通过 GRAFT 和 PRUNE 观察 Gossipsub 网络的动态性 - 网络
- 以太坊中文
- 发布于 2024-06-07 23:41
- 阅读 868
本文是 ProbeLab 团队对以太坊 P2P 网络中 Gossipsub 性能的研究报告,重点分析了 GRAFT 和 PRUNE 消息的频率,以及由此产生的会话持续时间和网络稳定性。

概要 & TL;DR
ProbeLab 团队(https://probelab.io)正在对以太坊 P2P 网络中 Gossipsub 的性能进行研究。继我们之前关于“Gossipsub 的 gossip 机制的有效性”的帖子之后,在这篇文章中,我们调查了 GRAFT 和 PRUNE 消息的频率,以及由这些协议原语产生的会话持续时间和网络稳定性方面的动态性。为了进行这项研究,我们构建了一个名为 Hermes 的工具(GitHub - probe-lab/hermes: A Gossipsub listener and tracer.),它充当 GossipSub 监听器和追踪器。Hermes 订阅所有相关的 pubsub 主题,并追踪所有协议交互。这里报告的结果来自一个 3.5 小时的追踪。
研究描述: 本研究的目的是确定每个主题的 GRAFT 和 PRUNE 消息之间的频率的分布和标准差。我们测量了我们的节点与其他节点之间的会话持续时间,按客户端拆分,并尝试识别任何异常(例如,连接太短)和潜在模式。
TL;DR: 总的来说,我们得出结论,就 MeshDegree 而言,Gossipsub 保持了一个稳定的网格,几乎没有超过 DLow 和 DHigh 的阈值 6 和 12,尽管有时动态性增加(即,GRAFT 和 PRUNE 的数量增加)。Teku 节点总是在几秒钟(或更短)内断开与我们节点的连接,并且无法保持任何连接运行更长时间(甚至几分钟)。 这一事实很可能导致一些不稳定,然而,这似乎并没有影响网络其余部分的正确运行。
有关以太坊网络的更多详细信息和结果,请访问 https://probelab.io 获取 discv5 每周网络健康报告。
背景
GossipSub 是最广泛使用的 libp2p PubSub 路由机制。Gossipsub 包括增强的 PubSub 路由,旨在通过减少每个订阅主题的连接数量(通过网格)并发送一些零星的消息元数据以实现弹性(通过 gossip 机制)来减少带宽。这确保了尽管消息是使用最短延迟路径(网格)广播的,但节点仍然有共享 msg_ids(gossip)的备份,以防止错过已经在网络中传播的消息。
由于 GossipSub 减少了每个主题的连接节点总数,即网格,因此在这些网格上拥有足够的节点对于在任何网络中进行高效的消息广播至关重要。这些网格作为 libp2p 连接下的连接子层工作,因为 1_libp2p_peer_connection ↔ 1_mesh_peer_connection 之间没有直接映射。
这种区分提高了协议的效率,因为一个节点不需要向比所需数量更多的节点“浪费”带宽发送完整消息,同时避免向已经共享相同消息的节点发送垃圾邮件。
然而,这意味着路由机制必须控制它连接了多少个节点,或者对于每个网格需要 GRAFT(添加)或 PRUNE(移除)多少个节点,这使得事情变得更加复杂。
本报告深入了解了 GRAFT 和 PRUNE 事件(网络动态性),以及基于 Hermes 的节点 [ link to Hermes GH repo] 在参与 Holesky 测试网的 3.5 小时内可以跟踪的 RPC 调用(会话持续时间)。
结果
添加和移除节点事件
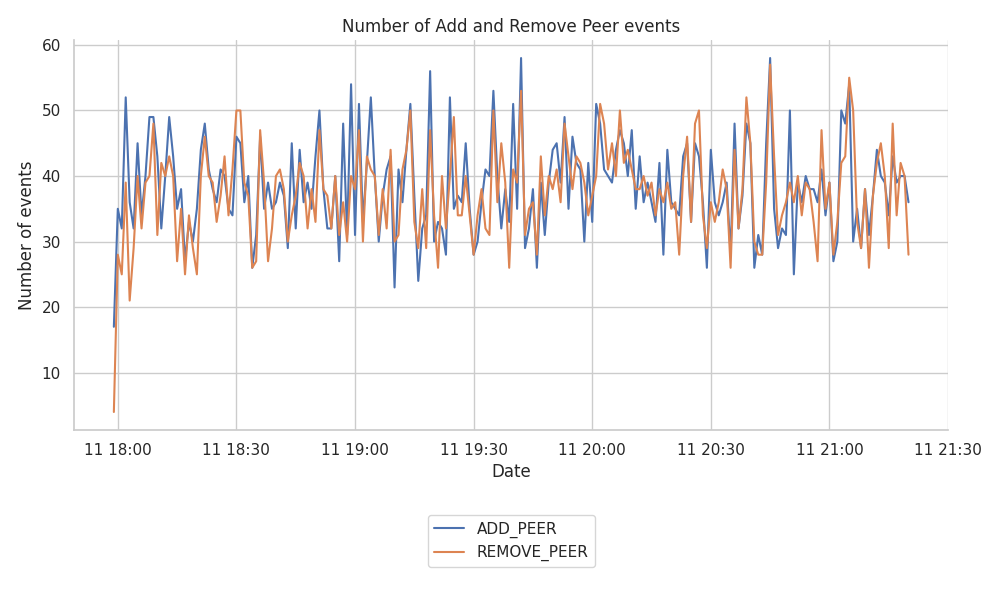
网络网格的稳定性在很大程度上取决于 libp2p 主机保持打开的连接。下图显示了 Hermes 节点在 3.5 小时运行期间跟踪的 ADD_PEER 和 REMOVE_PEER 的数量。
 \
add-remove-peers-overall1000×600 92.1 KB
\
add-remove-peers-overall1000×600 92.1 KB
从图中,我们没有看到任何特别不一致的行为或突出的模式。libp2p 主机上的连接和断开连接的数量保持相对稳定,大约每分钟 40 个事件。
GRAFT 和 PRUNE 事件
GRAFT 和 PRUNE 消息定义了何时将一个节点添加到我们订阅的网格中或从网格中移除。因此,它们直接显示了主题网格内节点连接的动态。
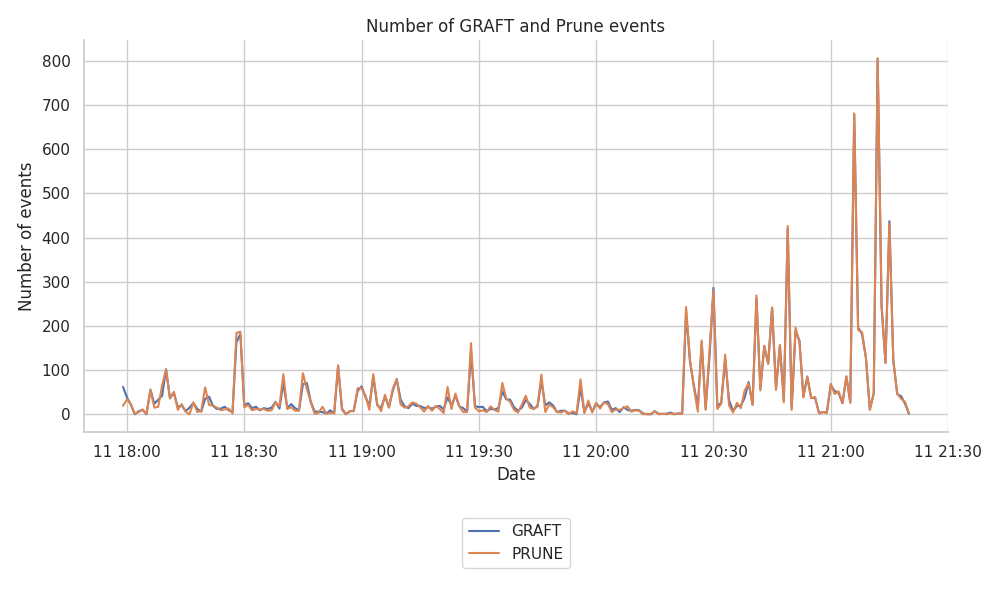
下图显示了 Hermes 节点注册的 GRAFT 和 PRUNE 的数量。
 \
graft-prune-all-topics1000×600 55.4 KB
\
graft-prune-all-topics1000×600 55.4 KB
我们还按主题对其进行了分解,并生成了相关的图,但是,我们没有在此处包括这些图,因为各个主题之间的拆分大致相等。
我们观察到,在 Hermes 运行约 2.5 小时后,记录的事件数量激增,从每分钟约 100 个事件的峰值跃升至每分钟高达 700-800 个事件的峰值。
与 GRAFT 和 PRUNE RPC 事件的相关性
在该节点在线运行 2 小时后,我们可以看到 GossipSub 主机跟踪网格连接性的频率高于前几个小时。由于 RPC 调用可以包括多个主题的 GRAFT 或 PRUNE,因此这些事件对应于原始发送和接收的 RPC 调用的总和。
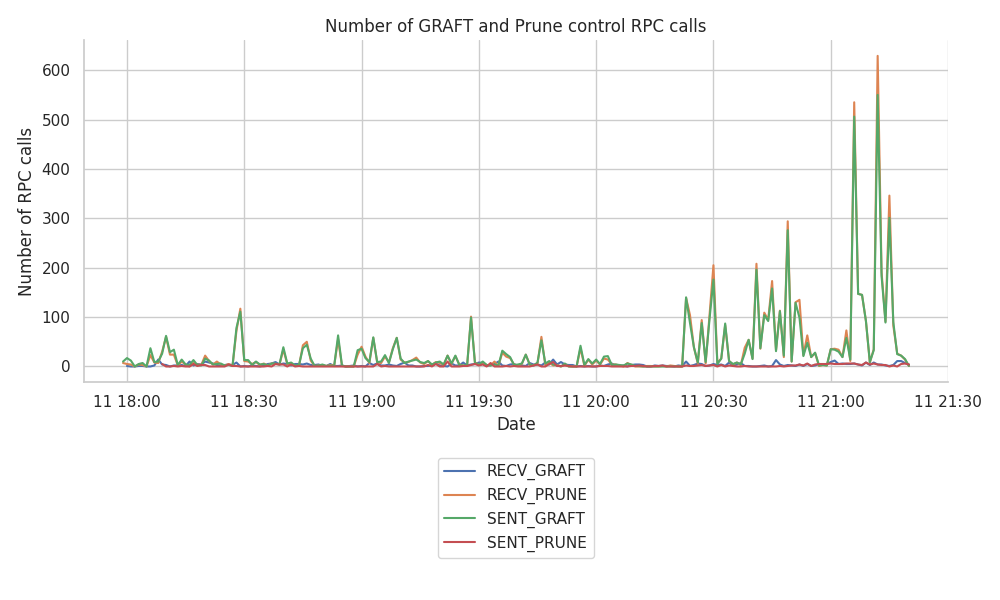
通过下图更仔细地观察这些消息的来源,我们可以看到最重要的大量事件属于 RECV_PRUNE 和 SENT_GRAFTs。
 \
graft_prune_rpc_collection_all_graft_and_prune_rpc_calls1000×600 55.1 KB
\
graft_prune_rpc_collection_all_graft_and_prune_rpc_calls1000×600 55.1 KB
和以前一样,我们也按主题对其进行了分解,并生成了相关的图,但是,我们没有在此处包括这些图,因为各个主题之间的拆分大致相等。
我们可以看到,由于在跟踪期结束时 GRAFT 和 PRUNE 事件的数量增加,网格的稳定性受到一些扰动。对此有两种可能的解释:
- 远程节点由于某种原因断开了与我们的连接(对等节点评分较低,或者只是因为它们的网格已满而发送零星的
PRUNE消息),并且我们的Hermes节点通过发送更多GRAFT消息来保持MeshDegree = 8来应对这种对等节点的丢失。 - 我们发送了太多的
GRAFT消息来轮换我们的对等节点并测试与网络中其他节点的连接,这遭到了远程对等节点的反对,因为它们的网格可能已经满了。请注意,Hermes的同时连接上限为 500 个,因此我们预计它比网络中的其他节点具有更高的连接对等节点范围。
无论如何,我们不认为这是一个令人震惊的事件,事件数量的增加可能仅仅是由于网络活动增加所致。在不久的将来,我们将通过进一步的实验来验证这是否不是一个令人震惊的事件,在这些实验中,我们将收集更长时间的跟踪数据。
网格连接时间
在每个主题网格中,稳定的连接和这些连接的某种轮换程度之间取得平衡非常重要。事实上,这种轮换程度是可以保证节点最终不会被恶意行为者遮蔽的程度(尽管 GossipSub-v1.1 也具有 gossip 功能来克服遮蔽尝试)。
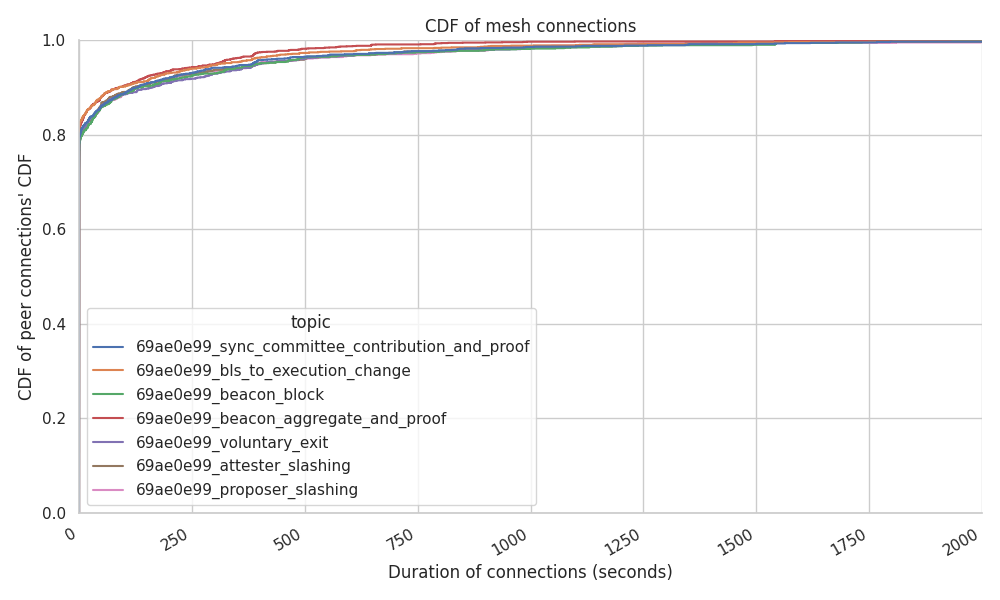
以下图表显示了每个对等节点和每个网格的平均连接时间。
 \
connection_stability_cdf_per_topic1000×600 48.4 KB
\
connection_stability_cdf_per_topic1000×600 48.4 KB
测量节点级别上的平均连接稳定性可以展示网络中的奇怪行为。在这种情况下,我们的 Hermes 运行确实测量了分散的结果:
- 80% 的对等节点在建立连接几秒钟后断开连接,尽管必须注意的是,这里的高百分比归因于我们在此特定数据集的跟踪期结束时看到的峰值。我们不希望这成为“稳定状态”下的正常行为。
 \
connection_stability_cdf_per_topic-801000×600 54.1 KB
\
connection_stability_cdf_per_topic-801000×600 54.1 KB
- 10% 的对等节点总共保持连接约 4 分钟。
 \
connection_stability_cdf_per_topic-101000×600 52.5 KB
\
connection_stability_cdf_per_topic-101000×600 52.5 KB
- 剩余的 10% 的连接保持在约 5 分钟到 1.6 小时之间。
但是,这些图表并未提供完整的画面。正如我们在 GRAFT 和 PRUNE 消息的数量中看到的那样,这些分布存在时间关系。这意味着仅仅因为 80% 的连接发生在第一秒内,并不意味着它们最近在跟踪期内分配。为了提供更清晰的信息,我们绘制了在 3.5 小时跟踪期内以 30 分钟为窗口分割的连接持续时间(以秒为单位)。
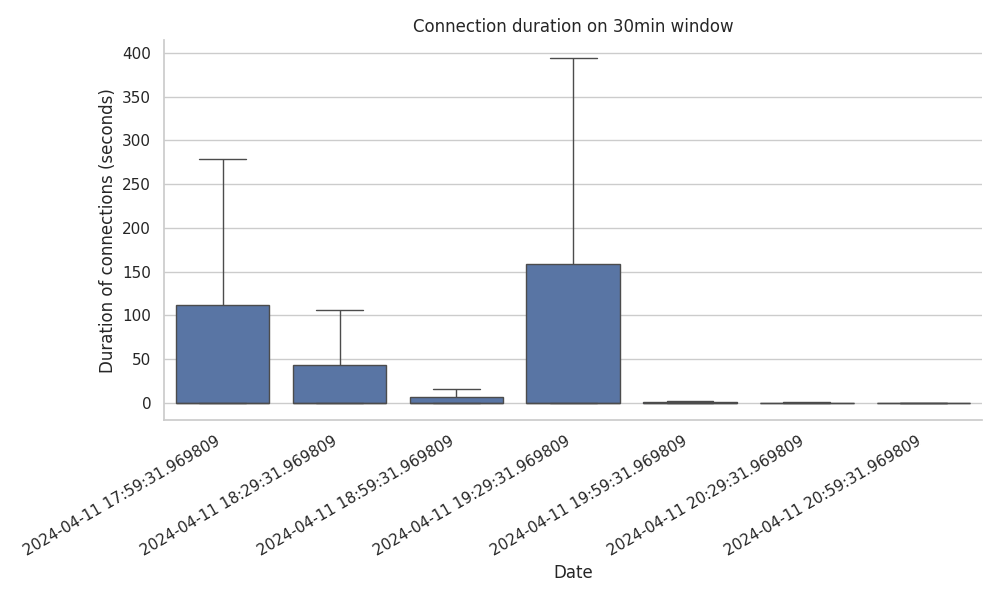 \
connection-duration-30min-window-total1000×600 14.1 KB
\
connection-duration-30min-window-total1000×600 14.1 KB
将 GRAFT 和 PRUNE 的突然峰值与跟踪期结束相关联,我们发现:在前 2.5 小时内建立的连接确实持续时间更长。
我们创建了按主题、按代理以及按主题和代理在 30 分钟窗口内分解连接的图表。我们在此仅展示一个具有代表性的图,因为我们没有看到任何突出的行为,除了以下几点:
- Lodestar 显然将连接保持更长的时间,其次是 Nimbus
- Teku 节点始终几乎立即断开连接。
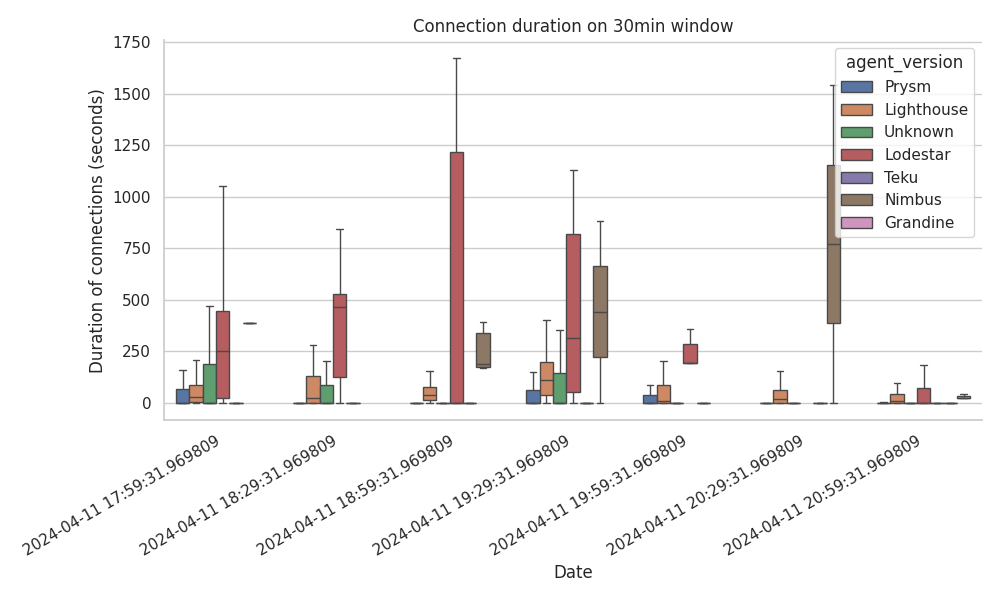 \
connection_duration-30min_user_agents_total1000×600 38.6 KB
\
connection_duration-30min_user_agents_total1000×600 38.6 KB
以下表格也证明了我们的两个观察结果,该表格包括每个客户端的总连接时间(以秒为单位)的百分位数。
| 百分位数 | p25 | p50 | p80 | p90 | p99 |
|---|---|---|---|---|---|
| Grandine | 6.53 | 17.22 | 31.52 | 43.67 | 117.36 |
| Lighthouse | 9.94 | 19.82 | 36.25 | 74.89 | 570.02 |
| Lodestar | 2.06 | 7.12 | 1768.40 | 5855.87 | 7165.20 |
| Nimbus | 200.44 | 523.96 | 599.88 | 599.97 | 4157.40 |
| Prysm | 5.00 | 5.00 | 175.65 | 594.67 | 4322.25 |
| Teku | 0.10 | 0.13 | 0.64 | 1.72 | 5.85 |
| Unknown | 0.07 | 0.14 | 5.00 | 5.22 | 5.90 |
每个网格的最终节点数
重要的是要强调,尽管网络连接性激增,以及相关的 RPC 交互,但我们的节点在每个主题网格内都保持了稳定的连接范围。
下图显示了每个主题的网格连接总数,以 5 分钟的间隔进行分箱。
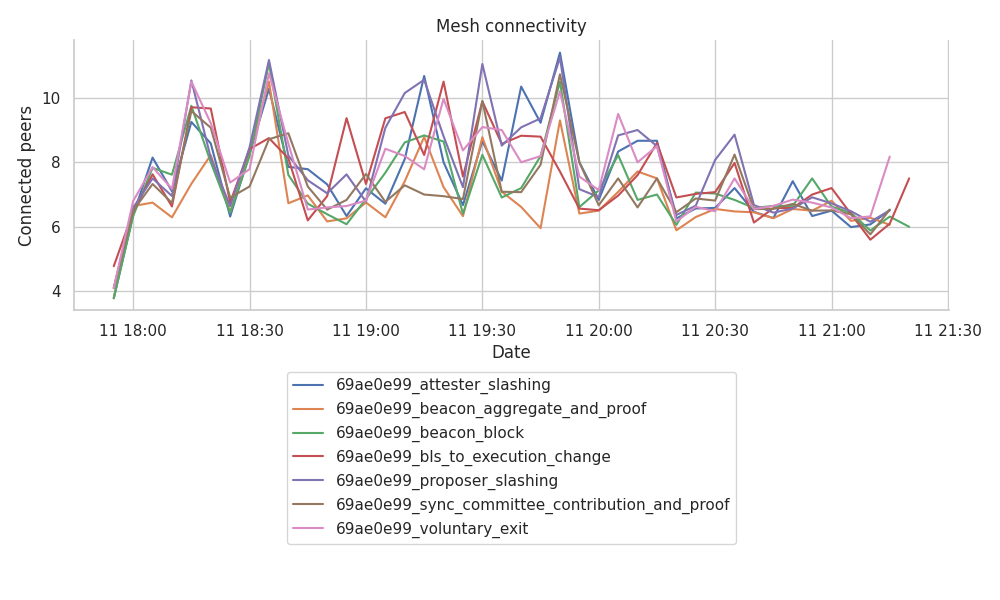 \
graft_and_prune_events_collection_mesh_connectivity_for_topics1000×600 106 KB
\
graft_and_prune_events_collection_mesh_connectivity_for_topics1000×600 106 KB
每个主题的连接范围几乎没有低于 6 个,即使在数据的最后一小时也是如此,我们在那段时间看到了 GRAFT 和 PRUNE 事件的激增。我们可以观察到:
- GossipSub 在保持
gossipSubD=8范围内的连接方面做得很好(在gossipSubDlo=6和gossipSubDhi=12之间)。 - 每个主题的连接比率确实在运行的最后一小时出现小幅下降,这与之前图中看到的
RECV_PRUNE的突然峰值相匹配。 - 最后一小时连接数量的下降似乎与在此期间打开的连接实际上比之前的连接短得多的事实有关。
结论和要点
-
总的来说,我们得出结论,就
MeshDegree而言,Gossipsub 保持了一个稳定的网格,几乎没有超过DLow和DHigh的阈值 6 和 12,尽管有时动态性增加(即,GRAFT和PRUNE的数量增加)。 -
Teku 节点总是在几秒钟(或更短)内断开与我们节点的连接,并且无法保持任何连接运行更长时间(甚至几分钟)。 这一事实很可能导致一些不稳定,然而,这似乎并没有影响网络其余部分的正确运行(至少从我们目前看到的情况来看)。
-
我们的数据显示,在研究的最后一小时,
GRAFT和PRUNE事件突然激增,尽管ADD_PEER和REMOVE_PEER事件在整个运行过程中保持稳定。 这可能表明Hermes或网络正在努力与其他参与者保持网格连接。GRAFT和PRUNE的激增通常来自传入的PRUNE事件,然后是随后的传出的GRAFT事件。目前仍不清楚是什么触发了这种行为,即,这只是来自远程对等节点严格的连接限制的一个异常,这些节点经常拒绝连接,或者是否是Hermes比它应该的更多地用GRAFT轰炸远程对等节点,而远程对等节点反过来用PRUNE事件响应。- 我们得出结论,这个事件值得关注(例如,节点最终在主机级别上具有稳定的连接,但在每个网格中保持健康的连接数量方面存在困难),并通过更长时间的实验进行验证。但是,我们不认为这是一个关键事件,即,不会导致任何其他指标受到影响。
- 原文链接: ethresear.ch/t/gossipsub...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





