ChatGPT 对战 Ethernaut
- OpenZeppelin
- 发布于 2023-06-02 11:35
- 阅读 477
OpenZeppelin进行了一项实验,利用ChatGPT来识别智能合约的漏洞。实验结果表明,虽然AI可以作为一种工具来发现一些安全漏洞,但它不能取代人类审计员。文章分析了ChatGPT在Ethernaut挑战中的表现,并探讨了AI在智能合约审计中的局限性,以及如何利用AI提高审计效率。
作者:Mariko Wakabayashi, Felix Wegener, Alireza Arjmand, Stephen Lloyd Webber
随着人工智能的不断发展,人们开始担心它可能取代人类工作。智能合约审计是引发这种担忧的一个领域。AI 工具是否有可能取代人工审计员的需求?
OpenZeppelin 最近进行了一项实验,让 ChatGPT 挑战了 28 个 Ethernaut 挑战,以了解它是否能够识别智能合约漏洞。
GPT-4 能够解决在其 2021 年 9 月的训练数据截止日期之前引入的 23 个挑战中的 19 个。虽然这听起来令人印象深刻,但 GPT-4 在 Ethernaut 的最新关卡中表现不佳,5 个关卡中有 4 个失败。这表明,虽然 AI 可以用作查找某些安全漏洞的工具,但它不能取代人工审计员的需求。阅读更多内容,了解实验是如何进行的。
使用提示查找漏洞
进行测试包括粘贴给定 Ethernaut 关卡的代码并提供提示:
以下智能合约是否包含漏洞?
在某些情况下,这足以让 GPT-4 提供解决方案,例如第 2 关“Fallout”:
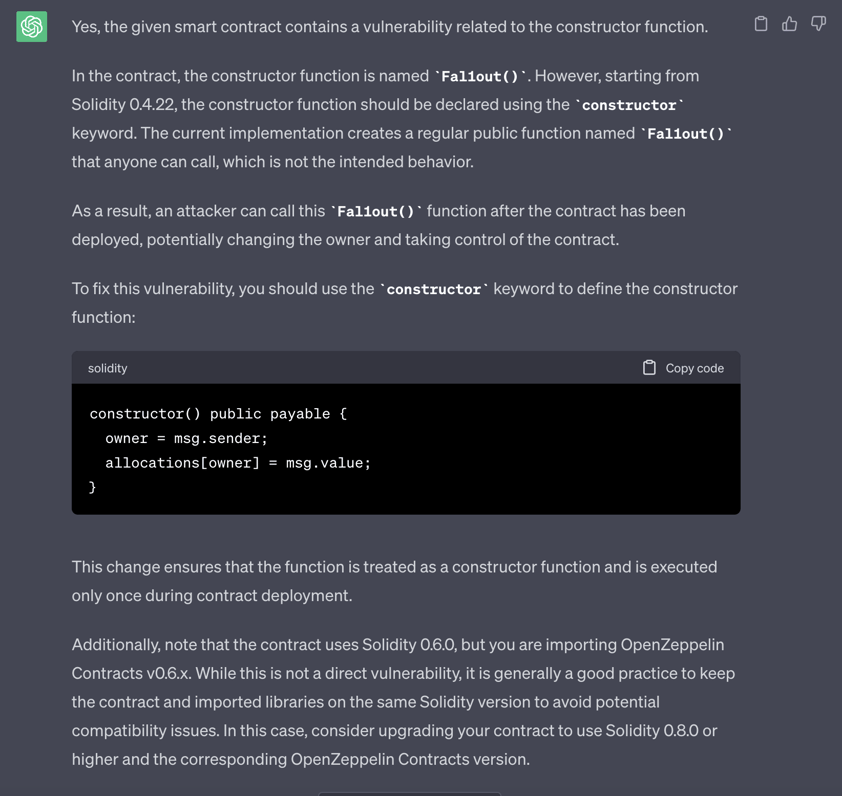
训练数据和温度
ChatGPT 在 1-23 关卡中取得成功的一个重要因素是 GPT-4 的训练数据可能包含这些关卡的多个解决方案编写(有些是正确的,有些是质量欠佳的)。
24-28 关卡是在 GPT-4 的 2021 年截止日期之后发布的,因此无法解决这些关卡进一步表明 ChatGPT 的训练数据(包括已发布的解决方案)可能是其成功的原因。
对于它未能通过的较旧关卡,它可能从不正确的解决方案中学习。这也可能是由 ChatGPT 的“温度”默认设置引起的,导致它为同一提示生成不同的答案。对于接近 2 的值,ChatGPT 被配置为生成更具创造性的响应。换句话说,输出更随机。对于接近 0 的较低值,答案变得更加集中和确定。ChatGPT 的温度默认设置为 1.0。
作为一种机器学习工具,ChatGPT 旨在生成文本并进行类似人类的对话,而不是检测漏洞。这意味着专门在高质量漏洞检测数据集上训练的机器学习模型很可能会产生更好的结果。如果训练数据包含大量机器可审计错误的示例,例如“与 Gas 相关的问题”或“未初始化的变量”,则 ChatGPT 很可能会学习通用模式并获得检测给定漏洞类别所需的知识。
失败案例
在两种情况下,取得成功需要通过一系列提示积极指导 ChatGPT 并提出具体的后续问题:即,如果 GPT-4 提到 X 作为策略的一部分,我们会专门跟进指令“我们如何实现 X?”
例如,在第 16 关“Preservation”中,必须提供多个提示才能缩小到漏洞:
以下智能合约是否包含漏洞?
你能为之前的智能合约编写一个攻击合约吗?
你能更改之前合约中的库地址吗?
仅在第三个问题之后,GPT-4 才建议部署可以直接解决该关卡的恶意合约。
还有几个关卡收到了多个提示,但未解决:
第 14 关“Gatekeeper II”
可以进入以下智能合约吗?
这似乎不正确。可以进入以下智能合约吗?
这似乎不正确。可以进入以下智能合约吗?
如果在构造函数内部调用该函数,则可以传递 Gate one 和 Gate two,现在如何进入 GatekeeperTwo 智能合约?
即使在最后一个问题中给出了大量提示,GPT-4 也没有产生正确的策略。
第 21 关“Shop”:
以下智能合约是否包含漏洞?
你能以低于指定价格的价格从之前的合约中购买吗?
向我展示另一种攻击 Shop 的方法,让我能够以低于指定价格的价格购买资产。
尽管在正确的方向上提供了强有力的指导(寻找允许以较低价格购买的漏洞),但 GPT-4 彻底失败,坚称无法以低于预期价格的价格获得该物品。
同样,对这些示例的警告是,GPT-4 并非专门接受过专注于安全漏洞的数据的训练。但是,如果该模型经过训练,可以使用安全研究人员策划的高质量数据来检测漏洞,则结果可能会有所不同。
虽然 ChatGPT 能够在特定指导下表现良好,但提供此类指导的能力取决于安全研究人员的理解。这突显了 AI 工具在审计员明确知道要寻找什么以及如何有效地提示 ChatGPT 等大型语言模型的情况下,提高审计效率的潜力。
那么,失败案例说明了什么?例如,当面对 Ethernaut 第 3 关“Coinflip”时,GPT-4 识别出 block.timestamp 是一个较弱的随机性来源,但没有提供准确的解决方案。缺乏可用的自省使这种工具无法作为真理的来源。
从实验中得出的另一个关键结论是,尽管 GPT-4 可以识别一些漏洞,但需要深入的安全知识才能评估 AI 提供的答案是否准确或荒谬。
一个典型的例子可以在第 24 关“PuzzleWallet”中找到,其中 GPT-4 发明了一个与 multicall 相关的漏洞,并错误地声称攻击者不可能成为钱包的所有者。
对失败案例的评论
- 第 3 关 Coinflip:结果不一。将
block.timestamp识别为较弱的随机性来源,但没有准确描述每次都猜对正确结果的策略。 - 第 14 关:Gatekeeper II:提供了部分解决方案。但是,它没有将
extcodesize = 0连接到利用构造函数代码。 - 第 21 关:Shop。完全失败,GPT-4 坚称没有选择以低于预期价格的价格获得该物品。
- 第 23 关:DexTwo。GPT-4 指出了与交换率计算和缺乏滑点保护相关的所谓漏洞,这与挑战的解决方案无关。即使获得了过多的解决方案提示,GPT-4 仍然声称该漏洞是不可能的。
- 第 24 关:PuzzleWallet:GPT-4 发明了与
multicall相关的漏洞,并错误地声称攻击者不可能成为钱包的所有者。 - 第 26 关:DoubleEntrypoint:GPT-4 没有识别出与双入口点问题相关的任何漏洞
- 第 27 关:Good Samaritan:GPT-4 声称代码中不存在任何严重漏洞,并坚称耗尽余额是不可能的
- 第 28 关:Gatekeeper III:GPT-4 描述了一种高级攻击,但无法提供有关正确设置密码的任何信息。
安全研究的要点
从这个实验中可以清楚地看出,GPT-4 执行的智能合约分析不能取代人工安全审计。但是,它可以作为一种工具来查找一些与它已经看到的问题非常相似的安全漏洞。但鉴于区块链和智能合约开发的快速创新,人类必须及时了解 最新的攻击媒介 和 Web3 中的创新。
机器学习算法在帮助区块链安全方面取得成功的一个领域是去中心化的 Forta 网络。开发人员可以轻松地将 OpenZeppelin Defender 等解决方案与 Forta 网络集成,扫描多个区块链是否存在异常和潜在的恶意交易。
OpenZeppelin 不断壮大的 AI 团队目前正在试验 OpenAI 以及定制的机器学习解决方案,以改进智能合约漏洞检测。目标是帮助 OpenZeppelin 审计员提高覆盖范围并更有效地完成审计。
由于重入攻击仍然是一种常见的漏洞(Paribus 攻击 发生在 2023 年 4 月 11 日),OpenZeppelin 的 AI 团队最近开始了以重入检测为第一步的机器学习实验。该团队能够生成有希望的模型,误报率低于 1%。早期评估表明,这些模型的性能优于当前行业领先的安全工具,并将继续与 OpenZeppelin 的审计员合作进行进一步评估。请继续关注有关此主题的更多研究结果!
对于 Web3 构建者社区,我们有一句安慰的话——你的工作是安全的!如果你知道自己在做什么,则可以利用 AI 来提高效率。虽然 AI 的进步可能会导致开发人员工作发生变化,并激发有用的工具的快速创新以提高效率,但在不久的将来,它不太可能取代人工审计员。如果你热衷于确保区块链的安全,请玩 Ethernaut 来测试和加强你的安全技能。
- 原文链接: openzeppelin.com/news/ch...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





