2025年将PeerDAS推向主网之路
- sigmaprime
- 发布于 2025-06-27 18:39
- 阅读 1100
文章讨论了PeerDAS在Fusaka升级中发布的可能性,并提出了一系列关键问题,包括规范冻结、安全发布范围以及发布前的必要步骤。文章还建议根据Lighthouse团队的测试结果,设定一个更现实的目标blob数量,并尽早冻结规范,以便团队可以专注于将当前实现投入生产。
只是想分享一些关于今年发布 PeerDAS 可能需要做的事情,以及我们如何尽快在范围和时间线上达成一致的想法。
当前的 PeerDAS 实现已经经历了漫长的开发周期和多次规范迭代。它并不完美(也永远不会完美),但没关系——这并非 blob 扩容的最终形式。在 Fusaka 之后,我们可能会继续对其进行改进。
我们已经到了这样一个阶段:进一步的改进开始与发布现有成果的价值相竞争。如果不划定界限,我们可能会将其变成技术债务——或者更糟,浪费工作。
随着Pectra的成功发布,焦点已经转移到Fusaka,PeerDAS的测试也在加速进行。随着测试的加速和更多人的参与,这为更多的想法和继续改变规范的诱惑打开了大门。
虽然新的想法令人兴奋,但我认为现在是我们认真规划范围并冻结规范的时候了。如果我们想在今年发布——我个人非常希望如此,考虑到 PeerDAS 已经开发了这么长时间——我们需要立即在范围和计划上达成一致,即使它不是“完美的”。
三个关键问题
为了向前推进,我们应该尽快尝试回答以下问题:
- 我们今天可以冻结规范吗?如果不能,还缺少什么?
- 我们可以在 Fusaka 和后续的 BPO 分叉中安全地发布多少扩容?即使它低于 PeerDAS 的理论极限(72 个 blobs),它仍然有价值。
- 在发布此版本之前必须完成哪些工作?哪些改进可以等到分叉之后或下一次分叉之后?
如果我们能在这些问题上达成一致,我们就可以为 Fusaka 制定一个明确的时间表,并专注于使 PeerDAS 准备就绪——而不是进行更多轮的设计。
改进提案
有很多很棒的改进正在讨论中。我可能遗漏了一些,但这里有一些类别以及它们可能如何适应:
libp2p改进:更低的延迟,更低的带宽。对于高 blob 计数的未来来说非常棒,但可以在 Fusaka 之后进行。我们甚至可以安排 BPO 来随着网络改进而增加 blob 计数。- Partial
getBlobsV2responses:对于完整的 DAS 很有用,并且可能是必要的,但我们需要一个临时版本吗,还是我们应该稍后直接全面采用完整的 DAS?我们需要考虑增加的复杂性,并权衡其收益。也可以在分叉之后引入该标志。现在更改默认行为可能需要规范更改、实施和测试周期——这种努力往往被低估。 - Engine APIs 中的 SSZ 支持:从性能的角度来看是有意义的,但可能不是 Fusaka 的关键。
- 还有很多其他的...
这些都值得为即将到来的分叉进行计划,但除非其中一个被证明是一个明显的阻碍,否则它们不应该阻碍 Fusaka。
我们的看法
对于 Lighthouse 来说,一旦验证者托管回填完成,我们主要关注的是:
- 同步性能和弹性
- 识别和修复性能瓶颈(例如,gossip 验证)
- Bug 修复和测试周期
我不能代表 EL 说话,但我认为其他 CL 客户端的情况可能也类似。
Sunnyside Labs 的测试表明,在 72 个 blobs 左右时,网络会不稳定,这非常有帮助。更深入地研究这些指标,Lighthouse 实际上并没有达到该水平的性能——我根据他们在附录部分中的指标做了一个快速分析。
我认为,与其花费时间尝试达到 72 个 blobs,不如将一个更现实的数字(即今天已经可以工作并且有一定余量的数字)作为目标并使其更加稳健。这使我们更有可能在今年发布 PeerDAS。它仍然可以带来真正的好处,并且感觉更容易实现。
以下是 Lighthouse 团队目前的想法:
- 规范冻结:是的,除非发现任何关键问题
- 暂定 目标规模:使用最多 18 个 blobs(2 倍于 Pectra)启动 Fusaka,并安排一个 BPO 分叉将其增加到 24 个 blobs。在 Mainnet 上观察,并在我们拥有真实数据后考虑进一步的 BPO 分叉。
- Mainnet 准备情况:所有主要客户端都稳定地支持私有 blobs + MEV 流,已证明可以从非最终性中恢复,并且具有足够的同步性能。
如果我们能尽快冻结规范(包括 blob 计划),团队就可以完全专注于使当前的实现达到生产就绪状态。
计划
这是一个粗略的时间表,可以从 2025 年 10 月中旬的 mainnet 发布倒推:
- 十月中旬 - Mainnet 分叉
- 八月中旬 - 开始公共测试网
- 七月中旬
- 私有 blobs + MEV 流测试
- 非最终性测试
- 七月初(可能在下一次 ACD 中?)
- 启动
fusaka-devnet-2 - 决定是否冻结规范
- 决定是否制定一个暂定的 blob 计划:
- 选择一个用于测试和生产目标的最大 blob 计数——理想情况下是今天就可以工作的,这样我们就可以专注于同步和边缘情况
- 定义一个通往该最大 blob 计数的 blob 计划并坚持执行
- 启动
我认为,按照目前事情的进展方式,这可能看起来相当紧张,但如果我们可以迅速达成一致并专注于 Fusaka 的范围,我认为这并非不切实际。
结论
我想要传达的主要观点是:如果我们认为今年发布 PeerDAS 至关重要,那么我们真的需要专注于加强当前的实现。这意味着收紧范围并尽快冻结规范。
请记住,即使是微小的更改也会分散注意力并导致延迟——从规范更新到额外的测试周期——而且我们经常低估所涉及的时间和精力。我认为,从现在开始,我们应该专注于让客户端实现生产化。
在没有足够真实数据的情况下最终确定 blob 计划可能有点冒险,但制定一个暂定的目标来围绕其进行测试仍然非常有帮助。现在最主要的是尝试回答上述三个关键问题,并确保我们迅速达成一致。
感谢大家在整理此文档时进行的审阅和分享的有价值的反馈——特别是 Pawan、Francesco 和 Lighthouse 团队的其他成员,以及 Sunnyside Labs 团队的 devnet 工作。如果我遗漏了任何内容,请告诉我——我很想听听大家的想法,并了解时间表的可行性。
附录
本节是对 Sunnyside Lab 最近发布的关于 Devnet-1-Mixed devnet 的测试报告的快速分析,该 devnet 包括混合客户端,最大 blob 计数为 128。
网络似乎可以维持到 72 个 blobs 左右。但是,更深入地研究,指标 beacon_block_delay_attestable_slot_start 在 2025-06-13 23:16:00 左右的超级节点上超过 4 秒:
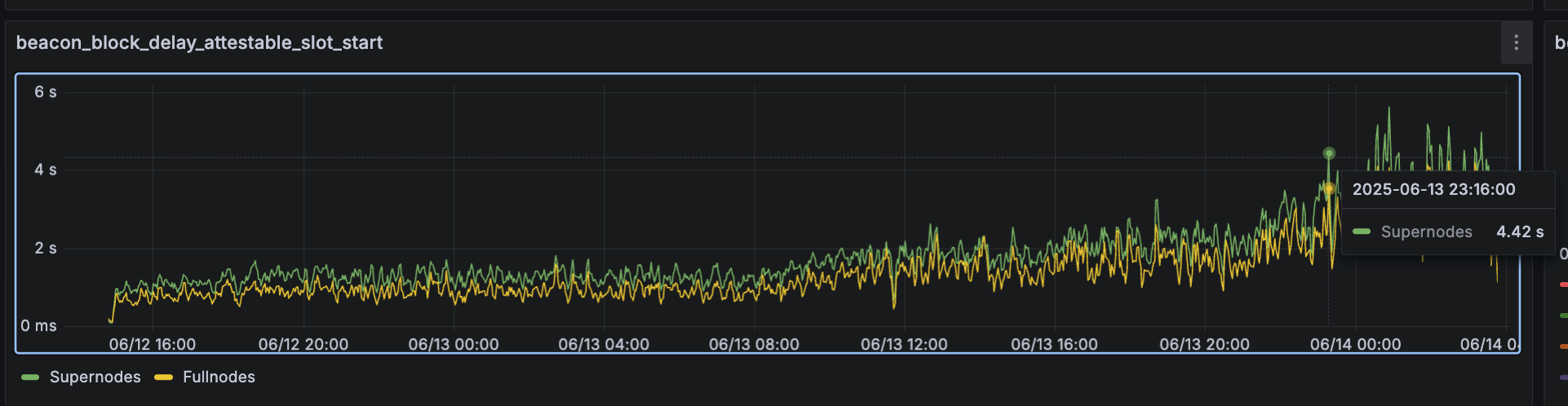
那时,blob 计数约为 70。虽然网络没有崩溃,但这表明共识性能可能已经在下降 - 因此可能需要大量工作才能安全地扩展到 70 个 blob。
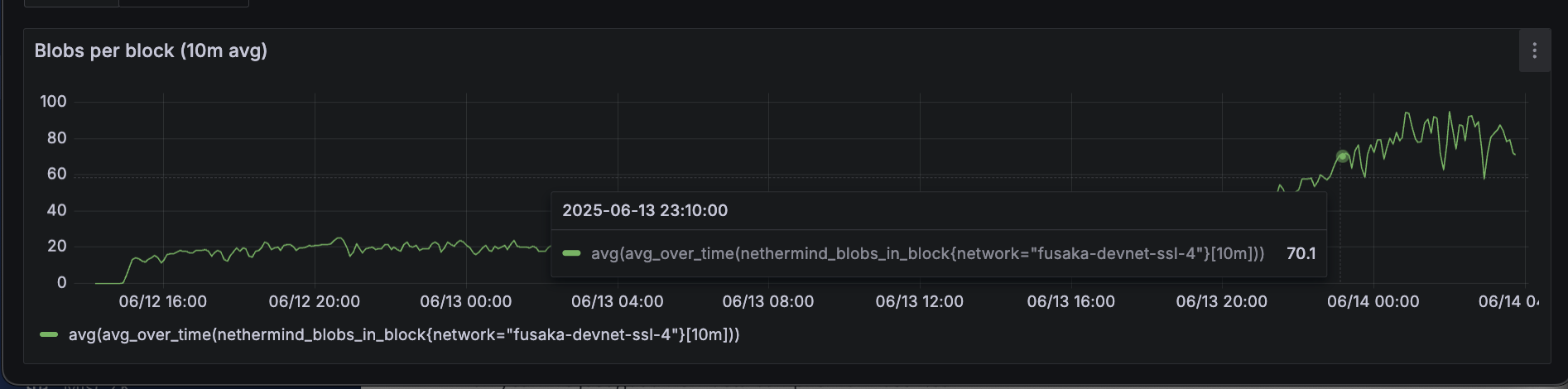
我们应该以什么 blob 计数为目标?
基于以上信息,现在以 72 个 blobs 为目标似乎太高了。beacon_block_delay_attestable_slot_start 指标是关键,因为如果它超过 4 秒,节点将不会证明该区块。
在 Mainnet 上,此延迟通常约为 2-3 秒。确定延迟开始超过该阈值的 blob 计数将很有用。
在这个 devnet 上,直到 2025-06-13 18:30 左右,趋势一直保持不变,之后我们开始看到一些超级节点的平均值高于 3 秒:
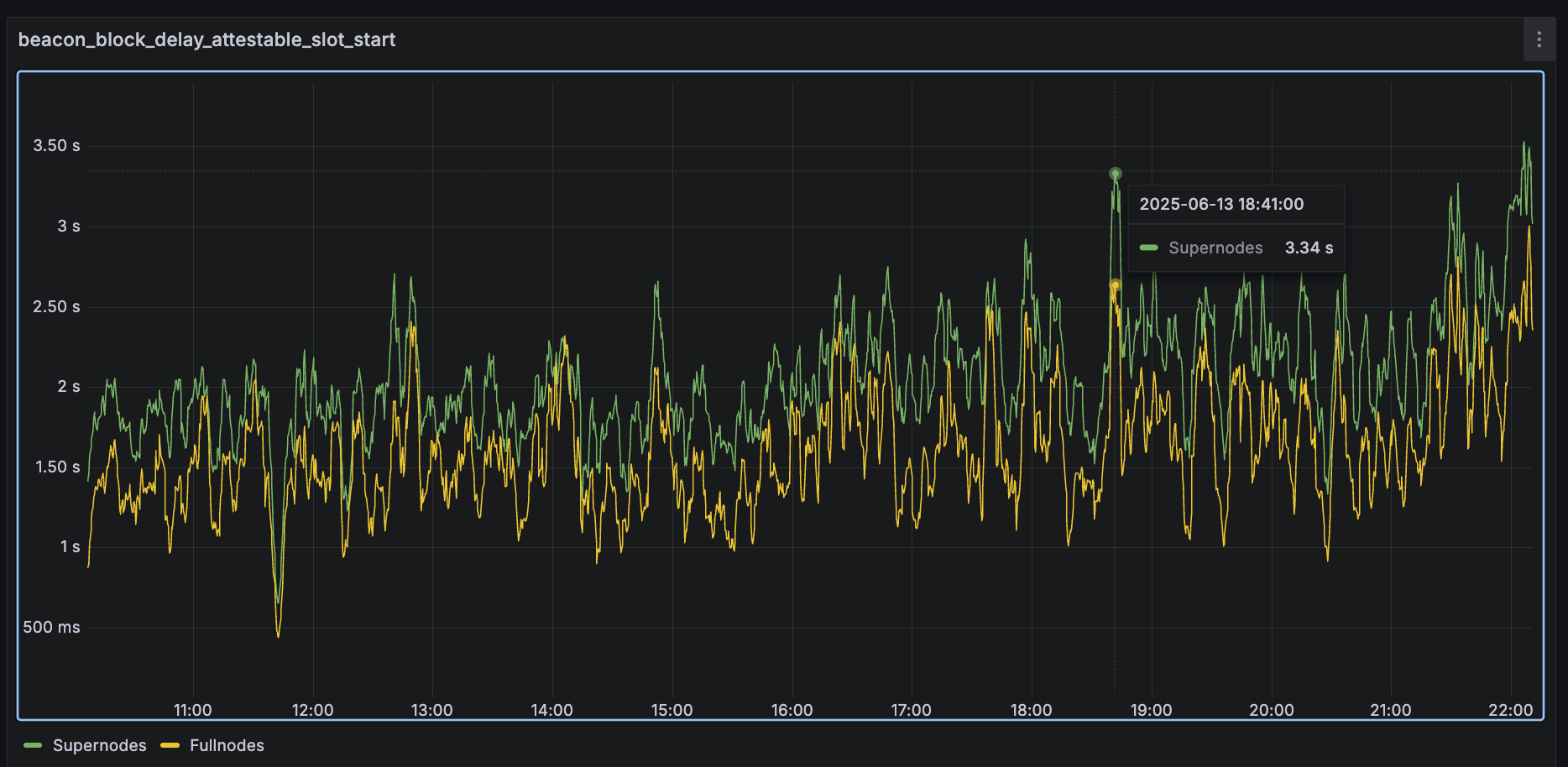
在那个时间点,区块达到大约 50 个 blobs:
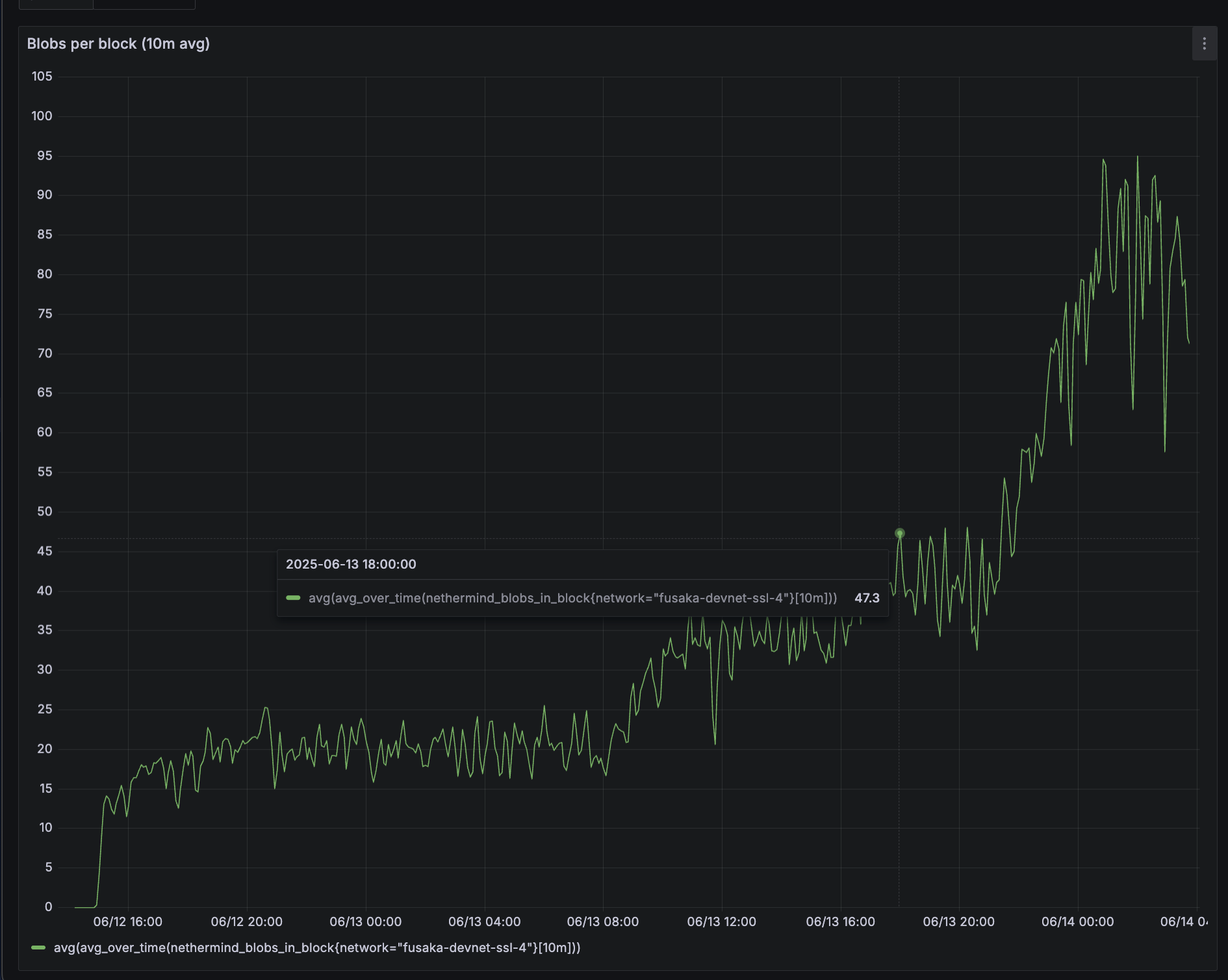
这当然是一个非常粗略的估计,并且基于一个小的 devnet。但就目前而言,瞄准低于 50 的某个值(在 Fusaka BPO 分叉中留有足够的余量)感觉是一种更现实和更安全的方法。
- 原文链接: blog.sigmaprime.io/shipp...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





