Snap v2:以 BALs 取代 Trie 愈合 — 执行层研究
- 以太坊中文
- 发布于 2026-03-10 22:21
- 阅读 273
本文详细介绍了以太坊快照同步(snap/1)中的“trie healing”阶段作为主要的同步瓶颈,该阶段迭代发现并修复状态不一致,效率低下。
快照同步(snap/1)在 Geth v1.10.0 中发布后,极大地改善了以太坊节点的同步。但它有一个众所周知的阿喀琉斯之踵:trie 修复阶段,这是一个迭代过程,同步节点在此阶段一次一个 trie 节点地发现并修复状态不一致性。这个阶段导致节点在修复过程中停滞数天或数周,并被认为是社区希望消除的问题。
随着 EIP-7928(区块级访问列表)的引入,一种新方法成为可能:完全用顺序 BAL 应用取代 trie 修复。本文将解释快照同步目前的工作方式,trie 修复存在的问题,以及拟议的 snap/2 协议升级将如何解决这个问题。
第 1 部分:快照同步目前的工作方式
快照同步解决的问题
一个新的以太坊节点需要当前状态:每个账户余额、存储槽和合约字节码。这种状态存在于一个默克尔帕特里夏树中,其中账户 trie 的饱和深度约为 7 层(EF 博客:快照加速),包含数亿个节点。
旧的方法(“快速同步”,eth/63–66)从根开始逐个节点下载这个 trie。在约 11,177,000 区块时,状态包含 6.17 亿个 trie 节点,同步它们需要下载 43.8 GB 的数据,分布在 1,607M 个数据包中,总计约 10 小时 50 分钟的同步时间。
快照同步的关键洞察:完全跳过中间 trie 节点,将叶子(账户、存储)作为连续范围下载,然后在本地重建 trie。这要求服务节点维护一个动态快照,这是一个扁平的键值存储,可以在约 7 分钟内迭代账户,而原始 trie 迭代需要约 9.5 小时(参见 snap.md)。
比较快速同步与快照同步,我们得到了以下改进:
| 指标 | 快速同步 | 快照同步 | 改进 |
|---|---|---|---|
| 下载 | 43.8 GB | 20.44 GB | -53% |
| 上传 | 20.38 GB | 0.15 GB | -99.3% |
| 数据包 | 1,607M | 0.099M | -99.99% |
| 服务磁盘读取 | 15.68 TB | 0.096 TB | -99.4% |
| 时间 | 10 小时 50 分钟 | 2 小时 6 分钟 | -80.6% |
注意:这些基准测试来自约 11.2M 区块(2020 年末)。自那时起,状态有所增长,但相对改进仍然具有代表性。在良好硬件上,现代快照同步通常总共需要 2-3 小时。
三个阶段
快照同步分三个阶段进行:
 \
sync690×260 28.6 KB
\
sync690×260 28.6 KB阶段 1 - 区块头下载
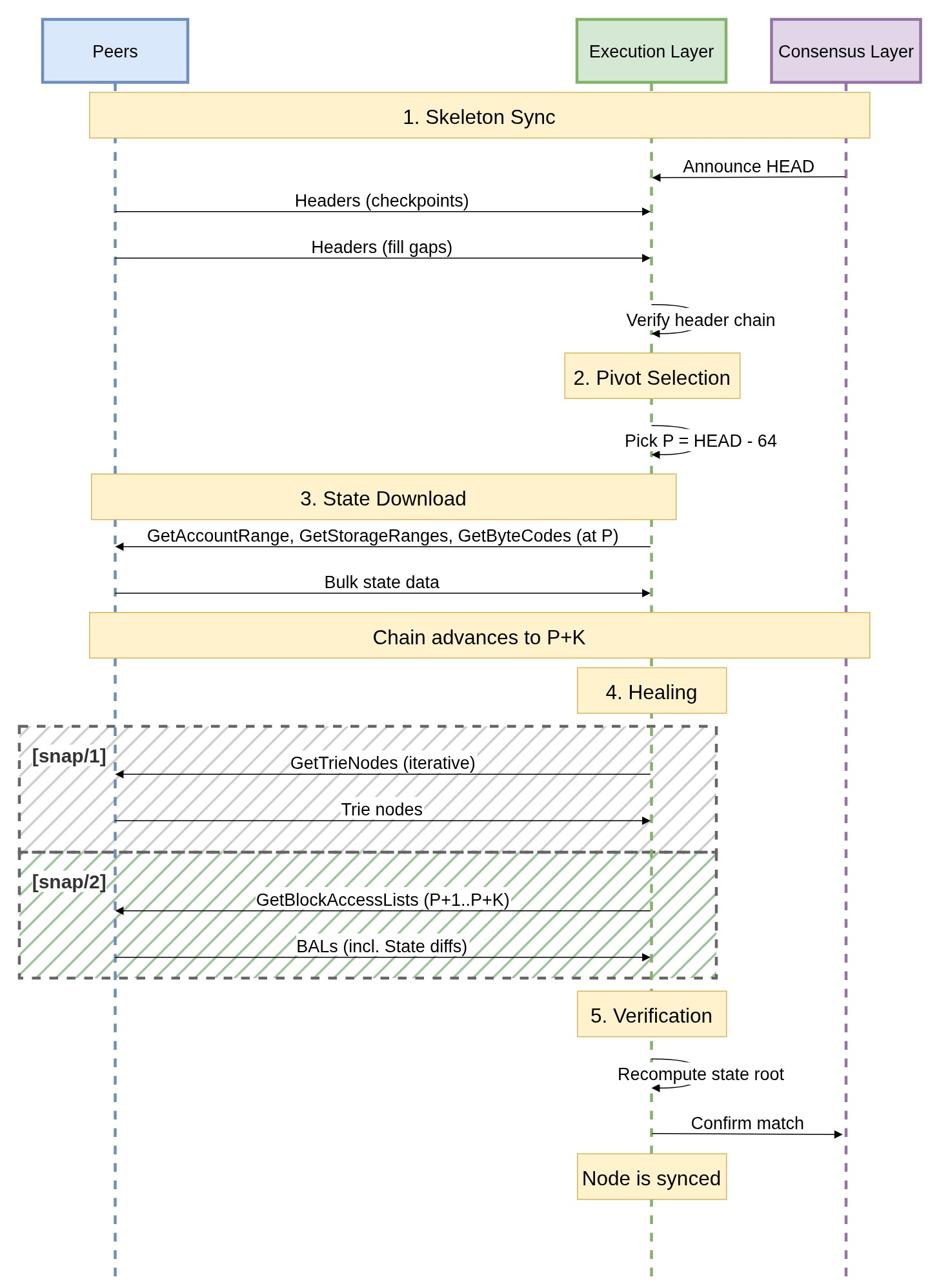
使用 eth 协议下载所有区块头,构建一个已验证的链。CL 驱动 EL,这意味着第一个 HEAD 从 CL 接收,然后 EL 从最新的区块头开始向后下载所有父区块头。
阶段 2 - 状态下载
节点选择一个枢轴区块 P(通常是 HEAD−64),并下载 P 处的完整状态:
GetAccountRange(0x00):下载连续哈希范围内的账户,每个响应在边界处经过默克尔证明以防止间隙攻击GetStorageRanges(0x02):下载合约的存储槽,多个小合约可以批量处理到一个请求中GetByteCodes(0x04):下载合约代码,通过代码哈希比较进行验证
每个响应都以字节大小为上限(而不是数量),以实现可预测的带宽,并且不同的对等节点可以并发地服务不同的范围。服务节点为最近的 128 个区块(在 每槽 12 秒 的情况下,约 25.6 分钟)保留快照。
枢轴区块是链尖端足够远的过去区块,以确保我们不会下载因稍后重组的区块而产生的状态。64 个区块深度的重组实际上是不可能的。即使发生这样的重组,已下载的状态也无需丢弃,可以通过迭代获取所需的 trie 节点来修复。
关键在于,当每个状态范围被接收时,节点在本地重建并持久化该段的中间 trie 节点,而不是通过网络获取它们。到阶段 2 结束时,大部分 trie 已正确构建,显著减少了修复工作负载,只需修复因下载窗口期间发生的状态更改而变得不一致的节点。
阶段 3 - 修复
当阶段 2 运行时,链从 P 推进到 P+K,使下载的状态过时。修复解决了这个问题,但这也是问题开始的地方。
trie 修复的工作方式
修复阶段使用 GetTrieNodes (0x06) / TrieNodes (0x07) 迭代地发现并获取已更改的 trie 节点:
 \
healing910×610 45.9 KB
\
healing910×610 45.9 KB为什么 trie 修复是瓶颈
- 迭代发现。 同步节点在查看之前不知道什么发生了变化。每一轮
GetTrieNodes都会揭示下一组差异,需要另一次往返。这根本上是顺序的。 - 小负载,多次往返。 单个 trie 节点为 100–500 字节。即使是批量处理,每次往返的数据量相对于网络延迟来说也非常小。
- 移动的目标。 在 12 秒槽的情况下,每个区块大约删除 1,000 个 trie 节点并添加 2,000 个。修复必须超越这个速度,否则永远不会收敛。
- 随机磁盘访问。 服务
GetTrieNodes需要随机数据库读取。与GetAccountRange使用的顺序读取相比,这成本高昂。 - 进度不可知。 正如 Geth 文档所指出:“无法监控状态修复的进度,因为在当前状态已经重新生成之前,错误的程度无法得知。”
实际影响可能很严重。例如,节点在修复过程中停滞了 2 周以上(4300 万个 trie 节点,下载了 11.7 GiB;吞吐量下降到约每秒 2 个 trie 节点),在修复期间停滞了 4 天或 6 天。
发布时的基准测试显示,在约 11.2M 区块时,修复增加了 约 541,260 个 trie 节点(约 160 MiB),但随着今天更大的状态和更高的区块 gas 限制,修复负担已经大大加重,并将随着 gas 限制的进一步增加而恶化。
第 2 部分:区块级访问列表 (BAL)
EIP-7928 引入了区块级访问列表 (BAL):记录区块执行期间访问的每个账户和存储位置以及执行后值的数据结构。每个区块头通过放置在区块头中的新 block_access_list_hash 字段提交其 BAL:
block_access_list_hash = keccak256(rlp.encode(block_access_list))一个 BAL 包含每个访问过的账户:
- 存储更改:每个槽的执行后值,按导致更改的交易索引
- 存储读取:已读取但未修改的槽
- 余额/nonce/代码更改:交易后值
BAL 是 RLP 编码的,确定性排序的(账户按地址字典序排列,更改按交易索引),并且是完整的。状态差异是 BAL 的一个子集,因此可以在同步期间提供帮助。
BAL 大小
对在 60M 区块 gas 限制下 1,000 个主网区块的经验分析表明,BAL 平均大小约为 72.4 KiB。
节点必须至少保留 BAL 弱主观性周期(高达 3,533 个纪元,按当前验证者集大小计算约 15.7 天)。
第 3 部分:snap/2:基于 BAL 的状态修复
snap/2 没有迭代地发现和获取 trie 节点,而是颠倒了 snap/1 的模式。在 snap/1 中,trie 在下载期间增量构建,扁平状态从中导出。在 snap/2 中,只同步扁平状态(叶子),BAL 差异直接应用于其上,并且trie 从完整状态重建一次,从而消除了增量 trie 构建及其所需的复杂修复。
具体而言,节点不是迭代地发现和获取 trie 节点,而是下载同步期间前进的每个区块的 BAL,并顺序应用状态差异。区块集是预先知道的。每个 BAL 都根据其区块头承诺进行验证。这消除了迭代发现的需要。
snap/2 移除了 trie 修复消息,并用 BAL 取代它们,重用相同的消息 ID:
| ID | snap/1 | snap/2 |
|---|---|---|
| 0x00–0x05 | 账户/存储/字节码下载 | 不变 |
| 0x06 | GetTrieNodes |
GetBlockAccessLists |
| 0x07 | TrieNodes |
BlockAccessLists |
请注意,重用消息 ID 是安全的,因为 snap/2 是在 RLPx 握手期间协商的新协议版本。snap/1 对等节点永远不会看到 snap/2 消息。
新消息
GetBlockAccessLists (0x06)
[请求 ID: P, [区块哈希₁: B_32, 区块哈希₂: B_32, ...]]BlockAccessLists (0x07)
[请求 ID: P, [区块访问列表₁, 区块访问列表₂, ...]]- 节点必须始终响应
- 对于不可用的 BAL,使用空条目(零长度字节)
- 响应保留请求顺序,并且可以从尾部截断
- 建议的软限制为每个响应 2 MiB,这与现有消息(例如区块、区块头或收据)一致。
新同步算法
 \
sync2910×380 28.2 KB
\
sync2910×380 28.2 KB值得注意的是,由于 BAL 通过共识(BAL 哈希与规范区块的哈希检查)保证是正确的,因此状态根也保证匹配;因此,客户端甚至可以跳过最终的状态根比较步骤。
为什么这有效
使用 snap/2,修复窗口是有限且已知的。对于 HEAD−64 处的枢轴:
- 64 个区块 × 约 72.4 KiB(预计 60M gas)≈ 4.5 MiB 总 BAL 数据
- 在 2 MiB 软限制下,适合2–3 个响应
- 服务 BAL 只需几次磁盘查找,而不是为每个已更改的 trie 节点查找
- 总共 1–3 次往返(包括应用期间到达的任何“尾部”区块)
- 从 BAL 中提取状态差异纯粹是本地计算。无需 trie 遍历。
与 snap/1 相比,snap/2 的修复更高效,需要的磁盘读取和往返次数更少。理论上,有了 snap/2,链条就不可能超越同步了。
与 eth/71 的关系
EIP-8159 将 BAL 交换作为消息 0x12/0x13 添加到 eth 协议中。两者存在的原因不同:
| eth/71 | snap/2 | |
|---|---|---|
| 目的 | 用于并行执行、重组处理的最新 BAL | 同步:修复期间批量 BAL 下载 |
| 数量 | 一次 1–3 个 BAL | 一次多个 BAL |
| 协议 | 所有节点必须使用 | 可选的卫星协议 |
eth/71 和 snap/2 中的消息重复是为了确保 snap 保持一个独立的卫星协议,并允许 snap 独立演进,例如,在未来版本中只提供状态差异而不是完整的 BAL,而无需更改 eth。
第 4 部分:比较
修复阶段:snap/1 vs snap/2
| 属性 | snap/1 (trie 修复) | snap/2 (BAL 修复) |
|---|---|---|
| 发现 | 迭代:节点在查看之前不知道什么发生了变化 | 确定性:P+1..P+K 区块是预先知道的 |
| 往返次数 | 数百次以上(问题报告数百万个 trie 节点) | 最终数量待定,但估计只有几次 |
| 验证 | 复杂的 trie 重建 + 根比较 | keccak256(rlp(bal)) == header.block_access_list_hash |
| 移动的目标 | 每次修复轮次 + 链条前进 → 更多修复 | BAL 应用是本地且快速的;尾部很小 |
| 收敛保证 | 弱:修复必须超越链条增长 | 强:确定性、有限的工作 |
比较 snap/1 与 snap/2 的完整流程如下:
 \
snapv2flowdiagram1455×1995 294 KB
\
snapv2flowdiagram1455×1995 294 KB
故障模式
| 故障 | snap/1 | snap/2 |
|---|---|---|
| 修复无法收敛 | 真实风险:trie 修复速度慢到链条可以超越它 | 几乎消除:只有 BAL 下载需要网络 |
| 不可用数据 | 无:snap/1 只要求修复超越链条 | 弱主观性周期(约 15.7 天)很宽裕 |
| 坏数据 | 默克尔证明捕获坏 trie 节点 | 哈希比较捕获坏 BAL |
| 重组越过枢轴 | 可恢复:trie 修复根据新的规范链解决状态 | 如果保留了孤立的 BAL 则可恢复;否则需要同步重启 |
具体示例
考虑在区块 22,000,000 处的枢轴,当状态下载完成时,链条已领先 200 个区块:
snap/1: 从区块 22,000,200 的状态根开始 trie 遍历。每一轮发现更多差异,深入更深。同时,修复期间有多个新区块到达。在最佳情况下,这需要几分钟;在病态情况(慢磁盘、慢网络)下,它需要几天。
snap/2: 请求多个区块的 BAL。在 60M 区块 gas 限制下,这约为 4–5 MiB,适合几个响应。在本地应用 BAL,可选地验证状态根是否匹配。应用期间又到达了几个区块?获取 2–3 个更多 BAL。总计:2–3 次往返,几秒钟完成。
- 原文链接: ethresear.ch/t/snap-v2-r...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





