什么是Solana虚拟机(SVM)?
- Helius
- 发布于 2025-11-06 07:55
- 阅读 2920
本文深入探讨了Solana虚拟机(SVM)的架构、工作原理及其与以太坊虚拟机(EVM)的不同之处。文章详细介绍了SVM的编译流程、账户模型、交易处理单元(TPU)以及如何在SVM上执行程序,强调了SVM通过并行执行和本地费用市场实现高吞吐量和低延迟的关键特性,并展望了SVM未来的发展方向。
非常感谢 Lostin, Alessandro, Brian, Brady, 和 Daniel Cumming 对本文早期版本的审阅。
可执行的见解
- 与明确指代字节码执行器的 EVM 不同,SVM 涵盖了整个交易执行堆栈。
- 要求交易在执行前声明它们将访问哪些账户,可以解锁跨 CPU 内核的并行执行和本地化的费用市场。
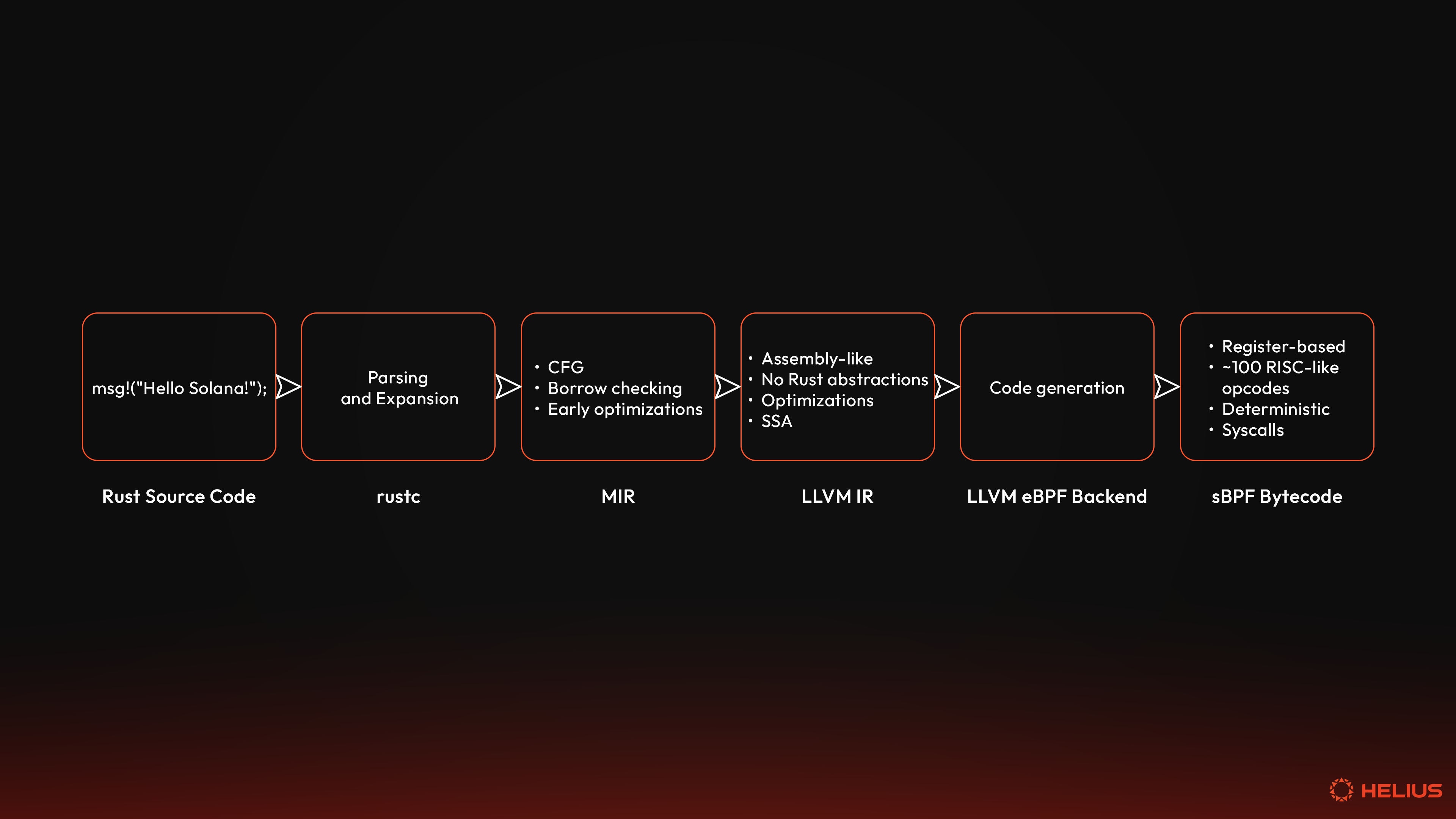
- Rust 源代码通过 rustc 编译成 LLVM IR,然后 LLVM 的 eBPF 后端(特别是 Solana 的分支 sBPF)将其降低为 sBPF 字节码。这意味着任何具有 LLVM 前端的语言(例如,C、C++、Zig)都可以用于编写 Solana 程序。
- sBPF 是 Solana 对 Linux eBPF 的分支,实际上,它们几乎相同,只是引入了一些历史性的添加。但是,这些添加将被回滚。唯一有意义的区别是,上游 eBPF 函数最多可以有 5 个参数,而 Solana 的分支可以有更多。
- 编译后的 sBPF 字节码存储在 ELF 文件中,其中包含指令和常量的 sections,以及重定位表。链接器将 syscall 引用解析为确定性的 32 位 Murmur3 哈希,并将内部函数重写为相对跳转,以实现可移植性。
- BPF Loader Upgradeable 使用双账户模型进行原地升级和部署,而即将推出的 Loader V4 将其简化为单账户,并提供可选的压缩。所有字节码在标记为可执行文件之前都会进行静态验证。
- 交易包含一个账户地址数组,其中包含读取和写入权限、指令和签名。这种结构化的格式允许冲突检测和并行调度非冲突交易。
- TPU 的 Banking Stage 负责并行调度非冲突交易。Bank 从 AccountsDB 加载账户状态。BPF Loaders 提供具有有界内存区域和计算预算的隔离 sBPF VM。成功的状态更改会原子性地提交,而失败则会完全回滚。
- SVM ISA 是唯一的正式规范——除了 Alpenglow 的白皮书和最初由 Toly 撰写的系列文章外,没有单一的“SVM 规范”。运行时是由 Bank、调度器、BPF Loaders 和 sBPF VM 本身之间的交互产生的。
介绍
Solana 虚拟机 (SVM) 是当今区块链中最被误解的系统之一。与以太坊虚拟机 (EVM) 不同,EVM 明确地指代了一个操作码执行器,而 SVM 这个术语涵盖了整个交易执行管道,从 Banking Stage 调度器到 sBPF 字节码解释器本身。这种模糊性反映了 Solana 的架构差异:没有传统的规范可以孤立地定义“SVM”。唯一接近的规范与 Solana 虚拟机指令集架构 (SVM ISA) 有关,该规范描述了 sBPF 字节码必须如何执行,但没有说明更广泛的运行时。
本文旨在作为对 SVM 是什么、它如何工作以及为什么它与 Anza 的 Agave 验证器实现的角度根本不同的综合参考。对 Firedancer 客户端如何运行的探索,以及它们符合 SVM ISA 的自定义虚拟机实现,不在本文的范围内。
我们有兴趣检查实际的代码库,而不是一些抽象的规范。我们追踪了完整的执行管道——Rust 源代码如何通过 LLVM 编译到 sBPF 字节码,程序如何部署和验证,运行时如何为并行执行配置隔离的执行环境,以及交易如何与已部署的字节码交互。
前几个部分将 SVM 的模糊性置于上下文中,并概述了它的工作原理。本文的其余部分适用于寻求对 Solana 执行层进行严格理解的更技术性的受众。
一个有争议的定义
“Solana 虚拟机”(SVM) 一词在社区内引发了激烈的争论,尤其是在网络扩展和其他构建在 Solana 之上的 Layer 区块链出现之后。争论源于该术语的范围:SVM 严格来说是低级 sBPF 解释器,还是它包含完整的交易执行堆栈?
狭义的观点将 SVM 视为类似于传统的虚拟机 (VM),例如 EVM 的操作码执行器。更具体地说,它是解释和 JIT 编译字节码的 eBPF 派生的虚拟机(rBPF,现在是 sBPF)。这种观点强调 SVM 是一个沙盒化的、基于寄存器的执行器,它处理指令,例如 ALU 操作或 Solana 特定的系统调用。从本质上讲,SVM 的灵感来自 Linux eBPF 的安全模型,但它是为区块链基础设施定制的。这与验证器代码中 SVM ISA(指令集架构)之类的短语相符,其中 SVM 仅是 VM 层。
广义的观点将 SVM 定义为 Solana 验证器的整个交易执行层。这不仅包括运行字节码,还包括上游组件,例如 Banking Stage 的调度器、计算单元预算和通过账户数据库(通常称为 AccountsDB)进行的状态更新。它是将原始交易转换为经过验证的状态更改的“运行时”。
出现歧义的原因是官方 Solana 通信将“运行时”与“SVM”交替使用,而没有一个明确的定义。安扎 (Anza) 为这场辩论增加了亟需的清晰度,在明确验证它的同时,也提倡一种务实、以行动为导向的、以工程为基础的观点。他们将 SVM 视为由 Bank 驱动的运行时,它提供 eBPF VM,这种框架提供了一个更广泛的、包含管道的视图,可用于形成 SVM 的正确定义。
这在 Anza 的官方 SVM 规范 中得到了正式确定,该规范将 SVM 定义为“负责交易执行的组件”,打包成一个独立的库,用于验证器、欺诈证明、侧链等等。
为了我们的目的,我们可以将 Solana 虚拟机定义为:
Solana 验证器中由 Bank 组件驱动的、解耦的运行时接口和交易处理管道,该管道协调并行指令和链上程序执行,从而提供一个定制的、基于 eBPF 的虚拟机,用于安全字节码的解释、JIT 编译和资源计量。
SVM 一览
Solana 虚拟机 (SVM) 用作处理与网络上的链上程序交互的交易的执行环境。它是代码与状态相遇的运行时层——将经过加密签名的交易转换为经过验证的状态更改的执行环境。
要真正了解 SVM,我们首先必须了解虚拟机在区块链环境中的含义。
虚拟机
虚拟机 (VM) 是一种虚拟化或模拟计算机系统的软件,它提供了一个隔离的执行环境,其行为类似于物理硬件。这个概念源于 IBM 在 20 世纪 60 年代对大型机系统的研究,该研究使多个用户能够在同一台物理机上运行不同的操作系统。虚拟机主要分为两类:系统虚拟机和进程虚拟机。前者提供了对真实机器的替代,而后者旨在在与平台无关的环境中执行程序。为了我们的目的,我们对系统虚拟机感兴趣,我们将它们称为“虚拟机”或简称为“VM”。
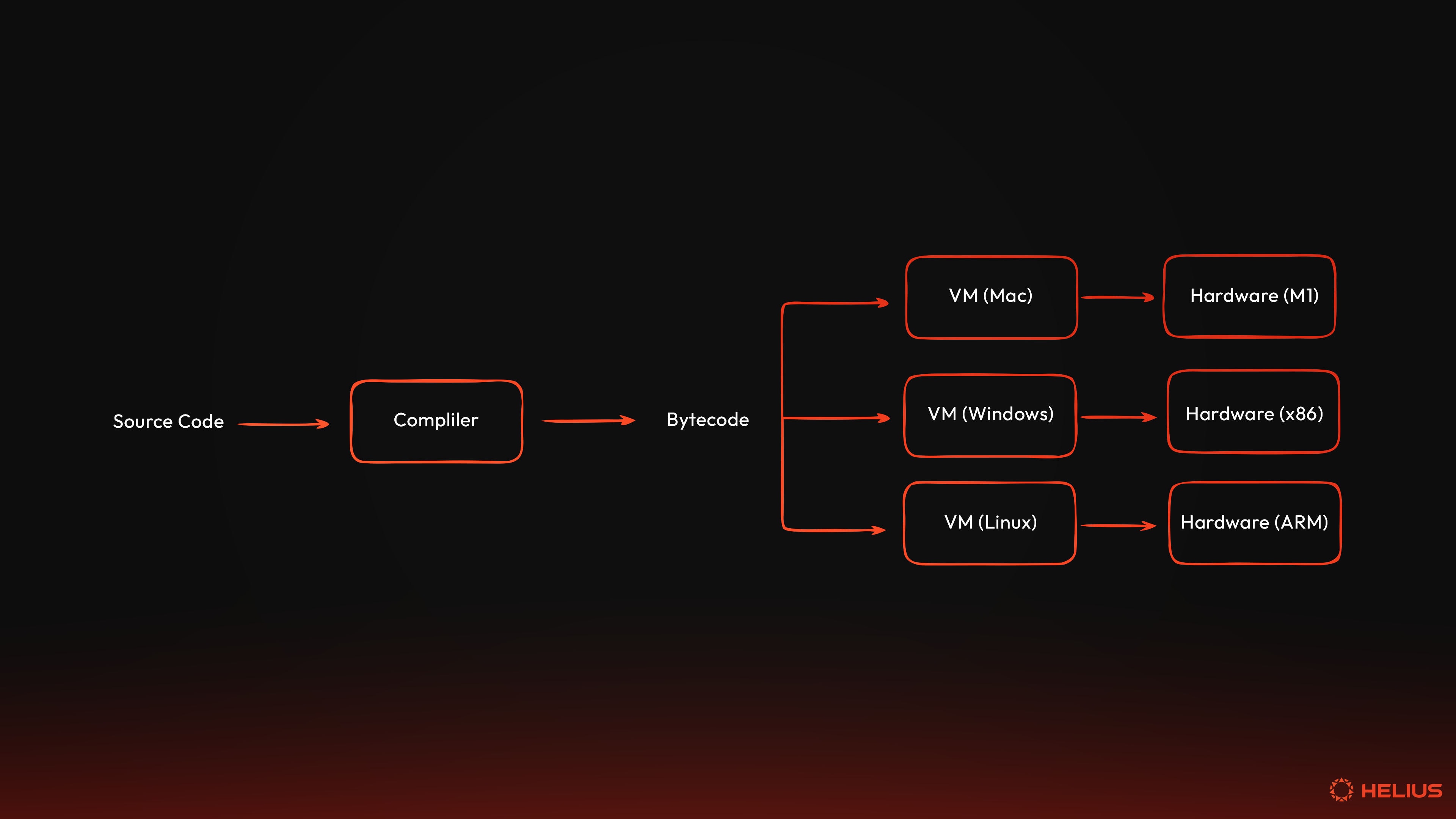
虚拟机解决了几个根本问题。首先,它们为硬件提供了一个抽象层。也就是说,为 VM 编写的程序可以在任何支持 VM 的物理硬件上运行,而无需重写程序。Java 的“一次编写,随处运行”的理念就是例证,因为 Java 字节码在安装了 Java 虚拟机 (JVM) 的 Windows、macOS、Linux 和其他系统上运行的方式是相同的。
虚拟机还提供隔离和安全保证。每个 VM 实例都在沙箱中运行,这意味着除非明确允许,否则它无法访问宿主系统的资源或其他 VM。因此,如果程序崩溃或包含恶意代码,则损坏仅限于该 VM 实例。这种隔离原则是 Google Cloud 和 AWS 等云提供商使用 VM 来分离客户工作负载的原因。
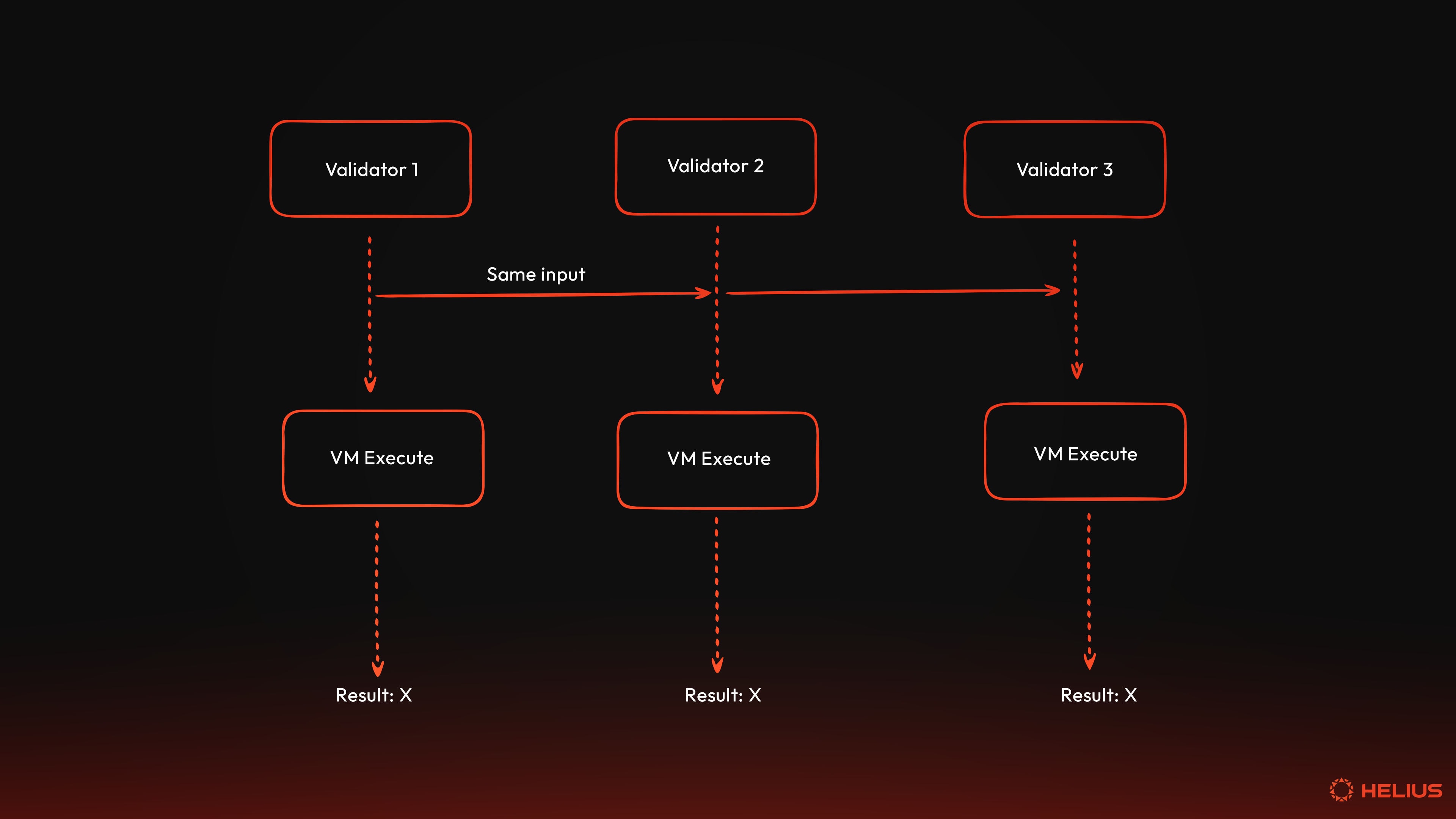
虚拟机还提供可预测的输出。这意味着虚拟机提供了一个受控环境,其中相同的输入始终产生相同的输出,而不管底层硬件如何。这种可预测性对于调试、测试和在分布式系统之间达成共识至关重要。
虚拟机也可以非常高效。现代虚拟机使用即时 (JIT) 编译来最大限度地减少性能开销。JIT 编译在运行时将 VM 字节码转换为本机机器代码,以实现接近本机的性能,同时保持可移植性和上述安全保证。
区块链中的虚拟机
区块链采用了 VM 的概念来解决一个独特的挑战:世界各地成千上万台独立的计算机如何执行不受信任的代码并获得相同的结果?VM 充当确定性的运行时环境,用于执行智能合约(即 Solana 上的程序)并管理网络的状态(即网络上所有账户、余额和其他数据的当前状态)。
当交易提交到区块链时,VM 负责:
- 从存储加载必要的账户数据。
- 执行交易中指定的程序字节码。
- 计量资源消耗以防止无限循环或拒绝服务 (DoS) 攻击。
- 验证所有状态更改是否都遵循网络预定义的共识规则。
- 将更新后的状态提交回永久存储(即账本)。
状态转换发生的具体规则由 VM 的指令集架构和运行时约束定义。
SVM 是如何工作的
SVM 是协同工作以安全有效地执行交易的子系统管道。Bank 为特定 slot 协调执行,管理账户状态,执行共识规则,并协调 Banking Stage 和持久存储(即 AccountsDB)之间的操作。每个 Bank 代表特定 slot 的所有账户的状态,并经历三个生命周期:active(即对新交易开放)、frozen(即随着 slot 的完成而对新交易不开放)和 rooted(即规范链的一部分)。
Banking Stage 是在验证器的交易处理单元 (TPU) 中执行交易的地方。它接收来自 SigVerify 阶段的经过验证的交易,对其进行缓冲,并使用账户锁定上的冲突检测来安排它们进行并行执行。Banking Stage 中的工作线程处理一批批非冲突交易,调用 Bank 的执行方法来加载账户、为每个指令提供 sBPF VM 实例、执行程序字节码并收集结果。Banking Stage 继续处理一批批非冲突交易,直到 Bank 在 slot 边界处被 frozen。请注意,批处理与条目不同,条目是写入账本以进行复制和共识的交易记录单元。
BPF Loaders 管理程序生命周期:部署、JIT 编译、升级和执行。当指令针对给定的程序时,将提供一个具有其自己的内存区域和计算预算的 sBPF VM,并将执行权交给程序的字节码。
sBPF VM 是程序字节码实际运行的沙盒执行环境。它派生自 Linux 的 eBPF,并使用具有 11 个通用寄存器的基于寄存器的架构。VM 通过五个不同的内存区域强制执行内存隔离,每个区域都具有明确的边界和权限。VM 还计量 compute unit 的消耗,以防止失控执行,并调度系统调用以执行特权操作,例如密码学、日志记录或跨程序调用 (CPI)。
AccountsDB 是所有账户数据所在的持久状态层。在执行之前加载账户状态,并利用缓存来避免重复读取频繁访问的账户的磁盘。成功执行后,更新将提交回 AccountsDB。如果执行失败,所有状态更改都将被原子地恢复。
这些组件共同构成了 SVM,一个解耦的、可重用的执行引擎。
SVM 的特别之处:预先声明账户
SVM 的决定性架构决策是所有交易都必须在执行开始之前明确声明它们将读取和写入哪些账户。这个简单的要求被烘焙到交易格式本身中,解锁了两种变革性功能,使 Solana 脱颖而出:并行执行和本地化的费用市场。
并行执行 (Sealevel)
与以太坊虚拟机 (EVM) 不同,EVM 顺序处理交易——一次处理一个交易,等待每个交易完成后再进行下一个交易——SVM 通过跨多个 CPU 内核同时执行多个交易来实现水平扩展。这种并行化是可能的,因为所有 Solana 交易都在执行开始之前明确声明它们将读取和写入哪些账户。
声明交易将读取和写入哪些账户允许运行时分析账户依赖项以检测冲突并调度非冲突交易:
- 访问完全不同账户的交易可以并行运行,而无需任何协调开销。
- 仅从同一账户读取的交易也可以并行运行,因为读取不会发生冲突。
- 尝试写入同一账户的交易会按顺序运行,以防止竞争条件并确保状态一致性。
本地费用市场
因为运行时在执行之前准确地知道每个交易将访问哪些账户,所以费用可以本地化到特定账户,而不是在整个网络上进行竞争。这是一种称为 本地费用市场 的概念。
在以太坊和其他 EVM 链上,每个交易都在一个单一的全局费用市场中竞争——将 ETH 发送给朋友、铸造 NFT 或在 Uniswap 上进行交易都会相互竞标相同的区块空间。一个领域的激增会推高所有人的费用,而不管他们是否试图做完全不同的事情。
在 Solana 上,只有访问相同账户的交易才会相互竞争。用户在两个账户之间转移 SOL 不必担心同时发生的流行 NFT 铸造。交易的优先级费用仅由账户竞争决定。这种本地化就是为什么 Solana 交易即使在活动高峰期也能保持低廉的原因。
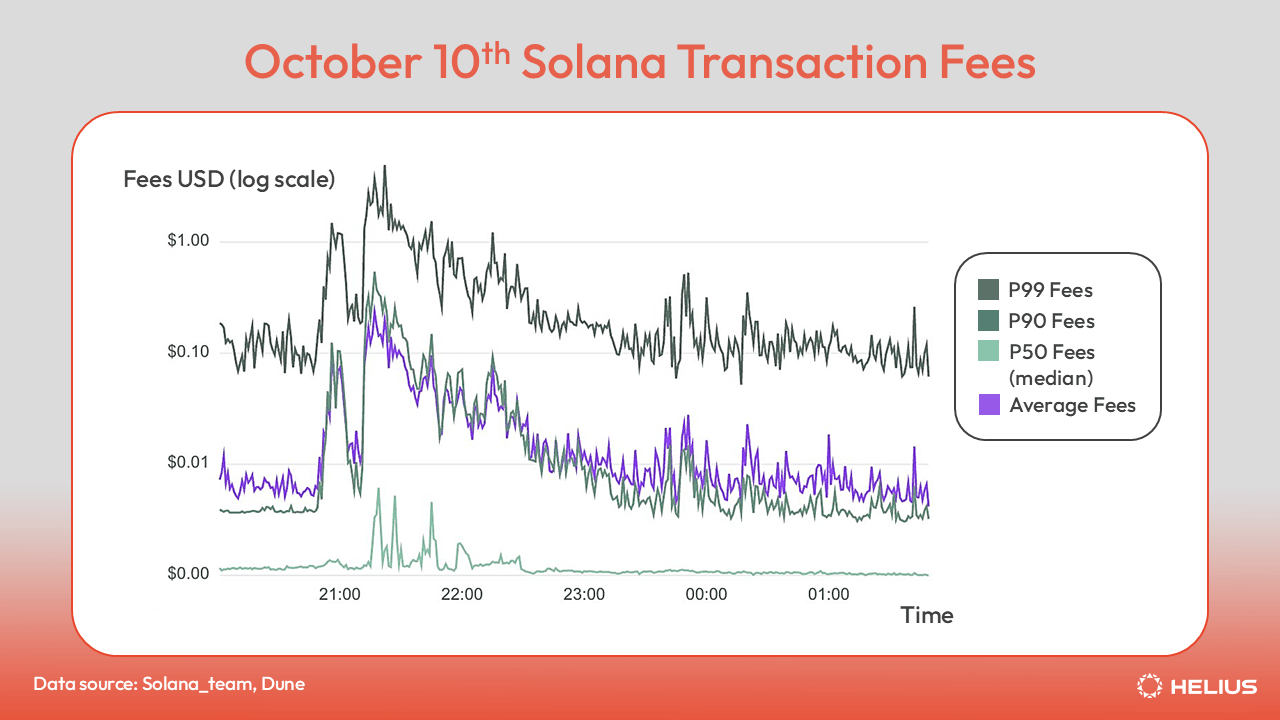
例如,10 月 10 日,加密货币市场经历了有史以来最大的清算事件。尽管活动量创历史新高,但 Solana 交易费用仍然相对便宜,中位数交易费用为 0.007 美元,平均费用短暂达到 0.10 美元,而前 1% 的交易峰值略高于 1.00 美元。在同一时间范围内,以太坊和 Arbitrum 的中位数费用都飙升至 100 美元以上,而 Base 的费用峰值超过 3 美元。
范式转变
| 方面 | EVM | SVM |
| 架构 | 基于堆栈的 VM | 基于寄存器的 VM(eBPF 派生) |
| 执行 | 顺序 | 并行(冲突检测) |
| 费用市场 | 全局 | 本地化(按账户争用) |
| 账户声明 | 不需要预先声明 | 需要预先声明 |
| ISA | ~140 个操作码,堆栈操作 | ~100 个操作码,类 RISC 寄存器 |
| JIT 编译 | 可选(取决于客户端) | 标准(本机性能) |
| 状态模型 | 合约存储费用 | 平面账户数据库 |
| 语言 | Solidity/Vyper → EVM 字节码 | Rust/C/C++ → LLVM → sBPF |
SVM 代表了一种从根本上不同的区块链执行方法。比特币引入了可编程货币。以太坊引入了通用智能合约和任意链上执行。但是,两者都受到顺序执行和全局费用市场的限制——这些架构决策从根本上限制了吞吐量和成本。
SVM 脱离了传统约束,提供了一个可以处理高吞吐量,而又不会牺牲可编程性或迫使用户参与过高的费用拍卖的网络。需要预先声明账户的决定既简单又强大,因为它可以在 CPU 内核上实现并行执行,并可以将费用本地化到账户级别的市场。
当然,这些并不是 Solana 与其他区块链相比,提供的唯一优化。Solana 的“增加带宽,减少延迟”的信条,以及对实现 互联网资本市场 的梦想的过度痴迷,导致了各种性能优化、设计选择和实现,从而培育了一个高吞吐量网络。
本文的其余部分将探讨这究竟是如何工作的——Rust 源代码如何编译为字节码,该字节码如何部署和验证,以及运行时如何提供隔离的执行环境以安全地并行运行数千个程序,同时保持严格的确定性和安全保证。
从 Rust 源码到 sBPF 字节码:编译管道
Rust

Rust 是 Solana 程序开发中的通用语言。像 Anchor 这样的框架为开发人员提供了一种强大、自以为是的方法来高效地构建安全程序。solana_program 旨在成为所有链上程序的基础库。最近,Pinocchio(一个高度优化、零依赖的库)已成为希望构建原生 Solana 程序的开发人员的首选。
无论使用哪种框架或库,所有程序都有一个入口点,运行时将在调用该程序时调用该入口点。solana_program 的 entrypoint 宏发出启动程序执行所需的标准样板。也就是说,反序列化输入,设置全局分配器和 panic 处理程序。Pinocchio 导出功能类似的入口点宏,但将入口点与堆分配器和 panic 处理程序设置分离,从而为开发人员提供更多可选性。
基本程序解剖
程序是一种能够运行代码的账户类型。更具体地说,程序是一个可执行账户,它将 sBPF 字节码的 blob 存储在由 BPF 加载器拥有的一个账户中,该账户具有唯一的公钥。程序在设计上是无状态的:所有持久数据都位于单独的账户中,程序可以在被调用时从这些账户读取或写入数据。
SVM 希望所有程序都具有特定的框架结构——一个接受三个输入的入口点:
- 程序 ID:程序本身的地址,用于自引用检查(例如,所有权)。
- 账户:账户元数据的数组(即,公钥、lamport 余额、数据缓冲区、所有者和标志)。这些是程序需要读取和写入的“状态”。
- 指令数据:来自交易的任意数据的字节切片。
程序应通过其入口点处理这些输入,修改相关的可写账户,发出日志或事件,然后返回一个成功状态,指示它是否能够成功地完成所有这些操作。这归结为一个 process_instruction 函数。
使用 solana_program crate 用 Rust 编写的简单程序如下所示:
simple_rust_program.rs
use solana_program::{
account_info::AccountInfo,
entrypoint,
entrypoint::ProgramResult,
msg,
pubkey::Pubkey,
};
entrypoint!(process_instruction);
pub fn process_instruction(
_program_id: &Pubkey,
_accounts: &[AccountInfo],
_instruction_data: &[u8],
) -> ProgramResult {
msg!("Hello, Solana!");
Ok(())
}在底层,这都由 SVM 的应用程序二进制接口 (ABI) 定义,我们将在后面探讨它。
Rust 编译器和 LLVM IR
像许多其他编程语言一样,Rust 是建立在汇编之上的二阶抽象。它专为人们编写安全、并发和可读的代码而设计,而无需微观管理每个细微的硬件交互。但是,计算机不会说 Rust,也不会说任何高级语言。
计算机理解机器代码——为特定架构或虚拟机量身定制的二进制指令。所有程序最终都转换为二进制代码,而这种转换最终由计算机完成。编译是一个多步骤的转换过程,它剥离了高级抽象,针对效率进行了优化,并输出了可执行的字节码。
rustc 是 Rust 的官方编译器。大多数开发人员通常不直接与 rustc 交互;他们通过 Rust 的软件包管理器 Cargo 来调用它。尽管如此,rustc 在发出可执行字节码之前,会将 Rust 源代码经过三个主要阶段。每个阶段都会剥离抽象,强制执行安全,并为下一次转换准备代码:
- 解析和展开
- MIR(中间级别中间表示)
- LLVM IR(低级虚拟机中间表示)
解析和展开
编译器读取给定的 Rust 文件(由 .rs 扩展名表示)作为纯文本。它在称为词法分析的过程中搜索特定的 token(例如,use、fn、None、impl、&[u8])。词法 token 化是将文本转换为属于给定类别(例如,标识符、运算符、分隔符、字面量、关键字)的有意义的词法 token 的过程。
rustc 获取这些词法 token,并将它们转换为称为抽象语法树 (AST) 的数据结构。这种类似树的结构表示 Rust 源代码的嵌套的、分层的结构。也就是说,函数包含块,块包含表达式,表达式包含运算符,依此类推。虽然抽象语法树仍然处于高级别,但它提供了源代码及其底层逻辑的忠实表示。
构建抽象语法树后,编译器会执行几个关键转换:
- 宏展开:像 entrypoint! 和 println! 这样的宏会被展开为原始 Rust 代码,以便将所有宏都转换为纯抽象语法树节点。
- 降低:为了使代码更具可读性而设计的高级简写语法会被重写为更原始的形式,这个过程称为降低。例如,for 循环会转换为具有手动迭代的 loop。降低的结果就是高级中间表示 (HIR)。
- 借用检查和安全分析:Rust 获取高级中间表示,并执行类型检查、trait 解析和类型推断。此过程的结果是类型化高级中间表示 (THIR)。
在此阶段,编译器处理不安全的代码。不安全的代码允许开发人员执行绕过 Rust 安全保证的操作(例如,解引用原始指针、调用外部函数、实现不安全的 trait)。它充当低级别控制的有意逃生舱口,在仍然要求代码在 Rust 语义下编译的同时,放宽了特定的规则。这对于 Solana 程序来说是关键,在 Solana 程序中,可能会谨慎地使用不安全的代码来提高性能关键型操作的性能,例如零复制账户反序列化(例如,在 Pinocchio 的账户包装器结构 中)。
不安全的代码首先在词法分析后的 AST 构建中被识别,因为不安全的 token 会被识别并标记为特殊节点。然后在类型和借用检查期间,于 AST 展开后处理它。编译器确保不安全的操作仅限于不安全的环境,否则会标记错误(例如,“无法在不安全的代码之外解引用原始指针”)。例如,编译器不检查不安全的代码是否正在损坏或错误地管理内存。
在此阶段结束时,展开的抽象语法树(现在是类型化高级中间表示)是经过验证的、已降低的 Rust 源代码表示。
MIR
然后,类型化高级中间表示会降低到中间级别中间表示 (MIR),这是一种以 Rust 为中心的 形式,它将源代码表示为简化的控制流图 (CFG)。所有特定于 Rust 的语法糖和复杂构造(例如,模式匹配、trait、闭包)都用基本块来表示,包括赋值和分支。这些基本块由跳转(更具体地说是 Goto)和分支连接,从而可以轻松地推理程序的流程。
MIR 并不是严格意义上的必须。编译器可以直接将类型化高级中间表示 降低为 LLVM IR。但是,MIR 提供了一个 Rust 感知层,允许编译器强制执行 Rust 特定的规则,并在应用 LLVM 的通用优化之前执行优化。这使得 MIR 非常适合 LLVM 来说过于高级,但对于类型化高级中间表示来说又过于低级的检查和转换,包括:
- 借用检查:初始语义检查发生在类型化高级中间表示的类型分析期间。但是,MIR 简化的控制流图可以实现完整的、精确的借用检查,以强制执行所有所有权、借用和生命周期规则。
- 移动和 Drop 检查:编译器确保所有值都按照 Rust 的内存安全保证来移动和删除,从而防止使用后释放错误。
- 初始化分析:编译器确保所有变量在使用前都已初始化。
- 内联和早期优化:编译器可以内联小型函数,简化算术表达式,并消除无法访问的代码。
例如,之前我们在示例 Rust 程序中调用了 msg!(“Hello, Solana!”)。这是 在 solana-program crate 中定义的一个宏,对于像静态字符串这样的单个表达式,它在宏展开阶段会展开为直接调用 sol_log($msg),其中 $msg 是该表达式。sol_log 系统调用会获取指向字符串数据及其长度的指针,并将其记录到 SVM 的输出中,而不会产生格式化开销。这可以在 MIR 中简化为:
bb0: {
_0 = const "Hello, Solana!"; // 常量字符串分配
_1 = len(_0); // 计算长度
sol_log(move _0, move _1); // 使用显式移动的所有权进行的系统调用
return = Ok(());
}在这里,
- _0 = const "Hello, Solana!";—MIR 为中间值引入了临时变量(即 _0)。该字符串被视为常量切片,分配在只读数据中。
- _1 = len(_0);—MIR 公开了切片上的简单长度操作,以用于潜在的常量折叠。
- sol_log(move _0, move _1);—系统调用,它转换为 sBPF 指令序列,该序列加载寄存器并调用系统调用 ID。我们将在后面的部分中详细分解这究竟是什么意思,但需要注意的重要部分是,这些移动连接到 Rust 的所有权语义并在编译时强制执行它们。
- Return = Ok(());—用终结符结束该块,向 SVM 发出成功的信号。
MIR 专注于 Rust 语义,这使其成为发现低效和调试 CU 昂贵模式的理想场所。例如,如果你的日志包含动态字符串,则 MIR 可能会识别出可以优化的额外分配或循环。开发人员可以使用命令 cargo rustc -- -Z dump-mir=all 来转储 MIR。
MIR 确保代码在语义上是合理的、经过优化的,并且在最终将其降低为 LLVM IR 之前,剥离了所有 Rust 特定的规则。
请注意,这通常被称为代码生成阶段。这不一定是 LLVM。但是,LLVM 很常见,也是大多数人在谈到 Rust 代码生成时想到的东西。Rust 编译器还附带 GCC 和 Cranelift 后端,它们分别发出 GIMPLE 和 CLIF。我们在 Solana 环境中重点关注 LLVM IR,但请注意,这在一般情况下并不总是 Rust 的情况。
LLVM IR
LLVM 最初的意思是“低级虚拟机”,指的是一个模块化编译器框架。LLVM 不是拥有一个单独的编译器,而是用于构建编译器、优化器和代码生成器的可重用组件的工具包。许多语言(例如,Rust、C、C++、Julia、Swift、Brainfuck、Zig)都使用 LLVM 来利用其从 x86 CPU 到虚拟 ISA 的多种架构的能力。
rustc 将 MIR 转换为 LLVM IR(低级虚拟机中间表示)——Rust 语义和最终部署在 Solana 上的字节码之间的桥梁。它更接近于机器代码,具有显式的内存分配(即 alloca)、存储、加载和函数调用。它没有所有权、生命周期或 trait 的概念,因为这些 Rust 抽象已被展开,不再存在——前面几轮的保证会被保留下来。
在此阶段应用了各种优化,包括:
- 常量折叠(即在编译时评估常量)。
- 内联(即用函数的正文替换调用)。
- 死代码消除(即删除不影响结果的指令)。
- 循环展开和向量化(即重写循环以更快地执行)。
因此,LLVM 为我们提供了:
- LLVM IR:一种可移植的、类似于汇编的中间格式。
- 优化遍:为了创建 LLVM IR,LLVM 使用静态单赋值 (SSA),确保每个变量只赋值一次,从而实现内联和消除死代码等优化。
- 代码生成器:将 LLVM IR 降低到实际机器代码的目标(即 x86_64、ARM、WebAssembly、eBPF)。
Rust 程序通常会为 x86_64 或 ARM 等硬件目标进行编译。但是,Solana 程序不会直接在硬件上运行。相反,它们在 Solana 虚拟机内部运行。因此,LLVM 后端会将 LLVM IR 降低为 BPF 字节码,在 Solana 上,它会变成 sBPF 字节码(即 eBPF 的一个分支,它删除了不确定的功能并引入了 Solana 特定的系统调用)。
请注意,虽然 Rust 是 Solana 程序开发的通用语言,但可以使用任何可以定位 LLVM 的 BPF 后端的语言(例如,C、Nim、Swift、Zig)。
eBPF
LLVM IR 被降低为 eBPF,这是构成 Solana 运行时基础的基于寄存器的 ISA。eBPF(扩展的伯克利数据包过滤器)起源于伯克利数据包过滤器 (BPF),后者由 Steven McCanne 和 Van Jacobson 在 1992 年在劳伦斯伯克利实验室为伯克利软件发行 (BSD) Unix 系统开发。从本质上讲,BPF 是一种网络分流和数据包过滤器,它允许在操作系统级别捕获和过滤网络数据包,而无需复制数据,并利用 限定词。
此后,eBPF 已经发展(即扩展)为 Linux 内核中的通用沙盒 VM。它的解锁类似于 JavaScript 为 Web 开发所解锁的内容——它是内核的安全脚本引擎。eBPF 使开发人员能够直接在 Linux 内核中运行小的、经过验证的程序,这些程序具有受约束的指令集,用于执行诸如性能监控、可观察性、安全性以及联网之类的任务。
这一点很重要,因为开发人员可以获得:- 沙盒执行:eBPF 程序在内核中的受限虚拟机中运行,这意味着它们不会崩溃或损坏内核内存。
- 安全保证:eBPF 字节码在加载之前会经过静态验证,以确保不会发生无效的内存访问、越界跳转或其他特权操作,从而在没有运行时开销的情况下提供安全性。
- 效率:eBPF 是基于寄存器的(而不是像 EVM 那样基于堆栈),并且可以 JIT 编译成机器代码,由于其轻量级设计(即,没有完整的操作系统开销),因此速度接近原生速度。
- 灵活性:eBPF 公开了系统调用,也称为 syscalls,它们本质上是内核功能的Hook。Syscalls 可以通过新功能进行扩展,而无需重新设计指令集。
Solana 需要一个确定性的、安全的和高性能的 VM,以便在其整个验证器集中运行不受信任的程序。eBPF 提供了一个成熟的安全模型,一个可移植且高效的 ISA,旨在运行数千个轻量级程序,以及 JIT 支持以获得更好的性能。因此,Solana 没有发明一个全新的 VM,而是 fork 了 eBPF 并创建了 sBPF。
sBPF
最初,Solana Labs fork 了 Quentin Monnet 的 rBPF,创建了 Solana 版本的 rBPF,确保每个验证器都有一个字节码格式,对于执行给定的程序和输入,产生完全相同的结果。
人们认为需要 fork eBPF,因为 Solana 的共识需要确定性执行和有界资源使用。虽然 eBPF 本身是确定性的,但 Solana 需要额外的保证和特定于区块链的功能:
- 固定的指令时间和成本。
- 用户空间执行。
- 一个确定性的运行时。
值得注意的是,它被设计为在用户空间而不是内核中运行,从而避免了对内核权限或修改的需求。这使得可以在各种操作系统环境中部署,而无需 root 访问权限或自定义内核模块。用户空间是 Solana 的一个实用选择——可移植性、测试和更简单的部署。尽管在用户空间中运行,JIT 仍然实现了接近原生的性能。此外,用户空间执行还允许在没有内核访问的情况下进行测试和模糊测试。
rBPF 不再使用。相反,当 Anza 创建时,他们 fork 了 rBPF 以创建 sBPF(Solana Berkeley Packet Filter)。Solana Labs 拥有的 rBPF GitHub 存储库已于 2025 年 1 月 10 日存档。
SVM ISA
SVM ISA(Solana 虚拟机指令集架构)是核心规范,它定义了兼容 Solana 的 VM(例如,Agave 的 sBPF 或 Firedancer 的重新实现)必须如何执行程序。它不是 VM 本身,而是标准或合约,确保了各种 SVM 实现之间的一致性和协议合规性。正是 SVM ISA 将这些安全性和确定性约束施加于 eBPF,删除了以内核为中心的功能,同时添加了特定于区块链的功能。
ISA 管理寄存器、指令编码、操作码、类、验证规则、panic 条件和应用程序二进制接口 (ABI)。对 SVM ISA 的任何更改都必须通过 SIMD 实现,以支持此指令集的受控演进,确保验证器之间的确定性执行。
寄存器
寄存器是 VM 内部的微型存储槽,在指令运行时保存数字或地址,类似于工作台上的变量或带标签的盒子。SVM ISA 定义了一个 64 位寄存器架构,具有 11 个通用寄存器(R0-R10)和一个隐藏的程序计数器。寄存器为 64 位宽,用于整数和地址,允许有效处理大值或指针。R0 保存函数返回值,R1-R5 传递前五个函数参数,如参数,R6-R9 是被调用者保存的,并在函数调用中保持不变,R10 用作只读帧指针,标记当前堆栈帧。隐藏的程序计数器跟踪执行,指示接下来要执行的指令。
指令
指令是 VM 知道如何执行的单个操作,例如“将这两个数字相加”或“跳转到此行代码”。指令具有类似 RISC 的设计,具有大约 100 个操作码,而像 x86 这样的 CISC 架构中有数千个操作码,这使得验证快速且 JIT 编译高效。
指令以小端格式编码为 64 位值,结构如下:
- opcode:8 位
- dst_reg:4 位
- src_reg:4 位
- offset:16 位(有符号)
- immediate:32 位(有符号)
opcode 告诉要做什么,dst_reg 告诉结果放在哪里,src_reg 告诉输入来自哪里,offset 告诉要查看哪个内存偏移量,immediate 是一个可以包含在指令中的额外常量。
lddw(或加载双字)是唯一占据两个 64 位槽的宽指令,以支持完整的 64 位立即数值。
指令分为不同的类别,包括内存操作、算术或逻辑运算、条件和无条件分支、函数调用和返回以及字节序转换。
内存区域
ISA 标识了五个内存区域,每个区域都有明确的边界(即,[addr, addr+len]),程序可以在其中读取或写入:
- 程序代码:编译后的指令本身(读取 + 执行)。
- 堆栈:函数的临时工作区(读取 + 写入,通常每个帧 4KB)。
- 堆:程序可以请求的动态内存(读取 + 写入)。
- 输入数据:通过交易传递的只读字节。
- 只读数据:常量和不可变值。
程序具有预定义的虚拟内存映射,程序代码从地址 0x000000000 或 0x100000000 开始,具体取决于编译版本,堆栈帧从 0x200000000 开始,堆从 0x300000000 开始,输入数据从 0x400000000 开始。
验证器
验证器在执行之前执行静态分析——它检查每个可能的代码路径,而不运行程序——以确保在加载时而不是在运行时提供安全保证。这包括检查:
- 没有未知或不支持的指令。
- 所有跳转目标都落在有效的指令边界上,并处理向后跳转。
- 没有无法访问的代码路径。
- 强制执行函数调用深度限制。
- 静态拒绝除零或模零。
- 程序具有最大大小限制,并且必须在此限制内。
虽然验证器很有用,但它不能阻止开发人员引入意外行为。也就是说,开发人员仍然能够在 Solana 程序中引入 use-after-free 和缓冲区溢出错误,例如。
Panic 条件
Panic 条件是由 SVM ISA 定义的运行时错误案例列表。这些包括:
- 无效或不支持的指令。
- 除零或模零。
- 越界内存访问。
- 不同内存区域的无效内存访问(即,权限冲突)。
- 堆栈溢出。
- 超出调用深度。
- 超过允许的最大指令数。
- 程序返回了错误代码。
ABI
应用程序二进制接口 (ABI) 是 Solana 程序和 SVM 之间的格式合约。虽然早期的基本程序解剖部分演示了这在 Rust 中是如何工作的(即,具有三个输入的 process_instruction),但 ABI 指定了这些输入和输出如何在内存中表示,确保每个验证器都可以确定性地执行程序。
在高层次上,ABI 定义了三件事:入口点约定、调用约定和寄存器以及内存布局。
每个 Solana 程序_必须_公开一个入口点函数。加载器将程序输入以规范的顺序序列化到 VM 的内存空间中:程序 ID、帐户数组和指令数据。然后,VM 将指向这些区域的指针传递到程序的入口点。
前五个寄存器(即,R1-R5)保留用于入口点参数,而返回寄存器(即,R0)保存程序的退出代码。退出代码为零被认为是成功,而非零值是映射到特定 InstructionError 的失败。这确保了所有程序都以一致的方式返回状态代码。此外,前五个参数之后的参数将传递到堆栈上。R6-R9 遵循被调用者保存的约定,这意味着函数必须在使用它们时保留这些值。
帐户和数据作为字节切片序列化到 VM 的线性内存中。程序必须将它们反序列化为更高级别的 Rust 类型(例如,AccountInfo、Pubkey)。ABI 强制执行严格的边界,因此任何程序都无法访问其分配区域之外的内存。
总之,这些规则使 ABI 成为将高级开发人员体验绑定到低级 ISA 的“粘合剂”。它确保简单的 Rust 函数签名编译成正确的寄存器用法、内存布局和返回代码,以便每个验证器每次都以完全相同的方式解释给定的程序。
Syscalls
ISA 是故意最小化的,没有内置的帐户或状态。它也不直接提供任何更高级别的功能,例如日志记录、哈希或跨程序调用。相反,公开了系统调用——内置于 VM 中的特殊函数,允许程序与外界交互。这些调用通常被称为 syscalls。
Syscalls 可以被认为是 VM 提供的 API。Syscall 公开了安全、标准化的操作,保证在所有验证器中以确定性的方式运行,而不是每个程序都必须重新实现特定的加密原语或帐户逻辑。
流行的 syscall 类别包括:
- 日志记录和调试(例如,sol_log syscall 将 UTF-8 字符串写入程序日志,并在底层由 msg! 使用)。
- 跨程序调用 (CPI)(例如,sol_invoke_signed 允许程序调用另一个链上程序,传入帐户和指令数据,这对于 Solana 的可组合性至关重要)。
- 密码学(例如,sol_sha256、sol_keccak256 和 sol_ed25519_verify syscall 都添加了确定性、快速的密码学原语,而无需开发人员编写自己的实现)。
- 内存和帐户实用程序(即,公开用于帐户数据借用、重新分配内存或使用程序拥有的堆分配的助手的 syscall)。
- 计算预算和计量(即,每个 syscall 消耗 CU,由运行时的计量系统强制执行)。
Syscall 是使用具有唯一哈希标识符的特殊 CALL_IMM 指令调用的。当程序调用 syscall 时,sBPF VM 会陷入执行,在其 syscall 注册表中查找哈希,并分派到在特权运行时代码中运行的本机实现。Syscall 在沙箱之外执行,可以访问运行时状态,这与程序中常规函数调用的执行方式完全不同。
Syscall 遵循与常规函数相同的 ABI,前五个参数通过寄存器 R1 到 R5 传入,返回值在 R0 中。每个 syscall 都有一个固定的计算单元成本,确保确定性的资源消耗。例如,对 secp256k1_recover syscall 的所有调用都会消耗 25,000 CU。
Syscall 形成了一个受控的安全边界,因为每个 syscall 都会验证其输入并在执行任何特权操作之前检查相关的权限。例如,跨程序调用 (CPI) syscall 会验证调用者是否具有关于正在传递的帐户的适当权限。
请注意,可以通过功能门添加新的 syscall,而无需修改 ISA 本身。这使 Solana 可以扩展其 VM 功能,包括对新密码学原语的支持,同时保持与现有程序的向后兼容性。
程序二进制文件
在编译结束时,所有阶段——从 Rust 源代码到 LLVM IR,再到 eBPF,再到 sBPF 及其对 SVM ISA 的遵守——都会生成单个输出:程序二进制文件。此二进制文件是实际部署到 Solana 的内容。
ELF
Solana 程序被编译成可执行和可链接格式 (ELF) 文件,这是一种在类 Unix 系统中使用的标准二进制格式。ELF 格式充当一个容器,它打包了 VM 执行给定程序所需的一切,同时保持平台独立性。
ELF 文件通常包含以下部分:
- 字节码部分:包含 .text 部分中编译的 sBPF 指令。
- 只读数据部分:保存 .rodata 部分中的常量、静态字符串和不可变值。
- BSS 和数据部分:分别包含 .bss 和 .data 部分中的全局或静态可变变量。请注意,Solana 不允许可变数据。也就是说,ELF 可以具有 .rodata,但不能具有 BSS 和数据段。
- 符号和重定位表:定义在加载期间如何在 .symtab 和 .strtab 部分中解析函数调用、syscall 和内存引用,以及在 .rel.dyn 和 .rela.dyn 部分中重定位条目。
每个 ELF 文件还包括一个标头,描述架构、指令宽度(即,64 位)、字节序(即,小端)和入口点地址。
链接和重定位
将编译器输出转换为单个可执行 ELF 文件的过程涉及最后一个组件:链接器。链接器负责将多个编译的代码单元组合成一个有凝聚力的二进制文件。它还解析编译器未解析的所有符号引用(即,占位符)。
例如,
- 当程序调用诸如 sol_log 之类的函数时,编译器不知道该函数在内存中的位置,因此使用占位符。
- 链接器将此符号引用替换为 syscall 的唯一哈希标识符(即,确定性的 32 位 Murmur3 哈希)。
- 类似地,内部函数之间的调用被重写为到 .text 部分中指令偏移量的相对跳转。
将符号引用重写为具体地址或哈希 syscall ID 的此过程称为重定位。但是,值得注意的是,重定位在很大程度上是最初构建工具的方式的产物,而不是基本要求。事实上,计划在未来版本的工具链中完全删除重定位,以简化部署过程。
此重定位步骤是必要的,以确保相同的 ELF 二进制文件在所有验证器上以相同的方式运行,因为没有嵌入绝对内存地址或特定于系统的符号。
此外,已经包含这些重定位的字节码缓存在内存中,因此所有未来执行都依赖于更新的字节码,而无需重新处理重定位。
一旦链接器生成一个完全重定位的 ELF 文件,程序就可以部署了。最终结果是一个二进制文件,它是:
- 可移植:它在任何验证器或 SVM 实现上以相同的方式运行。
- 确定性:它不包含非确定性 syscall 或操作系统依赖项。
- 自包含:它携带执行所需的所有字节码和元数据。
如何将字节码上传到 Solana
一旦 Solana 程序被编译并链接到有效的 ELF 文件中,下一步就是将其上传到区块链,以便验证器可以执行它。这个过程,被称为程序部署,涉及多个协同工作的组件:BPF 加载器、帐户模型、字节码验证和状态管理。
BPF 加载器程序
BPF 加载器是一个本地程序,它验证、重定位并将 ELF 文件标记为可执行文件。从本质上讲,它管理已部署程序的生命周期——它处理指令以初始化帐户、写入字节码、部署程序和处理升级。
Solana 已经经历了加载器的几个迭代,每个迭代都在前一个版本的基础上进行了改进:
- BPF 加载器:用于静态、不可升级程序的原始加载器,不再支持。
- BPF 加载器 V2:一个简化的加载器,没有管理指令。
- BPF 加载器可升级:当前的加载器,引入了程序可升级性。
- BPF 加载器 V4:最新的迭代,具有更好的部署功能,将当前的双帐户模型简化为单帐户模型。
部署架构:帐户模型
当前帐户模型
当前加载器使用双帐户架构将程序逻辑与程序数据分离。这会导致给定程序有两个帐户:Program 帐户和 ProgramData 帐户。
Program 帐户是一个小帐户,大约 36 字节大小,它保存元数据并标记为可执行文件。它通过 UpgradeableLoaderState::Program { programdata_address } 存储对 ProgramData 的引用。
ProgramData 帐户是一个更大的帐户,它通过 UpgradeableLoaderState::ProgramData 存储实际的 ELF 字节码以及部署元数据(例如,插槽、升级权限地址)。
两个帐户的分离启用了就地升级。也就是说,Program 帐户保留在相同的地址,而 ProgramData 帐户的字节码可以被替换。
未来帐户模型
加载器 V4 旨在通过单帐户模型简化部署过程。这里的想法是程序帐户将直接存储元数据和字节码,而无需单独的 ProgramData 帐户。它还为开发人员提供了存储 zstd 压缩图像的选项,以节省租金成本。
如何部署 Solana 程序
部署过程涉及上传编译的 ELF 二进制文件,并让 BPF 加载器验证、缓存并将其标记为可执行文件。由于上一节中概述的部署架构,可升级加载器和 V4 之间的过程略有不同。
BPF 加载器可升级
当前使用可升级加载器的部署过程涉及初始化一个缓冲区帐户,用于暂存 ELF 字节码。部署者将 InitializeBuffer 指令 发送到 BPF 加载器可升级,该指令创建一个由加载器拥有的新帐户,并将帐户状态设置为 UpgradeableLoaderState::Buffer { authority_address },记录授权写入缓冲区的地址。
编译的 ELF 二进制文件使用 Write { offset, bytes } 指令 分块上传到缓冲区。每个写入指令都会验证签名者是否与缓冲区的权限匹配,检查缓冲区是否仍然可变(即,尚未部署),并在元数据标头之后的指定偏移量处写入字节。请注意,由于交易大小限制,大型程序需要多个 Write 指令才能上传整个 ELF 文件。
一旦缓冲区包含完整的 ELF,部署者就会发送一个 DeployWithMaxDataLen { max_data_len } 指令。这是整个部署过程中最复杂的步骤,因为它协调了从帐户验证到状态完成的实际部署。
加载器首先验证部署过程中的所有帐户并验证:
- 程序帐户未初始化且免除租金。
- 缓冲区包含有效数据,并且初始化缓冲区的权限已签署交易。
- max_data_len 足够大,可以容纳缓冲区的数据。
- 总大小不超过 MAX_PERMITTED_DATA_LENGTH(即,10MiB 或 10,485,760 字节)。
然后,加载器创建 ProgramData 帐户,使用程序 ID 和加载器 ID 将地址派生为 PDA。然后,它将缓冲区的 lamport 排回给付款人,因为部署后不再需要缓冲区帐户。
此外,它通过 CPI 创建 ProgramData 帐户到系统程序,为元数据和 max_data_len 字节分配足够的空间。然后,加载器使用 PDA 的 bump 种子来签署 CPI。
deploy_program! 宏确保字节码可以安全执行。它首先解析 ELF 文件结构以验证 ELF 魔术字节(即,0x7f ‘E’ ‘L’ ‘F’)和标头(即,64 位,小端),提取程序部分,处理重定位表,并验证部分边界和对齐方式。如果 ELF 格式不正确或使用不支持的功能,加载将立即失败。
然后,RequisiteVerifier(即,sBPF 的验证器)在不运行程序的情况下对每个可能的执行路径执行静态分析,确保在执行任何指令之前它在可证明是安全的。验证器还强制执行前面提到的 SVM ISA 约束。如果验证失败,则部署会因 InstructionError::InvalidAccountData 而被拒绝,并且程序永远不会被标记为可执行文件。
一旦验证通过,字节码就会被编译并缓存以进行执行。load_program_from_bytes 函数创建一个 ProgramCacheEntry,其中包含:
- JIT 编译的可执行文件:sBPF 字节码被即时 (JIT) 编译为验证器 CPU 架构的本机机器代码。这提供了接近原生的执行速度,同时保持安全性。
- 插槽元数据:程序的部署时间和可见性时间分别记录为 deployment_slot 和 effective_slot。延迟可防止程序在部署的同一插槽中使用。
- 运行时环境:对 syscall 注册表的引用,以概述哪些 syscall 可用,以及程序执行时将使用的执行配置。
缓存条目存储在 program_cache_for_tx_batch 中,使程序可在后续交易中执行。
成功验证和缓存程序后,加载器会更新帐户状态以完成部署。ProgramData 帐户的状态会更新,以记录程序部署的时间以及授权升级程序的人员。ELF 字节码也会从缓冲区复制到帐户中。Program 帐户的状态也会更新以将其链接到 ProgramData 帐户,并标记为可执行文件。最后,缓冲区的数据长度设置为元数据大小,有效地清零字节码并回收空间。
程序现在已完全部署,可以由交易调用。
BPF 加载器 V4
BPF 加载器 V4 通过消除对单独 ProgramData 帐户的需求来简化部署,从而允许程序帐户直接存储字节码。它还引入了对 zstd 压缩 ELF 存储的支持,这大大降低了租金成本,同时在加载期间按需解压缩。
部署者调用 SetProgramLength { new_size } 以分配程序元数据和字节码的空间。对于新程序,这将使用 LoaderV4State::Retracted 状态初始化帐户,记录权限,并将帐户标记为可执行文件,尽管它还不能被调用。
然后,部署者通过 Write { offset, bytes } 指令将 ELF 二进制文件直接写入程序帐户。仅当程序处于 Retracted 状态时才允许这些写入。Copy 指令也可用于从另一个程序复制字节码,无论加载器版本如何,这对于迁移很有用。
然后,使用 Deploy 指令将程序从 Retracted 状态转换为 Deployed 状态。从本质上讲,此指令从程序帐户中的偏移量提取字节码,并运行与 BPF 加载器可升级完全相同的验证管道(即,ELF 解析、静态验证、JIT 编译、缓存)。如果验证成功,则程序的的状态更新为 LoaderV4Status::Deployed,并记录部署插槽。
程序现在已完全部署,可以由交易调用。
加载器 V4 还在状态转换之间强制执行冷却期(即,部署和撤回),以防止重新部署攻击。程序不能在上次部署的 一个插槽内 部署或撤回。这有助于防止恶意行为者快速更新程序以利用竞争条件或混淆用户,从而确保每个插槽的原子性,而不是多插槽延迟。请注意,此冷却期适用于 Deploy 和 Retract 指令。
程序还可以通过 Finalize 指令 设置为不可变。这会将程序从 Deployed 状态转换为 Finalized 状态,这意味着该程序不能再被撤回或升级。权限字段被重新用于指向“下一个版本”程序地址,从而在保持程序不变性的同时启用显式升级路径。
在 SVM 中执行是如何工作的
SVM 是验证器内的交易处理引擎,负责执行程序调用并相应地更新状态。
当交易到达验证器时,它会流经一个多阶段管道:验证、帐户加载、在隔离的 sBPF VM 中执行程序、不变性验证和状态提交。如果所有指令都成功,则帐户更改将写入 AccountsDB。如果任何指令失败,则整个交易都会以原子方式回滚。
SVM 作为解耦的执行引擎运行。也就是说,它不管理共识、网络或分类帐历史记录。相反,它只专注于安全、确定性且高效地执行程序。
Bank 协调 SVM 的执行,提供运行时上下文(例如,区块哈希、租金、功能集),并将结果提交到持久存储。SVM 管理程序执行,从加载字节码到强制执行计算预算。这种关注点分离使 SVM 可在验证器之外重用。
交易
交易是 Solana 或任何区块链的命脉——它们调用程序以执行状态更改。
交易是一组指令,概述了应执行哪些操作、在哪些帐户上执行,以及它们是否具有执行这些操作的必要权限。
指令是单个程序调用的指令。它是最小的执行逻辑单元,充当 Solana 上最基本的操作单元。
程序解释从指令传入的数据,以操作指定的帐户。指令包括程序 ID(即,要调用的程序)、要从中读取和写入的帐户列表以及传递给程序的输入。
交易始于用户定义目标时,例如将 10 SOL 转移到另一个帐户。此意图转化为一条指令,告诉系统程序将 10 SOL 从帐户 A 转移到帐户 B。帐户 A 将作为可写签名者传递到交易中,帐户 B 将作为可写帐户传递。然后,该指令将打包到还指定费用支付者、签名者和最近的区块哈希的交易中。
然后,该交易通常会被发送到 RPC 提供程序,例如 Helius。接收交易的 RPC 节点然后将验证所有必需的签名是否存在且有效,该交易尚未处理,提供的最近的区块哈希仍然有效,并且该交易未超过最大大小(即,1232 字节)。
然后,RPC 将交易转发到当前领导者的交易处理单元 (TPU)。
交易处理单元 (TPU)
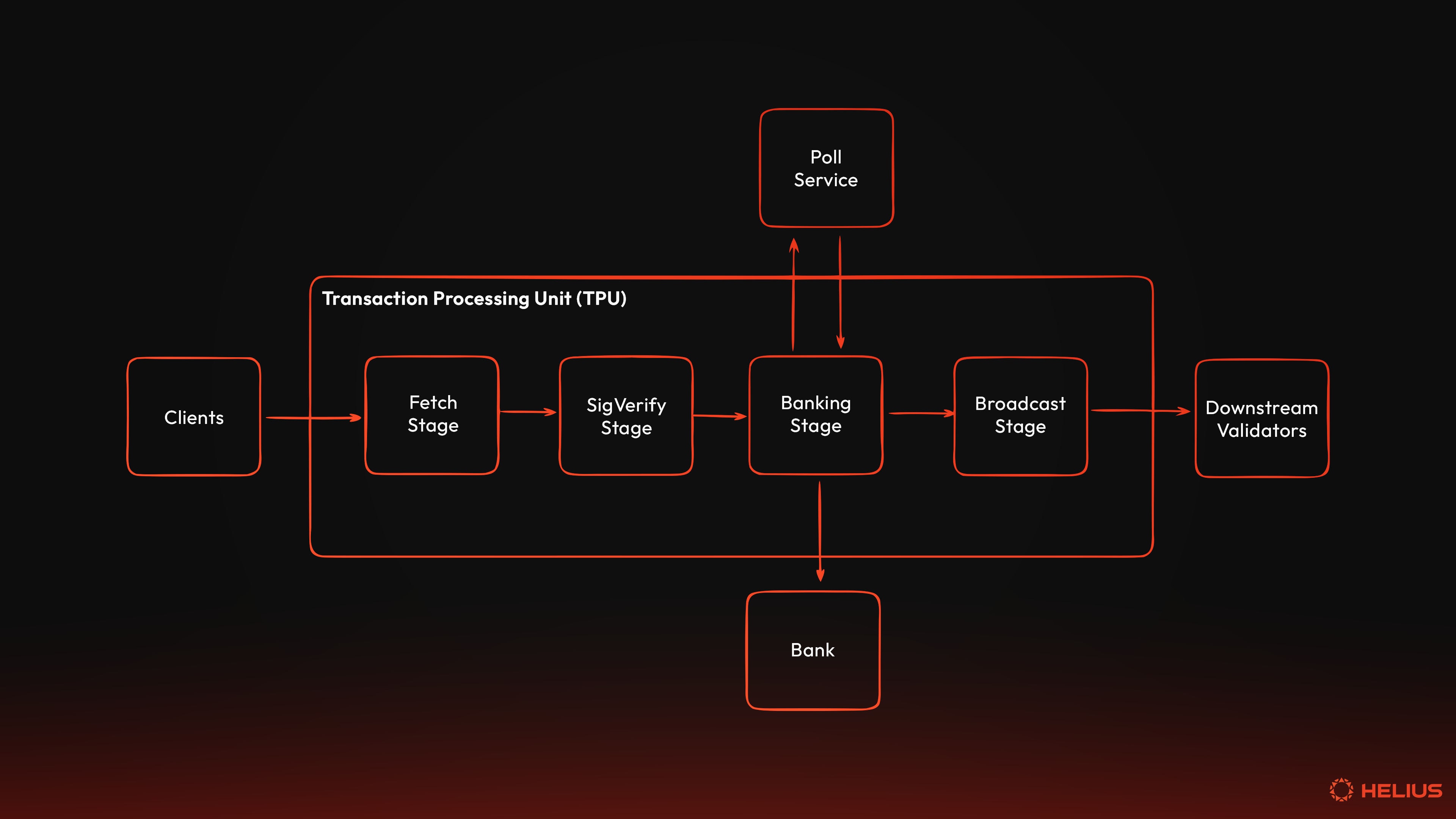
交易处理单元 (TPU) 是 Solana 验证器内的交易提取和处理管道。它有几个阶段,在交易提交到 Solana 的分类帐之前接收、验证、安排和执行交易。
出于我们的目的,我们将详细检查提取阶段、SigVerify 阶段和银行业务阶段,然后再继续进行 Bank 和 sBPF VM 的配置。
有关 TPU 的更详细检查,请参阅 股权加权服务质量:你需要了解的一切。
提取阶段
提取阶段是 TPU 管道中的第一阶段。它通过 QUIC 连接 接收所有传入交易,该连接利用 UDP 套接字作为底层传输层,并将它们批量处理以进行下游处理。
- tpu:常规交易,例如代币转账、NFT 铸造和程序交互。
- tpu_vote:来自验证器的投票交易——当 Alpenglow 删除投票交易时,这将发生变化。
- tpu_forwards:从先前领导者转发的未处理交易,先前领导者无法及时处理它们。
这些套接字在验证器的 gossip 服务 中注册并存储在 ContactInfo 结构中,允许其他验证器和 RPC 节点发现将交易发送到哪里。
提取阶段为每个套接字生成一个线程,所有线程都不断地:
- 轮询 UDP 套接字以获取传入数据包。
- 创建一批 64 个数据包。
- 通过其无界通道发送批处理。
无界通道当前用于将批处理传递到下游阶段,这意味着通道具有无限容量。无界通道的使用还意味着提取阶段可以独立于下游处理速度运行。
虽然这可以防止在流量高峰期间立即丢弃数据包,但它可能导致内存问题:如果下游阶段无法跟上提取阶段,通道将以不受限制的速度增长,从而可能导致速度减慢或内存不足 (OOM) 崩溃。
正在努力实现具有适当反压的有界通道,允许系统发出拥塞信号并防止无界内存增长。 Fetch 阶段还会创建一个专门处理转发数据包的线程。这些数据包被标记为 FORWARDEDflag,并根据领导者时间表进行保留或丢弃:
- Honored(接受):如果当前验证者很快将成为领导者,转发的数据包将通过常规 TPU 通道处理并发送到下一阶段。
- Discarded(丢弃):如果当前验证者不会很快成为领导者,则丢弃转发的数据包以防止浪费处理。
Fetch 阶段使用 PacketBatchRecycler 预先分配 1,000 个数据包批次,每个批次包含 1,024 个数据包。这样做是为了减少内存分配开销,因为可以重用数据包批次内存,而不是每次都分配新的批次。从历史上看,recycler 是 CUDA 内存 pinning 所必需的,但它已不再起作用,并且在很大程度上可以被认为是技术债务。
The SigVerify Stage(签名验证阶段)
SigVerify 阶段是 TPU 流水线的第二阶段,顾名思义,负责验证签名。这在流水线的早期完成,因为 Ed25519 的签名验证在计算上是昂贵的,尽管没有执行交易那么昂贵。在执行之前验证交易允许验证者拒绝欺诈性交易,防止拒绝服务攻击,并确保只有格式良好的交易才能到达 Banking 阶段。
SigVerify 阶段充当一个单线程,不断从 Fetch 阶段通道接收数据包,并通过验证流水线处理它们。尽管是一个单线程,但内部存在大量的并行性。
默认情况下,签名在 CPU 上使用并行迭代器进行验证。这样做是为了在所有可用的 CPU 核心上分配验证,从而允许每个核心独立验证签名的子集。
如果通过 perf_libs::api() 检测到性能库,则签名验证也可以 卸载到 GPU。只有当至少有 64 个数据包,并且预计 90% 的数据包有效时,才能使用 GPU。原因是 GPU 在设置和传输方面有 ~15-20ms 的开销,而 CPU 可以在 ~10-20ms 内验证 64 个签名。诚然,由于延迟开销,此功能在生产中已被证明是不切实际的,使其比实际工作负载的 CPU 验证慢得多。计划正在进行中,以删除此未使用的代码路径。
验证过程相对简单:
- 从 Fetch Stage 的无界通道接收数据包批次。
- 如果数据包量超过 165,000,则通过负载均衡随机丢弃交易。
- 删除重复的交易。
- 丢弃多余的数据包,以使任何单个 IP 都不能垄断验证带宽。
- 预先收缩和重组批次,以提高缓存局部性并减少内存浪费。
- 验证签名。
所有有效的数据包都将进入 Banking Stage。
The Banking Stage(银行阶段)
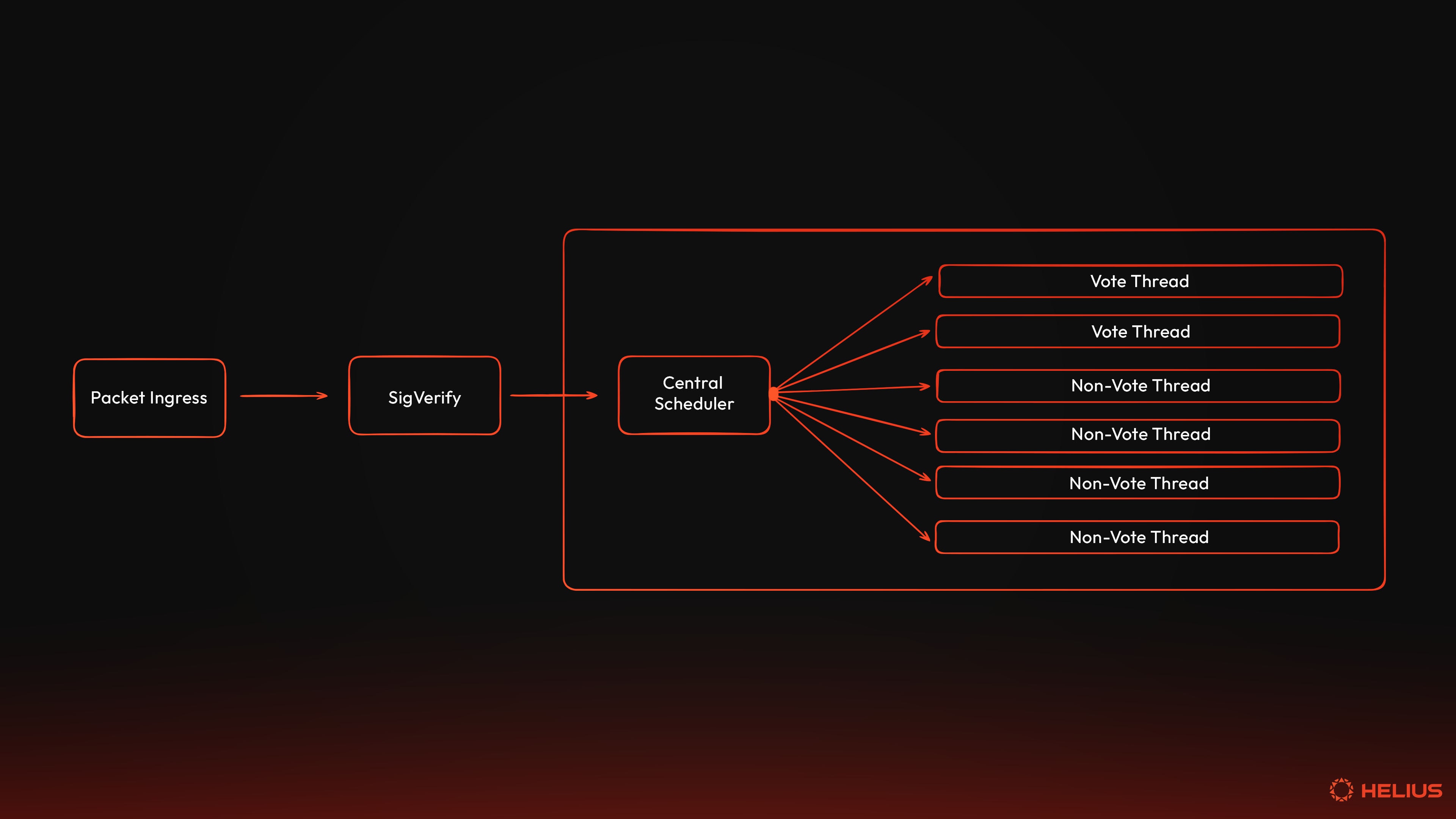
Banking Stage 是执行交易的地方。在这里,交易被缓冲、调度并由并行工作线程执行。
使用中央调度器模式,将投票交易和非投票交易的处理方式分开:
- 单个工作线程处理投票和 Gossip 投票交易。
- 四个工作线程处理所有非投票交易。
- 单个线程协调工作线程之间的工作分配。
传入的数据包被反序列化并缓冲到最多 100,000 笔交易。调度器在管理此缓冲区的同时不断接收新的交易,并在清理队列操作期间删除过期或无效的交易,一次最多检查 10,000 笔交易。
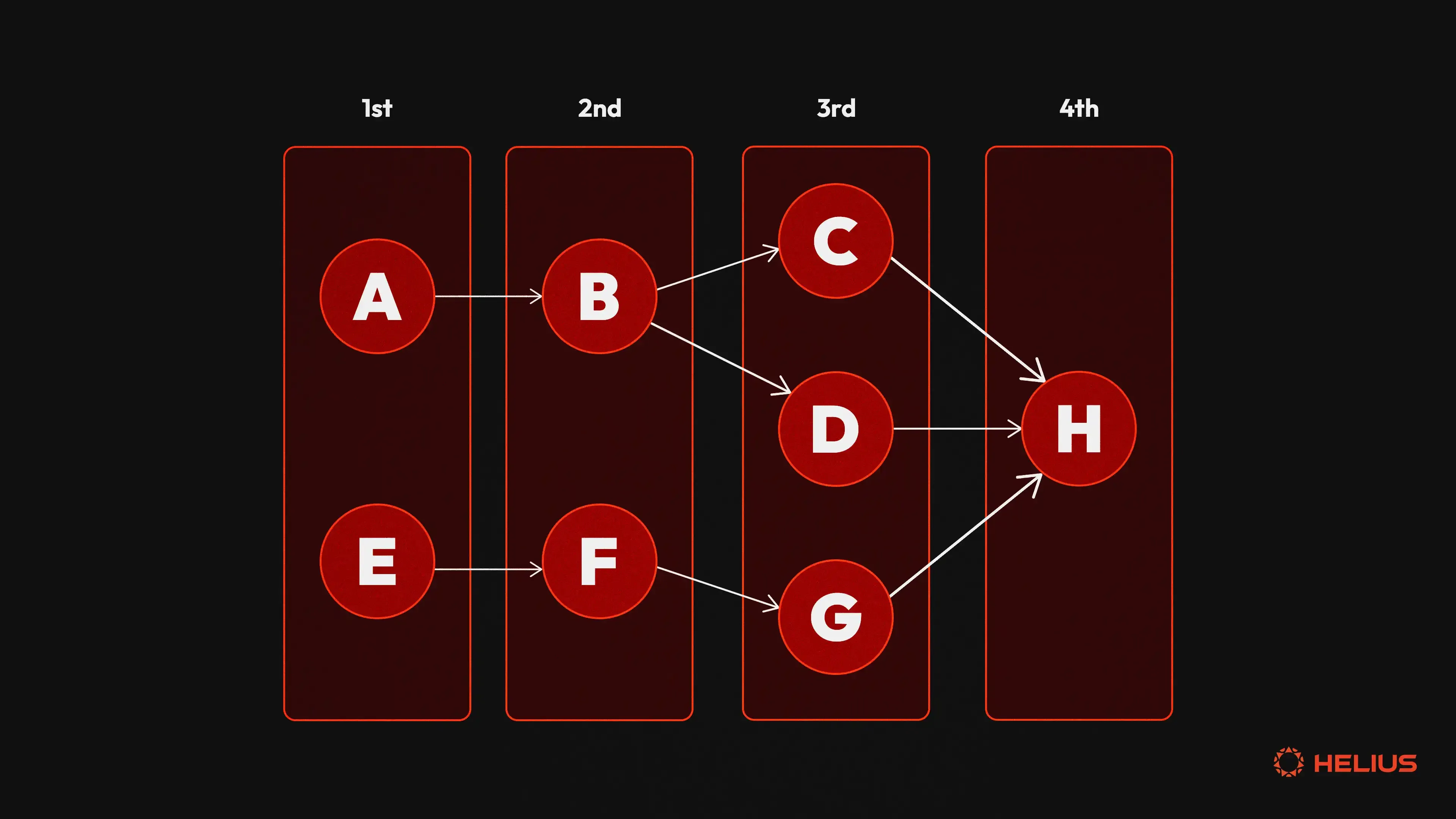
调度器使用冲突检测(即,希望为相同帐户保护读取和写入锁定的交易)来确定交易执行顺序。默认情况下有两种调度器实现可用:
- PrioGraphScheduler:一种构建优先级图以检测帐户冲突的调度器。
- GreedyScheduler:默认调度器,采用更直接的 FIFO 方法进行交易排序。
然后,调度器选择非冲突的交易并将它们分派给工作线程。每个工作人员接收一个批次并开始处理。
Bank Orchestration (银行编排)
Bank 代表特定 slot 中所有帐户的状态。它是管理帐户数据、强制执行运行时规则以及充当 Banking Stage 工作人员和 sBPF VM 之间协调器的中心数据结构,用于执行交易。
Lifecycle(生命周期)
每个 Bank 都会经历三个状态:
- Active(活动):新创建的 Bank,对交易开放。 Banking Stage 工作人员应用交易,直到 Bank 达到其目标tick计数或 slot 中的所有条目都已处理完毕。
- Frozen(冻结):一旦达到tick计数或所有条目都已处理完毕,Bank 就会被冻结。不能再应用任何交易。此时,交易费用会累积到区块领导者,sysvar 帐户会更新,并计算最终的 Bank 哈希。
- Rooted(已 Root):在冻结的 Bank 收到来自验证者的足够投票后,它将变为已 root。状态现在已最终确定,并成为链的账本的一部分。
除了创世 Bank 之外,每个 Bank 都指向一个父 Bank,形成一个树结构,表示账本的不同分支。
Execution Flow(执行流程)
Banking Stage 工作人员在当前工作 bank(即,为当前插槽构建的活动的、未冻结的 Bank)上运行。当工作人员从调度程序收到一批交易时,Bank 会协调执行:
- Account Locking(账户锁定):工作人员调用 prepare_sanitized_batch_with_results() 函数来锁定交易中引用的所有账户,以防止并发修改。
- Account Loading(账户加载):Bank 从 AccountsDB 中获取所有锁定的账户的账户数据。
- Fee Deduction(费用扣除):Bank 在执行前从付费方的账户中扣除交易费用。
- Validation(验证):Bank 验证 blockhash 是最近的,检查 nonce 账户状态,并验证账户所有权。
- VM Handoff(VM 切换):Bank 调用 load_and_execute_transactions(),将加载的账户传递给 sBPF VM。
- Execution(执行):sBPF VM 执行每个指令的程序字节码。
- Results(结果):sBPF VM 返回所有执行输出(即,LoadAndExecuteTransactionOutput)。
- Commitment(提交):Bank 通过 bank.commit_transactions() 将更新的账户状态写回 AccountsDB。
现在,执行进入 SVM 本身(即,sBPF VM)。在 Bank 调用 load_and_execute_transactions() 后,交易将通过一个多阶段流水线,其中每个指令都使用一个新的、隔离的 sBPF VM 实例进行处理,该实例已配置为执行程序的字节码。
交易的指令按顺序执行。每个指令的流水线是:
- Locate the Program(定位程序):从指令的程序 ID 查找程序账户。
- Load from Cache(从缓存加载):检查程序是否已在程序缓存中进行 JIT 编译。
- Provision the VM(配置 VM):创建具有特定内存区域和计算预算的隔离 sBPF VM 实例。
- Execute Bytecode(执行字节码):使用指令的输入运行程序的入口点。
- Verify Invariants(验证不变性):检查执行是否违反任何运行时规则。
- Collect Results(收集结果):打包执行结果。
Program Loading(程序加载)
在程序可以执行之前,必须从其链上帐户加载、验证并编译为本机机器代码。这通过程序缓存和 JIT 编译流水线完成。
程序缓存是一种性能优化,可避免在每次调用时重新加载和重新编译程序。它在交易批处理级别维护,并存储 ProgramCacheEntry 对象,其中包含:
- JIT-compiled Executable(JIT 编译的可执行文件):验证者 CPU 架构的本机机器代码。
- Deployment Metadata(部署元数据):程序部署并生效的 slot。
- Runtime Environment(运行时环境):对 syscall 注册表和执行配置的引用。
当交易引用程序 ID 时,将遵循以下查找顺序:
- Check Transaction Batch Cache(检查交易批处理缓存):查找缓存的、JIT 编译的版本。
- Check Global Program Cache(检查全局程序缓存):如果不在批处理缓存中,则检查验证者的全局缓存。
- Load From Account(从账户加载):如果所有缓存都未命中,则从 AccountsDB 加载程序账户。
- Parse ELF(解析 ELF):从程序账户数据中提取字节码。
- Verify Bytecode(验证字节码):运行静态验证器以确保安全。
- JIT Compile(JIT 编译):将 sBPF 字节码转换为本机机器代码。
- Cache Entry(缓存条目):存储编译后的程序以供将来调用。
这意味着新部署的程序的首次调用会产生加载、验证和编译的全部成本,而后续调用会直接执行缓存的本机代码。
当缓存未命中时,必须从其链上帐户加载程序。对于 BPF Loader Upgradeable 拥有的程序,程序帐户包含对 ProgramData 帐户的引用,该帐户是从 AccountsDB 加载的。对于 Loader V4 的单账户模型,字节码直接从程序账户加载,如果它是 zstd 压缩的,则可能需要解压缩。
提取的 ELF 字节被解析以定位可执行字节码和上述部分(即,.text、.rodata、.data/.bss、.symtab / .strtab)。成功解析 ELF 后,RequisiteVerifier(即,sBPF 的静态分析器)在不实际运行程序的情况下验证每个可能的执行路径,如前面的部分中所述。
JIT Compilation(JIT 编译)

一旦验证通过,字节码就会被即时 (JIT) 编译为本机机器代码。 JIT 编译器将每个 sBPF 指令转换为验证者架构的等效本机 CPU 指令。
JIT 编译使 sBPF VM 具有足够的性能来处理 Solana 的高吞吐量。如果没有 JIT,VM 将需要逐个指令地解释 sBPF 字节码,从而产生巨大的开销。
每个字节码指令都需要获取、解码和分派到处理程序代码,这会增加解释开销。然后,解释后的代码无法利用 CPU 级别的优化,例如流水线、分支预测或乱序执行。因此,每个 sBPF 指令都变成解释器中的函数调用。
JIT 编译通过生成直接在 CPU 上运行的本机机器代码,完全消除了这些成本。这会产生接近本机的性能、优化的边界检查、内联的计算计量、硬件级别的优化以及干净的寄存器分配映射。
JIT 编译器执行从 sBPF 字节码到本机机器代码的单通道转换。对于每个 sBPF 指令:
- 指令被解码以提取操作码、寄存器、偏移量和立即值。
- 设置堆栈帧,并保存被调用者保存的寄存器。
- 将 sBPF 操作映射到等效的 CPU 指令,以便每个操作都编译为本机指令。例如,在 x86-64 映射中,rax 将映射到 R0,而 rbp 将映射到 R10。
- 发出用于内存访问的边界检查和软件地址转换——由于其开销,将访客地址转换为主机地址是 VM 最慢的操作之一。
- 维护堆栈隔离(即,访客堆栈位于堆分配的缓冲区中,而不是主机堆栈中)。
- 插入 CU 扣除和预算检查以发出计算计量。
- 恢复寄存器并清理堆栈。
Instruction Translation(指令转换)
JIT 编译器以特定方式转换不同的指令类型(即,算术、内存访问、存储操作、条件分支、syscall 分派)。
算术运算 直接映射到单个本机 CPU 指令,开销为零,因为 sBPF 的寄存器可以很好地映射到验证者的相应硬件寄存器。
内存访问操作 需要边界检查以防止越界读取和写入。 JIT 编译器生成验证代码,该代码检查每个内存访问的下限和上限是否在有效区域边界内。
这基本上涉及 3 到 6 个本机指令,这些指令计算有效地址、验证它是否在预期范围内,然后执行实际加载。由于边界违规很少见,因此可以通过分支预测相对有效地处理此问题。
存储操作 包括边界检查和写入权限验证。编译后的代码验证目标地址是否在范围内,以及在写入内存之前是否启用了内存区域的写入权限。
条件分支 编译为本机条件跳转指令。 JIT 编译器在编译期间解析所有跳转目标,以便 sBPF 的相对指令偏移量转换为本机代码中的绝对地址。
syscall 分派 需要保存 VM 的状态 – 所有 11 个寄存器 – 并调用本机 syscall 处理程序。之后,VM 状态将使用返回值恢复。这种状态管理开销是 syscall 具有固定 CU 成本的原因,该成本高于常规指令。
Compute Unit Metering(计算单元计量)
JIT 编译器将计算单元跟踪直接内联到生成的代码中。每个 sBPF 指令都包括一个预算检查,以确保预算不会耗尽,因为指令会从剩余的 CU 计数中递减。
这种内联避免了函数调用开销,并且可以通过分支预测、乱序执行(即,CU 检查和操作可以并行执行)和指令级并行性来有效地完成。
对于具有可变成本的 syscall(例如,随数据长度缩放 的 sol_sha256 syscall),成本计算发生在返回到 VM 之前的本机 syscall 实现中。
Caching the Compiled Code(缓存编译后的代码)
JIT 编译完成后,本机可执行文件存储在 ProgramCacheEntry 中,其中包含:
- JIT 编译的代码
- 部署插槽和有效插槽元数据
- syscall 注册表引用
- 运行时环境配置
缓存条目放置在交易批处理缓存和全局程序缓存中。前者可用于当前批处理中的所有指令,而后者可用于所有未来的交易。
当程序升级(即,部署了新的字节码)、程序帐户关闭、功能门更改 syscall 可用性或验证者决定刷新其缓存时,可以使缓存条目无效。
Effective Slot Delay(有效 Slot 延迟)
请注意,在插槽 n 中部署的程序直到插槽 n + 1 才能被调用。此延迟确保所有验证者都观察到部署,程序缓存在网络上同步,并强制执行每个插槽的原子性。
Provisioning the sBPF VM(配置 sBPF VM)
一旦程序被加载和 JIT 编译,或从缓存中检索到,就会为每个指令执行配置一个新的 sBPF VM。此配置发生在 BPF Loader 中,涉及设置五个不同的内存区域,初始化计算预算,并注册 syscall。
Memory Regions(内存区域)
如我们在SVM ISA 部分中提到的,VM 创建了五个不同的内存区域。这些区域共同构成了 Solana 程序执行的隔离沙箱。
程序内存区域 通常从地址 0x100000000 开始。它包含要执行的 JIT 编译的本机代码——这是实际的机器代码,取决于验证者的 CPU 架构。如果禁用 JIT 进行调试,那么此区域将包含解释的 sBPF 字节码。此部分的权限是 只 读和执行。
只读数据 也包含在 0x100000000 中。它包含从程序加载期间从 ELF .rodata 部分提取的常量和静态字符串。此内存区域的目的是提供对编译时常量的有效访问,而无需堆分配。
堆栈 从 0x200000000 开始,包含局部变量、函数调用帧和返回地址。这是执行期间发生临时计算的地方。它从区域的顶部向下增长,寄存器 R10(即,帧指针)标记当前帧边界。允许对此区域进行读写权限,并且其大小固定为每个调用帧 4KB。超过此限制将引发 StackAccessViolation 错误,指示堆栈溢出。堆栈的较小尺寸鼓励开发人员使用堆,或者更好的是,将数据存储在帐户中,而不是依赖于基于堆栈的存储。
堆 从 0x300000000 开始,包含动态分配的内存,用于不适合堆栈或帐户的运行时数据结构。其大小范围从默认值 32KB 到最大值 256KB。以前,程序可以通过 sol_alloc_free syscall 扩展堆。但是,sol_alloc_free syscall 已被弃用,并且对新的程序部署禁用。程序必须在部署时指定其所需的堆大小,而不是动态扩展。
注意:堆增长根据公式 (heap_size / 32KB) * 8,000 CUs 消耗计算单元,默认堆成本为 8 CUs。
输入数据内存区域 从地址 0x400000000 开始。它包含程序在调用时接收的序列化入口点参数。这是一个只读内存区域,实际大小因交易而异。三个序列化组件是被调用的程序的 32 字节公钥、一个帐户数组和指令数据。
Memory Access Enforcement(内存访问强制执行)
每个内存加载和存储指令都由 VM 进行边界检查。在每次内存访问之前,VM 验证地址是否在区域的有效范围内,并且该区域允许访问类型(即,读取或写入)。
如果任一检查失败,执行将立即中止并显示 AccessViolation 错误。整个交易将回滚,并且不会提交任何状态更改。
这种强制执行以接近零的运行时成本发生,因为 JIT 编译器将这些检查编译为 CPU 可以直接执行的有效本机代码。鉴于违规行为很少见,现代分支预测可以有效地处理这些检查。
Compute Budget Initialization(计算预算初始化)
每个 VM 实例都使用计算单元预算进行初始化,该预算限制了给定程序可以执行的总工作量。这种有界执行模型确保程序不会无限期地运行,并且所有验证者都在可预测的窗口中执行交易。
当前预算参数如下:
- Default Compute Unit Limit per Instruction(每个指令的默认计算单元限制):200,000 CUs。
- Maximum Compute Unit Limit per Transaction(每个交易的最大计算单元限制):1,400,000 CUs。
- Builtin Instruction Limit(内置指令限制):3,000 CUs。
每个交易的默认 CU 为 min(1_400_00, (200_000*non_reserve_instructions + 3_000*reserve_instructions))。这本质上是基于提供的指令,最大计算单元限制和每个指令类型的默认成本之间的最小值。
计算预算跟踪整个执行过程中的剩余单元。当每个 sBPF 指令执行时,它会从剩余预算中递减其 CU 成本。如果在程序完成之前预算达到零,则执行将立即停止并显示InstructionError::ComputationalBudgetExceeded。交易失败,不会提交任何状态更改,但付费方仍然需要支付交易费用,以补偿验证者处理其交易。
Syscall Registry(系统调用注册表)
在 VM 配置过程中,还会在每个 syscall 的唯一 32 位 Murmur 哈希标识符与其原生 Rust 实现之间建立映射,以便注册所有可用的 syscall。
当程序执行带有 syscall 哈希的 CALL_IMM 指令时,会发生以下情况:
- VM 暂停 sBPF 指令流。
- syscall 分派器使用哈希在注册表中找到实现。
- syscall 验证调用者是否具有必要的权限(例如,进行 CPU、帐户所有权)。
- syscall 的 Rust 实现以沙箱外的完全运行时访问权限执行。
- syscall 的固定成本从剩余的计算预算中扣除。
- 结果放置在寄存器 R0 中,并恢复 sBPF 执行。
Program Execution(程序执行)
一旦配置了 sBPF VM,执行就会在程序的入口点函数处开始。对于 JIT 编译的程序,VM 直接跳转到本机机器代码,并让验证者的 CPU 本机执行它。如上一节所述,JIT 编译的代码包括所有必要的检测——内存边界检查、计算计量和控制流程验证,所有这些都内联以实现最佳性能。
寄存器 R1 包含指向输入数据区域的指针,其中驻留着三个序列化的参数(即,调用的程序的公钥、帐户数组和指令数据)。
注意:帐户数据通过指针访问,而不是复制。使用指针允许程序就地读取和修改帐户数据,这对于性能至关重要。
每个函数调用都会分配一个新的 4KB 堆栈帧,寄存器 R10 更新为指向新的帧。计算根据上述计算预算进行计量。
Cross-Program Invocations (CPI)(跨程序调用 (CPI))
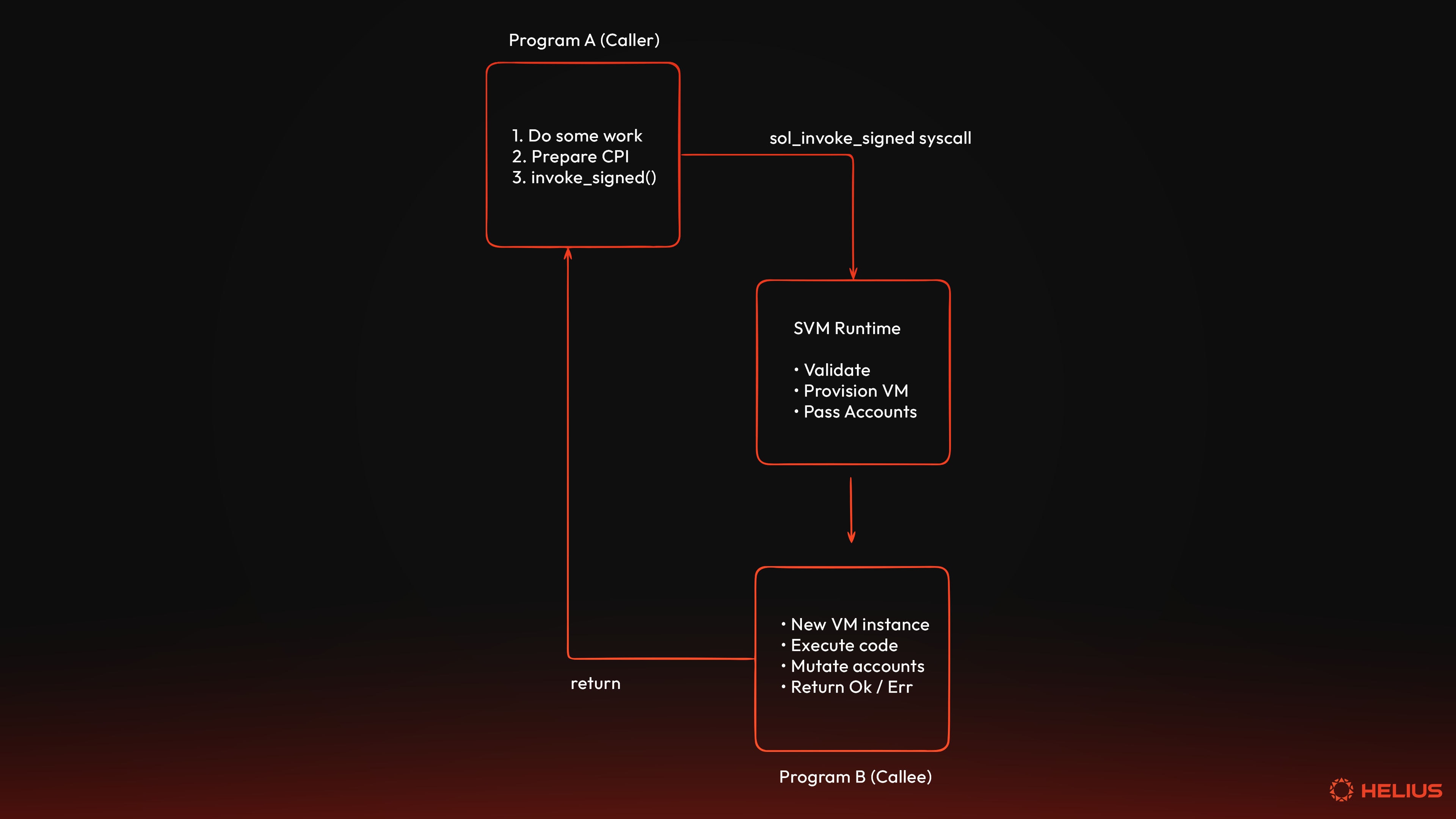
在执行期间,程序可以通过跨程序调用 (CPI) 调用其他程序——SVM 可组合性的支柱。
CPI 是通过 sol_invoke_signed syscall 启动的,该 syscall 的成本为 1,000 CUs,加上基于所传递的序列化帐户数据的额外成本。帐户数据和指令数据序列化的成本均为每个 CU 250 字节。
当程序进行 CPI 时,将创建一个新的执行上下文,其中包含其自己的指令堆栈帧。在编写本文时,最大指令堆栈深度为 5,或者在启用 SIMD-0268 的情况下为 9,这意味着一个程序可以调用另一个程序,该程序可以调用另一个程序,直到达到深度限制。每个嵌套调用都维护其自己的一组可写帐户和签名者权限。CPI 最多可以有 16 个签名者 并且可以传入 128 个 AccountInfo 结构体。
调用者序列化目标程序 ID、帐户和指令数据,然后调用 syscall。当前程序的执行暂停,并为被调用程序配置一个新的 sBPF VM 实例,遵循与上述相同的配置过程。然后开始被调用程序的执行。被调用程序使用从调用方的剩余预算中提取的自己的计算预算运行,这意味着 CPI 调用共享交易的总计算预算。
程序可以代表他们通过 程序派生地址 (PDA) 拥有的帐户进行签名。在使用 sol_invoke_signed 调用时,调用者提供种子以证明 PDA 的所有权。在授予被调用者签名权限之前,会验证 PDA 派生。
当被调用者完成时,控制权返回给调用者。被调用者所做的帐户修改对调用者可见,允许状态流经调用链。如果 CPI 链中的任何程序失败,则整个交易中止,并且所有状态更改都会还原。
注意:sol_invoke 是一个辅助程序,它在没有种子的情况下调用 sol_invoke_signed。
Post-Execution Verification(执行后验证)
在程序执行完成后,无论是直接执行还是作为 CPI 链的一部分,都会进行多次执行后检查,以确保状态一致性和安全不变性。
例如,运行时会验证所有标记为可写的帐户实际上是否由程序拥有或已正确签名——程序无法修改他们不拥有的帐户,除非这些帐户已明确标记为可写并且所有者已授予权限,从而防止未经授权的状态修改。
运行时还会检查交易中所有帐户的 lamport 总和是否相同,除非 lamport 已通过系统程序指令显式转移。此保护检查可防止程序创建或销毁 lamport,从而使 SOL 的总供应量保持不变。
运行时会验证所有带有可执行标志的帐户(即,程序)是否未被修改。程序无法在正常执行期间更改其数据,并且只能通过 BPF Loader 的升级权限机制进行升级。
Execution Results(执行结果)
一旦执行后验证完成,执行结果将返回给 Bank 的交易处理器。结果包含成功或错误状态(即,分别为零或非零结果)、使用的计算单元数以及对帐户状态所做的任何修改。
Bank 会原子地提交成功执行的所有帐户修改。更新的帐户数据、lamport 余额和元数据将写入 AccountsDB,并在后续交易中可见。将记录使用的计算单元,用于交易费用计算和网络指标。
对于失败的交易,不会提交任何状态更改——Solana 上没有部分恢复,因为交易会完全回滚。但是,交易费用仍会从付费方的帐户中扣除,以补偿验证者执行的计算工作。错误代码和使用的计算单元记录在交易元数据中,用于调试和分析目的。
执行结果会流回 Banking Stage 调度程序,该程序会更新其内部指标并继续进行下一笔交易。成功和失败的交易都会记录到 Proof of History 流中,并有助于构建当前的区块。包含失败的交易有助于防止重放攻击并维护完整的交易历史记录。
当插槽完成并收到其最大tick计数时,Bank 将转换为冻结状态。冻结是一种单向操作,可防止提交新的交易并计算 Bank 的哈希。请注意,冻结并不意味着最终确定——该插槽可能仍在被丢弃的分支上。
当验证者调用 BankForks::set_root() 以将其指定为规范链的一部分时,Bank 变为已 root。Rooting 触发 squash 操作,将已 root Bank 的帐户状态展平到 AccountsDB 中,合并所有父状态,并使其从验证者的角度来看是永久的。非 root 分支会被修剪和丢弃。由于 Solana 不同的 commitment levels,即使是已 root 的 Bank 也尚未从集群的角度来看进行最终确定。
Looking Forward(展望未来)
Solana 虚拟机代表了一种从根本上不同的区块链执行方法——一种可供大众使用的可扩展区块链,这归功于并行处理、本地费用市场以及高性能、确定性的 eBPF 派生运行时。
要理解 SVM,需要检查整个执行流水线,从 Rust 源代码编译到 LLVM、sBPF,最后到隔离 VM 实例的配置。
没有定义 SVM 的单一“规范”。相反,它是从 Bank、调度器、BPF Loader、sBPF VM 和 SVM ISA 的交互中产生的。
随着 SVM 的不断发展,未来看起来很有希望。
Solana 工具链正在进行全面改革,以消除多年来一直困扰开发人员入职的自定义 LLVM 基础架构。
当前的方法要求开发人员通过特定于平台的脚本安装自定义工具链。解决方案是采用与 Aya(Rust eBPF 库)使用的相同工具链。开发人员将能够运行两个简单的命令来直接编译为 eBPF 字节码:
rustup toolchain 安装 nightly
cargo build --target=bpfel-unknown-none没有脚本。没有自定义 LLVM 分支。只需使用上游 bpfel-unknown-none 目标,利用 Linux 内核开发和 LLVM 基础架构改进的无数年,将标准 Rust 工具直接编译为 eBPF 字节码。 SVM ISA 也将通过 SIMD-0377 进行更新,该提案旨在使 Solana 的 eBPF 实现(即 sBPF)与现代 eBPF 标准对齐。这包括引入 JMP32 指令变体、有符号除法和模运算、间接跳转和动态堆栈帧。这些更改将有助于降低程序计算成本、提高与上游 LLVM 基础设施的兼容性,并实现更高效的代码生成。
SVM 本质上是一个通过计算预算进行计量的系统。SIMD-0370 准备通过删除区块级别的计算上限,以及可能删除交易上限来改变这种运作方式。删除这些计算上限将使区块生产者能够根据其硬件能力(而非人为限制)来最大化吞吐量。结合 Alpenglow 的超时机制,此更改将使市场力量(而非协议级别的约束)决定最佳区块大小。当然,这是非常超前的,因为 Anza 希望先将 CU 限制提高到 1 亿以上,然后再取消这种上限。
所有这些更改的基础是一种构建者的精神,即在不牺牲安全性、确定性或去中心化的情况下,推动区块链可以实现的边界。
SVM 不仅仅是一个字节码解释器,它是一个完整的执行管道,彻底改变了区块链的功能。它是架构决策的结晶,这些决策优先考虑吞吐量和低延迟。随着 Solana 的成熟,SVM 将继续发展,以支持高性能、资本高效的应用程序。
互联网资本市场的梦想需要能够处理全球金融系统的吞吐量、延迟和成本要求的基础设施。Solana 虚拟机是实现这一愿景的关键一步。
附加资源
- Anza 的新 SVM API
- 如何使用 SBPF 汇编编写 Solana 程序
- Rust Compiler For Dummies
- Solana eBPF 虚拟机
- Solana 编程模型:Solana 开发简介
- 关于 Solana 本地费用市场的真相
- 从 Rust 代码到 SBPF 字节码的 Solana 程序执行幕后
- 什么是 SVM - Solana 虚拟机
- 原文链接: helius.dev/blog/solana-v...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





