Groq为何如此快速?Groq的TSP架构概述
- zellic
- 发布于 2024-04-25 14:39
- 阅读 1794
本文深入探讨了Groq的Tensor Streaming Processors(TSP)如何在深度学习工作负载中实现显著的LLM推理速度,重点介绍了其编译时数据传输调度、最佳缓存驱逐策略及TSP同步机制等技术优势。通过与传统CPU/GPU的对比,展示了TSP在确保确定性和提高带宽利用率方面的有效性。
你可能已经看到了 Groq 最近的演示,展示了最先进的 LLM 推理速度。但它为什么如此迅速呢?
我们深入研究了 Groq 的白皮书(令人惊讶的是,非常容易阅读!)以寻找答案。
这篇博客文章改编自原始的 Twitter 线程,可以在 这里↗ 找到。
Tensor Streaming Processors (TSP)与传统 CPU/GPU 的比较
你可能会想,定制处理器怎么会比传统处理器更快,而传统处理器经过了数十年的优化。
答案是,许多优化提高了平均情况性能,但并没有改善最坏情况性能,而最坏情况性能对于实现端到端优化(编译时数据传输调度)更为重要。
主要思想是,他们的处理器(即 Tensor Streaming Processors,以下简称 TSP)以一步步同步的方式执行指令,好像它们是与公共时钟同步的,从而可以在编译时调度数据传输,TSP 使用其指令指针作为隐式时间戳发送和接收数据。
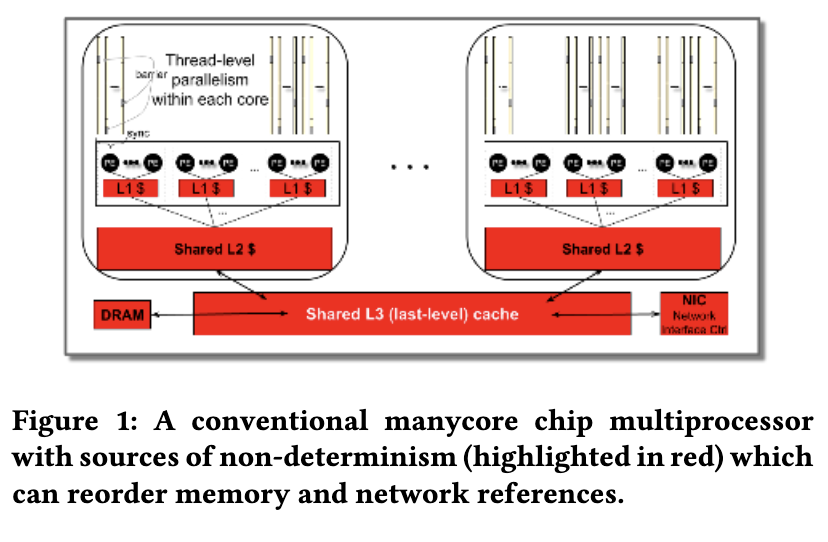
使用传统 CPU/GPU 来实现这一点并不简单,因为它们的优化,如缓存、分支预测和投机执行,引入了指令时序上的非确定性。
TSP 架构为了保证确定性,避免了这些优化,并用比在使用相似工艺制造的传统 CPU 或 GPU 中更多的 ALU 和内存来替换它们。
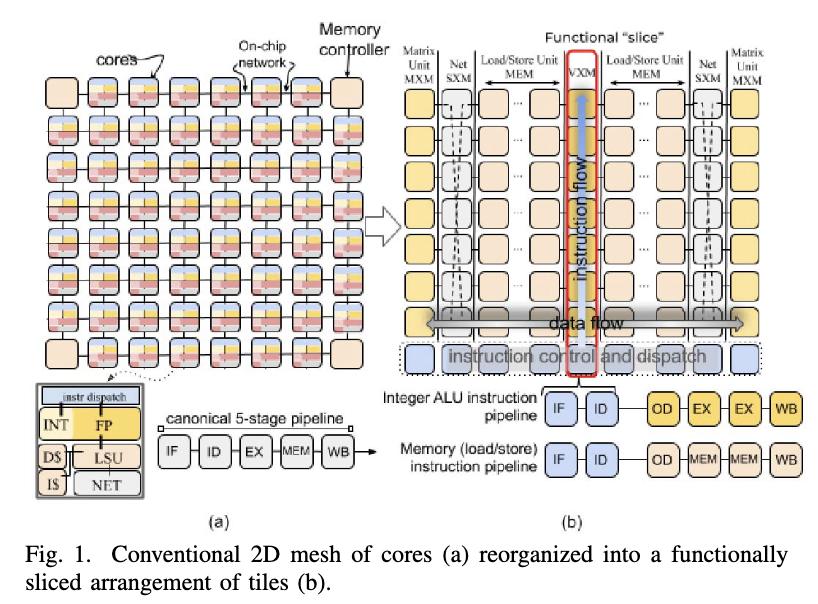
最优缓存驱逐
此外,传统的缓存驱逐策略可能并不能对机器学习工作负载产生最佳效果;通用 CPU 上的缓存驱逐策略试图近似预测程序在未来所需的内存,但对于一般图灵完备的程序而言这是不可判定的。
但是对于许多机器学习工作负载,计算图是提前已知的,因此对于每个程序点所需的内存是可判定的,因此编译器可以明确考虑内存延迟,减少或消除传统缓存的好处。
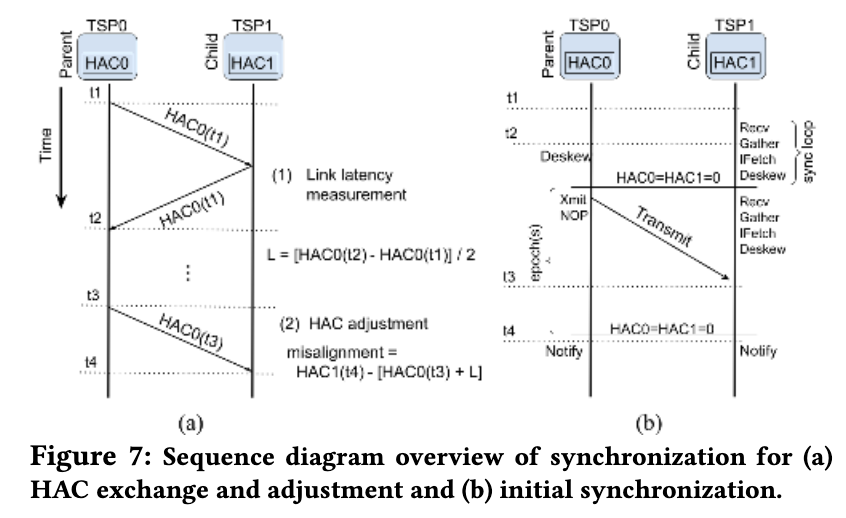
TSP 同步
由于时钟偏斜和物理连接质量仍然存在一定的时序变化,因此 TSP 通过校准一字节计数器以用作直接连接 TSP 之间的共享时钟进行自我同步,使用特定指令将指令流与 TSP 的计数器对齐。
在编译时调度数据传输的一个好处是,TSP 之间更多的物理连接可以同时使用。
具体而言,同时使用 A->B->C 和 A->C 路径比仅使用 A->C 提供了更多的带宽,但如果没有对所有数据流的全局视图,动态路由协议可能会保守行事,不使用 A->B->C,担心这会干扰 B 的带宽的其他使用。
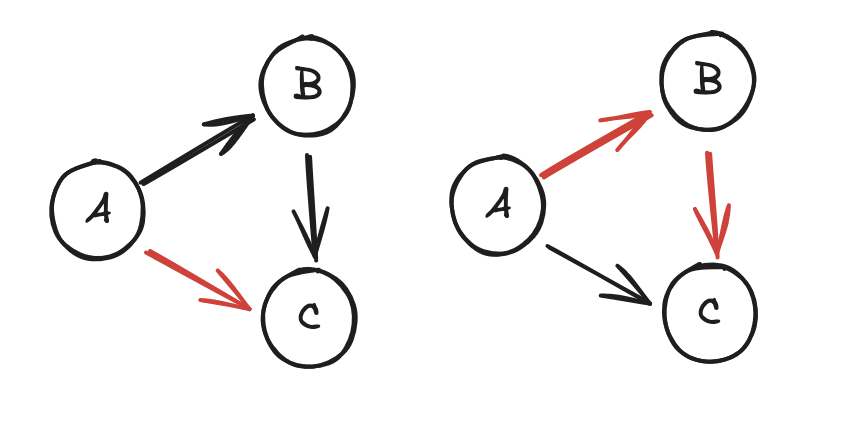
另一个好处是,由于发送 TSP 知道在哪个指令上发送数据,而接收 TSP 知道期望通过哪个指令到达数据,因此运行时不需要任何形式的请求/响应协议消息,这样不仅减少了延迟(消除了一次往返),还增加了带宽利用率(减少了报头大小/消息数量)。

结论
如果你想了解更多,查看这些论文:
- Think Fast: A Tensor Streaming Processor (TSP) for Accelerating Deep Learning Workloads↗
- A Software-defined Tensor Streaming Multiprocessor for Large-scale Machine Learning↗
关于我们
Zellic 专注于保障新兴技术的安全。我们的安全研究人员已在从财富 500 强到 DeFi 巨头的最有价值目标中发现了漏洞。
开发者、创始人和投资者信任我们的安全评估,以快速、自信地发布而没有关键漏洞。凭借我们在现实世界进攻性安全研究中的背景,我们发现了其他人所忽视的内容。
联系我们↗,获取比其他审计更好的审计。真实的审计,而不是走过场。
- 原文链接: zellic.io/blog/groq-tsp-...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





