Solidity调用图:构建、遍历和分析代码
- Cyfrin
- 发布于 2025-06-06 08:31
- 阅读 1507
本文介绍了如何构建和遍历Solidity调用图,用于静态分析、漏洞检测和更智能的合约开发。通过示例代码和详细的解释,展示了如何使用Router解析内部函数调用,并提出了在调用图中进行深度优先或广度优先遍历的策略,提高代码分析的准确性,并以Aderyn工具的实现为例,展示了如何应对函数调用解析中可能出现的二义性情况。
Solidity: 静态分析内部调用图指南
学习如何构建和遍历 Solidity 调用图,用于静态分析、漏洞检测以及使用 Aderyn 进行更智能的合约开发。
引言
Solidity 合约表面上看起来可能非常简单。但在底层,它们形成了函数调用、继承路径和修饰器的深层链,如果没有合适的工具,很难跟踪这些链。
调用图可以呈现这种复杂性。它展示了交易如何在智能合约中流动,帮助开发人员和审计员清晰有效地追踪执行路径。
本指南将教你如何构建它们。
什么是调用图?
调用图是一个展示函数如何相互调用和交互的图表。每个节点代表一个函数或子程序,每个箭头代表从一个函数到另一个函数的调用。
这是一个简单的例子:
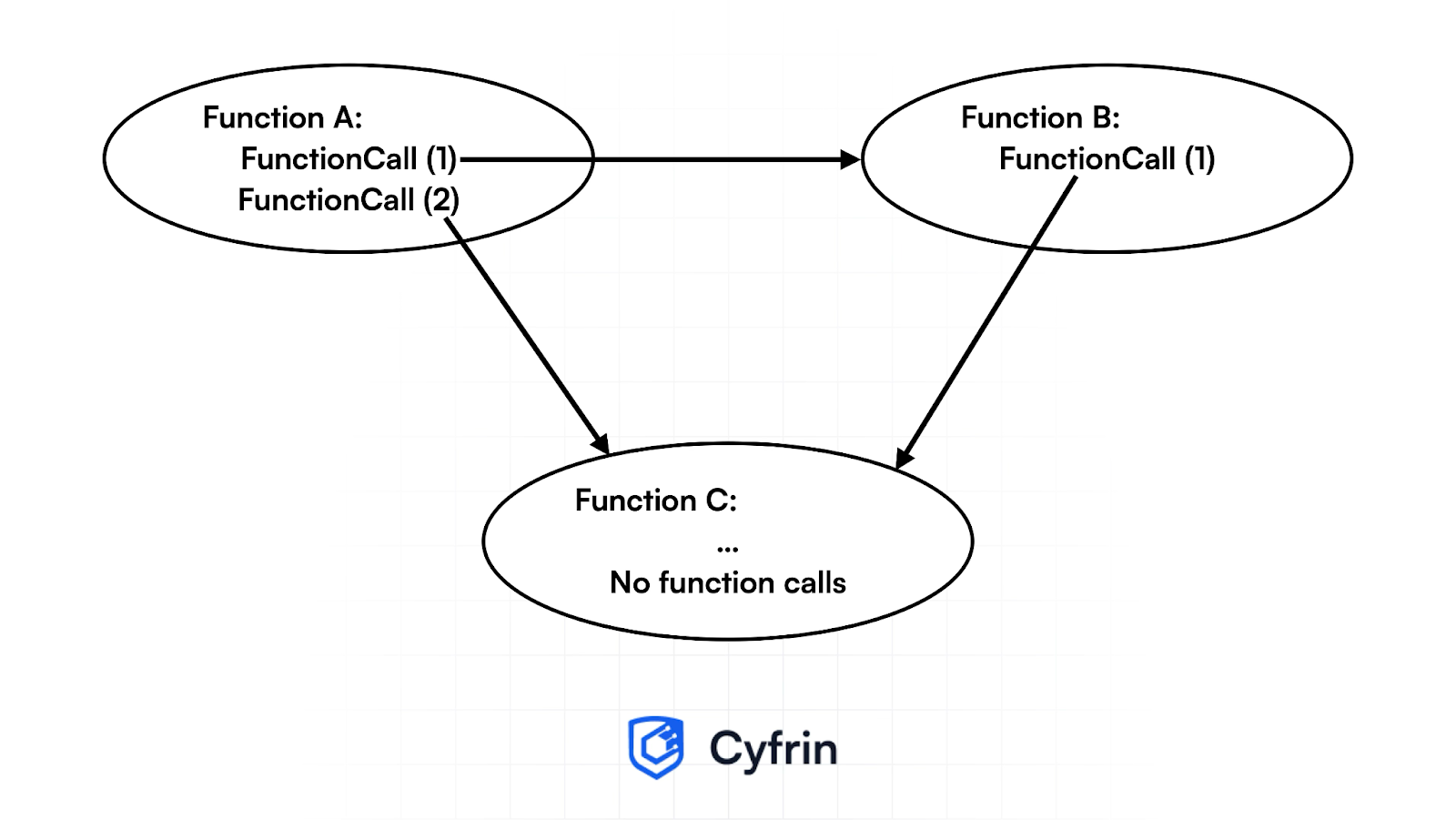
在这个图中:
-
函数 A 同时调用函数 B 和函数 C。
-
函数 B 调用函数 C。
-
函数 C 不调用任何其他函数。
调用图对于 静态分析 尤其有用。它们帮助我们理解数据和交易如何在智能合约中移动,并且允许我们放大任何函数,并查看其执行路径中可能涉及的内容。
在 Solidity 中,函数可以是内部的或外部的。内部调用发生在同一合约内或跨继承合约之间,无论可见性如何(public、internal 等)。我们忽略外部调用(那些可以向其他合约发送calldata的调用),因为我们只对函数如何在合约及其继承树中交互感兴趣。
虽然我们在此描述的实现来源于 Aderyn,但这些概念适用于任何 Solidity 智能合约。
准备调用图
第一步是提取项目中的所有可部署合约,即可完全实现、非抽象的合约。
我们建议为每个合约生成一个单独的调用图。如果一个函数在多个合约中被重用,它将出现在多个图中。这种重复是故意的并且是必要的,因为同一个函数可能会根据其被调用的位置表现不同。(我们在 Router 和 lookup 章节中解释原因。)
对于每个合约,首先识别入口点:在合约中定义或从父合约继承的 public 和 external 函数。这些函数被插入到工作列表 (worklist) 中。
工作列表是一个不断更新的列表,其中包含算法必须完成的所有子任务。这些子任务可以在算法执行期间添加到列表中或从列表中删除。通常,算法会一直运行,直到工作列表为空。
我们逐步遍历工作列表中的每个函数,尽可能地跟踪该函数中的调用链,然后再继续处理下一个函数。这有助于我们构建所有函数如何连接的完整图景。
以下是用伪代码表示的流程:
// 对于每个可部署合约 C:
Visited = {}
Graph = {}
// 使用 C 中的入口点函数列表进行初始化
Worklist = C->Entrypoints()
while not Worklist->empty():
Func = Worklist->pop()
// 防止递归情况下的无限循环
if Visited[Func]:
continue
Visited[Func] = true
for FuncCall in Func -> ListInternalFunctionCalls():
TargetFn = ::Router->ResolveFuncCall(C, FuncCall) // 稍后解释
// 存储图并将其与合约 C 关联
Graph->AddNodeIfDoesntExist(Func)
Graph->AddNodeIfDoesntExist(TargetFn)
Graph->AddEdgeIfDoesntExist(Func, TargetFn)
// 用于在调用图中进一步探索
Worklist.push(TargetFn)对于工作列表中的每个函数,我们提取其内部调用,并使用 Router 将每个调用解析为其定义(将在下一节中介绍)。然后,我们将调用函数链接到其目标函数或修饰器。
请注意,在实际实现中,我们对修饰器也执行相同的操作。每个已解析的目标(无论是函数还是修饰器)都会被推回工作列表以供进一步探索。此过程将一直持续,直到已遍历合约入口点的整个可达调用图。
有关实际实现,请参见 GitHub 上的源代码。
Router
router (路由器) 是系统的关键部分,它根据基本合约的上下文将内部调用解析为其定义。
在前面的伪代码中,你可能还记得这一行:``
TargetFn = ::Router-> ResolveFuncCall(C, FuncCall)乍一看,此函数似乎接受两个参数:基本合约 (C) 和要解析的调用 (FuncCall)。但是,还有第三个隐式输入,即 Function Call 在源代码中的位置。这可以从与 FuncCall 关联的抽象语法树 (AST) 节点推断出来。
为什么这很重要?为了回答这个问题,让我们探讨几个练习。
练习 1
contract Grandparent {
function myFunc() public virtual {}
}
contract Parent1 is Grandparent {
function p1() public {
myFunc();
}
}
contract Parent2 is Grandparent {
function p2() public {
myFunc();
}
}
contract Child is Grandparent, Parent2, Parent1 {
function myFunc() public override(Grandparent) {}
function abc() public {
p1();
}
}花点时间回顾上面的代码。
现在看看 p1 和 p2 函数。它们都调用 myFunc(),但真正的问题是:myFunc() 是否始终引用在 Grandparent 中定义的版本?
答案:否。
解释:
如果直接在 Parent1 的实例上调用 p1(),或者在 Parent2 上调用 p2(),则 myFunc() 会解析为在 Grandparent 中定义的那个。但是,如果 p1() 是由 Child 调用的,例如通过 abc() 函数,那么 myFunc() 会解析为在 Child 中定义的重写版本。
这里的关键见解是:解析函数调用不仅取决于函数名称及其参数,还取决于调用所源自的合约。换句话说,基本合约或启动合约决定了如何解释调用。
这就是路由器需要知道基本合约才能解析函数调用的原因。
练习 2
contract Grandparent {
function myFunc() public virtual {}
}
contract Parent1 is Grandparent {
function p1() public {
super.myFunc();
}
}
contract Parent2 is Grandparent {
function p2() public {
super.myFunc();
}
function myFunc() public override(Grandparent) virtual {}
}
contract Child is Parent2, Parent1 {
function myFunc() public override(Grandparent, Parent2) {}
function abc() public {
p1();
}
}让我们看看 p1() 和 p2() 函数。两者都使用 super.myFunc()。但真正的问题是:super.myFunc() 是否总是调用在 Grandparent 中定义的 myFunc() 版本?
答案:否。
解释:
如果 p1() 是直接从 Parent1 调用的,那么 super.myFunc() 指的是 Grandparent.myFunc(),因为 Grandparent 是在 Parent1 之后的线性化继承顺序中的下一个合约。
但是,如果 p1() 是由 Child 触发的,例如通过调用 abc(),那么一切都会改变。在这种情况下,Parent1 中的 super.myFunc() 开始查找 不是 从 Grandparent 开始,而是从 Child 的线性化继承层次列表中 Parent1 的下一个合约开始 - 即 Parent2。并且由于 Parent2 覆盖了 myFunc(),因此该版本是被执行的版本。
此行为可视化如下:
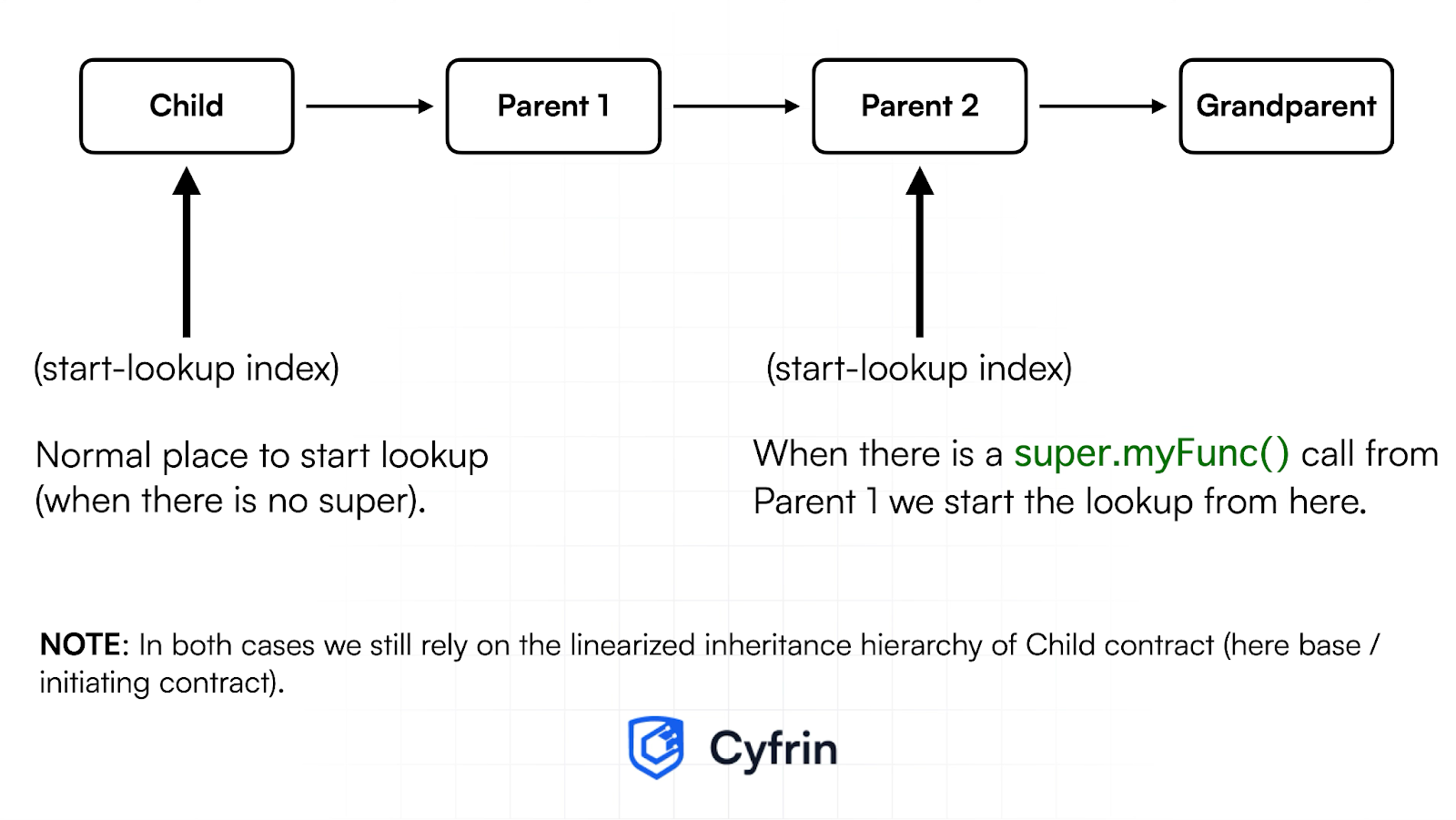
-
如果没有
super,查找将从基本合约开始 - 在本例中为Child。 -
使用
super,查找从位于调用合约的线性化 继承层级 中,在调用super的合约之后的合约开始(例如,Parent1→Parent2)。
注意:线性化继承层级 是使用 C3 算法组合所有合约的顺序。这是一个解释它的 视频。
关键要点:super 关键字并不意味着“转到我的直接父级,如包含合约中所定义的那样。” 相反,它的意思是“从_当前_基本合约的继承顺序中 在我之后 的合约开始查找。” 查找仍然发生在发起(基本)合约的层次结构中,但开始查找的索引已更改。
那么,我们需要什么才能准确地解析函数调用?
-
基本合约:设置上下文以解析函数调用的可部署 合约。
-
开始查找索引:在基本合约的线性化继承层次结构中从何处开始搜索。
-
函数调用 (AST 节点):提供函数名称 + 参数类型 + 调用位置
简而言之,函数解析是上下文相关的。相同的函数调用可能会根据其触发的位置和方式产生不同的结果。
练习 3
contract Grandparent {
function myFunc() public virtual {}
}
contract Parent1 is Grandparent {
function p1() public {
Grandparent.myFunc();
}
}
contract Parent2 is Grandparent {
function p2() public {
Grandparent.myFunc();
}
function myFunc() public override(Grandparent) virtual {}
}
contract Child is Parent2, Parent1 {
function myFunc() public override(Grandparent, Parent2) {}
function abc() public {
p1();
}
}让我们检查 p1() 和 p2() 函数。两者都显式调用 Grandparent.myFunc()。
问题:此调用是否始终解析为在 Grandparent 中定义的 myFunc() 实现?
回答:是
解释:这次,没有歧义。该调用显式命名了合约:Grandparent.myFunc()。这意味着查找从 Grandparent 定义开始和结束,无论对 p1() 或 p2() 的调用源自继承树中的何处。
最后一点说明:修饰符以类似于函数的方式解析。
现在我们已经了解了 Router 在不同上下文中的工作方式,让我们继续构建 router 本身。
Router 数据结构
在其核心,Router是一个嵌套的映射,允许我们解析具有可部署合约的完整上下文的内部函数调用和修饰符调用。其结构如下所示:
Mapping[
// 基本(或)启动合约
NodeID => Mapping[
// 基本合约 C3 层级结构中的开始查找索引
NodeID => Mapping[
// Selectorish(函数名称 + 参数类型组合)
String
=> // 函数定义
NodeID
]
]
]下方代码实现了构建内部调用的路由器:
pub(super) fn build_ic_router_for_contract(
context: &WorkspaceContext,
base_contract: &ContractDefinition,
) -> HashMap<NodeID, HashMap<String, NodeID>> {
let c3 = base_contract.c3(context).collect::<Vec<_>>();
let mut base_routes = HashMap::new();
for (idx, starting_point) in c3.iter().enumerate() {
let mut routes = HashMap::new();
for contract in c3.iter().skip(idx) {
for func in contract.function_definitions() {
if matches!(*func.kind(), FunctionKind::Function)
&& matches!(func.visibility, Visibility::Internal | Visibility::Public)
{
if let Entry::Vacant(e) = routes.entry(func.selectorish()) {
e.insert(func.id);
}
}
}
}
base_routes.insert(starting_point.id, routes);
}
base_routes
}而查找过程本身则通过下面一段代码来实现:
pub(super) fn _resolve_internal_call<'a>(
&self,
context: &'a WorkspaceContext,
base_contract: &'a ContractDefinition,
func_call: &'a FunctionCall,
) -> Option<&'a FunctionDefinition> {
// do not resolve if it's not internal function call
// very very very important check.
if func_call.is_internal_call() != Some(true) {
return None;
}调用图遍历策略
现在我们已经了解了如何准备和可视化调用图,下一步是了解如何有效地遍历它,特别是对于静态分析任务。
让我们举一个具体的例子:识别循环内的 delegatecall。
起初,直接扫描循环体似乎就足够了。但这不会捕获所有内容。如果循环包含函数调用,则需要跟踪这些调用并检查它们触发的函数。这就是调用图变得至关重要的地方。
这是处理它的方法:
1. 识别包含循环的函数。
找到此函数显示为节点的所有调用图。(请记住:每个可部署的合约都有自己的调用图。)让我们称之为 集合 1。然后,收集循环体内的所有函数调用节点。这些是你的 集合 2。
2. 解析调用
使用路由器将集合 2 的函数调用解析为其在集合 1 的每个调用图中的相应函数定义。使用已解析的函数作为其各自调用图中遍历的起始点。
3. 遍历图
从每个起点,执行深度优先或广度优先遍历。使用调用图的一个显着好处是它可以自动过滤掉无法访问的代码,例如已被覆盖或从未执行的函数。如果某个函数无法访问,则一开始就不会将其添加到图中。
你可以在 Aderyn 中 此处 探索我们对此遍历策略的实现。
结论
我们已在 Aderyn 中实现了这些策略,以生成精确的调用图,该图有助于漏洞检测器更有效地分析代码,并使开发人员更深入地了解执行流程。在我们的内部测试中,提高调用图的准确性使检测器的精度提高了 20%。
如果你对我们如何在 AST 级别处理事物感到好奇,或者只是想进行更深入的了解,请随时在 X 上 联系我们。我们总是很乐意聊天。
- 原文链接: cyfrin.io/blog/solidity-...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





