零知识证明 - SP1 zkVM源代码入门
- Star Li
- 发布于 2024-06-25 16:56
- 阅读 6772
一直对zkVM比较感兴趣。zkVM将零知识证明技术应用带入一个新的时代。几年前,应用零知识证明技术需要理解复杂的零知识证明算法,并且需要将证明业务逻辑描述成“电路”。zkVM将这些复杂的逻辑封装。基于zkVM,业务开发人员可以采用熟悉的高级语言轻松完成证明业务的描述。目前市面上zkVM层出不穷。先看
一直对zkVM比较感兴趣。zkVM将零知识证明技术应用带入一个新的时代。几年前,应用零知识证明技术需要理解复杂的零知识证明算法,并且需要将证明业务逻辑描述成“电路”。zkVM将这些复杂的逻辑封装。基于zkVM,业务开发人员可以采用熟悉的高级语言轻松完成证明业务的描述。目前市面上zkVM层出不穷。先看看SP1的代码和设计。
01. SP1 - zkVM
SP1是个支持RISC-V指令集的虚拟机。对于在该虚拟机执行的程序,SP1能生成证明,证明执行正确。
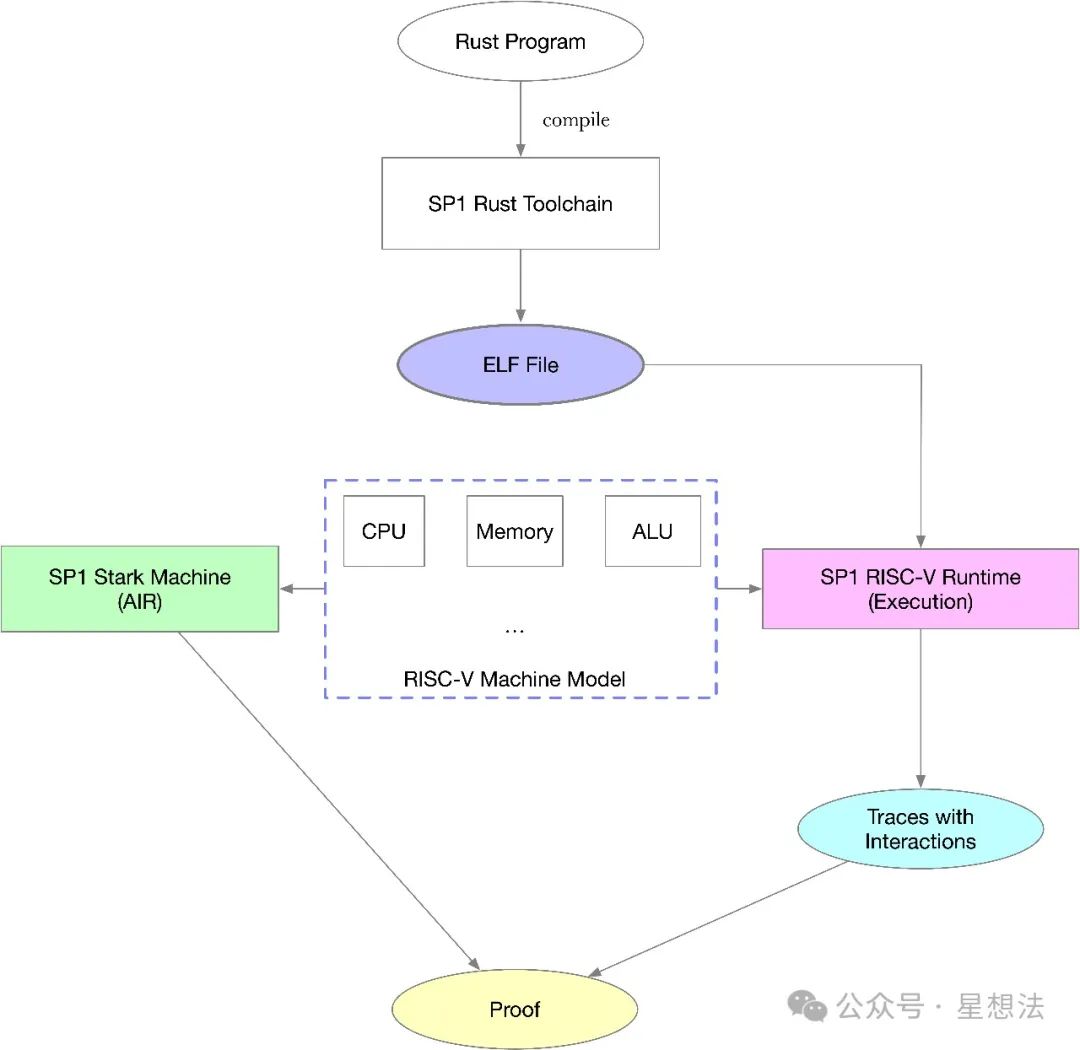
SP1提供了工具链(toolchain)将rust代码编译生成ELF文件(RISC-V指令集)。按照芯片功能,SP1虚拟机由多个芯片组成:CPU,ALU,内存等等。在Plonky3的基础上,SP1增强了芯片间互连的AIR描述,并利用LogUp算法,实现了完整的基于RISC-V CPU的虚拟机约束描述。除此之外,内存的访问一致性问题,巧妙地转换成置换问题,同样通过LogUp算法实现。
02. 使用Plonky3搭建电路
SP1在Plonky3的基础上构建虚拟机。SP1可以看成Plonky3上的一个庞大的电路“应用”。所以,理解SP1源代码,需要先理解Plonky3电路搭建逻辑和接口。
Plonky3的源代码:https://github.com/Plonky3/Plonky3.git。
其中,uni-stark/tests/fib_air.rs是一个Plonky3搭建电路的示例,实现斐波那契序列计算。从这个示例,可以快速学习Plonky3的电路搭建方法。
先查看prove函数的接口:
除了配置信息(config)以及挑战生成计算方式(challenger)外,prove函数需要:1/ 电路描述(air) 2/ trace信息 以及 3/ 公开输入信息(public_values)。Plonky3的证明系统调用Air接口中的eval函数,通过AirBuilder构建或者检查电路约束。在获取了电路约束的多项式形式后,Plonky3的证明系统通过多项式承诺以及打开生成证明。
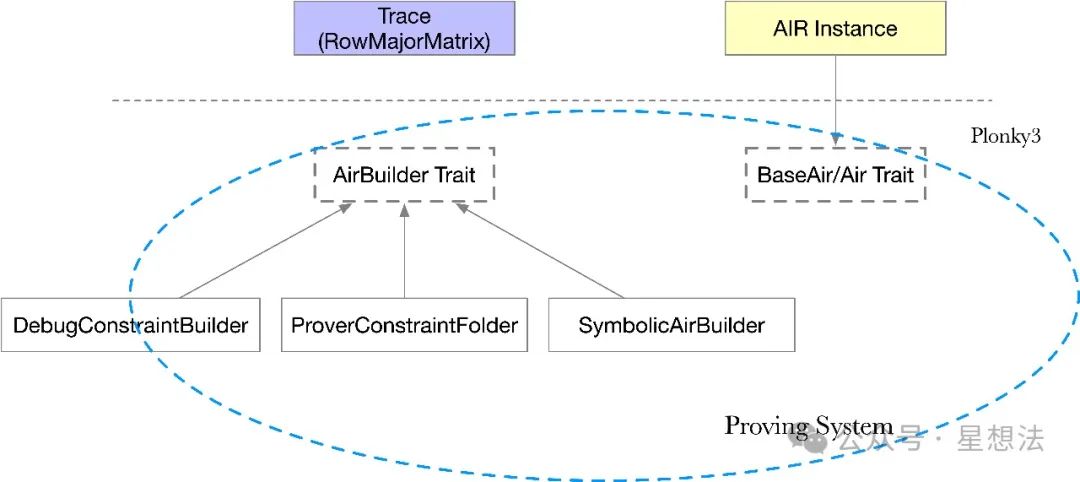
我们主要看看AIR电路描述和trace的生成过程。
AIR描述
Plonky3采用AIR( A lgebraic I ntermediate R epresentation)描述电路。电路描述的结构体,必须实现BaseAir和Air的接口(定义在air/src/air.rs中)。BaseAir接口实现电路的基本信息(width(列数))。Air接口实现eval函数,描述电路约束。
重点查看eval函数的定义:
pub trait Air<AB: AirBuilder>: BaseAir<AB::F> {
fn eval(&self, builder: &mut AB);
}Plonky3提供了约束描述的构建工具(AirBuilder)。开发者可以通过AirBuilder轻松构建约束。AirBuilder实现了一系列when以及assert函数,方便开发者定义“某些条件“下的约束。同时,AirBuilder提供了main函数,抽象出了当前行以及下一行的“内部”表示。
Plonky3自带了三个Builder:DebugConstraintBuilder,SymbolicAirBuilder以及ProverConstraintFolder。DebugConstraintBuilder定义在uni-stark/src/check_constraints.rs,主要用来检查每一行的约束是否满足。ProverConstraintFolder定义在uni-stark/src/folder.rs中,主要用来构建约束多项式的商多项式。 SymbolicAirBuilder主要用来确定商多项式的阶(degree)。
以斐波那契序列计算的示例为例,AIR描述的核心逻辑如下:
let main = builder.main();
let (local, next) = (main.row_slice(0), main.row_slice(1));
//如果是首行,首行的左右两个元素分别是公开输入a和b
let mut when_first_row = builder.when_first_row();
when_first_row.assert_eq(local.left, a);
when_first_row.assert_eq(local.right, b);
//如果不是首行或者最后一行的话,下一行的左边元素和上一行的右边元素相等,并且下一行的右边元素和上一行的左右元素和相等
let mut when_transition = builder.when_transition();
when_transition.assert_eq(local.right, next.left);
when_transition.assert_eq(local.left + local.right, next.right);
//如果是最后一行的话,右边的元素是另外一个公开输入(x)
builder.when_last_row().assert_eq(local.right, x);首先通过builder获取当前行以及下一行的描述,通过一系列assert函数约束这两行元素之间的约束关系。
Trace生成
trace信息存储成一个矩阵信息(RowMajorMatrix)。该矩阵的列数和BaseAir接口中定义的列数相等。以斐波那契序列计算的示例为例,trace由8行2列组成,其生成的逻辑如下:
let mut trace =
RowMajorMatrix::new(vec![F::zero(); n * NUM_FIBONACCI_COLS], NUM_FIBONACCI_COLS); //初始化矩阵信息
for i in 1..n {
rows[i].left = rows[i - 1].right; //下一行的左边元素 等于 上一行的右边元素
rows[i].right = rows[i - 1].left + rows[i - 1].right; //下一行的右边元素 等于 上一行左右两个元素的和
}熟悉了Plonky3的电路搭建方法,开始看SP1。
SP1的源代码:https://github.com/succinctlabs/sp1.git 。本文中使用的SP1源代码的最后一个commit如下:
commit 3c0dae88ffbcda9fd261e51bd1fea7571f0fd59e
Merge: 2ce75c6e f0a9f2f2
Author: Ratan Kaliani <ratankaliani@berkeley.edu>
Date: Thu May 30 11:49:13 2024 -0700
refactor: ProverClient::remote -> ProverClient::network (#840)03. SP1 Client/SDK
SP1提供Client端命令 cargo prove,进行电路业务的证明。所有的电路业务采用rust代码编写。cargo prove命令通过sp1up脚本进行安装,其对应的的源代码:cli/src/bin/cargo-prove.rs。cargo prove实现了一些子命令:项目创建,编译,证明,编译以及安装工具链。
Usage: cargo prove [OPTIONS]
cargo prove <COMMAND>
Commands:
new Setup a new project that runs inside the SP1.
build Build a program
prove (default) Build and prove a program
build-toolchain Build the cargo-prove toolchain.
install-toolchain Install the cargo-prove toolchain.
help Print this message or the help of the given subcommand(s)SP1虚拟机采用riscv32im指令集。SP1修改了rust的核心代码,增加了riscv32im指令集的支持,并提供对应的工具链。
new子命令用来创建工程模版:创建program和script目录。program目录创建虚拟机中运行程序。script目录初始化虚拟机,执行程序并生成证明。
编译过程比较简单,指定编译工具链,调用cargo命令编译生成elf文件:
let result = Command::new("cargo")
.env("RUSTUP_TOOLCHAIN", "succinct")
.env("CARGO_ENCODED_RUSTFLAGS", rust_flags.join("\x1f"))
.args(&cargo_args)
.status()
.context("Failed to run cargo command.")?;"passes=loweratomic" //单线程程序,不需要考虑原子操作
"link-arg=-Ttext=0x00200800", //程序地址从0x00200800开始有了编译后的elf文件和指定的输入数据,prove子命令通过ProverClient生成证明:
let client = ProverClient::new();
let (pk, _) = client.setup(&elf);
let proof = client.prove(&pk, stdin).unwrap();ProverClient定义在SDK中,抽象了几种Prover类型:MockProver,LocalProver以及NetworkProver。为了理解SP1的核心逻辑,我们主要关注LocalProver的实现。LocalProver是SP1Prover的封装。SP1Prover实现在prover目录中。SP1Prover的setup/prove/verify等核心逻辑都实现在core目录中。
04. StarkMachine - 基于RISC-V CPU的机器
StarkMachine是AIR描述的机器。为了更好的描述,SP1创建了新的trait接口 - MachineAir。MachineAir增加了generate_trace接口,生成trace信息。MachineAir还增加了generate_dependencies接口,描述芯片间的依赖关系。
StarkMachine由如下的芯片组成:
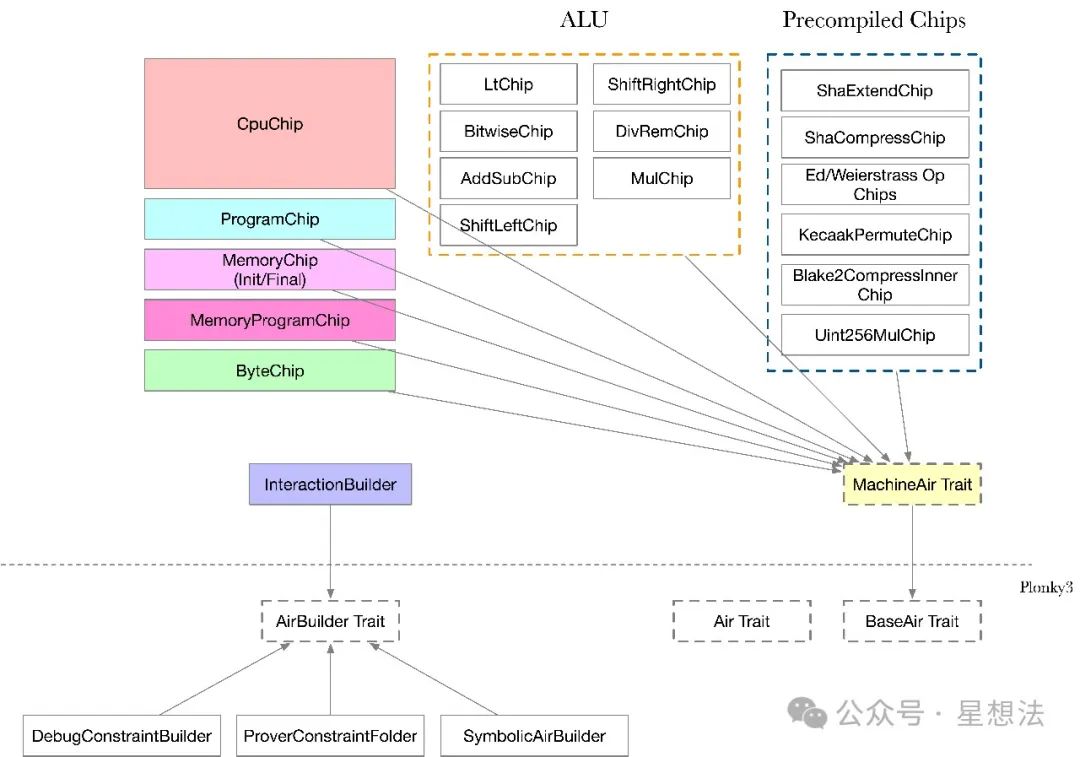
CpuChip负责程序的执行序列。MemoryChip负责内存信息。MemoryProgramChip存储执行程序。ByteChip存储有关字节操作的查找表。ALU中包括加减乘除以及比特操作芯片。除此之外,还有一些预编译的芯片。从列的定义以及约束描述(eval函数)可以大体了解芯片的主要功能。
CPU芯片(CpuChip)
CPU芯片所有的列信息由CpuCols结构定义:core/src/cpu/columns/mod.rs。CPU芯片的列信息包括:shard/channel ,clk,pc,instruction,op_a/op_b/op_c等等信息。CPU芯片的列信息比较多,不一一列举,大多数还是比较简单易懂的。
CpuChip的约束实现:core/src/cpu/air/mod.rs。主要约束了和其他芯片的连接关系(Interaction在后面详细解释),pc的正确性,寄存器的正确使用以及指令中的操作数是否正确。详细的约束关系,感兴趣的小伙伴可以查看源代码。
内存芯片(MemoryChip)
MemoryChip分为两种类型:Initialize(初始化)以及Finalize(内存最终状态)。
pub enum MemoryChipType {
Initialize,
Finalize,
}虽然内存分为两种类型,两种类型的内存芯片采用类似的约束结构。列信息由MemoryInitCols结构定义:
pub struct MemoryInitCols<T> {
pub shard: T,
pub timestamp: T,
pub addr: T,
pub value: Word<T>,
pub is_real: T,
}主要的信息包括:内存访问的时间,地址以及值。is_real指明某个内存的访问是否在执行序列中真实发生。也就是说,内存中有些地址在某个程序的执行序列中从来没有出现过。
需要特殊说明的是,寄存器的地址空间被映射成内存芯片地址空间的一部分,从0地址开始。在约束描述中,有个明确的约束,寄存器0的内存必须是0。
代码芯片(ProgramChip)
代码芯片定义在:core/src/program/mod.rs。代码芯片的列信息分为预处理以及非预处理的部分。
pub struct ProgramPreprocessedCols<T> {
pub pc: T,
pub instruction: InstructionCols<T>,
pub selectors: OpcodeSelectorCols<T>,
}
pub struct ProgramMultiplicityCols<T> {
pub shard: T,
pub multiplicity: T,
}预处理的部分,主要是pc以及对应指令信息(包括译码信息)。非预处理的部分说明代码在执行过程中的使用情况。
MemoryProgramChip
MemoryProgramChip是提供程序“固定”内存,其定义在core/src/memory/program.rs。
pub struct MemoryProgramPreprocessedCols<T> {
pub addr: T,
pub value: Word<T>,
pub is_real: T,
}
pub struct MemoryProgramMultCols<T> {
pub multiplicity: T,
pub is_first_shard: IsZeroOperation<T>,
}MemoryProgramChip的列信息分为两部分:一部分是能预处理的部分,一部分是不能预处理的部分。
字节数据芯片(ByteChip)
ByteChip提供了字节处理的相关功能,比如说,比特的逻辑运算,范围检查等等。ByteChip定义在core/src/bytes/mod.rs。
ByteChip的列信息也包括预处理以及不可预处理的两部分。
pub struct BytePreprocessedCols<T> {
pub b: T,
pub c: T,
pub and: T,
pub or: T,
pub xor: T,
pub sll: T,
pub shr: T,
pub shr_carry: T,
pub ltu: T,
pub msb: T,
pub value_u16: T,
}
pub struct MultiplicitiesCols<T> {
pub multiplicities: [T; NUM_BYTE_OPS],
}
pub struct ByteMultCols<T> {
pub shard: T,
pub mult_channels: [MultiplicitiesCols<T>; NUM_BYTE_LOOKUP_CHANNELS as usize],
}可以想象成,BytePreprocessedCols给出了功能“真值表”。ByteMultCols提供了具体功能使用情况。注意的是,ByteChip提供了多channel功能。也就是说,一个ByteChip提供了4个channel的字节处理功能。
ALU芯片 - AddSubChip
ALU芯片的功能比较多。以加减法为例。AddSubChip定义在core/src/alu/add_sub/mod.rs。
pub struct AddSubCols<T> {
pub shard: T,
pub channel: T,
pub add_operation: AddOperation<T>,
pub operand_1: Word<T>,
pub operand_2: Word<T>,
pub is_add: T,
pub is_sub: T,
}channel说明当前的操作使用某一个channel的Byte功能。operand_1/operand_2以及add_operation说明操作子和计算结果。
所有的芯片进一步由Chip结构体封装:core/src/stark/chip.rs
pub struct Chip<F: Field, A> {
/// The underlying AIR of the chip for constraint evaluation.
air: A,
/// The interactions that the chip sends.
sends: Vec<Interaction<F>>,
/// The interactions that the chip receives.
receives: Vec<Interaction<F>>,
/// The relative log degree of the quotient polynomial, i.e. `log2(max_constraint_degree - 1)`.
log_quotient_degree: usize,
}芯片间互连(Interaction)
先介绍一个重要的概念:Interaction。Interaction用来验证或者约束多芯片之间的连接关系。一个Chip中包括两个“方向”的互连操作:发送(send)和接收(receive)。发送互连是指芯片自己无法验证的逻辑,需要“发送”给其他芯片进行验证。接收互连指芯片接收到其他芯片的验证请求。
Interaction定义在core/src/lookup/interaction.rs:
pub struct Interaction<F: Field> {
pub values: Vec<VirtualPairCol<F>>,
pub multiplicity: VirtualPairCol<F>,
pub kind: InteractionKind,
}InteractionKind用来区分不同的连接类型:
pub enum InteractionKind {
/// Interaction with the memory table, such as read and write.
Memory = 1,
/// Interaction with the program table, loading an instruction at a given pc address.
Program = 2,
/// Interaction with instruction oracle.
Instruction = 3,
/// Interaction with the ALU operations.
Alu = 4,
/// Interaction with the byte lookup table for byte operations.
Byte = 5,
/// Requesting a range check for a given value and range.
Range = 6,
/// Interaction with the field op table for field operations.
Field = 7,
/// Interaction with a syscall.
Syscall = 8,
}为了更好的“收集”某个芯片和其他芯片的互连信息,SP1创建了InteractionBuilder。InteractionBuilder只关注芯片间的互连信息,忽略芯片的约束信息。
重新查看所有芯片的eval函数,总结SP1中芯片的互连信息如下:
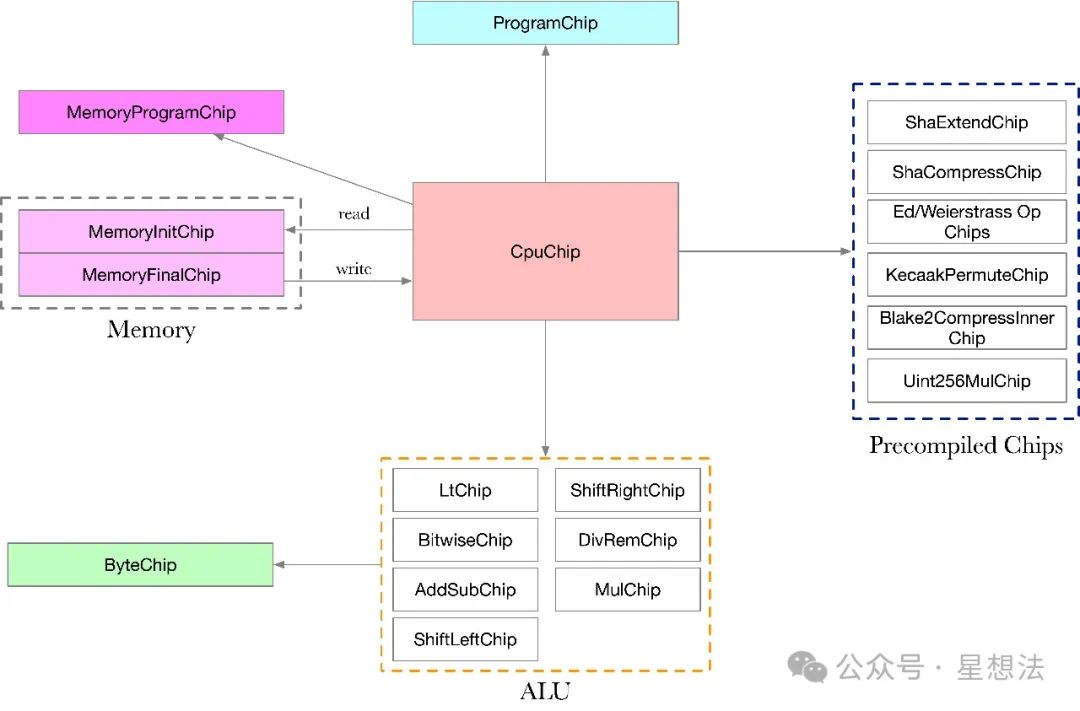
一个有趣的问题是,如何约束“互连”真实存在?一个连接的发送数据和接收收据一致?SP1采用LogUp(Log Derivative Lookup Argument)算法证明两个序列是置换关系。LogUp算法以及SP1的证明协议可以查看SP1技术设计文档的6.3。画个图说明证明思路。
举个例子,Chip2和Chip3发送一些数据发送给Chip1。multiplicity记录了每一行数据的使用次数。
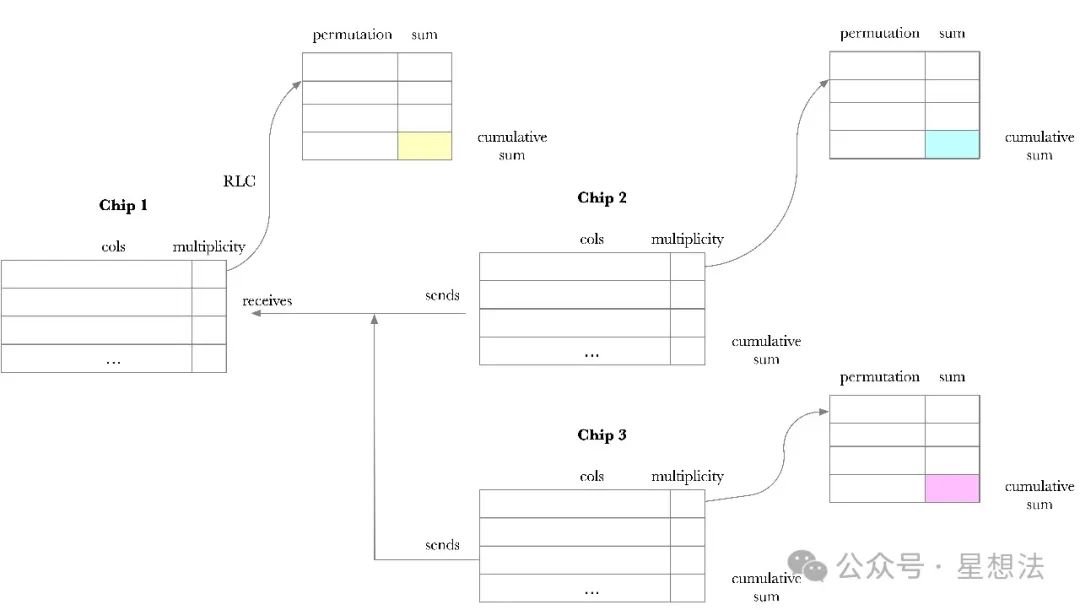
发送方和接收方首先将每一行的数据进行随机线性化处理。其结果乘以每一行对应的multiplicity后存储在每个芯片对应的permutation列中。注意,接收方的mulitplicity是负的。在所有的permutation计算完成后,将其进行累加。显然,如果发送方和接收方的发送和接收的数据一致的情况下(除了行先后次序不同外),发送方芯片的累加和和接收方芯片的累加和相加为0。
SP1技术设计文档的公式更清晰的表述了该过程。
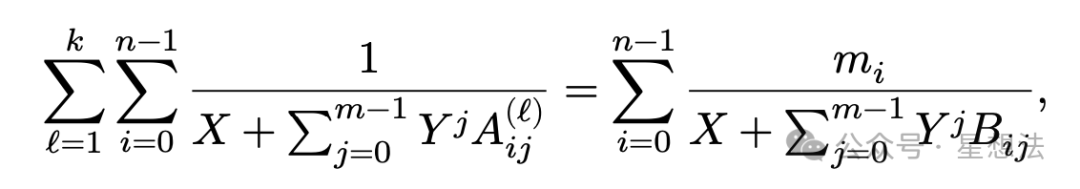
注意,permutation的计算以及累加和的计算SP1也进行了约束和证明。
内存一致性的保证
细心的小伙伴可能发现,内存的“中间变化”过程并没有体现在内存芯片中。内存访问的一致性(内存读的数据都是之前写入的数据)通过证明读和写数据是“置换”实现。置换证明的原理在“芯片互连”部分详细说明。这里,解释一下内存访问的一致性如何转换成“置换”问题。内存的读写都约束成一对读写操作。内存读变成(读,写),读写的数据一致。内存写变成(读,写),读写的数据不一致。除去初始化数据和最终数据外,读和写的序列是一样的。读写序列和clk编号后,消除了顺序,问题就转换成了读写序列是置换的问题。以一个内存单元(x0)的读写序列为例,下图说明了置换的逻辑原理:
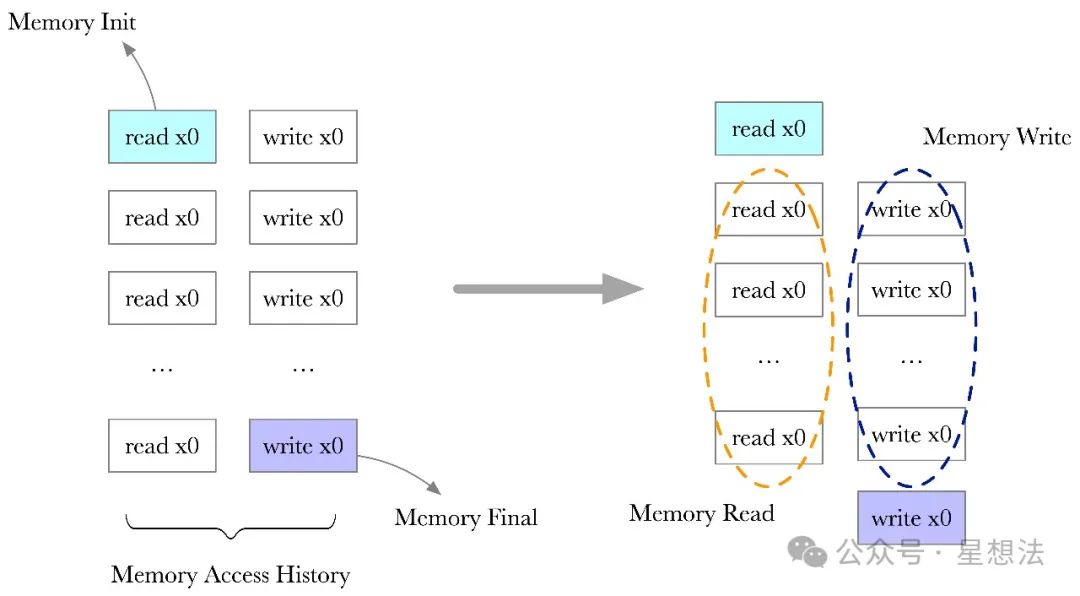

内存一致性问题,就转换成上图中的Memory Read/Memory Write序列是不是置换的问题。类似芯片互连,Memory Read/Write构成了“虚拟”的连接,逻辑如下:
fn eval_memory_access<E: Into<Self::Expr> + Clone>(
&mut self,
shard: impl Into<Self::Expr>,
channel: impl Into<Self::Expr>,
clk: impl Into<Self::Expr>,
addr: impl Into<Self::Expr>,
memory_access: &impl MemoryCols<E>,
do_check: impl Into<Self::Expr>,
) {
...
// The previous values get sent with multiplicity = 1, for "read".
self.send(AirInteraction::new(
prev_values,
do_check.clone(),
InteractionKind::Memory,
));
// The current values get "received", i.e. multiplicity = -1
self.receive(AirInteraction::new(
current_values,
do_check.clone(),
InteractionKind::Memory,
));
}以上描述的是AIR视角中的SP1虚拟机。接下来,可以看看虚拟机执行以及trace生成。
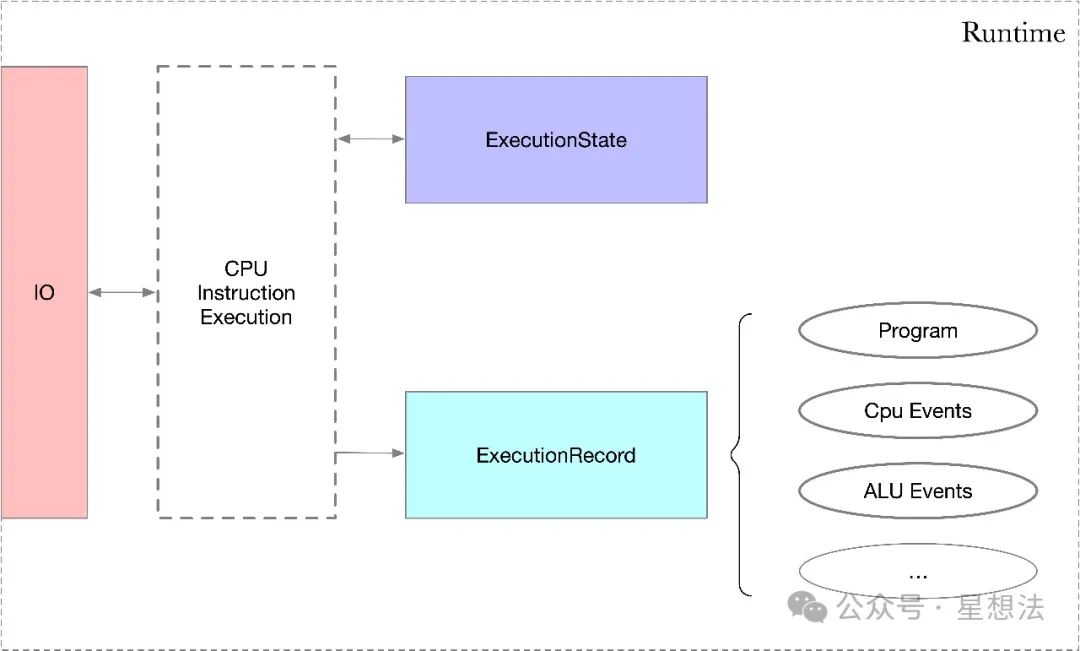
05 Runtime - Program执行
一个程序在Runtime环境中执行,并记录trace需要的各种事件(Events)。逻辑相对比较简单,主体的代码框架如下:
fn execute(&mut self) -> Result<bool, ExecutionError> {
if self.state.global_clk == 0 {
self.initialize();
}
...
loop {
if self.execute_cycle()? {
done = true;
break;
}
...
}
if done {
self.postprocess();
}
Ok(done)
}一个Runtime环境中主要包括三部分:IO(输入输出的管理),ExecutionState(存储执行过程中中间状态)以及ExecutionRecord(记录程序后的各种事件)。
注意,每一定数量(1<<22)个指令形成一个shard。shard大小的配置如下:
pub struct SP1CoreOpts {
pub shard_size: usize,
pub shard_batch_size: usize,
pub shard_chunking_multiplier: usize,
pub reconstruct_commitments: bool,
}
impl Default for SP1CoreOpts {
fn default() -> Self {
Self {
shard_size: 1 << 22,
shard_batch_size: 16,
shard_chunking_multiplier: 1,
reconstruct_commitments: false,
}
}
}06 sharding - Trace生成及分段
根据ExecutionRecord中各种Event信息,重新按照shard信息进行组织。对每一个shard的所有信息,枚举每一个芯片生成对应的trace信息。
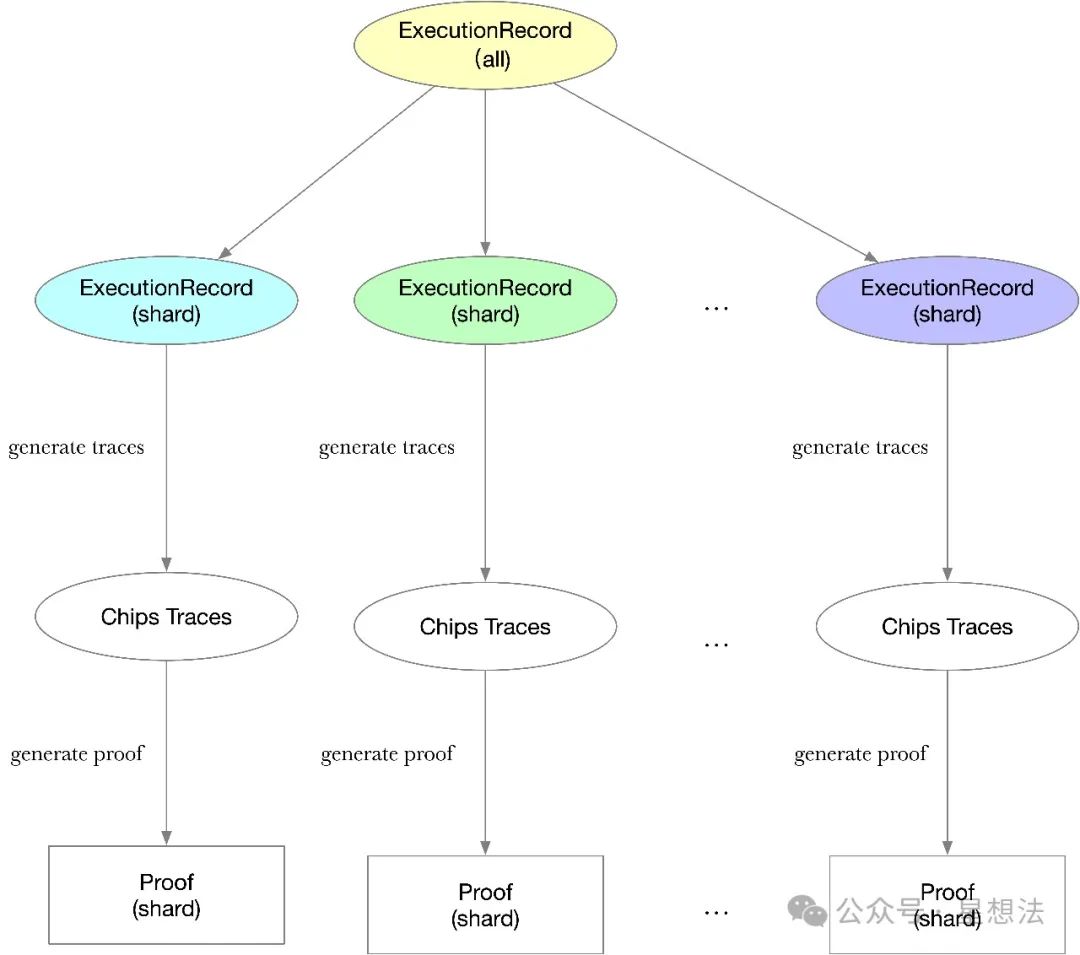
有了trace信息以及AIR的约束,就可以生成证明。prove_shard函数用来生成某一个shard的证明,定义在core/src/stark/prover.rs。
pub fn prove_shard(
config: &SC,
pk: &StarkProvingKey<SC>,
chips: &[&MachineChip<SC, A>],
mut shard_data: ShardMainData<SC>,
challenger: &mut SC::Challenger,
) -> ShardProof<SC>除了芯片互连的逻辑证明外,证明的核心算法大体和Plonky3类似(trace的多项式表示,承诺,打开)。到目前为止,每一个shard的证明证明了该shard中每一个芯片逻辑,芯片上的permutation计算以及芯片间的互连逻辑都正确。shard证明算法的详细代码,感兴趣的小伙伴可以自行查看源代码。
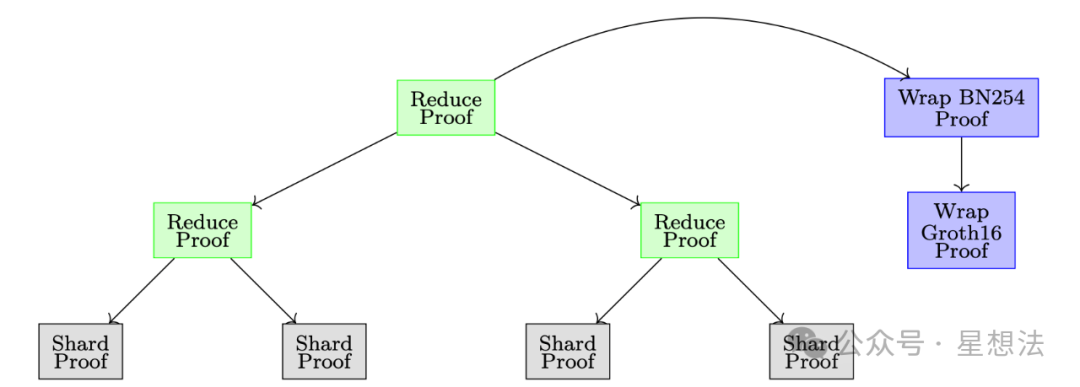
07. 递归证明
对于需要降低验证开销的场景,SP1提供了递归证明逻辑,将多个shard证明”压缩“成一个证明。该证明并可以进一步通过Groth16算法生成相应证明,便于链上验证。借用SP1设计框架和文档的图6:
总结
SP1是一款zkVM。SP1提供了工具链(toolchain)将rust代码编译生成ELF文件(RISC-V指令集)。按照芯片功能,SP1虚拟机由多个芯片组成:CPU,ALU,内存等等。在Plonky3的基础上,SP1增强了芯片间互连的AIR描述,并利用LogUp算法,实现了完整的基于RISC-V CPU的虚拟机约束描述。除此之外,内存的访问一致性问题,巧妙地转换成置换问题,同样通过LogUp算法实现。
参考资料:
2.SP1审计报告 https://hackmd.io/wztOd455QKWf-K8LXh_Fqw
3.RISC-V spec https://riscv.org/wp-content/uploads/2017/05/riscv-spec-v2.2.pdf
4.RISC-V reference https://www.cs.sfu.ca/~ashriram/Courses/CS295/assets/notebooks/RISCV/RISCV_CARD.pdf

星想法: 技术改变世界





