Ivy AST 解释器第一篇:Vyper的语法、语义及 为什么构建 AST
- cyberthirst
- 发布于 2025-09-15 10:34
- 阅读 1437
本文是关于Vyper AST解释器系列文章的开篇,介绍了作者开发的Ivy工具,一个用Python编写的Vyper AST解释器,旨在提供Vyper语言的可执行规范。文章解释了编程语言实现中的核心术语,如语法、语义、AST,并阐述了Ivy在其中的作用,以及选择AST而非IR或字节码的原因。
本文开启一个关于 Vyper 的 AST 解释器的系列。我构建了 Ivy,一个 Vyper 的 AST 解释器,目标是用 Python 编写一个易于阅读的语言的可执行规范。Ivy 主要用作 Vyper 编译器差异测试的模糊测试 Oracle。在这一部分,我们将建立编程语言实现的核心术语。实际的解释器设计将在后面的部分中介绍。
语法与语义
首先,让我们来谈谈语法和语义。程序表示以字符串开始,这是编译器的输入。在编译的第一阶段,这个字符串被转换成所谓的 tokens (例如 IF 或 FOR tokens)。语法规则规定了程序如何被构造,即哪些 token 序列是有效的。这些规则通过语法来定义。语法是一组递归的产生式规则,它规定了如何产生符合语法的代码。
parser 检查 token 序列是否符合语法,并构建一个树状结构。
假设语法规则:IfStmt → 'if' Expr ':' Body ('else' ':' Body)?,它表示:要生成一个 if 语句,你必须首先生成 if token,然后是一个表达式,然后是一个冒号 token,等等。例如,序列 if if a > b: body 是无效的。问题在于语法要求 if token 后面跟着 <Expr>,而第二个 if 不是一个表达式。
编译器的示例输入字符串:
def foo(i: bool):
a: uint256 = 0
if i:
a = 42
以及相应的词法分析器 tokens 的切片:
1: NAME 'def' (1,0)-(1,3)
2: NAME 'foo' (1,4)-(1,7)
3: OP '(' (1,7)-(1,8)
4: NAME 'i' (1,8)-(1,9)
5: OP ':' (1,9)-(1,10)
6: NAME 'bool' (1,11)-(1,15)
7: OP ')' (1,15)-(1,16)
8: OP ':' (1,16)-(1,17)
9: NEWLINE '\n' (1,17)-(1,18)
语法给出了结构,语义给语法元素赋予意义。语义通常分为两种类型:静态和动态。静态语义在编译时由编译器强制执行。编译时检查包括类型检查、作用域、名称绑定或者存储与内存规则。
动态语义则定义了当你执行一个具有有效静态语义的程序时实际会发生什么。它定义了在循环中执行一步意味着什么,评估顺序是什么,比较运算做什么,或者 gas 效应是什么。
例如,if 语句的一个动态规则是:评估 cond;如果它产生 true,则执行 body;否则执行 orelse 或者在 if 之后继续。
Ivy 位于何处? Ivy 将词法分析、解析和静态检查委托给 Vyper 编译器前端,然后解释类型化的 AST 来模拟动态语义。如果前端存在错误,那么 Ivy 也会受到影响。我们评估了哪些类型的错误是严重的,以及它们出现在编译器的什么位置,并得出结论:大多数错误都出现在动态语义部分。
什么是 AST?
Ivy 是一个 AST 解释器,那么什么是 AST 呢?编译器分阶段工作。首先,它们运行 lexer,将输入字符串(你的程序)转换为 tokens。然后运行 parser。parser 检查 token 序列是否满足语法的规则,并使用语法将 token 序列转换为抽象语法树。之所以说是抽象的,是因为没有冗余的语法,比如空格或语法糖。
对于 Vyper,AST 的根是 Module 节点。模块将有一个主体。主体可能包含像 VariableDef 这样的节点(用于存储或不可变变量),或者 FunctionDef 节点;这些节点递归地包含语句和表达式,直到像字面量和变量引用这样的叶子节点。
在 AST 经过编译器前端之后,节点具有:
- 一个由 parser 分配的节点种类 (例如,
Call(func, args, keywords)用于函数调用), 并且 - 一个由类型检查器分配的推断语言类型 (例如,
int8)。
对应于示例程序的 AST:
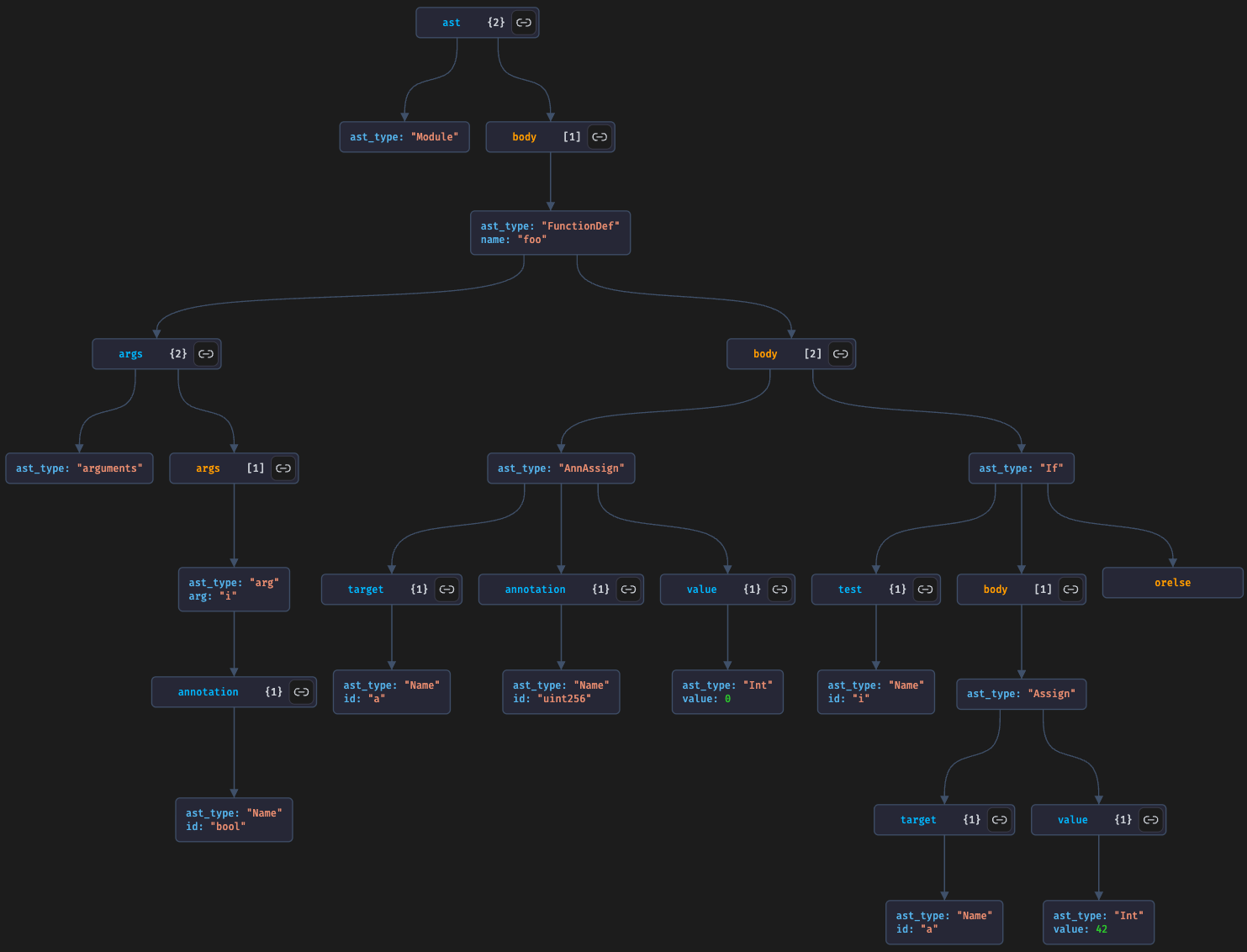
为什么不用 IR 或字节码?
那么,我们为什么要解释 AST 呢?1) AST 非常接近源代码,并且 2) 它很容易。Ivy 的目标之一是成为可执行规范 - 通过解释 AST,我们可以在每个语法结构及其语义之间建立清晰的对应关系。如果我们降低 AST 的级别,例如降低到字节码,这种对应关系就不会那么清晰了。此外,将 AST 转换为字节码并非易事,并且会增加开发时间并引入错误。
为什么许多生产环境中的解释器使用字节码而不是 AST?主要是性能。AST 富含指针且是异构的:遍历它们会损害局部性原理,并导致频繁的缓存未命中,页面访问也会累积。字节码是线性的和紧凑的,这种结构更适合高性能。
在 Ivy 中,我们不需要速度,我们只追求正确性,因此 AST 是理想的表示形式。
语句与表达式
语句和表达式是所有程序的基本构建块。这些概念稍后会派上用场,所以我现在就解释一下。通常,所有 AST 节点要么是语句,要么是表达式。函数定义是一个语句,if 节点或 for loop 节点也是如此。
程序由语句和表达式组成。语句是一种不向其周围环境产生值的语法形式;它对计算进行排序或引入绑定(例如,a: uint256 = 10)。表达式评估为一个值,并且可以出现在需要值的地方(例如,1、a、foo(42) // 12)。
我所说的 AST 解释器是什么意思?
在本系列中,AST 解释器是一个 Python 程序,它遍历 Vyper 的类型化 AST,并根据 嵌入在 EVM 模型中的 Vyper 的动态语义 来执行操作。
存在一些实际问题:
- EVM 没有 Vyper AST 的概念。我们将不得不把字节码解释切换至 Vyper AST 解释。
- Vyper 语义存在于 EVM 语义中。Vyper 中的外部调用对应于 EVM 消息调用。为了保持忠实性,Ivy 必须对 EVM 进行足够的建模,以使这些交互有意义(账户、存储、日志、调用栈、返回数据)。
因此,Ivy 必须为 Vyper 构造(如循环或赋值语句、存储模型或对内置函数的调用)赋予精确的含义,并将它们连接到 EVM 概念(账户创建、调用、日志、回滚和返回)。本系列的后续内容将讨论这方面的实际问题。
结尾
我们涵盖了要点:tokens → 语法 → AST(语法),静态 vs 动态语义(含义),为什么 Ivy 解释 AST(正确性和清晰度),以及语句与表达式的角色。下次我们将深入了解 Ivy 解释器的内部结构。
- 原文链接: hackmd.io/@cyberthirst/r...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





