AI代理如何在任何代码库中发现深层逻辑漏洞
- muellerberndt
- 发布于 2025-09-03 09:30
- 阅读 2225
文章介绍了Hound,一个语言无关的AI代码安全审计工具,它模拟人类专家的认知过程,通过构建动态知识图谱和推理模型来发现代码中的深层逻辑错误。Hound使用大型推理模型生成有针对性的假设,并使用认知和组织过程来帮助AI进行推理、记忆和改进。文章还展示了如何在Code4rena的SecondSwap审计竞赛的代码库上运行Hound。
Hound 是一种与语言无关的 AI 代码安全审计器,它模拟人类专家的认知过程。它将系统映射为动态的知识图谱,并使用来自强大推理模型的专注、高质量的假设来查找任何堆栈中的深层逻辑错误。在这篇文章中,我将解释 Hound 的工作原理,并展示如何在实际的审计竞赛的代码库上运行它。

2020 年初,我第一次将智能合约代码粘贴到 GPT-3 中,想知道语言模型是否可以发现安全问题。那时 ChatGPT 尚未出现,所以我必须将提示注入到名为 AI Dungeon 的基于文本的游戏中。不出所料,那些早期实验的结果平庸。
到 2023 年,我已经根据漏洞数据集对 GPT-3.5 进行了微调。它对于表面模式很有用,但感觉更像是一个不知疲倦的正则表达式引擎,而不是真正的审计员。然后是 GPT-4,我开始了名为 Hound 的私人研究项目:一系列 AI 辅助错误查找实验。
Hound 的第二个迭代版本获得了它的第一个漏洞赏金,但结果仍然不均衡。对于 v3,我决定从第一性原理重建。如果我模拟自己在审计期间使用的确切认知过程会怎样?人类构建灵活的系统心理模型,跟踪假设和不变量,并在新的关系出现时完善他们的理解。AI 应该做同样的事情。Hound v3 镜像了这个过程:它构建应用程序的不断演变的“心理地图”,跨越抽象和具体概念进行推理,随着时间的推移加深其理解,并在面对新证据时更新其信念。
有两个论点支撑着 Hound 中的一切:
- 与其进行数千次浅层检查,不如使用大型推理模型生成有针对性的假设,这些模型可以直观地判断漏洞在哪里。无论你进行多少猜测,浅层推理都会错过错误;深层推理会将几个步骤变成正确的步骤。
- 人类使用的认知和组织过程——灵活的心理模型、明确的假设/不变量、高级/初级协作、QA——对 AI 代理也很有用。结构有助于 AI 推理、记忆和改进。
这篇文章深入探讨了 Hound 的工作原理以及如何使用它。我们将在 Code4rena 上的 SecondSwap 审计竞赛 的代码上运行它。竞赛报告在模型训练截止日期之后发布,因此我们获得了干净的信号。
使用灵活的知识图谱对代码库进行建模
人类专家不会线性地阅读代码。我们构建心理地图:组件、调用层次结构、状态和值流、授权边界、假设、不变量。当我们学习时,该地图会发生变化。Hound 通过构建目标系统的动态知识图谱来镜像此过程。
它是如何工作的
Hound 首先生成与语言无关的 代码卡片:由线性分块创建的连续字节切片,每个切片都标有 char_start 和 char_end 偏移量,以确保对每个文件的完整、非重叠覆盖。然后,推理模型会审查这些卡片,并提出一组针对代码库量身定制的方面图。一个标准图——SystemArchitecture——始终生成,而其他图会根据手头的项目进行自定义。一旦定义了模式,一个更轻的模型会迭代地构建每个图。最后,Hound 将结果持久化为 JSON,以及包含引用代码片段的紧凑卡片存储。
这些图中的每个节点——无论它代表一个具体的函数还是一个抽象的概念——都可以用假设和观察来注释,例如“fee ≤ 1000 bps”、“只有所有者可以取消列出”或“totalAssets 等于 sum(strategyAssets)”。随着代理读取更多代码,它会不断更新地图。矛盾被视为信号;当地图的两个部分不同意时,通常是因为它们之间隐藏着一个错误。
图节点(函数、存储、角色)和边都是有证据支持的:它们存储对定义或使用出现的精确代码卡片 ID 和字符跨度的引用,如果符号跨越切片,则使用多个跨度。当检查节点或子图时,Hound 会加载引用的卡片,因此代理始终会看到它需要审计特定流、函数或功能的精确代码切片。这解决了在需要时将精确的正确代码放入上下文的问题,并且它无需解析或矢量化代码即可工作!
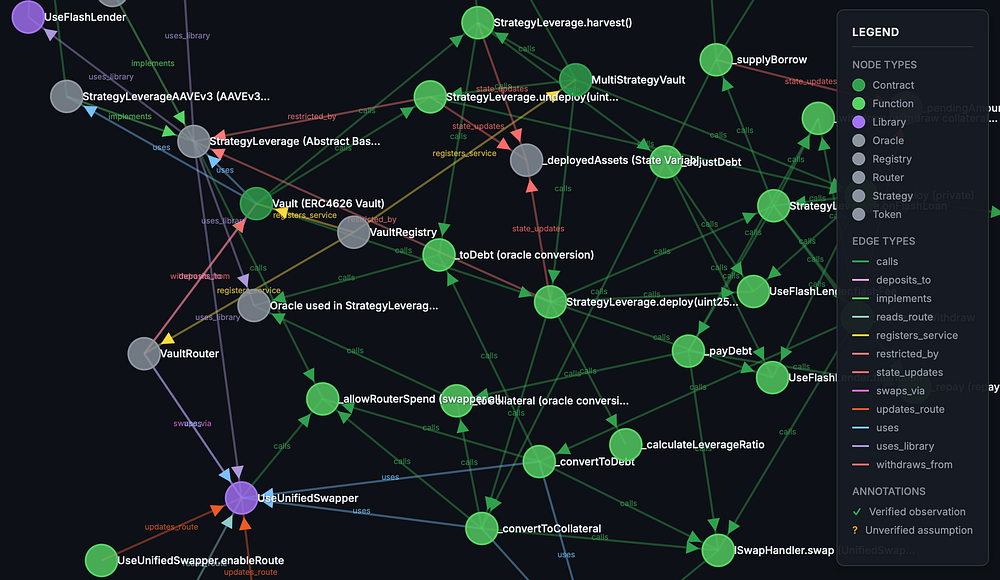
Hound 生成的典型图。此图对与执行杠杆策略相关的功能流进行建模。
实践中
让我们开始分析我们的 Code4rena 目标。首先,让我们看一下 main config 中设置的模型。总共,我们需要为各种角色配置 5 个模型。下表显示了一些建议:
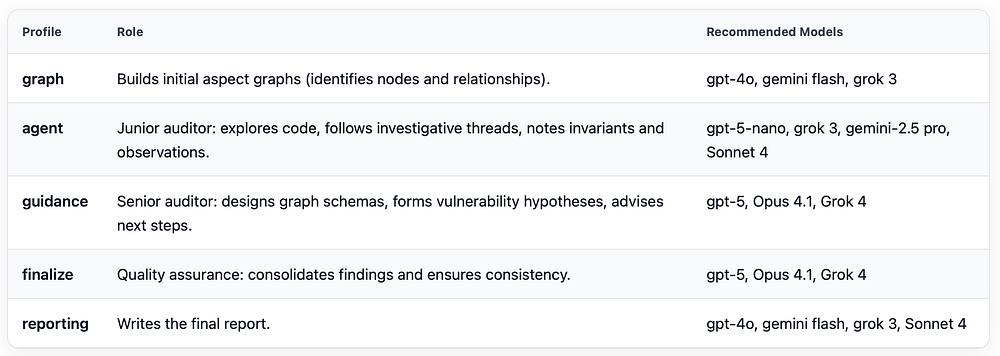
“agent”和“guidance”模型执行大部分分析。“agent”模型——通常是一个较小的模型——代表一个初级审计员。它浏览图,选择切片,将相关节点拉入视图,并使用观察注释节点,并在遇到问题时提出问题。“guidance”模型(又名高级安全研究员)创建高级计划,定期审查初级人员的操作,并且至关重要的是,拥有漏洞假设生成。将假设创建掌握在高级人员手中可确保漏洞假设具有针对性和高质量。
“finalize”模型负责审计结束时的单独 QA 步骤。绝对建议使用最新的推理模型进行“指导”和“finalize”,因为分析的整体质量在很大程度上取决于这些模型的功能。
对于此特定测试,我将 Grok 3(初级审计员)与 GPT-5(高级审计员)配对,这是一个非常不错的组合。GPT-5-nano 也被聘为图构建器和报告编写器。
我启动了一个新项目,并要求 Hound 基于核心合约(不包括测试和接口)构建五个知识图谱:
./hound.py project create
./hound.py graph build secondswap - graphs 5 - iterations 8 - files "contracts/SecondSwap_Marketplace.sol,contracts/SecondSwap_MarketplaceSetting.sol,contracts/SecondSwap_StepVesting.sol,contracts/SecondSwap_VestingDeployer.sol,contracts/SecondSwap_VestingManager.sol,contracts/SecondSwap_Whitelist.sol,contracts/SecondSwap_WhitelistDeployer.sol,contracts/USDT.sol"`Hound 生成了以下图:

这些初始图是 Hound 的第一个工作理解——足以进行推理,旨在进行完善。代理可以自由地放大特定节点,这些节点会返回相关的代码片段以及其他信息。这里的想法是,代理应该在任何给定时间将其注意力集中在图中最有希望的切片上。例如,如果代理怀疑与货币流上下文中的特定算法相关的问题,它可以查询该图以获取与此问题相关的精确代码片段。
请注意,SystemAchitecture 图始终会创建并且始终存在于代理的上下文中。其余图是为特定目标范围定制设计的。你可以使用 graph export 命令导出和查看 Hound 的图。
./hound graph export secondswap使用图模型,该模型可以流畅地关联跨粒度的细节——本地代码路径、组件级行为和系统级不变量——只要它重要。至关重要的是,它将抽象概念(假设、角色、不变量)链接到具体、有证据支持的代码跨度,并逐步构建这些锚点之间的关系。Authorization Roles 图中的“只有 s2Admin 可以取消列出”不仅必须与 Inter-Contract Calls 图中的每个 delist() 路径对齐,还必须与沿这些路径触摸的相关状态转换、前/后条件以及值/单元语义对齐。当观察结果与假定的不变量冲突时,不匹配会在图中亮起,并且该模型知道检查相关代码。
探索、调查和假设形成
图完成后,我们的审计员就可以开始工作了。对于 SecondSwap,我们像这样启动审计:
./hound.py agent audit secondswap - time-limit 180`我们的代理决定调查 Authorization Roles 图以审查角色边界。初级代理加载所需的节点(这将返回相关的源代码)并使用假设/观察对其进行注释。高级人员定期审查初级人员的工作并提出漏洞假设。
如果在审计期间或之后将图重新导出为 HTML,注释将显示在图中:
./hound.py graph export secondswap例如,“归属生命周期”视图中的节点会累积不变量,例如“releaseRate = amount / duration”、“stepDuration 干净地划分总持续时间”以及“转移归属不得更改其他头寸的计划”。当高级人员发现矛盾时——例如,重新计算 releaseRate 不一致的转移路径——它会指示初级人员调查相关代码和/或提出新的漏洞假设。
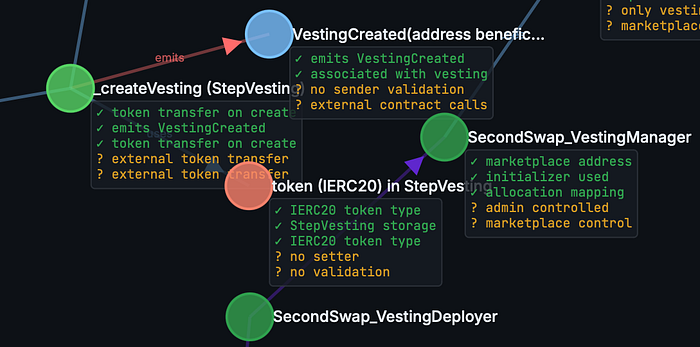
节点注释允许代理捕获假设和观察。这允许代理推断抽象和/或具体概念之间的关系。
知识细化:信念和假设系统
Hound 将图注释与有关漏洞的假设分开。注释是直接附加到节点的工作假设和不变量——“费用在购买前已知”、“只有所有者可以取消列出”、“releaseRate 在转移中稳定”——创建成本低廉,易于修改,并且始终以证据为基础。假设是有针对性的、可证伪的关于漏洞的主张,每个主张都有一个根本原因、攻击向量、影响和特定的代码引用。它们的铸造成本很高,并且高级人员承担该责任。
我们可以使用以下命令查看正在进行的审计的假设存储:
./hound.py project hypotheses secondswap你将获得一个表格,显示为该项目提出的所有假设,例如(为 Medium 格式化):
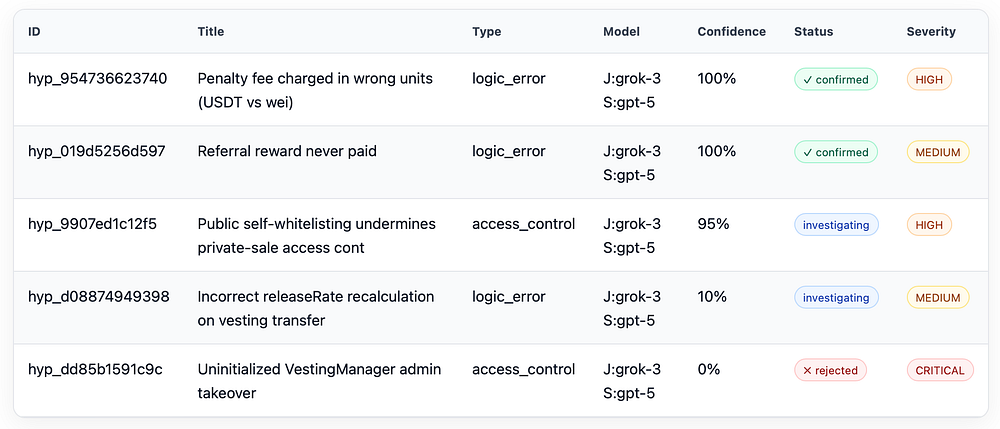
正如我们所看到的,每个假设都有一个置信度评级,该评级会随着时间的推移进行调整。审计可以随时中断,代理团队可以加入和离开审计——投入更多的时间和计算意味着更精细的结果。然后,最终列表将传递给 QA 代理,该代理将考虑高于可配置阈值的任何发现以包含在报告中。
代理团队之间的协作
Hound 的存储支持并发编辑。你可以并行运行多个高级/初级配对——例如,一个中的 Sonnet+Opus,另一个中的 Grok-3+GPT-5——并且他们将实时看到彼此的图和假设。
质量保证:过滤、验证并保持高标准
QA 运行为两步、常识性检查,旨在使最终的一组发现具有合理性。它首先进行一个简短的预过滤器,筛选出超出基准范围的项目,例如需要管理员或治理权限或最佳实践/gas 建议的问题。每个过滤后的项目都会提供一个简短的原因,以便清楚地了解为什么注意力被重定向。剩余内容通过一个有针对性的、代码绑定的审查。在这里,系统读取每个假设引用的文件,并用简单的术语提出一个简单的问题:代码是否按编写的方式公开了一个可利用的路径?确认需要显示的代码中存在可见的攻击路径,拒绝会调用有效的保护或不变量,并且任何不明确的内容都保留为“不确定”,而不是强制做出判断。
SecondSwap 结果
为了在 Code4rena 的 SecondSwap 竞赛中评估 Hound,我将 Hound 的假设与精心策划的基准中接受的发现进行了匹配。在 30 个预期发现中,Hound 生成了 28 个假设并匹配了其中的 10 个(真阳性),留下了 18 个与预期集合不对应的假设(相对于基准的假阳性)以及 20 个错过的预期项目(假阴性)。这转化为在严格匹配下 33.3% 的检测率。在错过的项目中,严重程度混合为两个高、十六个中和五个低。
Hound 以 10 个真阳性匹配 Code4rena SecondSwap 竞赛接受的发现(包括 1 个高度严重和 7 个中度严重问题),在重复份额后将获得大约 1.91 分,将其排在 294 名参与者中的前 15-25 名(Grok 的反向计算,因此请谨慎对待)。
Hound 用于人类审计员:有针对性的绘图和调查
Hound 不仅限于 Solidity——图、信念和假设循环在设计上与语言无关——但 Solidity 是一个方便的例子。在手动审计期间,你可以添加自定义视角来引导图朝着特定的关注点:
./hound.py graph add-custom secondswap "Model the management of vesting positions and transfers"在初始审计之后,图存储学习到的函数行为和不变量,因此你可以要求代理用新的视角重新访问切片:
`./hound.py agent investigate "Check that all invariants with respect to vesting position lifecycle and transfers hold. Note any interesting observations." - iterations 30`在幕后,初级人员组装相关的图和代码片段,并将繁重的推理传递给高级人员。我计划围绕不变量注释添加更明确的 CLI 选项,以便你可以在没有完整审计的情况下独立运行该阶段。
路线图和更多想法
可以轻松地将许多功能添加到 Hound 框架中。例如,如果让 QA 代理自动生成概念验证会很好。“深度研究”模式也会有所帮助:当协议集成外部系统(例如,Uniswap hooks)时,初级人员可以从文档中获取相关的接口和上下文,并将它们直接附加到图节点以供高级人员进行推理。而且,在审计期间,在代理团队之间添加实时通信会很有趣,这样高级和初级团队就可以共享透明的聊天流。
对于手动分析,目标是添加使 Hound 可用作高效建模工具的功能。想象一下自动发现给定应用程序的图模型和不变量,然后自动生成有针对性的测试支架——单击一个节点或不变量,Hound 会立即生成模糊测试和符号测试。它还可以生成任何类型的图(CFG、数据流图等),甚至可以充当直接嵌入到 IDE 中的初级联合审计员。可能性是无限的。
结束语
Hound 的早期测试显示出有希望的结果,但它仍然需要在不同的堆栈、协议和威胁模型上进行系统的基准测试。我的长期目标是完全自动化其开发,代理原型化新功能以优化基准性能。作为第一步,我构建了一个基准生成器,可以自动从最近的审计竞赛中创建数据集。生成器以及初始的精选数据集可在 scabench 上找到,我欢迎贡献和新目标。
Hound 的核心赌注很简单:为强大的模型提供专家审计员使用的相同工具——地图、假设、团队和 QA——他们将发现任何系统中的深层错误,而不仅仅是 Solidity。如果你有想法,或者想向 Hound 抛出不寻常的代码库,请通过评论或在 X 上联系。
- 原文链接: muellerberndt.medium.com...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~



