以太坊中RLP编码的综合指南
- markodayansa
- 发布于 2022-08-25 23:27
- 阅读 1366
本文深入探讨了递归长度前缀(RLP)数据序列化方法,主要集中在其在以太坊中的应用。文章详细介绍了RLP编码的原理,包括数据序列化的背景、RLP的定义以及其编码算法,提供了一系列代码示例来展示如何在JavaScript和Go等语言中实现RLP编码。最后,文章还展示了如何使用RLP编码计算以太坊区块头的哈希值,帮助读者更好地理解这一技术的实际应用。

在这篇博客文章中,我将向你介绍一种名为 Recursive Length Prefix (RLP) 的数据序列化方法,其在以太坊的实现中扮演着重要角色。
这篇文章的目标是帮助你了解 RLP 数据序列化究竟是什么,为什么它在以太坊中被广泛使用,以及它解决了什么问题。我们将在本文中主要聚焦于 RLP 编码,将 RLP 解码留待将来的某天(并且那篇文章会短得多!)。
我认为在关注反方向之前,首先自信地理解 RLP 编码更为重要。尽管解码部分被省略,但请做好准备进行一篇相当密集的阅读。我希望你能觉得这篇文章有用 🙂
为了帮助你更好地理解这一主题,让我们先对计算机系统中的数据序列化概念进行一些背景了解。如果你想直接深入 RLP 序列化,可以跳过下一部分。
什么是数据序列化?
序列化 是将数据对象转换为一系列字节的过程,以便于存储、传输或分发。
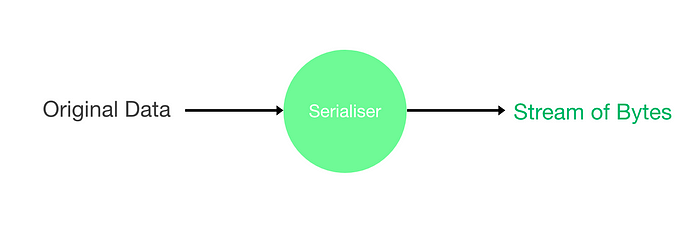
数据作为输入提供给序列化器,并生成以字节流形式编码的输出
数据的序列化表示(作为字节的集合)可以用于在另一个环境中重构与原始数据在语义上完全相同的克隆。这样的重构描述了序列化的反过程,称为 反序列化。
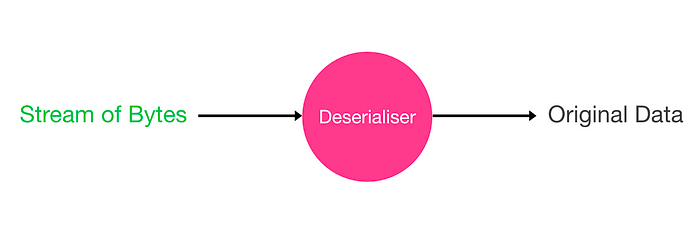
作为输入提供给反序列化器的一串字节,并以更高级的格式化数据形式生成解码输出
计算机系统的硬件架构、操作系统和寻址机制等可能会有所不同;考虑到这一点,我们可以理解数据在不同系统中的表示可能会有所不同。为了更加生动地类比上述提到的数据表示差异,想象两种根本不同的编程语言(比如 JavaScript 和 Golang)都可以表示字典,但实现的方式却大相径庭。
这些跨越系统的数据不同表示带来了如何在不常见环境之间进行数据传输和存储的挑战。对此的解决方案是提供一个所有相互通信的系统都可以理解的共同标准化格式。我们为简便起见,将这种标准化格式称为 数据序列化格式。
许多软件开发人员可能已经熟悉一些数据序列化格式,如 XML 和 JSON,它们在许多应用中得到了广泛使用。
数据序列化和反序列化的工作原理
数据有效载荷可以有多种形式。它可以是一个简单的 原始类型,如整数、布尔值或字符串,也可以在大多数情况下是 复合类型,如数组、表、树或类等数据结构。
当我们想要将数据有效载荷存储或传输到另一个位置(通常是通过网络)时,我们需要使用序列化。序列化的作用是将数据有效载荷编码为一种可共享的格式,从而可以在其他地方传输并能够根据该环境的数据表示规则在新位置进行重构。
让我们来看一个简单的例子,帮助理解上述解释:
我们下面的例子是;有两个应用程序彼此通信,作为系统的一部分, 我们想将数据有效载荷从我们的 JavaScript 应用程序发送到我们的 Golang 应用程序 :
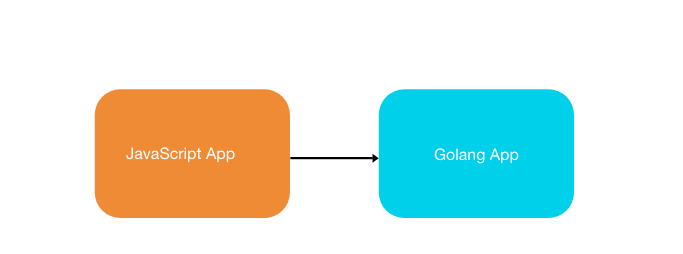
我们的系统中,JavaScript 应用程序将有效载荷发送到 Golang 应用程序
我们的有效载荷在下面的 UML 中说明:
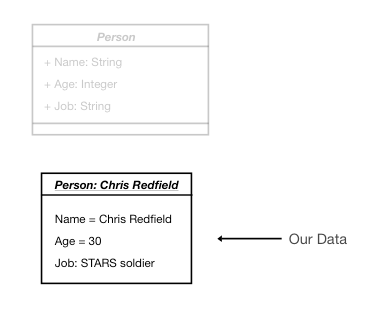
我们的“Chris Redfield”数据有效载荷(一个简单的对象)
我们将使用 JSON 作为双方应用程序共享的数据序列化格式。在这个前提下,我们的 JavaScript 应用程序将执行以下操作:
- 定义数据对象。
- 使用 JSON 序列化数据对象。
- 将序列化的有效载荷发送到 Golang 应用程序。
我们可以通过以下代码展示我们的 JavaScript 应用程序如何序列化有效载荷并将其发送到 Golang 应用程序:
// 第一步
let data = {
name: "Chris Redfield",
age: 30,
job: "STARS soldier",
};
// 第二步(序列化步骤)
let serialised = JSON.stringify(data);
// 第三步
sendToGolangApp(serialised);我们的 Golang 应用将期待 1) 接收序列化数据和 2) 将其反序列化为一个名为 data 的变量。我们将通过以下代码展示这一过程:
反序列化 - 接收序列化有效载荷并反序列化为 Golang 结构变量
// 第一步
serialised := receiveSerialisedPayload();
// 第二步 - 我们可以根据有效载荷结构反序列化为结构
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
Job string `json:"job"`
}
var data Person
json.Unmarshal(serialised, &data)
fmt.Println(data.Name) // Chris Redfield
fmt.Println(data.Age) // 30
fmt.Println(data.Job) // STARS soldier正如你从上面的例子所见,我们的 JavaScript 代码使用 JSON.stringify() 方法序列化数据有效载荷。我们的 Golang 代码在接收到序列化数据后,能够使用 json.Unmarshal() 方法将其反序列化为一个变量。
这就是例子。我们刚刚观察了一种在两个在数据表示上有基本差异的应用程序之间的非常基本的数据序列化形式!在这篇文章的下一个部分,我们将实际看到这种数据有效载荷在以字节序列的形式表达时是怎样的,所以请继续关注。
到此为止,我们简单介绍了数据序列化的背景。现在让我们转向有关 RLP 数据序列化在以太坊中独特用途的问题。
以太坊中的数据序列化
以太坊可以被描述为一个由 节点(计算机)组成的去中心化网络,这些节点运行 以太坊客户端(以太坊协议规范的软件实现),并以点对点的方式相互通信。
在不深入以太坊工作原理的细节(我将在未来的博客文章中详细阐述)之前,有一点重要的事情需要了解:
以太坊创建、存储和传输大量数据。
这条信息为什么对我们相关?
这与我们对以太坊的兴趣相关,因为大存储和带宽需求给在消费者级硬件上运行节点带来了挑战,而这对于维持一个真实的抗审查、去中心化网络至关重要。如果我们无法维持一个健康的去中心化网络,我们将失去区块链所具备的宝贵特性,这正是其价值主张的合理性所在。
为了帮助降低运行节点的成本,以太坊社区采取了通过 标准化数据格式 的形式进行优化,以以内存高效的方式降低存储和带宽需求。为了实现这一目标,使用了几种特定的数据结构(我们在这篇文章中不会探讨这些)和在以太坊栈上的数据序列化格式。
在以太坊中,实际上有 2 种占主导地位的格式:
- Recursive Length Prefix (RLP)
- Simple Serialize (SSZ)
我们在这篇文章中不会去讨论 SSZ,但如果你想了解更多,可以在 这里 找到一篇好的文章。
Recursive Length Prefix (RLP)
Recursive Length Prefix (RLP) 是在以太坊执行客户端中广泛使用的一种数据序列化方案,它帮助以空间高效的格式标准化节点之间的数据传输。
执行客户端管理事务执行、事务传播等任务。
我们可以正式定义 RLP 为 一种用于编码任意结构的二进制数据(字节数组)的序列化方法,同时将原始数据类型(例如字符串,浮点数等)的编码留给更高层的协议来处理。
理解 RLP 编码的一个重要细节是,数据输入需被表示为(二进制数据的)数组(或嵌套数组),以便成为有效的序列化输入。
表示为二进制数据数组究竟是什么意思?
好吧,想象一下我们想要序列化一个对象(对于 Python 的朋友来说,是字典),该对象等于 { k1: v1, k2: v2 } 。
目前,这不是一个可以通过 RLP 序列化的有效输入。
建议的格式更改是将对象描述为键值元组的数组,并按字典顺序排列键。通过这样的描述,我们可以表示对象为 [[k1, v1], [k2, v2]] ,这现在是一个通过 RLP 编码的有效输入。
变量
k1、v1、k2和v2代表二进制数据有效载荷(或根据原始数据结构的复杂程度而定的嵌套二进制数据有效载荷)。
例如,假设k1等于一个字符'A'而v1等于字符串"foo";则k1的二进制有效载荷将对应字节值65,而v1将对应字节数组[102, 111, 111]。
注意:请勿混淆变量的字节表示与实际的 RLP 编码(而我们尚未定义 RLP 编码!)。我仅仅是向你展示一个原始键值对表示为字节时各个值的样子。
请记住,一个字节表示整数范围内的一个值 [0, 255],而 可以用 [0x00, 0xff] 的十六进制形式来表达 。在我们进入 RLP 序列化定义之前,这一点至关重要。
话虽如此,让我们稍作停顿,更清晰地了解如何将字符串表示为字节的集合/数组/序列(即字节数组)。这将非常有助于你实际理解如何对数据进行 RLP 编码。 我们还将看到,为什么像 JSON 的一些序列化方案不适合在以太坊中序列化数据。
将字符串表示为字节数组(字节序列)
想象我们有 JSON 字符串 "{"name":"Chris Redfield","age":30,"job":"STARS soldier"}" 。
这个字符串可以表示为一系列字节,其中字符串中的每个 ASCII 字符都可以转换为范围从 0 到 255(十进制表示值)或 00 到 FF(十六进制表示值)的字节值。随着本文章的发展,我们将专门以 十六进制表示 来处理字节,以避免任何混淆。
所以,考虑到这一点,让我们看看如果以上字符串用十进制和十六进制表示为字节序列会是什么样子:
// 我们有一个字符串 -> "{"name":"Chris Redfield","age":30,"job":"STARS soldier"}"
// 字符串表示为字节数组
// 其十进制值为每个字节范围为 0 - 255
[
123,34,110,97,109,101,34,58,34,67,
104,114,105,115,32,82,101,100,102,105,
101,108,100,34,44,34,97,103,101,34,
58,51,48,44,34,106,111,98,34,58,
34,83,84,65,82,83,32,115,111,108,
100,105,101,114,34,125
]
// 字符串表示为字节数组
// 其十六进制值为每个字节范围为 00 - FF
[
'7B','22','6E','61','6D',
'65','22','3A','22','43',
'68','72','69','73','20',
'52','65','64','66','69',
'65','6C','64','22','2C',
'22','61','67','65','22',
'3A','33','30','2C','22',
'6A','6F','62','22','3A',
'22','53','54','41','52',
'53','20','73','6F','6C',
'64','69','65','72','22',
'7D'
]查看原始代码 将字符串表示为字节数组的十进制和十六进制表示
所以现在你可能会想,“JSON 似乎是管理以太坊中的数据序列化的一个不错的选择”。让我们简要探讨一下,为什么实际上情况截然相反,特别是在区块链和具体以太坊的语境中。
JSON 序列化 并不保证 在不同实现中产生确定性输出,详见 这里,该链接提供了一个简短但深刻的答案,讨论了为何 JSON 不保证此特性。如果你懒得阅读,总的原因归结为该属性未能标准化。
在区块链的背景下,尤其是以太坊的具体情况,这就构成了一个直接的问题,因为序列化数据在计算多个重要的哈希值(如交易哈希和区块哈希)方面扮演着角色。如果这些哈希值不是确定的,我们最终会导致交易和区块对应于多个哈希值。你可以想象,从这里开始,校验问题只会变得更加复杂,尤其在一个点对点网络当中,这样请求的默克尔证明不能计算出正确的默克尔根。
关键是,我们需要一个产生确定性输出的序列化方案。
RLP 编码算法探究
通过 RLP 编码,我们接收到以 项 形式的输入,该输入被馈送到序列化算法以生成以 RLP 序列化数据 形式的编码输出。
项被定义为:
- 字符串(即字符串的字节数组表示)
- 项的列表(即列表的列表、项的列表或两者的组合)
RLP 编码器接收到项作为输入并生成序列化数据输出
让我们来看一些 RLP 编码算法接受的有效项:
0x71(一个字节)"a"(字符串)"cat"(字符串)""(空字符串)[](空列表)["cat", "dog"](包含多个字符串的列表)["cat", "dog", ["cow", "chicken"], [[]], [""]](包含嵌套项的列表)[["name", "Claire Redfield"],["location", "Raccoon City"]](一个用于序列化格式化的嵌套项列表,表示一个对象)
请注意,这里示例中给出的全是 字节、字符串 和 列表 数据类型,或这三者的结合。这旨在强调 RLP 规范主要集中于这些数据类型。
非标准特性添加到 RLP 编码实现中
你可能会发现各种编程语言中的 RLP 编码算法实现允许指针、布尔值、大整数等类型作为要编码的输入。
需要强调的是,这 并不是 标准 RLP 规范的一部分,该规范序列化跨越不同环境传输的数据(例如 Go-ethereum 客户端向 Nethermind 客户端传播 RLP 编码数据)。
例如, go-ethereum 可能实现了可以接受多种类型输入的 RLP 编码,原因可能是它在客户端本身内部或在不同的 go-ethereum 客户端之间的独占传播中利用了这种序列化(这一点我仅做推测,但直觉上是有一定道理的)。
因此,我觉得有必要提及这一点,因为并非所有测试用例都适用于不同的 RLP 编码实现。
例如,
go-ethereum的 RLP 测试用例输入可能在ethereumjsRLP 包的编码算法中被视为无效。
重要的是,你 只需测试相应于下面要描述的条件情况 的输入。
那么我们就讨论一些刚才列举的输入: 正如你可以从一些嵌套项示例中判断,代表数据项(列表和字符串的组合)的形式可以在我们开始思考如何将复杂数据结构(如嵌套对象或树)转换为有效的编码输入时令人感到相当困惑。
幸运的是,通过这样的格式化,RLP 算法能够以高效且可预测的方式成功序列化任意结构复杂性的数据。其实现方式是遵循一组 条件情况,根据所提供的输入特征执行不同的序列化任务。
下面让我们看看这些 RLP 编码算法的条件情况:
有效输入始终将满足以下条件中的一个,其中输入可以是:
- (1) 一个 非值(
null,’’,false) - (2) 一个 空列表(
[]) - (3) 一个 单字节,其值在范围
[0x00, 0x7f]之内 - (4) 一个长度为 1 字节 的字符串
- (5) 一个长度为 2–55 字节 的字符串
- (6) 一个长度为 超过 55 字节 的字符串
- (7) 一个 列表,其 RLP 编码内容总和在 1–55 字节 之间
- (8) 一个 列表,其 RLP 编码内容总和超过 55 字节
接下来,我们将深入探讨每个条件情形所采取的具体操作,以展示它们根据不同要求如何序列化数据。
所有这些条件情形的产生的输出都表示为字节数组,即使有一个计算的值也如此。
在我们继续之前, 我想分享一个关于处理字符串的关键细节( 相关于情况 4、5 和 6): 在我们编码字符串时,我们将每个字符的 ASCII 字符转换为 对应的字符代码 。
示例: 字母'r'在十六进制字节数组中对应的字符代码值为114,而这一个字母会对应于0x72(这是字母'r'的字符代码的十六进制表示)_**
情况 1
规则:输入 p 是一个 非值 (null,’’,false):
因此, RLP 编码 = [0x80]
示例
让 p =
'’(空字符串 ε)∴ RLP 编码 =
[0x80]
情况 2
规则:输入 p 是一个 空列表([]):
因此, RLP 编码 = [0xc0]
示例
让 p =
[](空列表)∴ RLP 编码 =
[0xc0]
情况 3
规则:输入 p 是一个单字节,其中 p ∈ [0x00, 0x7f]:
因此, RLP 编码 = [p]
示例
让 p =
0x2a,
0x2a∈[0x00, 0x7f],因此我们满足情况 3∴ RLP 编码 = p =
[0x2a]
情况 4
规则:输入 s 是一个长度为 1 字节的字符串:
因此, RLP 编码 = [s]
示例
让 s =
[0x74](s 是字符串 "t" 的十六进制字节数组)∴ _RLP 编码 = s =
[0x74]
情况 5
规则:输入 s 是一个长度为 1–55 字节的字符串:
- len = s 的长度
- 计算第一个字节 f : f =
0x80+ len | 其中 f ∈[0x81, 0xb7](字符串的最小长度是1) - 因此, RLP 编码 =
[f, ...s]
示例
设 s =
[0x64, 0x6f, 0x67](s 是字符串 “dog” 的十六进制字节数组)len = 3(字节数组中的 3 个元素)
f =
0x80+ 3 =0x83∴ RLP 编码 =
[f, ...s]=[0x83, 0x64, 0x6f, 0x67]
情况 6
规则:输入 s 是一个长度超过 55 字节的字符串:
- len = 字符串的长度(以十六进制表示)
- 计算存储 len 所需的字节 , b :
b = 存储字符串长度所需的字节
*__ 例如,存储长度为 0xffff,需要 2 字节,因为它将在字节中表示为 len** = [0xff, 0xff]
- 计算第一个字节 f : f =
0xb7+ b | 其中 f ∈[0xb8, 0xbf](字符串的最小长度是1) - 因此, RLP 编码 =
[f,...len, ...s]
示例
设 s =
[0x4c, ..., 0x6c, 0x69, 0x74](s 是字符串 “Lorem ipsum dolor sit amet, consectetur adipisicing elit” 的十六进制字节数组,长度为 56 字节)。s 的长度为 56 字节,如果我们将这个长度转换为十六进制,则得到一个字节:
len =[0x38]
如果长度再大一些,比如 0x1234(4660 字节),我们的 len 值将会是 [0x12, 0x34](存储长度需要用 2 字节编码)。我提到这一点是因为我知道这点在一开始可能会引起困惑。我们可以将十六进制长度值表示为一个字节
[0x38]。
因此,表示 len 所需的字节数量是 1: b =1我们现在可以计算第一个字节: f =0xb7+ b =0xb8
∴ RLP 编码 =[f,...len, ...s]=[0xb8, 0x38, 0x4c, ..., 0x6c, 0x69, 0x74]
情况 7
规则:输入 l 是一个有效载荷为 1–55 字节的列表:
- len = 每个 RLP 编码的列表项长度总和(以十六进制表示)
- 计算第一个字节 f : f =
0xc0+ len | 其中 f ∈[0xc1, 0xf7](列表的最小长度为1) - concat = 列表项的 RLP 编码的串联
- 因此, RLP 编码 =
[f, ...concat]
示例
设 l =
["cat", "dog"]。
"cat"可以表示为字节数组[0x63, 0x61, 0x74]
"dog"可以表示为字节数组[0x64, 0x6f, 0x67]
"cat"的 RLP 编码 =[0x83, 0x63, 0x61, 0x74](长度为 4)
"dog"的 RLP 编码 =[0x83, 0x64, 0x6f, 0x67](长度为 4)
现在我们可以计算 concat 和 len : concat =[0x83, 0x63, 0x61, 0x74, 0x83, 0x64, 0x6f, 0x67]
len = 4 + 4 =0x08
我们现在可以计算第一个字节: f =0xc0+ len =0xc8∴ RLP 编码 =[f, ...concat]=[0xc8, 0x83, 0x63, 0x61, 0x74, 0x83, 0x64, 0x6f, 0x67]
情况 8
规则:输入 l 是一个有效载荷大于 55 字节的列表:
- len = 每个 RLP 编码列表项长度总和(以十六进制表示)
- 计算存储 len 所需的字节 , b : b = 表示 len 所需的字节
*__ 例如,存储长度为 0xffff,需要 2 字节,因为它将在字节中表示为 len** = [0xff, 0xff]
- 计算第一个字节 f : f =
0xf7+ b | 其中 f ∈[0xf8, 0xff](列表的最小长度为1) - concat = 列表项的 RLP 编码的串联
- 因此, RLP 编码 =
[f, ...len, ...concat]> 示例我已经写了很多,所以不妨通过一个实际的例子来展示,因为人们很少提供一个 🙃:
设 l =
["apple", "bread", "cheese", "date", "egg", "fig", "guava", "honey", "ice", "jam", "kale"]。"apple"可以表示为字节数组[0x61, 0x70, 0x70, 0x6c, 0x65]"bread"可以表示为字节数组[0x62, 0x72, 0x65, 0x61, 0x64]"cheese"可以表示为字节数组[0x63, 0x68, 0x65, 0x65, 0x73, 0x65]"date"可以表示为字节数组[0x64, 0x61, 0x74, 0x65]"egg"可以表示为字节数组[0x65, 0x67, 0x67]"fig"可以表示为字节数组[0x66, 0x69, 0x67]"guava"可以表示为字节数组[0x67, 0x75, 0x61, 0x76, 0x61]"honey"可以表示为字节数组[0x68, 0x6f, 0x6e, 0x65, 0x79]"ice"可以表示为字节数组[0x69, 0x63, 0x65]"jam"可以表示为字节数组[0x6a, 0x61, 0x6d]"kale"可以表示为字节数组[0x6b, 0x61, 0x6c, 0x65]RLP 编码的
"apple"=[0x85, 0x61, 0x70, 0x70, 0x6c, 0x65](长度为 6) RLP 编码的"bread"=[0x85, 0x62, 0x72, 0x65, 0x61, 0x64](长度为 6) RLP 编码的"cheese"=[0x86, 0x63, 0x68, 0x65, 0x65, 0x73, 0x65](长度为 7) RLP 编码的"date"=[0x84, 0x64, 0x61, 0x74, 0x65](长度为 5) RLP 编码的"egg"=[0x83, 0x65, 0x67, 0x67](长度为 4) RLP 编码的"fig"=[0x83, 0x66, 0x69, 0x67](长度为 4) RLP 编码的"guava"=[0x85, 0x67, 0x75, 0x61, 0x76, 0x61](长度为 6) RLP 编码的"honey"=[0x85, 0x68, 0x6f, 0x6e, 0x65, 0x79](长度为 6) RLP 编码的"ice"=[0x83, 0x69, 0x63, 0x65](长度为 4) RLP 编码的"jam"=[0x83, 0x6a, 0x61, 0x6d](长度为 4) RLP 编码的"kale"=[0x84, 0x6b, 0x61, 0x6c, 0x65](长度为 5)我们现在可以计算 concat 和 len : concat =
[0x85, 0x61, 0x70, 0x70, 0x6c, 0x65, 0x85, 0x62, 0x72, 0x65, 0x61, 0x64, 0x86, 0x63, 0x68, 0x65, 0x65, 0x73, 0x65, 0x84, 0x64, 0x61, 0x74, 0x65, 0x83, 0x65, 0x67, 0x67, 0x83, 0x66, 0x69, 0x67, 0x85, 0x67, 0x75, 0x61, 0x76, 0x61, 0x85, 0x68, 0x6f, 0x6e, 0x65, 0x79, 0x83, 0x69, 0x63, 0x65, 0x83, 0x6a, 0x61, 0x6d, 0x84, 0x6b, 0x61, 0x6c, 0x65]由于 concat 的长度为 57 字节(只需计数上述 RHS),因此我们看到将此长度转换为十六进制结果为
0x39。 要表示这个值只需 1 字节 因此表示 concat 长度的字节表示为:len =
[0x39](一个字节)*记住,根据我们的理论,如果长度是一个更大的值,例如 0x1234(4660 字节),我们的 len 值将是 [0x12, 0x34](需要 2 字节来编码长度)。我之所以在这里提到这一点是因为我知道这在一开始可能会造成困惑 ____。我们可以用一个字节表示十六进制的长度值 len 。
因此,表示 len 所需的字节数量为 1: b =
1我们现在可以计算第一个字节: f =0xf7+ len =0xf8∴ RLP 编码 =
[f,...len ...concat]=[0xf8, 0x39, 0x85, 0x61, 0x70,..., 0x61, 0x6c, 0x65]
经过所有的条件案例探讨,我们有了构建 RLP 编码算法所需的所有基本构件,以便对任何有效的复杂输入进行编码!
如你所见,与列表相关的条件案例需要对其包含的项目执行编码,以有效地序列化相关列表。从这一点来看,你可以推断出列表还可以包含更多的列表元素,我们还需要在新的执行范围内对这些元素进行序列化,因此你可以开始看到我们的编码算法将需要使用 递归 和 分而治之的策略。在所有的条件案例定义和探讨之后,这实际上将比你想象的更容易!
所以现在你可以看到术语“递归”在 RLP 序列化上下文中的来源。让我们看看 RLP 编码器算法的实现看起来像什么。
RLP 编码算法实现
好了,时机到了;让我们最终看到这个编码算法的实现。
简而言之,这是一个过于简单化的步骤:
- 算法 接收输入。
- 它检查输入属性是否符合之前描述的所有条件案例 (它还检查一些额外的案例,这些不是标准化规范的一部分,但很方便,我稍后会解释这些)。
- 根据满足的条件案例,应用适当的编码过程。根据输入,编码过程中可能会涉及递归。
- 接收 RLP 编码的输出 🏆
让我们在 TypeScript 中查看这个编码算法的实现:
type Input = string number bigint Uint8Array Array<Input> null undefined any;
function encode(input: Input): Uint8Array {
/* (1) 非值输入 */
if (input === ''| input === false| input === null) {
const value = parseInt('0x80', 16);
return Uint8Array.from([value]);
}
/* (2) 空列表输入 */
if (input === []) {
const value = parseInt('0xc0', 16);
return Uint8Array.from([value]);
}
/* 对于十进制值输入 */
if (typeof input === 'number') {
if (input < 0) {
throw new Error('整数必须是无符号的(提供大于或等于 0 的十进制值)');
}
if (input === 0) {
const value = parseInt('0x80', 16);
return Uint8Array.from([value]);
}
/* (3) 输入是范围 [0x00, 0x7f] 之间的单个字节 */
if (input <= 127) {
return Uint8Array.from([input]);
}
if (input > 127) {
const hexStr = input.toString(16);
const byteArr = hexStringToByteArr(hexStr);
const first = parseInt('0x80', 16) + byteArr.length;
return Uint8Array.from([first, ...byteArr]);
}
}
/* 真实布尔值输入 */
if (input === true) {
const value = parseInt('0x01', 16);
return Uint8Array.from([value]);
}
/* 对于十六进制转义序列输入 */
if (isEscapedFormat(input)) {
// @ts-ignore
const payload: any[] = (input as string)
.split('')
.reduce((acc, v) => acc + encodeURI(v).slice(1), '')
.match(/.{1,2}/g);
if (payload.length === 1) {
const value = parseInt(payload[0], 16);
return Uint8Array.from([value]);
}
if (payload.length <= 55) {
const first = parseInt('0x80', 16) + payload.length;
return Uint8Array.from([first, ...payload]);
}
}
/* 对于以 '0x' 为前缀的十六进制字符串 */
if (typeof input === 'string' && input.startsWith('0x')) {
const payload = stripHexPrefix(input);
// 如果十六进制字符串中的数字位数为奇数 -> 添加 '0' 前缀
const padded = payload.length % 2 === 0 ? payload : '0' + payload;
// 创建十六进制值的数组,其中每个元素前面都有 '0x' (我们这样做是为了在返回语句中将这些十六进制值转换为十进制字节值)
const hexArr: any[] = padded.match(/.{1,2}/g)!.map((x) => '0x' + x);
// 对于长度大于 55 字节的十六进制字符串
if (hexArr.length > 55) {
const lengthInHex = hexArr.length.toString(16);
const bytesToStoreLengthInHex = hexStringToByteArr(lengthInHex);
const first = parseInt('0xb7', 16) + bytesToStoreLengthInHex.length;
return Uint8Array.from([first, ...bytesToStoreLengthInHex, ...hexArr]);
}
const first = parseInt('0x80', 16) + hexArr.length;
return Uint8Array.from([first, ...hexArr]);
}
/* (4) 输入是长度为 1 字节的字符串 */
if (typeof input === 'string' && input.length === 1) {
const value = input.charCodeAt(0);
return Uint8Array.from([value]);
}
/* (5) 输入是长度在 2-55 字节之间的字符串 */
if (typeof input === 'string' && input.length <= 55) {
const first = parseInt('0x80', 16) + input.length;
const encoded = input.split('').map((c) => c.charCodeAt(0));
return Uint8Array.from([first, ...encoded]);
}
/* (6) 输入是长度超过 55 字节的字符串 */
if (typeof input === 'string' && input.length > 55) {
const lengthInHex = stripHexPrefix(input).length.toString(16);
const bytesToStoreLengthInHex = hexStringToByteArr(lengthInHex);
const first = parseInt('0xb7', 16) + bytesToStoreLengthInHex.length;
const encoded = input.split('').map((c) => c.charCodeAt(0));
return Uint8Array.from([first, ...bytesToStoreLengthInHex, ...encoded]);
}
if (Array.isArray(input)) {
const encoded = [];
let encodedLength = 0;
for (const item of input) {
const enc = encode(item);
encoded.push(...enc);
encodedLength += enc.length;
}
/* (7) 输入是列表,其RLP编码内容的总和在 1-55 字节之间 */
if (encodedLength <= 55) {
const first = parseInt('0xc0', 16) + encodedLength;
return Uint8Array.from([first, ...encoded]);
}
/* (8) 输入是列表,其RLP编码内容的总和超过 55 字节 */
if (encodedLength > 55) {
const lengthInHex = encodedLength.toString(16);
const bytesToStoreLengthInHex = hexStringToByteArr(lengthInHex);
const first = parseInt('0xf7', 16) + bytesToStoreLengthInHex.length;
return Uint8Array.from([first, ...bytesToStoreLengthInHex, ...encoded]);
}
}
throw new Error(
'未处理的输入负载(如果 bigint 负载,则编码方法需要更新) - 没有可用的编码方案(也许可以进行 stringify 或作为列表编码)'
);
}让我们深入探讨这段编码算法的实现。
如果你看一下上面的代码片段,你会注意到所有的条件情况都有标记注释。这些标记的情况在本文中已经探讨过,并展示了如何简单地解决各自的 RLP 编码输出。
如果你查看标记为 (1) 到 (8) 的每个条件案例,你会观察到我们每次都从 encode() 函数调用中返回一个 Uint8Array 数据类型。这个数据类型就是在 JavaScript 中用于定义字节数组的类型(你也可以使用 Buffer 类型来做到这一点,但是,我觉得 Uint8Array 在这个算法的范围内是更优雅的类型)
关于使用 Uint8Array 数据类型,有一点重要的是,字节数组的每个元素变成了范围为 [0, 255] 的十进制字节值。所以,如果你考虑一下,你可以推断出:
- 十六进制值被转换为十进制值(在 JavaScript 中,我们可以将这样的转换建模为
decimal_value = parseInt(hex_value, 16))。 - 字符代码被转换为十进制值(在 JavaScript 中,我们可以将这样的转换建模为
decimal_value = (character_code).charCodeAt(0))。
让我们通过两个简短的示例来看一下这个过程:
示例 1:
记住我们在条件案例示例中计算得到的字符串
"dog"的 RLP 编码是[0x83, 0x64, 0x6f, 0x67]。如果我们实际将"dog"作为输入提供给我们的encode()函数,它实际上会生成Uint8Array(4) [131, 100, 111, 103]的输出。示例 2:
记住我们在条件案例示例中计算得到的字符串
"t"的 RLP 编码是[0x74]。如果我们实际将"t"作为输入提供给我们的encode()函数,它实际上会生成Uint8Array(1) [116]的输出。
如果你简单地将每个输出字节值从十进制转换为十六进制,我们将得到以十六进制表示的字节数组。例如,在示例 2 中,116 的十进制字节值转换为十六进制的值是 74。
让我们迈出一步,检查算法是如何处理嵌套输入的,以及它们如何进行编码。
递归
在代码片段的第 111 行,你可以看到 encode() 函数处理列表输入的部分。
正如你可能记得的那样,从条件案例中走过编码列表及其内容,我们必须首先计算所有列表元素的 RLP 编码,然后才能完全向列表本身提供 RLP 编码的输出。这样做的原因是:
- 我们需要对每个项目 RLP 编码,以构建编码输出的主体.
- 需要查找连接所占用的总字节数。这个连接指的是将每个列表项的 RLP 编码输出拼接在一起。我们需要这个连接的字节长度,以确定可能需要在拼接的负载前添加何种附加前缀字节。
通过这个解释,你可以看到我们是如何遍历列表以对每个单独的列表项执行 encode() 函数调用,因此证明了递归在实践中的应用,直到返回与我们的一种条件案例(或我稍后将解释的附加案例)对应的简单编码输出!
编码算法的帮助函数
我故意没有解释 encode() 函数使用的这些小型自定义函数,因为这对于理解编码算法并不是关键,但它确实在抽象繁琐的代码中发挥了作用。如果你想深入了解或逐步通过代码,你可以将这些方法添加到你连接调试器/会话的任何执行脚本中:
/* 如果提供的字符串以 '0x' 为前缀,则移除并返回新字符串 */
function stripHexPrefix(input: string): string {
if (input.startsWith('0x')) {
input = input.slice(2);
}
return input;
}
/* 将十六进制字符串转换为十六进制字节值数组(以准备插入字节数组中) */
function hexStringToByteArr(input: string): Uint8Array {
input = stripHexPrefix(input);
let arr: string[] = [];
if (input.length % 2 === 0) {
// 如果十六进制数字的数量是偶数 -> 输入不需要前缀以拆分为十六进制字节值
arr = input.match(/.{1,2}/g)! as string[];
} else {
// 如果十六进制数字的数量是奇数 -> 在拆分为十六进制字节值之前添加 0 前缀
arr = ('0' + input).match(/.{1,2}/g)! as string[];
}
// 将十六进制值数组转换为十进制值数组
const decimalArr = arr.map((h) => parseInt(h, 16));
// 从十进制值数组创建字节数组
return Uint8Array.from(decimalArr);
}
/** 检测输入是否为转义的十六进制序列的方法 */
function isEscapedFormat(input: Input): boolean {
if (typeof input === 'string') {
return encodeURI(input[0]).startsWith('%');
}
return false;
}附加案例(不是必须的,但如果这是在你的系统中唯一使用的实现,可能会很好)
这些并不是为了实现 RLP 规范的核心承诺而需要的,但如果例如你将仅在一个仅支持这个特定实现的系统中使用该算法及其解码对, 那会很好。
我会简要列出已解决的附加案例:
- 编码 十六进制转义序列(例如
'x0400') - 编码 任何十进制 整数(例如
10000,0) - 编码 布尔值(例如
false,true)
设计此编码算法受到了什么影响?
从我们深入探讨 RLP 编码算法的具体细节中可以得出的关键几点是:
- 我们计算 1 或 2 个前缀字节,其本质上描述了被编码数据的形状和长度。
- 我们使用字节范围来确定第一个前缀字节的原因是帮助我们区分编码的数据类型及其长度。通过这种方式编码数据,我们节省了空间。
- 尽管我们的编码在内存方面效率高,但这确实带来了 轻微的折衷,解码将需要一些关于编码数据类型的上下文(我们将在未来的博客文章中探讨这个)。
RLP 编码在以太坊中的应用
我们现在已经达到本帖的倒数第二部分,在这里 我们将我们的新 RLP 编码知识与以太坊和区块链的知识结合起来,并来看 RLP 序列化的简要示例!
让我们看看如何计算(或验证)一个 Ethereum 块头,使用块的特定字段的 RLP 编码。
计算(或验证块头)
为了计算一个块头(具体指块的哈希),我们需要 :
- 创建一个特定块数据的元组。
- RLP 编码这个元组。
- 使用
keccak256加密哈希函数哈希 RLP 编码的数据。
第一步中描述的这个元组格式对于 EIP-1559 升级之前开采的块与之后开采的块是不同的。我们将这些不同类型的块称为:
- 传统块(指 EIP-1559 升级之前的块)
- 1559 块(指 EIP-1559 升级之后的块)
对于传统块:
Tuple = [ parentHash, sha3Uncles, miner, stateRoot, transactionsRoot, receiptsRoot, logsBloom, difficulty, number, gasLimit, gasUsed, timestamp, extraData, mixHash, nonce]对于 1559 块(在元组的末尾简单添加新的 baseFeePerGas):
Tuple = [ parentHash, sha3Uncles, miner, stateRoot, transactionsRoot, receiptsRoot, logsBloom, difficulty, number, gasLimit, gasUsed, timestamp, extraData, mixHash, nonce, baseFeePerGas]我为这两种类型各抓取了 1 个区块(并过滤掉了 transactions 属性,因为计算块头时我们不需要这个属性,只需有 transactionRoot )
在未来的文章中,我们可以深入探讨如何使用对交易封装、更多 RLP 序列化和一些梅克尔帕特里西亚树的知识来计算这个
transactionRoot。这将使我们能够验证transactionRoot。
接下来是我们的示例区块:
{
"difficulty":"0x1b315bd824e5e8",
"extraData":"0x65746865726d696e652d75732d7765737431",
"gasLimit":"0xe4e1b2",
"gasUsed":"0xe4dd4b",
"hash":"0x14687ccc4adfd2b0f0d530fc8f8c64dd29ac301ddea26e99087e11d0eae4f575",
"logsBloom":"0x2361a9b76107883d7089e585a3a1422374b21375b8168423507d70b2bccab1a10c5771c82882574255d25bb3c04747e9971ca844ed667b2407dbfb207a24ac5940985ec6f00a0b2c19baaaff217033b63ba7fc2467e64f816ace1764d9e90dd97f5098d2d383ae4951c21952e837eac70290d769b61b275e0a1f75d030382a06e890ef782655601487fc124d274a7626195724f7275409589d2f00e50a5b2914c3db2b5bb1de73284217e0d2f23fa4999a52fa4611e0a005292abd3e5b5d09ff13d12537398412f03416d82181fbb1939965568e078f2f1e65481b8eed3aea90f8f37e99c12fa02500ac1721c2409770d5b52440ab43c050277a2b93357970a7",
"miner":"0xea674fdde714fd979de3edf0f56aa9716b898ec8",
"mixHash":"0x7ae3558891959354b482938e5a61b1d7e371636e5a718137e16753f595531f6a",
"nonce":"0xb81e11f2cb22375e",
"number":"0xc5d40a",
"parentHash":"0x4b0a0331740041e0a110fb20295878a56e3ff9c52b4fabddb3f9ebb56ed664e0",
"receiptsRoot":"0x2922269aa89c5df859a38e168dbdce0e07a7ccb651f9ffcb6c6b1e74eaf7e069",
"sha3Uncles":"0x0eab1b145a087ad364aed20c2a313347afb5eb69ddaef3503f4d5b2c1be7c6c7",
"size":"0x113d2",
"stateRoot":"0xb51018a3b2723021f90de0c0461ea172c4d0477ccdf333d0bc0dad11b689e34c",
"timestamp":"0x610bd4ce",
"totalDifficulty":"0x608a1ed9014008c1d4b",
"transactionsRoot":"0x9b66b32f7d4cf7f5a80614e27ae874879c04136e0a9400c1b59e0cff13f71bec",
"uncles":["0xfc973d2542c05f90e18a1c1b1a484be25505cdcbd81ccf72c70331f85eb52bb0"]
}view raw 传统块(块号 = 12 964 874)
{
"baseFeePerGas":"0x2be5fed13e",
"difficulty":"0x281030ebe089b5",
"extraData":"0x6575726f70652d63656e7472616c322d676e7637",
"gasLimit":"0x1c9c380",
"gasUsed":"0x695d2c",
"hash":"0x01176f73081379cfd9d8bcee1c7e822b66f4d71160900d7f963619c42716cd83",
"logsBloom":"0x0004062c4100100084005220900000011029000028342020009504283640c340d095908023620024402a4d0900184d010a0020061a01a0308000080028a86c422100206024138a081c40181860201d00107a006f100981042888a406c40014a20068001352801028884020010028280842484c2001c80940120001320059000001c28002000003014049440c00026297c010080101ce8008091008312090322c1a0000b9108828042800c09108000c0248021049a9126190022c080a100cb858500c041605210080000000872a160052a2280002862a035210009144004020230010300140040040040c1022199408b0021000086900b0c0002a080210016401",
"miner":"0xea674fdde714fd979de3edf0f56aa9716b898ec8",
"mixHash":"0x151624c46d33ac76f36d3e365487ab78f0a9847f6b16b0775e36a9c9dbb3f520",
"nonce":"0x4b26791bc6ab68d4",
"number":"0xe6bfbf",
"parentHash":"0xdd86ae480441d2a1cf8bc56f0538ddb011933e95b47896239ce73eed41c50cf5",
"receiptsRoot":"0x828db5245f3a45b3bf34eb71f7d6e20b9e205774f490ff3a20a6651594f7c8c4",
"sha3Uncles":"0x1dcc4de8dec75d7aab85b567b6ccd41ad312451b948a7413f0a142fd40d49347",
"size":"0x4df1",
"stateRoot":"0xa1f9461c0a813465ab364d374c19e97988f239dc6295fc77183e9d015dceed2e",
"timestamp":"0x62cc4dd2",
"totalDifficulty":"0xb62e03db7fbd0bb9040",
"transactionsRoot":"0x9dd2ece84725e304409656ab41178a3c90e1c491f0aed0908aa306e1864b3a01",
"uncles":[]
}1559 块(块号 = 15 122 367)
从抓取的数据块中,我们可以看到:
- 传统块 的块哈希是 0x14687ccc4adfd2b0f0d530fc8f8c64dd29ac301ddea26e99087e11d0eae4f575
- 1559 块 的块哈希是 0x01176f73081379cfd9d8bcee1c7e822b66f4d71160900d7f963619c42716cd83我们希望对特定区块数据进行格式化元组的 RLP 编码,因此让我们首先编写一个函数,以便每次接收到区块时生成这种类型的元组:
function prepareBlockTuple(block: IRawBlock): ILegacyBlockTuple|IPost1559Tuple {
const blockNumber = parseInt(block.number, 16);
const tuple = [
block.parentHash,
block.sha3Uncles,
block.miner,
block.stateRoot,
block.transactionsRoot,
block.receiptsRoot,
block.logsBloom,
block.difficulty,
block.number,
block.gasLimit,
block.gasUsed,
block.timestamp,
block.extraData,
block.mixHash,
block.nonce,
];
// 如果是伦敦硬分叉后的区块,在编码前将基础费用添加到区块元组中
if (blockNumber >= LONDON_HARDFORK_BLOCK) tuple.push(block.baseFeePerGas as string);
return tuple as ILegacyBlockTuple|IPost1559Tuple;
}LONDON_HARDFORK_BLOCK 只是常量,表示区块号 12965000,在其中 EIP-1559 开始生效,引入了区块基础费用。
从上面可以看到,我们可以将接收到的任何区块转换为所需的元组,以计算区块头(无论区块类型)。
使用 prepareBlockTuple() 从我们上面的 2 个区块生成的元组如下:
生成的元组 – 中级
// 传统区块(区块编号 = 12 964 874)
[
'0x4b0a0331740041e0a110fb20295878a56e3ff9c52b4fabddb3f9ebb56ed664e0',
'0x0eab1b145a087ad364aed20c2a313347afb5eb69ddaef3503f4d5b2c1be7c6c7',
'0xea674fdde714fd979de3edf0f56aa9716b898ec8',
'0xb51018a3b2723021f90de0c0461ea172c4d0477ccdf333d0bc0dad11b689e34c',
'0x9b66b32f7d4cf7f5a80614e27ae874879c04136e0a9400c1b59e0cff13f71bec',
'0x2922269aa89c5df859a38e168dbdce0e07a7ccb651f9ffcb6c6b1e74eaf7e069',
'0x2361a9b76107883d7089e585a3a1422374b21375b8168423507d70b2bccab1a10c5771c82882574255d25bb3c04747e9971ca844ed667b2407dbfb207a24ac5940985ec6f00a0b2c19baaaff217033b63ba7fc2467e64f816ace1764d9e90dd97f5098d2d383ae4951c21952e837eac70290d769b61b275e0a1f75d030382a06e890ef782655601487fc124d274a7626195724f7275409589d2f00e50a5b2914c3db2b5bb1de73284217e0d2f23fa4999a52fa4611e0a005292abd3e5b5d09ff13d12537398412f03416d82181fbb1939965568e078f2f1e65481b8eed3aea90f8f37e99c12fa02500ac1721c2409770d5b52440ab43c050277a2b93357970a7',
'0x1b315bd824e5e8',
'0xc5d40a',
'0xe4e1b2',
'0xe4dd4b',
'0x610bd4ce',
'0x65746865726d696e652d75732d7765737431',
'0x7ae3558891959354b482938e5a61b1d7e371636e5a718137e16753f595531f6a',
'0xb81e11f2cb22375e'
]
// 1559 区块(区块编号 = 15 122 367)
[
'0xdd86ae480441d2a1cf8bc56f0538ddb011933e95b47896239ce73eed41c50cf5',
'0x1dcc4de8dec75d7aab85b567b6ccd41ad312451b948a7413f0a142fd40d49347',
'0xea674fdde714fd979de3edf0f56aa9716b898ec8',
'0xa1f9461c0a813465ab364d374c19e97988f239dc6295fc77183e9d015dceed2e',
'0x9dd2ece84725e304409656ab41178a3c90e1c491f0aed0908aa306e1864b3a01',
'0x828db5245f3a45b3bf34eb71f7d6e20b9e205774f490ff3a20a6651594f7c8c4',
'0x0004062c4100100084005220900000011029000028342020009504283640c340d095908023620024402a4d0900184d010a0020061a01a0308000080028a86c422100206024138a081c40181860201d00107a006f100981042888a406c40014a20068001352801028884020010028280842484c2001c80940120001320059000001c28002000003014049440c00026297c010080101ce8008091008312090322c1a0000b9108828042800c09108000c0248021049a9126190022c080a100cb858500c041605210080000000872a160052a2280002862a035210009144004020230010300140040040040c1022199408b0021000086900b0c0002a080210016401',
'0x281030ebe089b5',
'0xe6bfbf',
'0x1c9c380',
'0x695d2c',
'0x62cc4dd2',
'0x6575726f70652d63656e7472616c322d676e7637',
'0x151624c46d33ac76f36d3e365487ab78f0a9847f6b16b0775e36a9c9dbb3f520',
'0x4b26791bc6ab68d4',
'0x2be5fed13e'
]从这里我们可以创建一个函数,该函数将接受我们的格式化区块元组作为输入并进行 RLP 编码。之后我们可以通过使用 keccak256 加密哈希函数对 RLP 编码数据进行哈希来生成区块哈希:
import createKeccakHash from 'keccak';
function calculateBlockHeader(block: IRawBlock): string {
const tuple = prepareBlockTuple(block);
const encoded = Buffer.from(encode(tuple));
const calculated = createKeccakHash('keccak256').update(encoded).digest('hex');
return '0x' + calculated;
}查看原始代码
请注意,我从先前定义的 encode() 函数派生了一个 Buffer,这是因为我使用的特定 keccak 库需要 Buffer 输入。
我们可以将以上内容整合在一起,创建一个 verifyBlockHeader() 函数,该函数接受任何区块并通过形成一个区块元组、进行 RLP 编码然后哈希来验证哈希的完整性。我们将计算结果与我们接收到区块时提供的区块哈希进行比较。
function verifyBlockHeader(block: IRawBlock): boolean {
const expected = block.hash;
const calculated = calculateBlockHeader(block);
return expected === calculated;
}这就是使用 RLP 计算/验证任何区块头的一个简单但有用的示例。
结论
这篇文章最终比我最初计划的要长得多,但我很高兴我能把它完成。我非常清楚,encode() 的实现可以得到更好的优化,并且我看到过许多不同的实现,但通过我们定义算法的方式,我认为以这种方式介绍初学者这些概念是有一些价值的。
我绝对不是这方面的专家,如果你有任何反馈或想要指出的更正,请随时提出 👌🏾
我希望你从这篇文章中学到了新的知识,无论是对 RLP 序列化的介绍,以太坊的事实,还是通用的计算机科学和算法相关知识。我为写得不好的地方表示歉意,这是我第一次尝试技术写作 🙃
展望未来,我还有许多主题暗示会在未来的帖子中覆盖,所以如果你想要更多地了解以太坊及其背后的计算机科学,请点赞、关注,并期待我希望提供的更好的内容!
- 原文链接: medium.com/@markodayansa...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





