Rust 实战:打造高效代码相似度分析工具
- King
- 发布于 2025-06-26 22:27
- 阅读 1665
引言在开源协作和代码审查中,识别代码相似度是一个重要但耗时的任务。今天,我将分享如何使用Rust语言构建一个高性能的代码相似度分析工具。这个工具不仅支持多种编程语言,还能分析代码结构、函数命名等多个维度的相似性。项目概览构建的code-sniffer是一个命令行工具,主要功能包
引言
在开源协作和代码审查中,识别代码相似度是一个重要但耗时的任务。
今天,我将分享如何使用 Rust 语言构建一个高性能的代码相似度分析工具。
这个工具不仅支持多种编程语言,还能分析代码结构、函数命名等多个维度的相似性。
项目概览
构建的 code-sniffer 是一个命令行工具,主要功能包括:
- 比较两个 GitHub 仓库的代码相似度
- 支持多种编程语言
- 提供详细的相似度报告
- 可配置的相似度阈值
核心技术点
1. 项目结构
code-sniffer/
├── Cargo.toml
├── README.md
└── src/
├── main.rs # 程序入口
├── cli.rs # 命令行参数解析
├── github.rs # GitHub 仓库操作
├── similarity.rs # 相似度计算核心
├── function_names.rs # 函数名提取与分析
├── architecture.rs # 代码结构分析
├── analysis.rs # 分析逻辑
└── utils.rs # 工具函数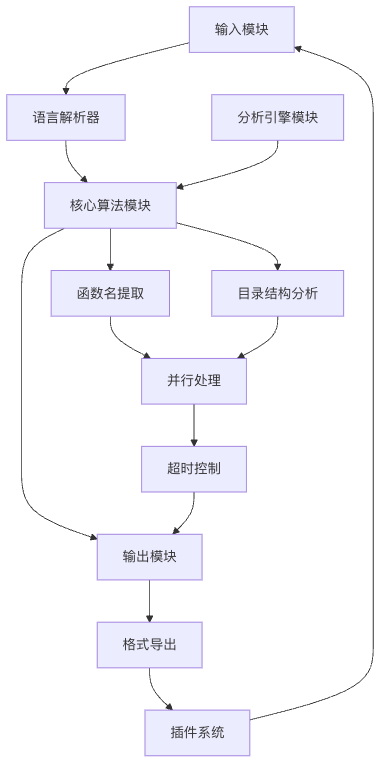
2. 核心功能实现
2.1 代码相似度计算
我们使用 Levenshtein 距离算法来计算两个字符串之间的相似度:
pub fn string_similarity(a: &str, b: &str) -> f64 {
let a_len = a.chars().count() as f64;
let b_len = b.chars().count() as f64;
if a_len == 0.0 && b_len == 0.0 {
return 1.0;
}
let distance = strsim::levenshtein(a, b) as f64;
let max_len = a_len.max(b_len);
1.0 - (distance / max_len)
}2.2 函数名提取
通过 Rust 的 syn 库解析代码 AST,提取函数名:
struct FunctionVisitor {
function_names: HashSet<String>,
}
impl<'ast> syn::visit::Visit<'ast> for FunctionVisitor {
fn visit_item_fn(&mut self, i: &'ast ItemFn) {
self.function_names.insert(i.sig.ident.to_string());
syn::visit::visit_item_fn(self, i);
}
// 其他 visit_* 方法...
}2.3 目录结构相似度
使用 Jaccard 相似度算法比较两个代码库的目录结构:
pub fn calculate_structure_similarity(
set1: &HashSet<String>,
set2: &HashSet<String>
) -> f64 {
let intersection_size = set1.intersection(set2).count() as f64;
let union_size = set1.union(set2).count() as f64;
if union_size == 0.0 {
0.0
} else {
intersection_size / union_size
}
}使用示例
- 安装工具:
cargo install --path .- 比较两个仓库:
code-sniffer user1/repo1 user2/repo2 --threshold 80- 查看详细的相似度报告:
=== Code Similarity Analysis Report ===
Repository 1: xxx
Repository 2: yyy
=== Similarity Breakdown ===
Content Similarity: 34.78% (40% weight)
Structure Similarity: 75.00% (30% weight)
Function Name Similarity: 33.57% (15% weight)
Architectural Similarity: 47.19% (15% weight)
-----------------------------------
Overall Similarity: 48.53%
Threshold: 70%
✅ No significant similarity detected above the threshold.
• The file contents show significant differences.
Note: This is an automated analysis. Please review the code manually for a complete assessment.
Analysis complete!
Similarity score: 48.53%性能优化
- 并行处理:使用
rayon库实现并行文件处理 - 超时机制:为耗时的比较操作设置超时
- 增量分析:跳过测试和示例目录
- 内存优化:使用迭代器避免不必要的数据加载
扩展性设计
- 插件系统:支持自定义相似度分析器
- 多维度分析:结合代码结构、命名风格、控制流等多个维度
- 结果导出:支持 JSON、HTML 等多种格式
总结
通过这个项目,展示了如何利用 Rust 的强大特性(如零成本抽象、模式匹配、并发安全等)构建高性能的代码分析工具。该工具不仅适用于代码相似度检测,还可以扩展用于代码质量分析、重构建议等场景。
下一步计划
- 支持更多编程语言的语法分析
- 添加机器学习模型提高相似度检测准确率
- 开发 IDE 插件实现实时分析
- 添加 CI/CD 集成支持
希望这篇文章对你有所启发!如果你有任何问题或建议,欢迎在评论区留言讨论。
- 原创
- 学分: 10
- 分类: Rust
- 标签: Rust 相似度分析 Jaccard Levenshtein



本文参与登链社区写作激励计划 ,好文好收益,欢迎正在阅读的你也加入。


