深入探讨 Solidity 库
- MarqyMarq
- 发布于 2023-02-03 21:28
- 阅读 1486
本文深入探讨了Solidity库的工作原理,详细介绍了如何使用delegatecall()调用库函数,以及如何创建和发布一个Solidity库。文章还讨论了库与智能合约的关键区别,并提供了多个代码示例来演示库的使用方法。
在本文中,我们将探讨 EVM 如何解释库,并通过一个示例演示如何创建一个库。
什么是库?
库类似于智能合约,但通常只部署一次。它们的代码通过利用 delegatecall() 被重用。这意味着代码的上下文是在调用合约中执行的。库函数不会在继承层次结构中显式可见。delegatecall() 的使用可以让我们访问调用智能合约的状态变量。然而,由于库是一段独立的代码,你必须提供状态变量以便库可以访问它们。
让我们来看一个例子:
pragma solidity^0.8.17;
library Lib {
// 将存储变量设置为新值
function changeState(uint256[1] storage changeMe) public {
changeMe[0] = 1;
}
}
contract C {
// stateVariable[0] 初始化为 0
uint256[1] stateVariable;
function callChangeState() external returns (uint256[1] memory, uint256[1] memory){
// 将状态变量存储到内存中,以便我们可以稍后返回
uint256[1] memory _oldState = stateVariable;
// 调用我们的库函数
Lib.changeState(stateVariable);
// 将我们的新状态变量存储到内存中,以便我们可以返回
uint256[1] memory _newState = stateVariable;
return (_oldState, _newState);
}
}以下是我们的输出:
_oldState[0]: 0
_newState[0]: 1
完美!这正是我们预期看到的。我们通过 delegatecall() 将传入的存储变量设置为不同的值。值得注意的是,当我们调用带有存储参数的库时,我们正在传递存储地址(指向存储变量的指针)。
如果你调用一个 view 或 pure 的库函数,你可以将该函数标记为 internal 而不是 public。这样做不会使用 delegatecall() 来调用函数。相反,代码会被包含在调用合约中。这意味着我们通过 JUMP 指令调用函数。JUMP 指令的成本仅为 8 gas,而 delegatecall() 的成本可能会有所不同。delegatecall() 的 gas 成本公式为:gas_cost = access_cost + memory_expansion_cost + gas_sent_with_call。delegatecall() 的成本会更高,因此我个人建议尽可能使用 internal 而不是 public。然而,在某些情况下,public 函数更适合。我们会在后面的文章中详细讨论这点。值得注意的是,当使用 internal 函数时,数据是通过引用传递给函数,而不是复制数据。
由于库的代码与合约是分开存储的,你可以使用以下代码获取地址:
function getLibraryAddress() external view returns(address) {
return address(Lib);
}此外,在部署时,你需要部署你的库并在智能合约中指定地址。以下是我们如何做到这一点。
const Lib = await ethers.getContractFactory("Lib");
const lib = await Lib.deploy();
await lib.deployed();
const YourContract = await ethers.getContractFactory("YourContract", {
libraries: {
Lib: lib.address
},
});
const yourContract = await YourContract.deploy();
await yourContract.deployed();在继续之前,让我们看一下库和智能合约之间的一些关键区别。
- 库中没有状态变量。
- 不允许与库进行继承。
- 库不能接收 Ether。
- 库不能被销毁。
函数签名与选择器
库在调用时不使用常规的智能合约 ABI。虽然类似,但有一些关键区别。主要区别在于库可以接受存储变量和递归结构体作为参数。对于结构体,你需要指定结构体的完全限定名称(例如,Contract Test { struct S {} } 将是 Test.S)。映射按照这种格式:mapping(<keyType> => <valueType>) storage。注意,括号与 storage 之间有一个空格。对于所有其他存储类型,你使用与非存储类型相同的标识符,但在其后加一个空格和“storage”。对于所有其他变量,你使用调用智能合约时获取函数签名时所用的标识符。
获取函数签名的最简单方法是使用以下代码:
function getSignature() external pure returns(bytes4) {
return Lib.changeState.selector;
}使用 For
库的一个不错的特性是 using x for y。这允许你将类型 y 附加到函数 x。第一个参数必须与要附加的类型匹配,否则编译器将抛出错误。你可以为一个类型指定多个函数,如 using { Lib.func1, Lib.func2 } for uint256。此外,你可以使用以下语法为所有类型指定一个完整的库 using Lib for *。这并不允许你在任何类型上调用任何函数。第一个参数的类型仍然必须与所使用的变量的类型匹配。这只是让你更方便,所以你不必一直使用 using x for y。让我们看一些例子。将以下函数添加到我们的库中。
function square(uint256 _val) public pure returns (uint256){
return _val * _val;
}现在在我们的合约 C 中,我们将添加这段代码。
using { Lib.square } for uint256;
function testUsing() external returns(uint256) {
return uint256(5).square();
}这里没有什么特别的,我们的输出将是 25,如预期的那样。让我们看看如果我们尝试将我们的库应用于所有变量会发生什么。
using Lib for *;
function testUsing() external returns(uint256) {
// 在 5 上调用 square()
uint256 callsSquare = uint256(5).square();
// 将我们的存储变量更改为 1
stateVariable.changeState();
// 抛出错误
stateVariable.square(); // 注释掉
return stateVariable[0] + callsSquare;
}如果你尝试以这种方式运行此函数,会得到错误提示,表示 square() 并不可见。这是因为我们正在将 square() 附加到一个不是 uint256 的变量上。好吧,现在让我们注释掉那一行,再次尝试运行它。太好了,输出是 26!我们得到它的方式是先平方5(25),然后将我们的状态变量更改为1并将它们相加。
本部分的最后一个主题是关于使用 global。global 允许我们将库附加到自定义数据类型(如结构体),即使合约位于不同的文件中。让我们看一个例子。首先假设我们有文件 globalTest1.sol:
pragma solidity^0.8.17;
// 我们的自定义数据类型
struct DataType {
uint256 var1;
uint256 var2;
}
// 我们对自定义数据类型进行操作的库
library Lib {
function sumDataType(DataType memory _data) internal pure returns (uint256) {
return _data.var1 + _data.var2;
}
}
// 将我们的库附加到这个自定义数据类型
using { Lib.sumDataType } for DataType global;
contract C1 {
// 文件内的简单函数,用于演示它有效
function getResult() external view returns(uint256) {
DataType memory data = DataType(1,2);
return data.sumDataType();
}
}同时假设我们有一个名为 globalTest2.sol的单独文件,如下所示。
pragma solidity^0.8.17;
// 仅导入我们的自定义数据类型
import { DataType } from "./globalTest1.sol";
contract C2 {
// 简单函数来验证它正常工作
function getResult() external view returns(uint256) {
DataType memory data = DataType(3,4);
return data.sumDataType();
}
}如果我们在两个合约中调用 getResult(),我们将获得以下输出:
C1.getResult(): 3
C2.getResult(): 7
请注意,我们只从 globalTest1.sol 中导入了我们的自定义数据类型。然而,由于我们将其全局附加,我们仍然可以使用我们的库。
这部分关于 use for 的内容到此为止。接下来,我们将开始了解如何创建我们自己的库!
编写一个库
为了确保在撰写本文之前我对库有充分的理解,我决定编写并发布我的第一个库。在本部分中,我们将讨论那个库,我根据我从编写第一个库中学到的内容所做的一些设计选择,以及如何将其作为 npm 包发布。
这是 GitHub 仓库的链接:https://github.com/marjon-call/memLibrary
此库重度使用 Yul。尽管我会描述代码的功能,但如果你想更好地理解 Yul,这里有我发布的一篇文章的链接:https://learnblockchain.cn/article/10872
库概述
如果你曾在 Solidity 中处理过内存数组,我相信你已经遇到过无法对其使用 push() 的情况。尽管没有明确地定义为固定大小数组,但内存数组不允许开发者执行与存储中的动态数组相同的操作。这个库解决了这一问题,允许用户在内存数组中 push(), pop(), insert() 和 remove() 元素。该库支持以下类型:uint8[] - uint256[], int8[] - int256[], address[], bool[] 和 bytes32[]。在本教程中,我们将只讨论 uint256 类型,但所有类型都以相同的方式工作。例如 myAddressArray.push(myAddress) 和 myUint256Array.push(myUint256) 都能工作。我们为什么能够为两种类型使用相同的名称,是因为函数签名看起来不同,因此没有冲突(例如,push(address[],address) 与 push(uint256[],uint256))。
让我们深入代码吧!
Push()
push(uint256[] memory arr, uint256 newVal) 接受要操作的内存数组和要追加到数组末尾的值作为参数。它返回一个数组,我们将其存储到代码中的旧数组中。以下是我们将用于 push() 的示例:
function testPush(uint256[] memory arr) external pure returns(uint256[] memory) {
arr = mem.push(arr, 4);
return arr;
}我将传入数组 [0, 1, 2, 3],我们将看到它返回 [0,1,2,3,4]。现在让我们看看代码!
// 允许用户向内存数组中添加值
function push(uint256[] memory arr, uint256 newVal) public pure returns(uint256[] memory) {
assembly {
// 数组存储在内存中的位置
let location := arr
// 数组的长度存储在 arr 中
let length := mload(arr)
// 获取下一个可用的内存位置
let nextMemoryLocation := add( add( location, 0x20 ), mul( length, 0x20 ) )
let freeMem := mload(0x40)
// 增加 msize()
let newMsize := add( freeMem, 0x20 )
// 检查内存中是否有额外变量
if iszero( eq( freeMem, nextMemoryLocation) ){
let currVal
let prevVal
// 通过向其他内存变量的位置推进 0x20(32 字节)为 _newVal 腾出空间
for { let i := nextMemoryLocation } lt(i, newMsize) { i := add(i, 0x20) } {
currVal := mload(i)
mstore(i, prevVal)
prevVal := currVal
}
}
// 将新值存储到内存中
mstore(nextMemoryLocation, newVal)
// 将长度增加 1
length := add( length, 1 )
// 存储新长度值
mstore( location, length )
// 更新自由内存指针
mstore(0x40, newMsize )
}
return arr;
}此函数中的第一件事情是我们获取内存中数组的位置。在这种情况下,它将位于内存位置 0x80。接下来,我们通过从内存中加载该位置来获取数组的长度。这将返回 4。现在我们知道接下来的四个内存位置将用于存储我们的数组。然而,我们需要一个无论数组大小如何都能工作的方程。我们需要将我们的地址加 0x20(这使我们在数组的第一个元素前进 32 字节)。接着,我们将数组的长度(存储在 0x80 的值)乘以 32 字节。然后将这两个数字相加。现在,我们将数组的下一个内存位置存储在 nextMemoryLocation 中。接下来,我们需要找出内存中是否有其他变量。我们这样做是因为我们不希望覆盖任何其他变量。这是通过加载自由内存指针 (0x40) 来实现的。由于我们计划向内存中添加一个新变量,我们还希望创建一个新栈变量,它跟踪我们在添加新变量到内存之后的自由内存指针(newMsize)。现在我们检查自由内存指针是否等于我们数组的下一个内存位置。如果是这样,我们就可以不必担心覆盖内存变量。在我们的示例中,我们不必担心这一点。如果确实有其他内存变量,则我们将遍历现有的内存位置并将每个变量存储到下一个内存位置。最后,我们可以存储我们新的内存变量。接着,我们需要更新数组的长度并存储该值。最后,我们需要更新我们的自由内存指针,以便 Solidity 知道不要覆盖我们最后存储的内存位置。现在我们可以返回我们的新数组。
让我们看看函数调用结束时的内存布局。
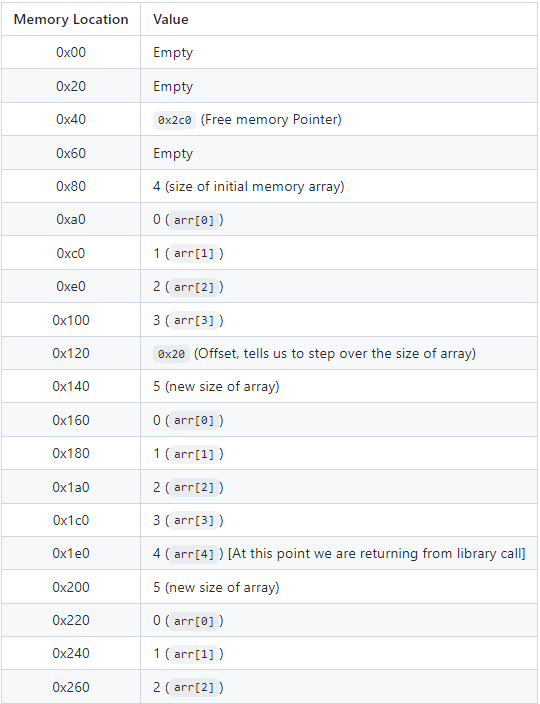
内存中现在发生了很多事情,让我们来回顾一下发生了什么。我们将原始数组存储到内存中。然后,我们需要通过 delegatecall() 调用我们的库。在那里,我们格式化我们的新数组并返回它。请记住,return 使用内存,由于我们在使用 delegatecall(),内存的上下文是在调用合约中的。我们现在将新的数组存储在 testPush() 的内存中。最后,我们返回我们的新数组,最后一次使用内存。
那么,显然,我们消耗了大量内存。如果我们将 push() 函数从 public 改为 internal 会发生什么?
尝试一下,这次像这样调用我们的库:
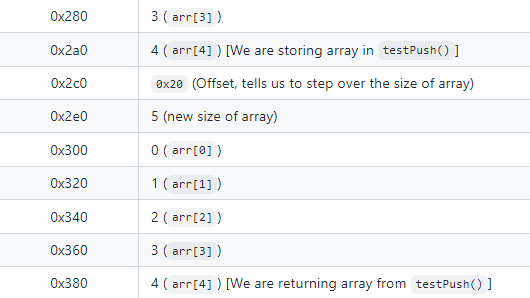
mem.push(arr, 4);让我们查看在这种情况下的内存。
我们大大减少了内存消耗,因为我们不需要存储我们的新数组变量或返回这么多数据。显然,这是一个更好的选择,对吧?其实,在仅有一个内存变量的情况下,这可能会更好,但让我们将函数更改为添加另一个内存变量,看看会发生什么。以下是我们的新 testPush():
function testPush(uint256[] memory arr) external pure returns(uint256[] memory, uint256[] memory) {
uint256[] memory arr2 = new uint256[](1);
arr2[0] = 100;
mem.push(arr, 4);
return (arr, arr2);
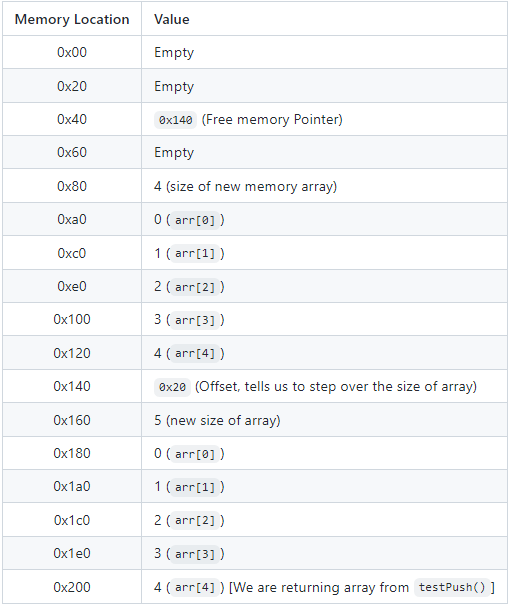
}在这个例子中,我们在内存中存储了另一个数组。它将在我们希望操控的数组之后存储,因为我们要操纵的数组是从我们参数中首先分配到内存中的。然后我们返回两个数组。
让我们看看输出:
arr: [0,1,2,3,4]
arr2: [1, 100, 64, 256]
所以 arr 看起来很不错!但是 arr2 看起来有点不对。我们原本期望 [100]。为什么会这样?内部调用不会在我们调用的函数的上下文中执行。因此,当我们告诉函数返回 arr2 时,它会查看先前定义的内存位置。我们刚刚将该位置覆盖为数组 arr 的最后一个元素(4)。因此现在返回的 arr2 的数组大小为 4。尽管 internal 函数节省了内存分配,但并没有提供我们所需的功能,因此我们必须使用 public 函数来处理我们的库。考虑到这一点,让我们看看我们库中的其他函数。
Pop()
与 push() 类似,pop() 操作数组的末尾。然而,替代地,我们将删除数组的最后一个元素。让我们看看我们的代码。
// 从数组中删除最后一个元素
function pop(uint256[] memory arr) public pure returns (uint256[] memory){
assembly {
// 数组存储在内存中的位置
let location := arr
// 数组的长度存储在 arr 中
let length := mload(arr)
let freeMemPntr := mload(0x40)
let targetLocation := add( add( location, 0x20 ), mul( length, 0x20 ) )
for { let i := targetLocation } lt( i, freeMemPntr ) { i := add( i, 0x20 )} {
// 将下一个变量存储到当前内存位置
let nextVal := mload( add(i, 0x20 ) )
mstore(i, nextVal)
}
// 更新并存储新长度
length := sub( length, 1 )
mstore(location, length)
}
return arr;
}像上次一样,我们获取数组的位置和长度。我们还获取内存中下一个可用空间的指针。然后,我们计算需要删除的元素的位置。接着,我们循环,从需要删除的元素开始,直到我们在内存中的最后一个位置。在循环中,我们将下一个值存储在当前内存位置。最后,在返回新的数组之前,我们更新长度并存储它。
Insert()
insert() 允许我们在数组的指定索引处存储一个新值。以下是代码。
// 在数组的索引处插入元素
function insert(uint256[] memory arr, uint256 newVal, uint256 index) public pure returns(uint256[] memory) {
assembly {
// 数组存储在内存中的位置
let location := arr
// 数组的长度存储在 arr 中
let length := mload(arr)
// 获取下一个可用的内存位置
let nextMemoryLocation := add( add( location, 0x20 ), mul( length, 0x20 ) )
// 自由内存指针
let freeMem := mload(0x40)
// 增加 msize()
let newMsize := add( freeMem, 0x20 )
// 我们希望插入元素的位置
let targetLocation := add( add( location, 0x20 ), mul( index, 0x20 ) )
let currVal
let prevVal
for { let i := targetLocation } lt( i, newMsize ) { i := add( i, 0x20 )} {
currVal := mload(i)
mstore(i, prevVal)
prevVal := currVal
}
// 将新值存储到内存
mstore(targetLocation, newVal)
// 将长度增加 1
length := add( length, 1 )
// 存储新长度值
mstore( location, length )
// 更新自由内存指针
mstore(0x40, newMsize )
}
return arr;
}与 push() 一样,我们获取 location、length、nextMemoryLocation、freeMem 和 newMsize。像 pop() 一样,我们获得 targetLocation。然后从 targetLocation 开始,我们循环到 newMsize,将每个值替换为前面的值。在存储新值后,我们更新数组的长度,然后更新自由内存指针,可以返回新数组。
remove()
我们的库的最后一个函数是 remove()。它允许我们从数组中删除指定索引的元素。以下是 remove() 的代码。
// 从数组的索引处移除元素
function remove(uint256[] memory arr, uint256 index) public pure returns (uint256[] memory){
assembly {
// 数组存储在内存中的位置
let location := arr
// 数组的长度存储在 arr 中
let length := mload(arr)
// 自由内存指针
let freeMemPntr := mload(0x40)
// 要移除的元素的位置
let targetLocation := add( add( location, 0x20 ), mul( index, 0x20 ) )
for { let i := targetLocation } lt( i, freeMemPntr ) { i := add( i, 0x20 )} {
let nextVal := mload( add(i, 0x20 ) )
mstore(i, nextVal)
}
length := sub( length, 1 )
mstore(location, length)
}
return arr;
}我们再次获得 location、length、freeMemPntr 和 targetLocation。现在我们从 targetLocation 开始循环,直到 freeMemPntr,并将前一个值存储在当前内存位置。最后,我们可以更新并返回新的数组。
发布我们的库
现在我们已经完成了库的编写,我们可以通过 npm 发布我们的作品。第一步是确保我们在命令行中进入代码所在的文件夹。接下来,如果我们还没有这样做,我们需要创建一个 package.json。可以使用以下命令完成此操作:
npm init -y
现在,我们有了 package.json。我们需要通过以下命令登录或创建一个 npm 帐户。
npm login
最后,我们可以通过以下命令发布我们的库:
npm publish
恭喜你!你现在知道如何使用 Solidity 创建和发布库!
这篇关于 Solidity 库的文章到此结束。
这里是关于库的 Solidity 文档:https://docs.soliditylang.org/en/v0.8.17/contracts.html#libraries
如果你有任何问题或希望我制作其它主题的教程,请在下面留言。
如果你想支持我制作教程,这里是我的以太坊地址:0xD5FC495fC6C0FF327c1E4e3Bccc4B5987e256794。
- 原文链接: coinsbench.com/deep-dive...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,在这里修改,还请包涵~





