Filecoin - testnet3中Sector处理逻辑变化
- Star Li
- 发布于 2020-04-01 10:51
- 阅读 5183
Lotus代码更新的频度变的快了,每天都有不少代码merge进来。目前零知识证明的CRS,已经从V20更新到V24版本。目前测试网络也进入了testnet3阶段。在之前的V20的版本基础上,V24版本对Sector处理也有些变化。
前一篇文章尝试了一下微信公众号文章收费,挺有意思。付费的大部分是认识的好朋友,主要是鼓励支持。谢谢朋友们的鼓励,也会坚持把理解及时写下来,分享。
前段时间看了傅盛的悬崖边的反思。感触比较深,文章中的16/17年大事件的时间点,我就在猎豹移动。猎豹移动,确实很早就预知工具会被OS化,工具App的未来比较迷茫。16年,工具App保收入,17年新闻,AI。猎豹移动的文化是小步快跑,快速试错。确实,那几年感觉猎豹移动主要在定目标,做任务。没有找到自己的积累和壁垒。猎豹移动也蛮拼的,最紧张的时候,基本上每周都发布更新。App做的像猎豹移动这么大,很不简单,也有自己的比较完善的开发流程和体系。
但是,有个大问题,就是收入。收入的模式主要靠广告。海外广告,确实很容易被广告平台卡脖子。还是没法还击,只能妥协的那种。
几点感触,感知未来的趋势,但是想改变自己的局势,特别是想改变自己的DNA,是非常难的事情。商业闭环,很重要。虽然一个小的点,刚开始无法形成闭环,但是,随着发展,形成自己的闭环很重要。
Anyway,猎豹移动,目前在AI和机器人方向做了不少尝试。希望老东家走出低谷,发展顺利。
Lotus代码更新的频度变的快了,每天都有不少代码merge进来。目前零知识证明的CRS,已经从V20更新到V24版本。目前测试网络也进入了testnet3阶段。在之前的V20的版本基础上,V24版本对Sector处理也有些变化。
本文介绍一下testnet3的Sector处理的逻辑。相关的逻辑实现在rust-fil-proof项目中,本文中使用的源代码的最后一个提交信息如下:
commit 14870d715f1f6019aba3f72772659e38184378bf (HEAD -> master, origin/master, origin/HEAD) Author: Rod Vagg Date: Fri Mar 20 22:30:18 2020 +1100
feat(filecoin-proofs): expose filecoin_proofs::pad_reader
commit 78da3a008a1407654db600e6d5161464a8595e85
01
Sector处理(Precommit)过程
Precommit过程分为两个阶段,分别是phase1以及phase2, 也就是阶段1和阶段2。相关的接口函数在filecoin-proofs/src/api/seal.rs文件中的seal_pre_commit_phase1和seal_pre_commit_phase2函数。
总的来说,Sector Precommit过程的逻辑有两个比较大的变化:1)label encoding的算法从window SDR变成了SDR。2)过程分割成两个阶段。
SDR的计算过程在之前的文章中已经深入介绍。
这里就不再说了,主要介绍一下Sector处理的两个阶段相关逻辑。
1.1 Precommit Phase1
Phase1的过程主要是两部分的计算:1)计算原始数据的merkle树(二叉树,sha256 hash计算)2)label,也就是SDR的计算。原始数据的merkle树(tree _d),树根为comm_d。
1.2 Precommit Phase2
Phase2的过程主要也是两部分的计算:1)column hash 2)针对column hash的计算结果生成merkle树(八叉树,poseidon hash计算)3)针对label的计算结果,再做一次encoding,生成merkle树(八叉树,poseidon hash计算)。
column hash的计算过程如下:
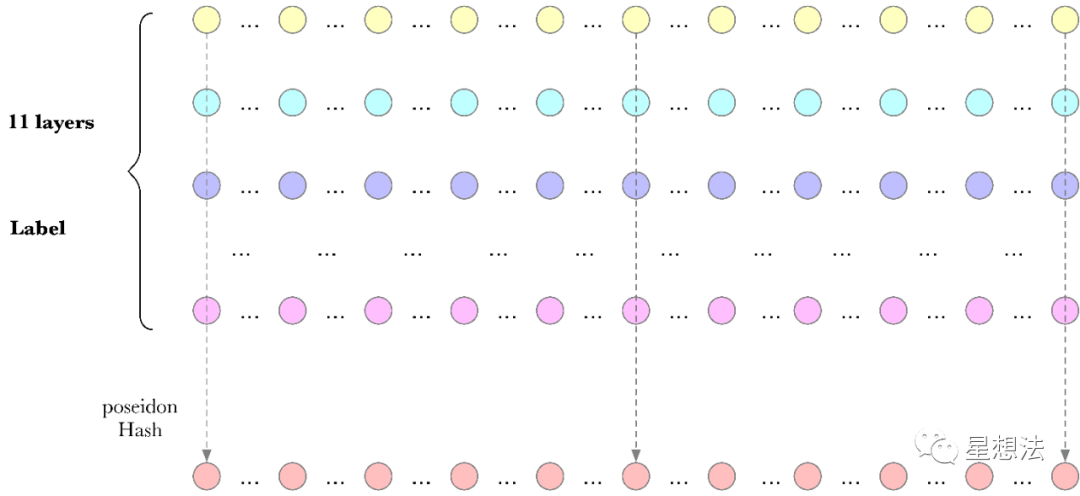
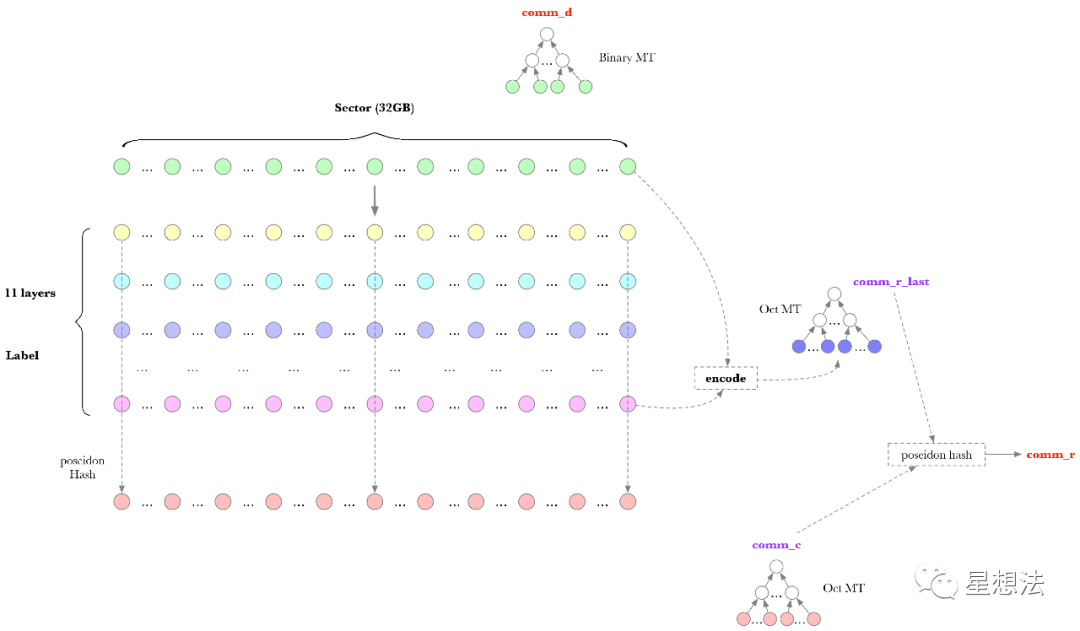
32GB的Sector,分割成1G个node。SDR的计算会生成11层的处理数据,每层都为32GB。每层的同一个编号的node数据,组合在一起后的hash的结果就是column hash的计算结果。Column hash的计算结果也是32GB。
针对column hash的计算结果,生成八叉树(tree_c),树根为comm_c。
label encoding的计算是将SDR的计算结果和原始数据进行encoding。所谓的encoding,目前就是大数的加法。encoding的结果,生成八叉树(tree_r_last),树根为comm_r_last。
上链的数据是两个:comm_d和comm_r。其中,comm_r是comm_c和comm_r_last的posedion的hash结果。
整个Sector处理逻辑,总结整体如下图:
02
Sector证明(Commit)过程
Commit过程分为两个阶段,分别是phase1以及phase2, 也就是阶段1和阶段2。Sector证明过程和零知识证明的过程密切相关。对零知识证明zk-SNARK理论和应用不熟悉的小伙伴,可以查看我之前写的相关文章。相关的接口函数在filecoin-proofs/src/api/seal.rs文件中的seal_commit_phase1和seal_commit_phase2函数。
Sector证明的阶段1,主要是准备电路需要的数据。这些数据即不完全是电路的公开数据,也不完全是电路的私有数据,而是电路数据需要的原始数据。阶段1,并不会对Sector的32G对应的1G的节点做证明,而是挑选一些节点做证明。
所有挑选的这些节点分为9个Partition:
pub static ref POREP_PARTITIONS: RwLock> = RwLock::new( [ (SECTOR_SIZE_2_KIB, 1), (SECTOR_SIZE_8_MIB, 1), (SECTOR_SIZE_512_MIB, 1), (SECTOR_SIZE_32_GIB, 9) ]
每个Partition都随机挑选一些节点。所有的挑选的节点个数不超过最小挑战节点数:
pub static ref POREP_MINIMUM_CHALLENGES: RwLock> = RwLock::new( [ (SECTOR_SIZE_2_KIB, 2), (SECTOR_SIZE_8_MIB, 2), (SECTOR_SIZE_512_MIB, 2), (SECTOR_SIZE_32_GIB, 138) ]
也就是说,对于32G的Sector而言,9个Parititon,每个Partition随机选择16个节点进行挑战。随机选择的具体算法在storage-proofs/src/porep/stacked/vanilla/challenges.rs的derive_internal函数中。
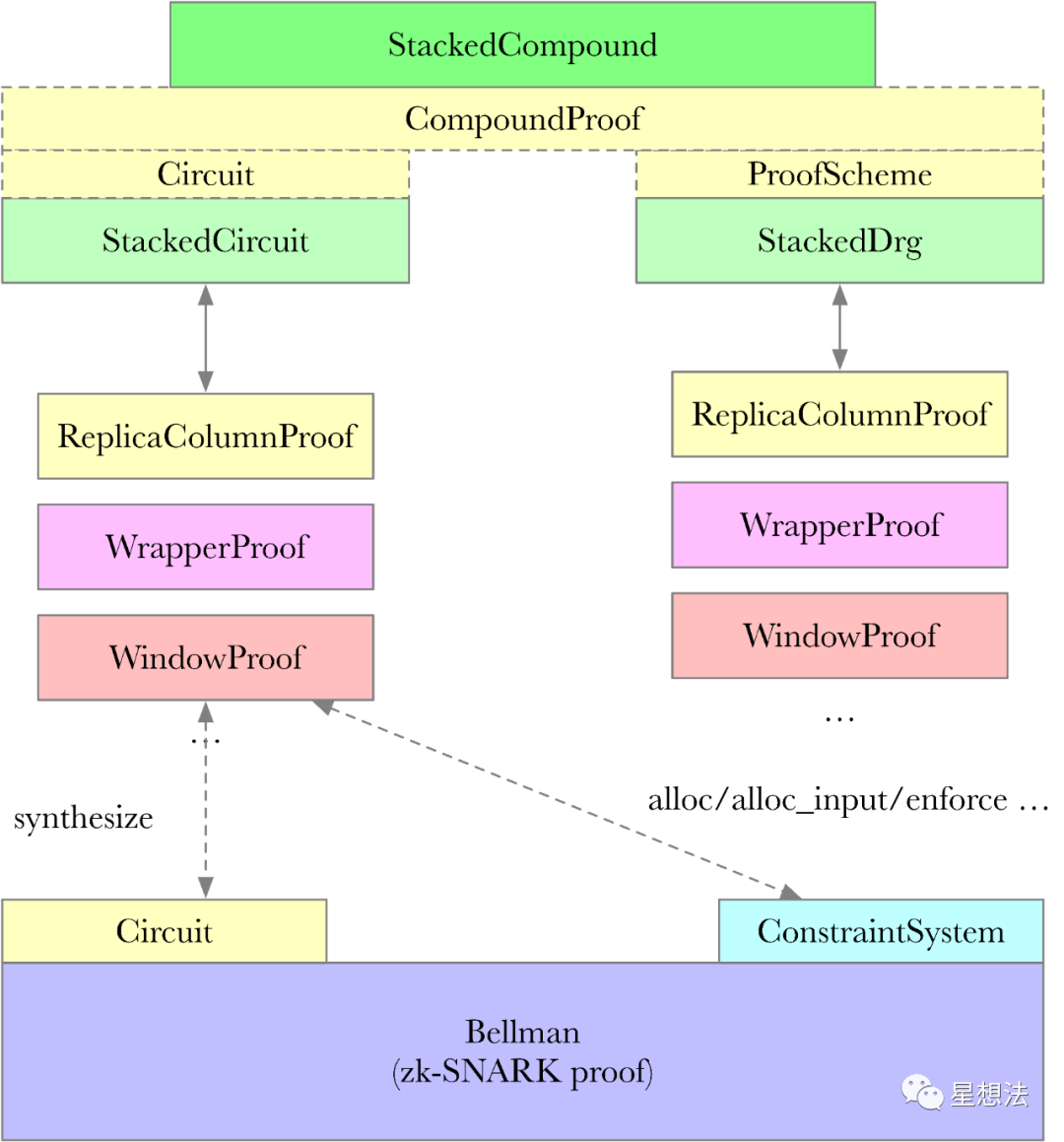
Sector证明的阶段2,就是零知识证明的电路处理以及生成零知识证明的过程。这部分的逻辑,总的框架和之前一样,主要是SDR的算法改动有一些变化。RUST-FIL-PROOF(FPS)实现了StackedCompound,专门用来实现Stacked DRG的数据处理证明。StackedCompound,将两部分整合在一起,一部分是电路(Stacked Circuit),另一部分是Stacked Drg,实现电路数据的准备。这些部分又分成一个个的子功能(Window,Wrapper,ReplicaColumn等等)。在调用Bellman生成证明时,相应电路的synthesize接口就会被调用,从而完成整个电路生成R1CS的过程。
总结:
Lotus的源代码更新比较频繁。Testnet3将Sector的Precommit和Commit处理都分成了两个阶段(Phase1和Phase2)。SDR是算法改动是最大的变化。零知识证明的CRS已经更新到V24版本。





