二叉树与MPT性能深度对比
- 以太坊中文
- 发布于 18小时前
- 阅读 29
本文深入对比了以太坊新型状态树结构二叉树(Binary Trie, GD-5)与现有生产环境 MPT 的性能表现。研究发现二叉树在读取操作上比 MPT 慢约 1.7 倍,写入操作慢 2.5 倍,主要原因在于其更深的路径深度导致的 I/O 开销。文章分析了架构差异并提出了未来通过快照层等手段优化性能的方向。
二进制 Trie(Binary Trie)在每个存储操作上的速度比生产环境中的 MPT 慢约 2 倍——读取慢 1.7 倍,写入慢 2.5 倍。原始的 Mgas/s 数据看起来更糟(高达 9.6 倍),这是因为二进制 Trie 分支使用了 EIP-4762 的 Verkle Gas 规则,使得相同的工作消耗更少的 Gas。在一周内完成 4 个优化 PR 后,差距虽然真实存在,但已处于可控范围内。
执行摘要
二进制 Trie 已被列入 Ethereum 协议草案,作为未来的状态树替代方案(EIP-7864)。第一部分(第一部分)确定了 GD-5 和 GD-6 是二进制 Trie 的最佳组深度(Group-depth)设置。在确定了这些参数后,接下来的问题是:优化后的二进制 Trie 与生产环境中的 MPT 相比表现如何?
测试内容
我们在相同的裸机硬件上对比了 BT-GD5(bintrie 分支,commit 991300c4)与 MPT(geth 主分支,commit 5d0e18f7)。测试涵盖了三种 ERC20 工作负载:erc20_balanceof(读取)、erc20_approve(写入)、mixed_sload_sstore(读写各占 50%)。测试采用冷缓存协议,每次运行间都会清除 OS 页面缓存并设置 --cache 0。MPT 每项基准测试运行 100 次,BT-GD5 运行 10 次。
测试结果
- 读取吞吐量存在 1.7 倍差距:在相同的 100M Gas 区块下,MPT 达到 19.0 Mgas/s,而 BT 为 11.2 Mgas/s。由于读取的 Gas 规则相同,Mgas/s 的对比是公平的。单次缓存未命中的成本差距为 2.8 倍(0.15 毫秒 vs 0.41 毫秒)。
- 每个存储槽的写入差距为 2.5 倍:总耗时分别为 0.23 毫秒/槽和 0.57 毫秒/槽。原始 Mgas/s 比例(9.6 倍)具有误导性,因为 BT 使用 EIP-4762 见证数据 Gas 规则,其中 SSTORE 的成本约为 5,600 Gas,而 MPT 在 EIP-2929 下约为 22,100 Gas。
- 随着交易数量增加,单次缓存未命中的读取成本上升 7.5 倍:在 BT 的 approve 区块中,成本从 $tx=1$ 时的 0.40 毫秒/次上升到 $tx=9$ 时的 2.99 毫秒/次。预取器会先消耗掉热门的上层路径节点,留下逐渐变冷的 Trie 路径。
阅读指南
第 2 节涵盖了自 第一部分 以来的变化。第 3 节详述了测试方法。第 4-5 节展示了结果:先是读取(清晰的对比),然后是写入(需要标准化的 Gas 调度差异)。第 6 节探讨了深层架构模式——冷尾效应、哈希时间为何本质上是 Trie 遍历时间,以及导致差距的根本原因。第 7 节展望了优化路径,第 8 节给出了最终结论。
立场: 二进制 Trie 目前尚未准备好投入生产,但差距正在缩小。
自第一部分以来的变化
硬件升级
第一部分 运行在 QEMU 虚拟机上。第二部分 运行在裸机上——AMD EPYC 9454P 48 核(96 线程),配备 126 GB RAM 和 3.5 TB SSD RAID。这消除了虚拟化开销,并提供了更真实的 I/O 特性。由于硬件变化,第一部分 和 第二部分 的绝对数值不可直接对比。
MPT 基准
第一部分 仅对比了不同的二进制 Trie 配置。第二部分 增加了首次跨架构对比:BT-GD5 vs 生产环境 MPT。这是以太坊路线图中最重要的核心问题。
优化 PR 汇总
在一周的集中攻坚中,合并了 4 个针对二进制 Trie 性能的 PR:
| PR | 描述 | 目标 | 合并日期 | 是否包含在测试中? |
|---|---|---|---|---|
| #34032 | 在浅层深度并行化 InternalNode.Hash | state_hash_ms |
2026-03-18 | 是 |
| #34025 | 避免 flatReader 中的 Bytes() 分配 | state_read_ms, GC |
2026-03-17 | 是 |
| #34021 | 跳过 Verkle 的冗余 Trie 提交 | commit_ms |
2026-03-17 | 是 |
| #34022 | 绕过二进制 Trie 的逐账户 updateTrie | 提交开销 | 2026-03-20 | 是(本地分支) |
数据库规模
| 数据库 | 大小 | 膨胀数据 | 状态条目 |
|---|---|---|---|
| MPT | 1.6 TB | ~2.53 GB ERC20 | ~4 亿 |
| BT-GD5 | 1.4 TB | ~2.76 GB ERC20 | ~4 亿 |
两者的大小差异反映了二进制 Trie 在 GD-5 下更紧凑的编码方式。
测试方法
基准测试设置
| 参数 | 数值 |
|---|---|
| 机器 | 裸机 – AMD EPYC 9454P 48 核, 126 GB RAM, 3.5 TB SSD (RAID) |
| 数据库 | MPT: 1.6 TB, BT-GD5: 1.4 TB (~4 亿账户 + 存储) |
| 配置 | mpt (geth 5d0e18f7) vs bt-gd5 (bintrie 分支 991300c4) |
| 协议 | 冷缓存 (清除 OS 页面缓存 + --cache 0) |
| 运行次数 | MPT: 100 次, BT-GD5: 10 次 |
| Gas 目标 | 每个区块 100M Gas |
| 基准测试 | erc20_balanceof (读), erc20_approve (写), mixed_sload_sstore (混合) |
冷缓存协议
每次运行流程:停止 geth,执行 sync && echo 3 > /proc/sys/vm/drop_caches,以 --cache 0 重启 geth,等待 RPC 就绪,执行基准测试并保存日志。这确保了每次运行都从冷状态开始——没有 Trie 缓存,没有 Pebble 块缓存,也没有 OS 页面缓存。
统计方法
- 使用 Mann-Whitney U 检验进行所有成对比较。
- 使用 Bootstrap 95% 置信区间计算中位数比例。
- 所有吞吐量(
mgas_per_sec)的成对 p 值均 $p < 0.001$。 - 运行稳定性:MPT 的变异系数(CV%)为 2–5%,BT 为 6–21%。
已知问题
不同的 Gas 调度:bintrie 分支触发了 EIP-4762 基于见证数据的 Gas 成本。SSTORE 在 EIP-4762 下成本约为 5,600 Gas,而在 EIP-2929 下约为 22,100 Gas。对于读取(balanceof),Gas 是相同的。对于写入(approve),MPT 每槽消耗 22,897 Gas,而 BT 仅消耗 5,955 Gas(相差 3.85 倍)。这意味着 Mgas/s 不是写入基准测试的有效跨架构指标,每槽耗时(Per-slot time)才是核心对比指标。
第一幕:读取性能
erc20_balanceof 基准测试对约 36,741 个随机地址调用 balanceOf()。这是一个纯读取负载:单位 Gas 的存储查找最大化,写入或合约逻辑开销最小化。
这是研究中最清晰的对比:两者的 Gas 调度相同,处理相同的 100M Gas 区块,进行相同数量的槽查找。
MPT: 19.0 Mgas/s, BT: 11.2 Mgas/s – 1.7 倍差距
组件拆解:
| 组件 | MPT | BT | 比例 |
|---|---|---|---|
state_read_ms |
4,956 ms | 7,935 ms | 1.6x |
execution_ms |
~280 ms | ~941 ms | – |
state_hash_ms |
0.07 ms | 0.18 ms | – |
commit_ms |
27.8 ms | 24.5 ms | 0.9x |
total_ms |
5,264 ms | 8,901 ms | 1.7x |
状态读取占据了绝大部分时间。1.6 倍的 state_read_ms 差距是核心代价:二进制 Trie 路径更深(GD-5 下约 52 个组节点,而 MPT 约 5-6 个十六进制分支节点),每个组节点在冷读取时都需要通过 Pebble 的 LSM 树进行单独的数据库查找。
- 每槽读取成本:0.135 vs 0.216 毫秒/槽 = 1.6 倍。
- 单次缓存未命中成本:0.146 vs 0.405 毫秒/次 = 2.8 倍。这代表了从磁盘遍历二进制 Trie 路径(~52 个节点)与 MPT 路径(~5-6 个节点)的原始成本。
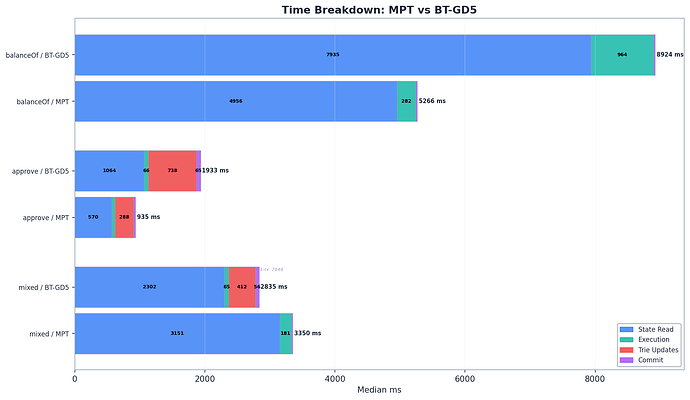
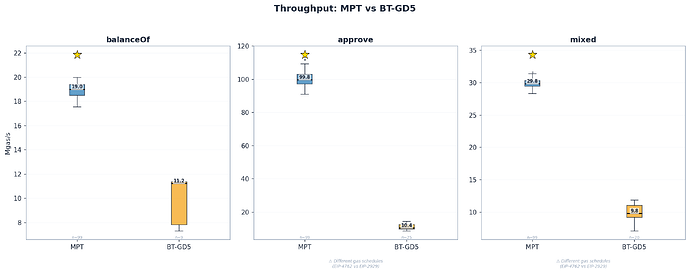
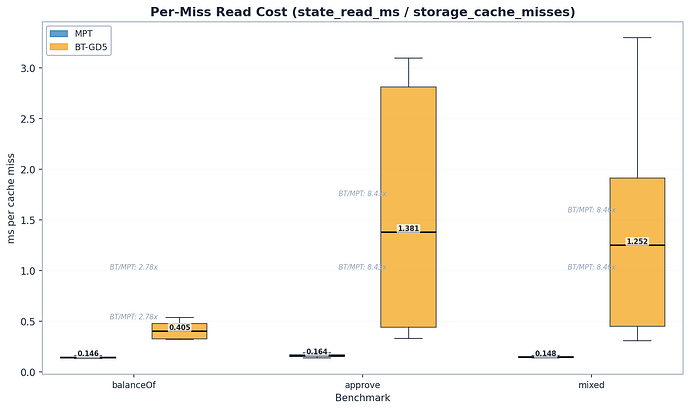
对于读取,差距是真实存在的,且根据指标不同被限制在 1.7-2.8 倍之间。二进制 Trie 更深的路径使得每次遍历更昂贵,但并没有达到 10 倍深度差异所暗示的那种程度。
第二幕:写入性能
erc20_approve 基准测试对约 4,094 个随机地址调用 approve()。每次调用都会触发一次冷 SLOAD(读取当前额度)和一次冷 SSTORE(写入新额度)。
如前所述,由于 Gas 调度差异,每槽耗时是主要的对比标准:
| 基准测试 | MPT 毫秒/槽 | BT 毫秒/槽 | 比例 | 95% 置信区间 |
|---|---|---|---|---|
| approve (总计) | 0.229 | 0.569 | 2.5x | $[2.24, 2.64]$ |
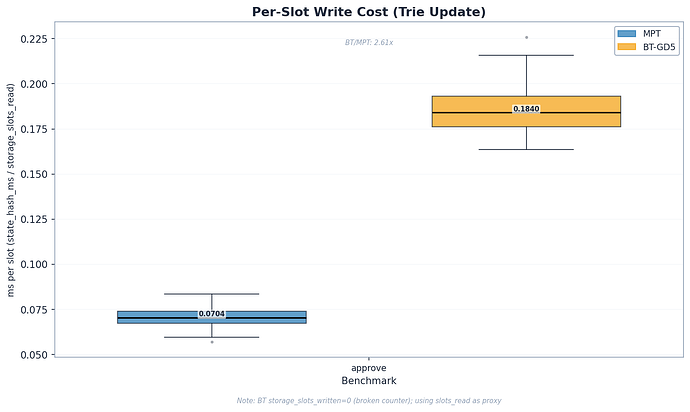
| approve (哈希) | 0.070 | 0.184 | 2.6x | $[2.51, 2.73]$ |
| approve (读取) | 0.139 | 0.260 | 1.9x | – |
2.5 倍的总耗时比例是写入性能最公平的对比。2.6 倍的哈希成本反映了 BT-GD5 内部子树的重新哈希——每个节点需要 $2^5 - 1 = 31$ 次哈希操作。
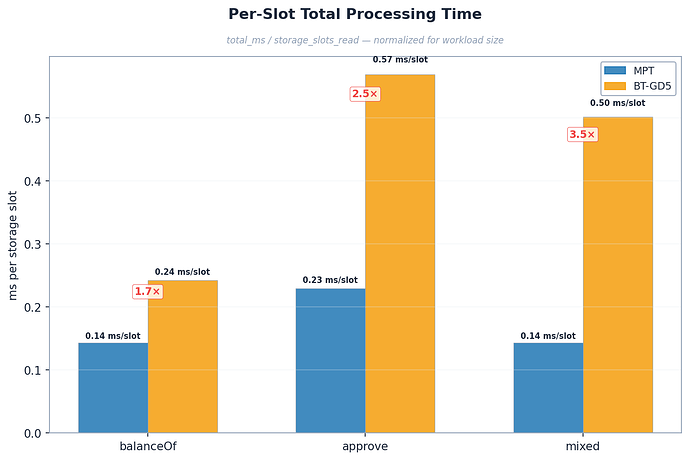
深度模式分析
6a. 冷尾效应 (Cold Tail Effect)
这是研究中最有趣的发现:随着区块中交易数量($tx_count$)的增加,BT 的单次缓存未命中成本上升了 7.5 倍。
在多交易区块中,预取器会先缓存易于访问的槽位。随着交易增加,剩余的缓存未命中对应的是逐渐变冷、更深的 Trie 路径。预取器先排干了热门的上层共享节点,后期的未命中在更浅的深度就开始分叉,需要每一层都进行新的磁盘寻道。
6b. 架构开销
性能差距源于两种 Trie 设计的根本结构差异:
- MPT 每次查找仅需 5-6 个节点:MPT 使用独立的账户存储 Trie。查找账户遍历约 5 个节点,然后进入一个单独的、较小的存储 Trie。
- BT 每次查找需要约 52 个节点:二进制 Trie 将所有账户和存储统一到一个 256 位的键空间中。在 GD-5 下,从根到叶的完整遍历需要跨越约 52 个磁盘节点。
- 哈希成本为何是 2.6 倍:每个 GD-5 组节点包含一个 5 层内部子树。修改一个键会触发约 260 次 SHA-256 哈希。而 MPT 仅需约 10-15 次更新。实测的 2.6 倍差距远小于哈希次数比例,因为 95-98% 的“哈希时间”实际上是节点遍历、脏节点收集和 I/O,而非加密运算本身。
6c. 哈希时间本质上是 Trie 遍历
state_hash_ms 指标名称具有误导性。它衡量的是完整的状态根重新计算:遍历 Trie 定位脏节点、从磁盘读取计算所需的兄弟节点以及计算哈希。它由 I/O 和遍历主导。
- MPT:4,094 个槽位的哈希耗时 288 毫秒。纯 Keccak-256 计算仅需约 4.8 毫秒。这意味着 Trie 操作带来了 60 倍的开销。
- BT:耗时 727 毫秒。纯 SHA-256 计算仅需约 38 毫秒。这意味着 19 倍的开销。
缩小差距
剩余的优化途径
- 快照层 / pathdb 快速读取:Geth 目前的
pathdb方案旨在使扁平状态读取接近快照级的速度。如果这适用于二进制 Trie,1.7 倍的读取差距可能会显著缩小。 - Pebble 块大小调整:GD-5 节点序列化后约为 1 KB。NVMe 页面读取基准显示,16 KB 随机读取的吞吐量是 4 KB 的 2.3 倍。更大的 Pebble 块可能有助于对齐访问模式。
- 并行执行:并行 EVM 执行可以增加有效的 I/O 队列深度,从而压缩架构间的读取延迟差异。
结论:二进制 Trie 准备好了吗?
二进制 Trie 目前尚未准备好投入生产。 约 2 倍的读取差距是核心担忧,因为以太坊是读取密集型的。然而,优化轨迹令人鼓舞,且最大的潜在改进(快照层)尚未被探索。
12 秒 Slot 预算
BT 距离适应以太坊 12 秒的 Slot 窗口有多近?
| 基准测试 | BT 处理 100M Gas 耗时 | 占 12s Slot 的百分比 |
|---|---|---|
| balanceof | ~8.9 s | 74% |
| approve | ~7.6 s | 64% |
| mixed | ~10.9 s | 91% |
BT 在混合负载下占据了 91% 的时间,几乎没有留给网络传输、证明和其他非执行开销的空间。在典型的验证者硬件上,如果没有进一步优化,这可能是不可行的。
持续存在的模式
- 读取差距是真实且受限的(1.7–2.8x):二进制 Trie 的路径深度虽然是 MPT 的 10 倍,但性能代价远低于此比例。
- BT 受限于读取:状态读取消耗了 BT 约 89% 的区块处理时间。读取路径是主要的优化目标。
- 哈希成本由 Trie 遍历主导:改变哈希函数(如 SHA-256 换成其他)不会有实质性帮助,优化 Trie 遍历和节点更新路径才是关键。
开放性问题
- 快照层基准测试:扁平快照层能否消除读取差距?这是决定生产可行性的最重要实验。
- 主网读写比分析:现实世界中 1.7 倍读取差距与 2.5 倍写入差距的综合影响取决于此比例。
- 数据库引擎选择:Pebble 是统一二进制 Trie 的正确选择吗?针对前缀顺序读取优化的引擎可能会减少读取差距。
基准测试运行在以太坊 execution-specs 框架上,使用 geth 二进制 Trie 分支 (EIP-7864)。方法论、原始数据和复现脚本可在 [bintrie-benchmarks 仓库](https://github.com/CPerezz/bintrie-benchmarks/tree/main/mpt-vs-bintrie) 中找到。
- 原文链接: ethresear.ch/t/the-path-...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





