全DAS采样分析 - 分片
- 以太坊中文
- 发布于 2024-11-03 15:25
- 阅读 1229
本文探讨了在以太坊全数据可用性采样(DAS)中,网络在不同条件下的采样性能。研究分析了节点数量、节点连接数、恶意节点比例等因素对采样速度和数据可用性的影响。结果表明,在正常网络条件下,DAS采样可以快速高效地进行,但大规模恶意攻击仍然是一个挑战,需要进一步的研究和解决方案。

这项工作由 Codex team 完成,我们要感谢 @dankrad, @matt, @Nashatyrev, @oascigil, @fradamt, @pop 和 @srene 对这项工作的反馈和贡献。
摘要
这项工作试图回答最初的 PeerDAS 文章中提出的关于抽样、数据保管、网络要求和诚实拜占庭比例的大部分问题。
- 在正常情况下和相对较低的网络假设下,网络可以快速执行抽样,同时保证高度去中心化。
- 该网络足够强大,可以吸收大型相关故障,其中超过三分之一的节点不参与抽样过程。
- 大规模的由不诚实的大多数 (90%) 协调发起的攻击仍然是一个挑战,需要通过其他技术来解决。
介绍
自 2024 年 3 月 13 日的 DenCun (Deneb-Cancun) 分叉以来,以太坊网络一直在运行 EIP4844。在目前的情况下,节点必须下载最多 6 个 blob,每个 blob 的大小为 128KB。当完整的 DAS 变为现实时,我们预计每个插槽会产生更多的数据。当前计划的结构 是一个 512 行乘 512 列的 2D 矩阵(在纠删码之后),其中每个单元格的大小为 560 字节(包括 KZG 证明)。这使得每行/列的大小为 280 KB,总矩阵大小为 140MB。当然,这些数字可能会改变,但我们将使用此估计值进行此分析。
假设
完整的 DAS 包括两个主要组成部分:数据分片和抽样。数据分片指的是网络中的节点不需要下载整个区块/blob,而只需要下载其中的一部分。抽样是节点验证区块是否可用的过程,而无需下载整个区块。
保管
在将数据分片成行和列,将其分散到 P2P 网络上并进行抽样之前,我们必须解释节点如何知道他们负责哪些数据。节点使用他们的 nodeID 和 custody_size 来确定性地推导出他们需要保管哪些行和列。custody_size 是节点想要保管的行和列的数量,并在发现过程中在以太坊节点记录 (ENR) 中传输。稍后会详细介绍。例如,想要保管 16 行和列的节点将生成其自身 nodeID 的 SHA-256 哈希,然后将此 256 位哈希切成 25 个 10 位段(丢弃最后 6 位),这些 10 位数字(从 0 到 1024)将是节点必须保管的行和列的列表。在这种情况下,25 不够,因为我们需要 32(16 行和 16 列),然后我们只需将 nodeID 递增 1,SHA-256(nodeID+1),以获得另外 25 个行/列 ID。可以根据需要重复此过程多次。如果任何 ID 重复,我们只需忽略它并采用下一个 ID,直到达到我们的配额。此过程只需在节点初始化时完成一次。请注意,任何节点都可以对其所有对等节点执行相同的计算,因为它具有所有对等节点的 nodeID 和 custody_size。因此,网络中的所有节点都知道哪些数据在他们各自对等节点的保管之下。此算法只是实现确定性保管的一个示例;存在许多其他选择。
数据分发
对于数据分发,我们假设节点从区块构建者处下载它们需要保管的数据部分。它们使用 GossipSub 通道下载数据,就像今天用于证明、区块、聚合等的方式一样。我们假设总共有 1024 个 GossipSub 通道(512 行和 512 列),并且网络中的节点订阅满足其保管需求所需的通道。此策略依赖于 GossipSub 应该有效地扩展到一千多个通道的前提,这在像以太坊主网这样的生产网络上从未经过测试。尽管如此,假设在不久的将来可能会出现这种情况,这并不是过于乐观。我们还假设节点不会频繁更改其保管集,仅当它们使用新的 nodeID 重新启动节点时才会更改,因此它们会长时间(例如,几个月)保持订阅这些 GossipSub 通道。此外,我们假设只有一半的行/列通过网络发送,另一半使用 Reed-Solomon 编码即时重建。这意味着想要下载整个区块(140 MB)的节点只需要下载 256 行,并且仅接收到一半的行(32 MB)。然后,节点可以水平扩展接收到的 256 个半行,然后通过垂直扩展数据来生成丢失的 256 行。换句话说,如果节点保管 256 行或更多行/列,它只需 32 MB 的数据即可重新生成所有内容。
抽样
对于抽样,我们假设节点可以通过轻量级通信通道(例如,新的发现协议、轻量级 libp2p 等)相互查询,在该通道中可以建立仅持续几秒钟的临时连接。今天不存在这样的协议,但我们认为我们可以相当快地实现这一点并非不切实际。大多数网络组件今天已经存在。鉴于保管集是从 nodeID 确定性计算的,因此网络中的任何节点都可以知道其对等节点的保管集中有哪些行和列。
此外,我们还假设一个类似于当前以太坊网络的 P2P 网络,该网络大约有一万个节点,并且我们还假设所有客户端都可以并行处理数百个对等连接而没有开销问题,考虑到今天的共识层 (CL) 客户端可以轻松地与大约一百个对等节点保持连接,这似乎是现实的。
目标
在本研究中,我们分析了使用上述给定的网络假设在完整的 DAS 中抽样一个区块有多困难。因此,我们对一个 P2P 网络进行建模,其中每个节点都有一定数量的对等节点 P,以及 2D 矩阵的 C 行和列的保管集。然后,我们研究这两个参数如何影响抽样完成的速度。
特别是,我们关注抽样所需的跳数。例如,当一个节点想要抽样给定的单元格时,它会查看其对等节点以找到谁保管了该单元格的行或列,然后发送查询。如果其对等节点都没有保管该单元格,则它会将查询发送给一个随机对等节点。接收查询的对等节点无法发送该单元格,因此,它将回复一个包含其保管集中包含该单元格的对等节点列表。原始节点现在可以将查询发送给这些对等节点中的任何一个,从而产生一个两跳抽样过程。可以根据需要重复相同的过程(H 跳),直到找到保管集中包含该单元格的节点。
我们将此概念命名为抽样范围。我们将一级范围称为节点可以通过查询其直接(一跳)对等节点来“看到”的单元格集合。在上图中,蓝色节点的一级范围由绿色节点保管集中 2D 矩阵的单元格表示。二级范围是节点可以从其直接对等节点及其直接对等节点(最多两跳)“看到/抽样”的单元格集合,即图中绿色和橙色节点保管的单元格。
 \
1050×550 87.6 KB
\
1050×550 87.6 KB抽样范围的概念,正如本工作中所定义的,与网络理论中的分离度密切相关。例如,一些研究预测所有人类都通过 六度分隔 连接起来。然而,区分这两个概念至关重要:分离度是定义网络中两个节点之间距离的指标,而抽样范围,如这里所述,是节点可以在 x 度分隔内看到的单元格集合。这也可以描述为 x 度分隔内节点的保管集合的并集。
鉴于所有这些,我们试图回答以下问题:对于特定的网络配置,我们在一级范围、二级范围等等上获得多少单元格覆盖率?这主要取决于两个参数:节点的对等节点数量 P 及其保管大小 C。让我们为它们分配一些值。
方法论
在本节中,我们将解释如何为保管大小和对等节点数量分配值。
扁平保管
保管是指节点负责存储去中心化网络中特定数据分区(行和列)的责任。扁平保管是一种方法,其中每个节点都被分配相同数量的行和列到其保管集,而不管该节点有多少验证器。例如,我们可以将网络中所有节点的保管设置为两行两列 (C=2),然后评估我们在 1 级、2 级等等的范围级别获得多少单元格覆盖率。
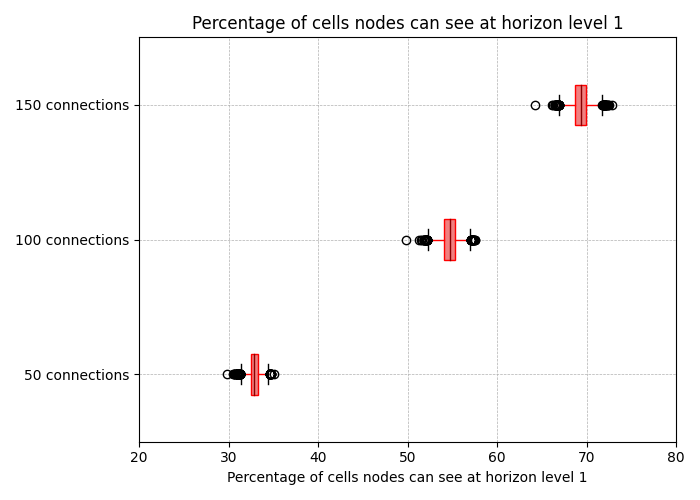 \
700×500 21.1 KB
\
700×500 21.1 KB上图显示了一个节点在 1 级范围级别可以看到的单元格百分比,假设 C=2,并且 P(50、100 和 150)有不同的值。对于整个 P2P 网络中的每个节点,我们计算了它可以其 1 级范围中看到的整个 2D 矩阵的单元格百分比。该图显示了中位数、第 1 个和第 3 个四分位数、须线和异常值。正如我们所看到的,节点拥有的对等节点越多,1 级范围覆盖率就越高,对于 P=150 个对等节点,高达 70%。区块大小会影响数据传播,因此分析节点需要下载的数据量至关重要。在这种情况下,所有节点都需要存储,因此每个插槽下载 2 2 512*560 = 1MB 的数据,这与今天在 EIP-4844 下节点必须为具有六个完整 blob 的区块下载的约 900KB 相差不远。
然而,扁平保管不是一种公平的数据分区策略,因为网络有许多不同类型的节点。在家里运行没有验证器的小节点与在云中运行具有数百个验证器的健壮节点是不同的。由于他们拥有的硬件、他们使用的网络带宽、他们存储的价值量以及他们产生的收入,这是两种非常不同的情况。因此,我们提出了另一种方法,该方法考虑了节点中运行的验证器数量以及按比例分配的预期资源。
验证器比例保管
在验证器比例 (VP) 保管模型下,保管分配基于节点拥有的验证器数量。这确保了具有更多验证器的节点承担更多责任,从而根据节点容量更有效地分配网络负载。
保管模型
在 VP 保管中,我们使用以下等式定义节点的总保管:
total_custody = min_custody + floor(val_per_node × val_custody)
其中
- 最小保管 (min_custody) 是每个节点应保管的最小行数和列数。这确保了每个节点,无论其验证器如何,都承担基本级别的数据责任。
- 每个节点的验证器 (val_per_node) 是指节点拥有的验证器数量。它是节点的属性。不同的节点具有不同的 val_per_node 值。
- 每个验证器的保管 (val_custody) 表示节点中分配给验证器的行数和列数。它是网络的属性。网络中的所有节点都将具有相同的 val_custody 值。请注意,此参数可以采用小数值,例如 0.5,并且节点将为其托管的每两个验证器添加一行/列。
模型参数化
现在我们有了一个保管模型,我们需要为该模型的参数赋值。
每个节点的验证器
为了使用验证器比例保管对网络进行建模,我们需要知道验证器在网络中的分布。由于过去开发的几个 爬虫程序,以太坊网络中今天的节点数量是 众所周知的。但是,每个节点的验证器数量是一个更棘手的问题。在我们之前的 研究工作 中, 我们使用了过去的证明主题订阅及其它额外数据来推断节点中托管的验证器数量。根据该研究,大约 10% 的节点拥有 64 个或更多验证器,而 80% 的节点没有或只有少量验证器,并且网络中最重的节点托管大约 3000 个验证器。这项工作使用相同的每个节点的验证器分布,如下图所示。请注意,即使我们有网络中节点的列表并估计了每个节点的验证器数量的分布,我们仍然无法确定每个节点拥有的确切验证器数量。因此,在我们的模拟中,我们从给定的分布中观察到的值中为每个节点分配一个随机的验证器数量。这样,我们可以重现此处呈现的相同分布。
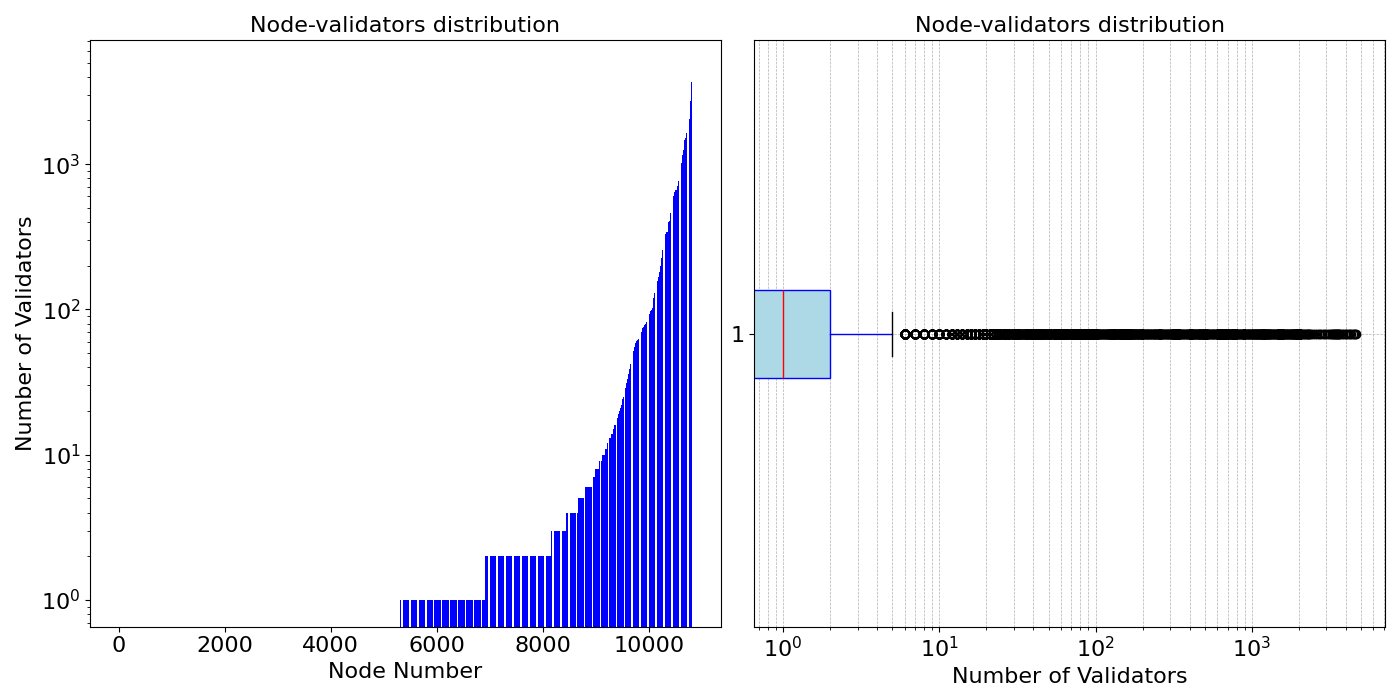 \
1400×700 46 KB
\
1400×700 46 KB每个验证器的保管
为了给 val_custody 参数赋值,我们可以首先询问节点何时应该下载整个区块。让我们选择一个任意数字,例如,每个验证器 1 行/列。从节点下载 256 行的那一刻起,它就可以使用 Reed-Solomon 编码自动重新生成另一半数据,从而最终保管整个区块,成为数据可用性 (DA) 提供商。重要的是要注意,在这种情况下,节点不需要同时下载行和列。仅下载行或列之一就足够了,因为它在纠删码之后具有全部数据。然后,让我们继续对具有 256 个验证器的节点进行经济分析。这样的节点正在保护 ETH 8192,按照今天的价格相当于超过 2000 万美元。因此,假设拥有如此多资金的节点有经济资源和动力在最好的硬件和网络条件下运行该节点似乎是合理的。这样的节点应该能够快速下载和重建每个区块。因此,我们可以设置 val_custody=1,以便具有 256 个验证器的节点将保管整个区块。如果我们想增加/减少节点保管大小和网络中 DA 提供商的数量,可以更改此参数,我们将在后面的章节中看到。
最小保管
我们使用不同的方法来为 min_custody 参数赋值。在这种情况下,目标是尽量减少没有验证器的小型家庭节点需要下载和存储的数据量。正如我们在扁平保管部分中看到的那样,保管大小为 2 行 2 列的节点必须每个插槽下载约 1MB 的数据,这与今天的具有六个 blob 的区块的情况非常接近。因此,在本研究的其余部分,我们设置 min_custody=2。
对等节点数量
在扁平保管的初步结果中,我们测试了不同数量的对等节点,从 50 到 150,正如我们在 之前的研究 中看到的那样,这些是今天可以实现的真实值。然而,该模拟的一个方面可能更具现实意义,即让所有节点的对等节点数量不完全相同。虽然大多数客户端保持在相同的范围内,但不同的 CL 客户端对对等节点数量具有不同的默认值。因此,我们调整了模拟器的代码,以便为对等节点的数量提供一个范围,而不是一个值。所有节点都在作为参数给定的范围内随机选择一个对等节点数量。例如,我们可以研究当对等节点数量在 50 到 100、100 到 150 和 150 到 200 之间变化时会发生什么。正如我们稍后将看到的那样,我们可以进一步探索当我们增加这些范围时会发生什么。
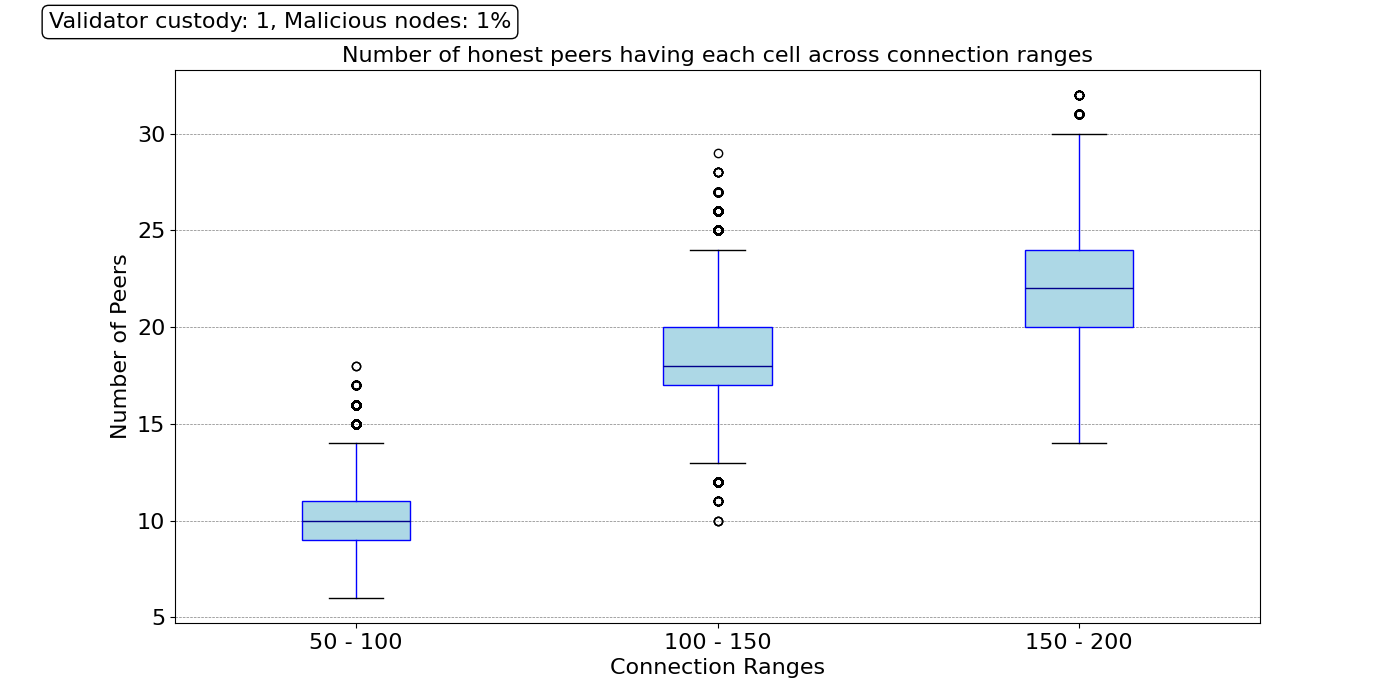 \
1400×700 34.1 KB
\
1400×700 34.1 KB因此,我们使用对等节点数量 P 的这三个范围和与上一节相同的保管参数 C(即,min_custody=2,val_custody=1)来研究抽样性能。例如,我们可以问一个问题:对于一个特定的单元格,有多少直接对等节点(1 级)保管此单元格?然后,我们可以对另一个单元格重复相同的问题,依此类推,直到我们获得区块中所有 262,144 个单元格的答案。然后,我们可以绘制这三个不同 P 范围的分布。结果如下图所示。
我们可以看到,平均而言,即使对于 50 到 100 个对等节点的连接范围,大多数单元格也由大约十个直接连接的对等节点(1 级)保管。当我们增加对等节点连接的数量时,1 级范围会增加,从而提高了分布式网络的可靠性。对于 150 到 200 个对等节点的范围,区块的单元格平均可以在大约 33 个直接对等节点中找到,并且所有单元格都至少在 20 个直接对等节点的保管集中。
评估
在本节中,我们执行多个模拟以评估多种情况下的抽样性能。我们对两个关键指标感兴趣:
- 1 级范围:这使我们能够了解可以快速(1 跳)回答的查询的百分比。它还显示了网络的可靠性级别,因为它间接表达了网络中的数据冗余。对于此指标,越高越好。
- 每个节点下载的数据量:这显示了不同类型的节点应具有的网络要求才能运行节点。这与网络的去中心化程度直接相关。对于此指标,越低越好。
乐观情况
我们关注的第一种情况是“乐观”情况,其中 99% 的节点行为正确,并且没有任何类型的性能问题,无论是网络数据丢失还是硬件故障。使用上述定义的比例保管模型和参数,与之前提出的扁平保管模型相比,1 级范围的单元格覆盖率显着提高,如下图所示。
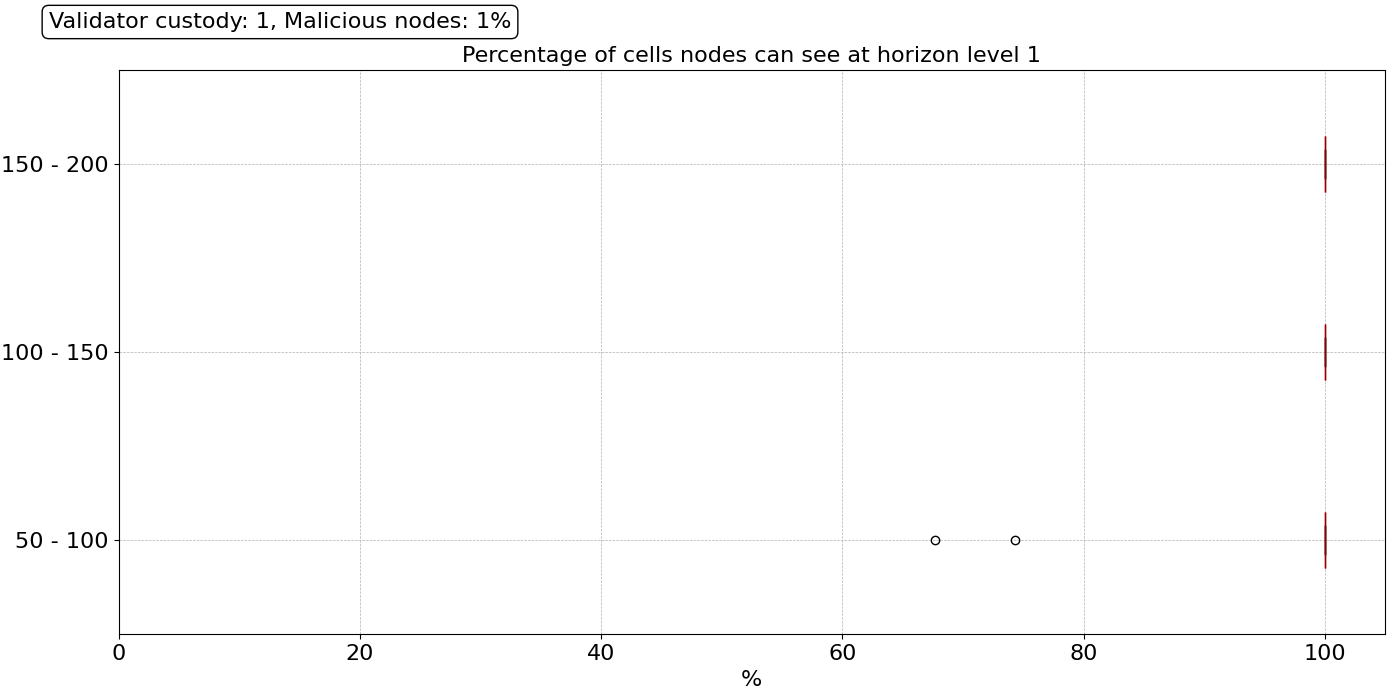 \
1400×700 29.9 KB
\
1400×700 29.9 KB所有节点都可以在一跳内访问所有单元格,并且对于所有三个对等节点数量范围都是如此,除了 50-100 个对等节点范围内的一些异常值。这是因为,在比例保管模型下,节点通常具有更大的保管集,并且还因为在其 1 级范围内存在 DA 提供商(具有 256 个或更多验证器的节点)。
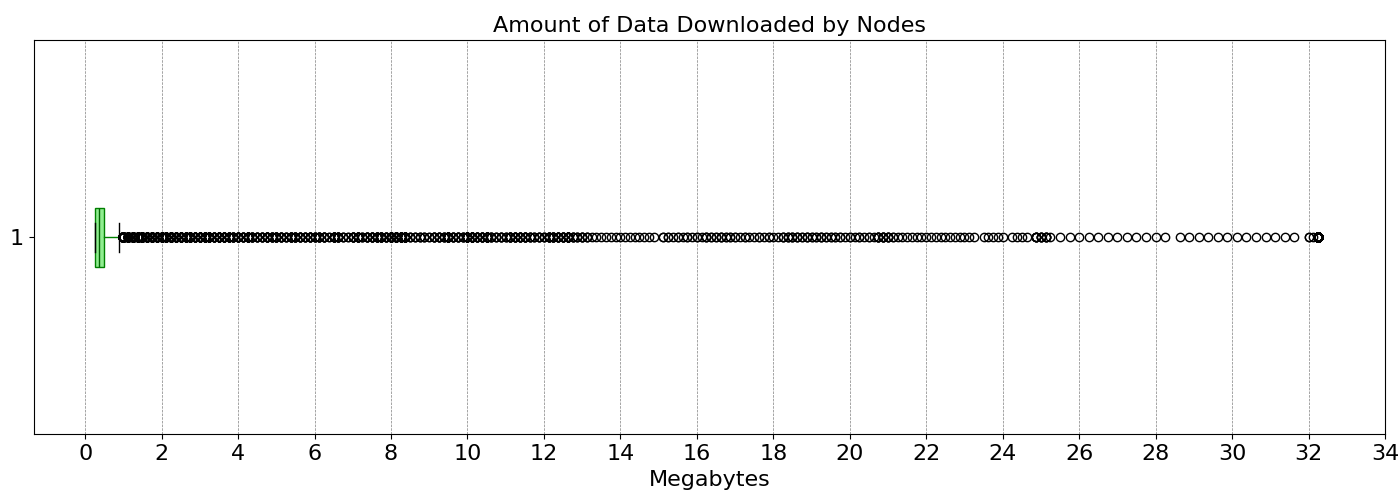 \
1400×500 27.7 KB
\
1400×500 27.7 KB关于需要下载的数据量,我们可以在上图中看到,大多数节点每个插槽下载的数据量少于 1 MB。只有少数异常值,主要是 DA 提供商,下载超过 2MB 的数据,直至整个区块(约 32MB)。这些结果表明,可以在理想条件下执行快速抽样,同时保持大多数节点的低下载需求。这是一个理想的结果,因为它保证了高安全性和高度去中心化。现在,让我们分析在更灾难性的情况下会发生什么。
相关故障
在本节中,我们将演示当发生相关故障时会发生什么,其中给定的特征与大量节点相关,并且此特征是故障的根本原因。感谢我们在 MigaLabs 的开源网络爬虫,我们拥有关于共识层网络中所有节点的详细信息,包括他们的 ISP、地理位置以及他们正在使用的 CL 客户端。此数据使我们能够根据这些标准有选择地模拟特定节点组的关闭。
我们关注关于 CL 客户端多样性、地理分布和托管类型的三种情况。例如,如果大多数 CL 客户端(即 Lighthouse)部署了一个新版本,其中包含一个导致节点无法同步的错误,我们可能会在很短的时间内看到超过 35% 的节点关闭。如果节点集中度最高的国家(即美国)突然禁止加密货币(例如,由于新当选的总统候选人),也可能发生同样的情况。如果以太坊网络中使用的三个较大的云提供商(即 AWS、Hetzner 和 OVH)决定同时禁止所有与加密货币相关的活动,则可能发生类似的情况。因此,我们模拟了当 35% 的节点遭受相关故障并停止提供样本和转发任何类型的请求时会发生什么。
在分析系统的可靠性之前,让我们进行网络带宽分析。需要下载的数据量不受节点故障数量的影响。因此,带宽要求保持不变。下载数据可能需要更长的时间,因为许多节点不会在 Gossipsub 通道上转发任何内容。因此,应该发送更多请求。这可以忽略不计带宽,但会有延迟影响。这项工作仅关注保管和抽样方面;数据传播不在本文的讨论范围之内。有关传播模拟,请参阅我们的 之前发表的论文。
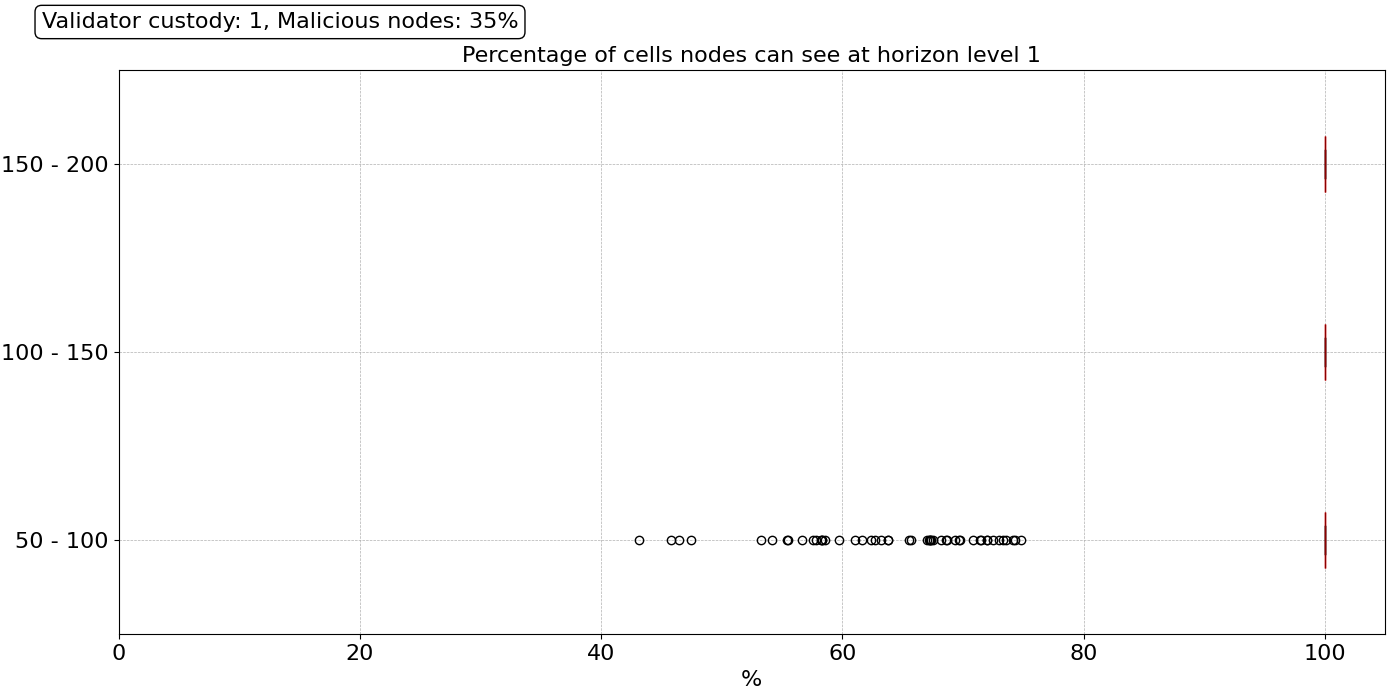 \
1400×700 31.2 KB
\
1400×700 31.2 KB关于抽样过程的鲁棒性,我们可以在上面的结果中看到,即使在这种灾难性的故障下,网络也高度可靠,并且 99.9% 的节点可以毫无问题地执行快速抽样(1 跳)。唯一的异常值是 50 到 100 个对等节点范围内的一些节点,它们在其 1 级范围内仅看到 40% 到 75% 的单元格。他们将需要到达其 2 级范围(2 跳)以满足其抽样需求,这意味着他们的抽样性能会较低,但这并不意味着他们一定会失败抽样过程。
为了了解这些异常值会如何扰乱网络,我们计算了网络中所有节点执行 75 个抽样查询需要多长时间。为此,我们为查询 1 级节点 st1 和查询 2 级节点 st2 分配一个抽样时间。我们还为节点查询恶意对等节点并且此对等节点不响应时设置一个超时。在这种情况下,节点必须对另一个对等节点启动第二个查询。以太坊网络中的大多数节点显示大约 100 毫秒的 RTT。因此,我们为我们的时间参数赋予以下值:st1=100~200 毫秒,st2=200~300 毫秒,to=500 毫秒。请注意,所有抽样查询都是并行启动的;唯一按顺序执行的查询是在超时后启动的查询。
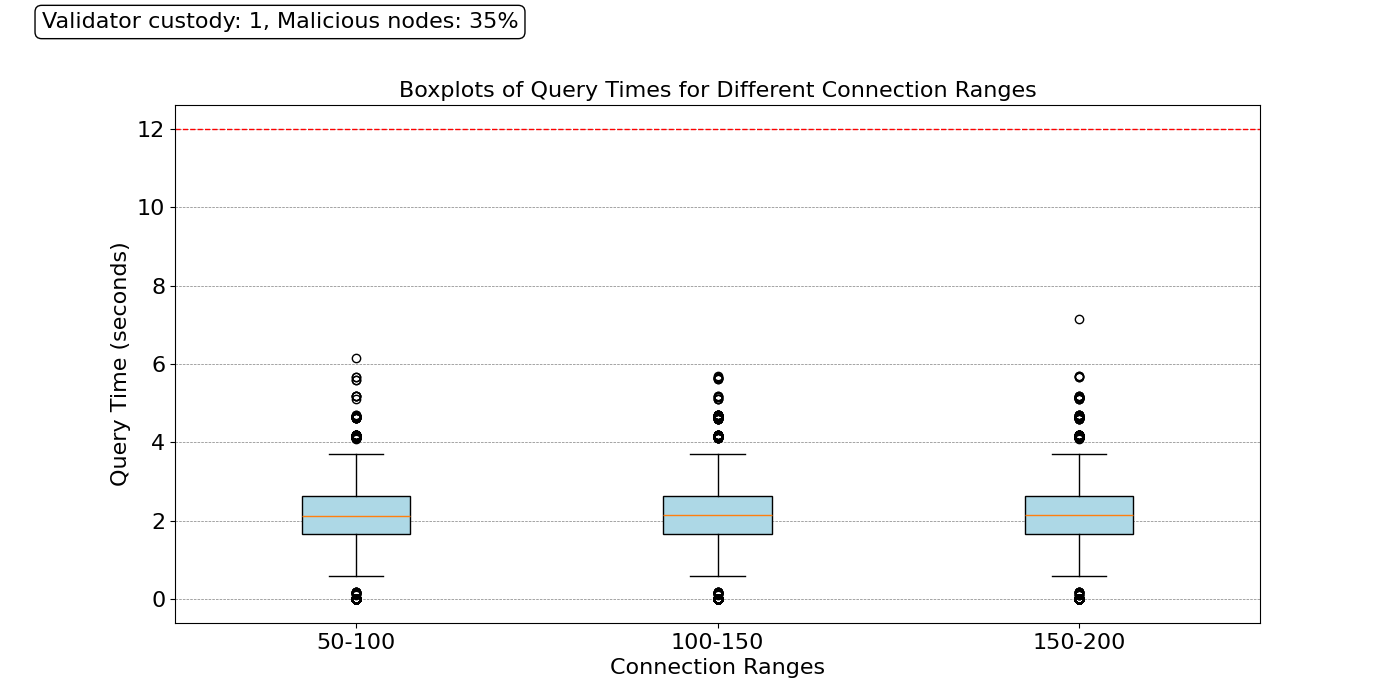 \
1400×700 37.5 KB
\
1400×700 37.5 KB在上面显示的结果中,我们可以看到,即使在这种灾难性的故障下,绝大多数节点也可以在 4 秒内完成其抽样任务。花费更多时间的节点是连续联系了多个恶意节点的节点。这些令人鼓舞的结果表明,即使在高度相关的故障下,也有可能实现高安全性,而不会损害去中心化。
拜占庭攻击
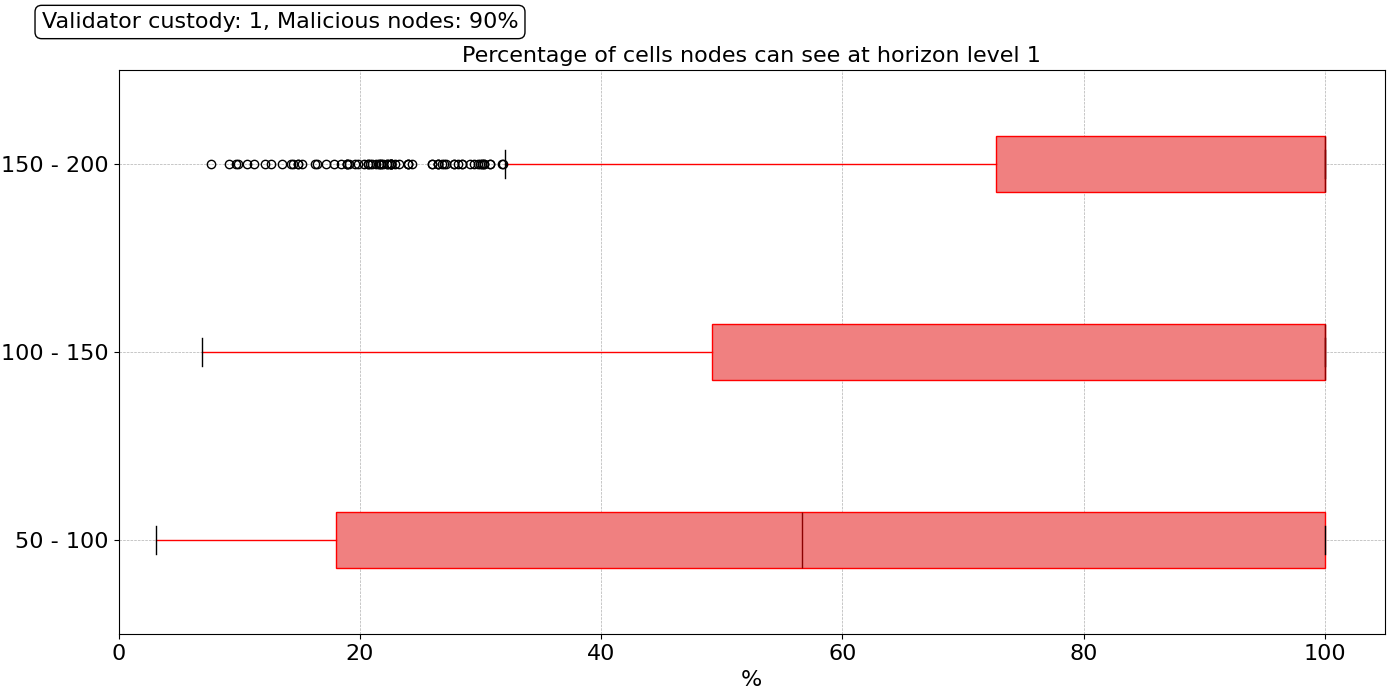 \
1400×700 31.2 KB
\
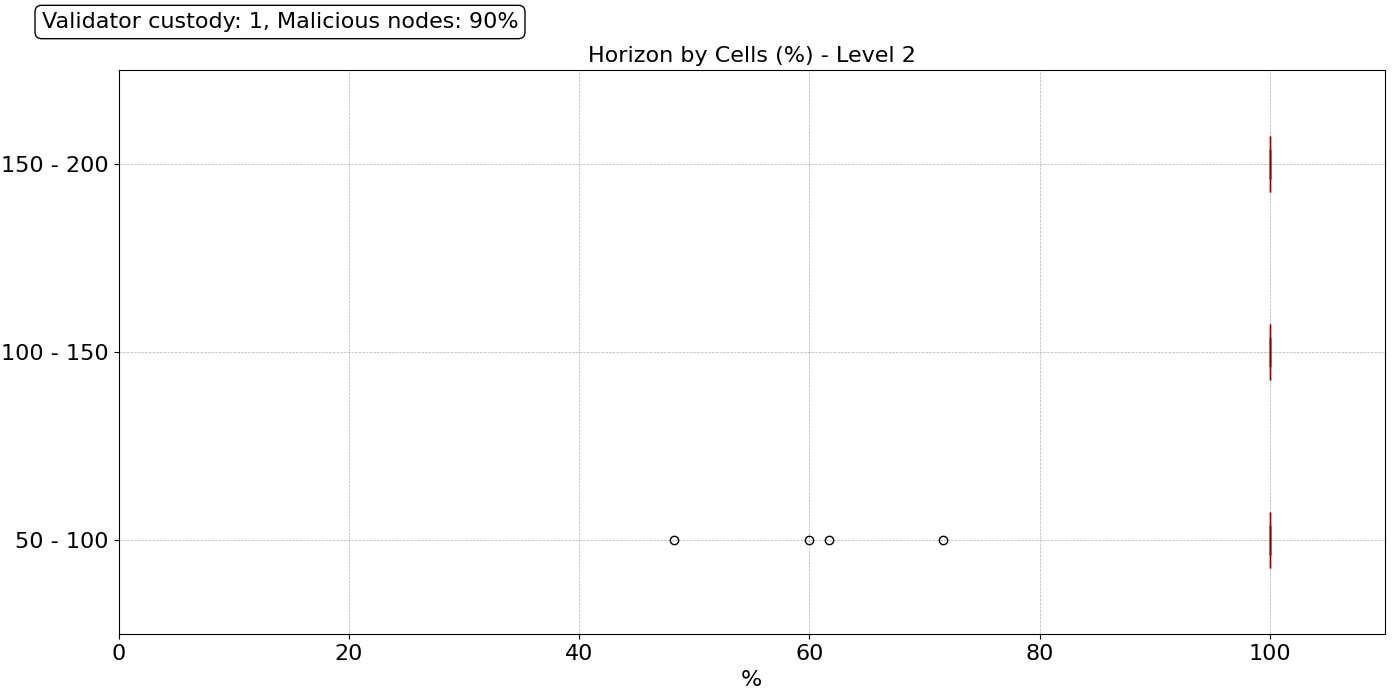
1400×700 31.2 KB现在,我们想将事情推向极端,并模拟一次协调攻击,其中绝大多数节点(90%)决定以恶意的方式行事,通过扣留数据并且不响应/转发抽样请求。我们模拟了网络中 60%、70%、80% 和 90% 的节点以恶意方式行事的情况,但为了本文的简洁,我们仅显示最坏情况的结果:无论其验证器数量如何,90% 的节点都是恶意的。这意味着即使 DA 提供商也可能是恶意的并扣留数据。
 \
1400×700 28.7 KB
\
1400×700 28.7 KB在这种情况下,我们看到 1 级范围存在显着差异。对于所有对等节点范围,这种分布都是灾难性的。绝大多数节点在 1 级上仅具有区块的部分视图。在查看 2 级时,情况有所改善,这主要是由于在其 2 级中存在诚实的 DA 提供商。然而,触手可及的诚实 DA 提供商并不能保证良好的抽样性能,因为在 90% 的恶意节点的情况下,通过纯粹的随机试验很难找到诚实的 DA 提供商。在这种攻击中,我们假设即使是恶意节点也会在一段时间内行为正确,直到他们决定发起攻击。在这些情况下,即使使用信誉机制,找到诚实节点也变得异常具有挑战性。
在这些条件下,节点将连续多次联系恶意节点,从而导致较长的抽样时间。我们计算了所有三个不同对等节点范围的所有节点的抽样时间,并在上图中绘制了分布。我们看到大多数节点需要超过 15 秒才能完成其抽样。但是,在以太坊协议中,存在时间限制,并且节点不能永远等待以确定区块是否可用。对于此实验,我们设置了一个硬最终超时 fto,它表示中断时间,如果 75 个抽样查询尚未成功完成,则节点会决定区块不可用。对于此示例,我们设置 fto=12 秒,请参见图中的红色虚线。
 \
1400×700 41.1 KB
\
1400×700 41.1 KB在这种情况下,只有少数节点设法及时完成其抽样查询。此实验的一个意外结果是,当我们增加对等节点数量时,抽样持续时间的分布会变宽,并且更少的节点设法及时完成抽样,如下图所示。当我们有许多直接对等节点时,我们会有一个大型恶意节点池,我们可能会在不知不觉中向其发送抽样查询。这意味着在这种大规模的协调攻击下,拥有大量已知的对等节点没有帮助,因为节点不知道哪些是对等节点是恶意的,哪些不是。在这些条件下,需要其他技术。
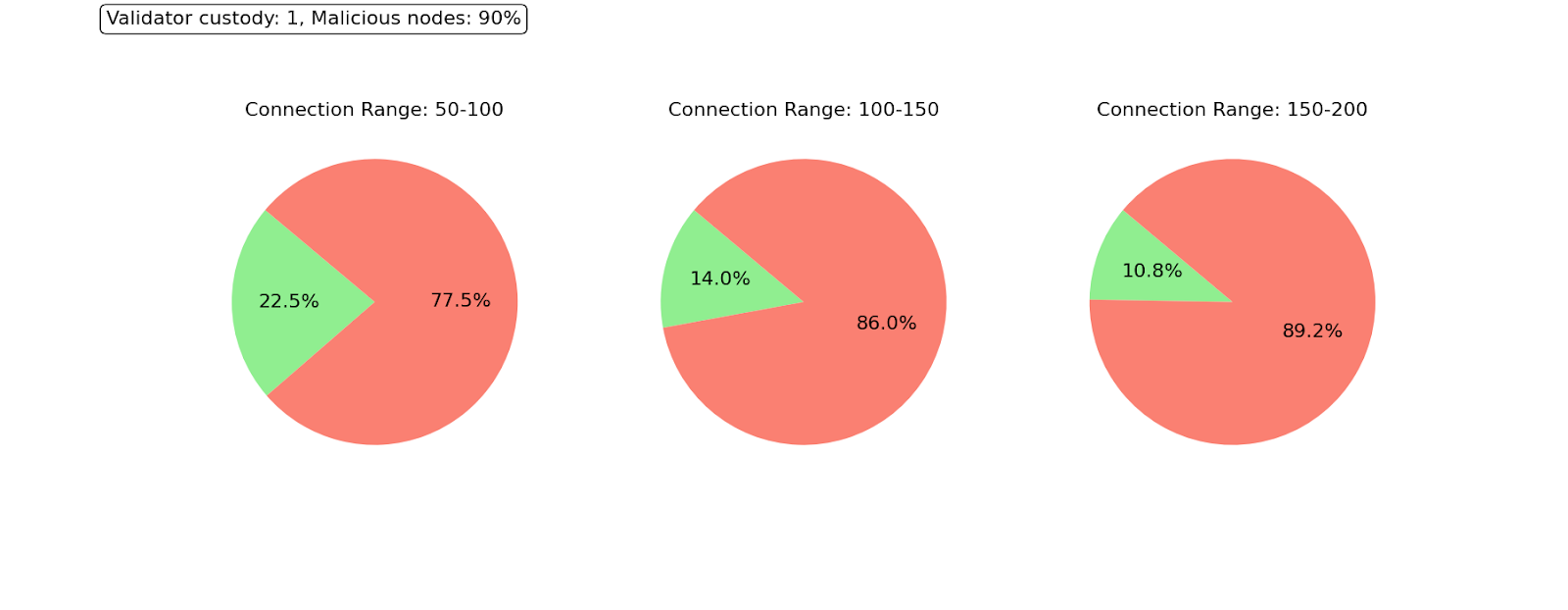 \
1600×622 56.1 KB
\
1600×622 56.1 KB缓解多数恶意攻击
增加复制
尝试缓解这些类型的攻击的一种方法是增加系统中数据的复制量。这可以通过增加验证器的保管来实现,以便具有验证器的节点保管更多的行和列,并且这也降低了成为 DA 提供商的门槛,这反过来又增加了网络中 DA 提供商的数量。例如,如果我们设置 val_custody=4,则任何具有 64 个验证器的节点都应该成为 DA 提供商,并且网络中会有更多的复制。但是,这不足以缓解此攻击,我们的模拟表明只有 15% 到 22% 的诚实节点将区块视为可用。此外,这也增加了所有节点的带宽需求,这是此策略的不良影响。
有损抽样
有损抽样 是另一种策略,允许节点在抽样过程中容忍一个或多个失败的查询。当缺少一个样本或少数几个样本时,这尤其有用。但是,有损抽样对于这种大规模的协调攻击几乎没有帮助。在这种情况下,大多数节点甚至没有完成一半的请求;因此,允许少数几个失败的查询不会以任何有意义的方式吸收拜占庭的错误。
讨论
在这项工作中,我们研究了完整 DAS 下的抽样过程,考虑了一组假设,主要与网络层相关,还有一些其他假设,例如验证器分布。我们已经证明,在公平的网络条件下,DAS 抽样不仅可以实现,而且可以非常快速地执行。我们已经提出了一些参数,研究人员可以利用这些参数来在去中心化和可靠性之间进行调整。该研究还表明了网络如何吸收大规模的相关故障,并且仍然可以可靠地执行抽样。
但是,这项工作有几个局限性:
- 在整个工作中,我们假设节点随机选择对等节点。实际上,节点可以调整其对等节点以改善其 1 级和 2 级范围,这应该会导致更加稳健的网络条件。在某种意义上,这项工作中提出的结果可以被视为基线,通过增强对等算法可以实现许多改进。
- 我们假设当节点在其范围 1 级中没有单元格时,它会随机联系一个节点以尝试到达潜在的 2 级节点。还有其他可以考虑并且我们没有在这项工作中考虑的策略。例如,topicID 路由可以在这种情况下提高性能。
- 整个研究都假设节点仅知道一小部分节点并且仅从该集合中进行抽样。但是,对等节点发现算法可以并行运行,并且节点可以在其数据库中存储相当多的对等节点。在同步时联系数千个对等节点并以巨大的 1 级范围启动整个抽样过程并非不可能。
- 这项工作假设了一个相当静态的视图,其中节点的范围不会演变。但是,这是不现实的。随着节点发现其他对等节点,它们的范围会不断演变,并且抽样性能也会随之演变。
- 我们仅显示了 10K 个节点的网络和特定验证器分布的结果。但是,网络规模和验证器分布都可能在未来几年发生变化。因此,有必要在这些条件下进行实验。
结论
这项工作表明,在某些实际的网络假设下,可以大规模地执行快速抽样。该研究还表明,通过提出的策略,网络甚至可以吸收大规模的相关故障。但是,多数恶意攻击仍然是一个挑战,应进一步研究。
致谢
这项研究是在以太坊基金会在 FY24-1533 赠款下支持下完成的。
- 原文链接: ethresear.ch/t/full-das-...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





