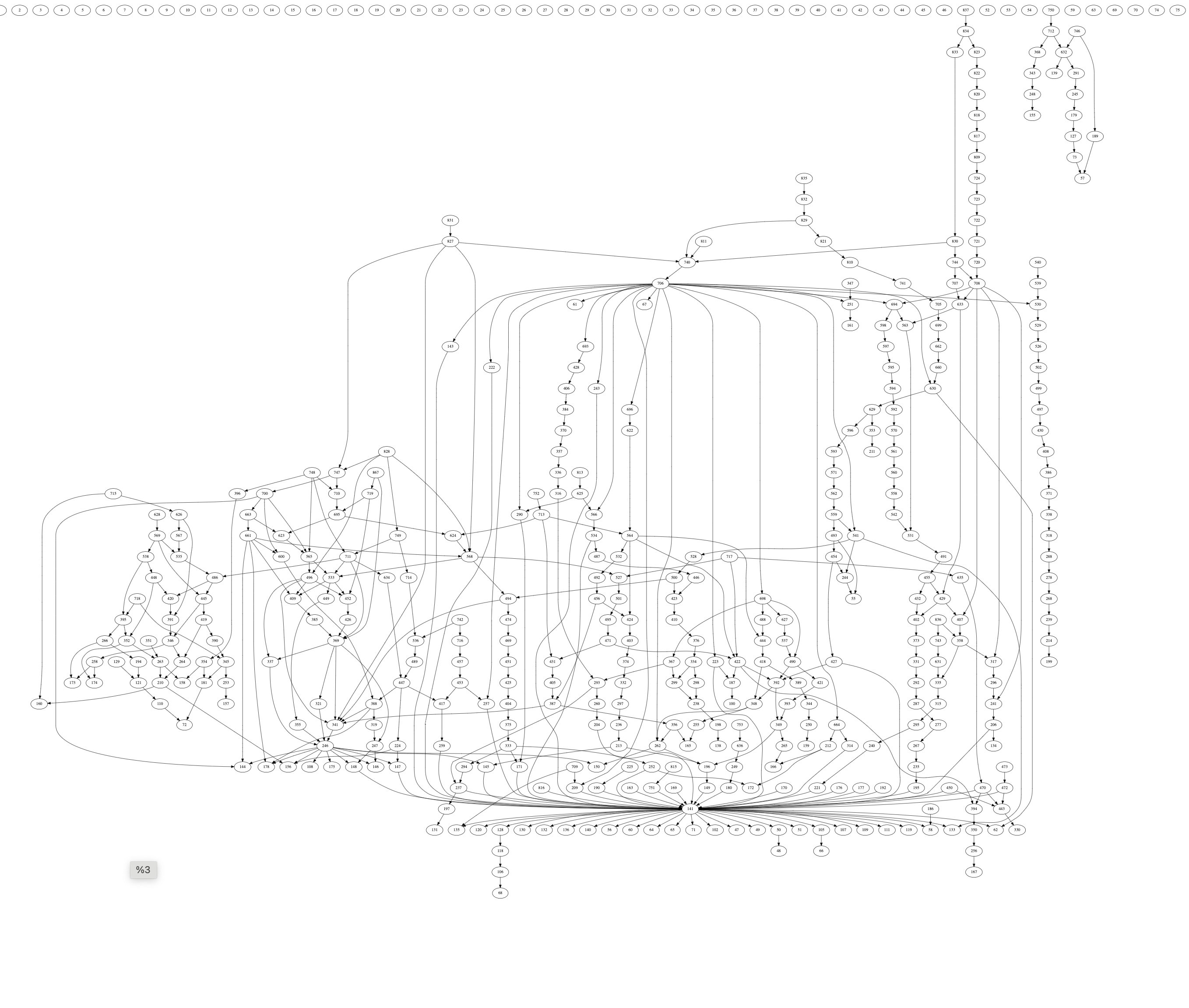
图 28: Solana 优先图 2 | 来源
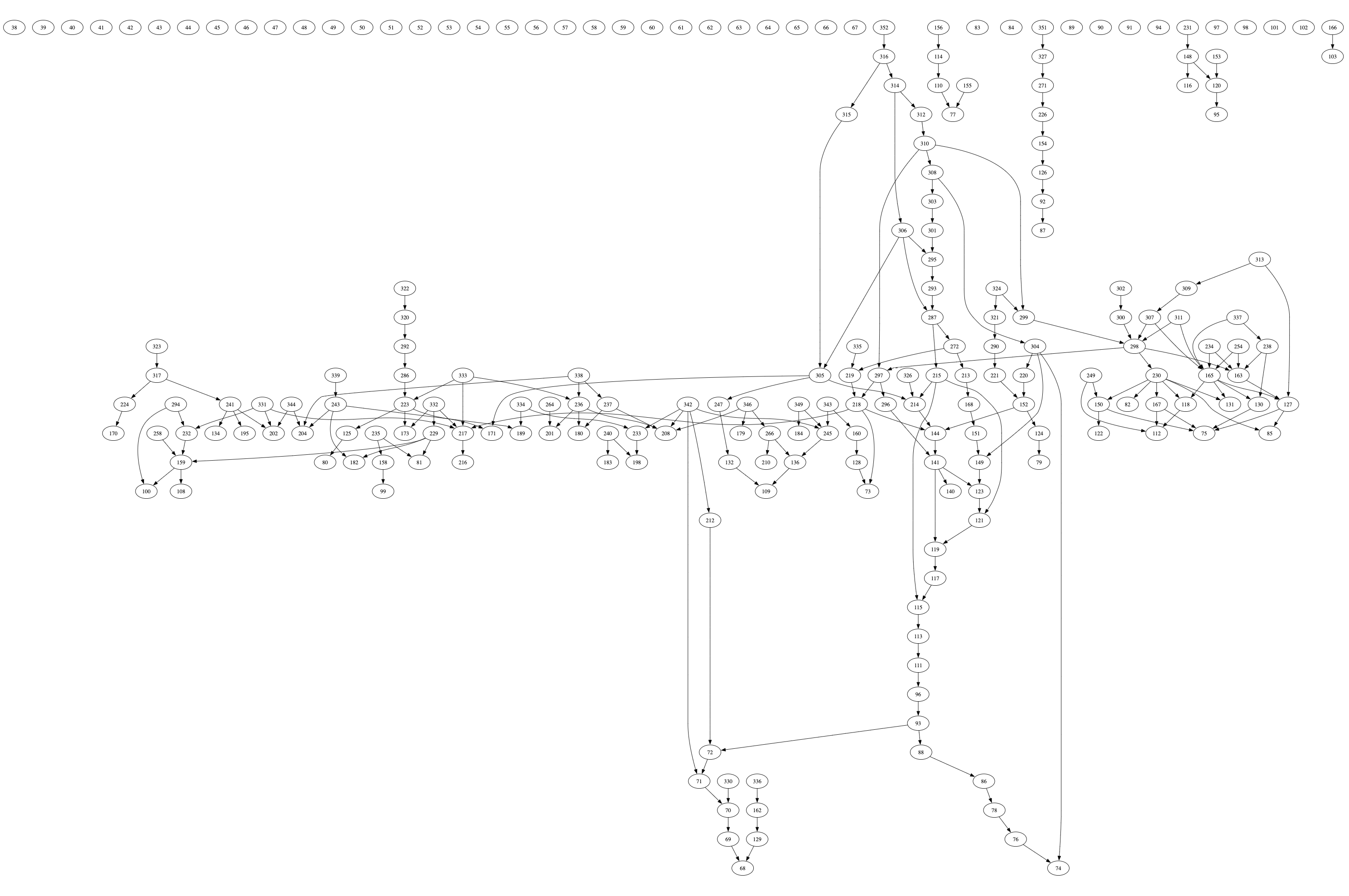
图 29: Solana 优先图 3 | 来源

图 30: 以太坊优先图 1(区块 20500428) |来源
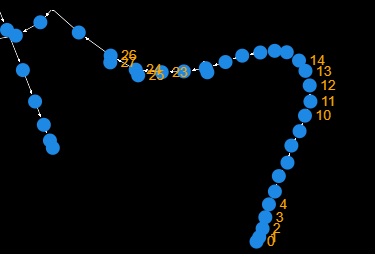
图 31: 以太坊区块 20500428 的优先图特写 |来源
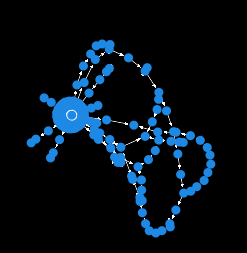
图 32: 以太坊优先图 2(区块 20500429) |[来源](https://en.wikipedia.org/wiki/Lock_\(computer_science?ref=ghost-2077.arvensis.systems))
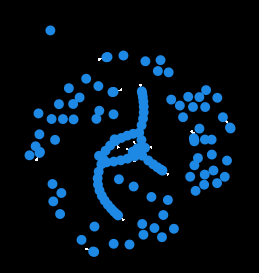
图 33: 以太坊优先图 3(区块 20500430) |[来源](https://en.wikipedia.org/wiki/Lock_\(computer_science?ref=ghost-2077.arvensis.systems))
总之,区块链上的状态访问是 非常有竞争性的。可以从数据中提取的更细致的结论是:
- 大多数高优先级交易都是针对高度争夺的状态部分
- 状态访问是有竞争的,但也是高度可并行的——有许多不同的热点(不同“温度”),而不是一个大型热点。
- 相当大的一组交易与其他交易没有竞争。这个集合相对于争夺交易的集合较小(可低至 10%),但并非微不足道。
那么,这对 Block-STM 和 Sealevel 意味着什么呢?这进一步加强了 Sealevel 在现实世界场景中表现更好的论点。“更好”的程度只有通过更复杂的模拟才能回答,但目前的数据强烈表明 Sealevel 在现实世界使用时显著更胜一筹。
综上所述,值得注意的是,尽管由于 Block-STM 的原始依赖识别和其他优化2, 3,Block-STM 的表现将远好于传统 OCC TPU。但其性能可能永远无法与 Sealevel 相匹配。
OCC 和 Block-STM 的案例
在接近本文结束时,很容易产生这样的印象,即 OCC(以及由此派生的 Block-STM)是无意义的——多年的研究和测试数据表明,在区块链这一 状态访问相对竞争激烈的环境中,它实际上肯定比 PCC 更慢。此外,Block-STM 看起来在交易费用市场(TFMs)方面是向后迈进了一步,因为它缺乏并发执行的主要优势之一——局部费用市场。然而,Block-STM 对传统 OCC 设计做出了许多改进,并将比以前的 OCC TPU 表现得更为出色。此外,Block-STM 设计还有三个值得注意的额外优点。
支持应用的更广泛范围
OCC-TPU 的主要优点在于它允许任意的事务逻辑。由于 PCC-TPUs 要求交易在前期声明它们将访问的内存部分,因此不可能编写事务逻辑,让交易根据执行过程中发现的信息来决定读取或写入某些内存位置。
一个很好的例子是链上订单簿设计。PCC-TPUs 上的订单簿通常无法提供原子结算(或无需许可的市场做市)和限价订单,因为交易必须提前指定在交易过程中将访问的账户。为解决这个问题,Solana 上的大多数订单簿需要依赖一个额外的实体——操作员——来完成限价订单。而 Solana 上的 Phoenix 已设法通过单个账户持有所有数字资产来克服这一难题,但这种方式也面临着自身的挑战。像 Aptos 这样的 OCC TPU 订单簿。
图 34: SEI 论坛讨论 OCC(Block-STM)采用的截图 | 来源
可移植性
支持 Block-STM 的最终论据是,即使与现有交易保持兼容,也可以将其整合到任何区块链中。在以太坊上,曾尝试让交易选择性地提前指定它们将访问的状态部分,以提高 EVM 的效率,但这些尝试从未实现。由于 Block-STM 的性质,能够在不破坏共识的情况下(无需许可)集成到任何区块链中。即使 Solana 客户端也能在不需要正式提案的情况下对区块进行修改以实现 Block-STM 的整合。这正是 Monad 和所有其他并行 EVM 选择使用 Block-STM 来实现 EVM 功能并行化的原因。
基于这些原因——任意事务逻辑、改善的开发者体验和可移植性——OCC 执行引擎值得至少进行探索。
结论
在本论文的过程中,我们考虑了两种改进区块链执行的对立范式:乐观并发控制(OCC)和悲观并发控制(PCC),通过审视两种范式的主要实现。这两种设计(Block-STM 和 Sealevel)都是非常创新的,毫无疑问,相较于顺序 TPU 而言,它们使用硬件的方式更为高效。
Block-STM 使用 OCC 和 dDB 设计的见解,在不牺牲开发者体验的情况下提高了并发性。Sealevel 则依赖于已有的基于锁的技术和硬件最大化设计,通过降低某些用例和更加困难的开发者体验来提高性能。
总体而言,Block-STM 和 Sealevel 都是顺序 TPU 的巨大发展,并为区块链 TPU 设立了新标准。在当前的背景下,由于存在其他瓶颈,它们的价值很难被重视,但随着区块链管道的其他组成部分不断改进,TPU 的重要性将变得愈发明显。
参考文献
- 并发控制
- DBMS中的并发控制 - GeeksforGeeks
- 多版本并发控制
- 数据库事务
- 数据库事务调度
- [锁(计算机科学)](https://en.wikipedia.org/wiki/Lock_\(computer_science?ref=ghost-2077.arvensis.systems)
- 两阶段锁定
- 保守两阶段锁定
- 分布式数据库系统中的确定性事务执行 | 指南书
- 死锁
- Solana 账户模型 | Solana
- Solana 验证者教育 - 交易生命周期
- 程序 | Solana
- 交易与指令 | Solana
- Solana 指令源代码
- 深入了解 Solana 交易
- Lollipop: SVM Rollups on Solana 版本: 0.1.0
- 交易确认与过期 | Solana
- Solana 验证者教育 - 交易生命周期
- Solana 交易生命周期 | Umbra Research
- Sealevel — 数千个智能合约的并行处理
- 聚光灯:Solana 的调度器
- 介绍中央调度器:Agave v1.18 的可选功能 - Anza
- Solana 的交易调度器有何新动态?
- Solana 调度器
- 你需要了解的 Solana v1.18 更新
- Solana 核心银行阶段源代码
- 交易确认
- 聚光灯:Solana 的调度器
- 介绍中央调度器:Agave v1.18 的可选功能 - Anza
- Solana 的交易调度器有何新动态?
- Solana 调度器
- 你需要了解的 Solana v1.18 更新
- Solana 核心银行阶段源代码
- 交易确认
- Aptos 优势:以规模移动 | Blockworks 研究
- 订单 | Econia 文档
- 座位 | Phoenix DEX
- Aptos 生态系统以并行性引领潮流
- 以太坊改进提案(EIP)第648号
- 多维区块链费用市场的设计
- 多维区块链费用(基本上)是最优的
- 并行虚拟机
- Avalanche 开发文档:无极限创造
- 执行 - Solana 虚拟机 (SVM) | Eclipse 文档
- 虚拟机简介 - 第1部分 2020年4月13日在线课程的Zoom录音
- 用Rust构建虚拟机指令集
- JVM(Java虚拟机)架构 - 教程
- arxiv.org
- Agave 运行时
- edgar 在 Twitter / X 上的帖子
- 什么是 eBPF?(扩展伯克利数据包过滤器)
- eBPF 解释:为何对可观察性至关重要
- 什么是 eBPF?eBPF技术的介绍与深度剖析
- 我们信任 Rust - 伯克利数据包过滤器与 Rust
- 分布式数据库
- 分区(数据库)
- 什么是 ACID 事务?
- 非常容易并行
- IPv6 数据包
- 在 8085 微处理器中的分支指令 - GeeksforGeeks
- 单指令多数据
- SIMD 编程基础
- 计算机体系结构中的指令类型 | GATE 笔记
- 线程(计算)
- CPU 核心与线程之间的区别
- 定义多线程术语(多线程编程指南)
- 汇编语言
- 优化调度器性能:加速数据包到事务的转换
- 序列化
- 最小-最大堆
- 有向无环图
- 通道(编程)
- 频率扩展
- 工作窃取
- 术语 | Solana
- [在区块链中,“状态”和“状态变化”是什么意思?](https://www.nervos.org/knowledge-base/state_and_state_change_\(explainCKBot?ref=ghost-2077.arvensis.systems)
- 线程与锁(PDF)
- 延迟执行 | Monad
论文参考文献
- Maurice Herlihy 和 J. Eliot B. Moss. 事务性内存:对无锁数据结构的架构支持. 第20届国际计算机体系结构年会(ISCA '93)会议论文,卷21,期2,1993年5月。
- 数据库管理系统中的乐观与悲观并发控制机制
测试的仓库
行话
CPU 架构
本节将提供报告中出现的计算机硬件术语的具体定义:
- CPU 核心本质上就是一颗独立的 CPU。它拥有所有必要组件,可以被视为完整的 CPU,能够自己执行任务。大多数现代 CPU 芯片有多个核心,共享内存和 I/O 硬件。
- 线程是一种抽象,它大致指由 CPU 核心执行的一系列指令。
- 多线程是通过多个线程执行程序(而不是交易)。
- 超线程技术允许 CPU 核心伪同时执行两个线程。内核在两个线程之间共享其资源,以提高并行性,但这并不意味着会带来通常暗示的 2 倍性能。
- 并行与并发
- 并行程序使用多个 CPU 核心,每个核心独立执行任务。另一方面,并发使程序能够处理多个任务,即使在单个 CPU 核心上;核心在任务(即线程)之间切换,而不必一定完成每一个任务。一个程序可以具有并行性、并发性或两者结合的特征。
- 并发着眼于使用一个资源高效管理多个任务,而并行性则利用多个资源同时执行任务,从而加速过程。
- 并发是指两个或多个任务可以在重叠的时间段内开始、运行和完成。它不一定意味着它们会同时运行。例如,在单核心机器上进行多任务处理。并行性是任务在同一时刻实际上运行,例如,在多核处理器上。现在应该清楚,为什么区块链中的事务处理更像是并发处理而不是并行处理。
- 其他术语
- 指令:指令是处理器可以执行的最细粒度操作。它们的复杂性可能因计算机的指令集架构而异,但理论上,指令由硬件设计保证是原子的。
- 字节码:字节码是一种类似汇编代码的中间表示。在该上下文中,它指的是虚拟机的指令集。
- 汇编语言:汇编语言是一种低级语言,其构造与底层 CPU 的指令集映射为 1:1。
- 锁的粒度:指的是锁的精确程度。假设一个事务需要更改表中的一个元素;粗粒度锁可能锁定整个表;更精细的锁可能仅锁定感兴趣的行/列;而非常精细的锁只能锁定特定的单元格。锁的粒度越细,越能实现并发内存访问,但高粒度锁更难管理,因为它们需要更大的键值数据库来管理内存的各个部分。
- 优先级反转:指的是较低优先级的进程(阅读:事务)阻止较高优先级进程的执行。
- 车队效应:车队效应发生在同一优先级的线程竞争访问共享资源时。每当一个线程放弃对资源的访问并暂停或停止进程时,都将承担一定的开销。
- 死锁:一种现象,其中两个或多个进程无法推进,因为每个进程都需要另一个持有的资源。
- 插槽:插槽是 Solana 对区块时间的术语,目前约为 400 毫秒。节点在成为领头节点时会获得四个连续的插槽。
- 纪元:在 Solana 中,纪元是432,000个连续插槽的独特区块。并非任何432,000个插槽,而是像一周的天数那样的独特区块。
- 序列化:将数据(如数据结构和对象)转换为位字符串的过程,以便能够根据该格式存储、传输和重建。
- 反序列化:从位字符串中重建序列化数据为原始数据结构或对象的过程。
- 缓冲区:缓冲区是一种临时存储元件。通常在数据无法或不应按照其输入速率处理到下一个处理区块时使用。
- 数据包:数据包是由分组交换网络传输的固定大小数据单元。数据包与 Solana 相关,因为每笔交易的大小受到最大 IPv6 数据包大小的限制。
- 双端队列:也称为双向队列,是一种抽象数据结构,支持在一端添加数据,另一端移除。
- 通道:高性能 I/O 装置。
- B-tree:自平衡数据结构。
- 哈希映射:高效的关联数组数据结构。
- 竞争条件:发生在无法控制的进程导致错误或不一致结果时。在本文中,竞争条件出现在 OCC 系统中。## 附录
A1: 分布式数据库
分布式数据库与区块链非常相似,事实上,说它们在根本上是相同的并不为过。分布式数据库是多个互联数据库的集合,这些数据库分布在不同的物理位置,通过网络相连。这些数据库对用户而言看起来像一个单一的数据库,但实际上在多个服务器上运行。
分布式数据库的主题非常广泛,因此我将(简要)仅讨论与本报告相关的领域:数据分发方法和数据库事务。
数据分发方法
- 水平分区:每个站点存储表中行的不同子集。例如,客户表可能会被分割,以便前 X 条记录存储在一个数据库中,而其他记录存储在其他地方。
- 垂直分区:每个站点存储表的不同列。例如,一个站点可能存储客户的姓名和地址,而另一个站点存储他们的购买记录。
- 复制:整个数据库(或子集)的副本存储在多个站点。这提高了数据的可用性和可靠性,但可能引入一致性挑战。
事务
在数据库管理系统(DBMS)中,事务被定义为执行逻辑操作的单个操作单元,通常访问和/或修改数据库。对于大多数数据库,尤其是那些跟踪财务记录的数据库,事务必须满足 ACID 属性,即事务是:
- 原子性:所有或没有,如果一个操作失败,则整个事务回滚
- 一致性:事务以可预测和可重复的方式修改数据库
- 隔离性:当多个事务并发执行时,它们之间不会互相影响,就像是顺序执行一样
- 持久性:已完成事务所做的更改是永久性的,即使在系统故障的情况下。
如果这还不够明显,区块链实际上就是有对抗操作员的复制数据库。因此,分布式数据库的研究构成了今天大多数区块链设计的基础。

A2: Narwhal 和 Quorum Store TLDR
Narwhal(以及 Quorum Store)的价值主张是“基于领导者的共识”,即一个共识系统,在该系统中,某个时隙的领导者负责在该时隙期间传输大部分信息(类似于 Solana),这种方式受限于领导者的性能,而不是整个验证者集。Narwhal(和 Quorum Store)通过将数据传播和共识解耦到硬件级别来解决这一瓶颈。这个想法的实现将工作均等分配给所有验证者,而不是让领导者独自承担重负。
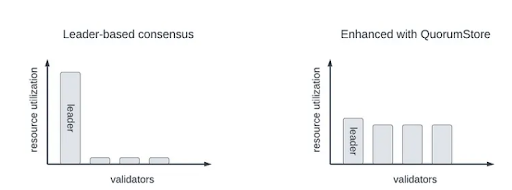
图 A2.1: 基于领导者的共识与 Quorum Store 中的带宽利用率 来源
也许没有比 Solana 本身更好的 Narwhal 价值证明。Solana 的文档目前建议验证者使用专用的 1 Gbit/s 线路作为最小带宽配置,理想情况下使用 10 Gbit 的线路。中型规模的验证者报告在领导者时隙期间的峰值流量约为 1.5 Gbit/s,而相比之下 Aptos 节点运行商报告使用 25 Mbps。当然,这两个链处理的流量远不相同,并且每个验证者的股权权重问题也存在,但大体思路是 Quorum Store 从领导者的角度来看比“基于领导者的共识”更有效。让我们来看看它是如何工作的。
在 Quorum Store 中,验证者不断地将有序事务的批次(类似于上述讨论的区块)传输给彼此。这些批次包含原始事务数据和元数据(批次标识符)。其他验证者接收这些批次,签署批次,并将签名传输给其他验证者,就像它们在“基于领导者的共识”中执行的正常区块一样。当一个批次达到权重签名的法定数量时,它实际上获得了可用性证明,因为所有签署该批次的验证者承诺保留并在要求时提供该批次,直到它“过期”。
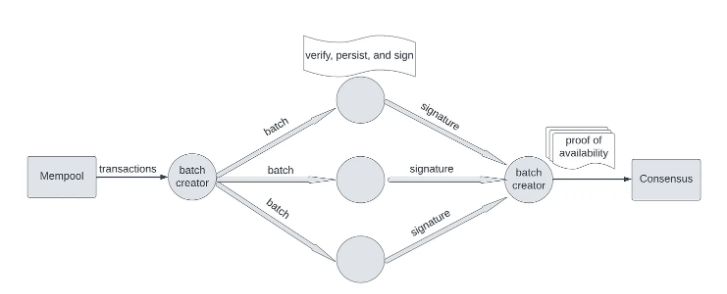
图 A2.2 插图
因为 Quorum Store,领导者不再需要提议事务批次。相反,领导者简单地选择一个拥有可用性证明的批次,发送批次元数据,执行区块,并发送执行结果。其他验证者随后可以将元数据映射到该批次并重放该批次以进行验证。如果他们没有该批次,可以向其他节点请求,并可以确信他们会收到,因为 2f + 1 个节点承诺存储和提供该数据。这减少了领导者的消息开销。而由于 Quorum Store 在单独的机器上运行,因此通过增加更多设备进行水平扩展。
我的 TLDR 遗漏了很多细节;你可以在 Aptos 博客帖子 和 Narwhal 论文 中找到更多细节。
A3: Block-STM 算法
本节包含论文中的 Block-STM 算法及其解释性注释,以帮助理解。
// 该块检查执行是否完成,如果完成,则结束程序,如果没有:
// 它检查是否有任务,并根据任务的类型执行操作
// 如果没有任务,它会调用调度器为其分配任务。
1: procedure run()
2: task ← ⊥ // ⊥ 是空值的伪代码
3: while ¬Scheduler.done() do // ¬ 是“不是”的伪代码
4: if task ≠ ⊥ ∧ task.kind = EXECUTION_TASK then
5: task ← try_execute(task.version) ⊲ 返回一个验证任务,或 ⊥
6: if task ≠ ⊥ ∧ task.kind = VALIDATION_TASK then
7: task ← needs_reexecution(task.version) ⊲ 返回一个重新执行任务,或 ⊥
8: if task = ⊥ then
9: task ← Scheduler.next_task()
// 这个块尝试执行一个事务版本
// 第 13 行检查事务是否没有读取任何估计值
// 第 14 行尝试添加依赖关系,如果失败则重试事务
// 第 18 行调用将稍后介绍的 MVMemory 模块
// 但 MVMemory.record 函数将读集和写集写入数据结构
// 然后返回一个布尔值,指示事务版本是否写入了新位置
10: function try_execute(version) ⊲ 返回一个验证任务,或 ⊥
11: (txn_idx, incarnation_number) ← version // 将版本解包成组件
12: vm_result ← VM.execute(txn_idx) ⊲ VM 执行结果没有写入共享内存
13: if vm_result.status = READ_ERROR then
14: if ¬Scheduler.add_dependency(txn_idx, vm_result.blocking_txn_idx) then
15: return try_execute(version) ⊲ 依赖已在此情况下解决,重新执行
16: return ⊥
17: else
18: wrote_new_location ← MVMemory.record(version, vm_result.read_set, vm_result.write_set)
19: return Scheduler.finish_execution(txn_idx, incarnation_number, wrote_new_location)
// 该块检查事务是否需要重新执行,并返回重新执行的任务,或 ⊥
// 第 23 行定义一个事务版本被视为中止的条件
// 该事务的读集必须无效且调度器中止的尝试必须为真
20: function needs_reexecution(version)
21: (txn_idx, incarnation_number) ← version
22: read_set_valid ← MVMemory.validate_read_set(txn_idx)
23: aborted ← ¬read_set_valid ∧ Scheduler.try_validation_abort(txn_idx, incarnation_number)
24: if aborted then
25: MVMemory.convert_writes_to_estimates(txn_idx)
26: return Scheduler.finish_validation(txn_idx, aborted)
// 定义原子变量
原子变量: data ← Map, 初始为空 ⊲ (位置, txn_idx)
last_written_locations ← Array(BLOCK.size(), {}) ⊲ txn_idx 到其最后完成执行中写入的内存位置的集合
last_read_set ← Array(BLOCK.size(), {}) ⊲ txn_idx 到其最后完成执行中读取的 (位置, 版本) 对的集合。
// data 是 MV 数据结构,即将 (位置, 事务索引) 对映射到 (实例编号, 值) 对或 ESTIMATE 标记
// 后两行描述创建抽象数据结构,以保存事务 ID 到最后写入内存位置的映射以及
// txn id 到该版本读的内存位置的对。
// 过程本质上是一个不返回任何值的函数
// 该块迭代写集中的每个位置-值对,并将其存储在多版本数据结构中
27: procedure apply_write_set(txn_index, incarnation_number, write_set)
28: for every (location, value) ∈ write_set do
29: data[(location, txn_idx)] ← (incarnation_number, value) ⊲ 存储在多版本数据结构中
// 读取-拷贝-更新变量来保存事务的最后写集
30: function rcu_update_written_locations(txn_index, new_locations)
31: prev_locations ← last_written_locations[txn_idx] ⊲ 原子加载(RCU 读)
32: for every unwritten_location ∈ prev_locations \\ new_locations do
33: data.remove((unwritten_location, txn_idx)) ⊲ 删除未被覆盖的条目
34: last_written_locations[txn_idx] ← new_locations ⊲ 原子存储新写入的位置(RCU 更新)
35: return new_locations \\ prev_locations ≠ {} ⊲ 最后一次是否有写入未写入的位置?
// 解包最后写入的位置到先前的位置
// 确定包含在新位置而不在先前位置中的元素的集合
// 对于该实例没有写入的每个位置,
// 从写集中移除该位置
// 这一整块字面意思就是查找未在新实例中写入的旧写入位置并将其删除
// 它还返回一个布尔值以确认是否存在写入事件发生在此时未写入的位置。
// 第 35 行中的 \\ 符号是集合差异。该行检查集合差异是否为空
// 该块记录版本到多版本数据结构中
36: function record(version, read_set, write_set)
37: (txn_idx, incarnation_number) ← version
38: apply_write_set(txn_idx, incarnation_number, write_set) // 过程调用
39: new_locations ← {location | (location, ★) ∈ write_set} ⊲ 提取新写入的的位置
40: wrote_new_location ← rcu_update_written_locations(txn_idx, new_locations) // 检查是否写入新位置
41: last_read_set[txn_idx] ← read_set ⊲ 原子存储读集(RCU 更新)
42: return wrote_new_location
// 调用 apply_write_set 过程,将写集数据存储在多版本数据结构中
// 提取由前一个实例写入的未写入的位置
// 解包 rcu_update_written_location 函数,它返回布尔值但也更新写入事务的集合
// 存储读集
// 返回 wrote_new_location 布尔值的值
43: procedure convert_writes_to_estimates(txn_idx)
44: prev_locations ← last_written_locations[txn_idx] ⊲ 原子加载(RCU 读)
45: for every location ∈ prev_location do
46: data[(location, txn_idx)] ← ESTIMATE ⊲ 条目保证存在
// 从多版本数据结构中读取的逻辑
47: function read(location, txn_idx)
48: 𝑆 ← {((location, idx), entry) ∈ data | idx < txn_idx} // | 表示这样的
49: if 𝑆 = {} then
50: return (status ← NOT_FOUND)
51: ((location, idx), entry) ← arg max𝑖𝑑𝑥 𝑆
52: if entry = ESTIMATE then
53: return (status ← READ_ERROR, blocking_txn_idx ← idx)
54: return (status ← OK, version ← (idx, entry.incarnation_number), value ← entry.value)
// 接受位置和 txn_idx 作为输入
// 创建一个形式为 ((位置, 事务 ID), entry) 的数据结构 S
// 并填充来自多版本数据结构的所有数据
// 当 data 中的事务 ID 元素小于指定的 txn id 时
// (记得 1<2<3<...)所以如果 txn_id 为 3,它会用 1 和 2 的所有数据填充 S
// 如果集合为空,则将状态设置为未找到,即没有先前事务写入该位置
// 从 S 中选择具有最高事务索引的条目(因为 2>1,最接近事务)
// 获取该位置的最近事务的写入。如果条目为估计,则返回状态为读取错误
// 并将输入中提供的阻塞事务的值设置为 idx
// 否则返回状态为 ok 并将版本设置为元组
// 拍摄多版本数据结构的快照
55: function snapshot()
56: ret ← {}
57: for every location | ((location, ★), ★) ∈ data do // ★ 是占位符
58: result ← read(location, BLOCK.size())
59: if result.status = OK then
60: ret ← ret ∪ {location, result.value} // 伪代码集并
61: return ret
// 对于每个位置,包含从 (估计或实例值对) 到位置和事务 ID 对的映射创建一个大小等于块大小的数组
// 并将其移动到结果中
// 如果 result.status = OK,则 **将位置和 result.value 添加到快照。**
62: function validate_read_set(txn_idx)
63: prior_reads ← last_read_set[txn_idx] ⊲ 加载原子读取的最后记录读集
64: for every (location, version) ∈ prior_reads do ⊲ version 在先前读取返回 NOT_FOUND 时为 ⊥
65: cur_read ← read(location, txn_idx)
66: if cur_read.status = READ_ERROR then
67: return false ⊲ 数据中之前读取的条目,现在为 ESTIMATE
68: if cur_read.status = NOT_FOUND ∧ version ≠ ⊥ then
69: return false ⊲ 数据中之前读取的条目,现在为 NOT_FOUND
70: if cur_read.status = OK ∧ cur_read.version ≠ version then
71: return false ⊲ 读取某些条目,但与之前不相同
72: return true
// 第 64 行和 65 行可以被解释为:对于每个位置、版本对在先前读取的集合中
// 将当前读取设置为由 txn 写入的最近值集
**算法 3: VM 模块**
73: function execute(txn_id)
74: read_set ← {} ⊲ (位置, 版本) 对
75: write_set ← {} ⊲ (位置, 值) 对
76: run transaction BLOCK[txn_idx] ⊲ 函数调用--运行事务,拦截读取和写入
77: ....
78: when execution requires writing data to a location:
79: if (location, prev_value) ∈ write_set then
80: write_set ← write_set \\ {(location, prev_value)} ⊲ 存储每个位置的最新值
81: write_set ← write_set ∪ {(location, value)} ⊲ VM 不写入 MVMemory 或 Storage
// 当执行的事务从未写入过某个位置时
// 第 81 行将位置值对添加到写集中。
82: ....
83: when execution requires reading from a location:
84: if (location, value) ∈ write_set then
85: VM reads value ⊲ 由该事务写入的值
86: else
87: result ← MVMemory.read(location, txn_idx)
88: if result.status = NOT_FOUND then
89: read_set ← read_set ∪ {(location, ⊥)} ⊲ 读取时记录版本 ⊥
90: VM reads from Storage
91: else if result.status = OK then
92: read_set ← read_set ∪ {(location, result.version)}
93: VM reads result.value
94: else
95: return result ⊲ 返回 (READ_ERROR, blocking_txn_id) 从 VM.execute
// 对于第 87 行,请记住“读取”函数
// 检查最近的写入并确定是否为空、估计值或 OK
96: ....
97: return (read_set, write_set)
**算法 4: 调度器模块、变量、公用 API 和下一个任务逻辑**
原子变量: execution_idx ← 0, validation_idx ← 0, decrease_cnt ← 0, num_active_tasks ← 0, done_marker ← false ⊲ 分别:跟踪下一个尝试执行的事务的索引。跟踪验证的类似索引。验证索引或执行索引减少的次数。正在进行的验证和执行任务的数量。完成标记。 txn_dependency ← Array(BLOCK.size(), mutex({})) ⊲ txn_idx 到一个互斥保护的相关事务索引集合 txn_status ← Array(BLOCK.size(), mutex((0, READY_TO_EXECUTE))) ⊲ txn_idx 到一个互斥保护的对 (incarnation_number, status),其中 status ∈ {READY_TO_EXECUTE, EXECUTING, EXECUTED, ABORTING}。
98: procedure decrease_execution_idx(target_idx)
99: execution_idx ← min(execution_idx, target_idx) ⊲ 原子
100: decrease_cnt.increment()
101: function done()
102: return done_marker
103: procedure decrease_validation_idx(target_idx)
104: validation_idx ← min(validation_idx, target_idx) ⊲ 原子
105: decrease_cnt.increment()
106: procedure check_done()
107: observed_cnt ← decrease_cnt
108: if min(execution_idx, validation_idx) ≥ BLOCK.size() ∧ num_active_tasks = 0 ∧ observed_cnt = decrease_cnt then
109: done_marker ← true
// 第 108 行可以解释为:
// 如果下一个任务是对于当前块中不存在的事务
// 以及活动任务数为 0
// 并且观察到的计数等于计数器减少的次数
// 则执行已完成
110: function try_incarnate(txn_idx)
111: if txn_idx < BLOCK.size() then
112: with txn_status[txn_idx].lock()
113: if txn_status[txn_idx].status = READY_TO_EXECUTE then
114: txn_status[txn_idx].status ← EXECUTING
115: return (txn_idx, txn_status[txn_idx].incarnation_number)
116: num_active_tasks.decrement()
117: return ⊥
// 不实际执行事务,仅设置执行环境来调用
// 从第 73 行的 execute
// 决定要执行哪个事务并调用 try incarnate 进行事务 ID
118: function next_version_to_execute()
119: if execution_idx ≥ BLOCK.size() then
120: check_done()
121: return ⊥
122: num_active_tasks.increment()
123: idx_to_execute ← execution_idx.fetch_and_increment()
124: return try_incarnate(idx_to_execute)
// 对验证任务的相同逻辑
125: function next_version_to_validate()
126: if validation_idx ≥ BLOCK.size() then
127: check_done()
128: return ⊥
129: num_active_tasks.increment()
130: idx_to_validate ← validation_idx.fetch_and_increment()
131: if idx_to_validate < BLOCK.size() then
132: (incarnation_number, status) ← txn_status[idx_to_validate].lock()
133: if status = EXECUTED then // 确保该事务已被执行
134: return (idx_to_validate, incarnation_number)
135: num_active_tasks.decrement()
136: return ⊥
// 在执行和验证任务之间进行选择
137: function next_task()
138: if validation_idx < execution_idx then
139: version_to_validate ← next_version_to_validate()
140: if version_to_validate ≠ ⊥ then
141: return (version ← version_to_validate, kind ← VALIDATION_TASK)
142: else
143: version_to_execute ← next_version_to_execute()
144: if version_to_execute ≠ ⊥ then
145: return (version ← version_to_execute, kind ← EXECUTION_TASK)
146: return ⊥
**算法 5: 调度器模块、依赖关系和完成逻辑**
// 判断一个事务是否被第二个参数中的事务阻止
147: function add_dependency(txn_idx, blocking_txn_idx)
148: with txn_dependency[blocking_txn_idx].lock()
149: if txn_status[blocking_txn_idx].lock().status = EXECUTED then ⊲ 线程持有两个锁
150: return false ⊲ 在第 148 行锁定之前已解决依赖关系
151: txn_status[txn_idx].lock().status() ← ABORTING ⊲ 先前状态必须为 EXECUTING
152: txn_dependency[blocking_txn_idx].insert(txn_idx)
153: num_active_tasks.decrement() ⊲ 由于依赖关系,执行任务中止
154: return true
155: procedure set_ready_status(txn_idx)
156: with txn_status[txn_idx].lock()
157: (incarnation_number, status) ← txn_status[txn_idx] ⊲ 状态必须为 ABORTING
158: txn_status[txn_idx] ← (incarnation_number + 1, READY_TO_EXECUTE)
159: procedure resume_dependencies(dependent_txn_indices)
160: for each dep_txn_idx ∈ dependent_txn_indices do
161: set_ready_status(dep_txn_idx)
162: min_dependency_idx ← min(dependent_txn_indices) ⊲ 如果没有元素,最小值为 ⊥
163: if min_dependency_idx ≠ ⊥ then
164: decrease_execution_idx(min_dependency_idx) ⊲ 确保相关索引被重新执行
165: procedure finish_execution(txn_idx, incarnation_number, wrote_new_path)
166: txn_status[txn_idx].lock().status ← EXECUTED ⊲ 状态必须为 EXECUTING
167: deps ← txn_dependency[txn_idx].lock().swap({}) ⊲ 交换出相关事务索引的集合
168: resume_dependencies(deps)
169: if validation_idx > txn_idx then ⊲ 否则索引已经足够小
170: if wrote_new_path then
171: decrease_validation_idx(txn_idx) ⊲ 为事务 idx 和更高的事务调度验证
172: else
173: return (version ← (txn_idx, incarnation_number), kind ← VALIDATION_TASK)
174: num_active_tasks.decrement()
175: return ⊥ ⊲ 未返回任何任务给调用者
176: function try_validation_abort(txn_idx, incarnation_number)
177: with txn_status[txn_idx].lock()
178: if txn_status[txn_idx] = (incarnation_number, EXECUTED) then
179: txn_status[txn_idx].status ← ABORTING ⊲ 线程更改状态,开始中止
180: return true
181: return false
182: procedure finish_validation(txn_idx, aborted)
183: if aborted then
184: set_ready_status(txn_idx)
185: decrease_validation_idx(txn_idx + 1) ⊲ 为更高的事务调度验证
186: if execution_idx > txn_idx then ⊲ 否则索引已经足够小
187: new_version ← try_incarnate(txn_idx)
188: if new_version ≠ ⊥ then
189: return (new_version, kind ← EXECUTION_TASK) ⊲ 返回重新执行任务给调用者
190: num_active_tasks.decrement() ⊲ 完成验证任务
191: return ⊥ ⊲ 未返回任何任务给调用者
*1 批量执行事务减少了消息和上下文切换的开销,但代价是需要额外的调度。
*2 有关 OCC 与 PCC 的主题在学术界被认为无关紧要——普遍观点认为 OCC 适用于低争用应用,而 PCC 适用于高争用应用。因此,在这方面几乎没有持续的工作——最近讨论该主题的论文之一是 1982 年写的。以下图表改编自这篇论文,并有助于重新确认已建立的观点。
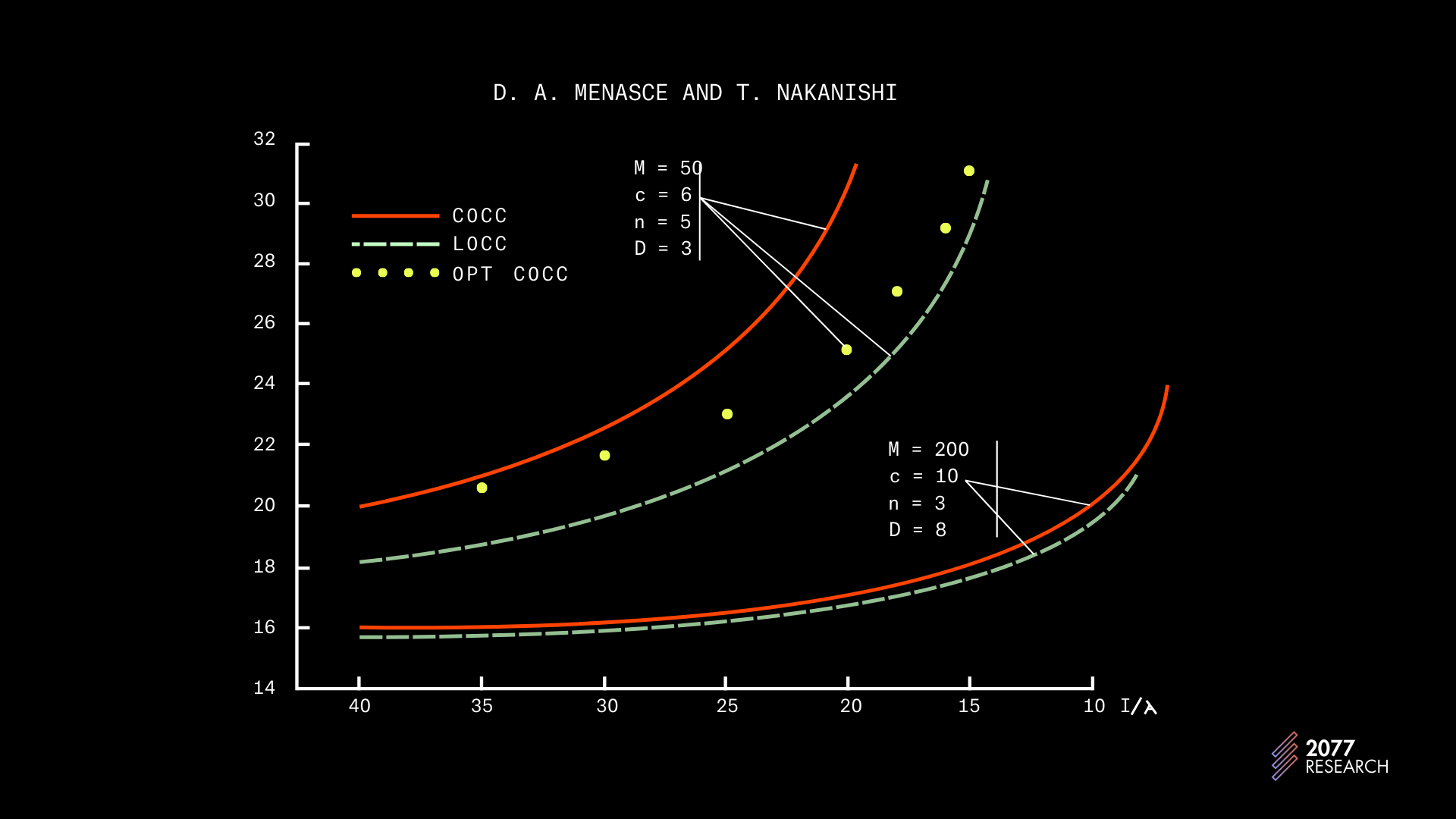
**图 24: OCC (COCC) 与 PCC (LOCC)** | **来源: 数据库管理系统中的乐观与悲观并发控制机制** [**D. Menascé**](https://www.semanticscholar.org/author/D.-Menasc%C3%A9/2264617067?ref=ghost-2077.arvensis.systems) , [**Tatuo Nakanishi**](https://www.semanticscholar.org/author/Tatuo-Nakanishi/31634756?ref=ghost-2077.arvensis.systems) , [**Information Systems**](https://www.semanticscholar.org/venue?name=Information+Systems&ref=ghost-2077.arvensis.systems) 1982. DOI: [**10.1016/0306-4379(82)90003-5**](https://doi.org/10.1016/0306-4379%2882%2990003-5?ref=ghost-2077.arvensis.systems)
2016 年,惠普实验室的 Goetz Graefe 进行的研究《重新审视乐观与悲观并发控制》得出了与 Menasce 和 Nakanishi 相同的结论;引用作者的话,
“ _我们得出的结论是,乐观并发控制仅在无法检测到某些实际冲突,或特定实现的锁定机制检测到虚假冲突时,才允许比悲观并发控制更多的并发性_。”
有无数研究得出相同结论,但我们为了简洁起见省略了它们。
*3 对 Block-STM 和 Sealevel 的完全公平评估需要隔离,即去除所有其他过程,例如 Solana 的 PoH 和账本确认,使用相同的 VM 进行 TPU 和一系列繁琐的工程任务,这些都是不值得的,特别是当初步测试表明 TPU 遵循既定趋势时。
*4 Block-STM 的实现中的一种优化允许从冲突点重新启动中止的事务。MoveVM 支持验证事务先前实例的读集,如果有效,则从冲突点继续执行,而不是从头重新启动。
*5 第二种优化是当在创建执行任务之前解决依赖关系,即当算法第 14 行返回 false 时。在实现中,VM 从暂停位置继续执行,而不是重新启动执行。
>- 原文链接: [research.2077.xyz/block-...](https://learnblockchain.cn/article/12552/block-stm_vs_sealevel)
>- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~




