原生 Solana :Borsh 序列化
- RareSkills
- 发布于 8小时前
- 阅读 58
本文详细介绍了Solana生态系统中Borsh序列化机制的工作原理。文章解释了序列化与反序列化的概念,Borsh作为Solana标准序列化格式的特点(确定性、紧凑性),以及如何处理固定长度和可变长度数据类型。同时,通过代码示例展示了如何在Solana Native程序中序列化和反序列化数据,并提及了手动读取数据和访问账户元数据的方法。
原生 Solana:Borsh 序列化
在之前的教程中,我们学习了如何读取传递给程序的账户。我们看到调用 account.try_borrow_data() 会将账户的 data 字段作为一个原始字节切片(例如 [0x01, 0x00, 0x00, 0x00])的引用。
Solana 将所有账户数据存储为字节。为了使用像 Rust 结构体这样的高级数据结构,我们使用序列化将结构体转换为字节,以便在链上存储,并在读取时将这些字节反序列化回结构体。Solana 使用 Borsh 作为其标准序列化格式。
本文解释了 Borsh 序列化如何工作以及如何解释这些原始字节。
在本教程中,我们将展示以下内容:
- 什么是序列化以及 Borsh 序列化在 Solana 中如何工作
- 如何读取和解释序列化的账户数据
- 当你尝试读取没有数据的账户时会是什么样子
什么是序列化和反序列化?
序列化是将数据结构(如 Rust 结构体或字符串)转换为可以存储或传输的字节序列的过程。反序列化是相反的过程——将这些字节转换回原始数据结构。
例如,如果你有一个计数器值为 42(存储为 u64)的结构体,序列化会将其转换为 8 个字节:[0x2A, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00]。第一个字节 0x2A 以小端序存储值的最低有效字节,其余 7 个字节为零,因为 u64 在内存中存储为 8 个字节。稍后,当你需要读取这些数据时,反序列化会将这些字节转换回你的结构体。
什么是 Borsh 序列化?
Borsh(用于哈希的二进制对象表示序列化器)是一种序列化格式,它定义了将 Rust 结构体转换为字节并返回的规则。Solana 使用 Borsh 作为其标准序列化格式,因为它具有以下特点:
- 确定性:相同的数据总是产生相同的字节(相同的字节也总是产生相同的数据)
- 紧凑性:它有效地存储数据,字段之间没有额外的元数据或填充(固定大小类型使用其标准字节大小,可变长度类型仅使用所需空间加上 4 字节的长度前缀)
borsh Rust crate 实现了 Solana 程序使用的序列化格式。
Solana 程序使用 Borsh 序列化指令数据和链上账户数据。对于账户,Borsh 将 Rust 结构体及其字段(字符串、整数、布尔值、向量等)转换为存储在账户的 data 字段中的原始字节。
Borsh 序列化如何工作
在原生 Rust 程序中,我们定义结构体来表示我们想要存储的账户数据(类似于你在 Anchor 中定义账户结构体的方式)。然后 Borsh 将这些结构体序列化为填充账户 data 字段的字节。序列化时,结构体字段在账户的 data 字段中按声明顺序连续排列。
基本流程如下图所示:

此图表显示:
- 序列化:你的 Rust 结构体(例如
CounterData { count: 42 })使用 Borsh 转换为原始字节 - 存储:这些字节存储在链上账户的
data字段中 - 反序列化:读取账户时,Borsh 将这些字节转换回你的结构体
Borsh 序列化后的 Solana 账户数据是什么样子的?
在 Anchor 中,序列化被抽象化了,但在原生 Rust 程序中,我们为结构体添加 #[derive(BorshSerialize, BorshDeserialize)] 属性。这会告诉 Borsh 库在编译时自动生成序列化和反序列化代码。
例如,这是一个 CounterData 结构体,它将计数器值存储为 u64:
#[derive(BorshSerialize, BorshDeserialize)]
pub struct CounterData {
pub count: u64,
}如果 count 值为 42,BorshSerialize 属性会将此结构体序列化为:

具体过程如下:
- Borsh 接收我们的计数器值(42)并将其转换为十六进制:十进制 42 = 十六进制
0x2A - 由于
count被定义为u64,Borsh 使用 8 个字节以小端序格式表示它 0x2A之后的 7 个字节为零,因为u64占用 8 个字节
Borsh 如何序列化可变长度数据
在查看更复杂的示例之前,让我们了解 Borsh 如何处理没有固定长度的数据类型,例如字符串和向量。
与 u64、bool 和 u8 等固定数据类型不同,它们无论值如何都使用相同数量的字节,String 和 Vec<T> 等可变长度数据类型的大小取决于其内容。
对于可变长度类型,Borsh 使用长度前缀:它首先写入数据的大小,然后是实际数据。这告诉 Borsh 在反序列化时需要读取多少字节(没有它,Borsh 将不知道一个字段在哪里结束,另一个在哪里开始)。
其工作原理如下:
- 首先,Borsh 将数据的长度以
u32(4 字节)的小端序格式序列化 - 然后,它序列化实际的数据字节
例如,如果我们有一个字符串“hi”:
- 首先,Borsh 将长度以
u32的小端序序列化:[0x02, 0x00, 0x00, 0x00](2 字节)。由于长度存储为u32,字符串的最大理论大小为2^32 - 1字节 - 最后,Borsh 序列化“hi”的实际 UTF-8 字节:
[0x68, 0x69]
这给我们带来了最终结果:
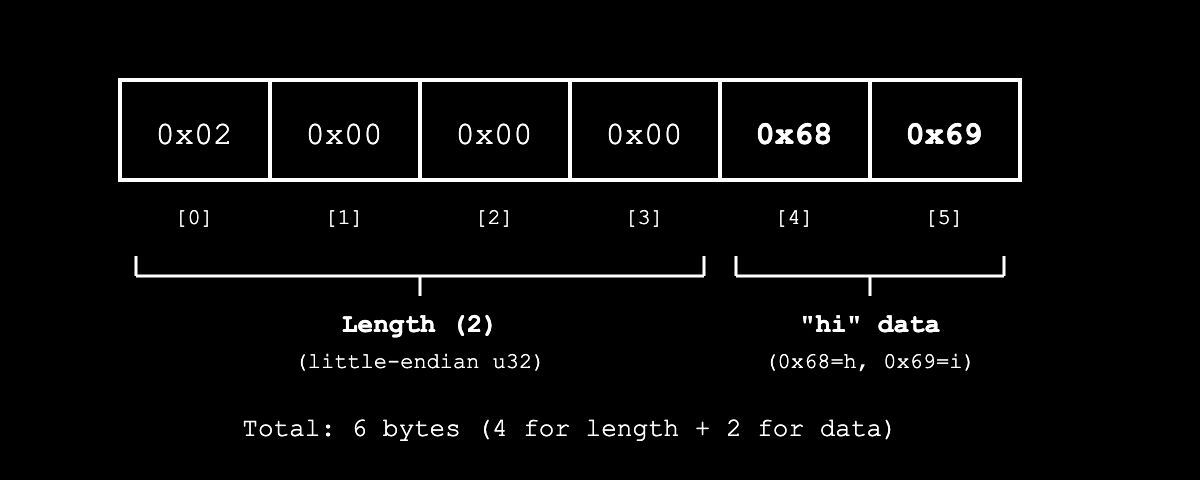
这个长度前缀有助于 Borsh 在反序列化时准确地知道可变长度类型需要读取多少字节。
如何序列化具有多个字段的 Solana 账户结构体?
假设我们有一个 UserData 结构体,包含多个字段来表示存储账户的用户信息:




