Sig 工程 - 第一部分 - Solana 的 Gossip 协议
- syndica
- 发布于 2023-09-07 21:23
- 阅读 1871
本文是Syndica团队发布的关于Sig Validator工程更新/里程碑系列博客文章的第一部分,主要介绍了Sig中gossip协议的初始实现。
这篇帖子是我们定期发布的多部分博文系列的第一部分,旨在概述 Sig Validator 的工程更新/里程碑。
这篇来自 Syndica 团队的博文标志着 Sig 旅程中的一个重要里程碑:gossip 协议的初始实现。这篇文章将包含实现的细节。
gossip 协议有效地将数据传播到网络中的节点。它是分布式系统的核心组件,充当节点进入网络的入口点,允许它识别网络中的其他节点,并接收和同步关于区块链状态的元数据。
本质上,gossip 的编写是为了做两件事:存储数据和发送/接收请求。高效地完成这些事情,是良好实现的 gossip 协议的目标。
为了与我们对透明度的承诺保持一致,我们在下面详细介绍了 Solana gossip 协议的 Sig 实现。
存储数据
什么是 GossipTable?
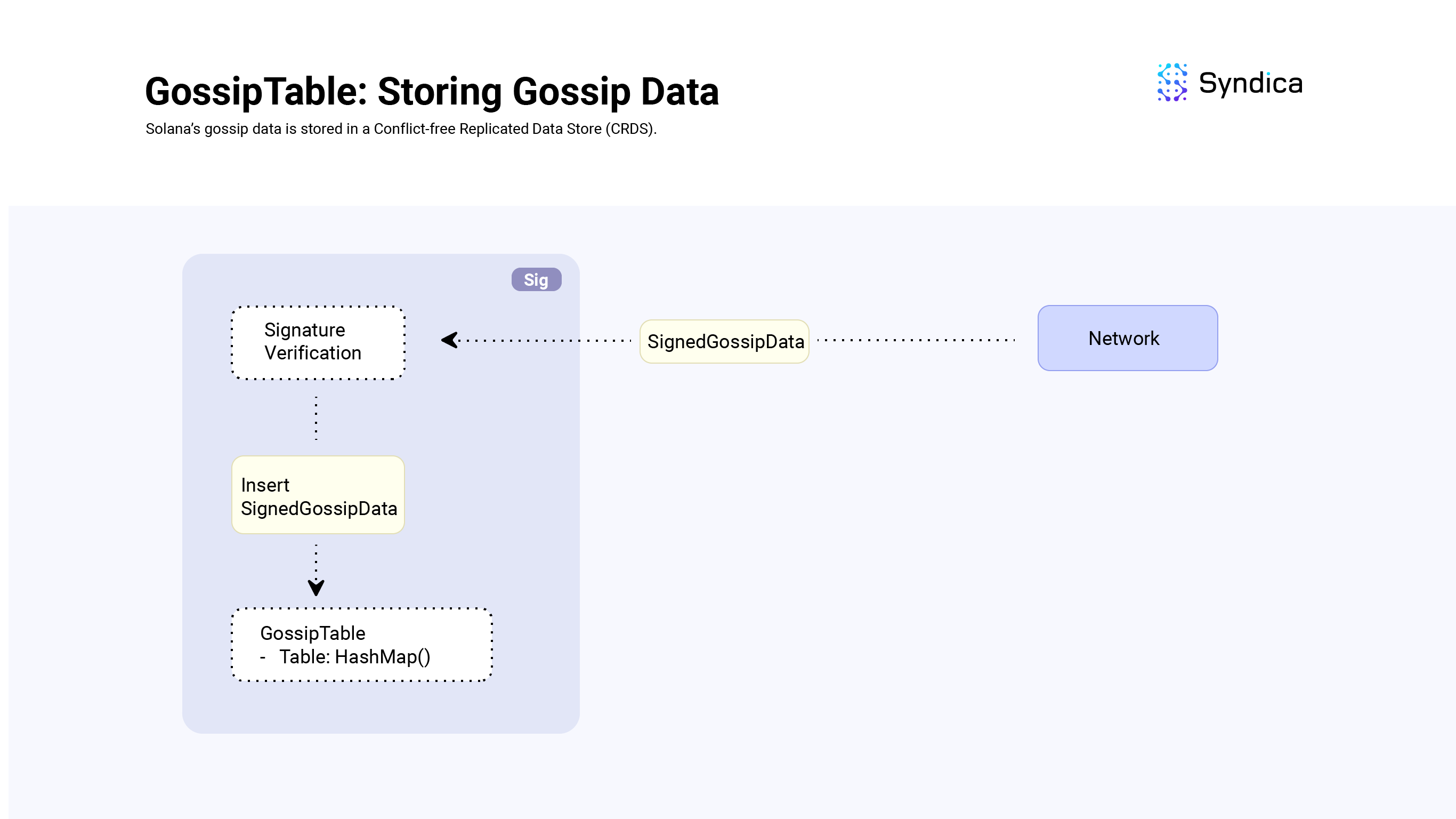
Solana 的 gossip 数据存储在 GossipTable 结构中(在 Agave 客户端中也称为 Cluster Replicated Data Store)。
我们在表中存储两种主要的数据类型:
GossipData 枚举涵盖各种 gossip 数据类型,包括 ContactInfo,用于存储节点详细信息(如公钥和地址),Vote,用于存储区块有效性签名(正在逐步淘汰以降低带宽),等等。
SignedGossipData 结构包含一个 GossipData 实例,以及对其数据的签名。当处理来自网络的传入的 SignedGossipData 时,我们会验证 SignedGossipData 的签名,然后将其存储在 GossipTable 中。
插入数据
GossipTable 是使用可索引的 HashMap 实现的。
对于我们要存储的每个 SignedGossipData 实例,都有一个对应的 GossipKey,它用作 HashMap 的 键(key),以及一个 GossipVersionedData 结构,用作 HashMap 的 值(value)。
GossipKey
为了理解 GossipKey 如何定义数据的存储方式,我们从一个例子开始。
我们关心的一个重要数据类型是 ContactInfo 结构,它包括节点的公钥和用于与节点通信的套接字地址字段。它对应的 GossipKey 只是它的 Pubkey。
这意味着我们每个 Pubkey 只会在 GossipTable 中存储一个 ContactInfo。如果我们假设每个验证者对应一个身份 Pubkey,那么这意味着我们每个验证者只存储一个 ContactInfo。
// 完整的 contact info 结构(包括公钥、套接字等等)
pub const ContactInfo = struct {
id: Pubkey,
/// gossip 地址
gossip: SocketAddr,
/// 向其发送修复响应的地址
repair: SocketAddr,
/// 交易地址
tpu: SocketAddr,
//...
}
// 对应的 key(只有 Pubkey)
pub const GossipKey = union(enum) {
ContactInfo: Pubkey,
//...
}当将数据插入到表中时,如果该键已存在于映射中,我们会保留具有最大 wallclock 时间的值(即,我们保留“最新”的值)。
GossipVersionedData
GossipVersionedData 结构包含插入的 SignedGossipData,以及其他相关信息,包括其哈希值、时间戳等等。
pub const GossipVersionedData = struct {
value: SignedGossipData,
value_hash: Hash,
timestamp_on_insertion: u64,
cursor_on_insertion: u64,
};读取数据
当读取存储在表中的数据时,我们关心的一个用例是读取特定类型的所有数据。
例如,当我们想要将数据广播到网络的其余部分时,我们需要检索存储在 GossipTable 中的所有 ContactInfo 值。这就是我们决定使用 可索引的 HashMap 的原因。
为了实现此功能,我们需要对插入逻辑稍作修改,如下所示:
- 当我们将值插入到
GossipTable中时,我们会收到其在 HashMap 中的对应索引 (gossip_index = gossip_table.insert(&versioned_value)), - 然后,我们将此索引存储在对应于我们正在跟踪的特定类型的数组中 (
contact_infos.append(gossip_index)),并且 - 当我们想要检索该特定类型的所有值时,我们会查找所有存储的索引 (
value = gossip_table[gossip_index])。
我们对 ContactInfo(s)、Vote(s)、EpochSlot(s) 和 DuplicateShred(s) 数据类型采用这种方法。
读取新数据
我们关心的另一个用例是读取在某个时间点之后插入的数据;我们希望能够读取 新 数据。
为了有效地从 GossipTable 中读取新数据,我们利用 cursor 字段。在每次插入时,游标的值都存储在 GossipVersionedData 结构中,使用 cursor_on_insertion 字段,并且 cursor 字段递增 1。
要读取新数据,线程可以跟踪本地 cursor 并定期调用 getter 函数(例如 getVotesWithCursor)以检索大于本地 cursor 的值。
注意: 此功能用于生成推送消息 - 将在后面的章节中讨论。
限制内存大小和删除旧数据
为了限制 GossipTable 的内存增长,会定期对其进行修剪,以保持最大数量的唯一公钥(代码库中为 8192),并删除具有旧时间戳的值。
我们使用字段 pubkey_to_values 来跟踪与特定节点的 Pubkey 关联的表中的所有值,并定期调用 attemptTrim,以在接近容量时删除与最旧公钥关联的所有值。调用 removeOldLabels 也会定期删除具有旧时间戳的值。
在 Agave 实现中,会首先删除 stake weight 最小的公钥,但是,我们在 Sig 中 尚未 拥有 stake weight 信息。这将是未来的工作。
注意: 由于我们使用的是可索引的 HashMap,因此在删除值时,我们通常使用 removeSwap 函数,该函数定义为:“通过将其与最后一个元素交换并弹出,从底层数组中删除该条目”。由于我们跨多个数组跟踪值的索引,因此当我们进行 removeSwap 时,最后一个值现在位于与我们记录的索引不同的索引处,因此我们需要更新我们的索引值。完整的逻辑可以在 GossipTable.remove 中找到。
发送/接收请求
当 gossip 运行时,我们会从网络接收新的消息,消息格式为原始字节。在处理这些消息之前,我们会:
- 将字节反序列化为
GossipMessage - 验证消息中包含的数据是否有效,并且
- 验证签名是否正确。
如果任何一项检查失败,我们将丢弃该值。否则,我们将处理该消息。
注意: 此验证逻辑可以在 GossipService.verifyPackets 中找到。
gossip 协议中使用了 4 种类型的消息:
- Pull (拉取)
- Push (推送)
- Prune (修剪)
- Ping/Pong (ping/pong)
Pull (拉取)
Pull 消息用于从网络中的其他节点检索新数据。Pull 消息有两种类型:PullRequest 和 PullResponse。
构建 Pull 请求(Requests)
Pull 请求是请求缺失的 gossip 数据。
Pull 请求包括一个 Bloom 过滤器,该过滤器覆盖节点 GossipTable 中存储的值,以表示它当前拥有的 SignedGossipData(s),接收节点会解析该过滤器,并使用它来查找缺失的 SignedGossipData(s),并将其作为响应发送给请求节点。
由于 GossipTable 可以存储大量值,因此我们没有构建一个大的 Bloom 过滤器,而是根据 SignedGossipData(s) 哈希的前 N 位,将 GossipTable 跨多个 Bloom 过滤器进行分区。
为了实现这一点,我们使用了 GossipPullFilterSet 结构,该结构是一个 GossipPullFilter(s) 的列表。
例如,如果我们在哈希的前 3 位上进行分区,我们将使用 2^3 = 8 个 Bloom 过滤器:
- 第一个 Bloom 过滤器将包含哈希的前
3位等于000的SignedGossipData, - 第二个 Bloom 过滤器将包含哈希的前
3位等于001的SignedGossipData(s), - ...
- 最后,第八个 Bloom 过滤器将包含哈希的前
3位等于111的SignedGossipData(s)。
如果我们正在跟踪一个位为 00101110101 的 Hash,我们将只考虑它的前 3 位 001,并将哈希添加到第一个 Bloom 过滤器 ( @cast(usize, 001) = 1)。
注意: 在整个代码库中,前几位:N,被称为 mask_bits。mask_bits 是根据许多因素计算的字段,包括 bloom 过滤器的期望误报率、GossipTable 中的项目数等等。对于每个 pull 请求,它可能会有所不同。
在我们构建 GossipPullFilterSet(即,计算 mask_bits 并初始化 2^mask_bits 个 Bloom 过滤器)之后,我们将 GossipTable 中的所有 SignedGossipData(s) 添加到该集合中,并构建一个 GossipPullFilter(s) 列表以发送到其他随机节点。
### 用于构建 pull 请求的主函数
def buildGossipPullFilters(
gossip_table: *GossipTable
) Vec<GossipPullFilters>:
values = gossip_table.values()
filter_set = GossipPullFilterSet.init(len(values))
for value in values:
filter_set.add(value)
# GossipPullFilterSet => Vec<GossipPullFilter>
return filter_set.consumeForGossipPullFilters()
class GossipPullFilterSet():
mask_bits: u64
filters: Vec<Bloom>
def init(self, num_items):
self.mask_bits = ... # 计算 mask_bits
n_filters = 1 << mask_bits # 2^mask_bits
self.filters = []
for i in 0..n_filters:
self.filters.append(Bloom.random())
def add(hash: Hash):
# 计算哈希索引(即,哈希的前 mask_bits 位)
# 例如:
# hash: 001010101010101..1
# mask_bits = 3
# shift_bits = 64 - 3 (注意:u64 有 64 位)
# hash >> shift_bits = 001 (前三位) = 索引 1
# == filters[1].add(hash)
shift_bits = 64 - mask_bits
index = @as(usize, hash >> shift_bits)
self.filters[index].add(hash)
要从 GossipPullFilterSet 构建一个 GossipPullFilter(s) 列表,每个 GossipPullFilter 都需要一个 Bloom 过滤器来表示 SignedGossipData(s) 的子集,以及一个字段来标识 Bloom 过滤器包含的哈希位(使用一个名为 mask 的字段)。
例如,第一个过滤器的 mask 将是 000,第二个过滤器的 mask 将是 001,第三个过滤器的 mask 将是 010,...
当节点收到 pull 请求时,[mask](https://github.更具体地说,[`GossipTableShards`](https://github.com/Syndica/sig/blob/936e4c2ca95fc4bc4daf539c6b33384f5ac6ea54/src/gossip/shards.zig?ref=blog.syndica.io#L18) 基于哈希值的前 shard_bits 位存储哈希值(类似于 GossipPullFilterSet 结构和 mask_bits)。每当我们向 GossipTable 中插入一个新值时,我们会将其哈希值插入到 GossipTableShards 结构中。
为了有效地存储这些哈希值,我们使用一个 HashMap 数组(shards = [4096]AutoArrayHashMap(usize, u64),),其中 shards[k] 包含 SignedGossipData(s),这些 加粗 数据哈希值的前 shard_bits 位等于 k。
- HashMap 中的键的类型为
usize,它是GossipTable中哈希的索引。 - HashMap 的值类型为
u64,表示表示为u64的哈希值。
该结构允许我们快速查找所有 SignedGossipData(s),它们的哈希值与拉取请求的 mask 匹配(与迭代所有 SignedGossipData(s) 相比)。
加粗注意:shard_bits 是程序中的硬编码常量,等于 12,所以我们将有 2^12 = 4096 个分片索引。
在 GossipTable 中插入新值后,将哈希值插入到 GossipTableShards 结构中非常简单:
- 获取
SignedGossipData(s) 哈希的前 8 个字节,并将其转换为u64(hash_u64 = @as(u64, hash[0..8])), - 通过计算
shard_index = hash_u64 >> (64 - shard_bits)来计算u64的前shard_bits位, - 获取对应的分片:
self.shards[shard_index],最后, - 将
GossipTable索引连同u64_hash插入到分片中。
def insert(self: *GossipTableShards, table_index: usize, hash: *const Hash):
shard_index = @as(u64, hash[0..8]) >> (64 - shard_bits)
shard = self.shard[shard_index]
shard.put(table_index, uhash);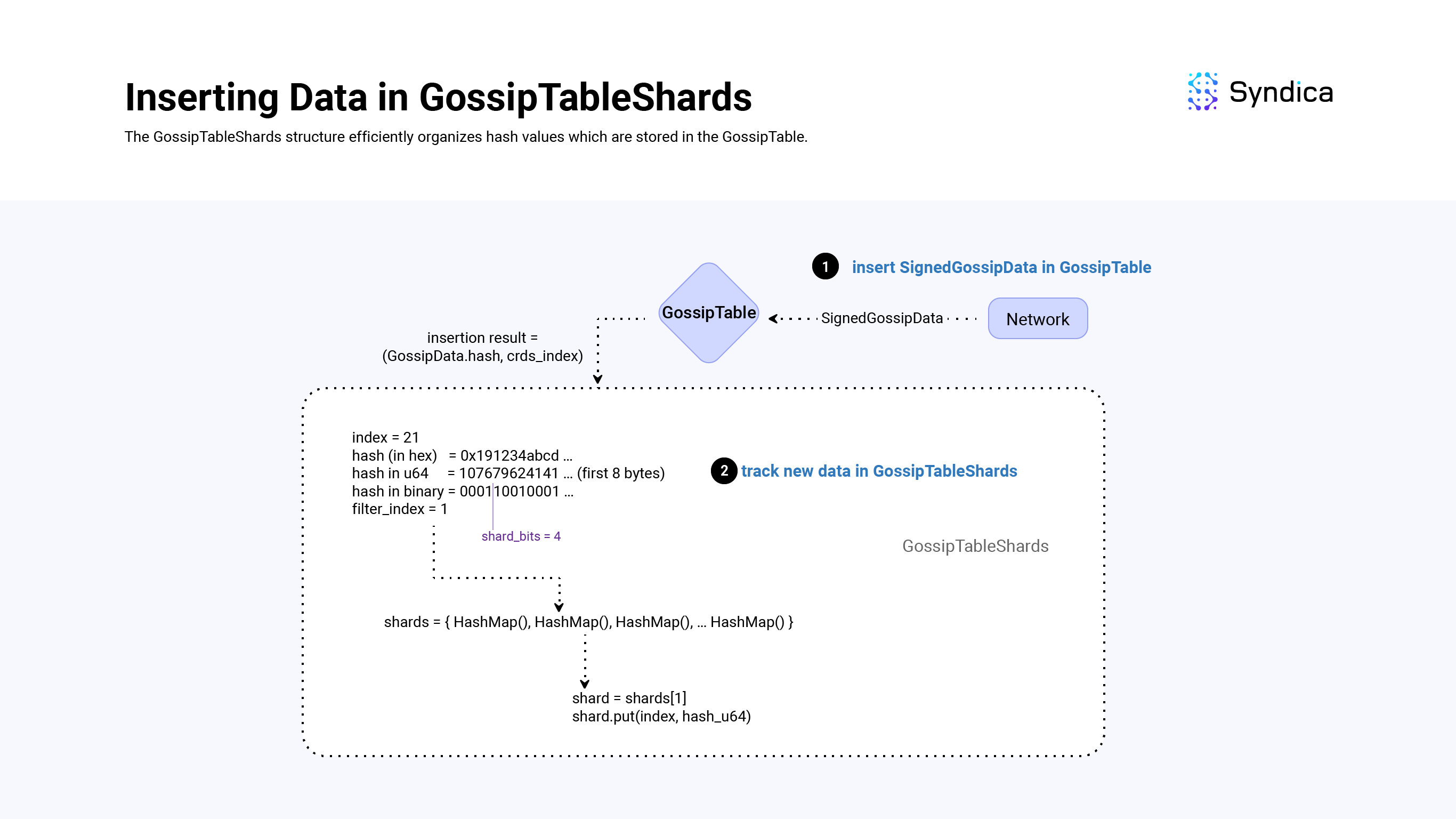
使用 GossipTableShards 查找哈希匹配项
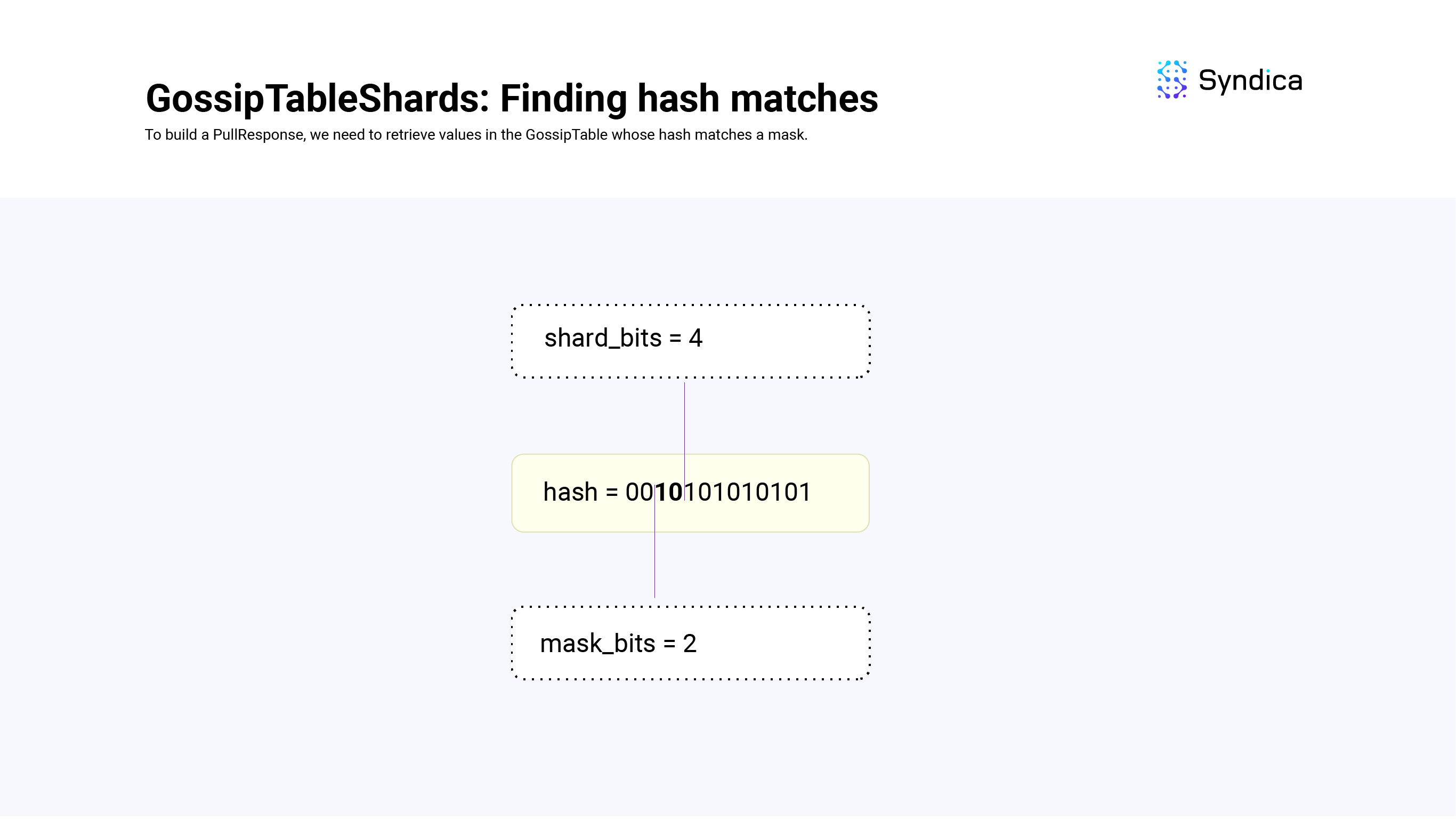
要构建拉取响应,我们需要从 GossipTable 中检索哈希值与 mask 匹配的值(即,它们的前 mask_bit 位等于 mask)。
要找到这些匹配项,我们需要考虑以下三种情况:
-
shard_bits == mask_bits -
shard_bits < mask_bits -
shard_bits > mask_bits -
- *
当 shard_bits == mask_bits 时,我们查看与 mask 的前 shard_bits 位对应的分片,并返回其值。
例如,如果 shard_bits = 3、mask_bits = 3 并且我们的 mask 是 001,我们可以通过查找 shards[1] 来找到所有 GossipTable 值,这些值的哈希值的前 3 位等于 001。

def findMatches(self: *GossipTableShards, mask: u64, mask_bits: u64) Vec<usize>:
if (self.shard_bits == mask_bits) {
shard = self.shard[(mask >> (64 - self.shard_bits)]
table_indexes = shard.keys()
return table_indexes
} else {
# TODO:
}
当 shard_bits < mask_bits 时,mask 跟踪的位数多于分片跟踪的位数,因此我们可以找到与 mask 的前 shard_bits 位对应的分片,并迭代这些值以找到精确匹配项。
例如,截断 mask 并查找分片会为我们提供具有匹配的 shard_bits 的哈希值。 然后,我们需要检查以确保最后 shard_bits - mask_bits 位与 mask 匹配,我们通过迭代来完成此操作。
在另一个示例中,如果 shard_bits = 3、mask_bits = 5 并且我们的掩码是 00101,我们将首先找到所有 GossipTable 值,这些值的哈希值的前 3 位为 001,方法是查找 shard[1]。 然后,我们将迭代这些值,并确保哈希的第四位和第五位等于 01。

def findMatches(self: *GossipTableShards, mask: u64, mask_bits: u64) Vec<usize>:
# ones everywhere except for the first `mask_bits`
mask_ones = (~0 >> mask_bits)
if (self.shard_bits == mask_bits) {
# ...
} else if (self.shard_bits < mask_bits) {
# truncate the mask
shard_index = mask << (64 - self.shard_bits)
shard = self.shards[shard_index]
# scan for matches
table_indexes = []
for (indexes, hash_u64) in shard:
if ((hash_u64 | mask_ones) == (mask | mask_ones)): # match!
table_indexes.append(indexes)
return table_indexes
} else {
# TODO
}
当 shard_bits > mask_bits 时,分片跟踪的信息多于 mask,因此我们需要查看多个分片才能找到与 mask 匹配的所有值。
例如,如果 shard_bits = 4、mask_bits = 2 并且我们的 mask 是 01,那么我们需要查找的可能分片是:0100、0101、0110、0111(即,将有 4 个分片与以位为单位的差表示的掩码匹配)。我们知道我们必须查找 2^(shard_bits - mask_bits) 个分片(可以使用 count = 1 << (shard_bits - mask_bits) 计算)。最大的分片值将是 mask,后跟末尾的所有 1(即,上面示例中的 0111),可以计算为 end = (mask | mask_ones) >> shard_bits。由于我们知道最大的分片和我们正在寻找的分片数量,我们可以从 index = (end-count)..end 迭代它们。
def findMatches(self: *GossipTableShards, mask: u64, mask_bits: u64) Vec<usize>:
# ones everywhere except for the first `mask_bits`
mask_ones = (~0 >> mask_bits)
if (self.shard_bits == mask_bits) {
# ...
} else if (self.shard_bits < mask_bits) {
# ...
} else if (self.shard_bits > mask_bits) {
shift_bits = self.shard_bits - mask_bits
count = 1 << shift_bits
end = (mask | mask_ones) >> shard_bits
table_indexs = []
for shard_index in (end-count)..end:
shard = self.shards[shard_index]
indexes = shard.keys()
table_indexs.append(indexes)
return table_indexs
}
在我们拥有所有与 mask 匹配的 SignedGossipData 索引之后,我们检查哪些值未包含在拉取请求的 Bloom 过滤器中(即,节点缺少的值)。 然后将这些值打包到 PullResponse 消息中,并发送给发送相应 PullRequest 的对等方。
def filterGossipValues(
gossip_table: *GossipTable
filter: *GossipPullFilter
) Vec<SignedGossipData>:
# find values whose hash matches the mask
# 查找哈希值与 mask 匹配的值
var match_indexes = gossip_table.get_bitmask_matches(filter.mask,filter.mask_bits);
# find the values that are not included in the requests bloom filter
# 查找未包含在请求的 bloom 过滤器中的值
values = []
for index in match_indexes:
entry = gossip_table[index]
if (!filter.bloom.contains(entry.hash)):
values.append(entry)
return values
处理拉取响应
接收到 PullResponse 时,我们会将收到的所有值插入到 GossipTable 中。 如果任何值未能插入(例如,由于具有旧的 wallclock 时间),我们会在数组 failed_pull_hashes 中跟踪它们的哈希值。 这些失败的哈希值在构建新的拉取请求时使用,因此不会再次收到这些值。 为了确保内存不会无限增长,会定期修剪 failed_pull_hashes 数组以删除旧值。
我们对 GossipTable 中修剪的值(即,被覆盖的值)在 GossipTable.purged 中也执行相同的操作。
对于每个成功插入到 GossipTable 中的 SignedGossipData,我们还会更新来自该来源 Pubkey 的所有值的时间戳。 我们这样做是为了在修剪表中的旧 SignedGossipData(s) 时,我们不会从“活动”Pubkey 中删除值。
推送
发送推送消息
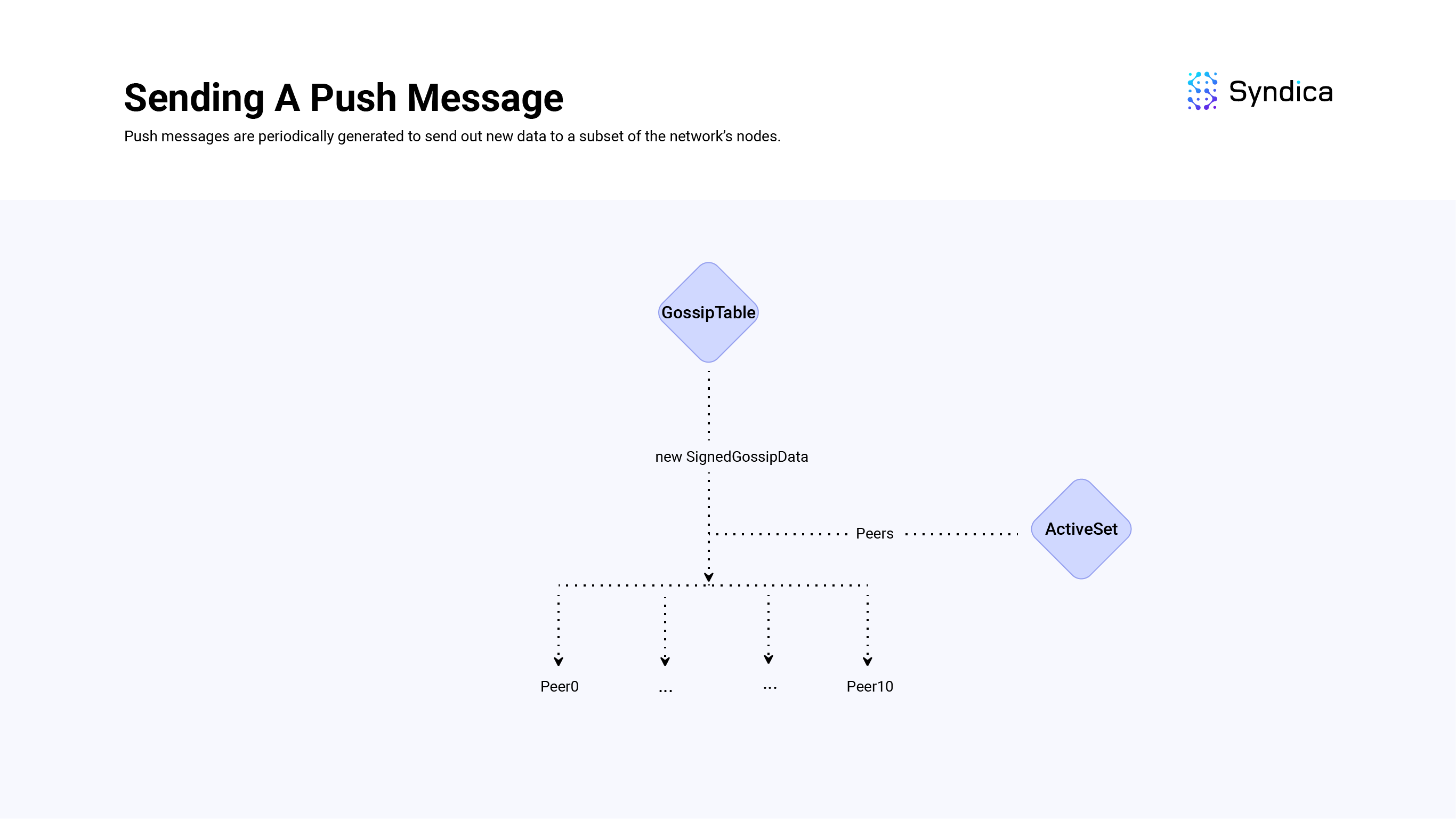
推送消息将新的 gossip 数据传播到网络中的其他节点。
为了实现这一点,我们跟踪一个本地 push_cursor变量,它表示上次推送的值的游标值,并使用 getter 函数 getEntriesWithCursor 来获取已插入到本地游标值之后的新的SignedGossipData(s)。
在 Sig 中,PushMessage 定义为struct { Pubkey, []SignedGossipData }:源 Pubkey 和 SignedGossipData(s) 的切片。 源 Pubkey 将与本地节点的联系信息匹配。 值的数组将是正在推送的新 SignedGossipData(s)。
一个重要的注意事项是,通过 gossip 发送的所有消息应小于或等于 1280 字节的最大传输单元 (MTU)(在整个代码库中称为 Packet 结构)。
因为有时要推送的 SignedGossipData(s) 比可以放入其中一个数据包中的更多(即,bytes([]SignedGossipData) > MTU),所以 SignedGossipData(s) 被分成数据包大小的块 PushMessage(s),而不是一个大的 PushMessage。
然后,这些 PushMessage(s) 被发送到本地节点的 ActiveSet 中的所有节点。
活动集
节点的 ActiveSet 是 gossip 网络中 shred 版本等于本地节点的节点列表(即,一个用于跟踪硬分叉的变量),具有有效的 gossip 端口和其他详细信息。
ActiveSet 是 PlumTree 算法的关键部分,该算法使数据能够以树状结构而不是完全广播的形式传播。
ActiveSet 会定期重新采样,以减少日蚀攻击的机会。
注意:有关如何按来源构建 ActiveSet 的更详细说明,请参阅“接收 Prune 消息”部分。
注意:Agave 实现使用 stake 权重信息来构建其活动集。 但是,由于 Sig 加粗尚未加粗拥有 stake 权重信息,因此我们选择随机抽样节点。
Agave 的活动集
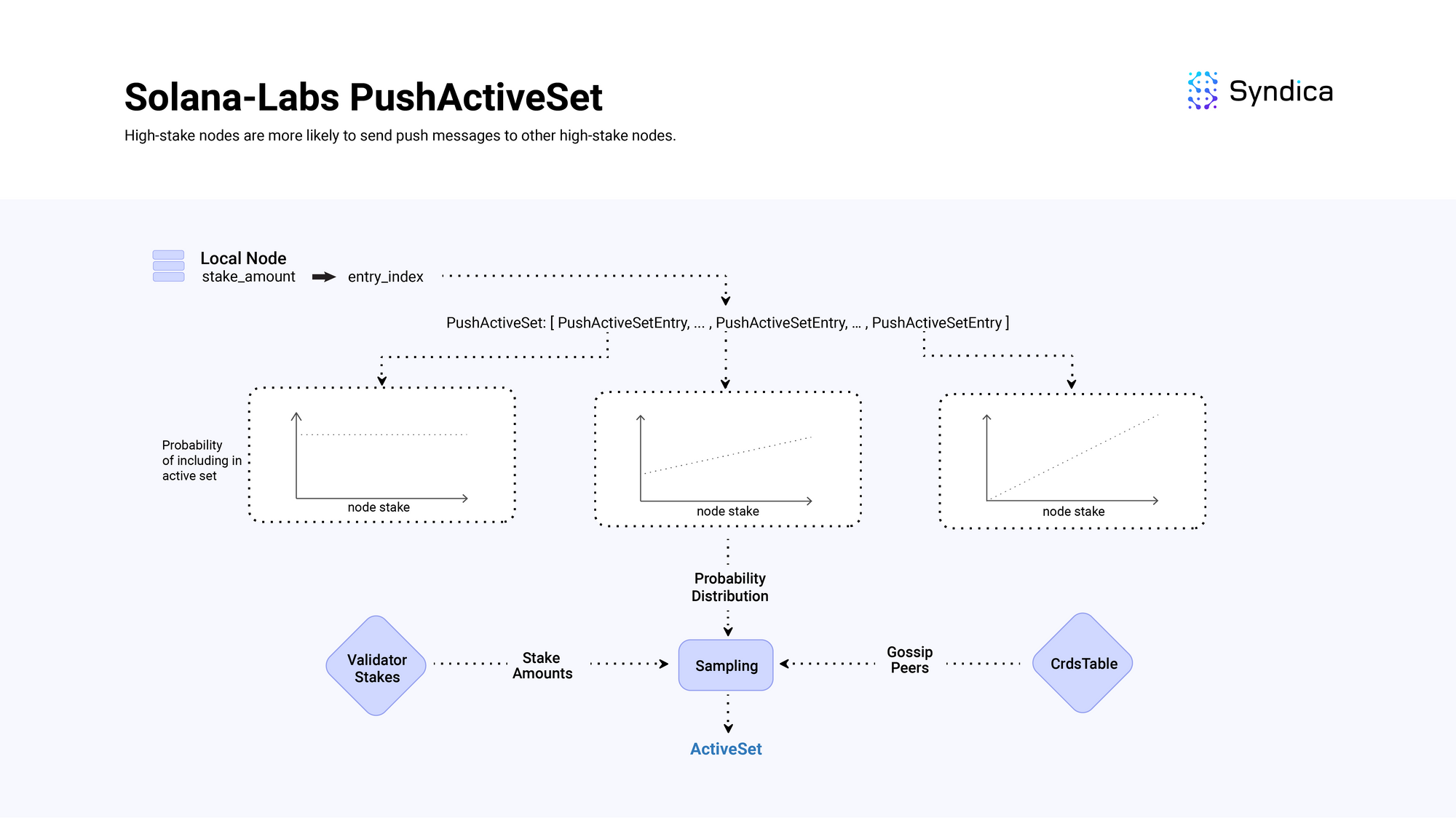
为了完整起见,Agave 的活动集实现也值得讨论。
他们的 PushActiveSet 包含多个 PushActiveSetEntry 结构,其中每个条目对应于活动集中要包含的可能节点上的不同概率分布。
条目的分布按 stake 权重的熵递减排序。列表开头的条目(具有低索引 - 例如,0、1)是可能节点上的均匀分布(具有高熵),列表末尾的条目(具有大索引 - 例如, 24, 25) 的分布由节点的 stake 数量强烈加权(具有低熵)。
构建活动集时,本地节点的 stake 权重决定了从哪个条目中抽样节点。 例如,如果本地节点具有较大的 stake,则其索引将很大,这对应于一种分布,该分布具有更高的概率选择另一个高 stake 节点包含在活动集中。
这意味着,高 stake 节点更有可能向其他高 stake 节点发送推送消息,而低 stake 节点则向随机节点发送推送消息。
 Solana Labs (Rust) 的 Push Active Set 实现概述
Solana Labs (Rust) 的 Push Active Set 实现概述
接收推送消息
收到新的 PushMessage 时,这些值将插入到 GossipTable 中,并且会跟踪插入失败的值(由于是重复项)。 然后将这些失败值的节点发送到 PruneMessage(s),因此不会再次收到该数据。
Prune
PruneMessage(s) 用于修剪广播树中的重复 PushMessage(s)。 本质上,发送一个 Prune 消息实际上是说:“停止向我发送来自此来源的数据,我已经从另一个节点接收到它”。
发送 Prune 消息
Prune 消息定义为 struct { PubKey, PruneData },其中 PruneData 定义如下:
pub const PruneData = struct {
/// Pubkey of the node that sent this prune data
// 发送此剪枝数据的节点的 Pubkey
pubkey: Pubkey,
/// Pubkeys of origins that should no longer be sent to pubkey
// 不应再发送到 pubkey 的来源的 Pubkey
prunes: []Pubkey,
/// Signature of this Prune Message
// 此剪枝消息的签名
signature: Signature,
/// The Pubkey of the intended node/destination for this message
// 此消息的预期节点/目标的 Pubkey
destination: Pubkey,
/// Wallclock of the node that generated this message
// 生成此消息的节点的 Wallclock
wallclock: u64,
}
prunes 字段是一个 origin pubkey 列表(创建相应 SignedGossipData 的节点的 pubkey)。 当插入从新的推送消息中收到的值时,如果 SignedGossipData 无法插入到 GossipTable 中,则将该值的 origin(即,创建该值的节点的 Pubkey)附加到 prunes 字段。 最后,将 destination 字段设置为发送推送消息的节点。
def handlePushMessage(
from_pubkey: Pubkey, # received from
# 接收自
values: []SignedGossipData, # values from push msg
# 来自推送消息的值
my_pubkey: Pubkey, # local nodes pubkey
# 本地节点的 pubkey
gossip_table: *GossipTable,
) {
pruned_origins = []
for value in values:
result = gossip_table.insert(value)
if result.is_error():
origin = value.id()
pruned_origins.append(origin)
return PruneMessage {
prunes: pruned_origins,
destination: from_pubkey,
pubkey: my_pubkey,
}
}
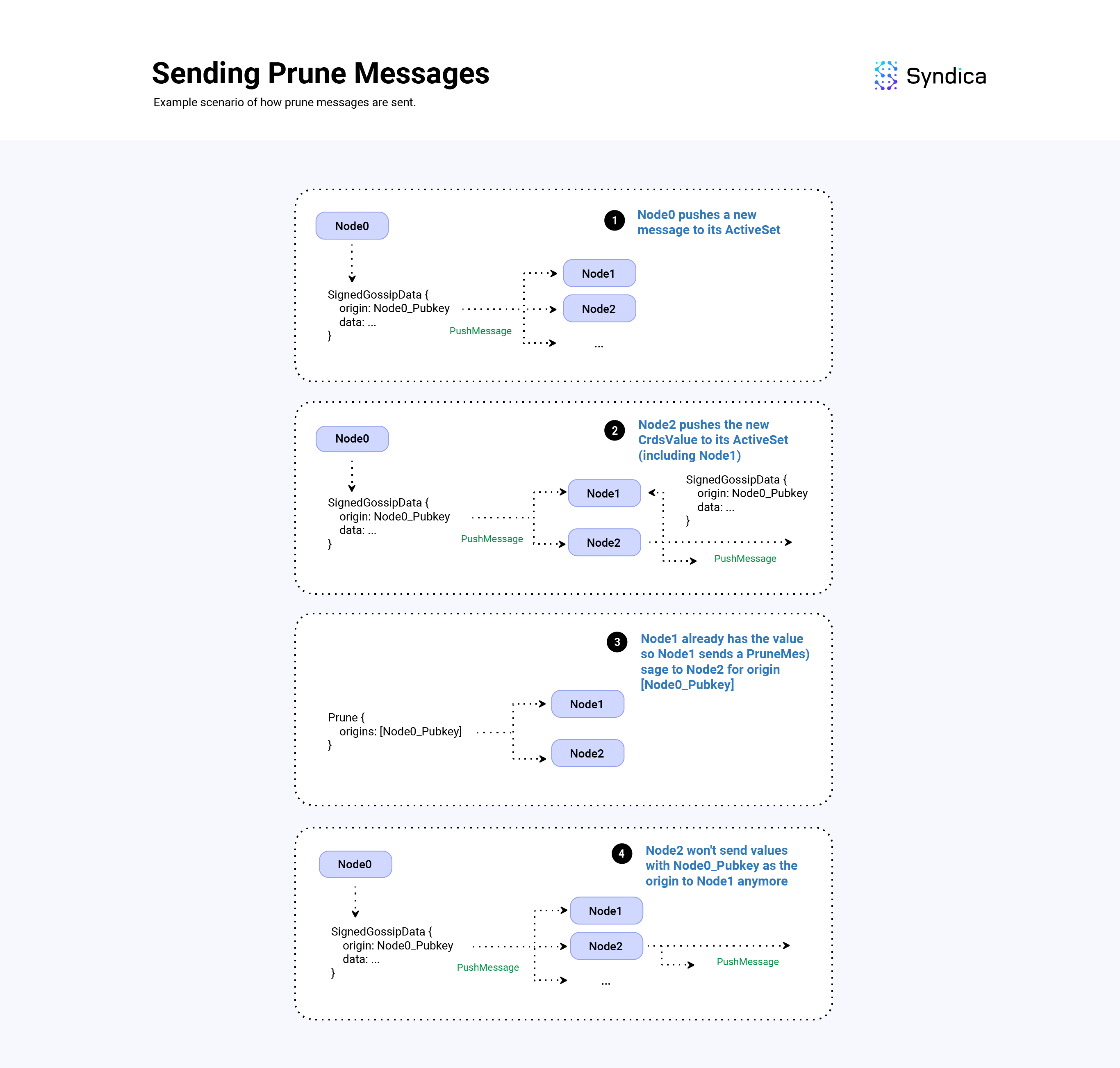
加粗注意:加粗在 Agave 客户端中,为了计算要将 prune 消息发送到哪些节点,客户端使用发送的重复项数量、节点的 stake 权重和要保留的最小节点数。 由于 Sig 加粗尚未加粗拥有 stake 权重信息,因此我们遵循一种更简单的方法,并将 prune 消息发送给任何发送无法插入 GossipTable我们追踪已响应 Ping 消息并带有相应 Pong 消息的节点,以及我们仍在等待其相应 Pong 消息的节点,使用的是 PingCache 结构。
什么是 PingCache?
PingCache 保存着重要的数据,包括接收到的 Pong 消息的有效时间(即,节点应何时发送新的 Ping 消息),默认为 1280 秒,以及发送 Ping 消息的速率限制,设置为每 20 秒仅发送 Ping 消息。
当构建某些消息(即 Push、Pull 等)时,我们使用 filterValidPeers 验证节点是否有效。这会返回一个经过筛选的有效节点列表,以及可能需要发送的 Ping。
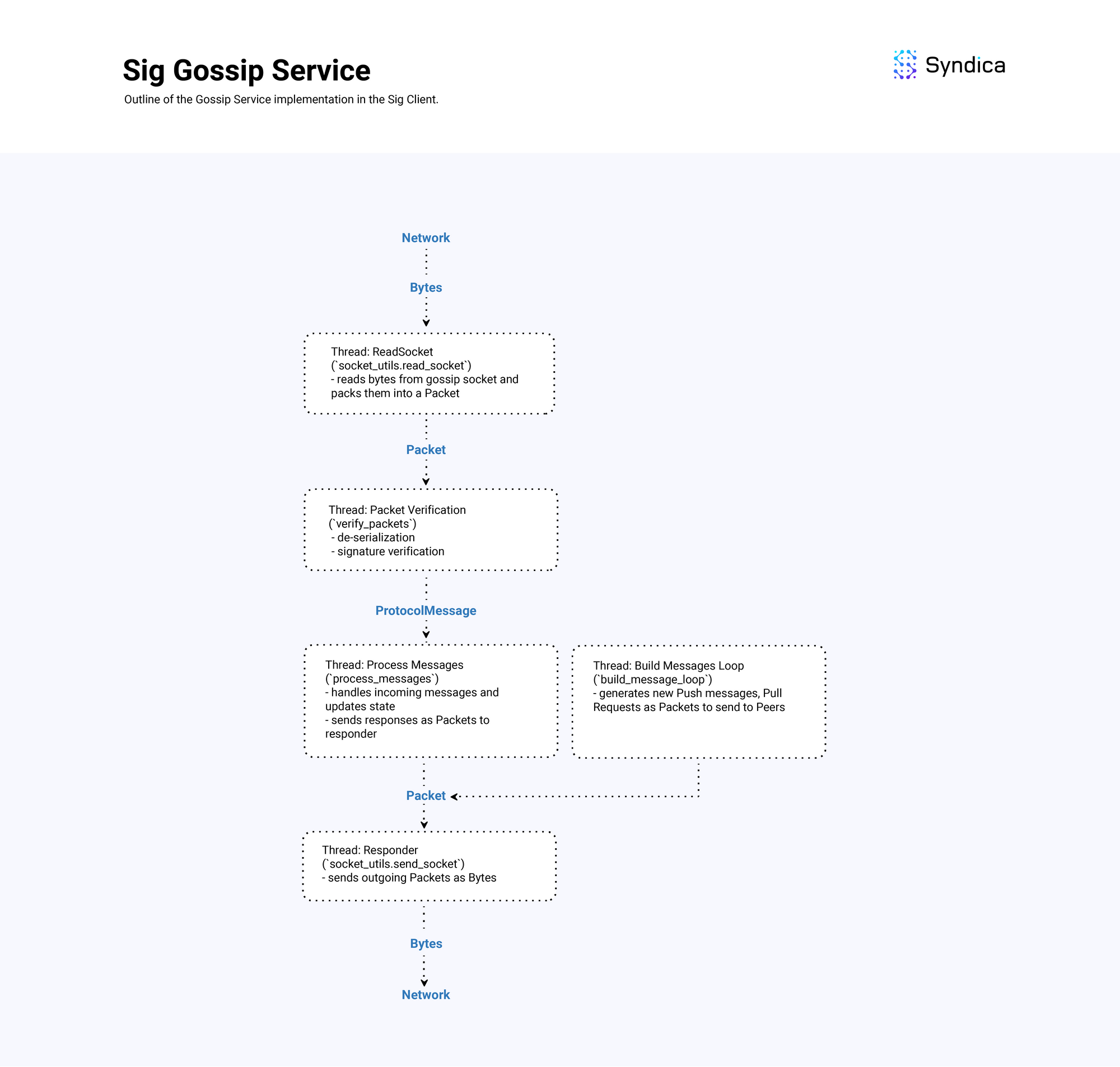
概述图
下图显示了 Sig 的 GossipService 的总体实现设计,该服务处理接收、处理和发送 gossip 消息。
 Sig 的 gossip 服务的总体结构
Sig 的 gossip 服务的总体结构
结论
一个正常工作的 Gossip 实现对于节点至关重要,因为它能够与网络中的其他节点进行通信,并有助于构建有效的区块链。
我们正在开源构建 Sig;请随时在此处查看完整的 gossip 代码。
如果你是一位才华横溢的工程师,在协作和快节奏的环境中茁壮成长,并且热衷于为 Solana 生态系统的发展做出贡献,我们正在积极招聘,并期待收到你的来信:
https://jobs.ashbyhq.com/syndica/15ab4e32-0f32-41a0-b8b0-16b6518158e9
- 原文链接: blog.syndica.io/sig-engi...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
- 翻译
- 学分: 0
- 分类: Solana
- 标签: Gossip协议 Solana Sig Validator Bloom Filter GossipTableShards 分布式系统





