Blob共享协议
- dapplion
- 发布于 2023-12-08 19:52
- 阅读 1603
本文档提出了一个blob多路复用器的概念,旨在提高rollup使用blobs的经济效率,特别是对于需要频繁提交数据的小批量数据。讨论了可信和非可信多路复用器的设计,以及身份验证、审查阻力和支付结算等方面的考虑,并探讨了ZK rollup和Optimistic rollup等用例。
感谢 @eduadiez, @aliasjesus, @kevaundray, @dankrad, @protolambda @n1shantd, @rauljordaneth, @dmarzz 的有益讨论
动机
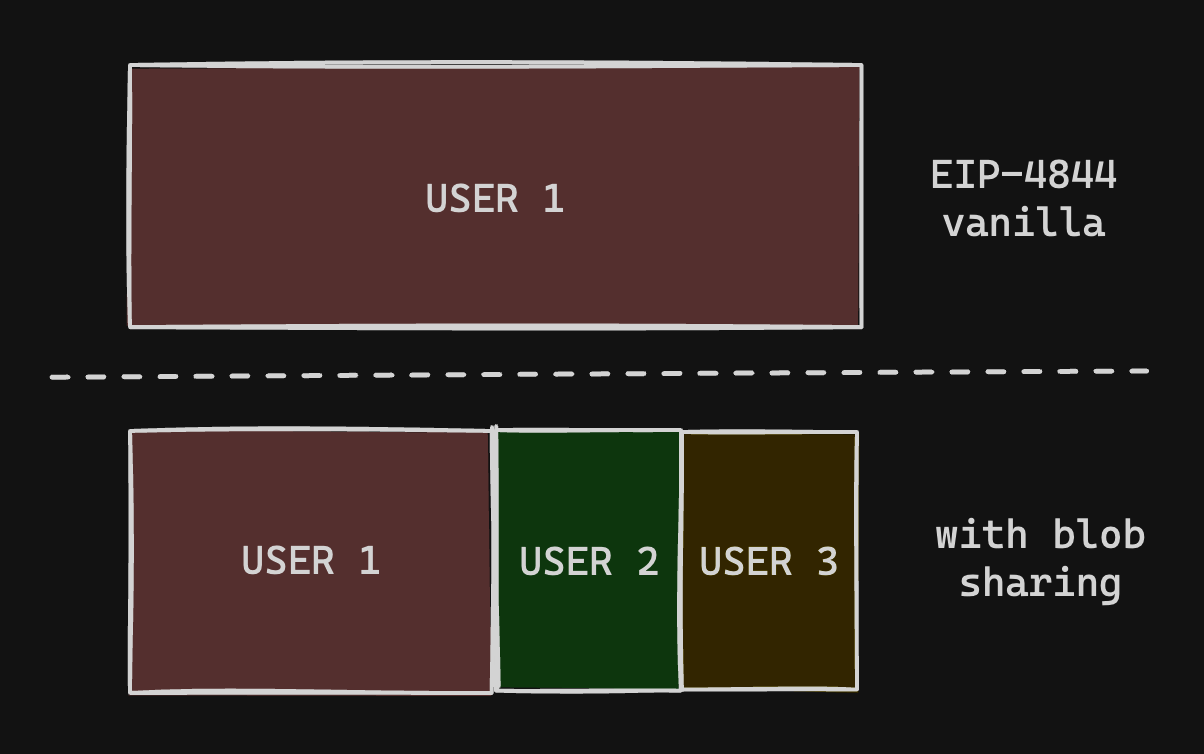
Blob 的定价模型比交易 calldata 更严格:你只能以 131072 字节的块为单位购买数据。
为了在经济上有效,如今的 Rollup 可以:
- 等待时间
t 来缓冲 131072 字节以填充整个 blob
- 以间隔
t/k 更频繁地发布,与其他参与者共享 blob
此外,为了执行原子操作,ZK Rollup 需要发布数据以及有效性证明,以实现即时最终性。如果 UX 要求需要频繁提交,Rollup 可能希望在能够填充整个 blob 之前执行状态更新。
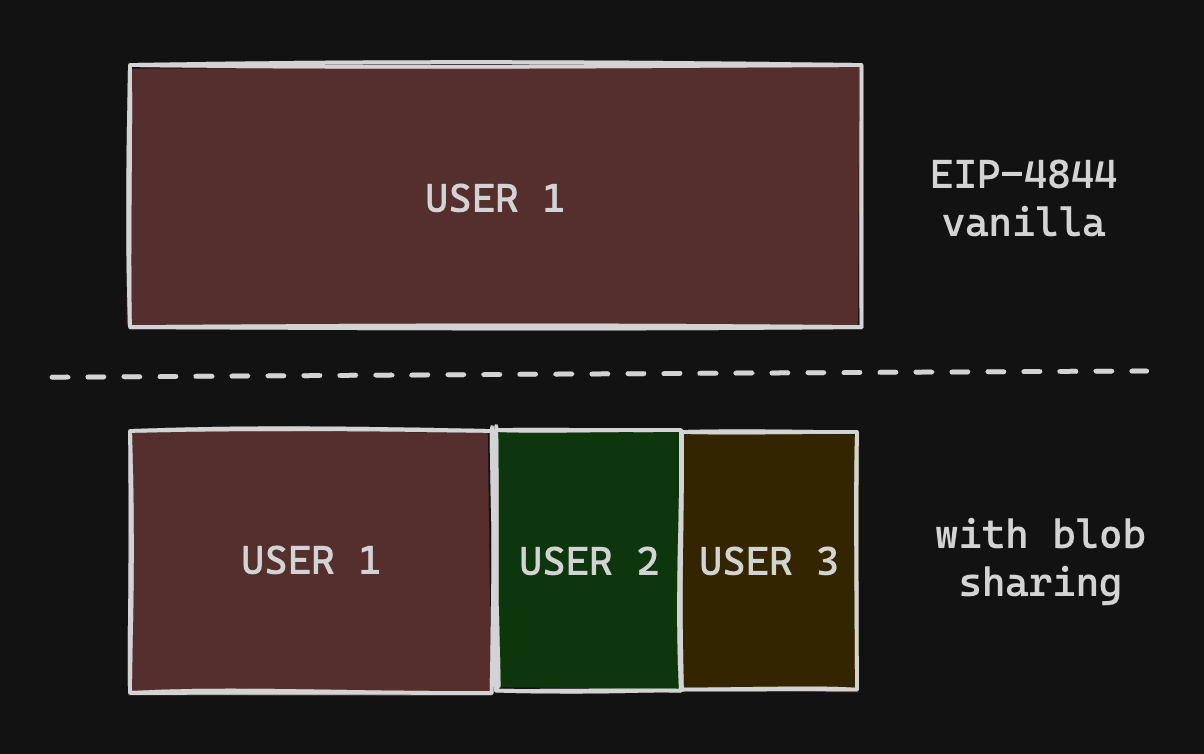
使用模式示例
概述
在其最基本的形式中,blob 多路复用器服务的使用看起来像以下序列。
Created with Raphaël 2.2.0PublishersPublishersMultiplxMultiplxChainChainConsumersConsumersI am willing to pay X_1to include data_1 on chainI am willing to pay X_2to include data_2 on chainConcat data_1 + data_2 send as blob txFilter and readPublisher's data让我们首先介绍一些要求。稍后我们将详细讨论为什么它们是必要的:
- 与自我发布完整 blob 相比,用户产生的最小(理想情况下为零)开销
- 数据提交及其位置应由用户进行身份验证
- 用户应该能够以低廉的成本从 L1 过滤和导出其发布的数据
此协议最初侧重于将排序器作为用户。如今,所有主要的 Rollup 都需要许可的排序器,即只有授权方才能发布数据。因此,当将数据发布中继到第三方时,必须存在一些与授权排序器实体的链接。
在可能的情况下,首选无信任协议,而不是受信任的解决方案。但是,上述要求使得提供经济上吸引人的无信任协议非常困难。
| 受信任的多路复用器 | 无信任的多路复用器 | |
|---|---|---|
| 支付结算 | 链下,事后 | 链上,原子 |
| 每个字节的成本开销 | 零或可忽略不计 | 显著 |
| 抗审查性 | 有点,可以通过包含证明来实现 | 有点,可以通过包含证明来实现 |
| 数据来源身份验证 | 有点,通过数据签名 | 是,必需 |
无信任协议的设计需要一个关键原语:你能否简洁地证明 datai 属于连接数据的承诺的版本哈希?以下各节描述了解决此问题的尝试。
。
如果没有此原语,就很难构建无信任的多路复用器层,因为你无法构建无信任的支付。
受信任的多路复用器
支付结算
提供多种结算选项非常简单,因为多路复用器是受信任的一方。这可能包括:
- 通过链上或链下交易预付积分
- 支付通道,在每次成功包含后更新
- 法定货币订阅模式,例如 Infura 或 Pinata
数据来源身份验证
如今,Rollup 需要许可的排序。如果数据由第三方(blob 共享协议)发布,则必须存在一种验证数据来源的方法。添加更复杂的身份验证协议会增加每个字节的成本。
第二个交易来验证指针
多路复用器仅发布数据,并期望消费用户执行第二个操作,以包含指向先前发布数据的经过身份验证的指针:
Created with Raphaël 2.2.0PublisherPublisherMultiplxMultiplxChainChainConsumerConsumerPost data X, YBuffer dataSend blob txVerify data in blobAuthenticate data + locationIterate publisherpointers要导出 L2 链,只需迭代经过身份验证的指针并解析其数据。
带有数据签名的单笔交易
无需第二个交易或额外的通信往返。但是,如果没有下载完整的 blob,观察者就无法确信 blob 的真实性。
Created with Raphaël 2.2.0PublisherPublisherMultiplxMultiplxChainChainConsumerConsumerPost data X + sigBuffer dataSend blob txIterate Multiplxtxs with Publishersignatures要导出 L2 链,请迭代 Multiplx 交易,并按来自用户(rollup)地址的有效签名的相关 blob 交易进行过滤。
多路复用器不是受信任的一方,并且可以发布无效数据。在 TODO 部分中,我们将探讨如何验证数据,但目前需要下载完整的 blob 才能最终确定其正确性。与数据的唯一链接是 blob 版本化哈希。
抗审查性
在受信任和无信任的多路复用器中,发布者都不能明确地强制多路复用器发送 blob 交易。因此,多路复用器可以通过忽略其数据发布请求来审查发布者。
多路复用器积极地受到激励,要包含数据发布请求以收取费用。但这可能不足以防止有利可图的审查攻击。在受信任的模型中,运行多路复用器的公司的社会声誉增加了一层额外的保护。
也可以通过惩罚来激励多路复用器不要排除数据发布请求。考虑以下协议:
- 多路复用器质押一些资金
- 发布者提供数据发布请求(即,将其包含在区块链中)
- 在一段时间超时后,发布者触发对上述可用请求的乐观审查声明
- 多路复用器有足够长的时间来链上证明发布请求的数据是过去规范区块的版本化哈希的一部分
- 如果多路复用器未能对审查声明提出异议,则其质押将被削减
现在,多路复用器被阻止(直至其质押价值)不审查发布者。但是,发布者应构建其协议,以便多路复用器和他们自己都可以发布数据。
无信任的多路复用器
WIP TODO
需要一些机制来执行基于 blob 包含的用户支付。
在 Intel SGX 上的受信任执行
EthGlobal istanbul '23 项目正在尝试使用 Flashbots SUAVE 架构:https://ethglobal.com/showcase/blob-merger-k7m1f
链上证明
需要一些尚未弄清楚的原语,并且在 L1 上执行可能会过于昂贵。
- TODO:在知道完整 blob 之前,弄清楚一个协议来证明版本化哈希包含用户签名承诺的数据
用例示例
ZK Rollup (Polygon ZK-evm)
ZK Rollup 有一些额外的要求来优化证明者成本:
- 排序器必须能够在 SC 级别形成哈希链 = 聚合器必须不能无信任地检查是否按顺序提交批次
- 排序器链上智能合约必须能够测试数据完整性
有关其当前架构的详细信息,请参阅 Polygon ZK-evm 如何发布/消费数据。
为了优化成本,链上 ZK 证明者通常使用很少的(或单个)承诺来最小化公共输入,以用于计算所需的所有数据。验证器电路的一部分包括检查承诺是否正确。使用 EIP-4844,此单个承诺必须包含版本化哈希作为与交易数据的唯一链接。
如何验证聚合 blob 上的数据子集
最便宜的策略是在其原生字段中计算完整数据的 KZG 承诺,然后进行等效性证明(参见 @dankrad/kzg_commitments_in_proofs)。然后提取你感兴趣的子集数据以进行其余的电路执行。虽然它需要摄取一些
k 系数的数据,根据 @eduadiez 的说法,这并不重要。
因此,处理完整 blob 或部分 blob 上 DA 的逻辑是相同的。实现部分 blob 读取,并将偏移量设置为 0 数据以用于完整 blob 情况。
TODO 其余部分的集成 @aliasjesus, @eduadiez
乐观 Rollup (OP Stack)
目前,OP Stack 使用一种非常简单的策略来发布数据,即向某个预定地址发送 blob 交易。它使用交易的签名来验证数据来源。
此体系结构必须略有更改,以适应从第三方(不受信任的)帐户发布的数据。
TODO 集成,@protolambda
附录:blob 检索
来自 EVM 的版本化哈希
https://learnblockchain.cn/docs/eips/EIPS/eip-4844#opcode-to-get-versioned-hashes
版本化哈希仅在 EVM 的交易执行期间可用。指令 BLOBHASH 读取 index 参数并返回 tx.blob_versioned_hashes[index]
Blob 数据
Beacon API 路由 getBlobSidecars 允许检索 BlobSidecars 的 block_id 和一组 blob indices
class BlobSidecar(Container):
index: BlobIndex # Index of blob in block
blob: Blob
kzg_commitment: KZGCommitment
kzg_proof: KZGProof # Allows for quick verification of kzg_commitment
...
附录:数据身份验证协议
附加身份验证后缀以消除发送消费交易。为了最大程度地降低内在成本。数据读取器需要丢弃无效数据的能力。
在发送 blob 交易 calldata 中附加用户的签名以验证正在提交的数据。
向链证明 blob 包含该数据。
数据[128:256] 属于地址 Y,
理由
- **无效偏移量问题:由于排序器在多路复用器发布数据后启动了稍后的交易,因此它可以仅在链下验证数据的完整性,并发布正确的偏移量和数据长度
问题:
- 排序器合约是否可以仅使用历史区块的证明来引用原始交易?更昂贵,但会绕过支付机制。
- 消费交易真的有必要吗?
- Proto 强烈考虑让完整节点也遵循该链。那么你的导出 L2 自 L1 函数是什么样的?以及它在与你相关的数据与下载的数据方面是否有效
结构 1
读取过程:
- 读取 send_blob_tx calldata
- 验证范围证明是否与 blob 的 KZG 承诺匹配,而无需加载完整 blob
- 需要避免重播标头而不包含数据
- 验证排序器签名是否正确
- 需要不读取来自其他人的垃圾数据
- 读取 blob,仅提取在范围证明中证明的数据
call_data = [ Signed KZG range-proof over chunk ] = sign_by_rollup_sequencer(range_proof(range info, KZG proof data))blob = [ chunk 0 ][ chunk 1 ] ...chunk = [ data ]
结构 2
读取过程:
- 读取 send_blob_tx calldata
- 验证范围证明是否与 blob 的 KZG 承诺匹配,而无需加载完整 blob
- 需要避免重播标头而不包含数据
- 验证排序器签名是否正确
- 需要不读取来自其他人的垃圾数据
- 读取 blob,仅提取在范围证明中证明的数据
call_data = [ Signed KZG range-proof over chunk ] = sign_by_rollup_sequencer(range_proof(range info, KZG proof data))blob = [ chunk 0 ][ chunk 1 ] ...chunk = [ data ]
附录:Rollup 如何发布/消费数据
概述了今天一些主要的 Rollup 如何在 EIP-4844 之前和之后发布和消费数据。
Dankrad 关于将 EIP-4844 集成到 Rollup 中的想法的相关注释:https://notes.ethereum.org/@dankrad/kzg_commitments_in_proofs
Polygon ZK-evm 如何发布/消费数据
- 排序器创建批次
- 在时间
t0,排序器将一批批次分组并将其发布到排序器智能合约(调用 PolygonZkEVM.sequenceBatches())
- 证明者监视链上交易并开始并行生成这些批次的证明
- 在时间
t1(在
t0 之后约 30 分钟),证明者将最终证明发布到验证器智能合约
当前的体系结构无法优雅地处理无效的排序器提交。因此,排序器角色是经过许可的。智能合约保证数据哈希是正确的,并且所有数据最终都由带有哈希链的证明者处理。
在 PolygonZkEVM.sequenceBatches 中,哈希链使用由先前的累加器哈希和当前交易组成的累加器进行计算(ref PolygonZkEVM.sol#L572-L581)。
// Calculate next accumulated input hash
currentAccInputHash = keccak256(
abi.encodePacked(
currentAccInputHash,
currentTransactionsHash,
currentBatch.globalExitRoot,
currentBatch.timestamp,
l2Coinbase
)
);
仅持久化数据以与此批次的累加器哈希中的未来验证器提交链接(ref (PolygonZkEVM.sol#L598-L602)[ https://github.com/0xPolygonHermez/zkevm-contracts/blob/aa4608049f65ffb3b9ebc3672b52a5445ea00bde/contracts/PolygonZkEVM.sol#L598-L602])
sequencedBatches[currentBatchSequenced] = SequencedBatchData({
accInputHash: currentAccInputHash,
sequencedTimestamp: uint64(block.timestamp),
previousLastBatchSequenced: lastBatchSequenced
});
在 PolygonZkEVM.verifyBatchesTrustedAggregator 中,验证器发布具有其证明的新根。验证证明的实际调用是 rollupVerifier.verifyProof(proof, [inputSnark])(ref),其中 inputSnark 是使用排序器提交的数据计算的(ref (PolygonZkEVM.sol#L1646-L1675)[ https://github.com/0xPolygonHermez/zkevm-contracts/blob/aa4608049f65ffb3b9ebc3672b52a5445ea00bde/contracts/PolygonZkEVM.sol#L1646-L1675])
bytes32 oldAccInputHash = sequencedBatches[initNumBatch].accInputHash;
bytes32 newAccInputHash = sequencedBatches[finalNewBatch].accInputHash;
bytes memory inputSnark = abi.encodePacked(
msg.sender, // to ensure who is the coinbase
oldStateRoot, // retrieved from smart contract storage
oldAccInputHash, // retrieved from smart contract storage
initNumBatch, // submitted by the prover
newStateRoot, // submitted by the prover
newAccInputHash, // retrieved from smart contract storage
newLocalExitRoot, // submitted by the prover
finalNewBatch // submitted by the prover
);
Arbitrum 如何发布/消费数据
SequencerInbox.addSequencerL2BatchFromOrigin
EIP-4844 发布后
WIP diff https://github.com/OffchainLabs/nitro-contracts/compare/main…4844-blobasefee
版本哈希是从抽象接口读取的,尚未定义。参考 src/bridge/SequencerInbox.sol#L316
- TODO:为什么这里使用
data?它不是 RLP 序列化的交易,而是合约调用数据
bytes32[] memory dataHashes = dataHashReader.getDataHashes();
return (
keccak256(bytes.concat(header, data, abi.encodePacked(dataHashes))),
timeBounds
);
OP Stack 如何发布/消费数据
对 EIP-4844 支持的 PR(没有智能合约更改)
https://github.com/ethereum-optimism/optimism/pull/7349
_Optimism 在 eip4844 之前的构造
- 收件箱地址,EOA
- 批处理器将交易提交到收件箱地址
- 验证器遍历目标地址:收件箱地址的交易列表
- 检查签名是否来自批处理器
附录:EIP-4844 经济学和 Rollup 策略
Davide Crapis、Edward W. Felten 和 Akaki Mamageishvili 的论文
https://arxiv.org/pdf/2310.01155.pdf
TODO,按 TLDR;
(1) 当 rollup 应该使用数据市场而不是主市场来发送数据到 L1 时?
(2) 聚合来自多个 rollup 的数据是否存在实质性的效率提升?数据市场费用会发生什么变化?
(3) Rollup 何时决定聚合?最佳的成本分摊方案是什么?
附录:数据子集的 KZG 承诺证明
数据发布者有一个数据块 data_i 编码为
(wi,yi) 其中
i∈0,...,k−1。它计算一个承诺
Ci,然后进行签名。多个发布者发送被签名的 data_i 和
Ci 给聚合器。每个块可能具有不同的
k。
聚合器连接不同大小的数据块,并计算一个总承诺
C,该承诺将作为 blob 交易的一部分发布在链上。
[ data_0 ][ data_1 ][ data_2 ]
[ data ]
聚合器必须允许验证器确信签名的
Ci 承诺属于
C。让我们定义
Cio 作为数据块的承诺,偏移量为
t。证明有两个步骤:
- 证明
Ci 等于
Cio,乘以
wt
- 证明
Cio 属于
C
术语
- f(x) 是连接数据的插值多项式。
- fi(x) 是使得
f(wj)=yj 其中
j∈0,...,k−1
- fio(x) 是使得
f(wt+j)=yj 其中
j∈0,...,k−1
- C=[f(τ)],并且
Ci=[fi(τ)],并且
Cio=[fio(τ)]
证明 Cio 等于 Ci,乘以 wt
插值多项式在单位根处求值,在我们的示例中为
wj 其中
j∈0,...,k−1。单位根可以通过乘以
wt 来移位
t 次。
Cio 和
Ci 是相同点集的多项式承诺,仅乘以
wt。我们需要证明
fio(x)=fi(wtx)。使用 Schwartz–Zippel 引理,我们可以证明确定性随机点
r 的恒等式,
fio(r)=fi(wtr)。
r 是从承诺
Cio 和
Ci 计算出来的。
验证器会获得
t,
Cio,
Ci 和评估证明
fio(r) 和
fi(wtr)。验证例程:
- 从
Cio 和
Ci 计算
r
- 验证评估证明
fio(r) 和
fi(wtr)
- 检查
fio(r)==fi(wtr)
证明 Cio 属于 C
给定一个点子集
xj,yj 其中
j∈0,...,k−1 证明
f(xj)=yj。
fio(x) 是点子集上的插值多项式,使得
fio(xj)=yj 对于所有
j。
z(x) 是零多项式
z(xj)=0 对于所有
j。
τ 来自可信设置。我们构造一个商多项式
q(x):
q(x)=f(x)−fio(x)z(x)
对于此多项式存在(不能除以零),
f(x)−fio(x)=0 对于所有
j。 该证明为
π=[q(τ)]
验证器会获得
π,
C,
Cio。验证例程:
- 计算零多项式
Z(x) 并计算
[Z(τ)]
- 进行配对检查
e(π,[Z(τ)])==e([f(τ)]−[Iio(τ)],H)
有关更多详细信息,请参阅 Dankrad 的笔记 "Multiproofs" 部分或 arnaucube 的批量证明笔记。
- 原文链接: hackmd.io/@dapplion/blob...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





