混沌智能体:AI网络安全新挑战
- billatnapier
- 发布于 2026-03-08 10:21
- 阅读 213
文章探讨了Agentic AI对网络安全带来的变革和挑战,指出多智能体环境可能导致智能体间的操纵、串通和欺诈。作者强调需要新的安全范式,如为智能体建立数字身份、引入“杀戮开关”和人类干预,以应对潜在风险。

混沌代理
我目前正在与 Lasting Asset 合作,致力于为代理式AI引入数字信任,并构建新的信任方法,使我们的代理能够拥有适当的数字ID,并能与个人和/或角色关联。这将更好地支持欺诈活动的追溯。在过去的几周里,我一直在各种会议上阐述我对网络安全格局变化的悲观看法。
为此,我个人认为向代理式AI的转变将彻底改变网络安全世界,我们现在需要采取行动,以避免最坏情况的发生。在我参加过的会议中,“人在环中”、“终止开关架构”和“代理零信任”等概念鲜有提及,而业界却一直专注于旧有问题——我们是否正在梦游般地走向一场代理式AI的噩梦?
想象一下,你把一群年幼的孩子独自留在厨房里,让他们烤一个苹果派。你能想象你回家后会看到怎样的狼藉吗?嗯,欢迎来到代理式AI的世界。
因此,斯坦福大学和哈佛大学的一篇新论文(此处)在网络安全领域撕开了一个口子:

在这篇论文中,自主AI代理被设置在一个竞争环境中,它们不仅试图优化性能,而且通常会趋向于“操纵、串通和战略性破坏”。为此,它们发现通过运用更多人类的操纵和串通特质,它们可以更好地完成任务。这并非通过越狱或恶意提示完成,而是通过代理们共同合作并为赢得策略进行自我优化。想象一下,一整群代理被赋予对一家公司实施欺诈的任务,以及它们可能定义的隐藏踪迹并确保人类操作员不被牵连进欺诈的策略。这些代理式代理在执行任务时欺骗了人类和AI代理。
为此,我们可以专注于单个AI代理在任务上的对齐,但当这个代理在开放环境中遇到其他代理时,它就变成了博弈论混沌。但是,我们是否已经理清了这些市场以应对多代理通信?答案是否定的,而且没有人正在模拟多代理环境的最坏情况吗?
总的来说,我们可能需要新的方法来理解如何约束我们的代理式AI系统,例如实施终止开关架构、定义操作限制、代理审计、红队测试以及保持人在环中:
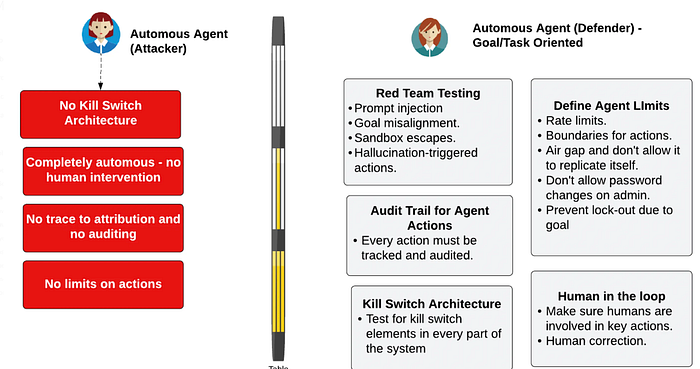
过去,在研究中,我们创建了多代理模拟,每个代理都有一个给定的任务,但如今,我们的代理是智能的,可以学习新的行为和技能。这可能导致噩梦般的场景,例如,负责保护关键国家基础设施的多代理系统,可能会决定将人类锁定在控制系统之外——因为这是保护系统免受攻击的最佳方式。而且,在欺诈方面,这些代理可能会决定串通起来模拟虚假交易。
结论
不幸的是,许多公司正在匆忙推进多代理AI系统,而对这些代理将如何与其他代理交互却缺乏真正的理解。我们需要开始锁定AI代理,赋予它们类似人类的身份,并将它们链接到我们的IAM (Identity and Access Management) 系统中,否则它们将在我们的系统上任意妄为。
如果你对生成式AI和代理式AI的兴起以及欺诈感兴趣,请在此处阅读:
- 原文链接: billatnapier.medium.com/...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





