在ZKsync上Aave V3中发现的关键LLVM编译器漏洞
- Certora
- 发布于 2024-09-10 21:25
- 阅读 1484
本文讲述了在Aave V3激活ZKsync时发现的LLVM编译器的关键优化漏洞,该漏洞可能导致资金被盗。文章详细分析了问题的根源,展示了如何通过手动检查和汇编代码来识别并解决编译器中的错误,强调了在代码校验过程中关注编译器的重要性。
在Aave V3在ZKsync上的激活期间,Aave Labs、BGD Labs、Matter Labs以及Certora发现了一个关键的优化漏洞,该漏洞存在于广泛使用的LLVM编译器中——一个可能导致从Aave在ZKsync实例中抽走资金的漏洞。编译器的错误往往非常棘手,因为许多工具在较高级别的编程代码上运行。在这篇博客中,我们将分享我们如何追踪问题至其根本原因。
背景
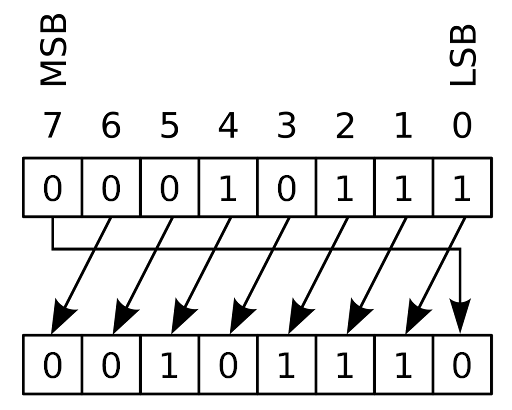
问题隐藏在管理UserConfigurationMap的代码中。用户的UserConfigurationMap记录了每个储备,无论用户是否从该储备借款或将其用作抵押。实际的“映射”(self.data在片段中)实际上是一个uint256的位掩码,其中顺序对的位表示每个储备的借款/抵押状态。因此,该映射的两个最低有效位记录索引为0的储备的抵押/借款状态,接下来的两个有效位记录索引为1的储备的状态,依此类推。在每一对中,最低有效位表示借款状态,最高有效位表示抵押状态。图形上,用户配置映射的布局如下,最低有效位位于图的右侧:

每个颜色组代表单个储备的状态;每个组内的c位表示该储备的抵押状态,b位表示借款状态。
函数setBorrowing更新用户的UserConfigurationMap。下面是其代码的简化版本。
function setBorrowing(
DataTypes.UserConfigurationMap storage self,
uint256 reserveIndex,
bool borrowing
) internal {
uint256 bit = 1 << (reserveIndex << 1);
if (borrowing) {
self.data |= bit;
} else {
self.data &= ~bit;
}
}我们可以看到,我们首先计算与reserveIndex索引的储备的借款状态对应的位。这个操作是通过将二进制数字1向左移动两位来实现的(回想一下,reserveIndex << 1等价于reserveIndex * 2)。在移位操作后,我们得到了一个位掩码,其唯一设置的位位于所指储备索引的借款标识的位置。如果我们被请求设置借款状态(即借款参数),那么我们简单地将这个位按位或到现有的配置映射中;换句话说,我们将self.data中的借款位设置为1,而不改变其他所有位。
清除借款状态的情况应用按位_与_操作到配置映射(即self.data)和该位的按位非操作。回想一下,该位是一个位掩码,在除所指出的储备的借款位索引外其他所有位均为0。应用按位非将产生相反的位掩码:即除了在储备的借款位处为0外,所有位均为1。通过按位_与_操作将该掩码应用于用户映射,能够使所有状态位保持不变,除了相关的借款标识被设置为0。
这个过程通过在reserveIndex为3的示例下可视化:

在这个清除操作中出现了异常:在清除储备的借款位后,观察到所有状态标识(包括借款和抵押)的低位(即较低有效位)实际上被清除了。其影响令人震惊:如果某个储备不再被标记为用户的抵押品,他们的仓位可能被认为是不健康的,导致清算。更令人担忧的是,如果资产未被正确标记为借款或抵押,系统可能错误地允许清除抵押,这可能会危及到整个系统的偿付能力。
如何通过手动检查找到编译器错误
首要任务是找到被执行并导致此异常的低级字节码的人类可读文本表示。幸运的是,ZKsolc编译器生成了编译字节码的汇编表示,这是编译的一个正常组成部分。
一旦我们知道如何阅读编译器的输出和汇编格式的文本描述,我们就可以开始搜索负责的字节码。然而,我们并没有立即开始查看受影响的Aave合约的汇编。即使找到负责设置/清除借款位的汇编代码也主要像是在大海捞针。相反,我们将受影响的核心代码提取到一个更小的自包含测试合约中:
contract Test {
mapping(address => DataTypes.UserConfigurationMap) s;
mapping(address => uint) loanAmt;
function doIt(uint res, uint loanValue) external {
DataTypes.UserConfigurationMap storage ref = s[msg.sender];
UserConfiguration.setBorrowing(ref, res, loanAmt[msg.sender] == loanValue);
loanAmt[msg.sender] -= loanValue;
}
function borrow(uint res, uint loanAmount) external {
bool isFirstBorrowing = loanAmt[msg.sender] == 0;
loanAmt[msg.sender] += loanAmount;
if(isFirstBorrowing) {
UserConfiguration.setBorrowing(s[msg.sender], res, true);
}
}
function supply(uint res, uint amount) external {
UserConfiguration.setUsingAsCollateral(s[msg.sender], res, amount == 0);
}
}每个函数的实际逻辑是无意义的;它只是以不同的方式使用UserConfigurationMap库。
在阅读了相对较短的汇编代码后,我们找到以下片段:

将其翻译成伪代码,我们得到:
r3 := r2 << 1
r2 := 1 << r3
r3 = storage[r6]
r4 := 0 - 1
r2 := r4 ^ r2
r2 := r3 & r2
storage[r6] := r2前两个操作看起来非常像我们期望见到的1 << (reserveIndex << 1)。后面的几个操作有些困难理解,但最终执行了按位非操作。0 - 1的减法下溢成为全1的位掩码,这个位掩码与借款位的位掩码r2进行异或,因此得到的是r2的反面:除了在借款索引下的一个0外,其他地方全为一。最后,这个位掩码通过按位与操作应用到从storage (r3)中读取的值,随后再次写回到存储中的同一location (r6)。
这给予我们一个指纹来识别原始Aave合约中的“清除借款标志”操作。特别是,我们然后查找shl.s 1, rX, rY,因为这可能对应于(reserveIndex << 1)。为了进一步缩小搜索范围,我们还检查了此计算是否大致跟随着以下汇编模式:
sload rA, rV
// compute bitmask rM with rY
rV := rM & rV
ssstore rA, rV这即是看起来像是“计算借款位”的值与从存储中读取的值结合,生成另一个位掩码,并通过按位与操作进行组合。
这次搜索只收获了一个结果:
shl.s 1, r1, r1
rol @CPI0_60[0], r1, r1
sload r3, r2
and r2, r1, r1
sstore r3, r1rol是“左旋转”的操作;与常规左移不同,被移出最左边的位被移进最右边,从而保留顺序。例如,当位宽为8时:rol 0b0010111, 1将生成0b00101110(此处和后面0b将指代二进制中的字面数字)。
被旋转的操作数@CPI0_60[0]是一个常数18446744073709551614。在十六进制中,这是0xFFFFFFFFFFFFFFFE,表示63个1位后跟一个0位。我们现在可以开始看到这个错误是如何形成的。如果我们在64个寄存器上工作,将这个常数向_借款位_索引的储备依次旋转左移(即reserveIndex << 1)的效果与将常数1左移并应用按位非相同。
换句话说,而不是将单个1左移并随后翻转所有的位,以便为我们想要清除的位创建一个“孔”,我们已经预先创建了一个孔,然后将其旋转到正确的位置。这个过程在我们之前的示例中得到了可视化(使用假设的位宽为10)和储备索引为3:

在这里,六个位的深红色从位掩码的左侧移出并置于右侧。当掩码与原始标志组合时,我们可以看到仅储备索引3的借款标志被清除。
不幸的是,ZkEVM并不在10位或64位寄存器上运行,而是使用256位寄存器。这个左旋转的移位技巧仅在常数左旋转时,如果在常数中所有的256位均设置为1,除了最低有效位之外才会有效。换句话说,我们希望得到0b11111…11110。然而,常数仅宽64位,因此其余192个位被隐式填充为0。所以在字节码中使用的常数实际上是0b00…0011…110。当这个掩码被左旋转时,将被清除的借款索引下方的位也将是0;上面的0位被从左侧移出并移到右侧。因此,清除一个储备的借款状态就会清除所有小于索引的状态标志。
为了确认我们的发现,我们修改了原始Aave代码,进行相应的计算,但以极其迂回的方式,以避免这种优化[1]:
uint256 orig = self.data;
uint lowerMask = bit - 1;
uint lowerData = orig & lowerMask;
uint toClear = orig >> (reserveIndex << 1);
uint clearLowerBitMask = 1;
clearLowerBitMask = ~clearLowerBitMask;
uint cleared = toClear & clearLowerBitMask;
uint shiftedBack = cleared << (reserveIndex << 1);
uint newValue = shiftedBack | lowerData;
self.data = newValue;用这个新实现重新运行编译器,得到了类似位置的汇编代码,但没有rol指令。这证实了多个工作假设,即:
- 原始
rol汇编片段确实对应于这个有问题的setBorrowing实现。 - 问题的行为是由于编译器优化造成的。
我们将我们的发现与Aave Labs、BGD Labs和Matter Labs.分享。Matter Labs随后能够准确找出LLVM中的一个错误,该错误最近被修复;一个LLVM优化通过未正确考虑架构位宽(因此使用的常数适用于64位架构,但不适用于256位架构)。
收获
开发人员和安全研究人员在分析代码正确性时常常忽视编译器,因为代码本身中的逻辑错误通常是重点。然而,我们刚呈现的案例证明了编译器错误虽然较为少见,但也无法被忽视。即使是广泛信任的编译器,例如LLVM,也不能免于引入关键错误。
在验证代码的正确性时,至关重要的是确保分析是针对实际可执行代码而非抽象表示(如高级源代码)进行的。无论你使用测试、模糊测试还是形式验证,你选择的工具都必须直接对字节码操作,以提供可靠的结果。这确保了验证过程反映生产中代码的真实行为。
此外,在编译字节码时,至关重要的是使用完全符合生产要求的参数,包括优化级别和链接的库。每个这些参数都可能显著改变生成的字节码,可能引入不可预见的问题。即使是微小的变化,我们也必须小心谨慎,始终质疑我们代码的完整性,以防止隐藏的错误。
我们要感谢Aave、BGD Labs和ZKsync团队在应对此问题上的合作。
[1] 一个合理的问题是,为什么rol模式没有出现在简化测试中。虽然我们无法在本例中提供确切的答案,但编译器通常会根据周围的上下文应用这些优化(所谓的“窥视优化”),而我们的测试合约可能并没有这种上下文。
- 原文链接: certora.com/blog/llvm-bu...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





