ZK × ML→迈向可验证人工智能的未来(上)
- Loki
- 发布于 2024-06-08 00:18
- 阅读 1993
“未来大政治的重大冲突才刚刚开始。在技术层面上,这场冲突的两极是:人工智能和加密技术”。人工智能自上而下集成数据,掌握在强势力量的机构和组织方。加密技术自下而上保护数据,代表的则是野火般的草根和 “反叛” 力量。AI x Crypto,如果可以将其充满矛盾的技术底层化为一体,势能必然不容小觑。
背景介绍
Peter Thiel 曾在 2020 年这么预测:“未来大政治的重大冲突才刚刚开始。在技术层面上,这场冲突的两极是:人工智能和加密技术”。这其中有几个重要信息点。首先,Thiel 笃定未来是属于人工智能和加密技术的,它们之间一个决定生产力、一个决定生产关系,都是当下最热门也是对现有秩序最具破坏性的技术,也就意味着他们的发展将会塑造人类社会的形态——因此作为人类,我们需要在进步中保持警惕。其次,在架构逻辑上,它们又为彼此的反面。人工智能自上而下集成数据,掌握在强势力量的机构和组织方。加密技术自下而上保护数据,代表的则是野火般的草根和 “反叛” 力量。AI x Crypto,如果可以将其充满矛盾的技术底层化为一体,势能必然不容小觑。 --------引自Web3caff研报
什么是 ZKML?
零知识机器学习(ZKML)是一种结合了机器学习和零知识证明(ZKP)的协议。 ZKP 是一种加密工具,一方(证明者)可以证明他们可以保证某些事情是真实的,而无需真正透露任何其他信息。将此与机器学习相结合意味着我们可以在不泄露训练数据本身中使用的敏感数据的情况下生成输出,并确保计算的分散性和准确性。 如我们所知,ZKML 通过在分散网络中不同节点上分布的数据训练机器学习模型来运行。然后,这些节点可以生成有关其数据的零知识证明。基本上可以确定的是,这些证明允许节点确认该数据完全真实,而不会泄露敏感数据本身。 是不是还不是太懂?接下来我们把它分开来看。 ZK(零知识证明)是一种密码协议,证明者可以向验证者证明给定的陈述是真实的而无需透露任何其他信息,也就是说不需要过程就可以知道结果。ZK有两大特点:第一,证明了想证明的东西而无需透露给验证者过多的信息;第二,生成证明很难,验证证明很容易。 基于这两个特点,ZK发展出了几大用例:Layer 2 扩容、隐私公链、去中心化存储、身份验证、以及机器学习等。本文的研究重点将集中在ZKML(零知识机器学习)上面。
Figure 1:The workflow of ZKP Source: @Harry Alford 什么是ML(机器学习) ?机器学习是一门人工智能的科学,涉及算法的开发和应用,使计算机能够自主学习和适应数据,通过迭代过程优化其性能,无需编程过程。如果我自己定义机器学习,我会这样解释:机器学习基本上是机器独立学习和适应数据的能力,这样你就知道这些计算机模型可以模仿或表现出“智能人类行为”。 众所周知,ML 是 AI(人工智能)的一个子领域,其应用范围包括根据你的活动和互动个性化你的淘宝消费行为或抖音偏好,或者决定在B站等第三方流媒体上向你展示的广告,或者利用你之前在线购买和搜索的数据历史,以便适应和展示你推荐的产品。详细来说,它利用算法和模型来识别数据得到模型参数,最终做出预测/决策。
Figure2: The workflow of ML Source: @Droom
为什么需要ZKML?
对于我们这些非开发者的普通用户来说,当我们使用机器学习模型时,我们需要知道的是,如果我们想从它们(大模型)那里获得可靠的答案/输出,我们需要有一些前提假设,它们是:
- 输入数据是准确且没有受到干扰,以及数据属性明确(私有或公共)
- 机器学习模型正确计算输出,没有人对模型进行了修改。简而言之,遵循我们所知道的准确性、完整性和保密性原则
- 最后,我们根据输入数据得到的输出或答案是准确的以及数据属性明确(私有或公共) 当使用像 ChatGPT 3.5/4 这样的机器学习语言模型时,用户通常会以提示的形式向它提供一些信息,并相信它会给你正在浏览的答案,而不会泄露你提供的相关内容或是有关敏感数据,也不会泄露任何私人信息和有关模型本身的详细信息。但不得不遗憾告诉你的是,推理过程中可能存在隐私安全风险。比如,这些可以是“成员推理攻击”或“模型反转攻击”。你问这些是什么?下面简单解释一下。
- 假设攻击者/黑客试图猜测你的医疗记录是否被用来训练健康保险机器学习模型——只需分析你知道的模型的输出就可以弄清楚。
- 或者你知道恶意用户可能会编造此类非常具体的提示来欺骗模型泄露其训练数据的细节。
这就是零知识机器学习技术致力于解决的隐私问题。你也许到现在还没理解上面的机器学习模型的问题到底出在哪里。但是在广泛讨论它的工作原理之后,我们可以确定最大的问题在于:很难准确地看出机器学习是如何得出答案的,这是一个黑盒系统。 这就是著名研究人Daniel Kang 的成果,他指出机器学习模型通常隐藏在封闭的 API 后面,我们不知道是否存在用于访问程序的秘密代码。 为了保护用户隐私,像X或 OpenAI 这样的公司并没有像你想的那样发布模型权重,例如,Elon Musk 的 X 已经开源了他们的“For you”时间线算法,但没有透露它是如何实现的细节发生。此外,另一个原因是这些机器学习模型就像这些公司的商业秘密,因为你知道他们投入了大量的时间和资源来训练它们,这可以使他们在竞争中保有优势。
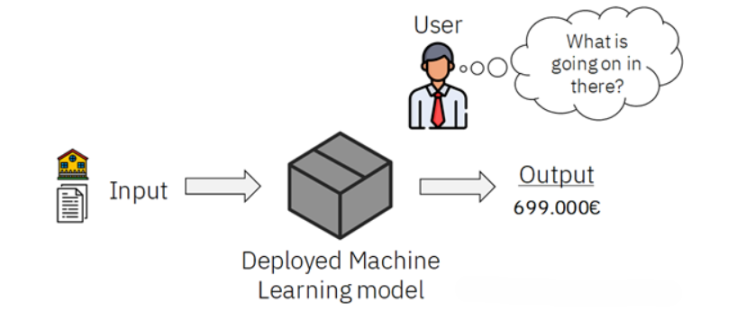 Figure 3:The Workflow of "BlackBox"
Source: @deephub-imba
Figure 3:The Workflow of "BlackBox"
Source: @deephub-imba
结语
再详细来说,因为缺乏透明度或可证明性,信任问题长期以来一直困扰着机器学习 ,主要原因有两个:
- 隐私性:如前所述,模型参数通常是私有的,在某些情况下,模型输入也需要保密,这自然会在模型拥有者和模型使用者之间带来一些信任问题。
- 算法的黑匣子:机器学习模型有时被称为“黑匣子”,因为它们在计算过程中涉及许多难以理解或解释的自动化步骤。这些步骤涉及复杂的算法和大量数据,这些数据会带来不确定的、有时是随机的输出,使算法成为偏见甚至歧视的罪魁祸首。 而通过将 ZK 集成到 ML 的过程可以提供了一个安全且隐私保护的平台,解决了传统 ML 的信任问题同时从保证隐私安全和计算完整性等方向上保证了AI的可控发展。
具体如何去应用ZK集成到ML的相关技术原理细节我们将在下一篇中详细为大家介绍。欢迎大家持续关注我的公众号👏👏P.S 思辨家的记录本
- 原创
- 学分: 0
- 标签: