人工智能与盗版:通用人工智能是否能阅读书籍并抄袭内容进行学习?
- asecuritysite
- 发布于 2025-12-03 14:49
- 阅读 981
文章讨论了AI公司(如Anthropic)使用书籍内容训练大型语言模型(LLM)是否侵犯版权的问题。文章引用Bartz v Antropic案例,指出如果公司购买书籍或从公共图书馆获取书籍进行扫描和用于LLM训练,属于合理使用;但如果使用盗版书籍,则构成侵权,可能面临法律诉讼。

AI 和盗版:GenAI 可以为了学习而阅读书籍和窃取内容吗?
我参与了一起集体诉讼,它涉及到我的两本书被 Anthropic 扫描 — 他们拥有 Claude AI 代理 — 然后被用在他们的 LLM 模型中:

图:这封邮件是真实的,并且与针对 Anthropic 的集体诉讼有关
所以,我们有这样一个问题…
GenAI 在未经我同意的情况下扫描我的书籍内容是否可以接受?
正如我们将看到的,答案是,如果该公司购买了该书或从公共图书馆获取了该书,那么这是可以接受的,就像有人阅读我的书并从中学习一样。只要 LLM 不向用户回放我的书的内容,那就是可以接受的。但是,如果 GenAI 公司从盗版网站获取我的书,那是不可接受的,我可以起诉该公司。明白了吗?好吧,我将解释。
简介
我发自内心地不喜欢 GenAI 为了少数公司的利润而窃取知识产权(IP)的方式。对我来说,目前,GenAI 呈现出一种虚假的智能,远非人类智能。对于 LLM,我们看到一种智能模型,它基本上只是对模板化答案中的下一个词进行概率猜测。
因此,主要的担忧之一是 GenAI 在未经许可的情况下抓取 IP,然后将其用在其模型中。这违反了我们现有的法律,并且没有任何回报给那些创造者 — 所有的利润都流向了 GenAI 公司。然而,这种情况已经发生了至少十年,谷歌扫描了几乎所有能找到的书籍,但未能征求许可。
Bartz v Antropic
总的来说,显然,一些 GenAI 公司正在违反现有的版权规则,并且在需要时没有征求许可。一个已经成功的案例是 Bartz v Antropic [ 这里]:

这与 2025 年 6 月 23 日加利福尼亚州的一名法官有关:
地区法院认为,Anthropic 使用书籍来训练其 Claude 大型语言模型,以及使用购买的书籍副本来创建数字永久图书馆构成合理使用,但使用盗版书籍来创建此类图书馆不构成合理使用。
这与 GenAI Claude 平台有关。为此,Anthropic 使用来自中央图书馆的书籍来训练其 LLM,但也使用了来自在线盗版图书馆(如 Books3 和 Library Genesis)的书籍。他们还批量购买书籍,然后剥去装订并扫描书籍 — 购买并扫描的副本。所有这些书籍随后在 LLM 中被索引用于训练。总的来说,这些书籍没有以其原始内容的形式呈现,因此 Anthropic 认为他们没有违反版权。对于 Anthropic 来说,这些书籍仅仅用于训练他们的模型。
对于 LLM 的训练,法院概述:
使用受版权保护的作品来训练 LLM 以生成新文本的目的和性质本质上是变革性的…… [l] 就像任何渴望成为作家的读者一样,Anthropic 的 LLM 训练作品不是为了抢先复制或取代 [这些作品] — 而是为了实现彻底的转变并创造出不同的东西。
因此,它裁定 LLM 训练要素为“合理使用”,因为它与某人阅读书籍然后从中学习的方式相同。
对于 “购买并扫描” 的方法,法院认为它已经公平地购买了实体书,然后有权将内容更改为另一种形式,然后随意处置该书。格式的更改使 Anthropic 能够快速索引内容并压缩内容的存储。
对于未经购买而下载的盗版书籍,法院裁定 Anthropic 无权在其图书馆中使用这些书籍,无论它是否将这些书籍用于 LLM 训练。法院将其定义为非变革性的。另一方面,对于 Google 图书,这些书籍直接链接到原始作品。对于 LLM 训练,情况并非如此(因为没有全文版本可用):
不存在 Anthropic 制作其第一份副本的授权副本。从中提取的全文副本没有立即用于训练 LLM。甚至不是每个副本都是必要的,也不是用于训练 LLM。
可以扫描所有涉及的书籍 [ 这里]:
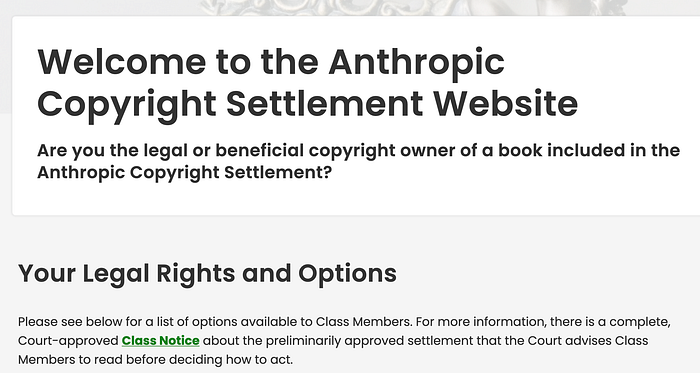
这是我的其中一本书:
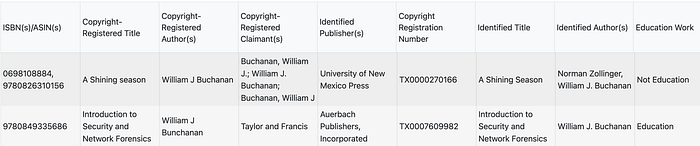
总之,该裁决定义,当公司购买书籍或使用开放图书馆时,扫描并用于训练 LLM 模型是合理使用,但盗版副本违反了合理使用:
然而,对于用于构建 Anthropic 中央图书馆的下载盗版副本,每个因素都与合理使用相悖。因此,法院驳回了关于此问题的简易判决,并将由此造成的损害问题留待审判。
正是这一点裁决将被用于索赔每本书约 3,000 美元的赔偿金。
结论
GenAI 正在窃取 IP,并且从法律的角度来看,他们可以逃脱惩罚,所以要小心!任何公开的东西都可能成为 GenAI 的合理游戏,所以注意你分享的内容!
- 原文链接: billatnapier.medium.com/...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





