AllReduce详解:高效分布式训练的关键
- niruthiha2000
- 发布于 2024-11-23 21:54
- 阅读 1738
本文介绍了AllReduce在分布式深度学习中的作用,它通过在多个设备之间同步梯度来加速训练,减少通信瓶颈,并确保模型的一致性。文章还提到了Horovod框架如何通过Ring AllReduce优化了AllReduce的效率,以及AllReduce在扩展性和框架兼容性方面的优势,最后讨论了AllReduce面临的挑战以及未来的发展方向。
随着机器学习模型复杂性的增加,在多个设备上高效地训练它们变得至关重要。AllReduce 已成为分布式深度学习中的一项关键技术,它促进了 GPU 或节点之间的无缝通信,从而加速训练。在本文中,我们将探讨 AllReduce 是什么、它为什么重要,以及在 Horovod 等框架中实现后,它如何彻底改变了分布式训练。
什么是 AllReduce?
AllReduce 是一种用于并行计算的集体通信操作。它执行两个基本任务:
- 聚合(Aggregation): 每个设备共享其本地数据(梯度或参数)。
- 重分发(Redistribution): 聚合后的结果被广播回所有设备。
这确保了分布式系统中所有节点在每次迭代后都保持同步的模型参数。
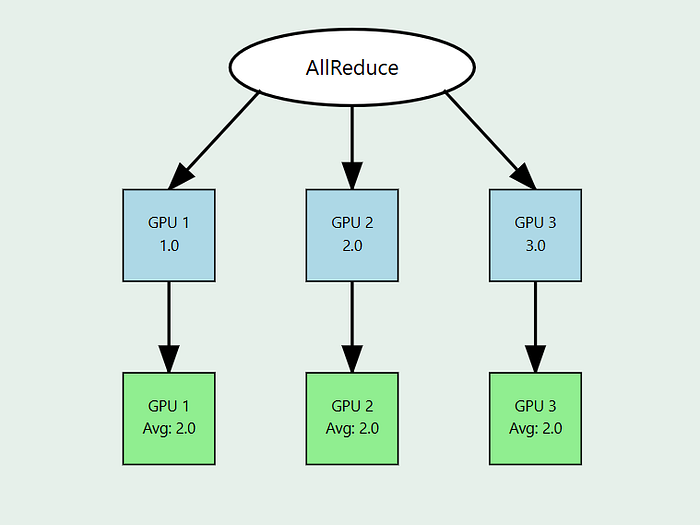
每个 GPU 从本地梯度 (1.0, 2.0, 3.0) 开始 GPU 共享并减少以计算平均值 (2.0) 最终平均值在所有 GPU 上同步。对所有设备的值求和或聚合。将聚合结果(在本例中为平均值)重新分发回所有 GPU。
它是如何工作的?
- 模型副本(Model Replicas): 每个方块代表一个模型在不同设备(例如 GPU)上的副本。这些设备在不同的数据分片(data shards)(数据集的子集)上独立工作,以计算训练期间的模型梯度。
- 数据分片(Data Shards): 每个设备处理数据的不同部分(分片),这有助于并行化训练过程。每个设备根据其数据分片计算梯度。
- 梯度 (Δw):
每个设备根据其数据分片计算局部梯度(表示为 Δw)。这些梯度表示在训练期间应调整模型权重的程度。
AllReduce 过程:
- 梯度计算(Gradient Calculation): 每个设备根据其数据分片独立计算梯度 (Δw)。
- AllReduce 聚合(AllReduce Aggregation): AllReduce 操作聚合来自所有设备的梯度。此步骤包括:
- 归约(Reduction): 来自每个设备的梯度被求和(或平均)以产生全局梯度。这确保了来自所有设备的信息都有助于最终更新。
- 广播(Broadcast): 聚合的全局梯度被发送回所有设备,因此每个设备都具有相同的更新梯度。
3. 模型更新(Model Update):
一旦设备收到聚合的梯度,它们就会更新其本地模型副本。这确保了所有设备保持同步并具有相同的模型参数。
为什么这很重要:
- 一致性(Consistency): 所有设备通过使用相同的全局梯度进行更新来保持同步。
- 效率(Efficiency): 设备之间的直接通信最大限度地减少了瓶颈,使分布式训练具有可扩展性和速度。
- 可扩展性(Scalability): 这种方法非常适合跨多个 GPU 或节点的大规模训练,同时处理不同的数据分片。
为什么 AllReduce 在深度学习中很重要
在深度学习中,尤其是在训练Rollup神经网络 (CNN) 等大型模型时,跨设备的梯度同步至关重要。AllReduce 通过以下方式解决此问题:
- 减少通信瓶颈(Reducing Communication Bottlenecks): 与中心化方法(如参数服务器)不同,AllReduce 依赖于对等通信。这最大限度地减少了网络拥塞并提高了可扩展性。
- 确保一致性(Ensuring Consistency): 通过重新分发聚合的数据,所有节点保持相同的模型状态,从而实现一致的更新并防止发散。
AllReduce 的工作原理:通信原语
AllReduce 利用称为通信原语(communication primitives)的基本操作:
- Reduce(归约): 使用指定的操作(如求和或平均)组合来自所有设备的数据。
- Broadcast(广播): 将归约后的结果分发回所有设备。
流行的变体包括:
- Ring AllReduce(环状 AllReduce): 每个设备仅与其邻居通信,以循环方式传递数据。这种方法最大限度地减少了延迟并最大限度地提高了带宽利用率,这对于大规模训练至关重要。
Horovod 和 AllReduce 效率的提升
Horovod 是 Uber 开发的分布式深度学习框架,它普及了 AllReduce 的使用,并展示了其 Ring AllReduce 变体的潜力。2018 年,Horovod 在 128 个 GPU 上训练 CNN 模型时,实现了近 90% 的扩展效率。这一突破使 AllReduce 成为分布式训练的标准,影响了 TensorFlow、PyTorch 和 MXNet 等框架。
主要优势
- 高效率(High Efficiency): 针对大规模训练进行了优化,尤其是在使用高带宽互连时。
- 可扩展性(Scalability): 支持数千个节点,使其适用于现代数据中心。
- 框架无关性(Framework Agnostic): 易于与流行的深度学习框架集成。
挑战和未来方向
虽然 AllReduce 提供了显着的优势,但仍然存在挑战:
- 网络拓扑依赖性(Network Topology Dependency): 性能在很大程度上取决于网络基础设施。
- 容错性(Fault Tolerance): 如何优雅地处理节点故障仍然是一个积极的研究领域。
未来的创新可能涉及更具适应性的算法和优化的硬件支持,以进一步提高性能。
结论
AllReduce 已经改变了分布式深度学习,实现了跨设备的模型参数的有效同步。它在 Horovod 等框架中的实现为可扩展性和效率树立了新标准,使大规模训练更容易获得和有效。随着模型不断增长,理解和利用像 AllReduce 这样的技术对于未来的人工智能发展至关重要。
- 原文链接: medium.com/@niruthiha200...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





