Thanos开发故事 — 1
- steven.lee94
- 发布于 2024-08-30 13:49
- 阅读 941
本文主要介绍了Thanos网络基础设施的优化过程。此前,Thanos使用EFS作为Elasticsearch和Prometheus的存储卷,但NFS速度较慢,导致查询性能不佳。新的架构通过将Elasticsearch迁移到EC2+EBS,并移除Prometheus的长期存储,显著提高了查询性能,并将每月成本降低了约192美元。并且介绍了Elasticsearch和Prometheus的配置细节。
Thanos 开发故事 — 1
Thanos 基础设施优化

TOP 项目团队计划在 12 月份推出 Thanos 主网,并在 7 月 1 日向世界揭晓了新的测试网络 Thanos-Sepolia。Thanos 网络解决了现有网络 Titan 之后的许多技术挑战。简要介绍如下。
Thanos 开发故事系列
- Thanos 基础设施优化
- L2 原生 Token 功能
- Thanos SDK
- 预部署合约: USDC Bridge
- 预部署合约: UniswapV3
- Thanos 网络的基础设施
- 网络升级: Span batch 和 Proto-danksharding
原生 token 支持
- Thanos 支持 TON(ERC-20) 作为网络的 gas token。
预部署 UniswapV3, USDC Bridge 支持
- Thanos 通过预先部署最基本的合约来支持它们。
优化的 SDK 支持
- Thanos 支持一个优化费用的 SDK,以帮助用户最小化他们用于存款和取款的费用。
Blob Batch 支持
- Thanos 可以使用 Blob 来减少 L1 数据费用。这可以灵活调整,以根据网络使用情况最小化 gas 成本。
Thanos 的开发故事由每个团队成员负责开发的部分组成,计划共包含 7 个故事。让我们首先从基础设施优化开始。
之前的架构
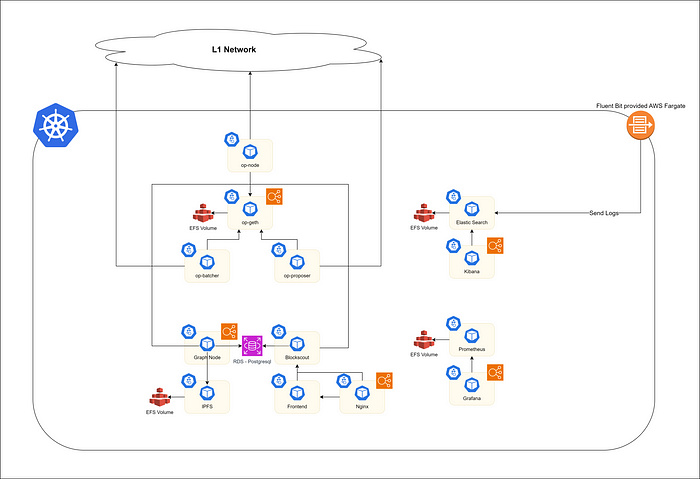
为了介绍一种新的改进架构,我们必须首先解释之前的架构是什么。之前的架构如上图所示。所有应用程序都在 Kubernetes 上运行,从中心向左的 pod 是核心网络 Pod。存在两个主要的系统来监控这些核心 Pod。一个是用于监控指标的 Prometheus 和 Grafana,另一个是用于收集日志的 Elasticsearch 和 Kibana。那么现有架构存在什么问题呢?
- EFS 被用作 Elasticsearch 中的卷。
- EFS 被用作 Prometheus 的卷。
如果你不知道为什么以上两件事是个问题,让我再解释一下。EFS 是 AWS 的 NFS 服务。NFS 是问题所在。默认情况下,Elasticsearch 和 Prometheus 不支持 NFS。准确地说,可以使用它,但它包含许多问题。最大的问题是 NFS 的速度慢。所有服务的日志和指标都需要存储,但 NFS 没有合适的存储速度。虽然 AWS 的 EFS 在 NFS 中速度非常快,但根据首尔地区的数据,它的写入速度限制高达约 1 GiBps (125 MB/s)。考虑到 SSD 的平均速度超过 1 GB/s,因此速度相差约 8 倍。事实上,通过 Kibana 查询 Elasticsearch 数据(约 3000 条日志数据)花费了 20 多秒。
新架构
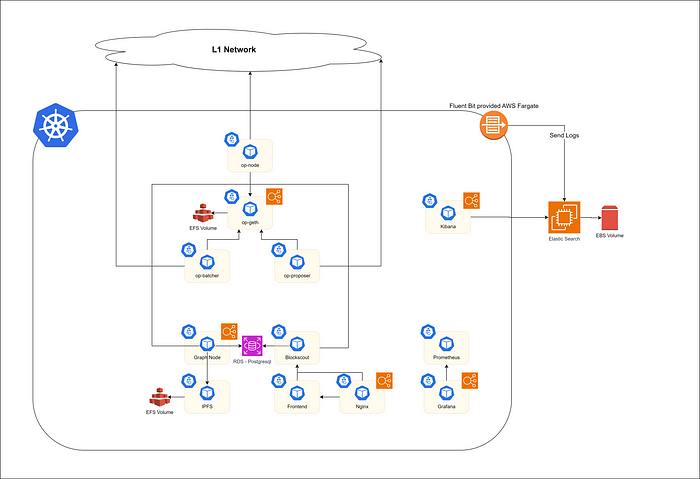
该项目通过 AWS 的审查创建了如上图所示的架构。以下是已更改的要点。
- 从集群中删除 Elasticsearch 并使用 EC2 + EBS
- 从 Prometheus 中删除存储
让我们从 Elasticsearch 开始。通过用 EBS 替换现有的 EFS,查询性能得到了显着提高。查询 3000 个 log_data 所需的时间已减少到不到 3 秒。考虑到 Elasticsearch 仅使用 EBS 卷类型 (gp3) 和 t3.medium 实例进行配置,这是一个令人惊讶的延迟。
Prometheus 最初在 EFS 中存储了一年的 Metric Data。但是,基于网络运营经验,我们了解到团队目前不需要过去的指标数据。因此,为了通过实时指标数据实现警报,我们决定使用 AWS Fargate 的临时存储(所有 pod 都在使用 Fargate 运行)来存储指标。
实现细节
Elasticsearch
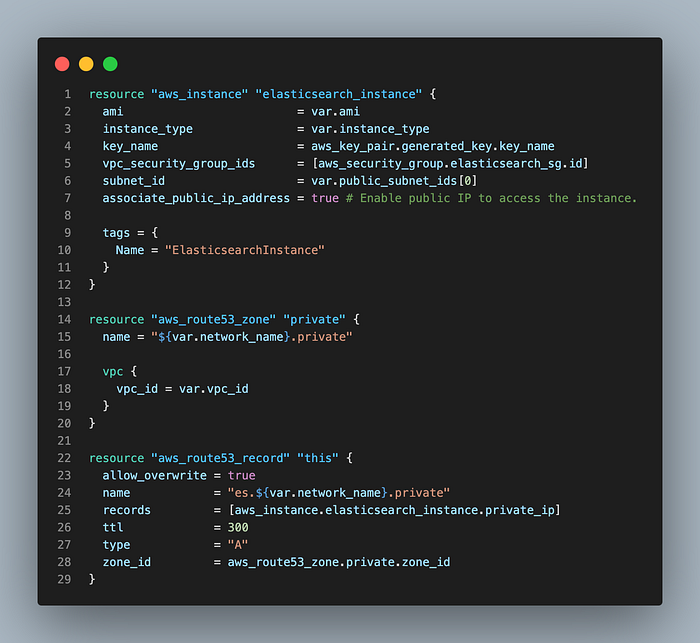
上图显示了用于创建 Elasticsearch 的 Terraform 代码中的 EC2 和 DNS 设置。在使用与 EKS 集群相同的 VPC 与 Kibana 通信时,注册了一个私有域并配置为进行通信。我们还注册了一个仅允许 VPC 内的内部 IP 的安全组。
resource "aws_route53_record" "es_record" {
zone_id = var.zone_id
name = "es.${var.domain}"
type = "A"
records = [
aws_instance.es_node.private_ip
]
ttl = 300
}
resource "aws_security_group" "allow_kibana" {
name = "allow_kibana"
description = "Allow traffic from kibana"
vpc_id = var.vpc_id
ingress {
description = "Allow traffic from internal subnet"
from_port = 9200
to_port = 9200
protocol = "tcp"
cidr_blocks = [var.internal_cidr]
}
}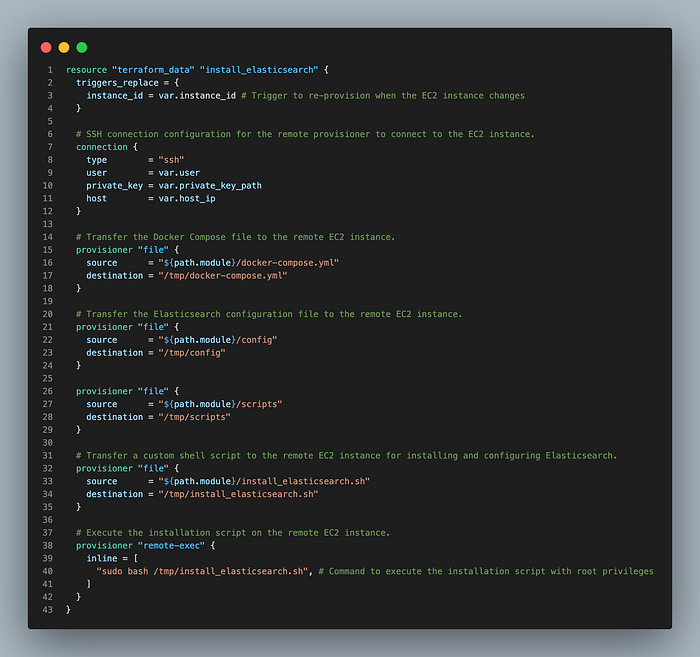
上面的代码显示了如何使用 Terraform 安装 Elasticsearch。通过 SSH 将命令发送到创建的 EC2 以安装 docker、挂载 EBS 并更新必要的权限。之后,通过 docker-compose 运行 Elasticsearch。
resource "null_resource" "install_es" {
depends_on = [
aws_instance.es_node
]
connection {
type = "ssh"
user = "ubuntu"
private_key = file("~/.ssh/ton-aws.pem")
host = aws_instance.es_node.public_ip
}
provisioner "remote-exec" {
inline = [
"sudo apt update",
"sudo apt install -y docker.io",
"sudo apt install -y docker-compose",
"sudo apt install -y awscli",
"aws ec2 attach-volume --volume-id ${var.volume_id} --instance-id ${aws_instance.es_node.id} --device /dev/sdf",
"sudo mkdir /data",
"sudo mount /dev/xvdf /data",
"sudo chmod 777 /data",
"sudo chown ubuntu:ubuntu /data",
"sudo tee /home/ubuntu/docker-compose.yaml << EOF\nversion: '3.8'\nservices:\n elasticsearch:\n image: docker.elastic.co/elasticsearch/elasticsearch:8.8.0\n container_name: elasticsearch\n environment:\n - discovery.type=single-node\n - xpack.security.enabled=false\n - vm.max_map_count=262144\n ports:\n - 9200:9200\n volumes:\n - esdata:/data\nvolumes:\n esdata:\n driver: local\n driver_opts:\n type: none\n o: bind\n device: /data\nEOF",
"docker-compose -f /home/ubuntu/docker-compose.yaml up -d"
]
}
}Prometheus
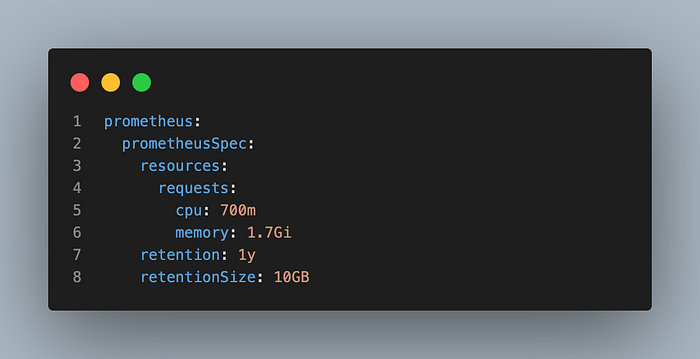
上图是 Prometheus 的 helm config。通过将 retentonSize 设置为 10GB,我们防止了由于存储空间不足而导致 Pod 被回收的情况(Fargate 临时存储提供 25GB)。
prometheus:
prometheusSpec:
retentionSize: 10GB结果
由于基础设施优化,我们能够进一步提高可用性,同时每月节省约 192 美元。详细结果可以在下面的页面上找到。
https://tokamak.notion.site/AWS-costs-after-improving-storage-aac435ec7b9649b596515fd0c6a0840c
结论
为了开发 Thanos 网络,该项目解决了许多基础设施和协议挑战。我希望在未来的开发故事中分享更多技术将对读者有很大帮助。谢谢。
- 原文链接: medium.com/tokamak-netwo...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
- 翻译
- 学分: 0
- 分类: 以太坊
- 标签: Thanos网络 基础设施优化 Elasticsearch Prometheus EBS EFS AWS





