使用初中数学从零开始理解 LLMs
- rohit-patel
- 发布于 2025-03-08 17:39
- 阅读 9
本文从零基础出发,深入解析了大语言模型(LLM)和 Transformer 架构的工作原理。内容涵盖了神经网络基础、模型训练、嵌入技术、分词器,以及自注意力机制、残差连接和层归一化等核心组件。最后,文章详细说明了如何将这些模块组合成 GPT 架构和完整的 Transformer 架构。
LLM 运行原理的完整自包含解释
在这篇文章中,我们将从零开始讨论大语言模型 (LLMs) 的工作原理——仅假设你知道如何对两个数字进行加法和乘法。本文旨在实现完全的自包含。我们首先从在纸笔上构建一个简单的 Generative AI 开始,然后逐步讲解深入理解现代 LLM 和 Transformer 架构所需的一切。本文将剥离 ML 中所有花哨的语言和术语,并简单地将一切呈现为它们的本质:数字。我们仍会标出这些事物的名称,以便你在阅读带有术语的内容时能够联系起来。
从加法/乘法过渡到当今最先进的 AI 模型,而不假设其他知识或参考其他来源,意味着我们要涵盖大量内容。这不是一个玩具级的 LLM 解释——一个有决心的人理论上可以根据这里的所有信息重建一个现代 LLM。我删减了每一个不必要的词句,因此这篇文章并不适合走马观花地浏览。
我们将涵盖哪些内容?
- 一个简单的神经网络
- 这些模型是如何训练的?
- 这一切是如何生成语言的?
- 是什么让 LLMs 表现得如此出色?
- Embeddings
- 子词 Tokenizers
- Self-attention
- Softmax
- 残差连接 (Residual connections)
- 层归一化 (Layer Normalization)
- Dropout
- Multi-head attention
- 位置嵌入 (Positional embeddings)
- GPT 架构
- Transformer 架构
让我们开始吧。
首先要注意的是,神经网络只能接收数字作为输入,也只能输出数字。没有例外。艺术在于如何将输入表示为数字,以实现目标的方式解释输出数字。最后,构建能够接收你提供的输入并给出你想要输出的神经网络(基于你为这些输出选择的解释)。让我们来看看我们是如何从数字的加减乘除演变到像 Llama 3.1 这样的模型的。
一个简单的神经网络:
让我们来看一个可以对物体进行分类的简单神经网络:
- 可用的物体数据: 主导颜色 (RGB) 和体积(单位:毫升)
- 分类目标: 叶子 (Leaf) 或 花 (Flower)
一片叶子和一朵向日葵的数据可能如下所示:
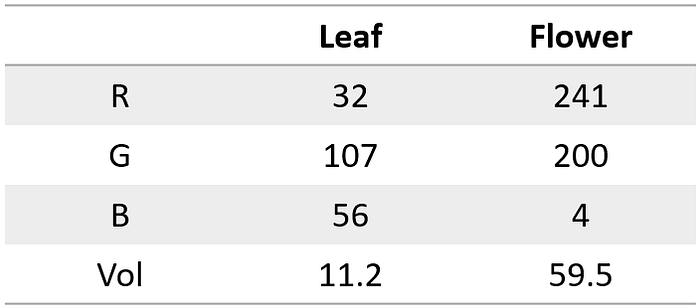
图片由作者提供
现在让我们构建一个执行此分类的神经网络。我们需要决定输入/输出的解释。我们的输入已经是数字,所以我们可以直接将它们喂入网络。我们的输出是两个物体:叶子和花,神经网络无法直接输出。让我们看看这里可以使用的几种方案:
- 我们可以让网络输出一个数字。如果该数字为正,我们说它是叶子;如果为负,我们说它是花。
- 或者,我们可以让网络输出两个数字。我们将第一个解释为叶子的数值,第二个解释为花的数值,并认为数值较大的那个即为选择。
两种方案都允许网络输出我们可以解释为叶子或花的数字。在这里我们选择第二种方案,因为它能很好地推广到我们稍后要看的其他事物。这是一个使用该方案进行分类的神经网络。让我们来看看它是如何运作的:
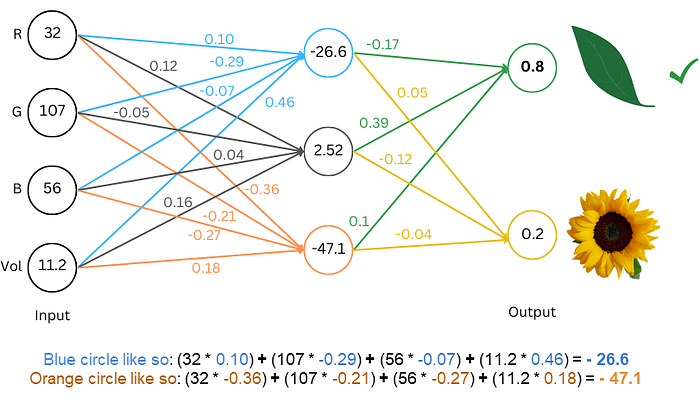
图片由作者提供
一些术语:
术语/节点 (Neurons/nodes):圆圈中的数字
权重 (Weights):线条上的彩色数字
层 (Layers):神经元的集合称为层。你可以认为这个网络有 3 层:包含 4 个神经元的输入层,包含 3 个神经元的中间层,以及包含 2 个神经元的输出层。
要计算这个网络的预测/输出(称为“前向传播 (forward pass)”),你从左侧开始。我们拥有输入层神经元的数据。要“向前”移动到下一层,你需要将圆圈中的数字与相应神经元配对的权重相乘,然后将它们全部相加。我们在上面展示了蓝色和橙色圆圈的数学计算。运行整个网络,我们看到输出层中的第一个数字更高,因此我们将其解释为“网络将这些 (RGB,Vol) 值分类为叶子”。一个经过良好训练的网络可以接收各种 (RGB,Vol) 输入并正确分类物体。
模型完全没有叶子或花的概念,也没有 (RGB,Vol) 的概念。它的任务是接收准确的 4 个数字并给出准确的 2 个数字。是我们解释了这 4 个输入数字是 (RGB,Vol),也是我们的决定去查看输出数字并推断如果第一个数字较大就是叶子,依此类推。最后,也取决于我们选择正确的权重,使得模型能接收我们的输入数字并给出正确的两个数字,以便在我们解释它们时得到我们想要的解释。
一个有趣的副作用是,你可以使用同一个网络,不输入 RGB,Vol,而是输入其他 4 个数字,如云量、湿度等,并将这两个数字解释为“一小时内晴天”或“一小时内下雨”,然后如果你校准好了权重,你可以让同一个网络同时做两件事——分类叶子/花和预测一小时内的降雨!网络只是给你两个数字,你是否将其解释为分类、预测或其他什么完全取决于你。
为了简化而略去的内容(可以忽略,不影响理解):
- 激活层 (Activation layer):这个网络缺失的一个关键点是“激活层”。这是一个花哨的词,意思是我们将每个圆圈中的数字带入一个非线性函数(RELU 是一个常用函数,你只需取该数字,如果它是负数则设为零,如果是正数则保持不变)。所以基本上在上面的案例中,在继续进行到下一层之前,我们会将中间层的两个数字($ -26.6 $ 和 $ -47.1 $)替换为零。当然,我们需要在这里重新训练权重以使网络再次有用。如果没有激活层,网络中所有的加法和乘法都可以合并为一个单层。在我们的例子中,你可以直接将绿色圆圈写成带有某些权重的 RGB 之和,而不需要中间层。它看起来会像 $(0.10 \cdot -0.17 + 0.12 \cdot 0.39 - 0.36 \cdot 0.1) \cdot R + (-0.29 \cdot -0.17 - 0.05 \cdot 0.39 - 0.21 \cdot 0.1) \cdot G$ ……等等。如果我们那里有一个非线性,这通常是不可能的。这有助于网络处理更复杂的情况。
- 偏置 (Bias):网络通常还会包含与每个节点关联的另一个数字,这个数字被简单地加到乘积中以计算节点的值,这个数字被称为“偏置”。因此,如果顶部蓝色节点的偏置是 $ 0.25 $,那么节点中的值将是:$(32 \cdot 0.10) + (107 \cdot -0.29) + (56 \cdot -0.07) + (11.2 \cdot 0.46) + 0.25 = -26.35$。术语“参数”通常用来指代模型中所有这些不是神经元/节点的数字。
- Softmax:我们通常不会像模型中显示的那样直接解释输出层。我们将数字转换为概率(即,使所有数字都为正且总和为 $ 1 $)。如果输出层中的所有数字已经是正数,实现此目的的一种方法是将每个数字除以输出层中所有数字的总和。尽管通常会使用“Softmax”函数,它可以处理正数和负数。
这些模型是如何训练的?
在上面的例子中,我们神奇地拥有了允许我们将数据输入模型并获得良好输出的权重。但这些权重是如何确定的呢?设置这些权重(或“参数”)的过程称为“训练模型 (training the model)”,我们需要一些训练数据来训练模型。
假设我们有一些数据,其中包含输入,并且我们已经知道每个输入对应的是叶子还是花,这就是我们的“训练数据 (training data)”,并且由于我们为每组 $(R, G, B, Vol)$ 数字都有叶子/花的标签,这就是“标记数据 (labeled data)”。
它的工作原理如下:
- 从随机数开始,即为每个参数/权重设置一个随机数。
- 现在,我们知道当我们输入对应叶子的数据($R=32, G=107, B=56, Vol=11.2$)时,假设我们想要输出层中代表叶子的数字更大。假设我们想要对应叶子的数字为 $ 0.8 $,对应花的数字为 $ 0.2 $(如上例所示,但这些是用于演示训练的说明性数字,实际上我们不会想要 $ 0.8 $ 和 $ 0.2 $。实际上这些会是概率,而这里不是,我们会希望它们是 $ 1 $ 和 $ 0 $)。
- 我们知道我们想要在输出层中得到的数字,以及我们从随机选择的参数中得到的数字(它们与我们想要的数字不同)。因此,对于输出层中的所有神经元,让我们计算我们想要的数字与我们拥有的数字之间的差异。然后将差异相加。例如,如果两个神经元中的输出层是 $ 0.6 $ 和 $ 0.4 $,那么我们得到:$(0.8 - 0.6) = 0.2$ 且 $(0.2 - 0.4) = -0.2$,所以我们得到总计 $ 0.4 $(在相加前忽略负号)。我们可以称之为我们的“损失 (loss)”。理想情况下,我们希望损失接近于零,即我们想要“最小化损失 (minimize the loss)”。
- 一旦我们有了损失,我们可以稍微改变每个参数,看看增加或减少它是否会增加损失。这被称为该参数的“梯度 (gradient)”。然后我们可以沿着损失下降的方向(梯度的反方向)将每个参数移动一小步。一旦我们稍微移动了所有参数,损失应该会更低。
- 不断重复这个过程,你就会减少损失,最终得到一组经过“训练”的权重/参数。整个过程被称为“梯度下降 (gradient descent)”。
几点说明:
- 你通常有多个训练示例,因此当你稍微更改权重以最小化一个示例的损失时,它可能会使另一个示例的损失变得更糟。处理这个问题的方法是将损失定义为所有示例的平均损失,并且
- 原文链接: medium.com/data-science/...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





