以太坊 - 介绍 kona
- clabby
- 发布于 2024-06-25 15:50
- 阅读 1047
OP Labs 团队发布了 kona 的 MVP,它是一套便携式的、no_std Rust 实现的 OP Stack rollup 状态转换。kona 包含 OP Stack 的第一个替代故障证明程序,为 OP Stack 的第二阶段去中心化提供了一个关键的冗余。
介绍 
今天,我和 @andreaslbigger 很高兴地宣布 kona 的 MVP,它是一套可移植的、no_std Rust 实现的 OP Stack rollup 状态转换。
6 月初,我们在 OP Labs 的团队发布了 OP 主网上的 第一阶段里程碑。本周,kona 仓库包含了 OP Stack 的第一个替代 Fault Proof Program,在整个 OP Stack 通往 第二阶段去中心化 的道路上,为证明系统提供了一个关键的冗余部分。
它如何工作?
在高层次上,验证关于 DA 层上 OP Stack L2 状态的声明的正确性包括引导可信输入,导出 L2 链的输入,无状态地执行导出的输入,最后根据生成的 L2 链断言 L2 声明的正确性。
该过程被建模为三个独立的阶段,如下所述。
序言
我们首先引入 L1 上的 争议合约 声明的几个输入:
- [TRUSTED] 一个 L1 区块哈希,其高度包含发布到 L1 的批量数据,用于在 L2 状态声明的高度重现链。
- [TRUSTED] 一个 L2 output root,用于确定推导过程中起始的 L2 safe head。
- [PROPOSER-SUBMITTED] 以下 output root 声明的 L2 区块号。
- [PROPOSER-SUBMITTED] 在上述区块高度声明的 L2 output root。
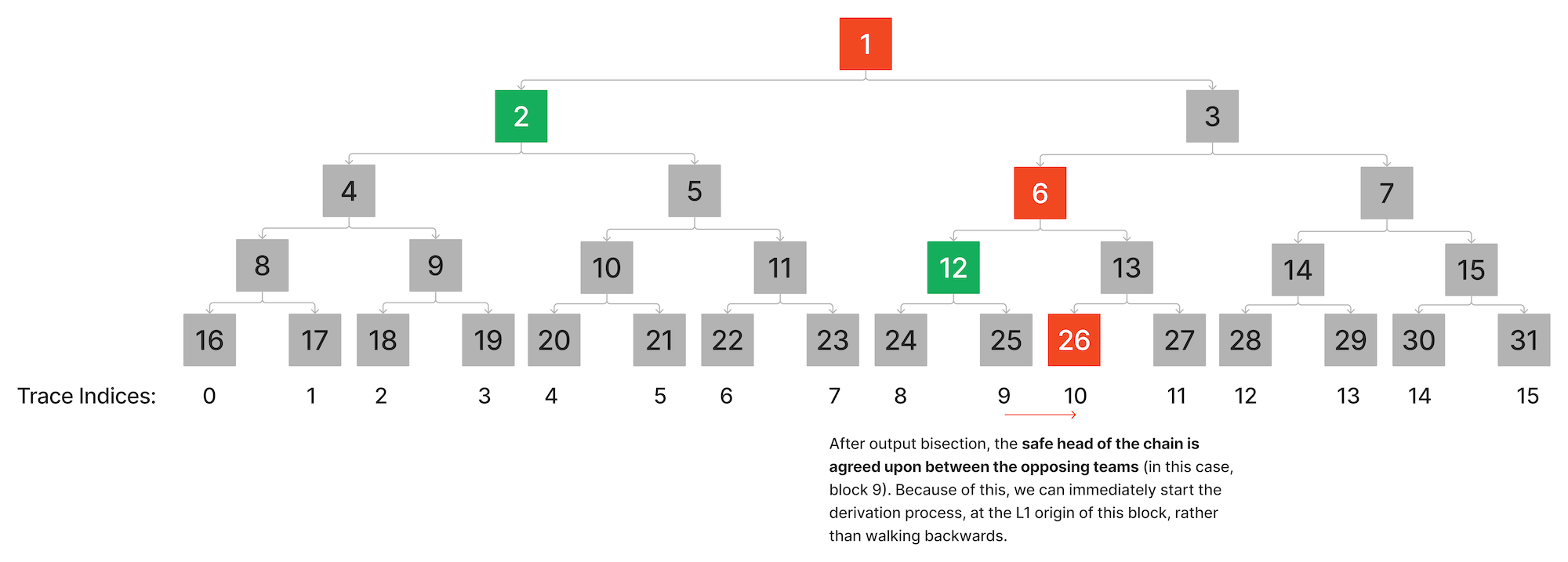
起始 L2 output root 可能会在链上的争议中被平分,以减少程序中的推导 + 执行需求。这个额外的平分阶段,已经存在于实时系统中,允许我们将必须执行的区块范围从 ( previous_finalized_proposal_block,disputed_proposal_block] 减少到 ( disputed_proposal_block - 1,disputed_proposal_block]。
执行
程序的执行阶段分为两个同步执行的子程序:推导(查看可信的 L1 状态)& 无状态的 L2 区块执行(查看 + 扩展可信的 L2 状态)。
推导
执行阶段的开始涉及从 L1 上可用的 批量数据 中推导出 L2 链输入。在这个过程中,通过以相反的顺序提供 L1 区块哈希的 preimage 见证,从序言阶段检索到的可信 L1 区块哈希开始,找到 L2 output root 声明的 L1 origin 区块。
一旦达到 L2 output root 声明的 L1 origin 区块,推导 就会向前推进,直到产生有争议的 L2 Execution Payload,可验证地从 L1 标头中的交易根和收据根获取交易和收据数据,以及从 batcher 提交的 EIP-4844 交易中的 IndexedBlobHash es 中获取 blobs。
L2 执行
一旦推导管道从验证的 L1 数据中产生了有争议的 L2 执行负载,那么从 prestate header(在可信的起始 output root 中提交)开始,无状态地执行有争议的 L2 区块。对于那些不熟悉的人来说,这个过程与标准 EL 中的常规区块执行几乎相同,但不是在快速数据库中访问执行期间触及的状态,该数据库了解先前验证的数据,而是通过为全局 Ethereum 状态 trie + 帐户存储 tries 中所有访问的帐户/存储槽提供 MPT 证明来可验证地获取它。 此外,必须在 trie 节点删除期间显示的任何哈希兄弟节点的前像都包含在此见证中,以便在区块边界上成功计算状态根。
这个子程序的结果是有争议的 L2 区块的规范区块头,它由在序言阶段检索到的两个可信承诺中提交的数据构建。
尾声
一旦在执行阶段产生了有争议的 L2 区块的区块头,最后一步是从生成的标头 + 有争议的区块执行后 L2ToL1MessagePasser 合约的帐户存储根计算 L2 Output Root。
最后,在序言阶段检索到的 output root 声明和指定的 L2 区块高度将根据生成的输出进行验证,其中可以明确地验证或取消验证提交者提交的声明。
kona Fault Proof Program 基准测试
针对原始的 op-program 对 kona 进行了多项优化,即 eth_getProof 支持以减少 RPC 命中,并减少了执行阶段推导子程序期间执行的初始 walkback 范围。 如今,fault proof program 能够成功验证 L2 output root 声明,并在 asterisc Fault Proof VM 上本地运行。
以下所有基准测试均在配备 64GB 统一内存的 M1 Max Macbook pro 2021 上执行,以 racing 线程本地运行 kona-client 和 kona-host。 客户端程序和主机程序都是使用面向性能的 release 配置文件编译的。正在推导 + 执行的区块是 OP Mainnet 上的区块 #121449098。
kona-client 基准测试,本地运行:
无缓存(咨询本地节点获取数据,低延迟。使用内存中的 k/v 存储):

带缓存(之前执行过 dry run,持久化所有 preimages。访问磁盘而不是 RPC):

op-program 基准测试,在同一台机器上,也本地运行:
无缓存(咨询本地节点获取数据,低延迟。使用内存中的 k/v 存储。省略 Datadir 标志以强制内存 k/v 存储):

带缓存(之前执行过 dry run,持久化所有 preimages。访问磁盘而不是 RPC - 省略 RPC 标志以强制 FetchingEnabled):

未来是 ZK 吗?
构建 kona 的组件时考虑了替代后端支持,从从头开始将它们构建为 no_std w/ alloc enabled 库开始,以促进裸机 LLVM 目标之间的可移植性。当归结为可验证程序的高级问题时,在 zkVM 上运行的程序与 Fault Proof VM 之间的最根本区别在于:
- 对于在 Fault Proof VM 上执行的程序,主机 <-> {客户端/访客} 通信可能会即时发生,而 zkVM 要求程序的执行器预先拥有完整的见证。
- 对于在 Fault Proof VM 上执行的程序,从主机检索到的数据可以假定为可信的,因为主机的链上实现(
PreimageOracle.sol)在进入时验证其中的所有数据。 相反,在 zkVM 上执行的程序必须在可验证执行环境的上下文中验证见证数据的正确性,以便完全约束证明。
考虑到这一点,kona 中的所有组件都已从其数据源中抽象出来,从而使其能够适应在各种上下文中执行。 例如,kona-derive 附带了 trait 抽象的数据源,允许下游使用者简单地维护这些 trait 的替代实现,而无需 fork。 一个明显的例子可以在这些 trait 的 online 实现中找到,以及 fault proof program 的 offline,PreimageOracle-backed 实现。
到目前为止,此策略运行良好,从而实现了大量的代码重用。 我们与 Succinct Labs 密切合作,为基于 kona 库构建的 ZK 程序的向前兼容性奠定了坚实的基础,我们非常感谢他们帮助构思了它的样子!
目前,Succinct Labs 团队与 @ZachObront 一起,也在开发 kona 的第一个 zkVM 后端。 到目前为止,他们已经发布了此后端的 MVP,使用 kona-host 生成所有见证数据,并在 SP-1 中使用生成的见证运行 kona,以便为该区块生成完整的证明。
OP Stack 多重证明
正如 OP Labs 之前的一篇 多重证明博客文章 中指出的那样,kona 只是我们希望为 OP Stack 开发的更广泛的多重证明系统中的一个组件。 在提款路径中聚合多个证明可以实现 L2 beat 对“第二阶段去中心化”的定义的一个关键部分,即安全委员会的行为必须仅限于“链上的、可证明的错误”。 多个证明在输出提议的有效性上存在分歧可能会满足此要求。
通过利用 OP Stack 现有的客户端多样性,kona 引入了状态转换函数的替代实现(基于 op-reth、revm 和 kona-mpt)和推导(kona-derive),从而为基于 op-geth + op-node 的 op-program 增加了冗余。
将来,借助 kona 和辅助 FPVM asterisc(由 @protolambda 和 Sunnyside Labs 开发),我们希望将 OP Stack 提款路径的安全模型从以下内容转移到:
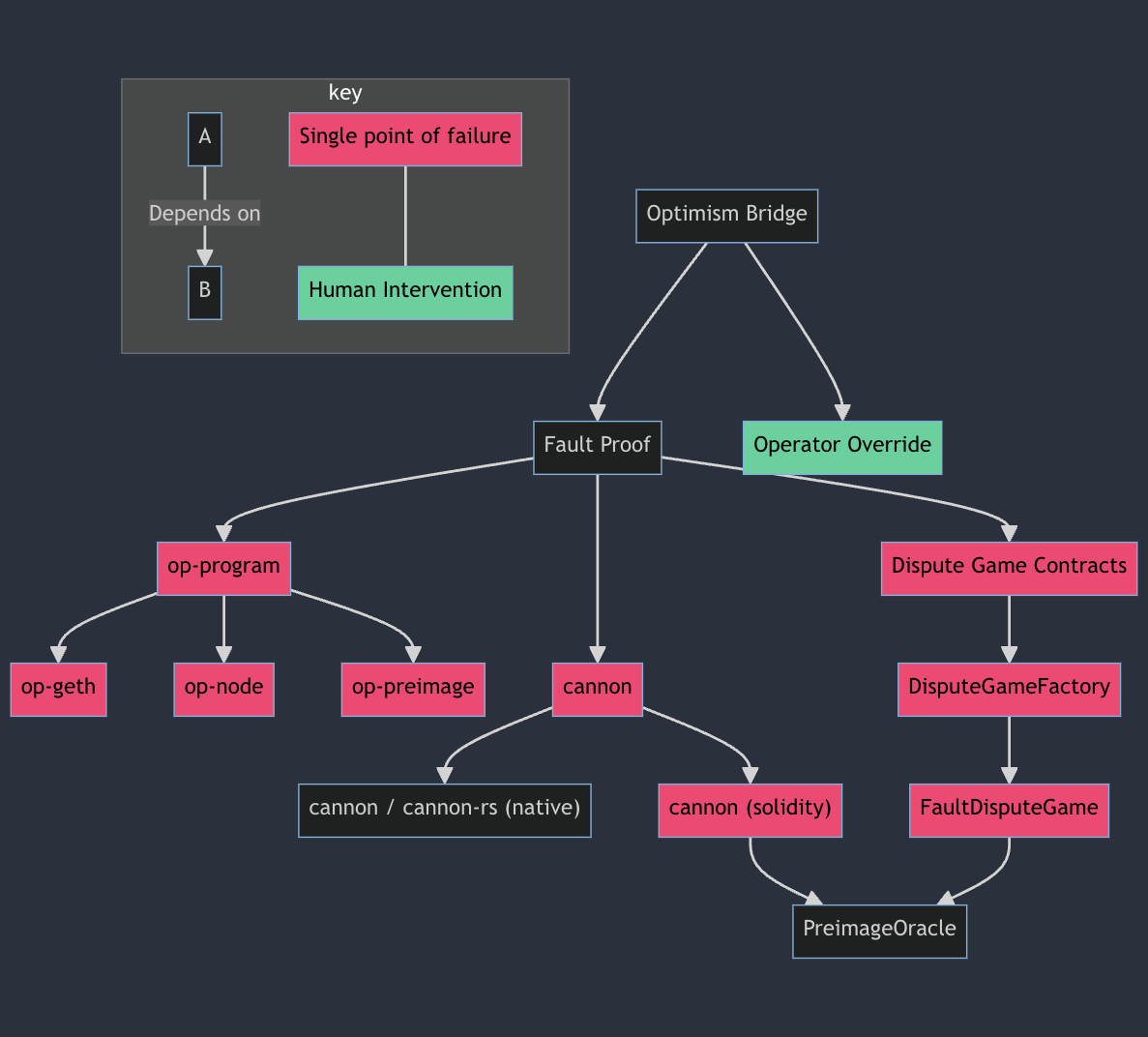
到这个:
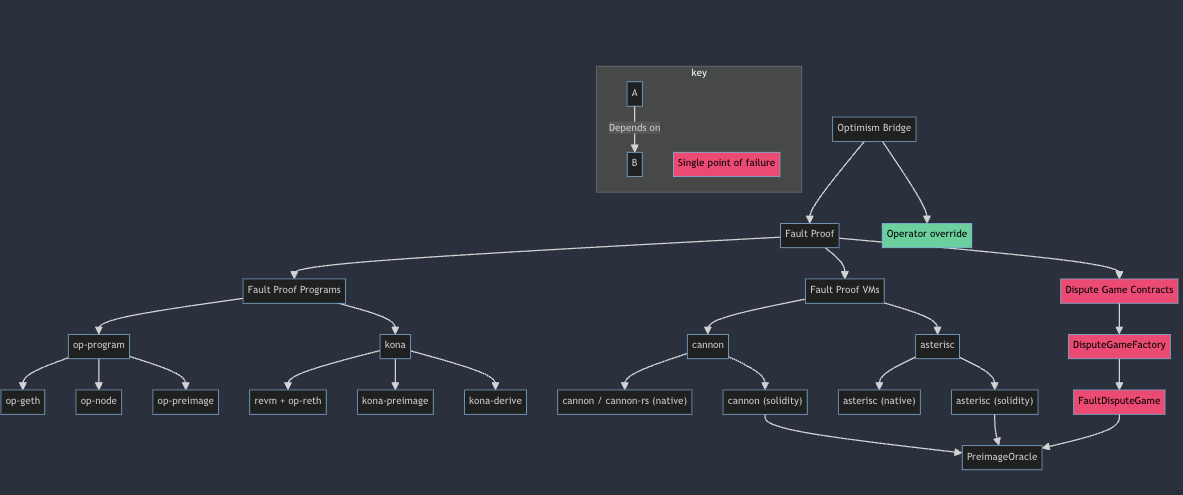
……并且可能会最终扩展到包括 ZK 证明 😉
接下来是什么?
- 继续迭代
kona,消除错误并生产现有的 MVP。 - 为 OP Stack 开发一个共识测试套件,允许针对共识关键代码路径的各种实现执行一组常见的测试向量。
- 更多
kona的 FPVM + zkVM 后端!- 记录构建替代后端的过程。
锦上添花
- 使用
kona-derive作为rethExecution Extension 开发替代 Rollup Node 实现。 - 激活了多重证明的 Reth AlphaNet,充当长期存在的测试环境。
你如何贡献?
除了查看 现有问题 之外,kona 的贡献指南可以在 book 中找到。
我们期待让更多的社区参与到开发过程中!
鸣谢
kona 的灵感和启用来自几个团队的工作:
- OP Labs 和其他贡献者在
op-program上的工作 - Paradigm 不断改进和支持我们最初的
op-rethdiff - Dragan Rakita 不断改进和支持我们最初的
revmdiff - BadBoiLabs 在 Cannon-rs 上的工作
特别感谢
非常感谢迄今为止为 kona 做出直接贡献的所有人:
- 原文链接: hackmd.io/@clabby/B1H79b...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





