深入剖析 Attestation:一项定量分析 - 数据科学
- 以太坊中文
- 发布于 2024-07-10 16:42
- 阅读 1320
本文深入分析了以太坊的 attestation 机制,通过对大量数据的统计和分析,探讨了 attestation 的延迟、失败率、不同客户端的表现、验证者(validator)的优劣,以及大区块、blob 和 proposer timing games 对 attestation 的影响。
深入研究 Attestation
我想提供一些关于以下方面的定量统计数据……
- Head-、target-和source投票,
- 单个节点运营商的 attestation 性能,包括最佳和最差的验证器,
- Attestation 时序和包含延迟,以及
- MEV-Boost、CL 客户端、Proposer Timing Games和Big Blocks with Blobs对 attestation 准确性的影响。

非常感谢 Caspar、DappLion、Barnabé 和 Potuz 的反馈和审核!
数据
我使用的数据范围从 slot 9,169,184 到 slot 9,392,415,总计 6,975 个 epoch,31 天的数据。
目标是提供一些分析 attestation 的初步结果,作为分析相关 attestation 惩罚的预热(EIP-7716)。
部分数据是我自己使用自定义解析脚本收集的。其他数据由 EthPandaOps 提供。这包括从每个客户端的节点在 悉尼、赫尔辛基和 旧金山地区运行收集的时序数据,所有节点都订阅了所有子网。对于 CL 客户端的分类,使用了 blockprint 工具。
重要的是,我的 solo staker 分类非常保守,以避免将专业的实体与 solo staker 混淆。总的来说,我的数据集包含 8,488 个被分类为 solo staker 的验证器。
用于创建图表的代码已发布在此 repo.
Attestation
基础知识
Attestation 是以太坊的核心。通过证明过去的检查点,以太坊的验证器就成为不可逆转的状态达成一致(Casper FFG)。此外,验证器使用 attestation 来就链的顶端达成一致,决定哪些交易得到确认,哪些不得到确认(LMD GHOST)。
每个验证器,以其 stake 为后盾,都参与每个 epoch,并被随机分配一个 slot,在此期间,它应该通过证明广播其对链的看法。
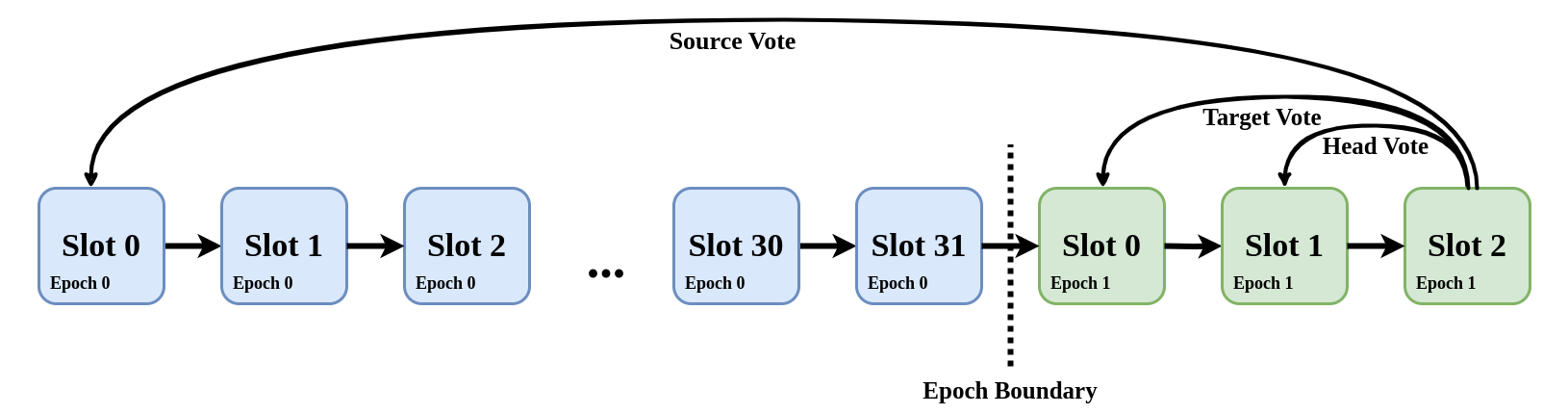
一个 attestation 包含三件事:
- 一个 source 投票:要最终确定的区块(以及所有前任区块)
- 一个 target 投票:要被证明是正确的区块(以及所有前任区块)(=pre-finalized)
- 一个 head 投票:被认为是链头的区块。
 \
epochslotvalidator1630×430 36.7 KB
\
epochslotvalidator1630×430 36.7 KB
自从包含 EIP-7045 的 Deneb hardfork 以来,epoch N 中一个 slot 的 attestation 可以包含到 epoch N+1 的结束。但是,包含并不能保证奖励:
为了获得奖励,验证器必须确保其 source 投票包含在 5 个 slot 内。target 投票必须包含在 32 个 slot 内才能获得奖励。head 投票必须包含在下一个 slot 中才有资格获得奖励。
截至今天,以太坊计数 ~1.03 百万个验证器。这意味着我们每个 epoch 有 103 万张选票,每个 slot 有 ~32,000 张。在一天内,有 225 个 epoch,大约有 2.25 亿个 attestation。这个数据增长得非常快。
如果 source 投票是无效的,那么 target 和 head 投票也必须是无效的。
一个 slot 可以分解为 3 个阶段:

- 验证器在他们看到当前 slot 的区块时或在 slot 中的第 4 秒(attestation 截止日期)证明。在 slot 中的第 0 秒广播的区块有 4 秒的时间被所有相关的验证器看到并收集投票。延迟的区块有收不到足够 attestation 并被后续区块 reorg 的风险。
- 在 slot 中的第 4 秒到第 8 秒之间,attestation 被 聚合 并由选定的验证器广播。
- 最终,后续的区块提议者将它们包含到它的区块中。
更多深入的解释,请查看 Georgios 和 Mike 关于“Time, slots, and the ordering of events in Ethereum Proof-of-Stake”的帖子。
定义
错过 vs. 失败:
- 验证器可以错过其 attestation(missed),也可以证明一个错误的检查点(failed)。
- 如果运行验证器的节点失去同步或离线,则可能发生 missed attestation。
- 为一个错误的检查点投票,例如错误的 head,可能有很多原因,例如收到区块太晚、失去同步甚至出现 bug 等。
- 无论是什么原因,一个failed投票告诉我们关于验证器的一个重要事实——它在线。
接下来,我们还需要术语“高性能验证器”,它指的是在分析的整个时间范围内,没有未能及时投出正确 head 投票的验证器。
Attestation 包含延迟
在最佳情况下,attestation 包含在下一个 slot 的区块中,导致延迟为 1。有时,特别是当下一个提议者离线或被 reorg 时,attestation 不包含在下一个 slot 中。然后,验证器错过了来自正确 head 投票的奖励,即使 attestation 仍然可以包含在后面的区块中。
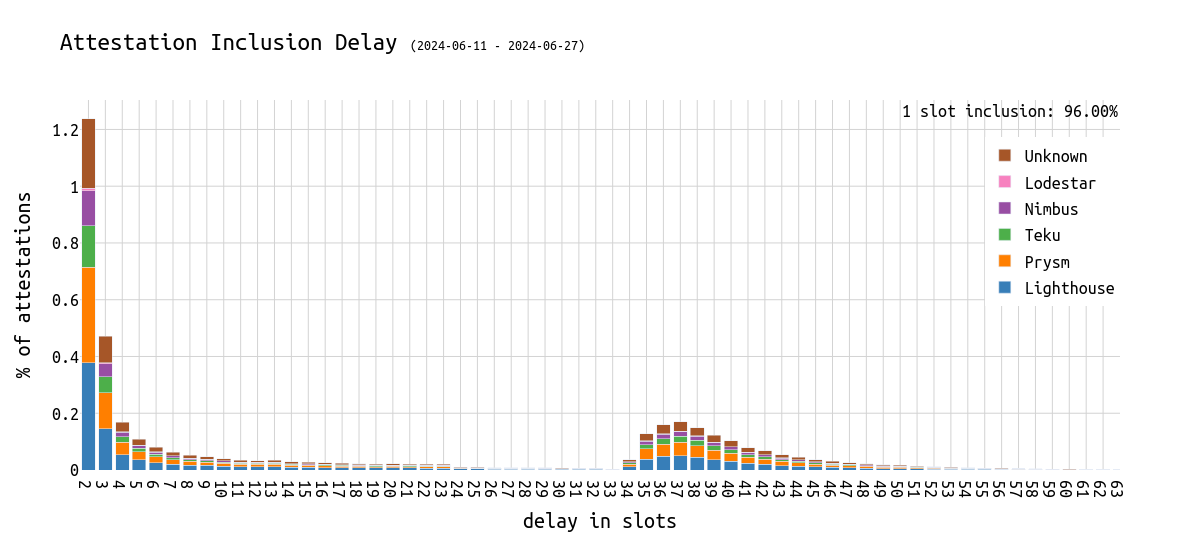
下图显示了在 1-63 秒内的包含延迟的分布,以及 attester 正在使用的客户端。
 \
correct_head_delay_clients1200×550 33.2 KB
\
correct_head_delay_clients1200×550 33.2 KB
- 95.85% 的 attestation 包含在下一个 slot 中。
- 约 1.2% 的 attestation 包含在下一个 slot 之后。
- 当一个新的 epoch 开始时,旧的 attestation 再次被拾取并最终包含。
- 这很奇怪(但在下面会有一个解释)。
- 所有客户端的验证器的 attestation 都受到影响。
这引出了一个问题,“客户端在做什么?”
例如,slot 9267438 的延迟为 35(5250 个验证器),slot 9267425 的延迟为 52(1813 个验证器),slot 9267427 的延迟为 36 个 slot(1305 个验证器)。
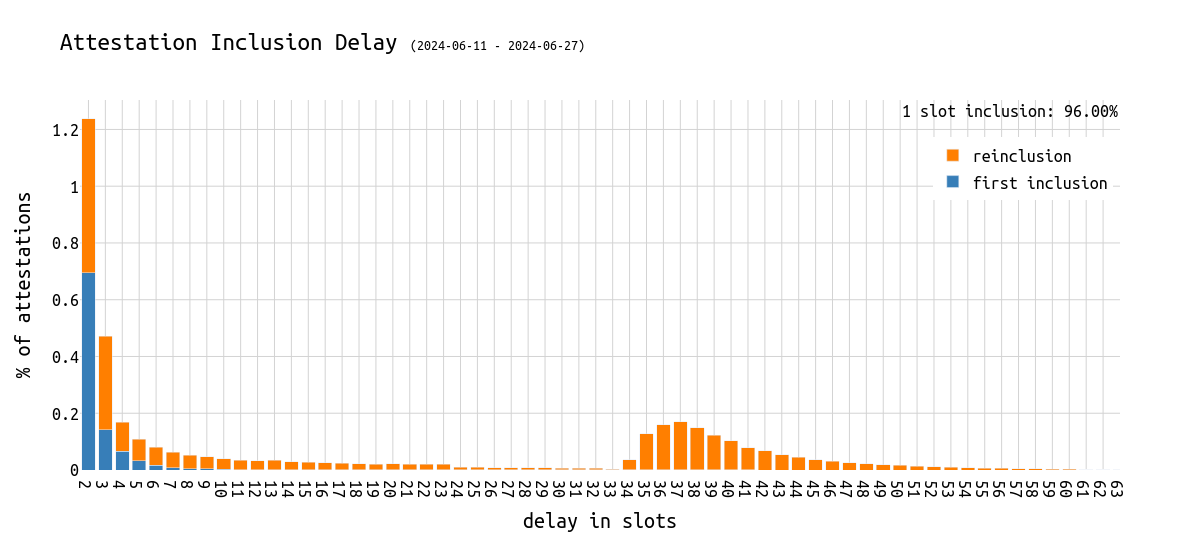
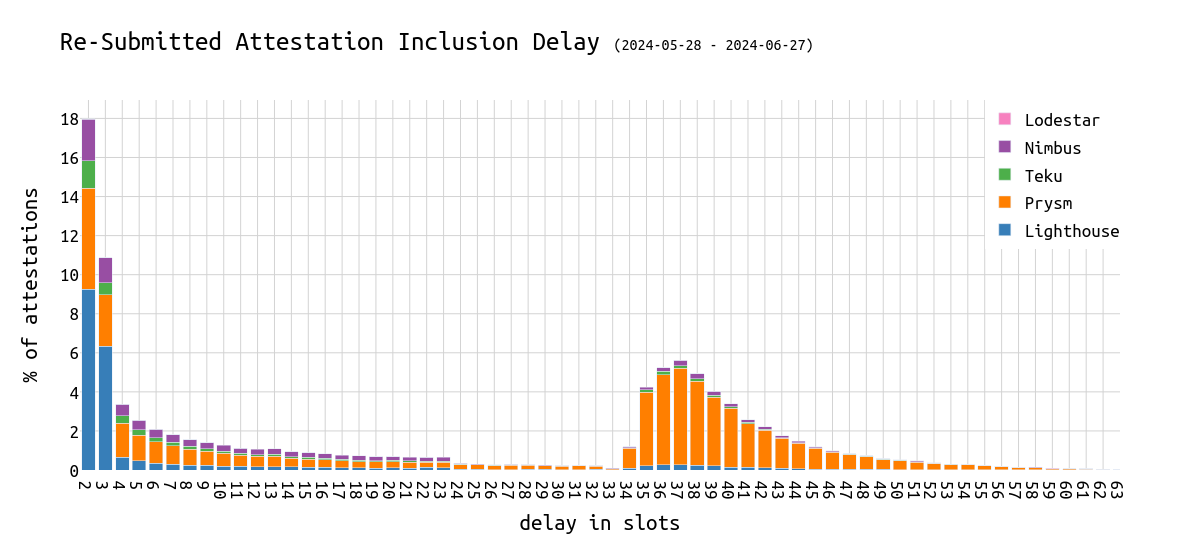
如果那些延迟的 attestation 已经提前包含,并在后来只是再次包含(h/t dapplion)呢?为了分析这一点,我们重现上面的图表,但按 第一次包含 和 每次后续包含 分开:
 \
correct_head_delay_reinclusion1200×550 28.9 KB
\
correct_head_delay_reinclusion1200×550 28.9 KB
首先,有趣的是,几乎一半以延迟 2 个 slot 包含的 attestation(注意:最好是 1)已经包含在更早的 slot 中。这是可能的,因为提议者可以自由地选择已经包含在过去 63 个 slot 中的 attestation,并再次包含它们。此外,一个区块可以包含相同的 attestation 多次,以不同的方式聚合。
我们可以看到,在延迟大约 35 个 slot 的第二个驼峰中包含的大多数 attestation 是 重新包含 的 attestation。
这引出了一个问题,“为什么会发生这种延迟超过 32 个 slot 的情况?”
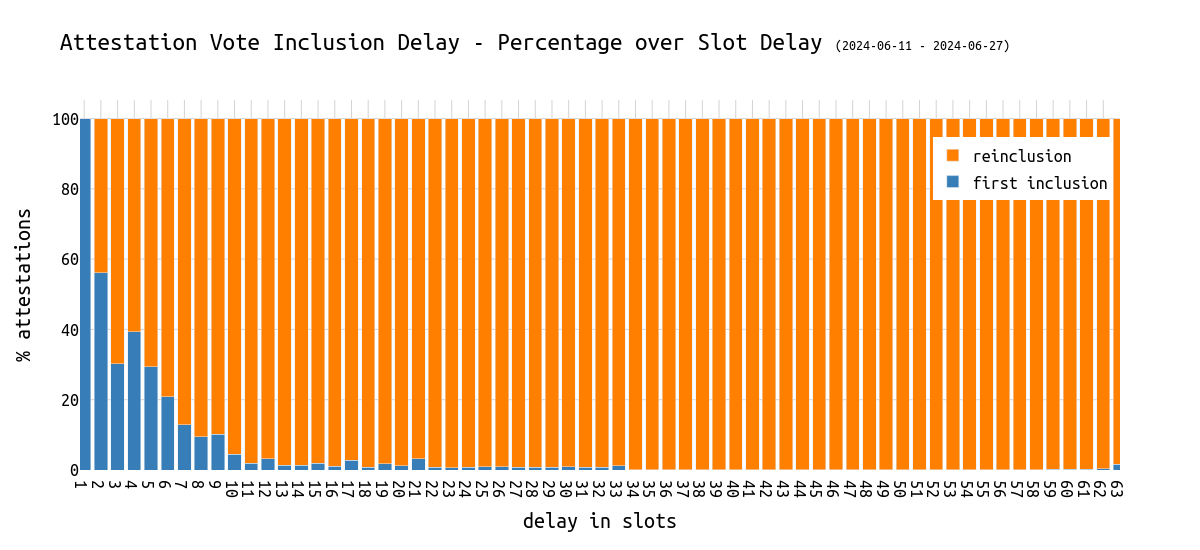
以百分比而言,我们可以看到第一次包含份额随着延迟的增加而减少:
 \
correct_head_delay_reinclusion_per1200×550 24.4 KB
\
correct_head_delay_reinclusion_per1200×550 24.4 KB
为了更深入地研究这种重新包含的发现,让我们检查一下构建包含 >32 个 slot 延迟的 attestation 的区块的 CL 客户端:
 \
correct_head_delay_clients_proposers1200×550 34.3 KB
\
correct_head_delay_clients_proposers1200×550 34.3 KB
我们可以很清楚地看到,主要是 Prysm 提议者包含已经提前包含的 attestation,这很可能是一个 bug。
该图还显示了其他受影响的客户端,这可能源于客户端概率分类的不准确。
Prysm 团队已收到通知。
编辑:Prysm 团队修复 bug 的速度比我完成这篇文章的速度还要快。
错过/失败的 Attestation
错过/失败的 Head 投票
Head 投票是 attestation 中最困难的部分。它们需要被正确和及时地投出。根据 诚实验证器规范,验证器有 4 秒 的时间来接收和验证当前 slot 的区块。如果在第 4 秒之前没有收到区块,验证器将证明前一个 slot 中的区块。在 head 投票的上下文中,及时性意味着 1 个 slot。 尽管可以包含较旧的 head 投票,但相应的验证器没有奖励。
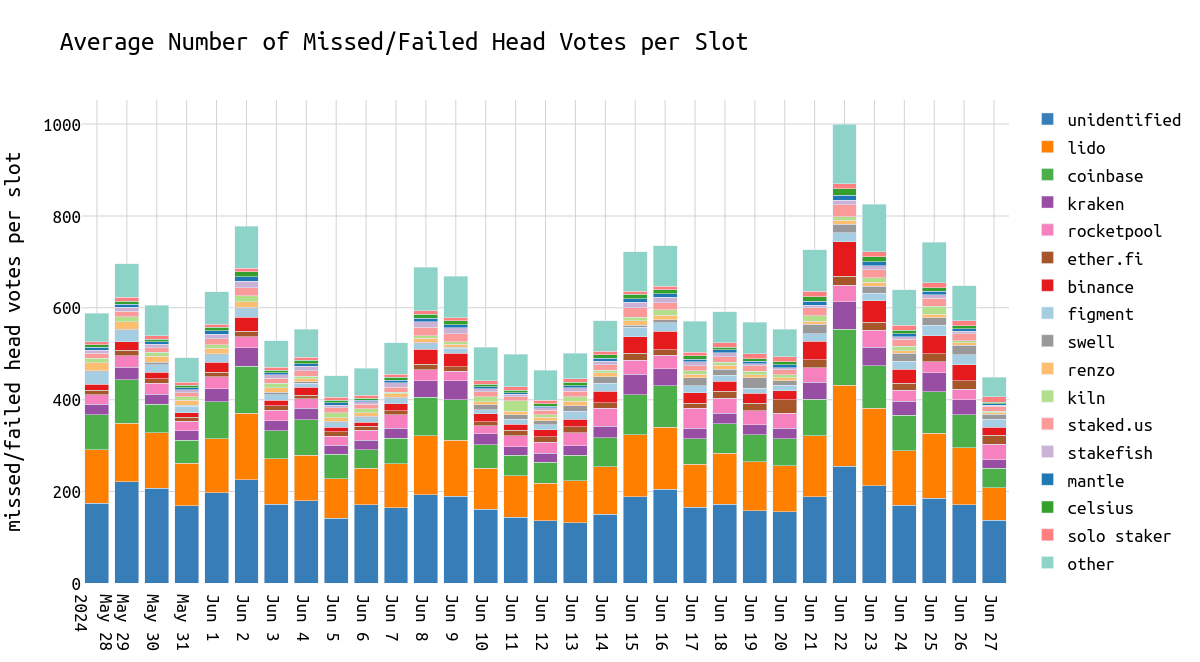
图例按错过投票的总和降序排列。
 \
missed_head_votes_over_date1200×662 53.3 KB
\
missed_head_votes_over_date1200×662 53.3 KB平均而言,我们观察到每个 slot 约有 ~500 个错过或错误的 head 投票(在 ~32k 个验证器中),以及每个 epoch 约有 ~16k 个(在 ~1m 个验证器中)。这约占 1.56%。
被标记为未识别的实体可能由多个独立的当事方组成,包括 solo staker 和尚未识别的实体,它在所有验证器中总共有 20% 的市场份额。
假设每个节点运营商的表现都一样,那么每个实体的市场份额应该反映其错过的 head 投票的份额。但是,情况并非如此,我们看到某些节点运营商比其他节点运营商更优秀。
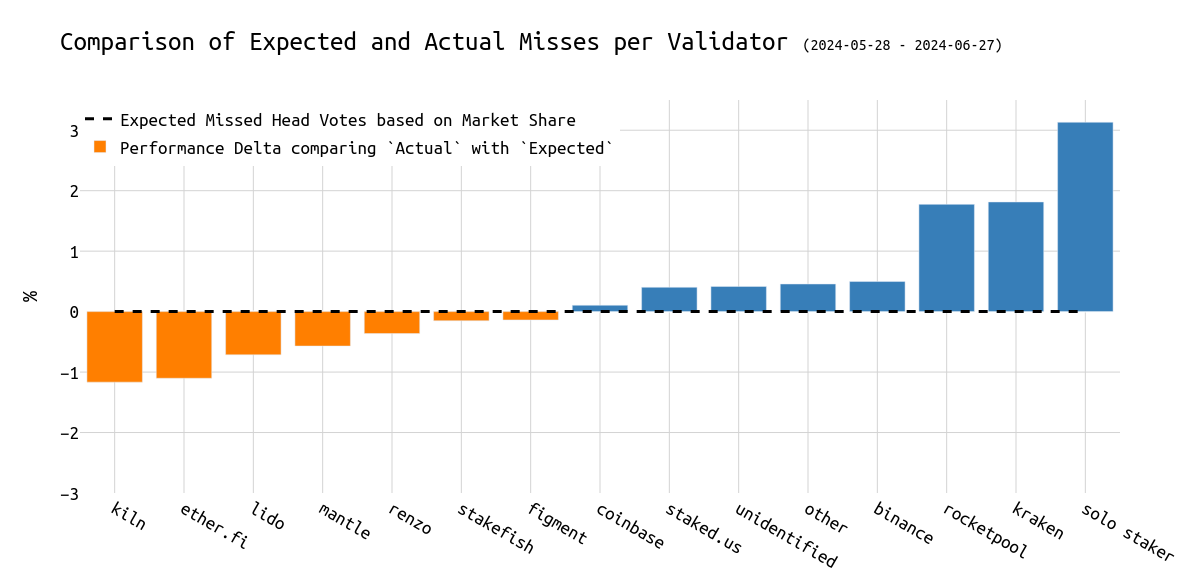
下图可视化了基于市场份额的预期错过 head 投票的数量与实际错过的 attestation 数量之间的差异。
 \
delta_missed_head_votes1200×583 34.9 KB
\
delta_missed_head_votes1200×583 34.9 KB
虽然 Kiln、Ether_fi、Lido、Renzo、Figment 和 Stakefish 等实体的表现优于平均水平,但我们观察到 Rocketpool 验证器、Kraken 验证器和 solo staker 错过的 head 投票比其市场份额多达 3%。
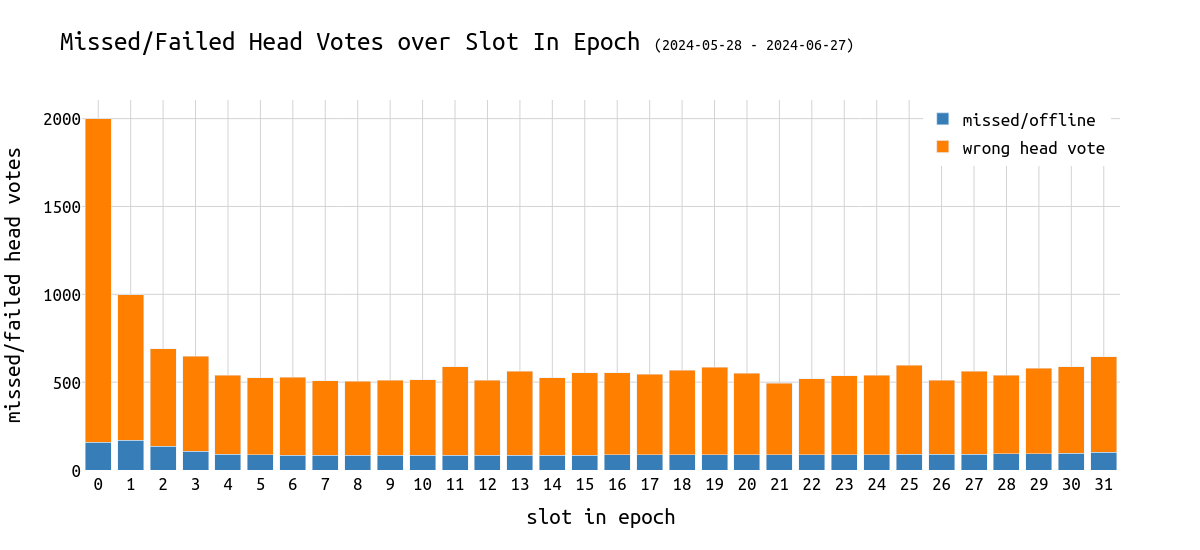
专注于 epoch 中的 slot 索引,我们区分由于离线而错过 head 投票和投票给错误的 head。
下图显示了在一个 epoch 的 slot 中错过/错误的 head 投票的平均数量:
 \
failed_missed_head_votes1200×550 29.3 KB
\
failed_missed_head_votes1200×550 29.3 KB
从上图中,我们可以推断:
-
missed head 投票 的数量相当恒定。
- 这是预期的,因为lost-key 验证器为该类别贡献了固定的部分。
- 一个 epoch 的开始,特别是第一个 slot,具有比其余 slot 更多的错误 head 投票。
- 这是预期的,因为第一个 slot 中的提议者必须执行 epoch 转换。然后,它必须广播该区块以到达所有 attester。
- 在 epoch 的第一个 slot 中错过/错误的 head 投票的平均数量是 epochs 2-32 的 3 倍。
专注于错过 head 投票和 CL 客户端,我们在下面的图表中看不到任何可疑之处:
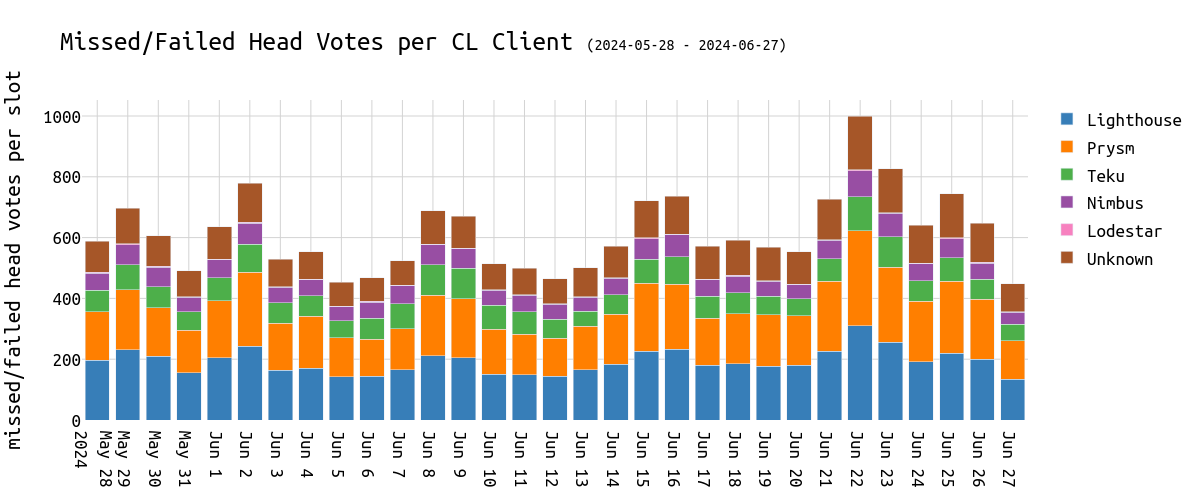 \
failed_missed_head_votes_over_clclient1200×500 34.8 KB
\
failed_missed_head_votes_over_clclient1200×500 34.8 KB
一般来说,看起来所有 CL 客户端都受到 epoch 早期错过的影响:
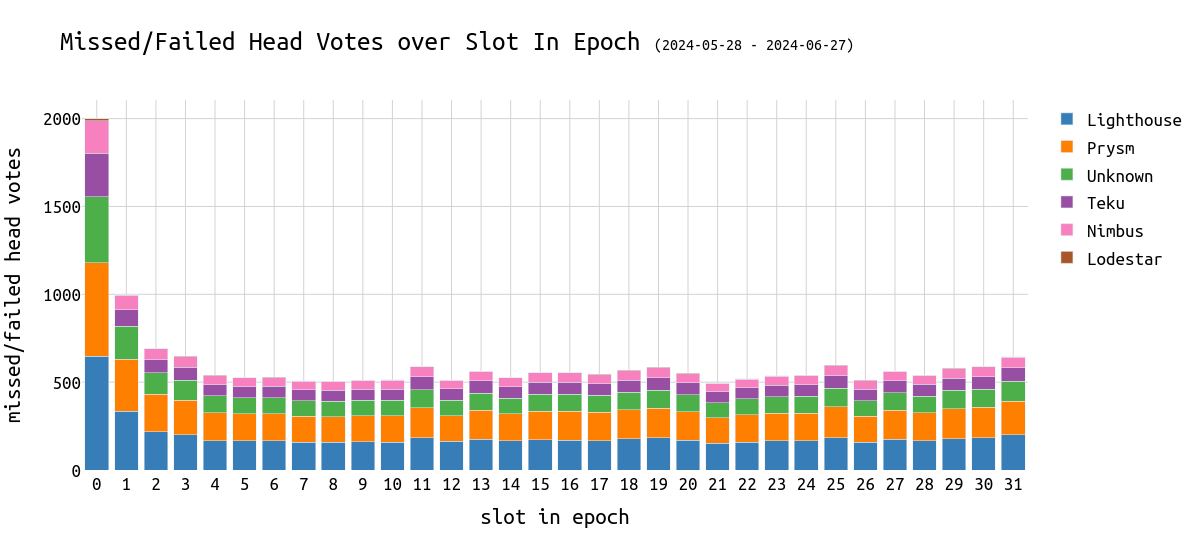 \
failed_missed_head_votes_over_clclient_over_slot1200×550 33.1 KB
\
failed_missed_head_votes_over_clclient_over_slot1200×550 33.1 KB
错过/失败的 Target 投票
Target 投票更容易做对了。唯一的例外是epoch 边界之后的 epoch 的第一个 slot:在这种情况下,head 投票等于 target 投票,并且 target 投票错误的验证器倾向于投票给父区块(=上一个 epoch 的最后一个 slot 中的区块)。
平均而言,我们观察到每个 slot 约有 150 个错过 target 投票,每个 epoch 约有 4800 个。这约占所有验证器的 0.48%。
 \
missed_target_votes_over_date1200×662 52 KB
\
missed_target_votes_over_date1200×662 52 KB
在不同的 CL 客户端上可视化相同的内容,我们看到所有客户端受到的影响都接近其市场份额。
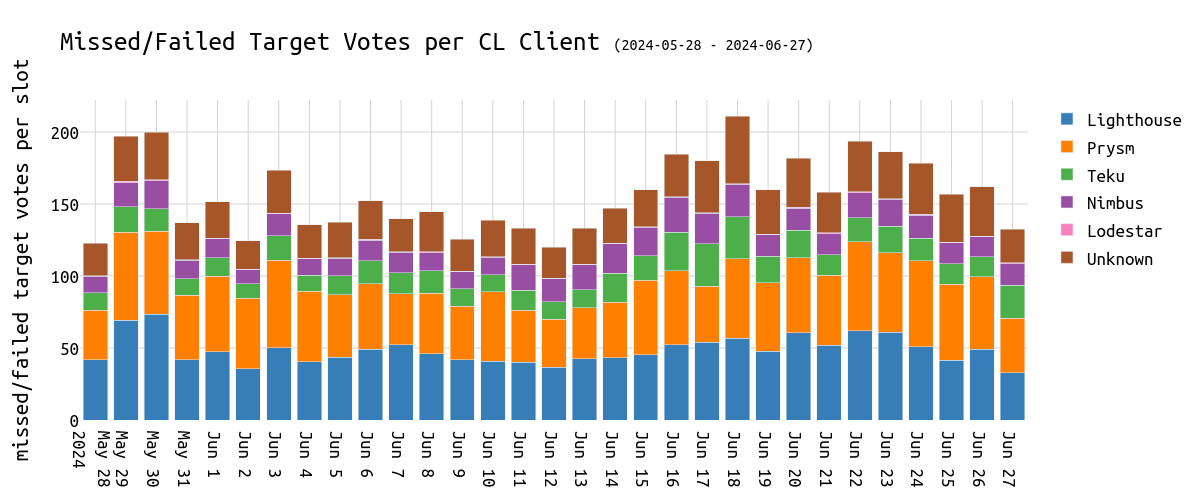 \
failed_missed_target_votes_over_clclient1200×500 34 KB
\
failed_missed_target_votes_over_clclient1200×500 34 KB
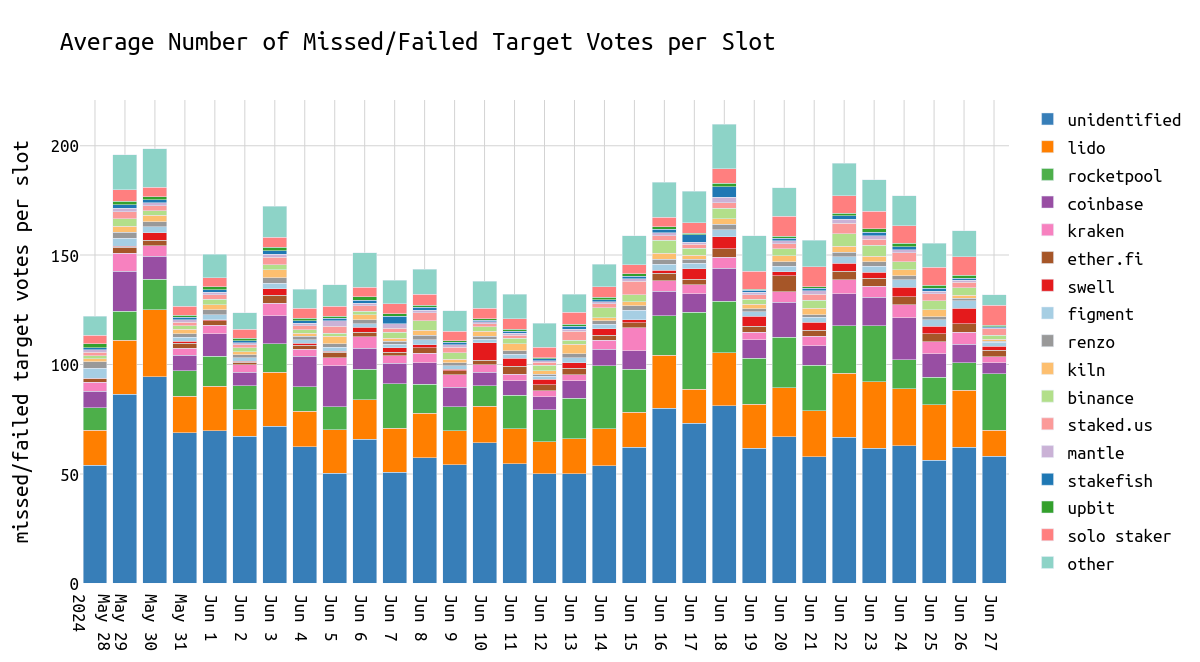
着眼于表现优于其他实体的实体,我们再次看到 Lido、Renzo、Mantle、Coinbase 等运营商的表现优于平均水平。
值得注意的是,Lido 不是一个单独的 NO,而是由多个运营商组成,为了简单起见,我将它们组合在一起。
另一方面,Rocketpool 验证器和 solo staker 的表现更差,并且错过的 target 投票比预期多达 3%。
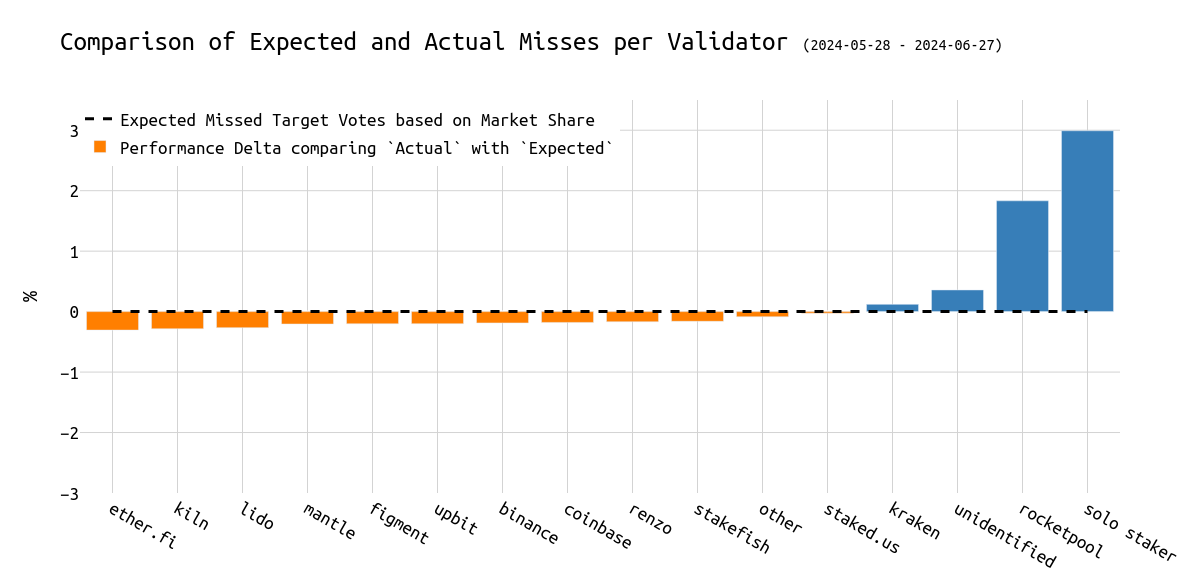 \
delta_missed_target_votes1200×583 33.1 KB
\
delta_missed_target_votes1200×583 33.1 KB
如 先前关于 reorg 的分析 中所见,当涉及提议区块时,epoch 边界可能会给某些验证器带来麻烦。
如果区块在一个 epoch 的第一个或第二个 slot 中被提议,则更容易被 reorg。 因此,我们预计这些区块会导致验证器之间最大的分歧,导致一些人证明当前区块,而另一些人则证明父区块。
即使是预期的,我们也可以看到 epoch 中的 slot 索引对失败的 target 投票有重大影响:
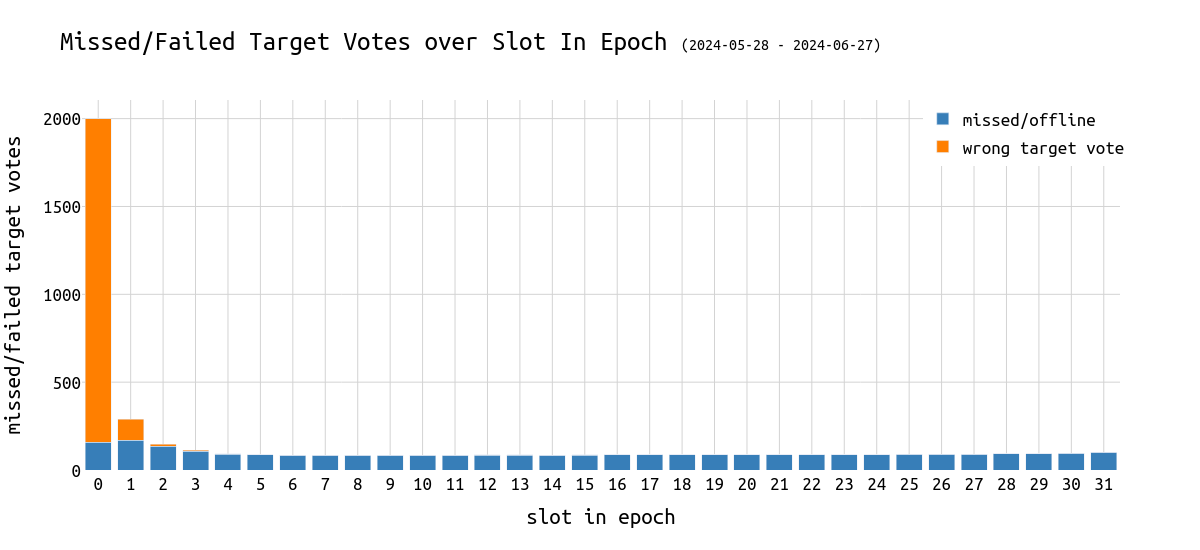 \
failed_missed_target_votes1200×550 30 KB
\
failed_missed_target_votes1200×550 30 KB
Target 投票在一个 epoch 的开始时最难做对。 这在上图中可见,其中一个 epoch 的第一个 slot 的错误 target 投票比其他 slot 多 18 倍。问题是,及时和正确的 target 投票带来的奖励是 head 或 source 投票的两倍。
尽管看起来有问题,但我认为这不是一个大问题。一个 epoch 开始时的 target 投票本质上只是一个 head 投票,并且第一个 slot 中失败的相对份额在 6.4% 仍然相对较低。此外,众所周知,epoch 边界会带来许多不同的级联效应,包括错过的 slot,这也导致了上述发现。
\ failed_missed_target_votes_over_clclient_over_slot1200×550 33 KB
这种现象似乎与 CL 客户端无关。
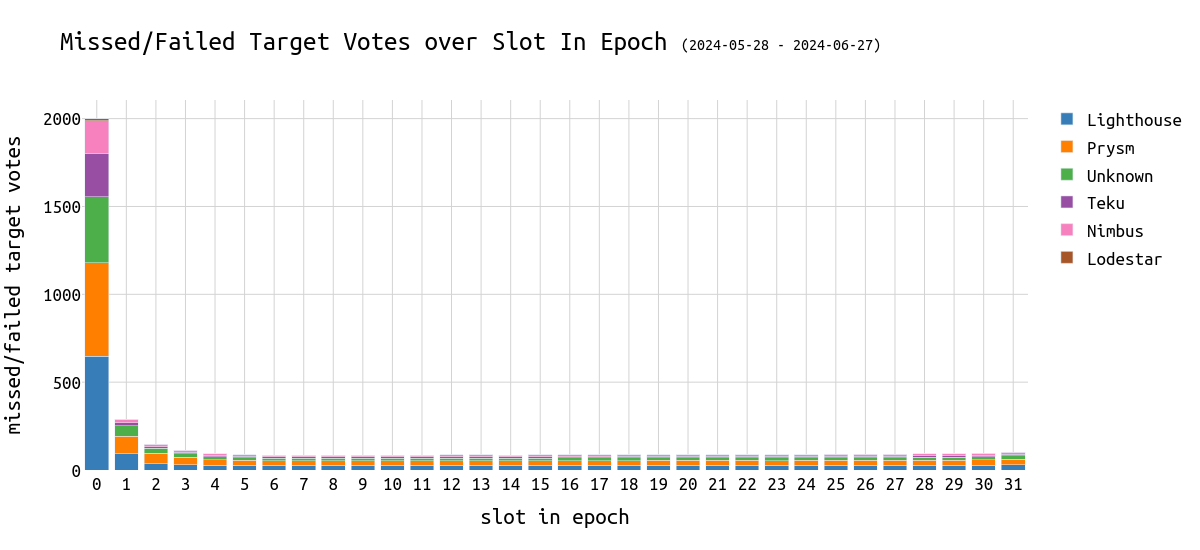 \
failed_missed_target_votes_over_clclient_over_slot1200×550 33 KB
\
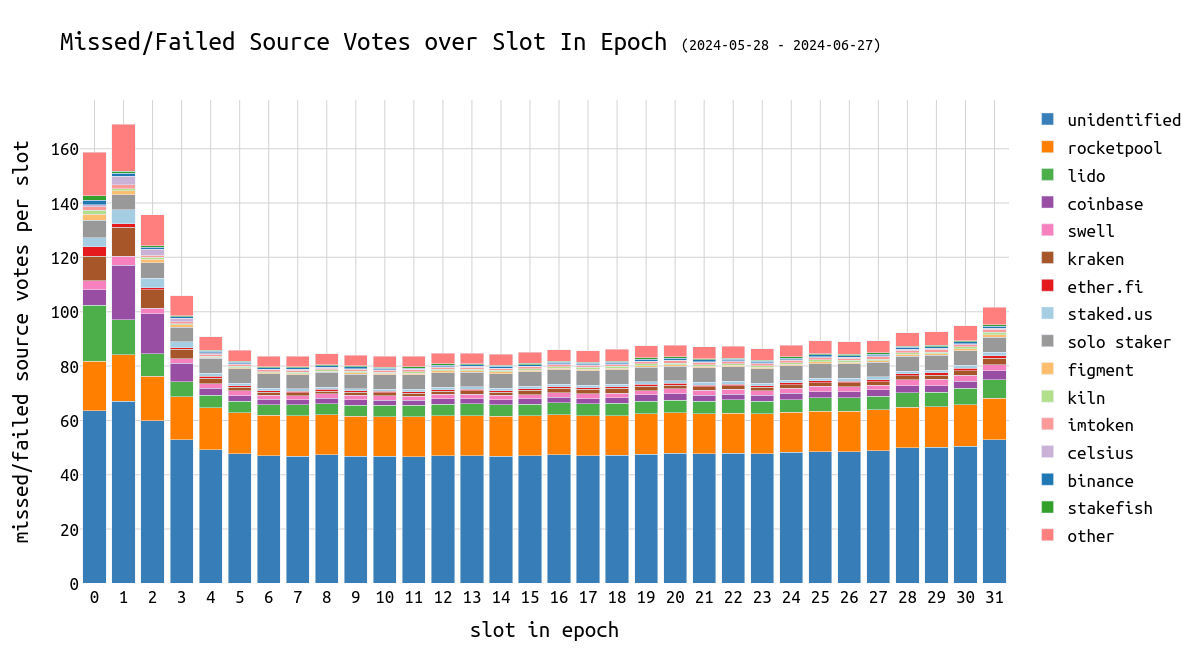
failed_missed_target_votes_over_clclient_over_slot1200×550 33 KB错过/失败的 Source 投票
Source 投票很容易做对,即使稍微失去同步的验证器也有很好的机会投票给正确的 source 检查点。这是因为要投票的检查点至少在 6.4 分钟(=1 个 epoch)之前。错误的 source 投票表明验证器要么失去同步,要么在完全不同的链上。因此,如果 source 投票错误,则 target 和 head 投票必须不正确。
对于 source 投票,无法区分错过和失败,因为错误的 source 投票永远不会上线,并且会被提议者/验证器忽略。
平均而言,我们观察到每个 slot 约有 100 个错过 source 投票,每个 epoch 约有 3200 个。
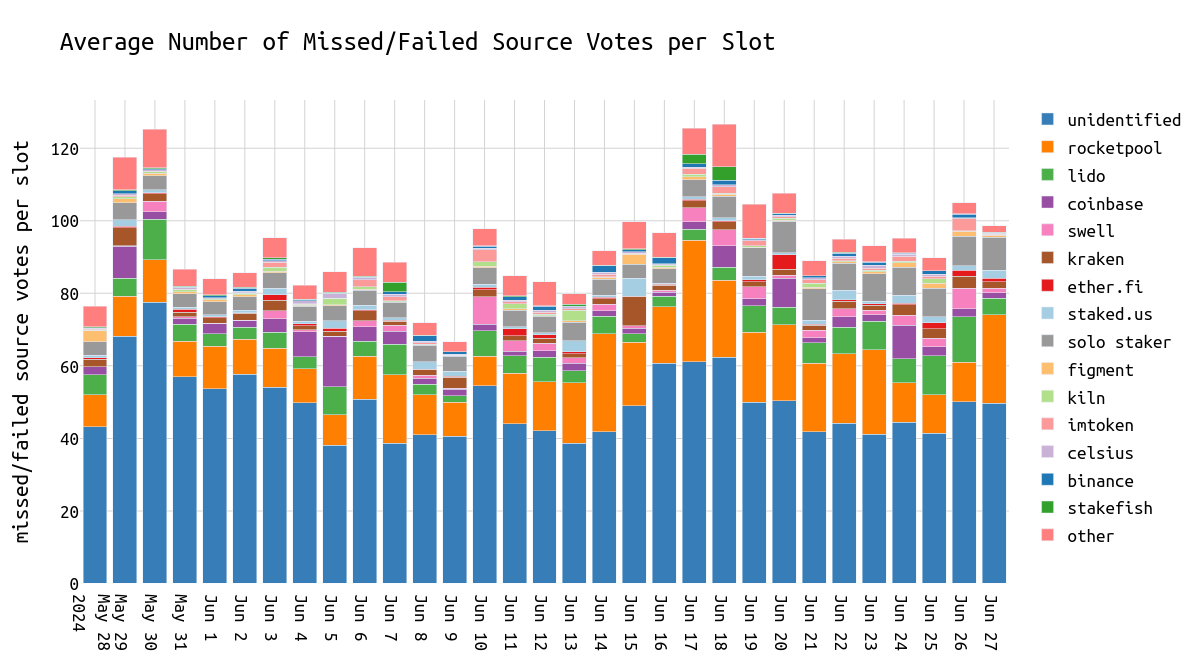 \
missed_source_votes_over_date1200×662 51.7 KB
\
missed_source_votes_over_date1200×662 51.7 KB
与 head 投票和 target 投票类似,我们观察到 epoch 开始时错过 source 投票的数量增加。这可能与 epoch 开始时重新组织的可能性增加有关,但需要进行更多分析才能确认这一点。
一般来说,验证器通常有充足的时间(至少 32 个 slot)来投出其 source 投票。但是,如果其 head 投票不正确,则可能导致聚合器忽略整个 attestation,并且因此不会在链上记录。
 \
missed_source_votes_over_slot1200×662 52.2 KB
\
missed_source_votes_over_slot1200×662 52.2 KB
最佳和最差验证器
验证器在每个 epoch 中进行投票,并且快速检查 beaconcha.in,超过 99.9% 的验证器在每个 epoch 中都处于活动状态。
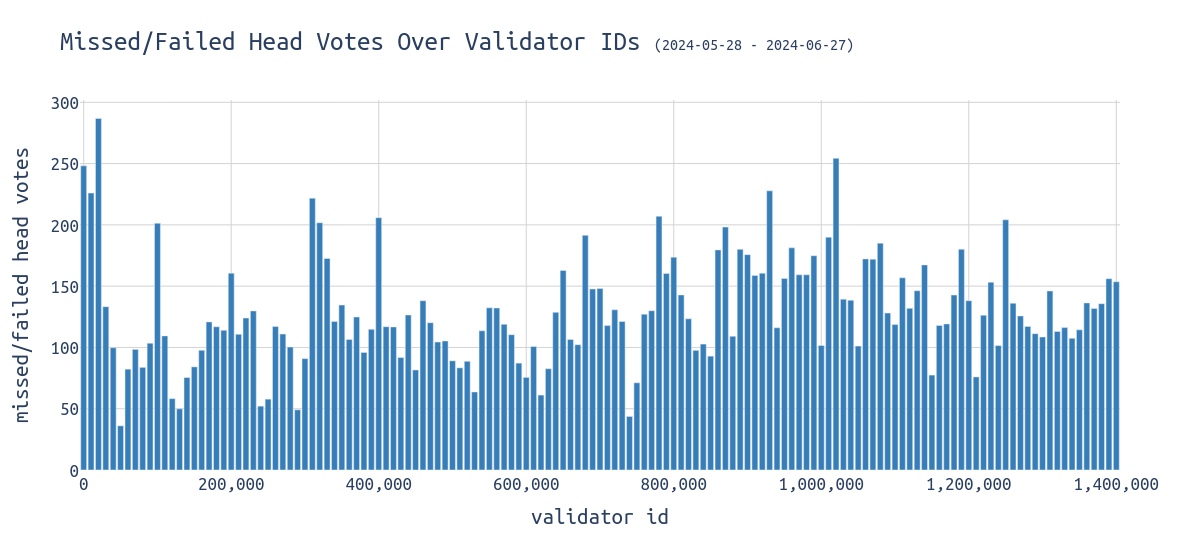
通过总结正确的 head 投票,我们可以确定性能最佳和最差的验证器。
下图可视化了每个 slot 的平均错过/失败的 head 投票,按验证器 ID:
排除撤回的验证器。
 \
head_votes_over_validator_ids1200×550 35 KB
\
head_votes_over_validator_ids1200×550 35 KB我们可以看到,随着验证器 ID 的增加,错过的 slot 率略有增加,,ID 为 0-30k、300k-330k 和 780k-790k 的验证器是异常值。
最好的验证器是 ID 从 50k-60k 的组。
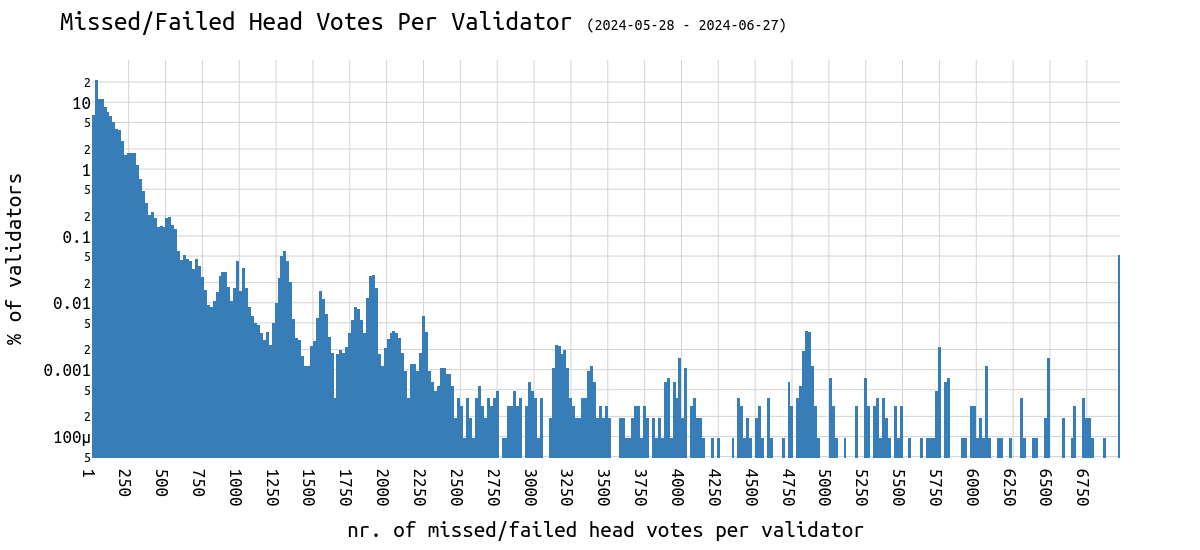
在四个星期内,大多数验证器错过约 20-30 个 head 投票:
下图具有对数 Y 轴,以确保我们还可以看到最右边的一个,该轴由在分析的 4 周内从未证明过的验证器组成。
 \
failed_missed_head_per_validator_dist_per1200×550 32.3 KB
\
failed_missed_head_per_validator_dist_per1200×550 32.3 KB
性能峰值(最佳验证器)
对于以下内容,我使用的数据范围从 epoch 292,655 到 epoch 293,105,而不是分析的整个时间范围,因为涉及的数据量很大。
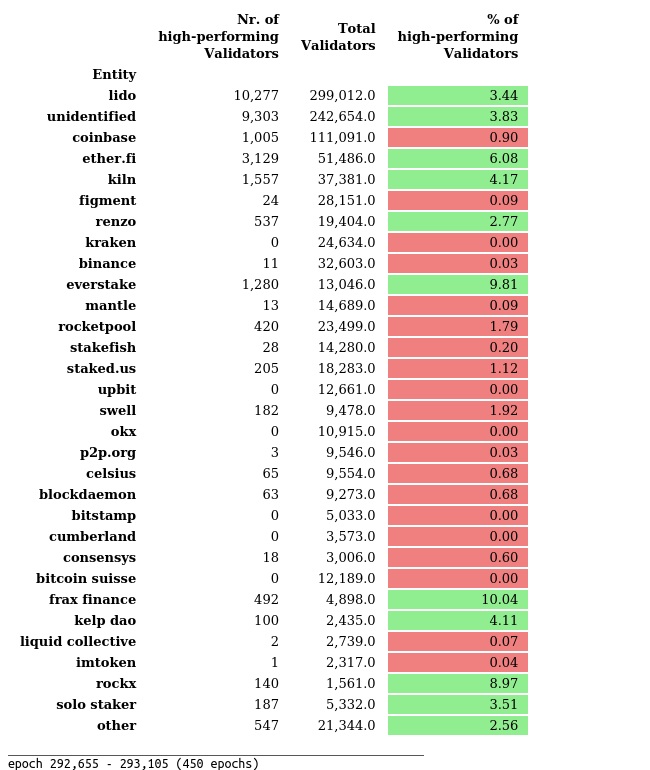
高性能者被定义为在过去 3 天内(从分析的最后一个 slot 开始向后)没有错过投票给正确 head 的验证器。
下表显示了最大的节点运营商(按市场份额降序排列)以及在 3 天内的高性能验证器的百分比,与每个实体的验证器总数相比:
 \
performer_table650×770 103 KB
\
performer_table650×770 103 KB
^ 绿色 中的实体具有比平均水平更高的高性能验证器。
使用条形图可视化的份额如下所示:
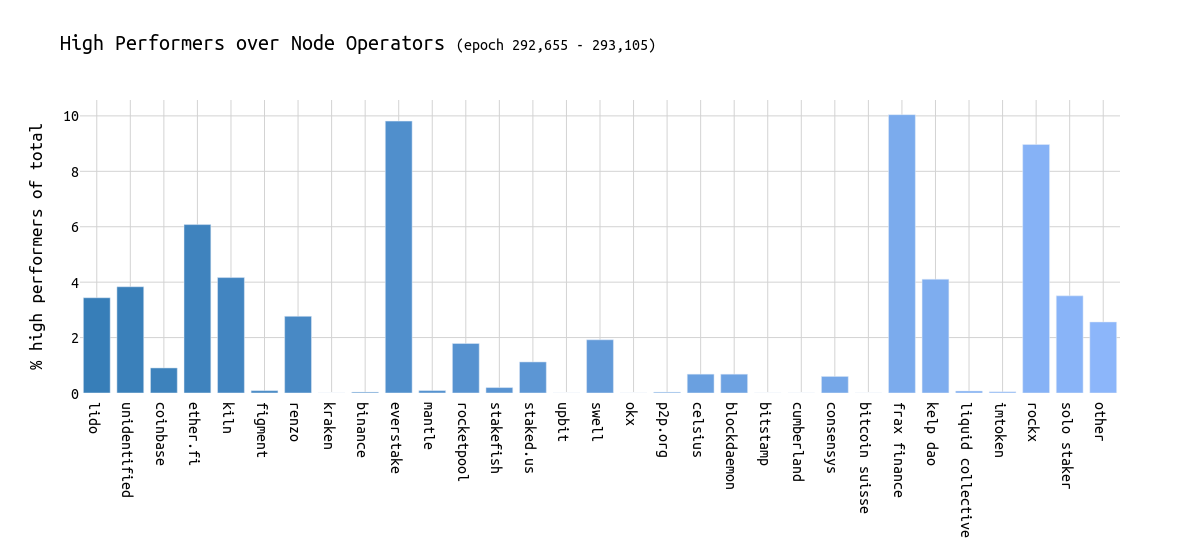 \
topperformer_percentage1200×550 28.2 KB
\
topperformer_percentage1200×550 28.2 KB
我们可以看到,所示实体的高性能者平均比率约为 0-5%。
异常值是Everstake、Frax Finance 和Rockx**。
那么,这 3 方与其他方有什么不同?
一个实体可能应用两种策略:
- 尽早证明,以确保其投票有足够的时间通过网络传播,并到达下一个提议者以进行包含。
- 稍后证明,以确保他们投票给链的正确 head。验证器等待的时间越长,就越容易确定链的 head,因为其他验证器已投票 -> 风险在于投票可能无法及时到达下一个提议者。
后一种策略可能被称为attester timing games。
但是什么更好?
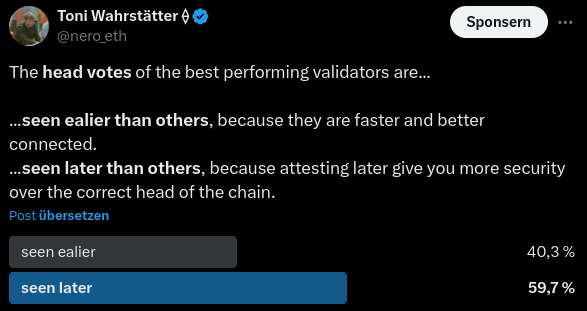
我问了我的 Twitter 朋友,大多数人投票赞成“seen later”,表明验证器正在玩时序游戏以提高 attestation 准确性。
事实上,两者都是正确的。
下图显示了高性能验证器与其余验证器(非高性能验证器)的 attestation-seen 时间戳的分布:
[ \
image1200×2000 285 KB
\
image1200×2000 285 KB为了更深入地研究这个主题,请查看 Barnabé 的这个模拟,它深入探讨了战略证明行为。
最后,我们得到了不同 CL 客户端的证明时间如下:
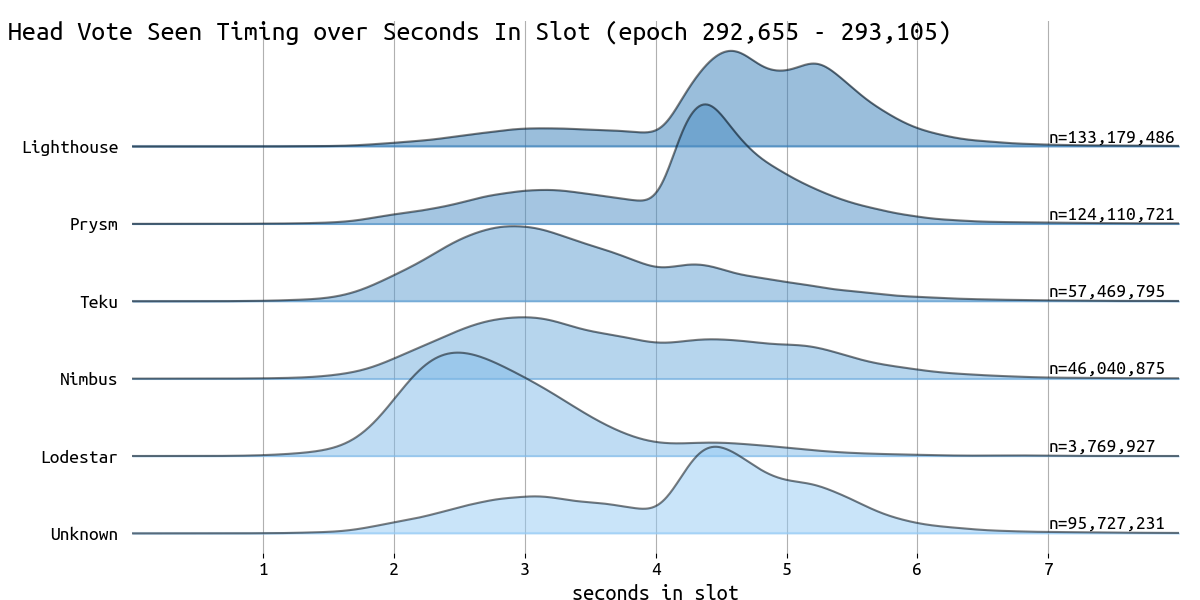 \
head_timing_cl_clients1200×600 87.2 KB
\
head_timing_cl_clients1200×600 87.2 KB
我们喜欢他们的本来面目……(最差的验证者)
其他验证者的性能比其他的更差。通过查看一段时间内错过的证明数量,这一点变得显而易见。
首先,让我们考虑一下离线的验证者。验证者离线的原因有很多,有时,随机的验证者可能会遇到短暂的中断。但是,有一小部分验证者很可能永久离线。

我们观察到 139 个验证者,占所有验证者的 0.014%,在分析的 4 周内永久离线。
现在,有人可能会说,离线超过 4 周并不意味着验证者永久离线。虽然这是合理的,但从未投过任何票的验证者为可能丢失密钥的永久离线验证者的数量提供了一个很好的上限估计。
在这些离线验证者中,我们确定了 12 个 solo staker,37 个 rocketpool 验证者,以及 90 个属于未识别类别的验证者(= 20% 的市场份额,包括许多实际的 solo staker)。
大多数离线验证者都具有较低的验证者 ID:
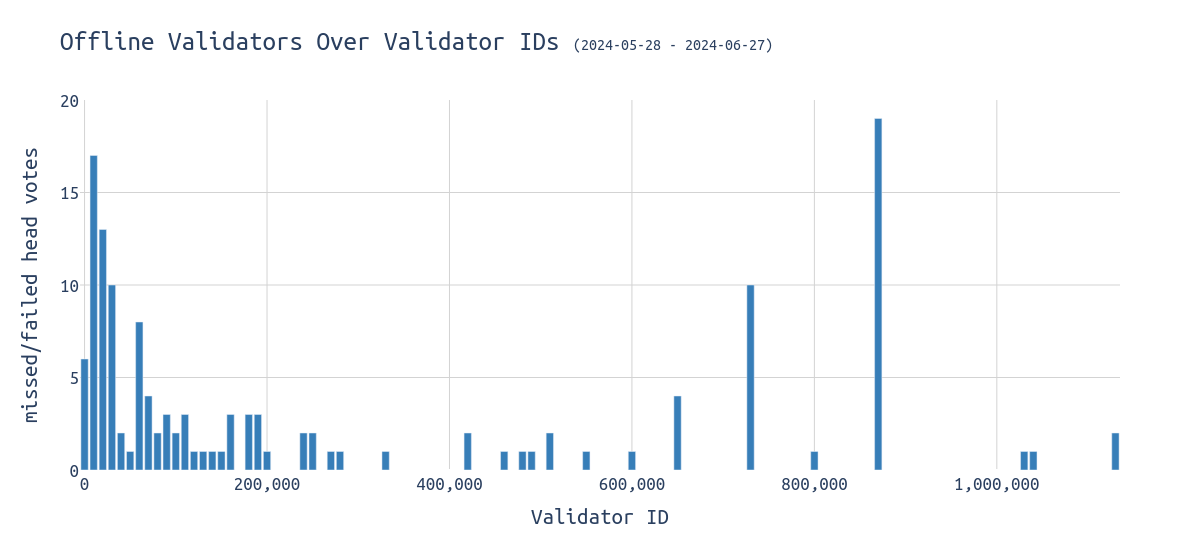 \
head_votes_over_offline_validator_ids1200×550 22.9 KB
\
head_votes_over_offline_validator_ids1200×550 22.9 KB
我们可以看到 73 万和 87 万左右的峰值,但最大部分来自具有较低 ID 的 OG 验证者,这些验证者在合并之前就已激活。这既在意料之中,又出乎意料:
- OG staker 通常是加密货币原生人士,他们可以安全地管理私钥。
- OG staker 通常是技术不够成熟的 solo staker。
根据以上内容,后者似乎更有可能成立。

将焦点转移到在分析的时间范围内错过超过平均值但并非所有 slot 的不良验证者,条形图如下所示:
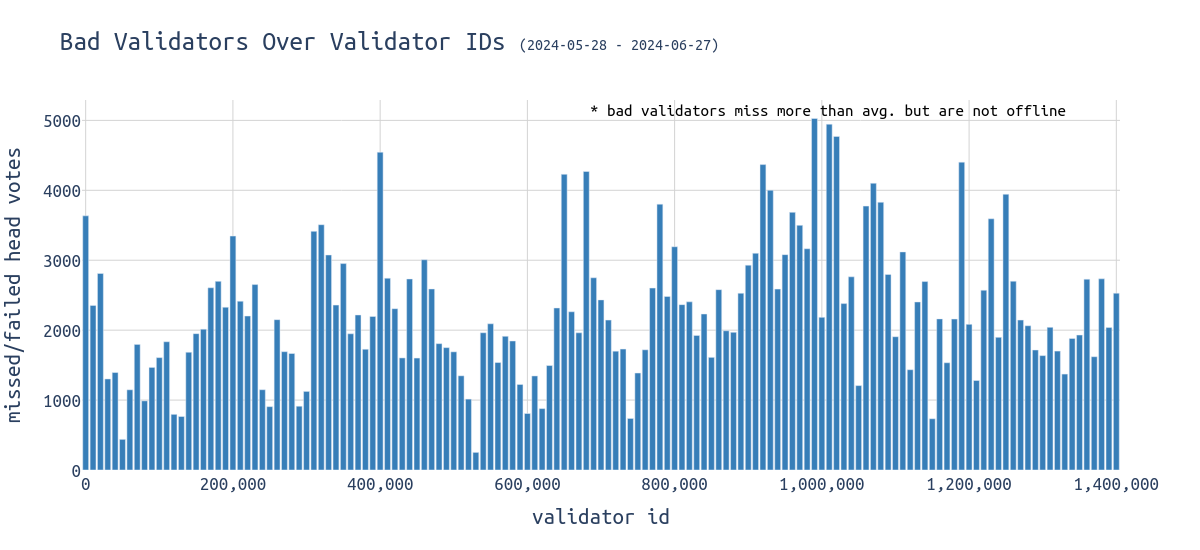 \
head_votes_over_bad_validator_ids1200×550 36.6 KB
\
head_votes_over_bad_validator_ids1200×550 36.6 KB
如果低 id 验证者没有离线,他们的表现相当好。 观察上面的图表,可以在 90 万到 100 万的 ID 范围内找到最大份额的“不良”验证者。
证明、大型区块和 Blob
预计大型区块和包含许多区块的区块收到的证明会更少。 这是因为某些验证者可能难以足够快地下载和验证区块,因此会投票给另一个区块。
- EL Payload(约 85 KB)
- 信标区块(不包括 EL payload)/ CL 部分(约 5 KB)
- Blob(约 384 KB)
之前的分析表明,不包括 blob 的平均信标区块大小约为 90 KiB。一个 blob 的大小为 128 KiB。因此,平均而言,我们得到的区块(包括 blob)的大小为 nr_blobs * 128 + 90,其中 blob 是区块大小的主要贡献者。
更多的 blob 意味着更多的数据需要传输到全球。因此,我们可以预期具有 6 个 blob 的区块的 head vote 失败次数多于具有 1 个 blob 的区块。
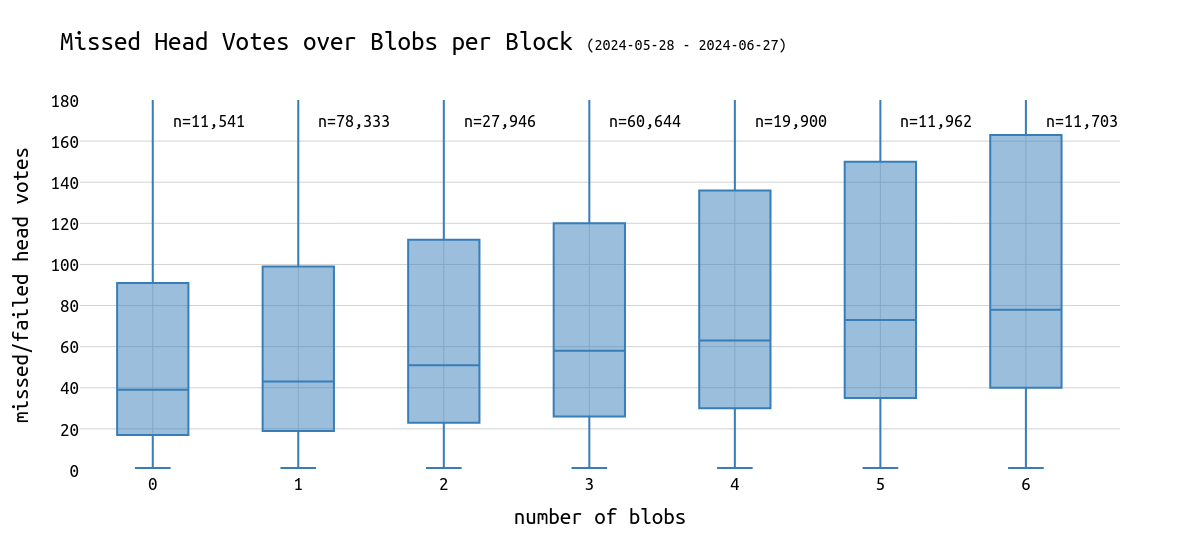 \
failed_missed_head_size_boxplot1200×550 30.3 KB
\
failed_missed_head_size_boxplot1200×550 30.3 KB
当查看上面的箱线图时,这种预期成立:
→ 从中等到 6 个 blob,错过的 head vote 的中位数翻了一番。
让我们更精细一些……
以下可视化了每个 slot 中包含 blob 的区块大小(以 MiB 为单位)与失败的 head vote。
此图表仅显示错误/失败的 head vote,不包括离线验证者。
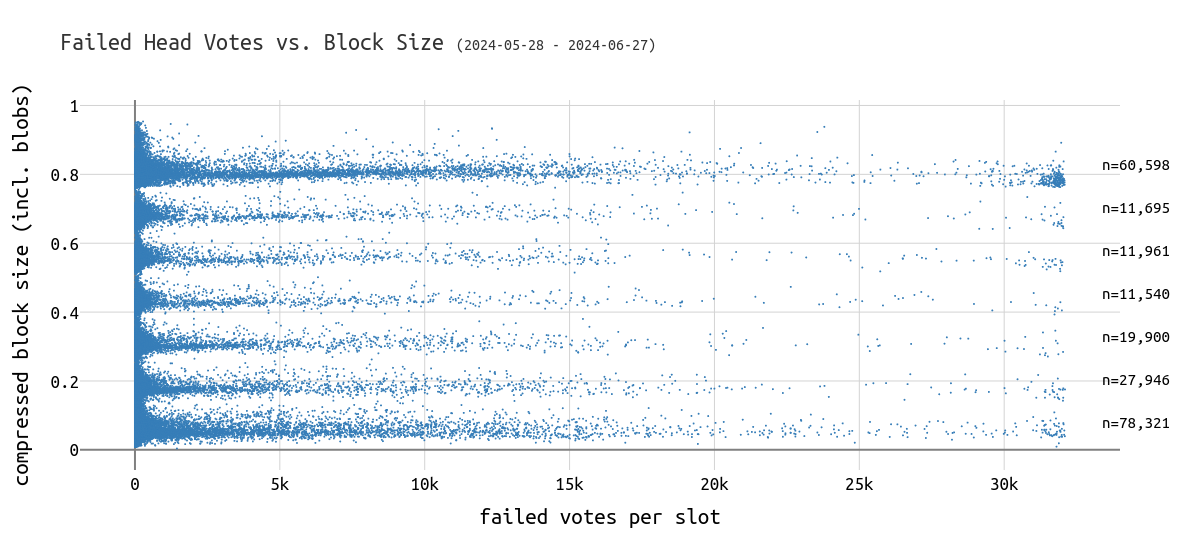 \
failed_missed_head_size_scatter1200×550 110 KB
\
failed_missed_head_size_scatter1200×550 110 KB对于大于 0.8 MiB 的大小,这很可能是具有 6 个 blob 的区块,我们可以看到比 0 个 blob 的区块更多的弱区块。“弱”是因为该 slot 中最多 32k 个证明者中,最多 99% 的人投票给了不同的区块。
该区块仍然进入规范链的唯一方法是下一个验证者在它之上构建,而不是重新组织该区块。
在分析的月份中,我们观察到 401 个区块,其中超过 31k 个证明者投票给了不同的区块,但这些区块仍然进入了规范链。其中 233 个携带了 6 个 blob。假设大多数验证者最迟在 slot 的第 4 秒进行证明,那么这些区块的传播一定非常晚,以至于验证者在看到它之前已经证明了另一个区块。
可以通过绘制这些弱区块的“首次看到”时间与 slot 中的秒数的关系,并将其与所有其他区块进行比较来确认这一点:
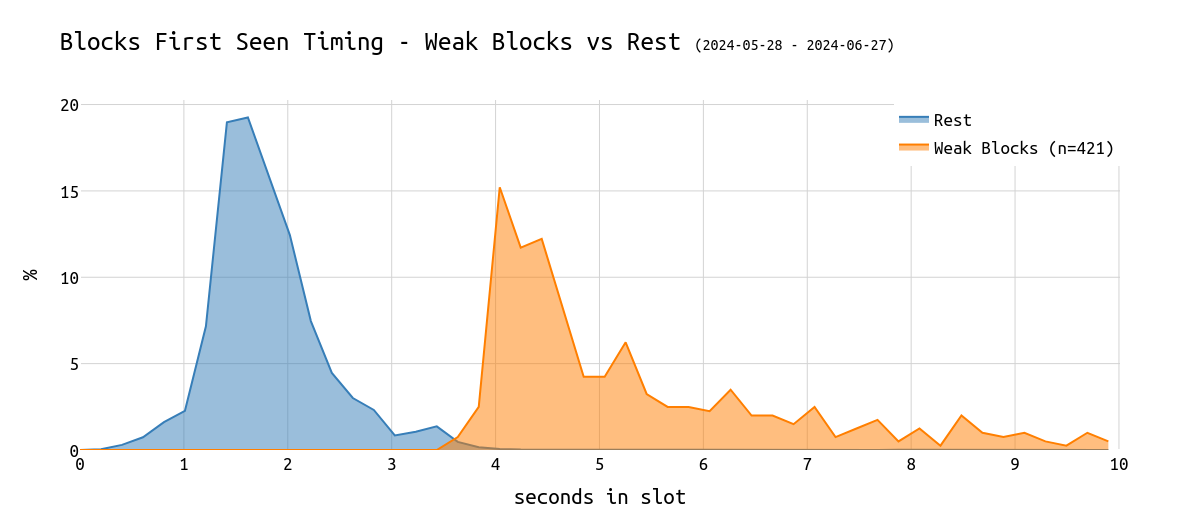 \
hist_late_performer1200×530 37.6 KB
\
hist_late_performer1200×530 37.6 KB
该图表显示,大多数区块在 slot 的第 1 秒和第 2 秒之间被看到。对于这些弱区块,它位于第 4 秒和第 5 秒之间,恰好在证明截止日期之后。
我们可以通过查看 slot 中每秒的证明时间来确认这一点。我们可以看到,80% 的证明在 slot 的第 5 秒被看到。在 slot 的第 4 秒传播的区块很可能会错过至少约 40% 的所有可能的证明,无论它在网络中传播的速度有多快。
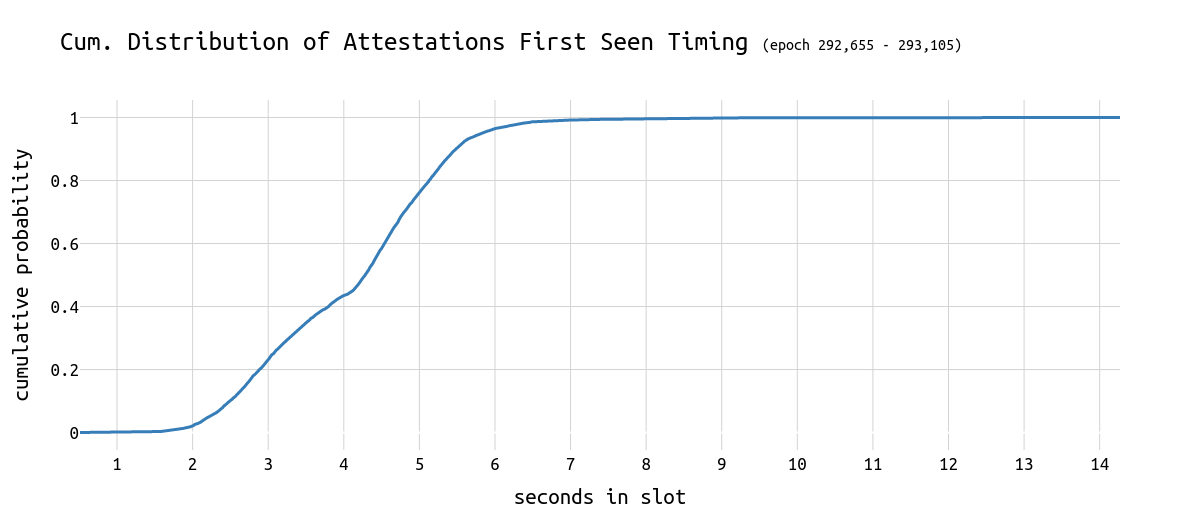 \
attestations_cdf1200×530 27.5 KB
\
attestations_cdf1200×530 27.5 KB
blob 是问题所在吗?
下图显示了 1-blob 区块与 6-blob 区块的首次看到时间:
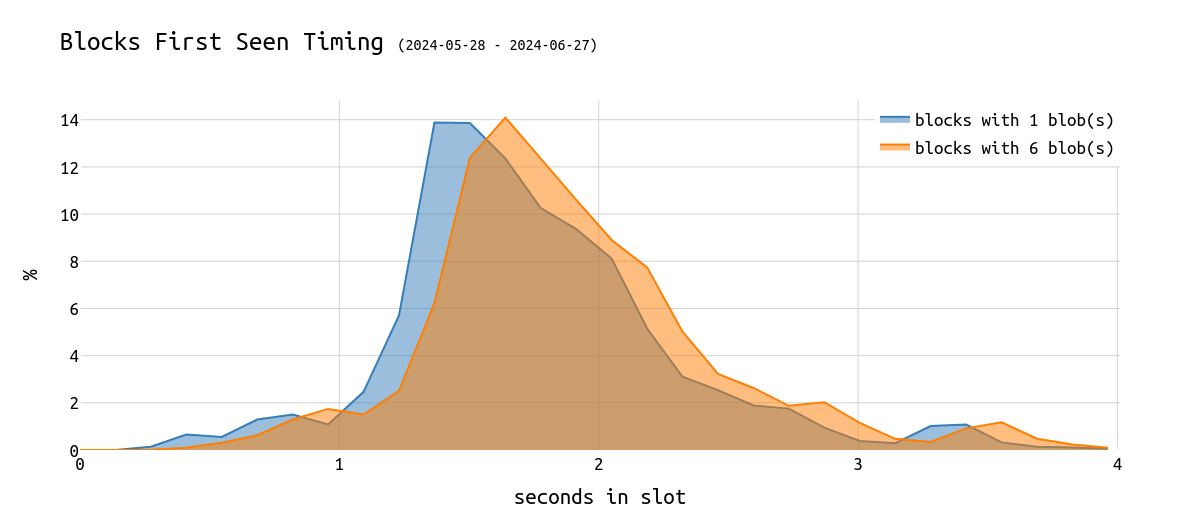 \
hist_late_performer_blobs1200×530 40.1 KB
\
hist_late_performer_blobs1200×530 40.1 KB
我们可以看到,尽管 6-blob 区块在 slot 中被看到的时间较晚,但增量相当小,甚至可以忽略不计。在区块到达时,blob 应该已经被看到了。
过去,用户是否使用 MEV-Boost 会影响不同的性能指标。因此,为了完整起见,让我们绘制 MEV-Boost 用户与本地构建者的关系:
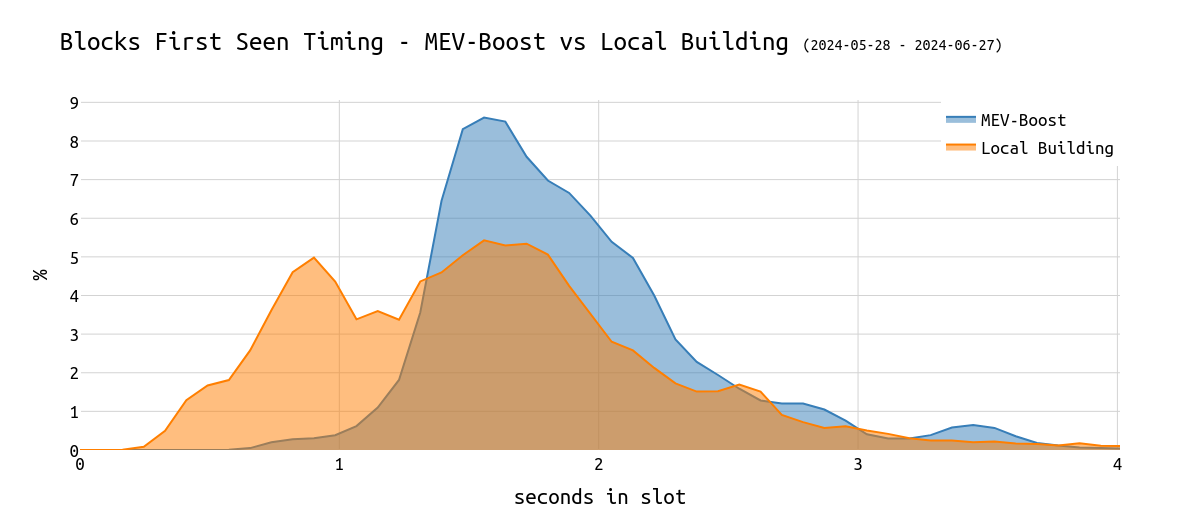 \
hist_late_performer_mevboost1200×530 41.1 KB
\
hist_late_performer_mevboost1200×530 41.1 KB
最后,比较三个最大的中继器,我们得到以下图像:
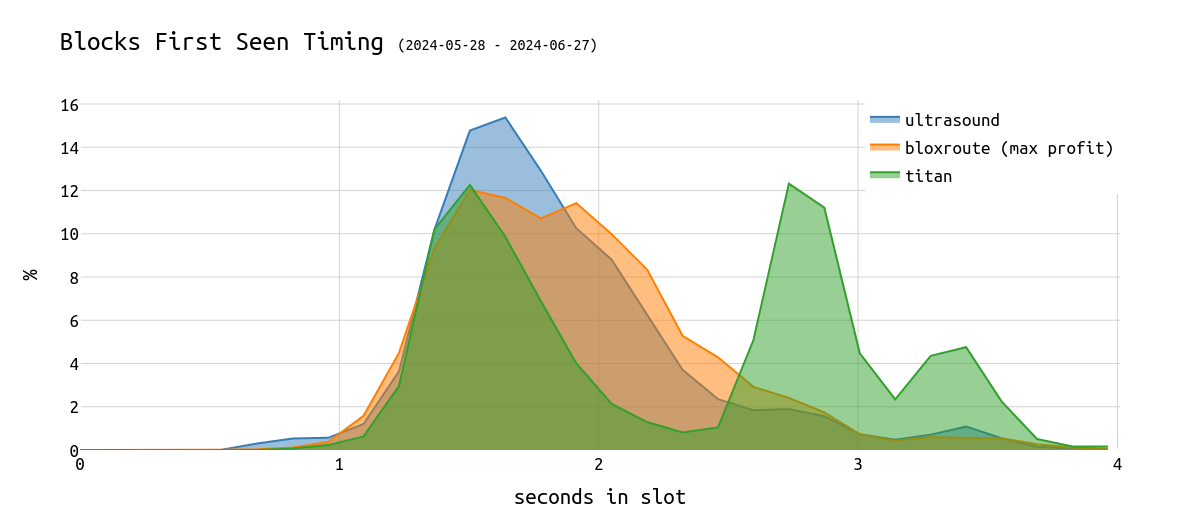 \
hist_mevboost_relays1200×530 50.5 KB
\
hist_mevboost_relays1200×530 50.5 KB
虽然大多数中继器(如 Ultra Sound、BloXroute、Agnostic Gnosis 或 Flashbots)显示非常相似的曲线,但我们可以看到 Titan 中继器有两个峰值而不是一个。
这意味着通过 Titan 中继器的一些区块在 slot 的 2.5-3 秒之间首次在 p2p 网络中被看到,这非常晚。
值得注意的是,Titan 的那些较晚区块仍然变成了规范区块,这表明了提议者的时间安排游戏。
证明和提议者时间安排游戏
接下来,让我们看看提议者时间安排游戏对证明的影响。
如果区块提议者延迟其区块提议,以便为构建者提供更多的时间进行 MEV 提取,我们将把这称为提议者时间安排游戏(请参阅[1],[2])。
提议者可以不要求中继器在区块的第 0 秒提供区块,而是可以延迟此操作,例如延迟到 slot 的第 2 秒,并最大限度地提高利润。这带来了无法获得足够证明并被重新组织的风险。
在 timing.pics 上找到有关时间安排游戏的一些实时视觉效果。
 \
timing_games2463×620 274 KB
\
timing_games2463×620 274 KB预计提议者时间安排游戏会对验证者的证明性能产生负面影响,尽管尚未对此进行彻底分析。令人担忧的是,提议者时间安排游戏可能会产生连锁反应:证明者可能会稍微延迟其证明,以确保他们投票给链的正确 head。知道提议者正在玩时间安排游戏,延迟证明也可能是合理的。这种策略可能对网络的整体健康有害。
有关提议者时间安排游戏对证明的影响的更多信息,请查看 Caspar 的帖子。
下图显示了每个 slot 中每秒错过的 head vote 的平均数量。 中继器的数据 API(bidsReceived 端点)用于 slot 内的时间戳。
之前的多项分析表明,使用 bidsReceived 时间戳可以提供对实际传播时间的一个足够好的近似值。值得注意的是,bidReceived 必须早于区块的传播时间。
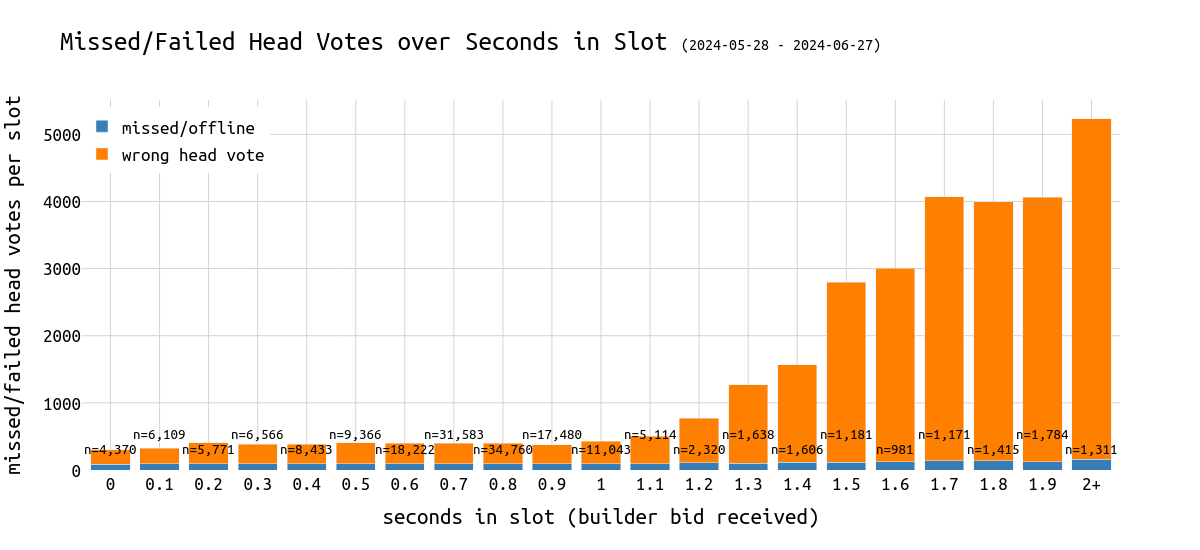 \
failed_missed_head_votes_over_timing1200×550 41 KB
\
failed_missed_head_votes_over_timing1200×550 41 KB
上面的图表显示,在进入 slot 的 1 - 1.2 秒后,错过的 head vote 的数量迅速增加。提议者等待的时间越长,预计其区块收到的证明就越少。
我们可以看到,对于发布到 slot 的超过 1.7 秒的较晚区块,每个 slot 中错过的 head vote 的数量平均增加到 >4k(委员会的 12.5%)。
这听起来很糟糕,尽管与每个 slot 中进行证明的 32k 个验证者相比,这些数字仍然相对较低。
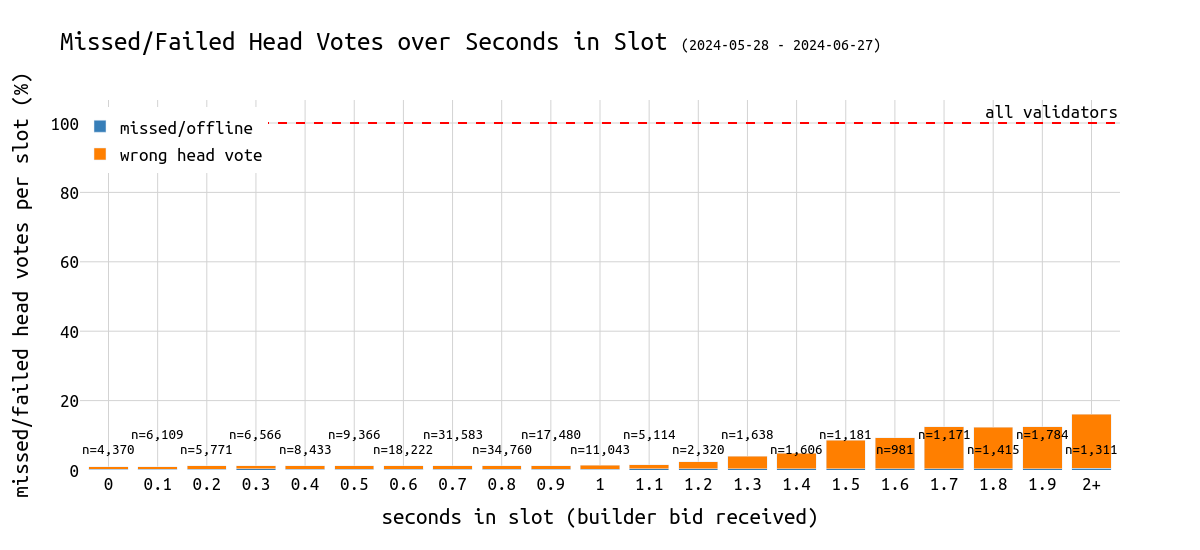 \
failed_missed_head_votes_over_timing_per1200×550 42 KB
\
failed_missed_head_votes_over_timing_per1200×550 42 KB
提出一个bid received 时间戳超过 2 秒的区块会导致平均 5k 个证明被错过。这约占委员会的 15%。
- Diseconomies of Scale: Anti-Correlation Penalties (EIP-7716)
- On Attestations, Block Propagation, and Timing Games
- On Proposer Timing Games and Economies of Scale
- 原文链接: ethresear.ch/t/deep-divi...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
- 翻译
- 学分: 0
- 分类: 以太坊
- 标签: attestation 以太坊 验证者 区块传播 mev-boost Proposer Timing Games





