ICICLE-Stwo 简介:一种 GPU 加速的 Stwo 证明器
- ingonyama
- 发布于 2025-02-07 20:31
- 阅读 1689
Ingonyama 与 Starkware 合作,通过 CUDA 后端加速 Starkware 的 Stwo 证明器,在不改变 Stwo 前端设计的前提下,ICICLE-Stwo 在多个 CPU/GPU 配置中实现了比 Starkware 优化后的 SIMD 后端 3.25x-7x 的性能提升. ICICLE-Stwo 仓库完全开源,可直接替换标准 Stwo 证明器。
介绍 ICICLE-Stwo: 一个 GPU 加速的 Stwo Prover
简而言之:
这个项目的目标是向 Starkware Stwo prover 添加一个 CUDA 后端,而不对 Stwo 的前端设计进行任何更改。
这里我们概述了集成的进展,分享了性能指标,并展望了未来的增强功能。在众多的 CPU/GPU 配置中,ICICLE-Stwo 表现出比 Starkware 经过大量优化的 SIMD 后端 3.25x–7x 的性能提升。ICICLE-Stwo 仓库是完全开源的,可以作为标准 Stwo prover 的直接替代品。
从 Circle STARK 到 ICICLE 中的 Stwo 加速
我们与 Starkware 的合作始于 2023 年。我们首先在 2024 年 8 月宣布了我们围绕 Stwo prover 加速的 战略合作伙伴关系。
Stwo 是 Starkware 开发的新一代 prover 技术,基于 Circle STARK 的突破性工作。作为 GPU 加速的第一步,我们需要使用基于 M31 的多项式算术支持来扩展 ICICLE 库。

Circle STARK 带来了几个我们需要适应 GPU 使用的新原语,包括离散圆形曲线变换 (DCCT),它的作用类似于 NTT。
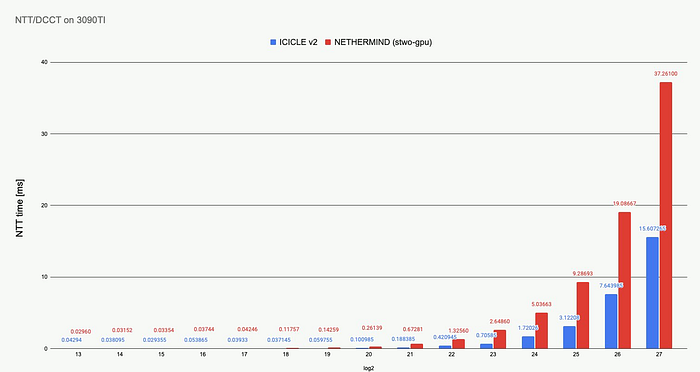
ICICLE DCCT 与 Nethermind DCCT ( reproduce)
有了这些资产,我们继续进行集成。
早期集成:稻草人解决方案
当我们开始为 Stwo 集成 ICICLE 时,策略是使用 ICICLE 的方法,并用 ICICLE 结构替换 Stwo 中现有的机制。任何 CPU-GPU 集成的主要挑战之一是使用非统一内存架构,这通常会导致浪费时间在两个平台之间来回复制数据。另一个相关的问题是由于冗余抽象,需要在平台之间移动时转换数据,这通常被 CPU 软件语言所利用。我们的第一次尝试惨败。超过 90% 的时间都花在了传输上。
构建在 Stwo 的后端 Trait 之上
由于 Stwo 已经使用 Rust traits 构建了一个后端,该后端是为 CPU 和 SIMD 后端实现的,因此我们决定再次在这个后端的约束下完成这项任务。在后端之外进行更改是可行的,但也会完全改变 Stwo 框架,从而导致两个独立的实现。我们严格按照以下条件进行工作:只有 Stwo 后端结构会受到集成的影响(所有前端代码保持不变)。
我们的实现基于示例:
test_wide_fib_prove_with_blake() 在 "crates/prover/src/examples/wide_fibonacci/mod.rs" 中。
该示例生成一个跟踪,将其添加到 CommitmentSchemeProver 的一个实例中,对其进行扩展并提交。CommitmentSchemeProver 的实例以及 Fiat Shamir (FS) 通道的实例和跟踪组件约束的描述被传递给 prove() 函数以生成证明。
在证明之前,我们生成跟踪。跟踪是 M31 元素的列的集合。它通常是构造证明所需的最大数据结构之一。它用于构造证明,但不是最终证明输出的一部分。因此,最合理的做法是在 GPU 中生成它,或者在生成后立即复制一次,并在 prove() 函数的范围内保持指向它的指针。重要的是要注意,我们的设计假设所有内存结构都可以存储在 GPU 的全局内存中。对于跟踪大小小于 3GB 的证明,此限制应该不会有问题。更大的证明需要稍微不同的处理方式,这通常会影响前端,目前超出了范围。
后端的基本虚拟结构是 Col<T>,它实现了 T 类型元素的列。为 GPU 实现这一点使我们能够直接在 GPU 中对此数据结构(及其扩展)使用 ICICLE 机制,这非常有效。Stwo 实现中的第二个基本结构是 SecureColumnByCoords,它表示安全字段元素的列(安全字段元素是 M31 基字段的第四个扩展,即 QM31)。与 Col<T> 不同,SecureColumnByCoords 不是以虚拟方式实现的,而是强制实现 _Col<T> 的_数组。从本质上讲,ICICLE 在字段元素的列上工作,因此对于安全字段元素,自然的 ICICLE 机制是将其实现为 Col<QM31>,但 Stwo 的实现迫使我们重写一些结构来支持这种多个 M31 列的表示形式。可以通过虚拟化 SecureColumnByCoords 来避免这种情况,但正如我们所说,这超出了范围。一旦 Col<T> 和 SecureColumnByCoords 结构都在后端实现,并且所有后端函数都调整为可以使用它们,一切就到位了。
以下是过程中涉及的主要内存结构列表:
1. 跟踪 —— M31 列的集合,可能被分组到几个称为组件的组中。
2. 组合多项式 (CP) —— 几个 M31 列的集合,每个跟踪组件四个。
3. 域外 (OOD) 样本 —— QM31 样本的集合,每个查询中每个跟踪和 CP 列最多两个。
4. 商多项式 (QP) —— 几个 QM31 列,每个跟踪组件一个,CP 一个。
5. 跟踪、CP 和 QP 的 Merkle 树承诺。
证明的输入是跟踪及其组件的约束,输出是来自已提交的 Merkle 树的多个路径以及 OOD 样本。因此,大部分数据(见下文)只能存在于 GPU 上,并在完成证明后丢弃。下图示意性地描述了这一点。

ICICLE-Stwo 的 CPU-GPU 示意图
性能分析
以下是在 i9–12900k + 3090Ti 平台上执行 test_wide_fib_prove_with_blake() 的配置。
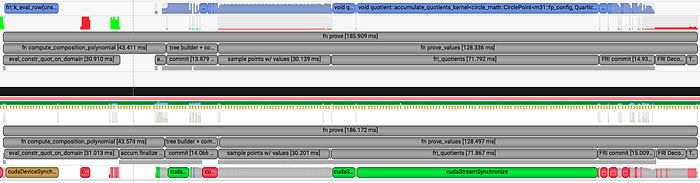
现在让我们分解一下配置:
函数 fn-prove 对应于完整的证明生成,不包括跟踪。跟踪及其 Merkle 树承诺是在 fn-prove 之前生成的。fn-prove 的第一部分是 fn-compute_coposition_polynomial。此部分有三个硬件选项:CPU、SIMD 或 GPU。上面描述的 GPU 版本目前受到限制,不支持查找(见附录),但优于 CPU 和 SIMD。它仍然占证明的四分之一左右,并且仍有很大的改进空间。
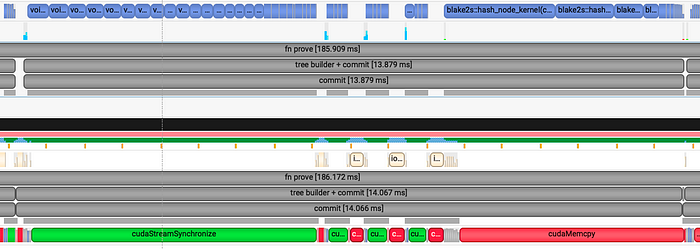
下图显示了 CP 的 Merkle 树构造。显而易见的是,配置由 CUDA 内核执行(蓝色块)主导。这里可以改进的一件事是前半部分时间,其中为 DCCT 操作生成旋转因子。这些旋转因子可以在设置阶段生成,并在以后根据需要使用。
OOD 采样,如下图中的放大图像所示,是下一个阶段。此函数大约占用运行时的五分之一,并且仍然可以大大改进。一个简单的改进,可能会将此减少十倍,是将当前采样循环从前端移动到后端(参见此 PR)。这将允许并行计算所有样本,从而实现更好的 GPU 利用率。

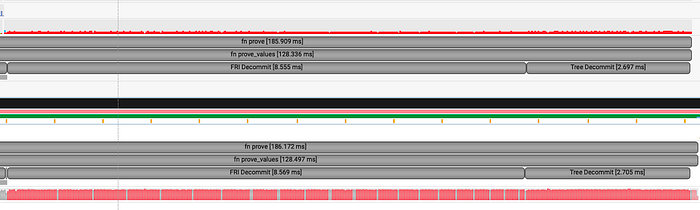
FRI 商数和 FRI 提交已经由 CUDA 内核执行主导,如下图所示。因此,FRI 可能会从进一步的内部内核并行化中受益。

最后一个配置快照是取消提交逻辑,其中证明元素被复制回 CPU。
最后,我们注意到可以进行进一步的优化以支持批处理。我们将在下面的基准测试中演示这一点。
运行时比较
我们将 ICICLE-Stwo 与 Starkware SIMD 和 Nethermind Stwo-GPU 进行了比较。我们在四台机器上运行基准测试,每台机器都有不同的 CPU 和 GPU。
我们对 test_wide_fib_prove_with_blake() 进行了单次运行的基准测试。原始数据和关于如何重现的说明可以在以下 电子表格 中找到。
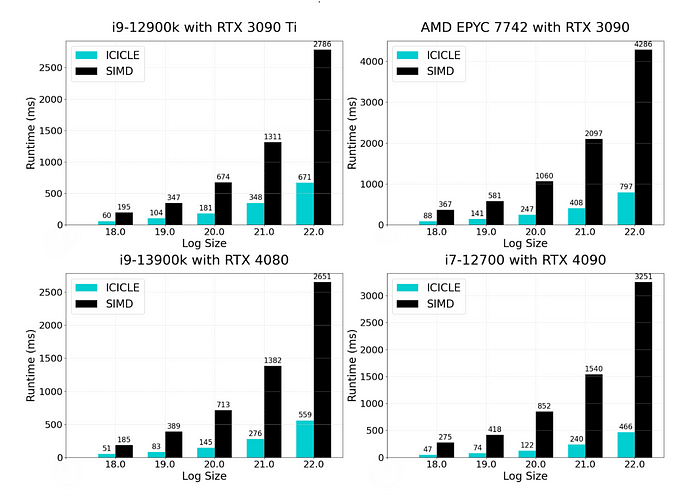
具有不同设置的 SIMD-Stwo 与 ICICLE-Stwo
笔记:
- ICICLE-Stwo 正在使用 GPU 进行复合多项式运算(见下面的附录)。使用 SIMD 后端会导致稍微慢的结果
- ICICLE-Stwo 从 2²³ 开始出现 OOM 错误。正如我们上面所说,这可以处理。对于相同的跟踪,Stwo-GPU 已经从 2²⁰ 开始出现 OOM 错误。
- 当我们从 128 列增加到 1024 列时,与 Stwo-GPU 相比,加速效果越来越小,这表明我们的代码中缺少批处理优化。
附录 —— 在 GPU 中运行复合多项式的查找
我们的配置中使用的斐波那契示例没有使用查找,因此受到限制:例如,Cairo 编译的程序可能会使用查找。
缺少的功能会影响评估函数 compute_composition_polynomial() 中涉及查找的跟踪约束的能力,该函数位于 "crates/prover/src/core/prover/mod.rs" 中。在 GPU 上扩展此功能是可行的,但目前超出了范围。
作为替代方案,我们提供了一个选项,仅对 compute_composition_polynomial() 使用 Stwo 的 SIMD 后端。此选项使我们能够利用 SIMD 提供的加速,而不会影响前端代码,也不会限制查找功能。这应该重新审视,因为 GPU 加速比 SIMD 提供更好的性能:在我们当前的实现中大约快 2 倍。
致谢
Starknet 基金会为该项目的工作提供了支持。
延伸阅读
作为 Circle Starks 加速工作的一部分,我们也发布了我们的 RC-STARKs 论文。
关注 Ingonyama
Twitter: https://twitter.com/Ingo_zk
YouTube: https://www.youtube.com/@ingo_zk
GitHub: https://github.com/ingonyama-zk
LinkedIn: https://www.linkedin.com/company/ingonyama
加入我们: https://www.ingonyama.com/career
Snark Chocolate: Spotify / Apple Podcasts
- 原文链接: medium.com/@ingonyama/in...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





