嵌入式费用市场与ERC-4337(第二部分)- 经济学
- 以太坊中文
- 发布于 2024-09-06 21:57
- 阅读 871
本文探讨了ERC-4337账户抽象中用户在交易打包时面临的挑战,并提出了改进用户体验的方法。文章分析了当前ERC-4337的状态,探讨了其在Layer2的变体和签名聚合经济学,提出了几种Layer2解决方案以解决用户因缺乏mempool信息而导致的出价困难,包括使用预言机、共享排序器以及Layer2 खुद充当bundler等方案。
作者:Davide Rezzoli ( @DavideRezzoli) 和 Barnabé Monnot ( @barnabe)
非常感谢 Yoav Weiss ( @yoavw) 向我们介绍这个问题,Dror Tirosh ( @drortirosh) 对草案提出的有益评论,以及 4337 团队的支持。评论≠认可;所有错误均由作者承担。
这项工作是为 ROP-7 完成的。
介绍
在我们之前的文章中,我们介绍了 ERC-4337 模型。该模型概述了 bundler 的费用市场结构,并详细说明了与链上发布成本以及 bundle 的链下(聚合成本)相关的成本函数。
我们还介绍了“Bundler Game”的概念。这个游戏将是第二部分的主要焦点。给定一组交易,bundler 可以选择将哪些交易包含在其 bundle 中。这会在 bundler 和用户之间造成信息不对称,因为用户不知道将有多少交易包含在 bundle 中。这导致了一个零和博弈,用户明显处于劣势。
本研究旨在探索改进用户体验的方法,确保用户无需为包含在下一个 bundle 中而支付过高的费用。相反,用户应该能够根据实际的市场需求来支付费用。
ERC-4337 的当前状态
在当今的市场中,P2P mempool 尚未在主网上线,并且正在 Sepolia 测试网上进行测试。构建在 ERC-4337 上的公司目前以私有模式运营,用户通过 RPC 连接到私有 bundler,然后 bundler 将与 builder 合作以在链上发布你的 useroperation。Kofi 开发的 Bundle Bear 应用程序 提供了有关 ERC-4337 当前状态的一些有趣的统计数据。
在 每周 % Multi-UserOp Bundles 指标中,我们观察到创建包含多个 userop 的 bundle 的 bundler 的百分比。从 2024 年初到 2024 年 6 月,这个百分比没有超过 6.6%。当考虑到许多 bundler 运行自己的 paymaster(代表用户赞助交易的实体)时,这个数据变得更加有趣。值得注意的是,就已发布的用户操作而言,两个最大的 bundler 同时也作为 paymaster 运营,赞助了 97% 的使用其服务的用户操作。paymaster 支付 useroperation 的一部分,其余部分由 dApp 或其他实体支付。
由此产生的问题是,为什么 paymaster、dApp 等要为 useroperation 付费?用户将来会偿还他们吗?我们不能确定会发生什么,但我个人的猜测是,目前 dApp 正在支付费用以增加其应用程序的使用和采用。一旦采用率很高,用户可能必须自己支付交易费用。值得一提的是,对于用户来说,使用当前模型支付 useroperation 费用并不是最好的选择,因为一个基本的 ERC-4337 操作花费约 42,000 gas,而一个正常的交易花费约 21,000 gas。
ERC-4337 的变种
ERC-4337 概述
mempool 仍在 Sepolia 上进行测试,尚未在主网上线。如果没有 mempool,用户使用账户抽象的选择有限。用户与 RPC 交互,RPC 可以由 bundler 提供(捆绑 UserOp),也可以由不捆绑的 RPC 服务提供,类似于 Alchemy 或 Infura 等服务,这些服务接收交易并将其传播给其他 bundler。
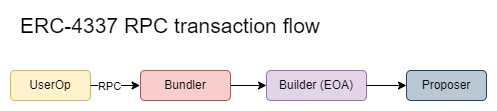
一旦 mempool 上线,交易流程将类似于下图,这与当前的交易流程类似。mempool 增强了用户的抗审查性,因为与 RPC 模型不同,它降低了交易被排除的可能性。然而,即使有 mempool,RPC 提供商仍可能不转发交易的风险,但 mempool 模型对于喜欢运行自己的节点的用户尤其有益,因为它减轻了这种风险。
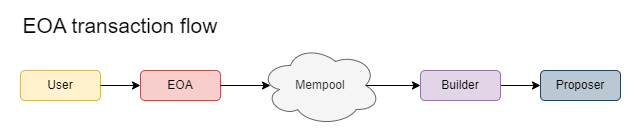
虽然 bundler 有可能充当 builder,但由于竞争格局,我们更倾向于将角色分开。Bundler 将面临来自现有、成熟的 builder 的巨大竞争,这使得构建吸引力降低,并且可能利润也更低。因此,bundler 更有动力与已建立的 builder 合作,而不是独立构建并冒着损失的风险。
将 bundler 和 builder 的角色合并为一个实体意味着对当前系统进行重大更改。Bundler 需要与现有的成熟 builder竞争,或者,当前的 builder 需要横向整合并承担 bundler 的角色。后一种情景虽然更合理,但会引发对市场集中度和对审查阻力的潜在负面影响的担忧。
Bundler 和 builder 作为两个不同的实体
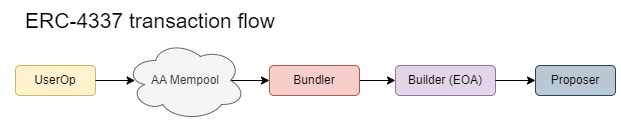
由于用户直接连接到 RPC,因此一切都在更私有的环境中运行,这无助于市场竞争。在不久的将来,mempool 将在主网上线,从而加剧竞争。
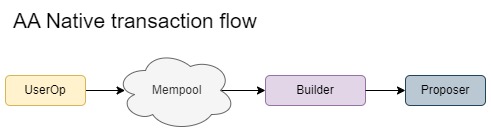
使用 mempool(其中 userop 对不同的 bundler 公开)会加剧竞争,在非原生账户抽象的情况下,需要将 bundler 和 builder 分开,在原生账户抽象的情况下,可能不需要这种分离,因为 builder 可以将 userop 解释为普通交易。
对于我们的模型,我们认为将 bundler 和 builder 分开也提供了一些优势,尤其是在竞争和抗审查方面。想象一下这样的场景:所有 bundler 都提供成本 \textbf{v}v 以包含在其 bundle 中。将会有一个 bundler 想要吸引更多用户以获得更高的利润,因此他们将提供成本 \textbf{v’}v’,其中 \textbf{v’} < \textbf{v}v’<v。在 bundler 之间有足够的竞争的情况下,\textbf{v'}v' 将接近 \omegaω,即 bundle 的聚合成本。在这种情况下,能够更有效地搜索并拥有更好的硬件以在 bundle 中包含更多交易的 bundler 将获得更高的费用,反过来又使用户的 useroperation 更便宜。
这可能导致以下结果:在竞争激烈的环境中,bundler 将降低其价格以被用户选中,而用户又将寻求以最低的价格将其 useroperation 包含在 bundle 中。这种竞争将创建一个系统,在该系统中,提供最佳价格的 bundler 将比仅试图通过创建较小 bundle 来最大化其利润的 bundler 更频繁地被选中。分离 bundler 和 builder 的角色还可以增强抗审查性。Bundler 可以创建一个聚合的 useroperation bundle 并将其发送给不同的 builder。如果 bundle 包含可能被审查的操作,则非审查 builder 可以接受它并继续构建。但是,值得注意的是,从用户的角度来看,这种设置可能会增加成本,因为 bundler 的引入会增加一个额外的参与方,从而导致更高的费用。
RIP-7560
原生账户抽象并不是一个新概念;它已经被研究多年。虽然 ERC-4337 正在获得关注,但其在协议之外的实现提供了独特的优势以及权衡。值得注意的是,现有的 EOA 无法无缝过渡到 SCW,并且各种类型的抗审查列表更难使用。如前所述,与正常交易相比,userOp 成本的 gas 开销显着增加。RIP-7560 本身不会解决当前关于链下成本的问题,但它会大幅降低交易费用。从最初的约 42000 gas,可以将成本降低约 ~20000 gas。
Layer2s 账户抽象
账户抽象可以在 Layer 2 (L2) 解决方案中使用。一些 L2 已经以原生方式实现了它,而另一些 L2 则遵循 L1 方法,并等待类似于 RIP-7560 的新提案。在 L2 中,L1 用于数据可用性以继承安全性,而大多数计算发生在 L2 上的链下,从而提供更便宜的交易和可扩展性。
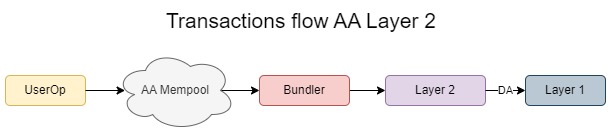
在 L2 上的计算成本远低于主链上数据可用性 (DA) 的 calldata 成本的情况下,signature aggregation 的使用被证明是非常有益的。例如,EVM 中的 0x08 预编译促进了主网上 BLS 的配对,其成本约为 ~45000k gas。因此,在 L1 上使用 BLS 比传统交易更昂贵。
L2 上的压缩技术已经被使用,例如 0 字节压缩,它将 ERC20 转账的成本从约 188 字节降低到约 154 字节。通过 signature aggregation,可以使用单个签名进一步提高压缩效率,从而将大小减少到约 128 字节。
在 Layer 2 中,signature aggregation 是一项至关重要的创新,它可以提高交易效率和成本效益。通过将多个签名合并为一个签名,可以显着减少整体数据负载,从而降低与 Layer 1 上的数据可用性相关的成本。这种进步不仅提高了可扩展性,还降低了用户的交易成本,使系统更经济、更高效。
Layer2s 中 Signature Aggregation 的经济学
当使用 L2 服务时,用户会产生一些成本,包括 L2 运营商的费用、基于网络拥塞的成本以及 L1 上的数据可用性成本。
从之前关于“从第一性原理理解 rollup 经济学”的研究中,我们可以概述用户在使用 L2 服务时面临的成本如下:
当用户与 layer 2 交互时,他会产生一些成本,我们可以将其定义如下:
- 用户费用 = L1 数据发布费用 + L2 运营商费用 + L2 拥塞费用
- 运营商成本 = L2 运营商成本 + L1 数据发布成本
- 运营商收入 = 用户费用 + MEV
- 运营商利润 = 运营商收入 - 运营商成本 = L2 拥塞费用 + MEV
在非原生账户抽象的情况下,额外的实体 bundler 可能会引入费用以创建 userop 的 bundle。
考虑到 bundler,成本和利润扩展如下:
- 用户费用 = L1 数据发布费用 + L2 运营商费用 + L2 拥塞费用 + Bundler 费用
- Bundler 成本 = Quoted(L1 数据发布费用 + L2 运营商费用 + L2 拥塞费用)
- Bundler 收入 = 用户费用
- Bundler 利润 = Bundler 收入 - Bundler 成本 = L1 和 L2 成本之间的差额以及 bundler 的报价 + Bundler 费用
- 运营商成本 = L1 数据发布费用 + L2 运营商费用
- 运营商利润 = 运营商收入 - 运营商成本 = L2 拥塞费用 + MEV
bundler 从用户那里获得服务费用,而用户支付的剩余款项则用于支付 L2 运营商的成本。如果用户不知道 bundle 的大小,那么估算发送 userop 的实际成本将变得具有挑战性,这可能会导致 bundler 收取的费用高于支付运营商成本所需的费用。
L2 中的激励对齐
bundler 和 L2 之间的交互有助于解决这个问题,因为 L2 有动力保持较低的用户成本,因为存在竞争。向用户收取过高的费用可能会促使他们切换到提供更公平价格的其他 L2。
让我们通过引入运营商来重新定义我们的模型。用户通过竞标值 VV 向 bundler 竞标以包含在下一个 L2 块中。用户旨在最小化数据发布费用,而 bundler 寻求最大化其费用或从 L2 交互成本和用户费用中获得盈余。
创建 bundle 并将其发布在链上的相关成本可以分为两部分:
链上成本函数: 当基本费用为 rr 时,发行 bundle \mathbf{B}B 的 bundler 的支出成本为:
C_\text{on-chain}(\mathbf{B}, r) = F \times r + n \times S \times r
Con-chain(B,r)=F×r+n×S×r
聚合成本函数: bundler 具有将单个 bundle \mathbf{B}B 中聚合 nn 笔交易的成本函数,基本费用为 rr:
C_\text{agg}(\mathbf{B}, r) = F' \times r + n \times S' \times r + n \times \omega
Cagg(B,r)=F′×r+n×S′×r+n×ω
其中 S' < SS′<S 是交易大小的缩减,预验证 gas 使用量 F' > FF′>F,其中包括单个链上聚合签名的发布和验证。
如果用户可以获得 nn 的可靠估计,他们可以使用 estimateGas 函数(大多数 L2 解决方案中都可用)来计算其成本。拥有良好的估计可以使用户相应地出价,而不必高估其包含在内的出价。良好地估计 nn 和 estimateGas 函数可以避免用户支付更高的 preVerificationGas 费用。在下一节中,我们将探讨各种机制,以确保对 nn 进行可靠的估计。
Layer2s 运行一个预言机
预言机的角色是监视 mempool 并估计存在的交易数量。该过程如下:Layer 2 部署一个预言机以检查 mempool,然后告知用户 mempool 中的交易数量。这使用户能够估计其包含在 bundle 中的出价。Layer 2 可以请求 bundler 在 bundle 中至少包含指定数量的交易 (nn),否则该 bundle 将被拒绝。一旦 bundler 收集到足够的交易以形成 bundle,它会将 bundle 发送到 Layer 2,然后 Layer 2 将其作为 calldata 转发到主网以实现数据可用性。
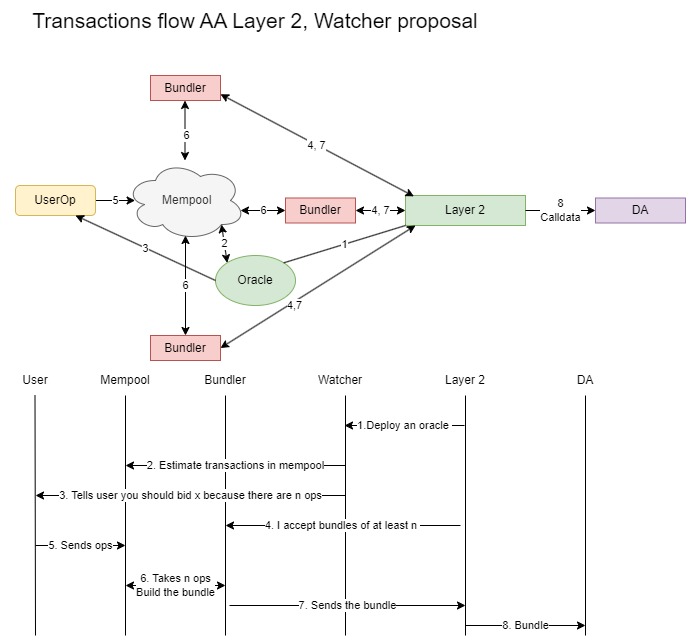 \
Watcher 提案691×642 47.4 KB
\
Watcher 提案691×642 47.4 KB具有共享排序器的 Layer2s
一个有趣的方法是让多个 Layer 2 (L2) 网络运行一个共享排序器。由于排序器通过共享排序器促进的共识达成协议,因此这种设置可以提供对 mempool 的更准确估计。
在这种配置中,不同的 L2 网络独立运行,但共享一个公共排序器。这些网络定期检查共享 mempool 中的 user operation (userop) 数量。共享排序器有助于同步和聚合来自这些网络的数据。一旦他们达成协议,信息就会传达给用户,从而允许他们根据存在的 userop 数量进行出价。
这种方法提供了几个优点。首先,它提供了一种去中心化的方法来确定 mempool 中的 userop 数量,从而增强了对勾结的抵抗力。其次,它消除了如果只有一个系统管理用户和 mempool 之间的通信时可能发生的单点故障。第三,共享排序器确保了一致性并减少了不同 L2 解决方案之间的差异。
通过利用共享排序器,此方法确保了一个强大而可靠的系统,用于估计 mempool 的状态并将其传达给用户,从而提高了流程的整体效率和安全性。
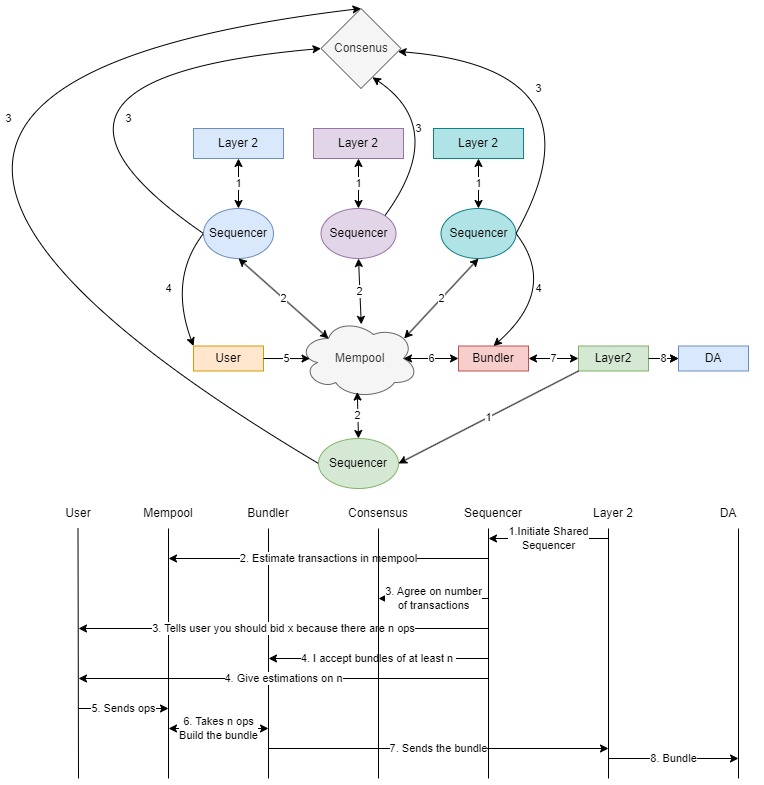 \
共享排序器764×785 66.3 KB
\
共享排序器764×785 66.3 KB在两个通过使用预言机解释的方法中,存在一个潜在的攻击向量,即攻击者可能会在 mempool 中生成多个 user operation,知道如果将它们聚合在一起,它们将恢复。结果,预言机看到有 nn 笔交易并需要一个大的 bundle,但 bundler 无法创建该 bundle。这个问题可能会使网络停顿多个区块。
Layer2s 运行自己的 bundler
在此提案中,Layer 2 本身承担 bundler 的角色,而另一个实体处理签名的聚合(这可能是当前的 bundler 服务)。该过程如下:Layer 2 运行自己的 bundler,用户将其 operation (userop) 发送到 mempool。Layer 2 从 mempool 中选择一些这些 userop,并将它们“原始”发送到聚合器,补偿聚合器以聚合签名。一旦聚合器生成 bundle,它将 bundle 发送给 bundler,然后 bundler 将其作为 calldata 转发到主网以实现数据可用性。
主要思想是 Layer 2 处理 userop 的收集,然后将聚合外包给另一个实体。Layer 2 支付聚合费用并向用户收取服务费。
有两种不同的选择:
- 固定费用模型: bundler(排序器)选择一些交易并向用户收取固定费用。此固定费用的计算方式类似于当前的 Layer 2 交易,预测 L1 数据发布的未来成本。或者,Layer 2 可以根据捆绑 nn 个聚合 userop 的成本向用户收取固定费用,layer 2 仍然必须预测他将构建的 bundle 中将有多少笔交易才能正确地向用户报价,这可以以相同的方式进行,即 l2 向用户收取最佳竞争价格,即 Layer 2 最好尽可能保持用户价格的竞争力。
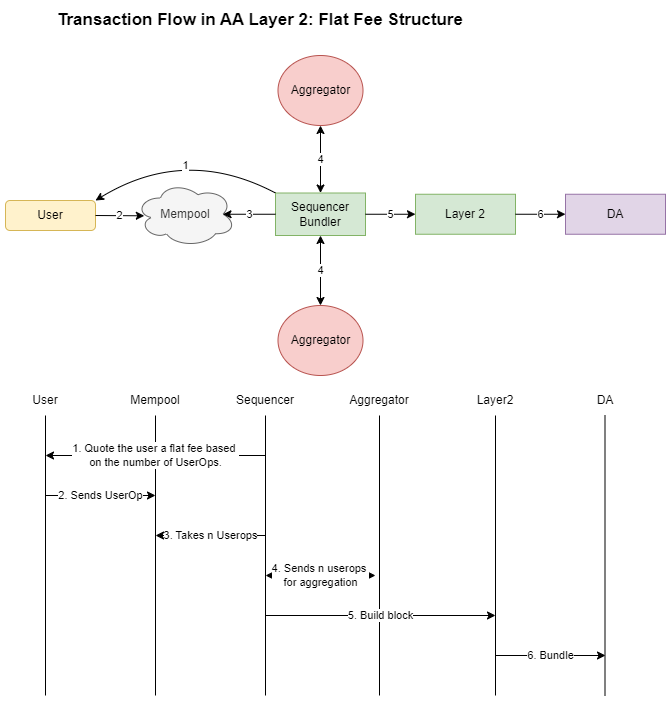 \
固定费用671×702 22.1 KB
\
固定费用671×702 22.1 KB- 请求退款: 如果 Layer 2 想要提高其可信度,它可以启用自动退款。这将涉及一种机制,该机制检查单个区块中发布了多少 userop,以及交易是否可以聚合。如果本可以聚合的 userop 没有聚合,并且没有发出自动退款,则用户可以请求退款。在这种情况下,Layer 2 可以抵押一些资产,如果未提供退款,则用户可以强制执行退款,从而确保公平性和责任性。
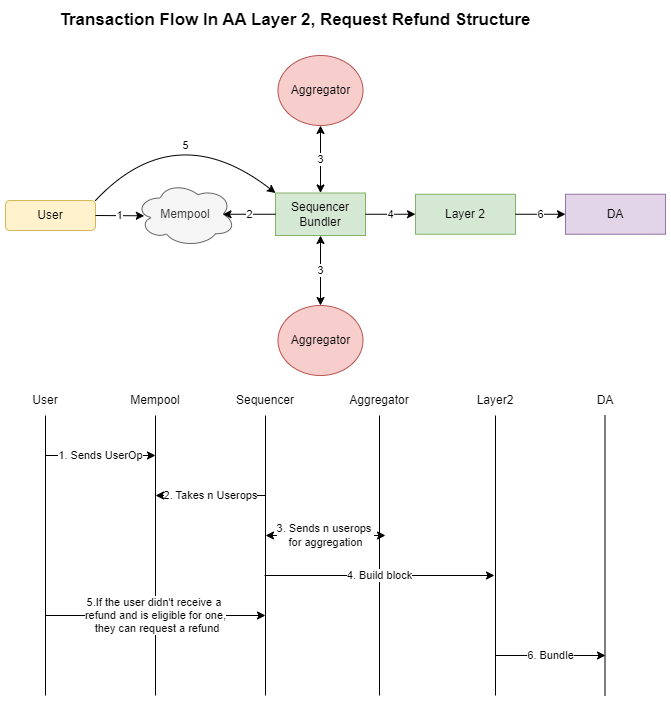 \
请求退款671×702 22.8 KB
\
请求退款671×702 22.8 KB结论
在这两篇不同的文章中,我们概述了用户在竞标被包含在下一个 bundle 中时遇到的困难。在第一部分中,我们介绍了 ERC-4337 模型,解释了 bundler 在链上发布 bundle 时产生的成本以及相关的链下成本。我们还概述了 bundler 的费用市场,并开始讨论格式化 bundler 的问题。由于缺乏关于捆绑时 mempool 中存在的交易数量的知识,用户在竞标时会遇到困难。
在第二部分中,我们解释了 ERC-4337 和 RIP-7560。然后,我们讨论了为什么 signature aggregation 更有可能发生在 Layer 2 解决方案上,而不是直接发生在 Layer 1 上。我们展示了 Layer 2 解决方案如何以不同的方式解决用户遇到的不对称知识问题。第一个是使用预言机向用户发出信号,告知 mempool 中有多少笔交易,通过这种方法,用户知道他们应该出价多少,并且可以强制 bundler 制作更大的 bundle。第三种方法是最简单的,即 L2 充当 bundler 并将聚合外包给第三方,并让用户为此支付费用。
- 原文链接: ethresear.ch/t/embedded-...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





