Tekton:大规模部署 AI 代理,面向下一代软件开发
- lambdaclass
- 发布于 2026-03-18 08:09
- 阅读 286
这篇文章介绍了 LambdaClass 公司如何利用 AI 代理提升软件开发效率。他们开发了一个名为 Tekton 的自托管平台,用于大规模运行 AI 代理,该平台利用 NixOS 和轻量级虚拟机提供隔离、可复现的开发环境,并集成了任务管理、成本跟踪和部署预览等功能,以确保在引入 AI 提高生产力的同时保持代码质量和安全性。
我们一直在 LambdaClass 密切关注人工智能的进展。在过去的几个月里,编码代理的质量飞跃令人印象深刻,这要求我们对软件开发方式进行根本性的重新思考。开发人员越来越倾向于使用像 Claude code、Codex 或 Kimi 这样的代理来完成他们的日常工作;曾经用于添加测试和审查代码等琐碎任务的工具现在正被用于完成整个功能甚至整个项目。
你可以在我们的 GitHub 上看到这些例子。Rust 库使用 AI 从头重写,并取得了令人印象深刻的成果;通过自动化设置中不断使用 Claude 为 ethrex 找到性能改进;回测软件在几天内用 Rust 重写,并添加了新功能;用 Lean 编写的形式化验证优化编译器;直接在浏览器上运行的 2D 和 3D 结构分析工具;这样的例子不胜枚举。
这些项目涵盖了从传统 SaaS 到低级 Rust 代码再到编译器的各种领域;AI 现在已经足够优秀,可以应对大多数软件。然而,这并不意味着它可以随意掌控我们的项目。它还不完美;它经常犯错,需要进行纠正。挑战在于利用 AI 提高我们的生产力,同时不牺牲质量或安全性;这需要让人类参与其中,提高我们工作的可见性,减少摩擦并增加防护措施,以便 AI 不会越界。
引入 Tekton
为了帮助实现这一切,我们开始着手开发一个用于大规模运行 AI 代理的自托管平台,名为 Tekton。受 Michael Stapelberg 关于在 NixOS 中运行编码代理的微型虚拟机的启发,我们着手创建基础设施,以自行启动轻量级、短暂的虚拟机。这为我们带来了:
- 一种简单、声明性的依赖处理方式,通过 nix 确保构建可重现并避免依赖地狱
- 一个防护措施,确保代理不能做任何危险的事情,并且只能访问其通过 VM 隔离被授予的环境
有了这个,任何人都可以从一个新想法开始,在一个隔离的环境中让代理在其上工作,并在几秒钟内将其部署到虚拟机上。在此基础上,我们建立了一个 Web 仪表板,供组织中的任何人使用并查看其他人正在进行的工作。这不仅适用于开发人员;产品经理和团队中其他非技术人员也可以使用它来尝试想法并获得关于其他人正在做什么的更好反馈。
下面的截图显示了我们仪表板上的“任务”选项卡。显示了来自用户的不同任务列表;每个任务都是其自己的实例,用户发送提示然后迭代一个功能。
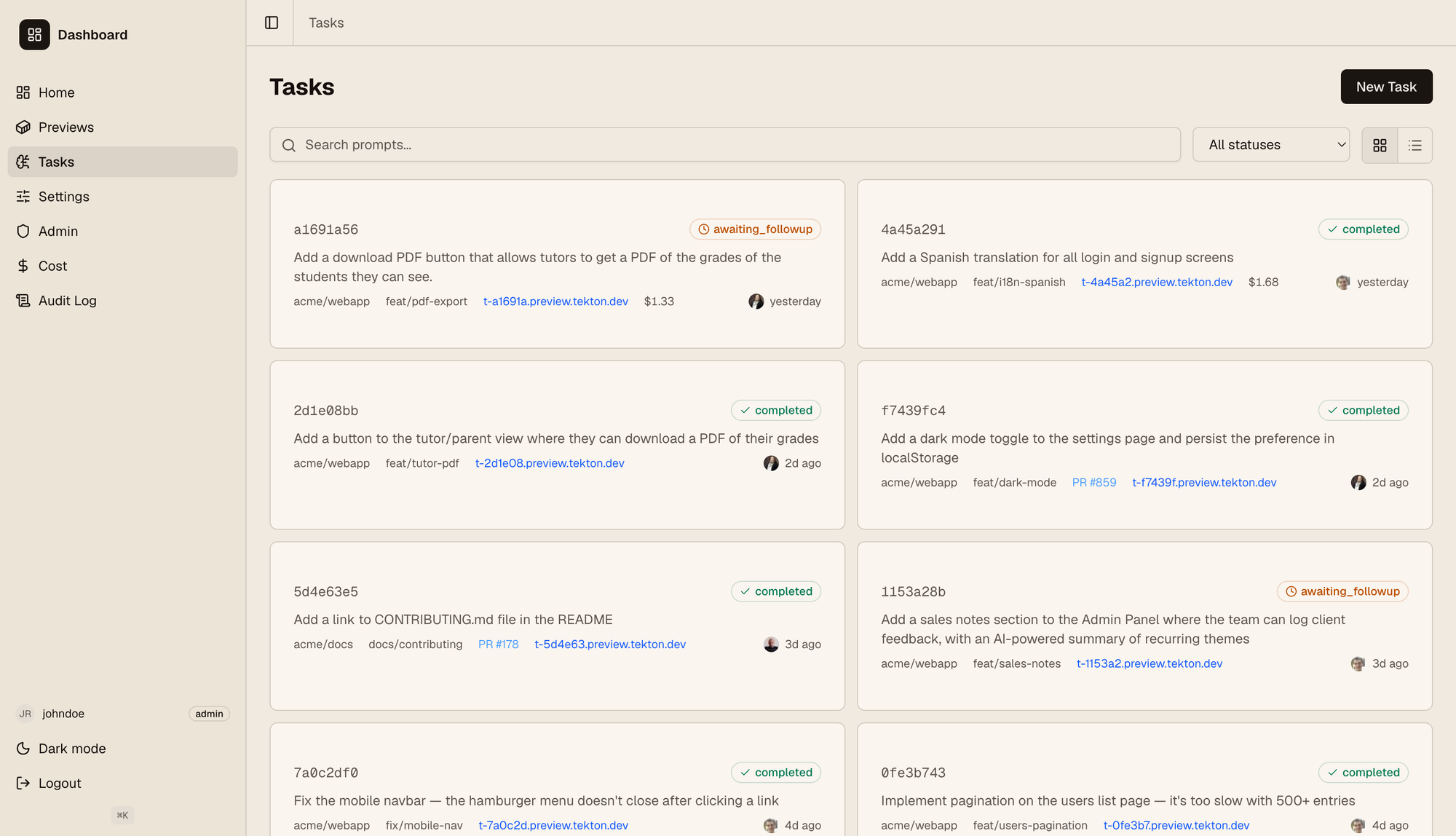
每个卡片上显示的链接都指向其部署的虚拟机,因此任何人都可以快速阅读提示,然后立即看到它的实际运行。从左侧可以看出,仪表板具有带有角色和权限的 RBAC 模型;用户拥有不同的权限,可能只能查看特定的仓库,拥有只读访问权限(即可以查看任务但不能与代理交互),等等。我们还跟踪每个用户的代理成本,并将其显示给管理员,以确保我们不会超支。我们使用 OpenRouter 开箱即用地支持不同的模型,用户可以从其设置选项卡中选择。
点击任务后,你将进入其详细信息页面,如下所示。
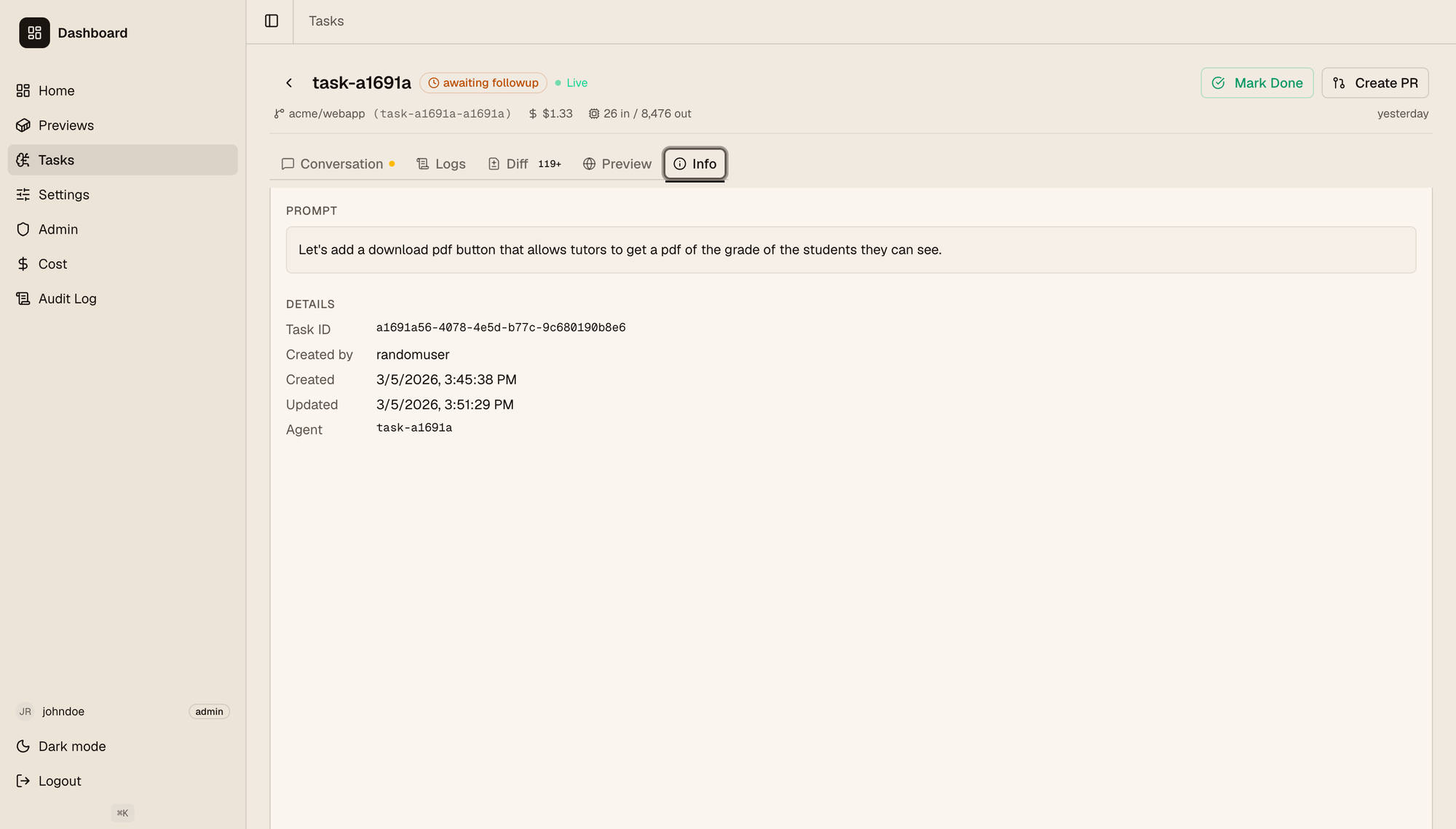
用户可以在这里查看:
- 与代理的完整历史对话。这是公开的,因此拥有适当权限的人可以跟进对话,并继续要求代理更改内容,向他们解释功能等。
- 完整的日志,包括部署功能的 VM 和代理 VM 的日志,你可以在其中查看完整的代理日志(不仅仅是对话)。
- 为给定功能在此分支上生成的代码差异。开发人员可以像在 GitHub 上一样查看它。
- “预览”选项卡带有一个嵌入的 iframe,其中包含部署的应用程序(如果是 Web 应用程序),以及一个链接,如果用户想在单独的选项卡中访问它。
- 截图中显示的信息选项卡。
功能完成后,可以直接从仪表板创建 PR。我们计划支持嵌入式审查,以便仪表板和 GitHub 保持同步,从而消除两者之间的来回切换。
技术深入探讨
Tekton 的架构可以在下图中看到:
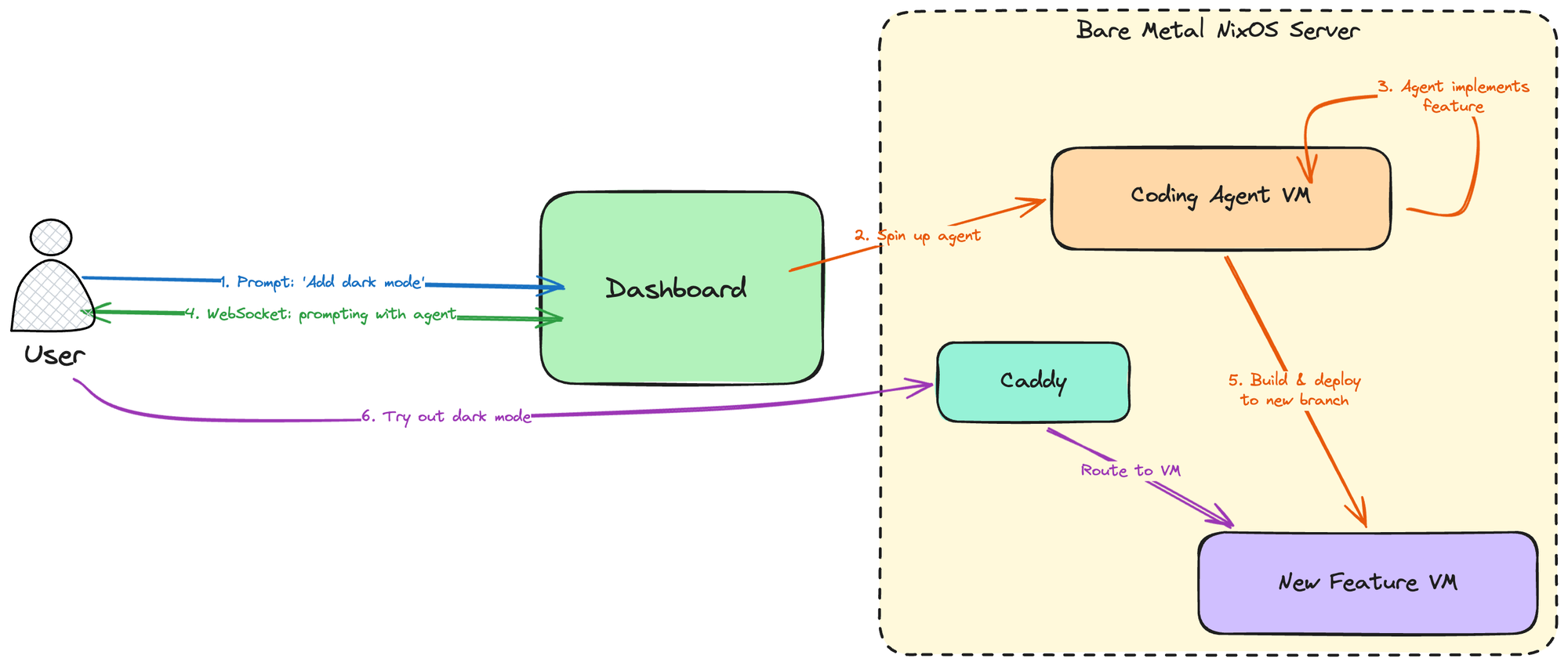
我们的裸金属服务器运行 NixOS,并使用 nspawn 容器(我们将来可能会切换到 nixos microvms 设置,但这足以满足我们目前的用例)来创建轻量级虚拟机,既用于编码代理,也用于部署用户所做的任何事情。用户与仪表板通信,仪表板是一个带有 Rust (Axum) 后端的 React 前端,然后管理 VM(用于编码和部署功能)的创建、销毁和通信。
当用户创建新任务(即发送他们想要尝试或构建的新功能的提示)时,仪表板会:
- 配置一个新的 VM 并在其中生成一个代理,该代理开始工作。
- 与用户建立 WebSocket 连接,以便他们可以查看代理的输出并与代理通信以进行任何所需的来回交互。
- 当代理完成时,它将功能推送到一个新分支,并在该分支上部署一个 VM。一个 Caddy 反向代理位于服务器和 VM 之间,为这个新 VM 分配一个新的子域名,Caddy 会相应地进行映射,然后用户可以在浏览器上访问他们部署的分支并尝试它。
此示例显示了典型 SaaS Web 应用程序的流程。其他用例有所不同,因为“部署”它们可能意味着完全不同的事情。例如,如果我们要使用它来尝试 ethrex 的优化机会,一旦代理完成,我们就不想将其部署在 VM 上,因为性能需要在专用服务器上的适当环境中进行测量。在这种情况下,我们可能会将其部署到所述专用服务器上,然后将用户指向那里。然而,Tekton 的核心流程保持不变。
Tekton 需要了解的关于它集成的每个仓库的一件事是它究竟意味着什么才能部署它。我们通过一个简单的 .nix 文件来实现这一点,仓库需要公开该文件,以便 Tekton 在部署时获取它以相应地构建仓库,公开适当的端口等。你可以在这里查看此文件对于 python webserver 的简单示例。除了告诉 Tekton 如何构建整个应用程序之外,其核心部分是:
## Caddy routing: most-specific path wins; "/" must be last.
## Add stripPrefix = true to strip the matched prefix before forwarding.
routes = [\
{ path = "/"; port = 8000; }\
];这告诉我们需要到达哪个端口才能进行内部 Caddy 路由,从而通过子域名将应用程序暴露给外部。
下一步计划
虽然这已经功能齐全,但它仍在开发中。由于 AI 开发是一种新范式,我们仍在摸索正确的工具来适当地利用它并发挥其最佳作用。因此,用户需求驱动 Tekton 的开发非常重要。如果我们的团队不使用 Tekton,那么它就毫无价值,因此迭代他们的反馈目前是首要任务。
当然,我们并非唯一从事此类工具开发的人。我们从 Ramp、Stripe、OpenAI 和许多其他公司那里汲取了想法。AI 软件开发的领域仍未被充分探索;尝试新想法,放弃无效的想法,并不断适应是提高我们生产力并保持领先地位的关键。
查看我们的仓库以获取更新:https://github.com/lambdaclass/tekton。
- 原文链接: blog.lambdaclass.com/tek...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





