为什么 AI 安全需要渗透测试、红队演练与审计的结合
- zealynx
- 发布于 1天前
- 阅读 11
文章深入探讨了生成式AI时代安全防护的演进,分析了AI渗透测试、红队演练与安全审计三大支柱的异同与整合。内容涵盖了OWASP LLM十大风险、对抗性机器学习(AML)攻击向量以及欧盟AI法案等全球监管框架。作者强调企业需通过TEVV生命周期建立动态防御体系,从技术、行为和治理三个维度保障AI系统的安全性与合规性。
几十年来,安全团队围绕三大支柱构建其保障计划:使用渗透测试发现可被利用的漏洞,使用红队演练在真实条件下对防御进行压力测试,以及通过审计来证明合规性。当保护的是每次行为都一致的确定性软件时,这种模型运行良好。
生成式 AI 完全打破了这一契约。LLM 的失败并不是因为一个放错位置的分号;它们失败是因为训练数据分布、权重属性或语义歧义。一个 AI 系统可以通过所有 OWASP 检查,却仍然泄露机密文档或批准欺诈交易。
这篇文章梳理了当前的格局:每种学科在 AI 语境下覆盖什么、各自单独使用时会在哪些方面失效,以及组织如何将它们整合进一个连贯的生命周期中。

为什么传统方法在 AI 上失效
传统网络安全漏洞来源于人类编写代码中的逻辑缺陷——错误配置的网络或过时的库。修复方式是确定性的:修补代码或关闭端口。
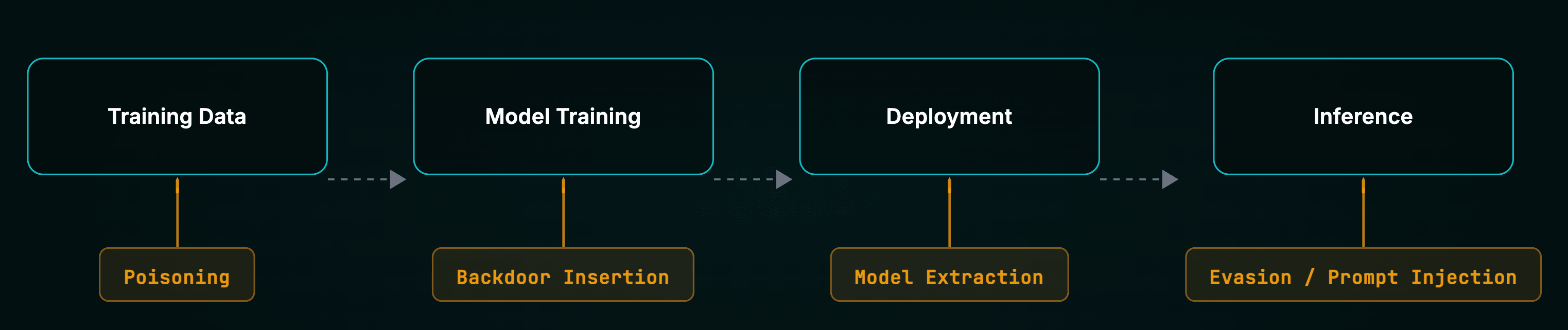
AI 漏洞则来源于认知层——训练数据的统计分布以及模型权重的操控。这属于对抗性机器学习(AML)的领域,它利用了训练数据与推理数据共享相同统计分布这一假设。
核心 AI 攻击类别
- 逃避攻击: 几乎不可察觉的输入扰动,迫使模型发生错误分类。
- 投毒攻击: 在训练流水线中植入休眠后门。
- Prompt 注入: 直接或间接的恶意指令,用于劫持 AI 的上下文。
- Jailbreaking: 使用角色扮演或编码变体系统性地绕过安全约束。
- 模型提取: 收集输出以重建专有模型参数。
- 成员推断: 判断特定敏感记录是否属于训练集的一部分。
AI 渗透测试:建立安全基线
AI 渗透测试调整了传统结构,以便在已定义范围内发现可被技术利用的缺陷。主要框架是面向大型语言模型应用的 OWASP Top 10。
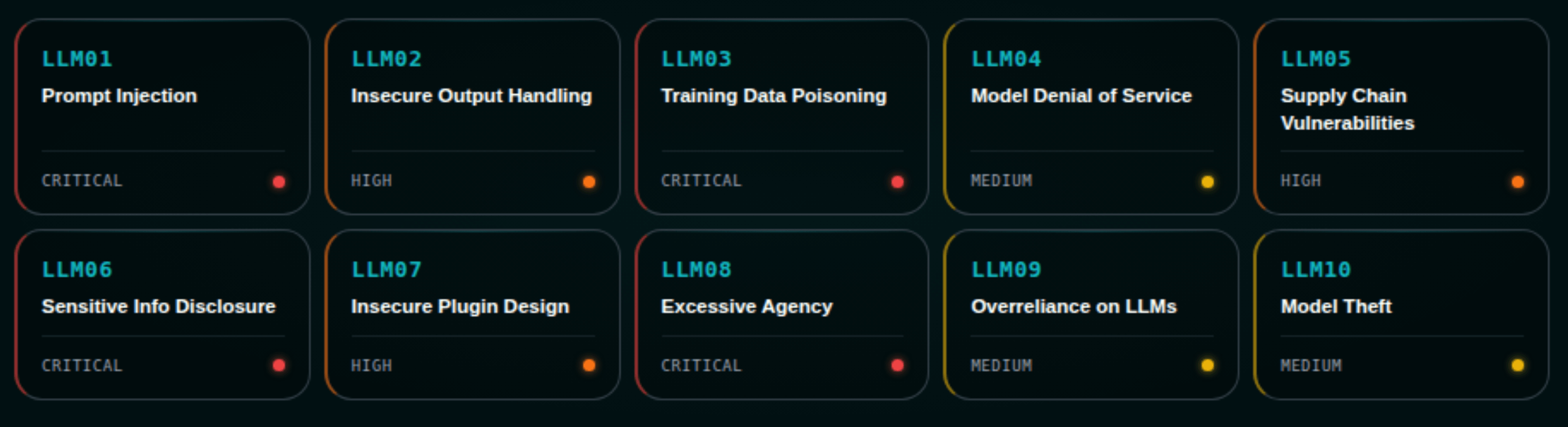
OWASP LLM 关键关注领域
- LLM01 — Prompt 注入: 使用对抗性输入获取未授权访问或劫持逻辑。
- LLM02 — 不安全的输出处理: 未对 LLM 输出进行清洗,导致 XSS 或远程代码执行。
- LLM03 — 训练数据投毒: 被操纵的数据集引入偏见或后门。
- LLM04 — 模型拒绝服务: 构造复杂请求以造成服务退化和高额基础设施成本。
- LLM05 — 供应链漏洞: 被攻陷的第三方 ML 库或预训练模型。
- LLM06 — 敏感信息泄露: 迫使模型外泄 PII 或知识产权。
- LLM07 — 不安全的插件设计: 扩展上的弱访问控制,这对 MCP server 安全至关重要。
- LLM08 — 过度自主性: 在没有 human-in-the-loop 控制的情况下,给予Agentic AI过多自主权。
- LLM09 — 过度依赖: 在未缓解幻觉风险的情况下盲目信任 LLM 输出。
- LLM10 — 模型窃取: 允许对手复制专有模型权重的 API 漏洞。
它产出什么: 一份包含严重性评分和修复指导的结构化报告。
它的不足之处: 它是战术性的且有边界。它不会评估隐蔽性、行为漂移或复杂的人类流程失效。
AI 红队演练:发现系统性失效
AI 红队演练采用对抗性视角来发现扫描器遗漏的真实世界失效。这包括人员层面的系统性失效、行为模型失效(攻击性内容),以及约束的逐步侵蚀。
红队演练中的行业实践
- Microsoft: 使用跨学科团队攻击多模态模型(视觉和音频),结合质量压力测试与对抗性思维方式。
- Google: 以真实世界威胁情报为基础开展演练,模拟国家级行为者针对 AI Agent 的实际 TTP。
- OpenAI: 结合外部专家与基于 AI 的自动化红队演练,以大规模生成对抗性 Prompt。
红队演练的独特价值
它评估流程有效性。由于演练是隐蔽进行的,它们会测试异常输入是否会触发检测,以及事件响应能够多快隔离威胁。
AI 安全审计:治理与合规
红队演练展示的是系统如何失效,而审计则建立法律责任。AI 安全审计验证风险管理是否被正确实施。
NIST AI RMF 和 AI 600-1
NIST 框架要求组织记录 AI 韧性。NIST AI 600-1 将风险映射到整个生命周期,从设计中的威胁建模到部署中的内容溯源。
ISO/IEC 42001
首个 AI 管理体系(AIMS)标准。它审查企业政策、差距分析,并要求提供进攻性技术评估(渗透测试和红队报告)的证据,作为合规工件。
欧盟 AI 法案
这是惩罚力度最大的框架,处罚最高可达 3500 万欧元或全球营收的 7%。对于高风险系统,强制性的合格评定涵盖风险管理、数据治理以及对抗性入侵下的韧性。
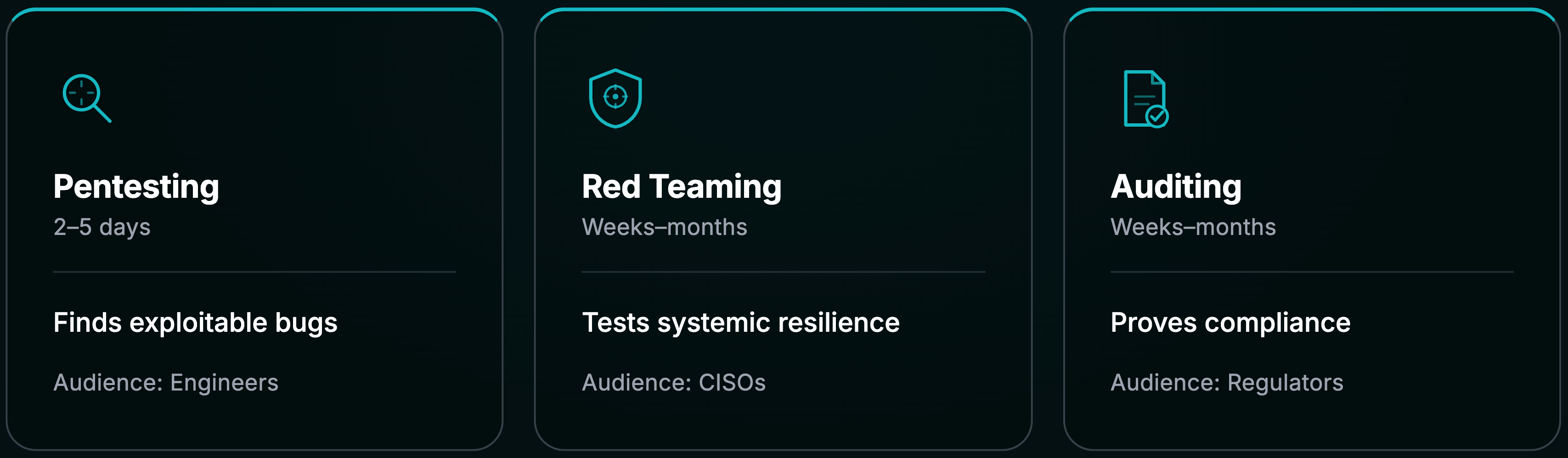
交付物对比:选择合适的工具
| 特征 | AI 渗透测试 | AI 红队演练 | AI 安全审计 |
|---|---|---|---|
| 主要受众 | 安全工程师、DevOps | CISO、高管层 | 监管机构、法务、合规团队 |
| 方法 | 预定义范围、方法驱动 | 广泛范围、真实模拟 | 流程审查、政策合规 |
| 发现内容 | 具体可利用缺陷(OWASP) | 系统性脆弱性、人为失误 | 治理与政策缺陷 |
| 交付物 | 漏洞看板、PoC | 高管叙述、攻击链 | 合规认证、法律证据 |
| 持续时间 | 数天 | 数周到数月 | 数周到数月 |
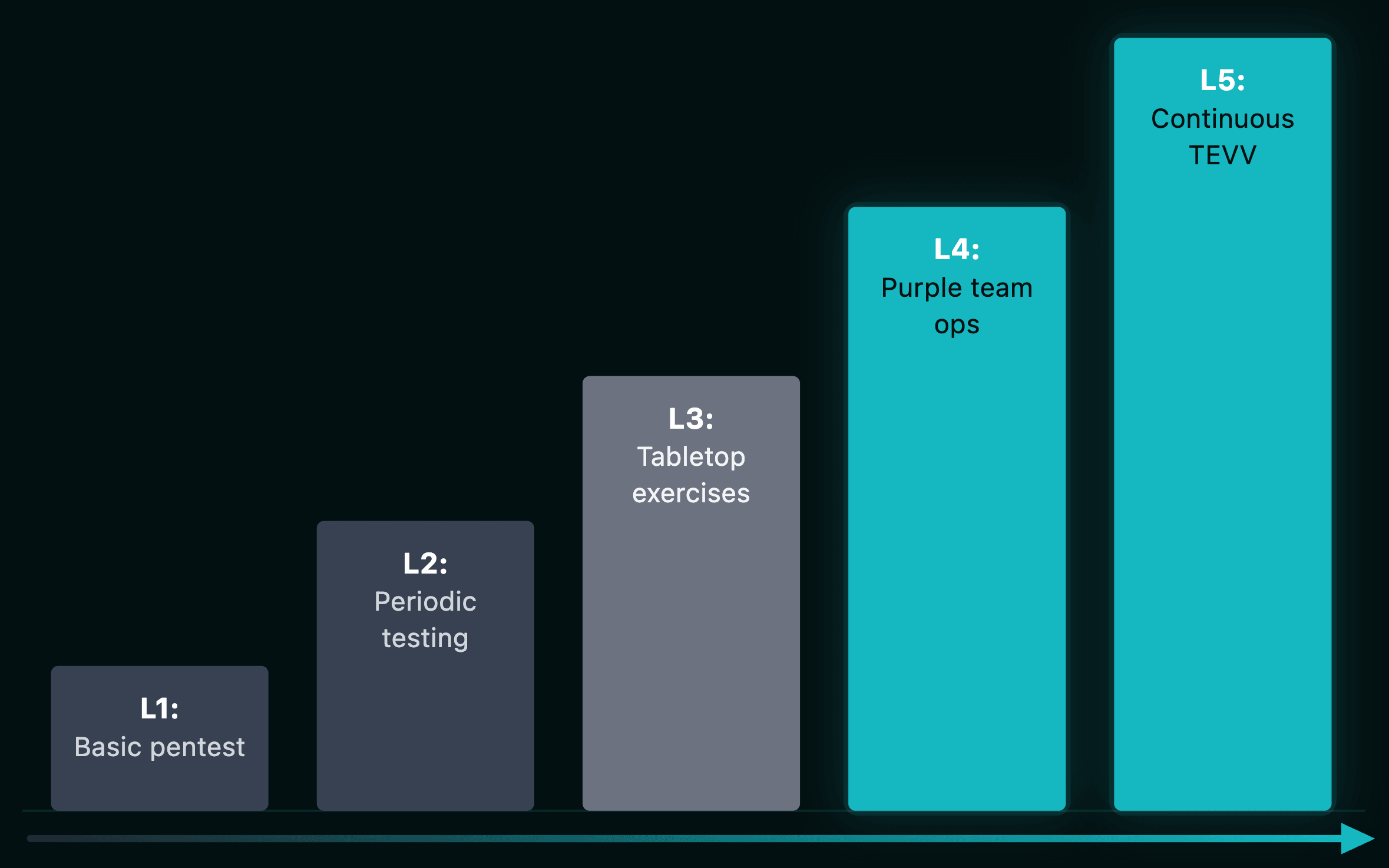
集成 TEVV 生命周期
战略性安全需要将这些内容整合到测试、评估、验证与确认(TEVV)生命周期中。防御方法必须从数据摄取到运行验证彼此联锁,遵循纵深防御理念。
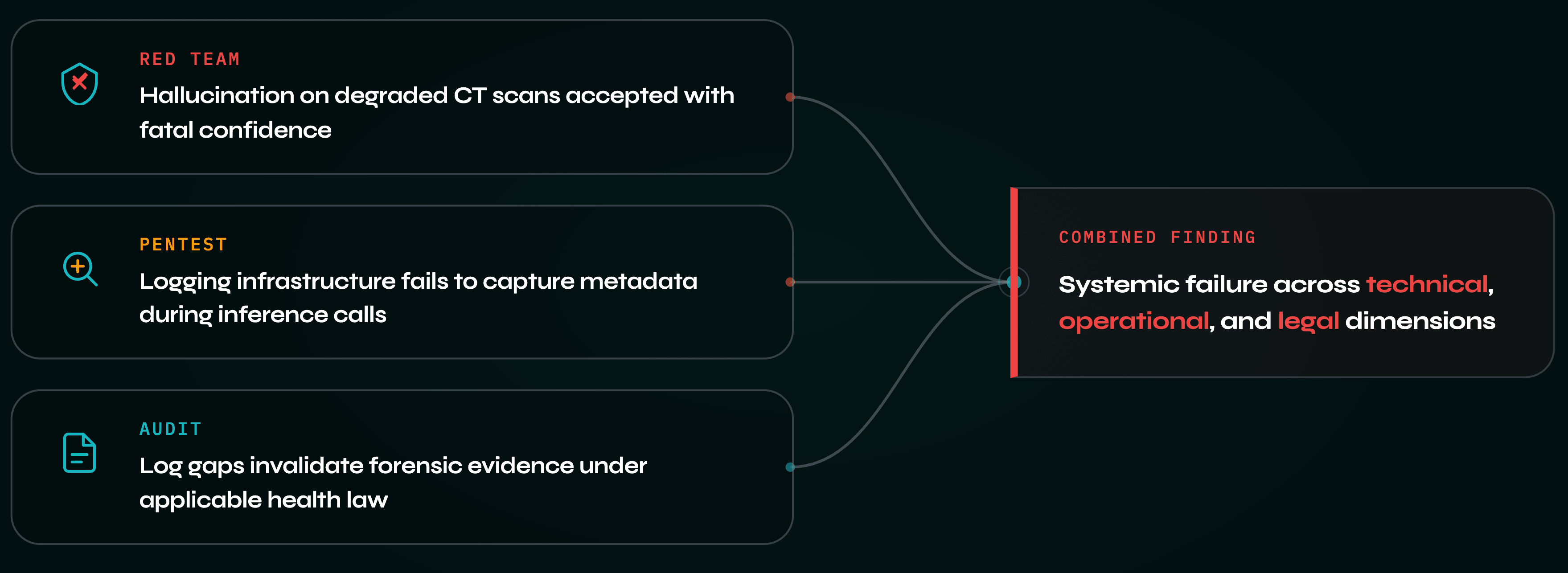
案例研究:医疗中的复合失效
考虑一个用于放射影像扫描的 AI 分诊助手:
- 红队发现,退化图像中的幻觉会在高置信度下被接受。
- 渗透测试揭示,日志基础设施未能捕获关键元数据。
- 审计发现,缺陷日志使卫生法律要求的取证证据失效。
实际的下一步
- 绘制你的攻击面: 使用 OWASP LLM Top 10 作为基线。
- 建立红队演练节奏: 在监管机构或保险公司要求提供证据之前,先建立主动性项目。
- 为可审计性构建报告: 将渗透测试和红队发现视为 ISO 42001 或欧盟 AI 法案的合规工件。
- 执行差距分析: 如果在欧盟运营,立即开始评估是否符合 AI 法案第 9–15 条。
常见问题
什么是对抗性机器学习?
对抗性机器学习(AML)研究的是攻击者如何利用 ML 模型的统计基础。不同于传统漏洞,AML 攻击通过逃避、投毒或提取来操控 AI 的概率性本质。
什么是 IID 假设?
独立同分布(IID)假设指部署数据与训练数据分布一致。攻击者通过构造落在该分布之外的对抗性输入来破坏这一点,从而使模型在没有错误信号的情况下失效。
什么是面向 LLM 的 OWASP Top 10?
它是针对 LLM 应用关键安全风险的标准化分类体系,包括Prompt 注入、数据投毒和过度自主性。它是 AI 渗透测试的主要框架。
AI 安全中的 TEVV 是什么?
TEVV 代表测试、评估、验证与确认。它是一个生命周期框架,将渗透测试、红队演练和审计统一到一个持续流程中,确保安全措施贯穿整个 AI 生命周期并彼此联锁。
不遵守欧盟 AI 法案有哪些风险?
在未进行合格评定的情况下部署高风险 AI,可能导致最高 3500 万欧元或全球营收 7% 的罚款。它还要求有文档化的风险管理、数据治理以及经证明具备抗攻击韧性。
- 原文链接: zealynx.io/blogs/ai-secu...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





