使用P2P数据估计验证者去中心化程度 - 网络
- 以太坊中文
- 发布于 2024-06-28 16:28
- 阅读 1061
本文介绍了如何使用P2P网络数据来估计以太坊验证者的去中心化程度。文章深入探讨了验证者的结构、职责,以及验证者如何在P2P网络中通过attestation subnets进行通信。文章还详细描述了一个用于抓取validator信息的爬虫架构,以及如何分析收集到的数据来估计validator的数量和地理位置。
作者:Jonas & Naman 来自 Chainbound.
这项研究由以太坊基金会的 Robust Incentives Group 资助。这项工作特别与 ROP-8 相关。更多信息请参见 此处。我们要感谢 soispoke、EF DevOps 团队、MigaLabs 和 ProbeLab 的建议和贡献!
目录
引言
验证器集合的地理分布是决定区块链去中心化程度的 最关键因素之一。验证器的去中心化对于以太坊至关重要。它通过分配控制权并最大限度地降低单点故障或恶意攻击的风险,从而增强网络安全性、弹性和抗审查性。
众所周知,以太坊拥有一个 非常大的 验证器集合,但 这个验证器集合是否在地理上分布均匀? 以太坊在共识层网络上运行着大量的信标节点,目前的估计约为 12,000 个活跃节点(来源)。信标节点可以作为验证器进入网络的潜在入口点,但它并不能代表实际的验证器分布。
 \
image1920×1920 117 KB
\
image1920×1920 117 KB可能不是。
在本文中,我们将介绍一项旨在解决此问题的调查的方法和结果。我们首先介绍构成验证器的逻辑组件的一些背景知识,然后介绍在信标 P2P 网络上识别验证器的潜在方法。然后,我们扩展我们选择的方法,最后展示结果。
验证器的剖析
以太坊验证器是一个虚拟实体,由信标链上的余额、公钥和其他属性组成。它们大致负责 4 件事:
- 提议新的区块
- 对其他区块提案进行投票(证明)
- 聚合证明
- 在其他验证器出现故障时削减它们
验证器客户端 是一种软件,它为每个注册的验证器密钥(可以有很多)执行这些职责。但是,验证器客户端本身无法连接到 P2P 信标网络以直接与其他验证器通信。相反,它连接到一个称为信标节点的实体,该实体是一个独立的客户端,用于维护信标链并与其他信标节点通信。
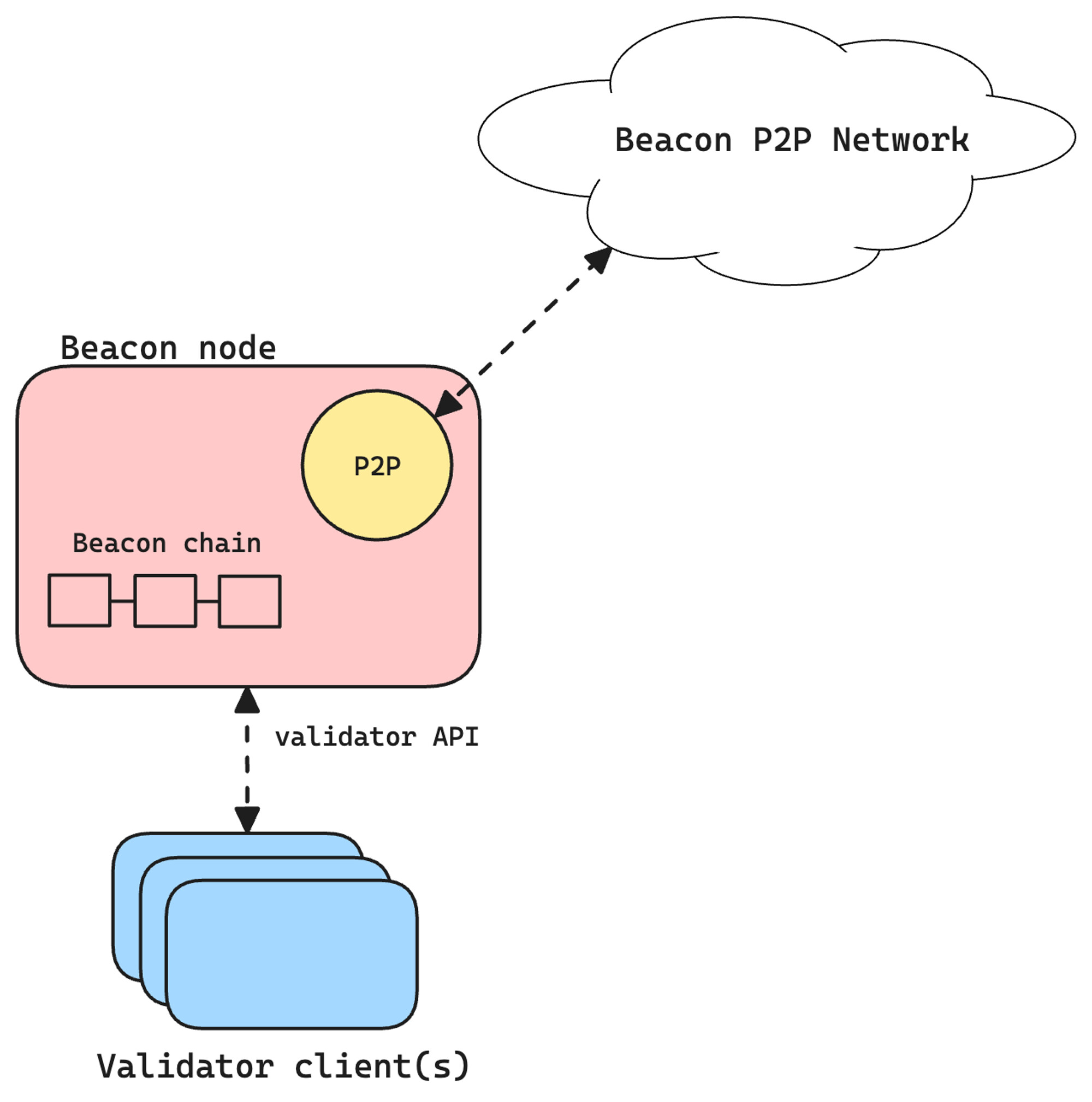 \
image2000×2019 162 KB
\
image2000×2019 162 KB验证器客户端和信标节点的示意图
信标节点可以附加许多验证器,范围从零到数千个。事实上,据报道,在一些以太坊测试网中,客户端开发人员在一台机器上运行了超过 5 万个验证器。这种关注点分离使我们的调查更加困难:对 P2P 网络的简单爬取可能会让我们很好地了解实时在线信标节点的集合,但这根本不能代表整体验证器客户端的分布。在我们解决这个问题之前,我们将仔细研究验证器职责及其在网络上的足迹。
证明职责和委员会
如上所述,验证器的主要职责之一是通过广播证明对区块进行投票。这些证明表达了验证器关于他们认为哪个链是正确的观点。更详细地说,它们实际上投了 2 种不同的票:一种用于表达他们对当前头部区块的看法,另一种用于帮助最终确定过去的区块。这是因为以太坊的共识是 2 个子协议 的组合:LMD GHOST,一种分叉选择规则,以及一个名为 Casper FFG 的最终性工具。
这些职责是每个 epoch 随机分配的(有一些 前瞻),RANDAO 作为随机性来源。验证器在每个 epoch 中被分配到一个 slot,他们必须在该 slot 投出证明,这只是一个带有投票的消息,该消息使用验证器 BLS 私钥签名。然后,这些投票将被打包并存储在下一个信标区块中。但是,如果 所有 100 万个验证器 都为每个区块进行证明,那么网络将被消息淹没,并且应该将这些证明打包到其区块中的提议者将难以及时验证所有这些签名。这将使以太坊的低资源验证的设计目标变得不可行。
为了解决这些问题,信标网络被细分为委员会,这些委员会是活动验证器集的子集,用于分配整体工作负载。委员会的最小规模为 128 个验证器,并且每个 slot 分配 64 个委员会。但这是如何在实践中实现的?我们需要哪些网络原语来实现这种逻辑分离?
证明子网
以太坊共识 P2P 网络是使用 GossipSub 构建的,这是一个在 libp2p 上运行的可扩展发布/订阅协议。作为一种发布/订阅协议,GossipSub 支持发布/订阅模式以及将网络划分为称为主题(又名 P2P 覆盖网络)的逻辑组件**。_这些是支持信标委员会的网络原语。
主题的一个示例是beacon_block 主题,这是一个全局主题,用于广播新的信标区块。每个验证器都必须订阅此主题才能更新其本地链视图并履行其职责。
证明覆盖网络看起来截然不同。对于每个委员会,我们基于委员会索引(0-64)派生一个子网 ID。然后,相应子网的主题变为 beacon_attestation_{subnet_id}。每个验证器至少提前 1 个 epoch 知道他们即将进行的证明职责,并且可以提前加入正确的子网。当他们必须进行证明时,他们会在此子网上广播它。
如前所述,这些证明最终应该进入信标区块。但是,由于即将到来的提议者可能没有订阅这些子网,那么这是如何工作的呢?这就是证明聚合器发挥作用的地方。这些是信标委员会的一个子集,负责聚合他们看到的所有证明,并在全局beacon_aggregate_and_proof 主题上广播聚合的证明。此主题再次是所有验证器都将订阅的强制性全局主题,从而提供了一种使本地未聚合证明进入网络全局视图的方式。每个委员会的目标聚合器数量为 16 个。
子网类型
上面描述的这些证明子网是临时的,并且与验证器职责直接相关。我们称这些为 短寿命 证明子网。这些临时子网的问题在于它们不是很健壮,并且可能导致消息丢失。为了解决这个问题,引入了“ 子网骨干”的概念。
此骨干由 长寿命 的持久子网订阅组成,这些订阅不与验证器职责相关,而是与信标节点唯一 ID 和当前 epoch 的 确定性函数 相关。这些长寿命子网维护 256 个 epoch,或大约 27 小时,并且每个信标节点都必须订阅其中的 2 个。它们也在发现层上公布,从而使具有某些职责的信标节点可以更轻松地在相关子网上找到对等方。
验证器足迹
回到信标节点和验证器客户端的分离,现在验证器在信标节点的网络身份上留下了清晰的足迹:他们的短寿命子网订阅。这将是我们方法论的核心。
方法论
通常,信标网络由 3 个域组成:
- 发现域
- Req/Resp 域
- Gossip 域
这些域中的每一个都提供有关信标节点的一些信息。
长寿命子网 & 节点元数据
在 发现层 (discv5),信标节点的身份由一个带有附加元数据的 ENR 组成。此元数据大致可以表示为以下对象:
{
peer_id,
ip,
tcp_port,
udp_port,
attnets, // 重要
fork_digest,
next_fork_version,
next_fork_epoch
}
此元数据有助于其他对等方连接到与它们相关的对等方,实际上,其中一个额外的元数据字段是此节点订阅的(长寿命)证明子网!
Req/Resp 域 是实际发生握手的地方。这是节点交换如下所示的 Status 消息以建立连接的地方:
(
fork_digest: ForkDigest
finalized_root: Root
finalized_epoch: Epoch
head_root: Root
head_slot: Slot
)
用于 Req/Resp 域的基础协议(再次)是 libp2p。在较低级别,设置连接时还会交换其他信息,如 client_version。
在此级别,对等方还可以交换 MetaData 对象以识别彼此最新的长寿命子网订阅。MetaData 对象如下所示:
(
seq_number: uint64
attnets: Bitvector[ATTESTATION_SUBNET_COUNT]
...
)
短寿命子网
到目前为止,我们只看到了节点如何交换元数据及其长寿命子网订阅,这并没有告诉我们任何有关潜在验证器的信息。为此,我们需要短寿命子网,我们只能在 gossip 域上收集这些子网。我们最初的策略就是这样做的:
- 监听传入的主题订阅请求
- 保存并索引它们
但是,在对数据进行初步审查时,我们看到了太多的信标节点,除了其长寿命的强制性订阅之外,没有订阅任何其他子网。
我们的假设是,为了在 gossipsub 主题上发布数据,需要订阅它。事实证明并非如此,并且许多客户端具有不同的行为以最大限度地减少带宽和 CPU 使用率。对等方不是直接订阅子网,而是事先找到订阅所需子网的其他对等方,并与它们共享证明。订阅的对等方确保验证并转发这些证明。请记住,从理论上讲,只有证明聚合器才需要监听所有传入的证明才能完成其工作。这正是发生的情况,并解释了为什么我们对短寿命子网的观察如此之少。
有了这种理解,我们现在可以调整我们的假设:
- 对于每个子网,每个委员会的目标聚合器数量为
TARGET_AGGREGATORS_PER_COMMITTEE=16 - 这意味着平均而言,每个委员会中只有 16 个验证器会在一个 epoch 的持续时间内订阅一个额外的短寿命子网
- 这导致每个 epoch 最多 16 32 64 = 32768 个有用的观察结果
考虑到这些假设,我们可以开始估算验证器数量。
估算验证器数量
对于每个观察结果,我们从所有已订阅的子网 S_{all} 中减去长寿命子网 S_l 的数量,以得出短寿命子网 S_s 的数量:
S_s = S_{all} - S_l
由于我们知道聚合器每个 epoch 订阅一个额外的子网,因此 S_s 将导致此 epoch 中某个信标节点的估计验证器数量。请注意,仅一个观察结果不足以获得准确的估计,原因如下:
- 验证器可能不是此 epoch 的聚合器,因此不会订阅任何子网
- 长寿命子网和短寿命子网之间可能存在重叠
由于这个原因,我们不断尝试收集每个已知信标节点每个 epoch 的观察结果,并保存最大估计验证器数量。另请注意,验证器估计的上限为 64 - 2,因为这是我们可以记录的最大短寿命子网数量。这很重要!这意味着对于拥有超过 62 个验证器的信标节点,我们无法估计有多少个验证器,只能记录上限。我们想再次强调,这只是一个估计,并不能非常准确地表示验证器的总数。
架构
在本节中,我们将更深入地研究架构。所有代码都是开源的,可以在此存储库中找到:GitHub - chainbound/valtrack: An Ethereum validator crawler。许多爬虫代码都基于 Hermes 和 Armiarma 等项目。概述如下所示:
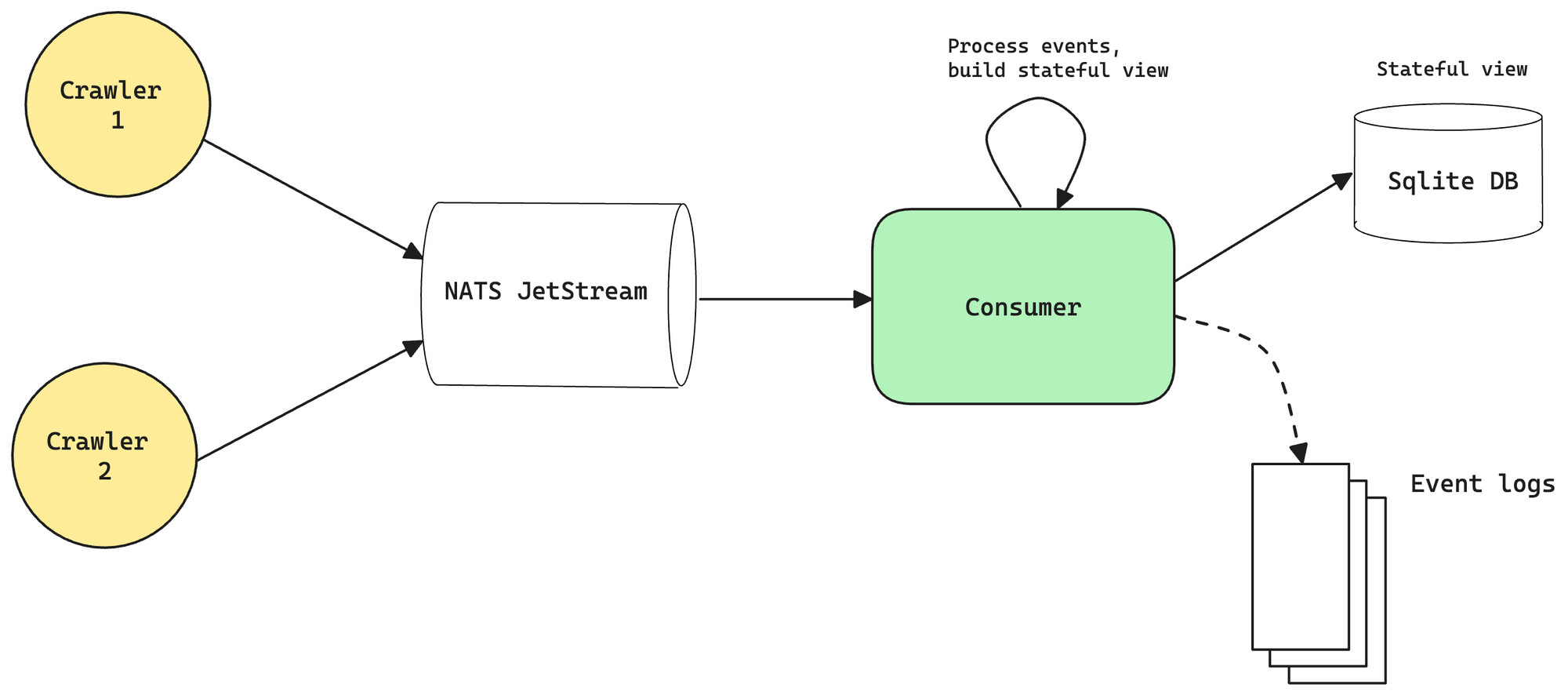 \
image2000×886 99.1 KB
\
image2000×886 99.1 KB爬虫
爬虫是系统的核心组件。它将爬取 discv5 发现 DHT,通过查看 ENR 中的元数据来查找位于正确网络上的节点,然后尝试与它们连接。它将保留已知对等方的本地缓存,并尝试每隔一个 epoch 重新连接以获取更新的观察结果。
我们概述了 2 种类型的事件(观察结果):PeerDiscoveryEvent 和 MetadataReceivedEvent。第二个最相关,并包含以下字段:
type MetadataReceivedEvent struct {
ENR string `json:"enr"`
ID string `json:"id"`
Multiaddr string `json:"multiaddr"`
Epoch int `json:"epoch"`
MetaData *eth.MetaDataV1 `json:"metadata"`
SubscribedSubnets []int64 `json:"subscribed_subnets"`
ClientVersion string `json:"client_version"`
CrawlerID string `json:"crawler_id"`
CrawlerLoc string `json:"crawler_location"`
Timestamp int64 `json:"timestamp"` // UNIX 时间戳(毫秒)
}
除了某些元数据之外,这还包含应用先前描述的方法所需的所有字段:SubscribedSubnets 包含通过监听 GossipSub 域获得的实际订阅的子网,而 MetaData 包含对等方的长寿命子网。
所有这些事件然后都将发送到持久消息队列,在其中存储它们,直到它们被使用者读取。
消费者
使用者通过实现上述方法将事件日志转换为网络的有状态视图。它从元数据事件中解析短寿命子网以获取估计的验证器数量,并更新其有状态视图中的任何现有条目。此有状态视图保存在本地 sqlite 数据库中,我们通过 API 公开它。表架构大致如下所示:
validator_tracker (
peer_id TEXT PRIMARY KEY,
enr TEXT,
multiaddr TEXT,
ip TEXT,
port INTEGER,
last_seen INTEGER,
last_epoch INTEGER,
client_version TEXT,
possible_validator BOOLEAN,
max_validator_count INTEGER,
num_observations INTEGER,
hostname TEXT,
city TEXT,
region TEXT,
country TEXT,
latitude REAL,
longitude REAL,
postal_code TEXT,
asn TEXT,
asn_organization TEXT,
asn_type TEXT
)
然后,我们将这些数据与 IP 位置数据集连接在一起,以提供有关地理分布的更多信息。
结果
Chainbound 运行一个 GitHub - chainbound/valtrack: An Ethereum validator crawler 部署,该部署每 24 小时将所有数据推送到 Dune。
Dune 表链接:https://dune.com/data/dune.rig_ef.validator_metadata。
此数据已剥离了敏感信息,例如 IP 地址和确切坐标。但是,它保留了诸如城市、精度为 10 公里半径的坐标以及 ASN 信息之类的信息。
一个利用此信息的示例仪表板可以在 此处 看到。
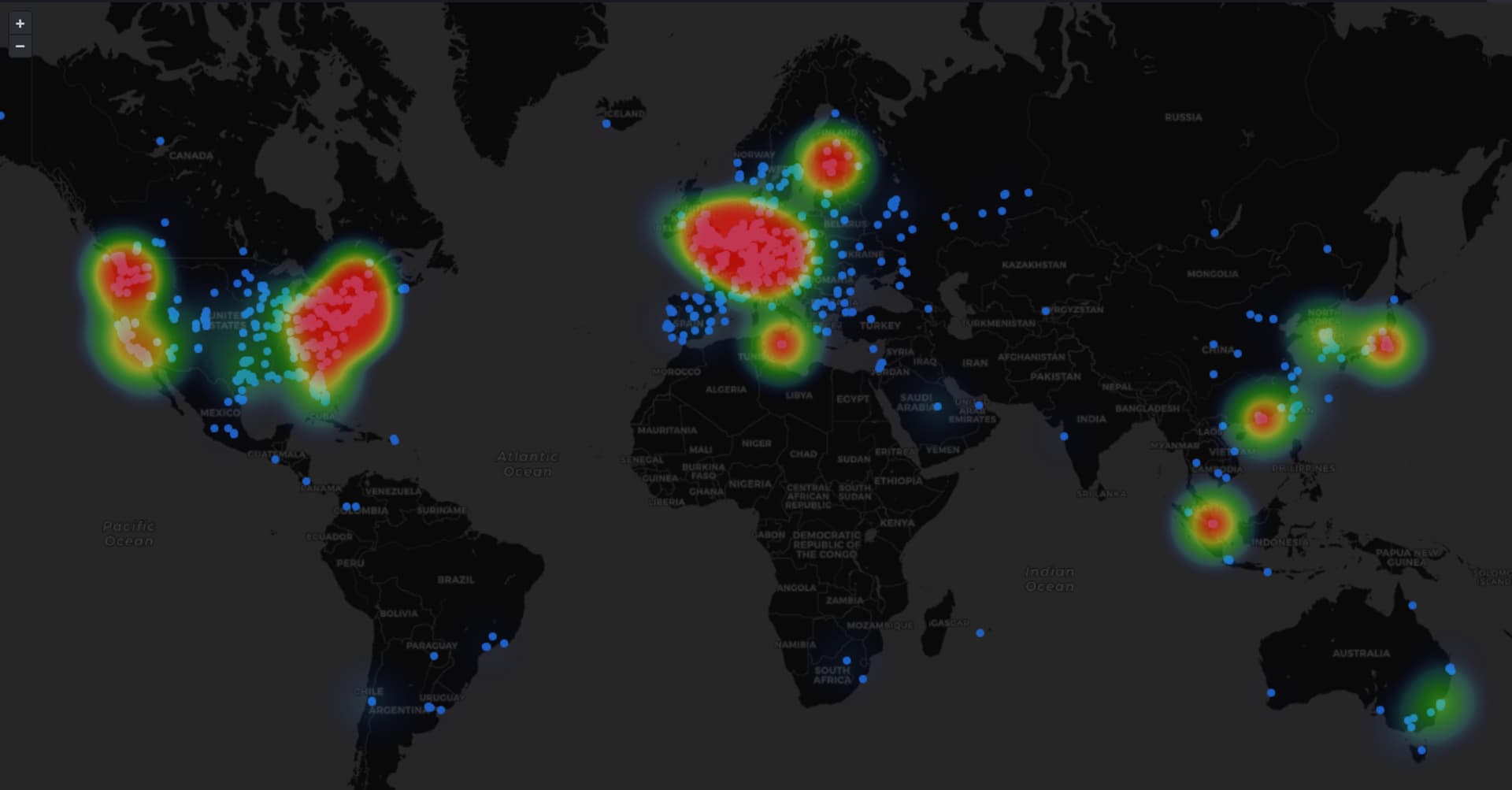 \
image1920×1003 66.3 KB
\
image1920×1003 66.3 KB我们还存储单独的事件日志,例如 PeerDiscoveryEvent 和 MetadataReceivedEvent。可以通过发送电子邮件至 admin@chainbound.io 按需获取这些日志。
局限性
- 由于短寿命子网订阅的最大数量为 62 个,因此我们使用此方法估算每个信标节点的验证器的最大数量为 62 个。这将导致大大低估验证器的总数,但仍然应该能够提供对地理分布的合理估计。
- 在 30 天的时间内,我们未能收集到有关 Teku 节点的任何有意义的数据,这可能表明我们的 P2P 实现中存在错误并影响结果。
- 这些结果将偏向于连接到在其防火墙中打开了 P2P 网络端口的信标节点的验证器,这些节点主要是在云提供商上运行的信标节点。原因是我们的爬虫可以更轻松地连接到已暴露端口的节点。
参考文献
- 升级以太坊
- 以太坊共识中的 P2P 覆盖网络的Hitchhiker指南 - HackMD
- GitHub - ethereum/consensus-specs: 以太坊 Proof-of-Stake 共识规范
- P2P 网络中的隐私问题以及它们告诉我们的信息
- Blob Notaries:一种分布式 blob 发布设计,用于扩展 DA
- 原文链接: ethresear.ch/t/estimatin...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





