大模型全栈工程指南
- kmeanskaran
- 发布于 5小时前
- 阅读 22
该指南从工程视角全面梳理了大语言模型(LLM)的全栈技术,涵盖模型架构核心(如注意力机制、RoPE、SwiGLU)、训练与对齐策略(LoRA、DPO)、以及生产级推理优化方案(vLLM、KV缓存、PagedAttention)。文章强调在构建系统时如何平衡精度、延迟与成本,旨在指导工程师从底层原理走向实际的系统落地与性能调优。

如果你作为一名工程师正在学习大语言模型(LLM),你的目标不仅仅是理解它们,还要构建、优化并发布它们。这需要你在三个层面上保持清晰的认识:模型内部如何工作、如何训练和微调,以及如何在生产环境中高效运行。
本指南将贯穿全栈,重点关注在构建系统时真正重要的事情。
1. 核心思维模型
在最简单的层面上,LLM 只做一件事:它根据之前的 Token 预测下一个 Token。
其他一切都是为了使这种预测更准确、更高效且更有用。
流水线:
文本 → Tokens → Embeddings → Transformer → 概率 → Tokens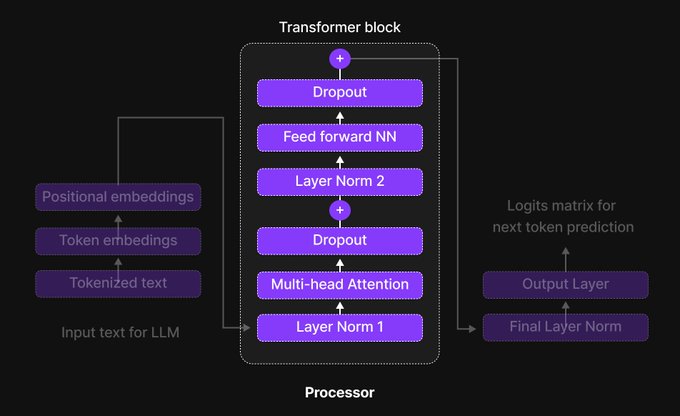
2. 分词(Tokenization)与嵌入(Embeddings)
在进入模型之前,文本会被转换为 Token。这些是代表子词或字符的整数 ID。然后,Token 被映射为嵌入(Embeddings),即稠密向量。这些向量捕获语义,是模型的实际输入。
从工程角度来看:
- Token 数量直接影响成本和延迟。
- 更好的分词(Tokenization)能提高代码和推理任务的性能。
3. 位置编码(RoPE)
Transformer 默认不理解顺序。如果你打乱单词,如果没有位置信息,模型会一视同仁。RoPE(旋转位置编码)通过在向量空间中使用旋转来编码相对位置,从而解决了这个问题。RoPE 不是将位置作为单独的信号添加,而是根据位置旋转嵌入向量。
为什么这很重要?
- 捕捉 Token 之间的相对距离。
- 能更好地泛化到长上下文。
- 被 LLaMA 等现代模型使用。
工程洞察:RoPE 帮助模型理解 Token 之间的距离,而不仅仅是它们的绝对位置。
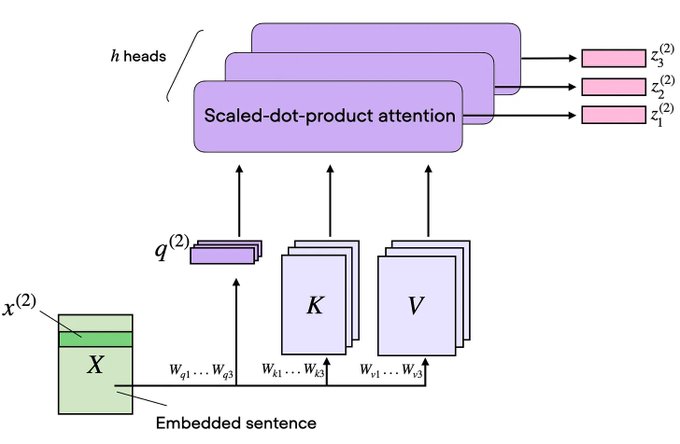
4. 自注意力(Self Attention):核心机制
自注意力是 Transformer 的心脏。每个 Token 都会观察所有其他 Token,并决定哪些 Token 重要。从数学上讲,注意力计算 Token 之间的相似性,并利用它来整合信息。
直觉理解:
- Query(查询) 提出问题。
- Key(键) 代表每个 Token 包含的内容。
- Value(值) 是实际的信息。
模型计算每个 Token 应该关注其他 Token 的程度,并汇总相关信息。
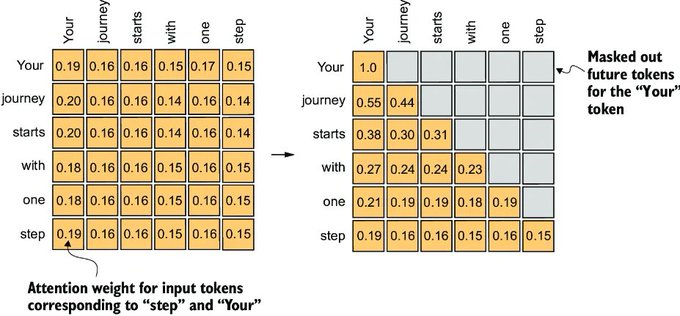
5. 因果注意力(Causal Attention):实现生成
在生成任务中,模型绝不能“预见未来”。因果注意力确保每个 Token 只能关注之前的 Token。这使得模型具有自回归特性,意味着它一次生成一个 Token 的文本。如果没有因果掩码(Causal Masking),模型会通过向后看而作弊。
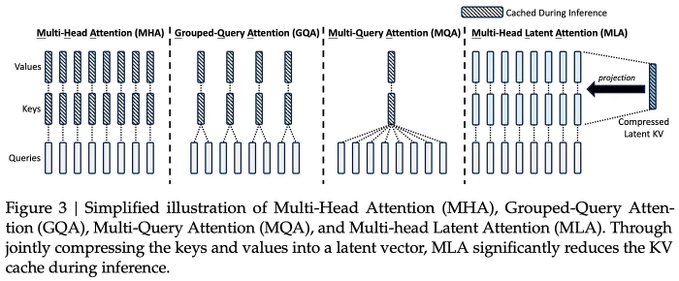
6. 多头注意力及其变体
Transformer 使用多个头,而不是单一的注意力机制。
多头注意力(MHA)
每个头学习不同的关系,例如语法、语义或长程依赖。这提高了表示能力。
多查询注意力(MQA)
所有头共享 Key 和 Value。
- 优点: 减少内存占用并实现更快的推理。
分组查询注意力(GQA)
头被分组,每组共享 Key 和 Value。这平衡了性能和效率。
工程视角:MHA 强大但沉重;MQA 和 GQA 为生产环境进行了优化。
7. Transformer 块结构
Transformer 是通过堆叠块构建的。每个块包含:
- 注意力层
- 前馈网络(FFN)
- 残差连接
- 层归一化(Layer Normalization)
流程:
输入 → 注意力 → 相加 → 归一化 → FFN → 相加 → 归一化残差连接
它们将输入加回到层的输出中,这稳定了训练并允许构建更深的网络。
层归一化
归一化激活值以保持训练稳定。
8. 前馈网络与 SwiGLU
在注意力层之后,每个 Token 都会通过一个前馈网络,计算在每个 Token 上独立进行。现代模型使用 SwiGLU 激活函数代替 ReLU。
为什么 SwiGLU 很重要?
- 更好的梯度流。
- 提升性能。
- 更具表现力的变换。
工程观点:注意力负责收集信息;FFN 负责处理信息。
9. 训练:从数据到智能
训练始于预训练。
- 目标: 预测下一个 Token。
- 过程: 使用交叉熵损失在大规模数据集上完成。
- 结果: 模型学习语言结构、事实、模式和基本推理。
训练挑战:
- 分布式系统和 GPU 利用率。
- 数据质量和内存限制。
更好的数据往往比更大的模型更重要。
10. 微调与对齐
预训练后,模型需要针对特定任务进行塑形。
有监督微调(SFT)
在指令-响应对上进行训练,以教授格式、风格和行为。
指令微调
让模型接触多样化的任务以提高泛化能力。
对齐方法
- RLHF: 使用人类反馈和强化学习。
- DPO(直接偏好优化): 直接从偏好与拒绝的响应中学习。
- GRPO: 通过比较一个组内的多个输出来学习。
核心思想:对齐塑造的是行为,而不是知识。
11. 参数高效微调(PEFT)
全量微调非常昂贵。LoRA(低秩自适应)在冻结基础模型的同时添加了小的可训练矩阵。
LoRA 的优点:
- 低内存占用。
- 训练速度快。
QLoRA 将 LoRA 与量化相结合,使得在消费级硬件上训练大型模型成为可能。
12. 量化:使模型可部署
量化降低模型权重的精度以节省内存。
- 格式: FP16, INT8, INT4。
- 优点: 更低的内存占用和更快的推理。
- 权衡: 轻微的精度损失。
- 常用方法: GPTQ, AWQ, QLoRA。
量化对于生产系统至关重要。
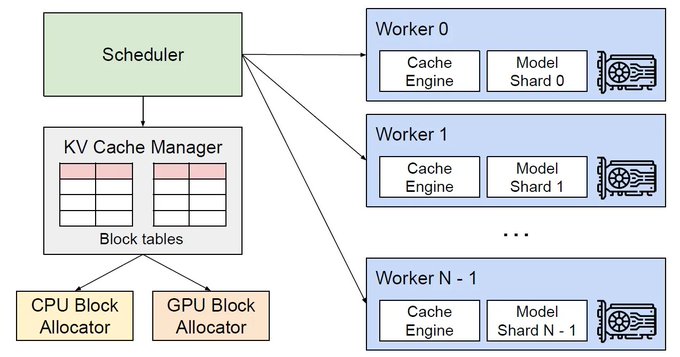
13. 推理:真实的系统
推理是模型实际运行的地方。像 vLLM 这样的现代框架专注于优化这个阶段。
循环:
输入 → 预测 Token → 追加 → 重复关键优化:
- KV 缓存: 存储中间值以避免重复计算。减少计算但增加内存使用。
- FlashAttention: 通过减少内存移动来优化注意力计算。
- PagedAttention: 使用固定大小的内存块管理 KV 缓存以防止碎片化。
- 连续批处理(Continuous Batching): 动态处理请求以最大化 GPU 利用率。
- 投机解码(Speculative Decoding): 使用较小的模型来加速生成。
14. 解码策略
模型输出概率;解码将概率转换为 Token。
- 选项: 贪婪搜索(Greedy)、采样(Sampling)、Top-k、Top-p、温度(Temperature)。
- 这些参数控制输出的创造性和确定性。
15. 推理模型
推理模型在提供最终答案之前生成中间步骤。
- 技术: 思维链(CoT)、自一致性、工具使用。
- 权衡: 以更高的延迟和成本换取更好的准确性。
16. 训练工具与实用栈
要作为工程师工作,你需要一套强大的工具集:
- Hugging Face: 用于模型加载、训练流水线和数据集。
- Unsloth: 用于更快的 LoRA 和 QLoRA 训练,且内存占用更低。
- vLLM: 用于高性能推理,具有 PagedAttention 和连续批处理功能。
典型工作流:
1. 加载基础模型。
2. 应用 LoRA。
3. 使用 Unsloth 训练。
4. 评估。
5. 导出用于推理。
6. 使用 vLLM 提供服务。17. 真正的工程洞察
要构建 LLM 系统,你必须理解其中的权衡:
- 准确性 vs 延迟
- 内存 vs 速度
- 成本 vs 质量
大多数现实世界的工作涉及平衡这些因素。
18. 最终思维模型总结
一个 LLM 系统由几个层级组成:
- 模型层: 注意力机制、Transformer 块。
- 训练层: 预训练、微调、对齐。
- 系统层: KV 缓存、FlashAttention、PagedAttention、批处理。
- 优化层: LoRA、量化。
结论
作为工程师学习 LLM 意味着超越理论。你需要理解注意力机制如何工作、模型如何训练、行为如何对齐,以及系统如何针对现实世界进行优化。
- 原文链接: x.com/kmeanskaran/status...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





