Eloizer 介绍:Solana 程序的静态分析器 - Inversive Labs
- inversive
- 发布于 2026-01-21 21:29
- 阅读 678
Eloizer 是一款用于 Solana 程序的静态分析工具,它通过解析 Rust 源代码来检测常见的漏洞模式,无需编译即可快速运行。文章介绍了 Eloizer 的架构、规则系统以及如何使用它,并讨论了源代码级别与编译器分析之间的权衡,展示了如何编写自定义规则以及使用 CLI。
Eloizer 简介:Solana 程序的静态分析器
这篇文章介绍了 Eloizer,我们构建并开源发布的 Solana 程序的静态分析器。
目录
简介
Eloizer 是一款用于 Solana 程序的静态分析器。它直接解析 Rust 源文件,无需编译,应用检测规则来查找常见的漏洞模式,并报告带有精确源位置的发现结果。该工具在大多数项目上的运行时间不到一秒,使其在开发期间使用成为可能。
我们构建 Eloizer 是因为我们需要一种快速、可扩展的方式来捕获 Solana 代码中的安全问题。它可以检测诸如缺少所有权检查、重复的可变账户和未检查的算术运算等问题。该工具包括一个用于编写自定义检测规则的 DSL,因此你可以添加特定于你项目的检查,而无需修改核心分析器。
这篇文章解释了 Eloizer 的工作原理:架构、规则系统以及如何使用它。我们将介绍源代码级别和基于编译器的分析之间的权衡,展示如何编写自定义规则,并演示 CLI 的用法。
动机
安全审计员在分析智能合约时会结合多种技术:手动代码审查以理解程序逻辑,模糊测试以发现意外行为,以及对关键属性进行形式验证。每种技术都有其权衡。
静态分析占据了一个特定的领域:快速、自动地检测已知的漏洞模式。它不会捕获所有的错误,你仍然需要动态分析和人工审查,但它可以立即捕获常见的错误。当集成到开发工作流程中时,它会在早期发现问题,此时修复成本较低。
我们构建 Eloizer 是因为当时 Solana 的开源静态分析选项很少。我们想要一个可以:
- 在开发过程中在本地运行,速度足够快以供迭代使用
- 以确定性结果集成到 CI 管道中
- 支持自定义规则而无需 Fork 分析器
- 为 IDE 集成提供精确的源位置
架构
Eloizer 的架构将关注点分离为不同的组件:
该架构有三个主要层:
- RuleEngine:管理规则注册和执行。规则可以按严重程度、ID 或类型(Anchor、Native 和其他框架)进行过滤。
- Analyzer:协调文件发现、解析和规则执行。
- DSL Layer:提供
AstQuery用于查询 AST,并提供RuleBuilder用于声明式地定义规则。
解析库
编译 Solana 项目通常需要 nightly 工具链、BPF 目标和很长的构建时间,这对于旨在在每次更改时运行的分析器来说太慢了。Eloizer 避免了编译器,并使用两个互补的 crate 直接读取源代码。
-
syn:基础解析层,将 Rust 源文件转换为结构化的 AST 表示形式 (syn::File)。启用full和visit功能后,它为所有 Rust 语法元素、impl块、表达式、属性、宏和源代码跨度提供自动遍历功能。这消除了手动访问者实现的需求,并构成了所有语法级别规则检测的基础。 -
anchor-syn:一个专门的层,用于解释 Anchor 框架结构。它处理过程宏,如#[derive(Accounts)]、#[instruction]和#[event],将它们转换为类型化的表示形式 (AccountInfo、Signer、UncheckedAccount)。此外,它还提取 Anchor 的约束元数据(is_signer()、has_one、seeds),否则这些元数据只能在运行时进行验证。
因此,Eloizer 使用 syn 解析项目一次以构建完整的 AST,并且只有需要 Anchor 语义的节点才委托给 anchor-syn。这种方法在保持速度的同时,保持了对宏及其约束的感知。
理解设计权衡
静态分析器面临着一个基本的架构决策:通过直接解析在源代码级别操作,或者与编译器集成以进行语义分析。这种选择既塑造了能力,也塑造了约束。
Eloizer 采用源代码级别的方法,使用 syn 和 anchor-syn 直接解析文件,而无需编译。Trail of Bits 的 solana-lints 是另一种选择的示例,它是一个使用 Dylint 的编译器插件,可在 rustc 本身中运行。
编译器集成方法
在 rustc 内部运行可以访问编译器的语义理解:
- 数据流跟踪:通过 MIR(中级中间表示)跟踪变量值通过赋值和控制流
- 类型解析:通过
rustc_middle::ty访问完整的 trait 实现和类型关系 - 路径分析:使用支配树分析证明安全检查在所有可能的代码路径上执行
- 行为理解:分析代码做什么,而不仅仅是它看起来如何
这些功能带有要求:nightly Rust 工具链、rustc-dev 组件、成功编译以及编译器内部的专业知识(LateLintPass、rustc_hir、clippy_utils)。
源代码级别解析
直接在源代码上操作提供了互补的优势:
- 近乎即时分析:无需构建延迟即可快速显示结果
- 无构建要求:完全避免了 Solana 程序的构建过程,无需特定的 nightly 工具链、依赖项差异或等待编译。当由于与要分析的代码无关的工具链问题而导致构建失败时,这一点尤其有价值
- 弹性:分析无法编译的不完整或损坏的代码
- 轻量级设置:标准的 Rust 工具链就足够了。无需 nightly 或编译器组件
- 平易近人的扩展:DSL 抽象了复杂性,使安全研究人员无需编译器知识即可编写规则
权衡是明确的:Eloizer 识别结构模式和缺失的代码元素,但无法执行完整的数据流分析或验证需要类型信息的语义属性。
设计依据
三个原则指导了我们的架构选择:
- 开发集成:亚秒级分析支持预提交Hook和实时编辑器反馈
- 左移安全:在最初编码期间、在尝试编译之前检测问题
- 社区贡献:降低安全研究人员添加检测功能的门槛
实际的区别在于每种工具何时提供价值:像 Eloizer 这样的源代码级别分析会在编写代码时立即捕获结构问题,而基于编译器的分析需要成功编译,但随后可以验证更深层次的语义属性。这两种方法都不是完全全面的,结构模式可以找到语义分析可能遗漏的漏洞,反之亦然。
分析管道
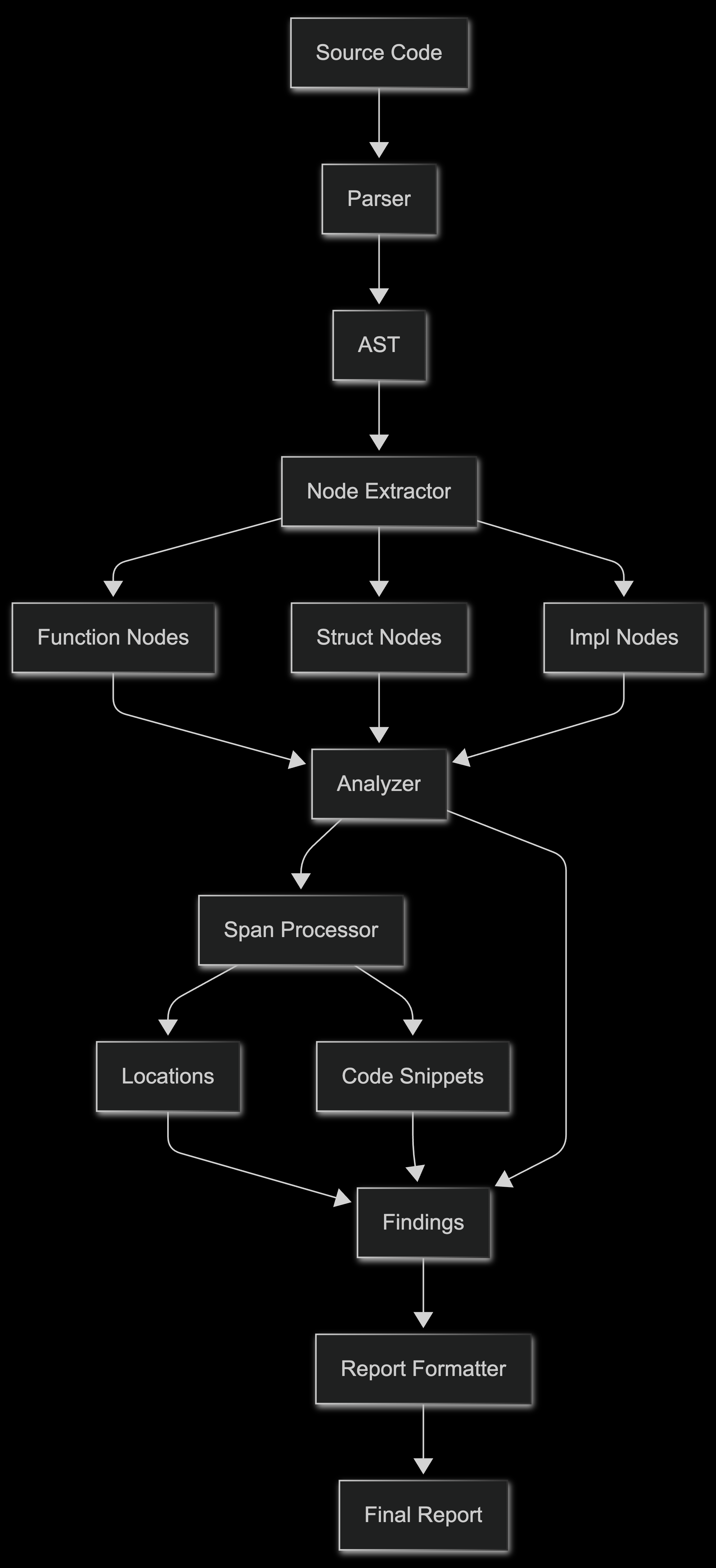
该管道通过六个阶段处理每个源文件:
1. 文件发现:Eloizer 遍历项目目录,识别 Rust 源文件 (.rs)。
2. 解析:使用 syn 解析每个文件。解析器生成一个 syn::File AST,其中包含完整的句法结构:项(函数、结构体、枚举、模块)、属性和表达式。
3. 节点提取:并非每个 AST 节点都与安全分析相关。DSL 的查询层提取特定的节点类型:函数(包括 impl 块中的函数)、结构体(尤其是带有 #[derive(Accounts)] 的结构体)和相关的属性。当一个结构体是 Anchor 特定的时,我们还会通过 anchor-syn 运行它,以在规则逻辑执行之前获得类型化的字段和约束元数据。这种提取是延迟发生的,因为规则会查询 AST。
4. 规则执行:每个注册的规则都针对解析的 AST 运行。规则使用 DSL 来表达查询,例如“查找包含除法运算的所有函数”或“查找具有重复可变引用的帐户结构”。该查询返回匹配的节点,这些节点将转换为发现结果。
5. 富化:原始发现结果需要上下文才能采取行动。SpanExtractor 组件将 AST 跨度映射回源位置(文件、行、列)并提取代码片段。这实现了精确的错误报告:
6. 报告生成:发现结果被格式化以供输出。CLI 支持带有严重性着色的终端输出、用于 CI 集成的静默模式和用于文档的 Markdown 导出。
领域特定语言
直接针对 syn 的 AST 类型编写检测规则需要手动实现访问者 trait 并处理遍历逻辑。考虑检测派生 Accounts 的结构体,而无需 DSL:
// 没有 DSL:手动访问者实现
struct AccountsStructVisitor {
findings: Vec<Finding>,
}
impl<'ast> Visit<'ast> for AccountsStructVisitor {
fn visit_item_struct(&mut self, struct_item: &'ast ItemStruct) {
// 检查结构体是否派生 Accounts
for attr in &struct_item.attrs {
if let Meta::List(meta_list) = &attr.meta {
if meta_list.path.is_ident("derive") {
let tokens = meta_list.tokens.to_string();
if tokens.contains("Accounts") {
// 现在检查字段是否有重复的可变字段
if let Fields::Named(fields) = &struct_item.fields {
let mut mutable_count = 0;
for field in &fields.named {
// 30+ 行的属性解析...
}
}
}
}
}
}
visit::visit_item_struct(self, struct_item);
}
}每个规则都会重复此样板:AST 遍历、模式匹配、跨度提取和结果格式化。我们构建了一个 DSL,通过将要检测的内容与如何遍历 AST 分离来消除这种重复:
// 使用 DSL:声明式查询
AstQuery::new(ast)
.structs()
.derives_accounts()
.has_duplicate_mutable_accounts()DSL 有两个核心组件:用于声明式规则定义的 RuleBuilder 和用于可组合 AST 查询的 AstQuery。
RuleBuilder:声明式规则定义
RuleBuilder 提供了一个流畅的 API 用于定义规则。无需实现 trait 和处理底层细节,你可以声明规则的元数据并提供一个查询来描述要查找的模式:
pub fn create_rule() -> Arc<dyn Rule> {
RuleBuilder::new()
.id("duplicate-mutable-accounts")
.severity(Severity::Medium)
.title("Duplicate Mutable Accounts")
.description("检测具有多个可变引用的帐户结构...")
.recommendations(vec![
"添加约束以确保帐户不同",
"使用 #[account(constraint = a.key() != b.key())]",
])
.dsl_query(|ast, _file_path, _span_extractor| {
AstQuery::new(ast)
.structs()
.derives_accounts()
.has_duplicate_mutable_accounts()
})
.build()
}dsl_query 闭包接收解析的 AST 并返回一个 AstQuery。当规则执行时,构建器会自动将匹配的节点转换为发现结果,附加规则的元数据、严重性、描述、建议,并通过 SpanExtractor 提取精确的源位置。作者专注于检测逻辑;基础设施处理发现结果生成。
AstQuery:可组合的 AST 查询
AstQuery 类型是 DSL 的主力。它包装了一个 AST 节点集合,并提供可链接的方法来过滤和转换它们:
pub struct AstQuery<'a> {
results: Vec<AstNode<'a>>,
}每个方法消耗当前查询并返回一个新查询,其中包含转换后的结果。这个函数式组合模式确保了不变性并实现了自然的链式调用:
AstQuery::new(ast)
.structs() // 提取所有结构体定义
.derives_accounts() // 仅保留 #[derive(Accounts)] 结构体
.has_duplicate_mutable_accounts() // 用于漏洞模式的自定义过滤器在内部,每个方法都迭代 self.results,应用其过滤逻辑,并使用过滤后的节点构造一个新的 AstQuery:
pub fn structs(self) -> Self {
let mut new_results = Vec::new();
for node in self.results {
if let NodeData::File(file) = node.data {
for item in &file.items {
if let Item::Struct(struct_item) = item {
new_results.push(AstNode::from_struct(struct_item));
}
}
}
}
Self { results: new_results }
}管道在每个步骤都急切地处理节点。这几乎就像对我们要寻找的内容的描述:“从 AST 中,找到派生 Accounts 并且具有重复可变帐户的结构体。”
该设计启用了两类过滤器:通用(内置于 AstQuery 中用于常见模式)和自定义(实现为扩展 trait 用于特定于域的逻辑)。
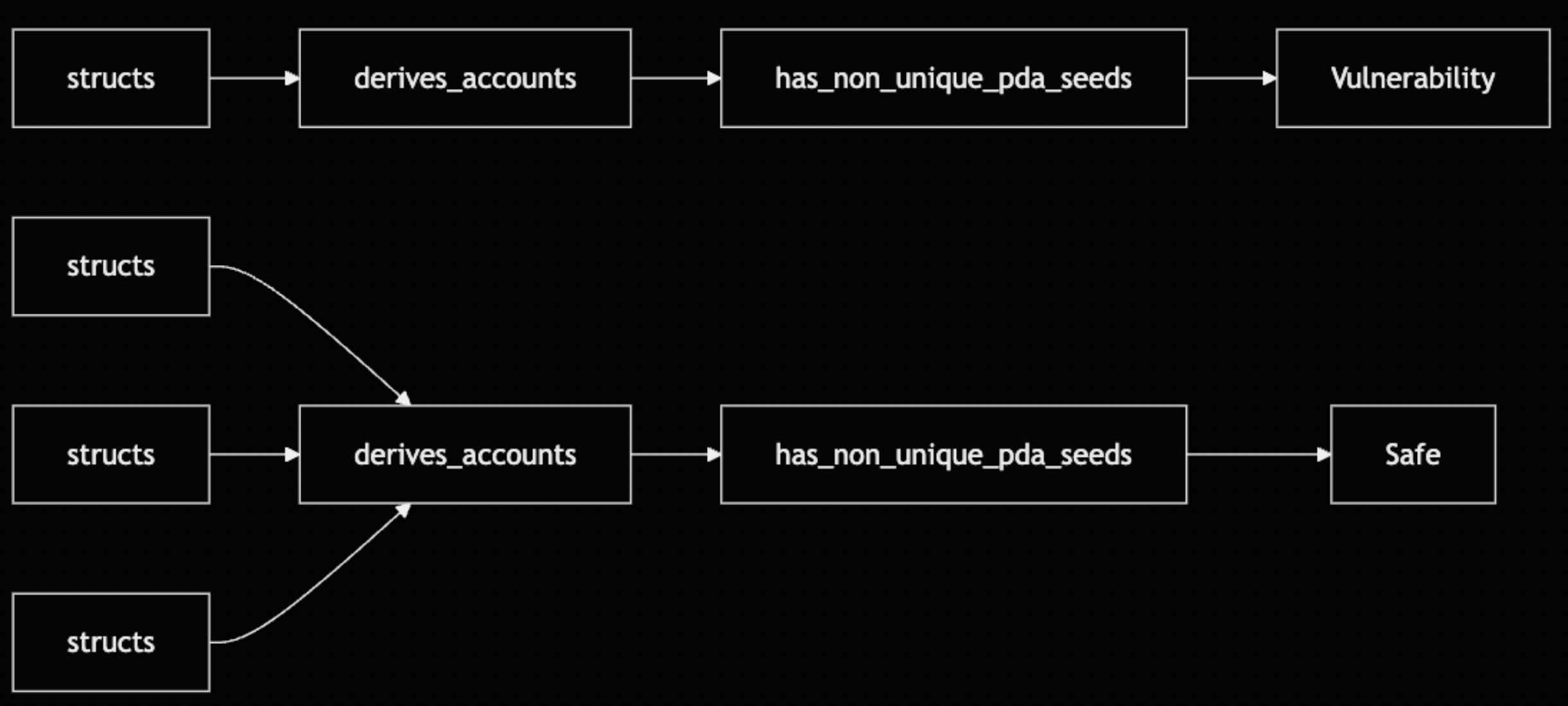
通用过滤器
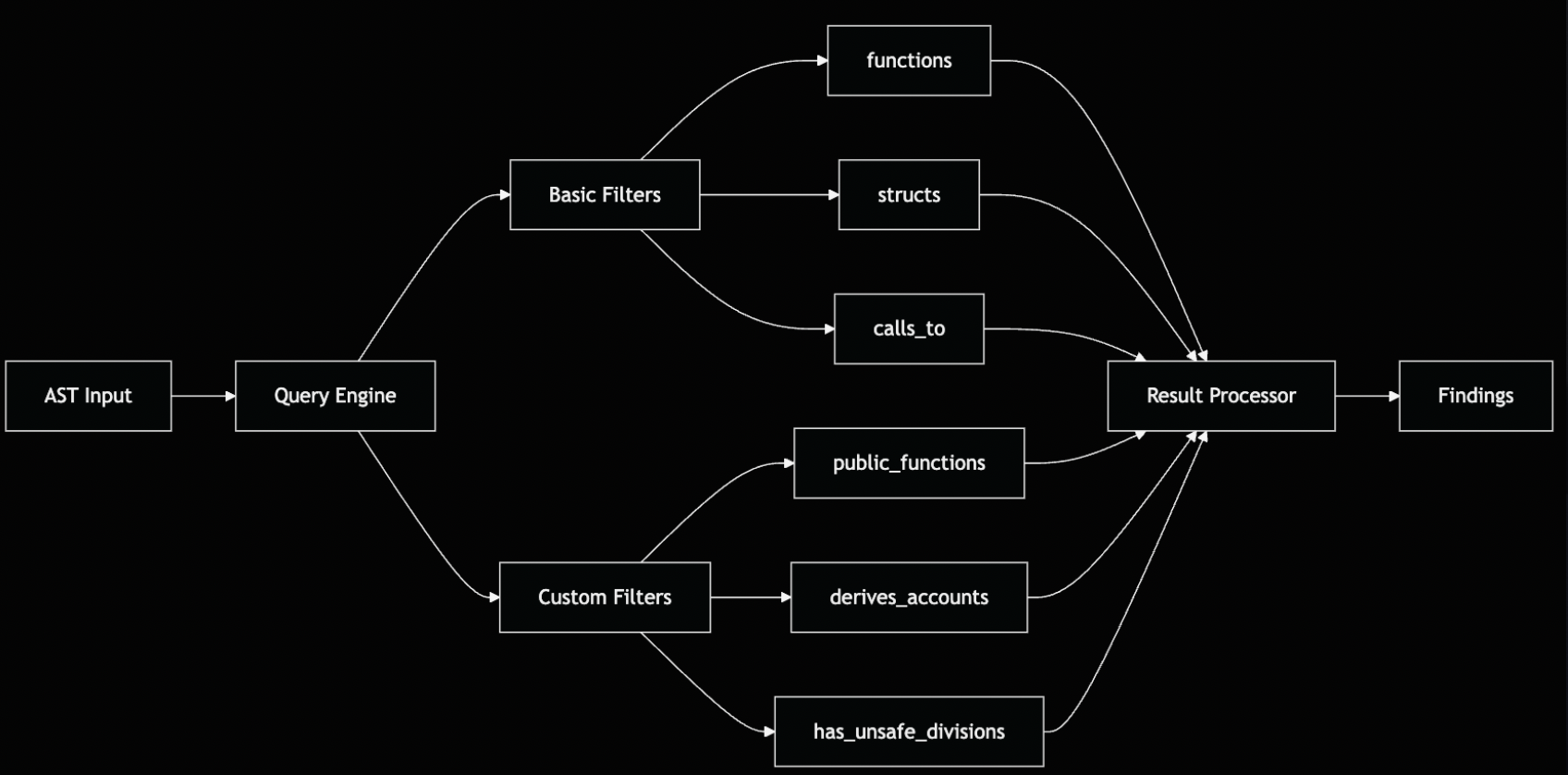
通用过滤器是 AstQuery 上的方法,用于处理常见的遍历模式。它们被实现一次并在规则中重复使用。
| 过滤器 | 描述 |
|---|---|
.functions() |
选择所有函数定义,包括 impl 块中的函数 |
.structs() |
选择所有结构体定义 |
.public_functions() |
过滤到具有 pub 可见性的函数 |
.with_name("foo") |
按标识符名称过滤节点 |
.calls_to("bar") |
查找包含对特定函数的调用的节点 |
.filter(predicate) |
应用自定义谓词函数 |
这些过滤器自然地组合在一起。例如,要查找所有调用 invoke 的公共函数:
AstQuery::new(ast)
.functions()
.public_functions()
.calls_to("invoke")
通用过滤器涵盖了大多数句法检测场景。它们纯粹在 AST 结构上操作,根据节点的形状匹配节点,而不了解 Solana 或 Anchor 语义。对于特定于域的逻辑,例如验证 Anchor 约束或跟踪变量赋值,需要自定义过滤器。
自定义过滤器
通用过滤器处理句法模式,但安全漏洞通常需要更深入的分析。自定义过滤器编码了解 Solana 和 Anchor 语义的特定于域的逻辑。
我们使用 Rust 的扩展 trait 模式来实现自定义过滤器。这使核心 AstQuery 保持通用,并与特定于 Solana 的逻辑解耦。每个规则都可以定义自己的 trait,其中包含为 AstQuery 实现的自定义方法,从而实现无缝链接:
// 将自定义过滤器定义为 trait
pub trait DuplicateMutableAccountsFilters<'a> {
fn has_duplicate_mutable_accounts(self) -> AstQuery<'a>;
}
// 为 AstQuery 实现 - 现在它可以自然地链接
impl<'a> DuplicateMutableAccountsFilters<'a> for AstQuery<'a> {
fn has_duplicate_mutable_accounts(self) -> AstQuery<'a> {
// 迭代结构体,计算可变帐户,检查约束
// 仅返回具有未受保护的重复可变帐户的结构体
}
}为什么使用扩展 trait 而不是 AstQuery 上的直接方法?
- 模块化:规则引入自己的逻辑,而无需修改核心 DSL
- 命名空间隔离:防止不同检测器之间的的方法名称冲突
- 可扩展性:用户可以添加自定义过滤器,而无需 Fork 分析器
这种模式实现了复杂的检测逻辑,同时保持了 DSL 的可组合性。自定义过滤器执行特定于域的分析:
- Anchor 属性解析:提取
#[account(...)]Token并验证保护模式(constraint、seeds、bump、key()比较) - 语义类型检查:将
syn::ItemStruct转换为anchor_syn::AccountsStruct,以便进行类型化的字段访问(Signer<'info>,AccountInfo<'info>)和约束元数据(is_signer(),has_one) - 变量跟踪:通过赋值跟踪定义,以确定除数是常量、参数还是可能为零的值
- 跨字段验证:检测双向约束,其中字段保护出现在另一个字段的属性中
基于 trait 的设计意味着规则可以自然地链接通用过滤器和自定义过滤器:.structs().derives_accounts().has_duplicate_mutable_accounts()。DSL 处理管道,过滤器作者专注于检测逻辑。
编写自定义规则
为了演示 DSL 如何实现复杂的漏洞检测,让我们检查一下 duplicate-mutable-accounts 规则。
漏洞模式
在 Anchor 程序中,单个指令中的多个可变帐户引用可能会在多次传递同一帐户时导致意外行为。考虑这个易受攻击的结构体:
##[derive(Accounts)]
pub struct Transfer<'info> {
#[account(mut)]
pub from: Account<'info, TokenAccount>,
#[account(mut)]
pub to: Account<'info, TokenAccount>,
pub authority: Signer<'info>,
}如果调用者为 from 和 to 传递相同的帐户,则程序将在同一帐户上执行借记和贷记。如果没有明确的约束来防止这种情况,程序的逻辑可能会产生不正确的结果。
安全版本强制执行唯一性:
##[derive(Accounts)]
pub struct Transfer<'info> {
#[account(mut)]
pub from: Account<'info, TokenAccount>,
#[account(
mut,
constraint = from.key() != to.key()
)]
pub to: Account<'info, TokenAccount>,
pub authority: Signer<'info>,
}规则实现
该规则使用 RuleBuilder 声明元数据并指定检测查询:
pub fn create_rule() -> Arc<dyn Rule> {
RuleBuilder::new()
.id("duplicate-mutable-accounts")
.severity(Severity::Medium)
.title("Duplicate Mutable Accounts")
.description(
"检测具有多个可变引用的帐户结构,
而没有确保唯一性的约束"
)
.recommendations(vec![
"添加约束:#[account(constraint = account1.key() != account2.key())]",
"对基于 PDA 的唯一性使用种子/ Bump 约束",
"在指令处理程序中实现显式验证",
])
.dsl_query(|ast, _file_path, _span_extractor| {
AstQuery::new(ast)
.structs()
.derives_accounts()
.has_duplicate_mutable_accounts()
})
.build()
}DSL 查询简洁明了:查找派生 Accounts 并且具有不受保护的重复可变帐户的所有结构体。复杂性在于自定义过滤器中。
自定义过滤器逻辑
has_duplicate_mutable_accounts 过滤器执行多遍分析:
pub trait DuplicateMutableAccountsFilters<'a> {
fn has_duplicate_mutable_accounts(self) -> AstQuery<'a>;
}
impl<'a> DuplicateMutableAccountsFilters<'a> for AstQuery<'a> {
fn has_duplicate_mutable_accounts(self) -> AstQuery<'a> {
self.filter(|node| {
if let NodeData::Struct(struct_item) = &node.data {
let mut mutable_account_count = 0;
let mut mutable_accounts_with_constraints = 0;
// 第一遍:收集所有约束表达式
let mut all_constraints = Vec::new();
if let Fields::Named(fields) = &struct_item.fields {
for field in &fields.named {
for attr in &field.attrs {
if let Meta::List(meta_list) = &attr.meta {
if meta_list.path.is_ident("account") {
let tokens = meta_list.tokens.to_string();
if tokens.contains("constraint") {
all_constraints.push(tokens);
}
}
}
}
}
// 第二遍:检查每个可变帐户
for field in &fields.named {
let mut is_mutable = false;
let mut has_protection = false;
for attr in &field.attrs {
if let Meta::List(meta_list) = &attr.meta {
if meta_list.path.is_ident("account") {
let tokens = meta_list.tokens.to_string();
if tokens.contains("mut") {
is_mutable = true;
}
// 检查保护性约束
if tokens.contains("constraint") ||
tokens.contains("seeds") ||
tokens.contains("bump") ||
tokens.contains("!=") ||
tokens.contains("key()") {
has_protection = true;
}
}
}
}
// 检查双向约束
if is_mutable && !has_protection {
if let Some(field_name) = &field.ident {
for constraint in &all_constraints {
if constraint.contains(&field_name.to_string())
&& constraint.contains("!=") {
has_protection = true;
break;
}
}
}
}
if is_mutable {
mutable_account_count += 1;
if has_protection {
mutable_accounts_with_constraints += 1;
}
}
}
}
// 漏洞:2 个或更多没有完整约束覆盖的可变帐户
mutable_account_count >= 2
&& mutable_account_count != mutable_accounts_with_constraints
} else {
false
}
})
}
}该过滤器执行三个关键检查:
- 属性解析:提取
#[account(...)]属性Token以标识可变帐户和约束 - 约束检测:识别保护模式,如
constraint = a.key() != b.key()、seeds和bump指令 - 双向验证:检查字段是否在其他字段的约束中引用,捕获
field_a受field_b上的约束保护的模式
这种多遍方法处理了约束可能出现在一对字段中的复杂场景,确保检测器最大限度地减少误报。
自定义过滤器封装了有关 Anchor 约束系统的特定于域的知识,同时与通用 DSL 操作保持可组合性。过滤器作者专注于漏洞逻辑、解析属性、验证约束、计算引用,而 DSL 基础设施处理 AST 遍历、结果收集和发现结果生成。
这种关注点分离使得编写复杂的检测器成为可能,而无需为每个规则重新实现样板代码。
精确的源位置
静态分析器的一个常见问题是模糊的错误位置。“第 50 行的漏洞”在实际问题跨越多行或隐藏在嵌套表达式中时没有帮助。Eloizer 为每个发现结果提供精确的源范围。
这种精度来自 syn 的跨度跟踪。每个 AST 节点都带有一个 Span,用于记录其在源中的确切位置:起始行、起始列、结束行、结束列。SpanExtractor 组件将这些跨度转换为可操作的位置:
这支持 IDE 集成(高亮显示确切的代码范围)、报告中的准确代码段以及在同一文件中存在多个漏洞时明确识别问题。
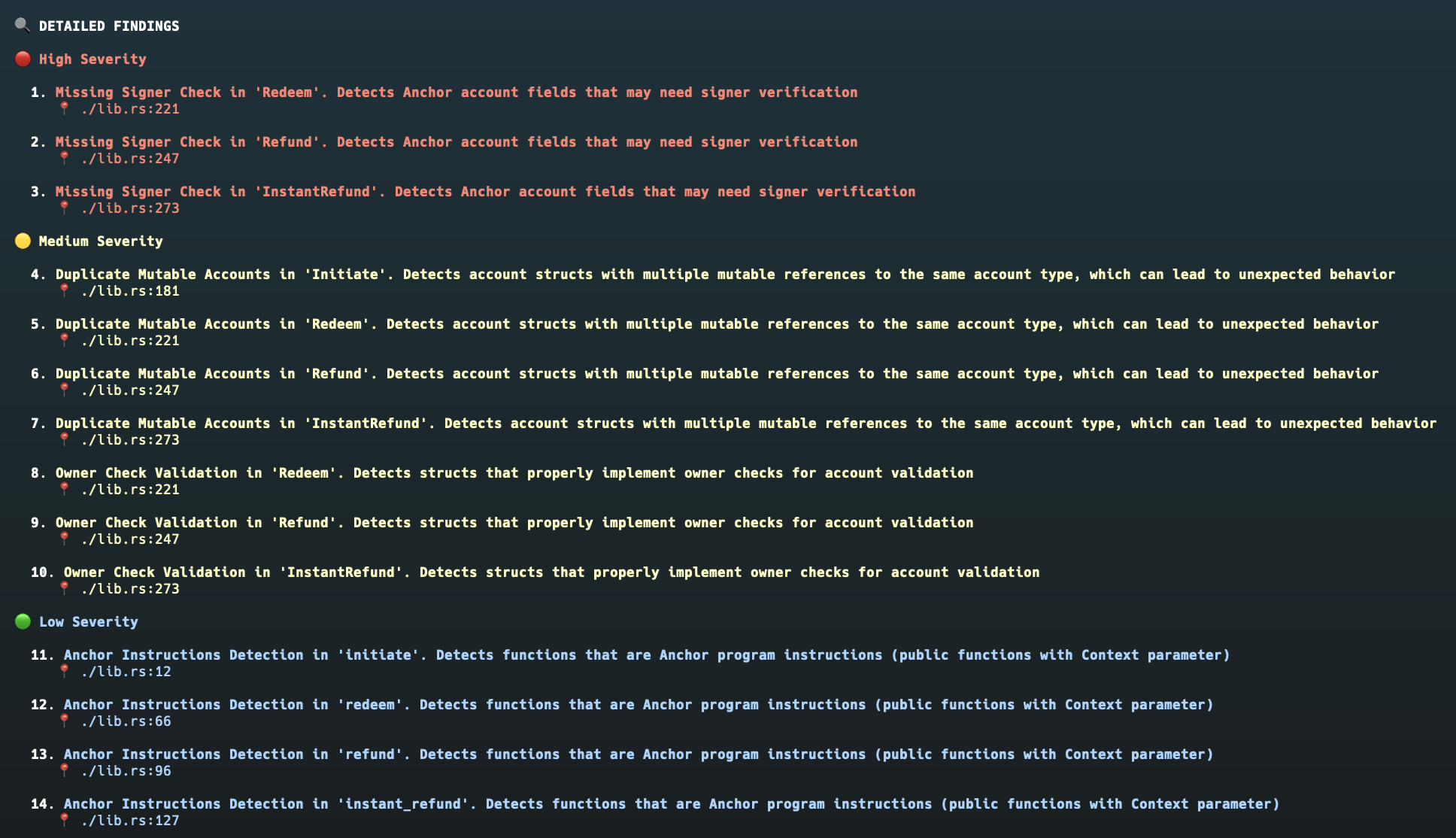
CLI
Eloizer 提供三个主要命令:
| 命令 | 描述 |
|---|---|
analyze |
对项目或文件运行安全分析 |
list-rules |
显示所有可用的检测规则 |
rule-info |
检查特定规则的详细信息 |
基本用法:
## 分析项目
eloizer analyze -p ./my-solana-project
## 列出可用规则
eloizer list-rules
## 将报告导出为 Markdown
eloizer analyze -p . -o report.md分析器生成一个摘要,其中包含按严重性分组的发现结果,以及终端或 Markdown 格式的详细报告:
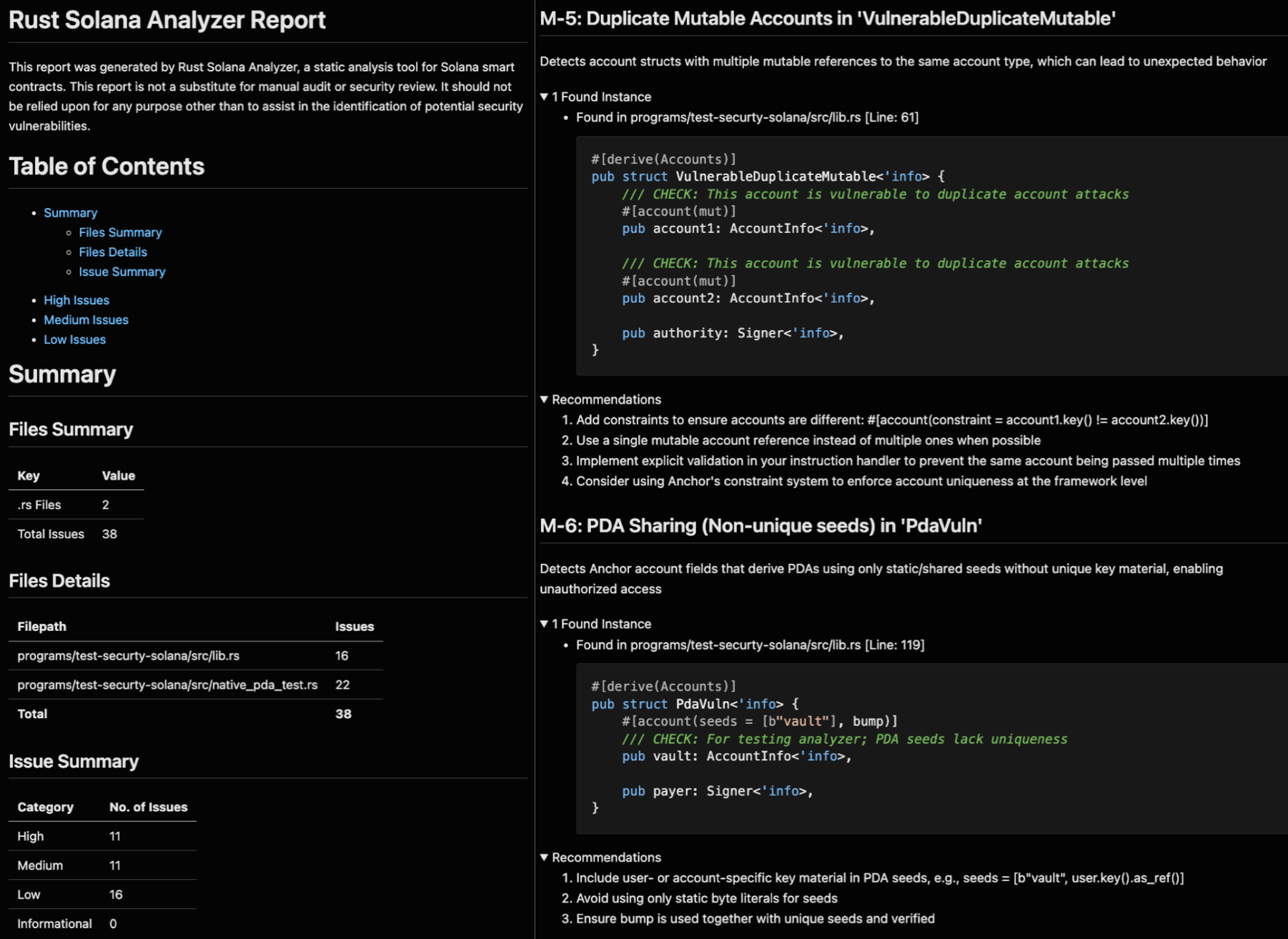
示例:Eloizer 实践
在 Solana 程序上运行 Eloizer 可以立即提供有关潜在漏洞的反馈。以下是分析输出的外观:
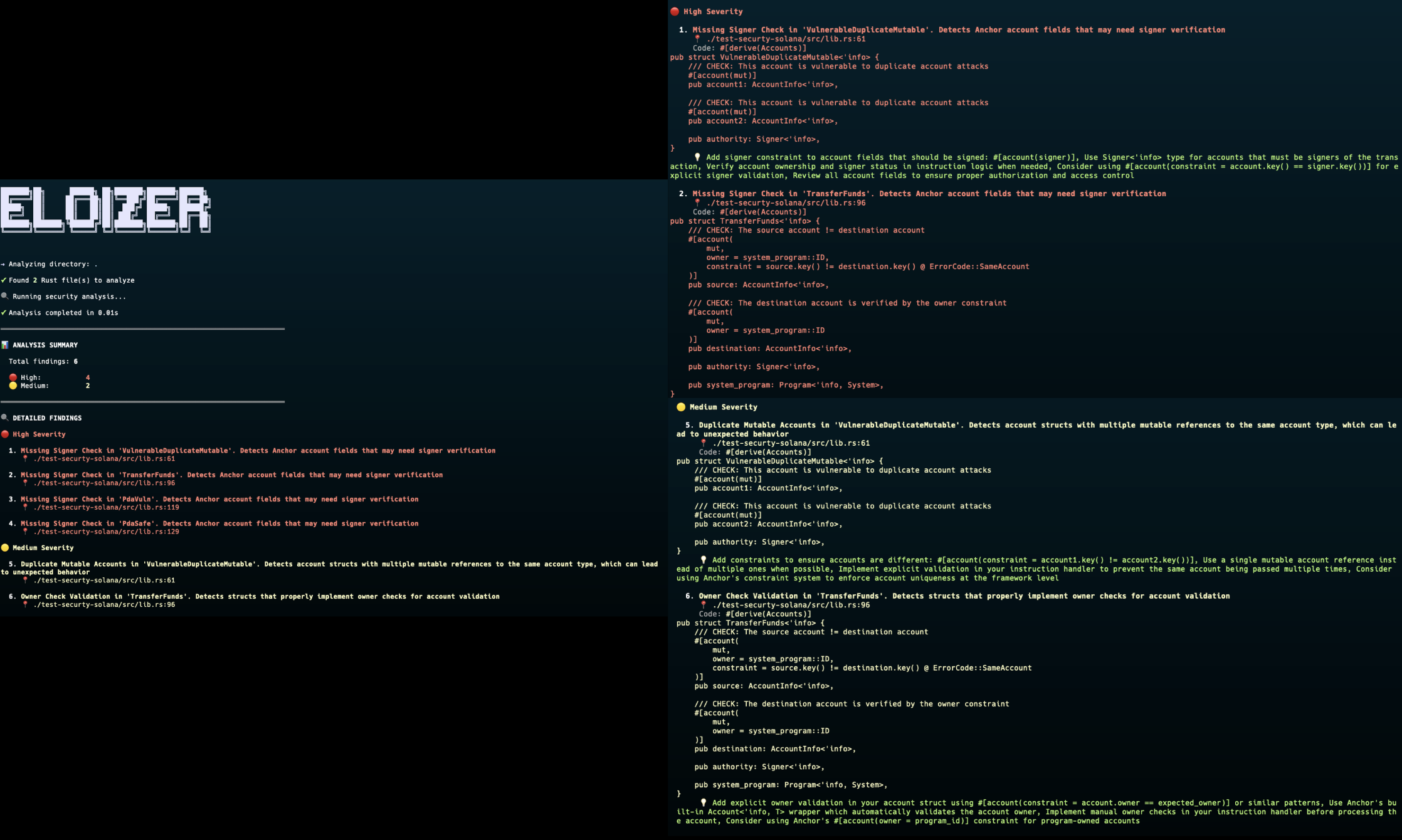
每个发现结果包括:
- 严重性分类:基于利用风险的高/中/低
- 精确位置:确切的文件路径、行和列
- 代码段:具有上下文的易受攻击的模式
- 可操作的建议:具体的修复建议
快速执行支持集成到预提交Hook和编辑器扩展中,在开发期间提供即时反馈。
Eloizer 可以检测什么?
Eloizer 附带了一组内置检测器,但真正的价值在于 DSL 的灵活性。该架构支持为任何可以表示为 AST 查询的模式编写规则。
一些自然适合的规则类别:
-
访问控制模式:缺少签名者检查、未经授权的帐户访问、通过未检查的所有权进行权限升级。
-
算术安全性:没有零验证的除法、未检查上下文中的溢出、Token计算中的精度损失。
-
帐户验证:重复的可变引用、缺少所有权检查、种子不足的 PDA 派生。
-
代码质量:未使用的错误结果、无法访问的代码路径、已弃用的 API 用法。
DSL 可以直接编码这些模式。如果你可以将漏洞描述为“查找缺少 Y 的 X”或“查找包含 Y 的 X”,则可以为其编写规则。未来的帖子将展示如何实现特定的检测器并根据你自己的需要扩展规则集。
局限性和未来改进
Eloizer 的设计通过源代码级别分析优先考虑速度和可访问性。这种方法实现了近乎即时的执行和零编译开销,但引入了我们正在积极解决的架构约束。
当前范围
按文件分析
目前,Eloizer 独立分析每个文件。这是故意的,它可以实现并行处理并避免编译依赖关系图。但是,某些漏洞模式跨越多个文件:
// validation.rs
pub fn validate_authority(account: &AccountInfo, signer: &Signer) -> Result<()> {
require!(account.owner == signer.key(), ErrorCode::Unauthorized);
Ok(())
}
// transfer.rs
use crate::validation::validate_authority;
pub fn transfer(ctx: Context<Transfer>) -> Result<()> {
validate_authority(&ctx.accounts.from, &ctx.accounts.authority)?;
// 验证发生在另一个文件中
transfer_internal(...)?;
Ok(())
}Eloizer 的按文件分析可能会标记 transfer 缺少所有者检查,因为验证逻辑位于单独的模块中。开发人员可以禁止这些发现结果或将验证重构为内联。
正在进行的增强
全程序符号索引
我们正在实施一个全局 AST 索引,它将解锁跨文件功能:
- 符号解析:跨模块跟踪函数定义和调用站点
- 导入分析:了解从何处调用哪些验证函数
- 跨模块模式:检测跨越文件边界的漏洞
这种增强功能将显着减少过程间模式的误报,同时通过增量索引保持速度优势。文件仅在更改时才重新索引,从而保留了快速反馈循环。
扩大检测范围
当前的规则集针对 Solana 审计中发现的最关键的漏洞类别。通过持续的开发:
- 新的漏洞模式:随着生态系统的发展,扩大对新兴攻击媒介的检测
- 框架支持:为 Native Solana 和 Anchor 以外的其他框架添加检测器
- 协议特定规则:为特定于项目的固定规则启用自定义检测器
每个新规则都利用 DSL 基础设施,这意味着实现工作重点在于检测逻辑而不是样板代码。当我们改进启发式方法并增加覆盖范围时,检测广度会增加,而不会牺牲分析速度。
设计权衡
架构决策反映了慎重的优先级:
- 速度支持工作流程集成:近乎即时的分析适合预提交Hook和编辑器扩展
- 无编译依赖:即使项目无法编译,分析也能正常工作,从而更早地发现问题
- 可扩展性高于内置完整性:DSL 允许用户编码特定于项目的模式,而无需 Fork 该工具
持续的增强功能,尤其是全程序索引,将扩展 Eloizer 的功能,同时保留使其适用于日常使用的特性。
未来功能
计划在短期内对架构进行两项重大改进:
-
中间表示 (IR):在 AST 和检测规则之间构建 IR 层将支持数据流和控制流分析。IR 将跟踪变量的生命周期、所有权转移以及跨函数边界的值传播。
-
Dylint 集成:Dylint 提供了一个框架,用于将自定义 lints 作为编译器插件运行,从而可以访问来自 rustc 的完整类型检查的 HIR(高级中间表示)和 MIR(中级中间表示)。集成将允许 Eloizer 在混合模式下运行:默认情况下使用快速 AST 分析,但在可用时利用编译器工件进行更深入的语义分析。
结论
Eloizer 是我们使静态分析对 Solana 开发实用化的一种方法。通过直接解析源文件而不是要求编译,它的运行速度足够快,可以在开发期间使用,而不仅仅是在 CI 中使用。DSL 使编写新的检测规则变得简单,而无需处理底层 AST 遍历。
设计优先级是明确的:
- 速度:亚秒级分析支持集成到开发工作流程中
- 可扩展性:过滤器系统允许用户添加检测功能,而无需修改核心代码
- 精度:确切的源位置减少了从发现到修复的时间
静态分析是深度防御策略中的一层。它不会捕获每个漏洞,你仍然需要动态分析、模糊测试和人工审查。但是它可以立即捕获常见模式,并在修复成本较低时发现问题。
Eloizer 是开源的。未来的帖子将深入探讨特定的检测器,并展示如何编写自定义规则,以及介绍新功能。
- 原文链接: inversive.xyz/blog/Eloiz...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





