从第一原理扩展以太坊虚拟机:重新构想存储层
- SeiNetwork
- 发布于 2024-11-23 23:13
- 阅读 2606
本文详细探讨了区块链虚拟机的存储层及其面临的挑战,特别是以太坊的Merkle Patricia Trie结构带来的高昂存储成本和状态膨胀问题。通过分析各种区块链(如Solana、Sui、Sei)在存储和检索数据方面的优化策略,本文旨在提出有效的解决方案来实现更高的性能和可扩展性。作者呼吁社区参与协作,共同推动更美好的区块链基础设施的发展。
特别感谢 Philippe Dumonet、Lefteris Kokoris-Kogias、Patryk Krasnicki、dcbuilder.eth、Evan Pappas、Rishin Sharma、Anastasios Andronidis 的反馈和讨论。
引言
区块链虚拟机的存储层至关重要,因为它管理持久数据,如智能合约和帐户,以及它们的内部状态和变量。在以太坊虚拟机(EVM)上进行的存储操作是资源密集型且耗费气体的操作之一,直接与 EVM 处理存储操作的效率相关。在以太坊上存储数据的成本很高,因为 EVM 从叶节点重新计算哈希,一直计算到根节点。随着 MPT 的大小和深度增加,读取和写入操作的计算复杂性也随之增加。
随着更多智能合约的部署和更多数据的存储,区块链状态持续增长,导致“状态膨胀”。这个问题增加了节点的存储需求,特别是全节点,它们必须存储整个状态以验证交易,这使得使用消费级硬件参与网络变得越来越资源密集型。
状态膨胀造成的读/写操作低效限制了开发者的设计空间,提高了消费者的成本。本文将探讨缓解这些限制的方法。
EVM 存储层及其局限性
EVM 存储层负责维护持久但可变的数据,这些数据在智能合约执行完成后仍然存在。这与 EVM 的内存不同,后者用于合同执行过程中的短期临时数据。
EVM 的持久存储组件:
- 程序代码:智能合约的编译字节码,存储在区块链上并且一旦部署不可变。
- 程序存储:智能合约中的状态变量在执行中保存数据。
- 机器状态:与帐户相关的信息,如余额和随机数,在每次交易、区块数据、交易收据和日志中更新。
EVM 使用修改版的帕特里夏梅克尔树(Patricia Merkle Tree)。Trie 是一种树状数据结构,允许高效地存储和检索键值对。
以太坊有:
- 状态 Trie:包含所有帐户的状态,将地址映射到帐户状态。
- 存储 Trie:对于每个作为智能合约的帐户,它有一个存储 trie 保存合约的数据。
- 交易 Trie:存储块中包含的所有交易。
- 收据 Trie:保存所有交易的收据,包括日志和状态信息。
这些 trie 的根哈希只存储在块头中,确保数据完整性,同时防止块头变得过大。
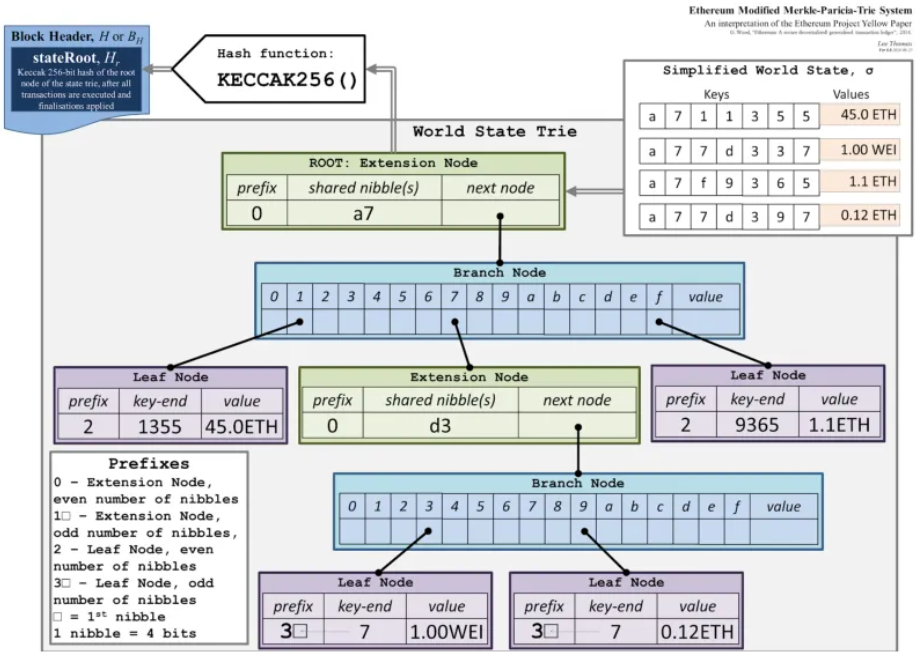 以太坊的修改梅克尔-帕特里夏树结构
以太坊的修改梅克尔-帕特里夏树结构
以太坊维持多客户端方法,并且故意没有参考客户端,所有人 必须 运行,以提高冗余、安全性、技术和政治的去中心化,并促进实验改进。目标确保没有一个共识或执行客户端占据网络的 ⅔ 以上。
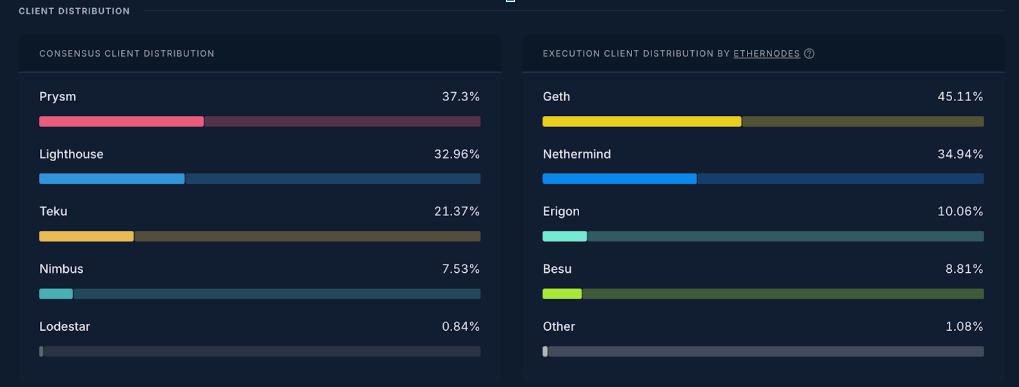 以太坊客户端分布 - 2024年11月
以太坊客户端分布 - 2024年11月
每个客户端变体遵循规范,但采用不同的实现方式,导致不同的性能指标。
Geth
第一个以太坊客户端是用 Go 编写的,它使用 LevelDB,这是一个优化用于快速读取和写入的键值存储库。它实现了黄皮书中指定的 Merkle Patricia Trie,并使用快照来优化状态访问,提高同步时间。
Besu
它用 Java 编写,使用 RocksDB,这是一个针对快速存储优化的可嵌入持久键值存储,是 LevelDB 的一个分支,优化了 SSD。它实现了 Merkle Patricia Trie,并具有先进的缓存机制以提高性能。
Nethermind
用 C# 编写,使用 .NET Core 框架,采用 LMDB(闪电内存映射数据库)进行高效的数据存储,并进行了内存缓存的优化,以支持频繁访问的节点和写入缓存以批量处理数据库操作。
Erigon
它是用 Go 编写的,使用基于 MDBX(内存映射数据库极限)的自定义存储层。它在很大程度上消除了运行时 MPT 结构,同时通过在需要时计算状态根来保持 MPT 兼容性。相反,状态 trie 被扁平化为一个键值数据库,以减少复杂性。这消除了 MPT 所需的多个数据库查找,提供了更好的存储效率、减少了磁盘空间需求,并降低了与 MPT 基于客户端相比的磁盘 I/O。
Silkworm,也称为 Erigon++,是基于 Erigon 架构的以太坊协议的 C++ 实现。它同样使用 libmdbx 作为数据库引擎,并寻求进一步优化客户端性能和资源利用。当前正在开发中,尚未进入 alpha 阶段。
Reth
Reth 采取模块化、以库为先的方法进行以太坊客户端开发。用 Rust 编写以提高性能,它采用 Erigon 的分阶段同步架构,同时强调组件的可重用性。Reth 正在实现并行区块处理,采用表分区以改进数据组织,并实施高效的修剪策略。
EVM 存储层的局限性
尽管有各种客户端,但一些核心局限性依然存在。
存储操作的高Gas费用
- 昂贵的写入:向存储写入数据是以太坊中最昂贵的操作之一,消耗大量气体。例如,设置非零存储插槽的费用为 20,000 gas。随着 trie 的增长,更新存储所需的时间增加。节点需要更多的 CPU 资源来处理存储写入,因为它们必须重新计算更大 trie 部分的哈希。
- 昂贵的读取:从存储读取数据的费用虽然比写入要低,但与使用内存的操作相比,仍然会产生显著的Gas费用。
状态膨胀
- 状态大小增长:随着更多智能合约的部署和更多数据的存储,以太坊状态持续增长。这种“状态膨胀”增加了节点的硬件存储要求。
- 对节点的影响:全节点必须存储整个状态以验证交易,这使得参与网络的资源需求越来越高。
梅克尔·帕特里夏树的复杂性与低效的数据检索
- 结构加深:虽然帕特里夏 Tries 优化了数据完整性和验证,但在数据检索和存储更新方面可能不够高效。随着状态条目的增加,trie 变得更深,增加了更多的分支。
- 遍历开销:读/写操作需要遍历 trie 中的多个节点,从而增加了延迟。
我们可以对存储收费,但这并不能解决这些局限性。开发者和用户会被激励更加谨慎地处理他们的存储需求,但历史上这并未奏效,例如 C 语言与垃圾回收之间的对比。存储租赁是一个经济解决方案,而不是技术解决方案。
更有效的解决方案可能涉及替代数据结构,和/或优化的数据库。让我们探讨一些区块链为优化读取、写入和梅克尔化所采取的不同方法。
以太坊
读取
以太坊的状态检索过程从每个区块头中的 stateRoot 开始,该状态根是处理该区块交易后的状态 trie 的根哈希。为了访问当前状态数据,节点从最新块的 stateRoot 开始。帐户信息的检索通过首先用 Keccak-256 哈希帐户地址,创建一个状态 trie 的键。节点然后遍历这个 trie,沿着由键的小字节(nibbles)定义的路径从根到叶,通常涉及对每个节点的数据库查找。
对于任何类型的帐户,包括外部拥有帐户(EOA),检索的数据包括余额和随机数。对于合约帐户,还存储以下附加字段:
- codeHash:合约字节码的哈希。
- storageRoot:合约存储 trie 的根哈希。
为了执行合约,EVM 必须检索实际的字节码。codeHash 用于定位和验证存储在节点代码存储中的字节码(通常是一个单独的键值存储)。这涉及使用 codeHash 作为键来访问代码存储,以获取字节码。要访问特定的合约存储变量,类似的过程也会发生。存储键(通常是变量的插槽索引)使用 Keccak-256 哈希。所得到的键用于遍历合约的存储 trie,从 storageRoot 开始,检索相关值。
提高数据读取效率的优化
以太坊采用多种优化措施来应对状态管理和检索的挑战。在数据库层面,以太坊客户端使用了像 LevelDB 或 RocksDB 这样的键值存储,这些存储都针对快速读取和写入进行了优化。这些客户端还实现了批量操作,以最小化磁盘访问。缓存策略起着至关重要的作用,频繁访问的节点保存在内存中以减少磁盘 I/O,同时通过修剪 trie 节点来节省空间。快速同步模式,如快照同步和急速同步,使得节点可以下载最新的状态数据,或依赖区块头获得历史信息,从而显著减少同步时间。
协议改进,如 EIP-1052、EIP-2929 和 EIP-2930,旨在优化状态访问模式和更精确的Gas费用计算。对无状态以太坊的持续研究探讨了客户无需存储整个状态,而是依赖于证明进行验证的设计。此外,像 Verkle Trees 这样的替代数据结构也在研究中,以提供更小的证明确认和更快的验证。
写入
写操作始于用户或智能合约提交事务。事务进入内存池,等待被验证者提议包含在块中。验证者通过验证事务的签名、随机数和执行所需的气体来验证事务。这个过程与以太坊的存储结构进行交互,主要是帐户的状态 trie 和合约的存储 tries。在事务执行过程中任何值的变化都需要更新相应的 trie 节点并重新计算哈希直到根,确保加密数据的完整性。
以太坊所采用的写入优化
1. Gas费用调整
- EIP-2200(重新平衡Gas费用):调整 SSTORE 操作的Gas费用,以更好地反映实际的计算开销,并激励高效使用存储。
- 退款机制:当存储槽被清空(设置为零)时,将提供气体退款,鼓励用户清理未使用的存储。
2. 无状态以太坊研究
- 减少状态依赖:无状态客户端不需要存储整个状态,依赖于与交易一起提供的见证。
- Verkle Trees:探索提供更小证明确认和更快验证的替代数据结构,可能减少写入开销。
3. 数据库和存储改进
- 批量写入:将多个写入操作组合在一起,减少磁盘访问次数,提高性能。
- 异步写入:实施异步数据库写入可以最小化事务处理过程中的阻塞。
- 缓存优化:缓存频繁访问的数据和写入缓冲区,以减少磁盘 I/O。
4. 协议层的增强
- EIP-1559 费用机制:调整交易费用的工作方式,从而可能影响用户根据气体价格对写入操作的优先级。
- EIP-2929 和 EIP-2930:提高某些存储操作的Gas费用,引入访问列表以优化状态访问模式。
- EIP-4844 引入了一种新的事务类型,称为 blob-carrying transactions,这种事务携带大量数据(blobs),这些数据对 EVM 不可访问但由共识层承诺。这允许高数据吞吐量而无须增加状态大小,从而优化写操作。
以太坊社区探讨的梅克尔化优化
为了应对上述 MPT 限制,以太坊社区正在探索 Verkle trees,
这是一种多项式承诺梅克尔树,允许更小的证明大小和更高效的验证。
Verkle 证明的大小远小于梅克尔证明,减少了轻客户端和无状态客户端所需的带宽。更小的证明和更高效的验证使更好的可扩展性成为可能,并为无状态以太坊铺平道路。EIP-4844(Proto-Danksharding)引入了数据可用性抽样,为实施 Verkle trees 奠定基础。通过减少加密证明(见证)的大小,Verkle trees 使无状态客户端能够验证事务,而无需维护整个状态数据库。这一效率是以太坊可扩展性路线图的一个重要组成部分,促进了更轻节点和更广泛的网络参与。
Solana
Solana 的数据存储模型
1. 扁平账户模型
- 统一账户空间:Solana 采用扁平账户模型,所有账户在一个单一的全局命名空间中存在。这与以太坊使用梅克尔·帕特里夏树的层次结构形成对比。
- 代码和数据的分离:程序(智能合约)和账户(数据)是两个独立实体。程序是无状态的代码,而账户持有程序操作的状态或数据。
- 直接访问:可以直接使用其公钥访问账户,无需复杂的数据结构遍历。
2. 内存映射账户存储
- 内存数据库(AccountsDB):Solana 在一个称为 AccountsDB 的内存数据库中存储账户数据,使用 RAM 和内存映射文件的组合。
- 内存映射文件:通过利用内存映射文件,Solana 允许操作系统管理数据分页,从而能够高效访问不完全适合 RAM 的数据。
- 零复制读取:程序可以直接读取账户数据,而无需额外复制,从而减少开销和延迟。
提高 Solana 数据读取效率的优化
1. 避免复杂的数据结构
- 不使用 trie 进行状态存储:Solana 避免使用梅克尔·帕特里夏树进行状态存储,消除了与哈希和树遍历相关的开销。
- 扁平键值存储:账户被存储在简单的键值存储中,允许 O(1) 的读取和写入访问时间。
2. 使用 Sealevel 进行并行交易处理
- Sealevel 运行时:Solana 引入 Sealevel,这是一种并行智能合约运行时,可以同时处理数千个事务。
- 不重叠的事务:不与相同账户交互的事务可以同时执行,增加吞吐量。
- 优化的读取访问:预确定不重叠的账户访问模式,减少状态冲突。
3. 高效的数据序列化
- 二进制序列化格式:Solana 使用高效的二进制序列化格式(如 Borsh)存储账户数据,最小化大小和处理时间。
- 零复制反序列化:程序可以直接访问序列化数据,而没有反序列化开销,因为它们直接操作内存映射数据。
4. 缓存和数据位置
- RAM 缓存:频繁访问的账户数据保存在 RAM 中,减少磁盘访问的需求,提高读取速度。
- 数据位置优化:Solana 优化数据放置,以提高缓存命中率并减少延迟。
5. 用于状态同步的快照机制
- 增量快照:Solana 使用当前状态的快照,帮助新的验证者快速加入网络,而无需处理整个交易历史。
- 高效的状态重构:这减少了重构当前状态所需的时间和数据读取。
6. 乐观并发控制
- 冲突检测:在事务执行过程中,Solana 在账户层面检测读-写和写-写冲突。开发者不需要声明状态依赖关系,从而提供更好的开发体验。
7. 账户版本和垃圾回收
- 版本化账户:账户包括版本号,以高效处理更新,并在读取期间确保一致性。
- 垃圾回收:清理旧账户数据以释放存储空间,提高读取性能。
写入
Solana 的写操作采用账户模型,分离程序和数据,使用扁平命名空间实现直接访问。系统采用乐观并发控制和 Sealevel 运行时进行并行交易处理,写锁确保数据一致性。Solana 的历史证明和塔 BFT 共识加快交易确认,而内存映射存储实现零复制写入。事务流水线和 GPU 加速提高处理速度。该平台通过持久存储、定期快照和有效的数据压缩保持数据完整性。
提高 Solana 写入操作效率的优化
1. 并行化
- 最大化硬件利用率:并行处理允许 Solana 充分利用多核处理器,提高写操作的容量。
- 可扩展性:架构随着硬件改进而扩展,支持更多的事务,因为处理器核心数量增加。
2. 乐观并发控制
- 非阻塞执行:通过假设事务不会冲突,并在发生冲突时处理,这最小化了与锁机制相关的开销。
- 高效的冲突处理:重试冲突事务使得开发者更容易编写代码,预先串行化所有事务。如果不相关事务数量足够多,则 OCC 可以提供有意义的优化。
3. 高性能运行环境
- Sealevel 的高效性:Sealevel 为并发设计,最小化开销,最大化写操作的吞吐量。
- 异步执行:非阻塞 I/O 和异步处理防止慢操作阻塞交易处理。
4. 直接账户访问
- 没有复杂的数据结构:不需要层次数据结构,写操作涉及简单的读取和写入到账户。
- 减少开销:消除复杂的状态管理可以减少延迟并降低写入时的资源消耗。
5. 减少磁盘 I/O
- 内存数据处理:将活动账户数据保存在内存中大大缩短了写操作期间的磁盘访问时间。
- 高效的持久化:在写入磁盘时,Solana 使用批量写入和优化的存储格式以最小化 I/O 开销。
6. 精简的共识
- 快速的交易最终性:Solana 通过其高效的共识机制实现快速确认写入交易。
- 低沟通开销:验证者需要更少的相互沟通来达成账本状态的一致性,加快写入过程。
7. 交易费用机制
- 可预测且低费用:Solana 的费用结构通过保持低而可预测的费用,鼓励频繁的写入操作。
- 动态费用调整:网络可以根据需求调整费用,确保即使在高负载下,写操作依然高效。
Solana 对状态管理与梅克尔化的处理
与以太坊 MPT 相比,Solana 在梅克尔化方面采取了不同的方法,优先考虑性能和简单性。它没有采用 trie 结构,而是只使用简单的梅克尔树进行块验证,每个块包含从所有账户状态计算的状态根哈希。该系统直接使用 SHA-256 对账户状态进行哈希,结合诸如 lamports(余额)、拥有者信息、可执行标志、租赁时代和账户数据等元素。
这种简化的梅克尔化策略与 Solana 的扁平账户模型和高度吞吐的重视相一致。状态验证主要通过交易执行期间的运行时验证进行,而不是通过加密证明。通过消除复杂的树遍历和中间节点,它实现了更快的状态访问和更新,同时减少了存储开销。然而,这种方法具有权衡——验证者必须在内存中维护完整的当前状态,且证明生成的粒度不如以太坊的 MPT 系统。这种设计以性能为最大化,要求验证者具有更高的内存占用。
Sui
Sui 的数据存储模型
Sui 的数据存储模型围绕对象优先的方法展开,其中对象作为存储和计算的基本单元。这些对象封装状态和行为,表示用户数据和智能合约。Sui 维护一个全局对象存储,每个对象在扁平命名空间中唯一标识,通过对象 ID 实现直接和高效的访问。
该平台利用 Move 编程语言,该语言专为安全和可验证的智能合约开发而构建。Move 的资源导向模型与 Sui 的对象优先设计无缝对接,增强了整体系统的完整性和效率。
Sui 实现了所有权和访问控制系统。对象可以由用户账户或其他对象拥有,所有权决定着访问权限和修改能力。共享对象的概念允许多个事务的并发访问和修改。这种所有权模型提供了细粒度的访问控制,通过最小化不必要的争用来优化数据读取。
提高数据读取效率的优化
1. 通过对象 ID 直接访问对象
- 消除复杂的哈希:与以太坊在 tries 中使用哈希键不同,Sui 通过对象 ID 直接访问对象。
- 扁平地址空间:这简化了数据检索,因为它减少了遍历层次数据结构或进行广泛的键值查找的需要。(Sui 还支持动态对象,这可能在执行时需要查找)。
2. 事务的并行执行
- 拥有对象的单写原则:仅涉及拥有对象的事务可以在没有冲突的情况下并行执行,因为每个事务对其对象拥有独占访问权。
- 多线程执行:Sui 的执行引擎可以同时处理多个事务,提高吞吐量,减少读取延迟。
- 冲突避免:通过识别不重叠的事务,Sui 最小化读写冲突,从而增强读取性能。
3. 高效的共识机制
Mysticeti:Sui 凭借低延迟和高吞吐量口优化。
- 它允许多个验证者并行提议区块,充分利用网络的带宽,提供抗审查能力。这些都是基于 DAG 的共识协议的特性。
- 它只需三轮消息即可确认来自 DAG 的区块,符合 pBFT,相当于理论上的最小值。
- 提交规则允许并行对区块上的区块进行投票和认证,从而进一步减少中位数和尾部延迟。
- 提交规则还容忍不可用的领导者,而不会显著增加提交延迟。
4. 对象版本和缓存
- 版本化对象:每个对象都有一个版本号,以确保读取与最新状态的一致性。
- 内存缓存:频繁访问的对象存在内存中,从而减少磁盘 I/O,提高读取性能。
- 惰性加载:对象仅在需要时加载到内存中,以优化资源利用率。
5. 高效的数据序列化
- Move 的资源模型:Move 强制执行资源操作的严格规则,这有助于提高对象的序列化和反序列化效率。
- 二进制序列化格式:对象使用紧凑的二进制格式进行序列化,从而降低数据读取的大小和解析的开销。
6. 数据库和存储优化
- 键值存储后端:Sui 使用高性能的键值存储(例如,被优化过的 RocksDB)以获取快速的读取和写入。
- 批量读取和写入:事务可以批量执行多个读取和写入操作,最小化数据库访问次数。
- 数据修剪和压缩:不再需要的旧数据会被修剪,存储也会被压缩以提升读取效率。
7. 处理共享对象
- 基于锁的并发控制:对于涉及共享对象的事务,Sui 使用锁来管理访问并确保数据一致性。事务必须在读取或写入共享对象之前获取锁。这一机制可防止并发修改导致状态冲突。
- 高效的同步:不相互影响的事务即使可以并行执行,仍可最大化吞吐量。
写入
Sui 的写操作围绕以对象为中心的数据模型展开,唯一标识的对象封装数据和行为。这一方法实现了直接访问和通过所有权进行的细粒度控制。Sui 利用并行交易执行来处理独立对象,最小化冲突并最大化吞吐量。Move 编程语言保证了数据的完整性和高效的序列化。Sui 优化的共识机制结合快速的事务传播与 BFT,确保快速和安全的写入确认。内存高效的数据结构,包括内存中存储和有效的垃圾收集,进一步提升写入性能。
Sui 对状态管理和梅克尔化的处理
Sui 采用了一种独特的状态管理和梅克尔化方法,与其以对象为中心的架构一致。它不是使用传统的梅克尔树或 MPT,如以太坊一样,而是实现了一种有向无环图(DAG)结构,用于组织交易及其对对象的影响。该平台的梅克尔化策略主要围绕对象版本控制和认证数据结构,这些结构跟踪对象历史和所有权。
Sui 中的每个对象都有一个唯一的版本号,在修改时单调增加。系统在每个检查点维护对象状态的梅克尔根,结合增量验证和因果顺序跟踪。这一架构使得在保持密码验证的前提下,可以实现并行处理交易。Sui 并未使用全局状态 trie,而是使用每个对象的认证路径,与其 Narwhal-Tusk 共识协议相结合,实现高效的状态验证。这一方法使验证者能够并行处理不重叠的交易,同时保持强一致性保证。
Sui 在梅克尔化中的关键创新在于与 Move 编程语言的资源模型的整合。Move 的所有权系统确保对象只能被其拥有者或指定智能合约所修改,这简化了梅克尔证明的生成和验证。通过在认证数据结构中直接跟踪对象的所有权和版本历史,Sui 在不依赖传统梅克尔树的开销下实现了高效的状态验证。然而,这一设计选择意味着验证者必须维护比仅跟踪当前状态的系统更为详细的对象历史。
Sei
在 Sei,我们识别了一些关键挑战:
写入放大:当前的 IAVL 树结构导致高写入放大,导致磁盘上写入的过多元数据超过实际有效数据。这导致存储使用效率低下和磁盘 I/O 增加。
存储增长:由于写入放大和低效压缩,磁盘使用迅速增长。这种指数增长使得运行归档节点变得昂贵且不可持续。
慢速度操作:关键操作,如状态同步、快照创建和数据检索,随着区块链状态的增长而变得日益缓慢,影响节点性能和用户体验。
数据库性能随着时间的推移而下降:随着数据规模的增长,LevelDB 的性能显著下降,尤其影响状态操作。这在处理大型数据集时尤为明显,影响节点的效率。
Sei 中读取的优化
1. 状态承诺与状态存储的分离
- 状态承诺(SC):通过隔离 SC 层,Sei 确保共识操作快速且轻量。SC 层无需处理历史查询,便于其优化速度和效率。
- 状态存储(SS):SS 层专注于以优化读取为重的方式存储数据,特别是用于服务历史查询。
2. 采用 MemIAVL 进行状态承诺
Sei 使用 MemIAVL,即 IAVL 树的内存版本,处理状态承诺:
- 内存操作:所有最近状态由内存提供,大大提高了共识相关数据的读取和写入速度。
- 预写日志(WAL)和树快照:为了确保数据持久性和快速恢复,MemIAVL 使用 WAL 记录更改和树的定期快照。这种方法在日常操作中最大限度地减少磁盘 I/O。
对读取的好处:
- 更快的访问:内存数据结构提供几乎瞬时的读取访问,适用于共识操作。
- 减少延迟:块验证和承诺的关键读取操作得以加快,从而增强整体网络性能。
3. 优化历史查询的状态存储
对于 SS 层,我们提出一个可插拔接口以允许集成针对读取性能优化的数据库:
- 可扩展的存储解决方案:通过选择旨在实现高读取吞吐量和高效数据检索的数据库,确保历史查询能够迅速得到处理。
- 自定义数据库选项:应用可以根据特定的访问模式和性能要求选择最合适的数据库后端。
潜在的读取优化:
- 缓存策略:频繁访问的数据可以缓存以减少磁盘读取的需求。
- 批处理:以批量读取数据提高吞吐量,减少开销。
4. 节点特定配置
不同节点有不同需求:
- 验证者节点:
- 内存集中操作:验证者能够将所有必要数据保存在内存中,优化共识的读取速度,无需磁盘存储开销。
- 最小磁盘使用:通过关注最新状态,避免存储历史数据,验证者减少了存储需求,提升了性能。
- RPC 和归档节点:
- 持久存储:提供历史数据的节点使用优化的 SS 层以高效处理读取密集型工作负载。
- 高读取性能:这些节点配置以快速响应历史查询,对依赖于过往区块链数据的应用和用户至关重要。
5. 改进的数据结构和存储技术
通过拯救传统 IAVL 树进行状态存储,Sei 可以采用更适合读取优化的数据结构:
- 简化键值存储:采用以扁平键值格式存储数据的数据库,减少复杂性,加快读取操作。
- 减少元数据开销:优化的数据结构最小化元数据量,降低存储需求和读取放大率。
结论
EVM 的存储层面临关键挑战:存储操作需要通过 MPT 进行昂贵的哈希重新计算,这使得它们既昂贵又资源密集。随着智能合约的增多,状态规模的增加增加了计算复杂性和存储需求,使得使用消费硬件参与网络变得越来越困难。这些低效限制了开发者的选择,提高了用户的成本。
优化区块链存储的关键在于认识到状态承诺(用于共识和验证)与状态存储(用于数据持久性)具有不同的需求,并且可以独立优化。虽然不同区块链都在探索这一分离的不同方法,但 Sei 使用 MemIAVL 和可插拔存储实现的实现展示了这种架构分离如何实现并行执行和管理状态膨胀,同时保持低硬件需求。该分离允许独立优化共识操作和数据存储与检索,减少状态膨胀的影响,同时支持更高的交易吞吐量。
研究仍然在第一性原理的探索上检讨状态管理,探寻能够进一步优化两个层层的新的数据结构和存储方法,同时保持安全性和去中心化。
加入 Sei 研究计划
我们邀请开发者、研究人员和社区成员加入我们的任务。这是一次开放源代码协作的邀请,旨在建立更可扩展的区块链基础设施。查看 Sei Protocol 的 文档,探索 Sei 基金会资助机会( Sei 创建者基金, 日本生态系统基金)。
- 原文链接: blog.sei.io/research-sca...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





