NVIDIA GB200互连架构分析 - NVLink、InfiniBand及未来趋势
- naddod
- 发布于 2024-11-21 17:51
- 阅读 3816
文章详细介绍了NVIDIA NVLink的带宽计算方法,对比了NVLink 4.0和5.0的互连带宽,并深入探讨了GB200 NVL72及NVL576的架构设计,解释了NVLink与InfiniBand在数据中心和高性能计算系统中的关系与应用,以及铜互连和光互连的选择分析。
1. NVLink 带宽计算
NVIDIA在NVLink传输带宽以及SubLink/Port/Lane概念的计算上存在很多混淆。通常,单个GB200的NVLink 5带宽为1.8TB/s,这是由面向带宽的人员以字节/秒(Byte/s)为单位计算的。然而,在NVLink交换机或IB/以太网交换机和网卡上,Mellanox的视角是根据传输的数据位,以比特/秒(bit/s)为单位计算网络带宽。
在这里,我们将详细解释NVLink的计算方法。从NVLink 3.0开始,它由四个差分对组成,形成一个“sub-link”(通常被NVIDIA称为Port/Link,定义上有些含糊)。这4对差分信号线同时包含信号线的接收和发送方向。通常,在计算网络带宽时,一个400Gbps接口指的是同时以400Gbps传输和接收数据的能力,如下图所示:
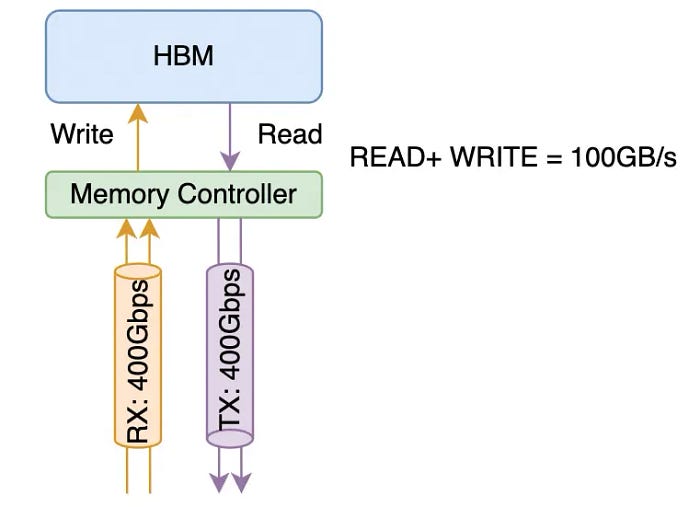
它由总共4对差分信号线组成,每对都有RX/TX。从网络的角度来看,这是一个单向400Gbps的链路,而从内存带宽的角度来看,它支持100GB/s的内存带宽。
1.1 NVLINK 5.0 互连带宽
在Blackwell这一代中,使用了224G Serdes,这意味着每个sub-link的传输速率为200Gbps * 4 (4对差分线) / 8 = 100GB/s。从网络的角度来看,单向带宽为400Gbps。一个B200包含总共18个sub-link,从而产生100GB/s * 18 = 1.8TB/s的带宽。从网络角度来看,这相当于9个单向400Gbps接口。类似地,在NVSwitch的介绍中,声明了双200Gb/sec SerDes形成一个400Gbps端口。

为了方便后续章节的讨论,我们为这些术语提供以下统一的定义:
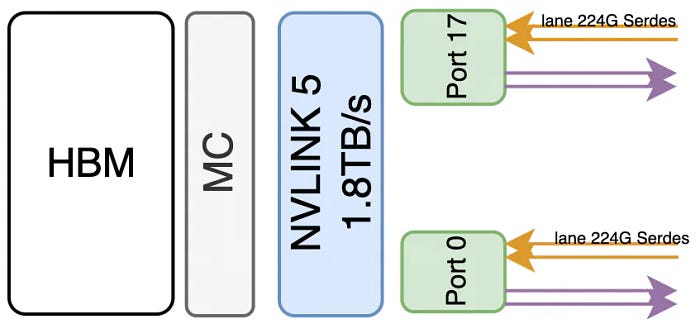
B200的NVLINK带宽为1.8TB/s,由18个端口组成,每个端口的带宽为100GB/s。每个端口包含四对差分线,包括两组224Gbps Serdes(2x224G PAM4,从网络接口的角度计算,每个端口的单向带宽为400Gbps)。
1.2 NVLINK 4.0 互连带宽
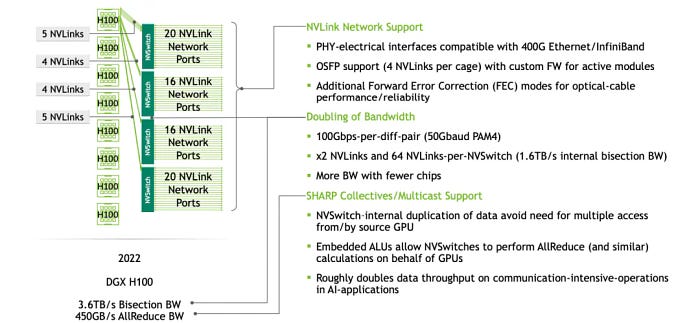
让我们进一步阐述Hopper。在NVLINK 4.0中,使用了112G Serdes,这意味着一对差分信号线可以传输100Gbps。因此,NVLINK 4.0的每个sub-link包含4x100Gbps = 50GB/s。在支持NVLINK 4.0的Hopper一代产品中,每个H100有18个sub-link(端口),总带宽为50GB/s * 18 = 900GB/s。当在一台机器中使用八张卡时,它们使用四个NVSwitch互连,如下图所示:
此外,它还可以通过添加二级交换机进一步扩展,形成256张卡的集群。

扩展接口采用OSFP光模块。
如下图所示,一个OSFP光模块可以支持16对差分信号线,因此每个OSFP可以支持4个NVLINK端口。
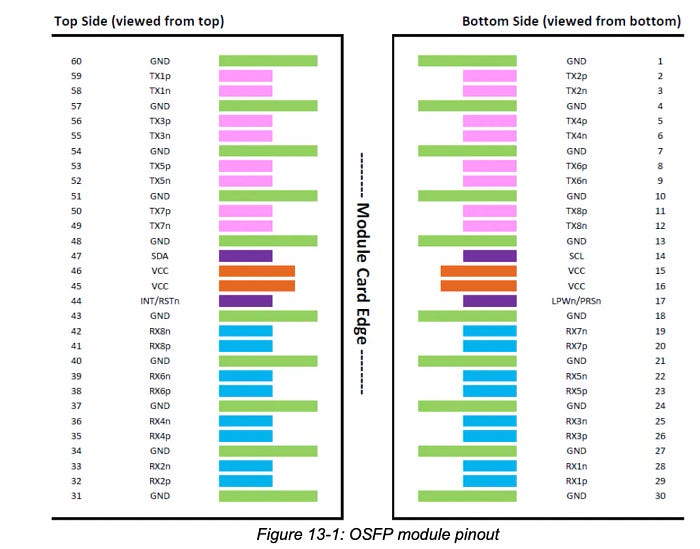
换句话说,下图所示的NVLink交换机包含32个OSFP光模块接口,从而能够累计支持32 * 4 = 128个NVLINK4端口。

2. GB200 NVL72
GB200 NVL72的规范如下图所示。本文主要讨论与NVLINK相关的问题。
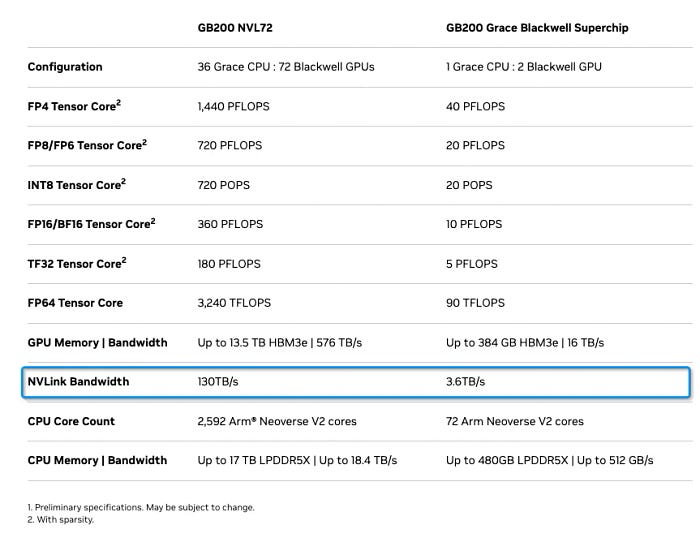
一个GB200包含一个具有72个核心的Grace CPU和两个Blackwell GPU。

整个系统由计算托盘和交换托盘组成。一个计算托盘包含两个GB200子系统,总共有四个Blackwell GPU。

一个交换托盘包含两个NVLINK交换芯片,提供累计总共72 * 2 = 144个NVLINK端口。单个芯片的结构如下,顶部和底部各有36个端口,提供7.2TB/s的带宽。根据网络算法,它的交换容量为28.8Tbps,略小于目前领先的51.2Tbps交换芯片。然而,需要注意的是,这种减少是由于实现了诸如SHARP (NVLS)等功能。

整个机柜支持18个计算托盘和9个交换托盘,从而形成一个具有72个Blackwell芯片完全互连的单机柜架构,称为NVL72。

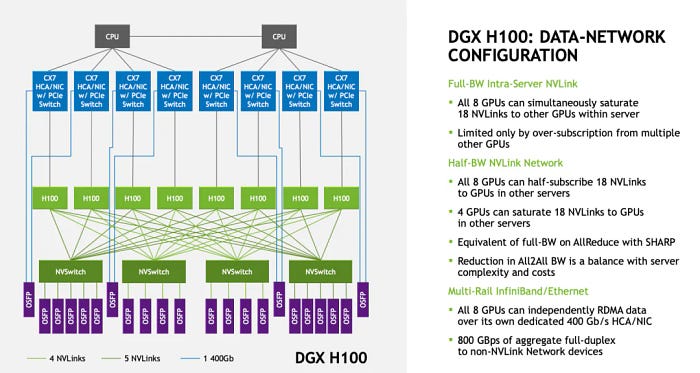
单个GB200子系统包含2 * 18 = 36个NVLink5端口。整个系统的外部互连没有采用OSFP光模块接口,而是直接通过后铜背板连接,如下图所示:


金融分析师关于从光纤到铜缆过渡的断言有些片面。Hopper一代的设计考虑是相对松散的耦合连接,导致这些分析师过度强调对光模块的需求。此外,当时对机柜散热部署有更灵活的要求。然而,这一代涉及在单个机柜内交付整个机柜,类似于IBM大型机的交付逻辑,自然导致选择铜背板。此外,单个B200的功耗更高,液冷交付也施加了功率限制。从功耗的角度来看,切换到铜缆可以显著降低功耗。然而,这并不意味着铜互连将在未来持续存在,因为后续章节将提供详细的分析。
整个NVL72的互连拓扑如下:
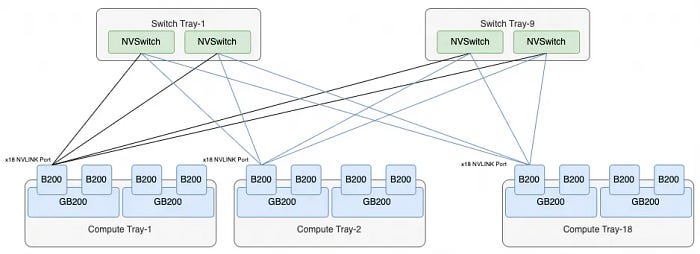
每个B200有18个NVLINK端口,以及9个交换托盘,总共有18个NVLINK交换芯片,每个B200端口都连接到一个NVSwitch芯片。因此,整个系统正好包含每个NVSwitch 72个端口,形成连接所有72个B200芯片的NVL72架构。
3. NVL576
我们注意到在NVL72机柜中,所有交换机不再具有用于互连以形成更大规模的两层交换机集群的附加接口。从NVIDIA的官方图片中,我们可以看到16个机柜形成两行。虽然总共72 * 8个机柜在液冷解决方案中构成一个576卡的集群,但从机柜连接的角度来看,这些卡主要通过横向扩展的RDMA网络互连,而不是通过纵向扩展的NVLINK网络互连。

对于32,000张卡的集群,使用相同的NVL72机柜。一列包含9个机柜,其中4个NVL72机柜和5个网络机柜,形成一个子Pod,并通过RDMA横向扩展网络互连。

然而,这不是所谓的NVL576。为了支持NVL576,每72个GB200需要18个NVSwitch,这使得将它们装入单个机柜变得不切实际。实际上,我们注意到官方文档中的以下声明:

官方文档指出,NVL72既有单机柜版本,也有双机柜版本。在双机柜版本中,每个计算托盘只包含一个GB200子系统。另一方面,我们注意到NVSwitch上有备用的铜缆连接器,这些连接器可能是为不同的铜背板连接定制的。

目前尚不清楚这些接口是否会在铜背板上为第二层NVSwitch互连保留一些OSFP Cage。然而,这种方法有一个优势:单机柜版本不可扩展,而双机柜版本可扩展,如下图所示:
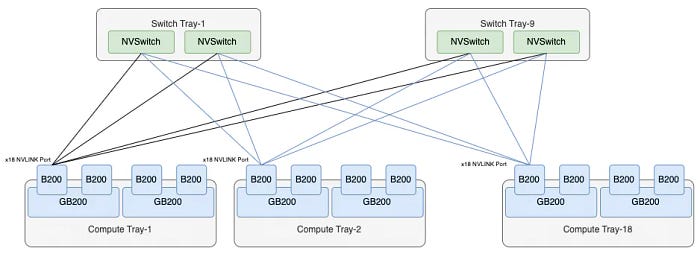
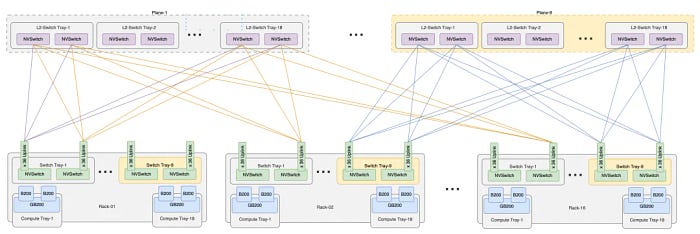
双机柜版本有18个NVSwitch托盘,可以背靠背互连,形成NVL72。虽然交换机的数量是原来的两倍,但每个交换机提供36个外部互连,用于上行链路,以便将来扩展到576卡的集群。NVL576需要16个机柜,因此上行链路端口的累积数量为648 * 16 = 10,368。实际上,这可以通过9个第二层交换平面来实现,每个平面有36个子平面,由18个交换托盘组成。NVL576的互连结构如下图所示:
4. NVLINK 和 InfiniBand
在讨论NVLINK和GB200之间的关系时,不可避免地会涉及到InfiniBand技术。NVLINK是NVIDIA为其GPU加速器开发的专有互连技术,而GB200是基于NVLINK构建的GPU芯片。同时,InfiniBand作为一种在数据中心和高性能计算系统中广泛使用的通用互连技术,也在该领域发挥着重要作用。
虽然NVLINK在构建GPU集群和相关高性能计算系统中起着至关重要的作用,但它不是唯一的互连选项。在大型数据中心和超级计算系统中,通常需要与各种设备和服务器节点进行高效通信,而InfiniBand作为一种通用和标准化的互连技术,提供了与不同设备和节点进行有效通信的能力。
事实上,许多数据中心和超级计算系统都采用混合互连架构,同时利用NVLINK和InfiniBand技术。在这种混合架构中,NVLINK通常用于连接GPU节点,以加速计算和深度学习任务,而InfiniBand用于连接通用服务器节点、存储设备和其他数据中心设备,以实现整个系统的协调和高效运行。

通过结合NVLINK和InfiniBand技术,数据中心和超级计算系统可以充分利用各种设备和资源,从而实现更高的性能和效率。此外,这种混合架构还提供了更灵活的部署和扩展选项,以满足不同应用场景的需求。
在未来,随着数据中心和超级计算系统的不断发展和进步,我们可以预期NVLINK和InfiniBand技术将继续发挥重要作用,并不断提高性能和功能,以满足不断增长的数据处理需求。在这个过程中,诸如光模块之类的高速互连设备将继续发挥关键作用,为系统互连提供更高的带宽和更低的延迟解决方案。

NADDOD 在定制网络解决方案方面的专业知识确保组织能够优化其互连架构,以满足特定的工作负载需求和运营需求。无论是部署高速InfiniBand结构、优化网络拓扑还是实施定制的互连解决方案,NADDOD对卓越的承诺都使企业能够充分释放其数据中心生态系统的潜力。
- 原文链接: naddod.medium.com/nvidia...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





