利用 Valida 通过简洁证明优化以太坊执行引擎
- 0xlita
- 发布于 2025-05-28 10:52
- 阅读 976
Lita 提议扩展 Valida ISA 作为新的以太坊执行环境,以取代以太坊虚拟机(EVM)。这将加速以太坊上的执行速度,降低证明成本,并简化以太坊的验证过程。Valida ISA 专为简洁证明设计,更适合以太坊智能合约的执行。
2025年5月27日
Lita 提议扩展 Valida ISA 作为一个新的以太坊执行环境,以取代以太坊虚拟机(EVM)。由于这些努力,执行应该在以太坊上更快地发生,同时证明的成本更低,并且以太坊的实现应该更容易验证。作为以太坊执行环境的 ISA,Valida 的扩展将提供与 RISC-V 扩展相同的优势,但同时还具有对智能合约执行进行更快、更高效的简洁证明的优势。
1. 背景
让“以太坊执行环境”意味着智能合约执行的环境。目前,以太坊执行环境是以太坊虚拟机(EVM)的同义词。“EVM”指的是:
- EVM 指令集架构(ISA),它是可以直接被以太坊执行的二进制代码格式,或
- EVM ISA 的任何软件实现。
在 2025 年 4 月 20 日,Vitalik Buterin 提议 以太坊执行环境应该与 EVM ISA 解耦,并基于 RISC-V ISA 重新设计。Buterin 写道:
“这篇文章提出了一个关于以太坊执行层未来的激进想法,它与 beam chain 为共识层所做的努力同样雄心勃勃。它的目标是极大地提高以太坊执行层的效率,解决一个主要的扩展瓶颈,并且还可以极大地简化执行层 - 事实上,这可能是唯一的方法。
这个想法:用 RISC-V 替换 EVM 作为智能合约编写的虚拟机语言。”
作为对此的回应,Lev Soukhanov 写道:
“我的建议是,相反,构建一个具有最小 MMU 的对证明友好的架构,允许将合约作为单独的可执行文件运行;我不认为它应该是 RISC-V;而是一个单独的 ISA - 理想情况下,了解 SNARK 协议所规定的限制。即使 ISA 类似于 EVM 的一些操作码子集也可能会更好(+ 正如我们所知,无论我们是否愿意,预编译都将与我们同在,因此 RISC-V 在这里并没有带来任何简化)。”
来源:Soukhanov, Lev. 评论 on Buterin, Vitalk. “长期 L1 执行层提案:用 RISC-V 替换 EVM。” Ethereum Magicians. 2025 年 4 月 20 日。
Buterin 和 Soukhanov 的提案都旨在简化以太坊执行环境的 ISA,以提高以太坊的可验证性、智能合约执行的效率以及证明智能合约执行的效率。
Soukahov 与 Buterin 的不同之处在于 Soukhanov 否认 RISC-V 以太坊执行环境会消除对预编译的需求。对预编译的需求也得到了 Ben Adams 在 Buterin 的同一篇文章上的评论 的支持。
Soukhanov 与 Buterin 的另一个不同之处在于,他认为 RISC-V 特别适合作为以太坊执行环境的 ISA。相反,Soukhanov 建议为此项目设计一个专用 ISA,Soukhanov 建议在设计时应考虑 SNARK 证明。
2. 提案
以太坊执行环境需要重新架构,以支持以太坊进一步扩展到更高的交易量和更复杂的交易。主要问题之一是 EVM 使用 256 位字长。这导致更高的内存消耗和由此产生的内存局部性损失,以及相当昂贵的算术运算。所有这些都是对 EVM 代码进行有效解释或 JIT 编译的障碍。
EVM 架构的另一个问题是其指令具有相对复杂的语义。这导致更复杂的实现,其中有更多的错误机会,从而使审计、测试和形式验证工作更具挑战性。
为了简化和使用 JIT 编译进行有效执行,Valida 和 RISC-V core (RV32IM) 都是很好的起点。它们都支持为主流编程语言(如 C 和 Rust)生成高效代码。Valida 和 RV32IM 的复杂度大致相同,并且它们比 WASM 或 EVM 等替代方案简单得多。
为了有效地进行简洁的执行证明,Valida 比 RISC-V 更好。Valida ISA 专门为进行简洁的执行证明而设计。主要区别在于 RISC-V 具有 31 个通用寄存器组,而 Valida 没有通用寄存器,而是大多数 Valida 操作码直接寻址保存在 RAM 中的堆栈操作数。
在 CPU 中,寄存器是一个位于靠近控制单元和算术逻辑单元(ALU)的内存位置,提供相对快速的读写延迟。寄存器保存相对少量的数据:通常是一个字、少量字或少至一位。通用寄存器通常用于保存算术和逻辑运算的输入和输出。
寄存器是最低延迟形式的易失性存储器,具有最小的存储容量。下一个最低延迟形式的易失性存储器是 L1 缓存,其次是 L2 缓存等,然后是 RAM。通常,较低的延迟意味着较小的存储容量。信息在计算机硬件中传递的速度不会超过光速这一事实解释了这一点。这被称为内存局部性原则:更靠近处理点的内存访问速度更快。
内存局部性原则对硬件上运行的代码的性能有非常明显的影响,因为内存访问延迟通常远高于处理延迟。在 SNARK 证明的上下文中,内存局部性原则不以相同的方式适用。仍然存在访问较小内存成本较低的一般趋势,但这不如 CPU 的情况那么明显。SNARK 与不可变的、永恒的数学关系一起工作,而硬件与因果链一起工作。由于信息不会在 SNARK 证明的关系中通过空间和时间传播,因此对于 SNARK 来说,在物理意义上没有与信息传播速度相关的内存局部性原则。在 SNARK 证明中,通常的趋势是,更新较小的内存可以通过提交较少的信息来完成,这可以降低访问较小内存的成本。
与所有现代 CPU 架构一样,RISC-V 的架构使用通用寄存器来存储逻辑和算术运算的输入和输出。这导致需要在 RAM 和寄存器之间移动数据,尤其是在函数调用边界,其中寄存器的内容必须由调用者和/或被调用者保存和恢复(根据调用约定)。与 Valida 相比,RISC-V 的代码生成将倾向于发出更多处理加载和存储数据的操作码。
使用通用寄存器会增加生成代码的复杂性。在 CPU 架构的上下文中,通用寄存器具有超过成本的优势。在典型的程序中,处理器的运行速度比没有通用寄存器时快得多。另一方面,在 SNARK 证明中,拥有通用寄存器的好处不足以弥补成本。作为 Lita,我们认为这是根据 我们的测试 以及我们从用户收到的反馈,Valida 提供比使用 RISC-V 的 zk-VM 更快的证明的主要原因。
3. 解决 Twist and Shout
Srinath Setty 和 Justin Thaler 的 Twist and Shout 论文(2025 年) 引入了一种新颖的内存参数,与同类产品相比,它对内存局部性更敏感。Setty 和 Thaler 认为,这项创新可能消除对为 SNARK 证明设计的 ISA 的需求:

来源:Setty, Srinath and Thaler, Justin. “Twist and Shout: 通过单热寻址和增量实现更快的内存检查参数。” Cryptology ePrint Archive, Paper 2025/105. P. 23.
在同一篇论文的后面,Setty 和 Thaler 提供了 Twist 内存参数成本对内存局部性敏感性的定量描述:

来源:Setty, Srinath and Thaler, Justin. “Twist and Shout: 通过单热寻址和增量实现更快的内存检查参数。” Cryptology ePrint Archive, Paper 2025/105. P. 68.
值得注意的是,实际上,在 Twist 内存参数的上下文中,内存局部性的好处不如在硬件的情况下那么大。在 Twist 的情况下,对于证明内存访问,如果自上次访问相同地址以来经过的时间加倍,那么证明内存访问的边际成本会增加一到三个字段乘法。另一种考虑方式是,如果你将程序执行中访问地址之间的中值时间加倍,那么你将使内存访问的中值边际成本增加一到三个字段乘法。
为了进行比较,以下图表显示了不同类型内存的内存访问延迟。这些数字截至 2012 年,并且未指定测试系统,因此仅应将其视为粗略的、数量级和相对衡量标准:
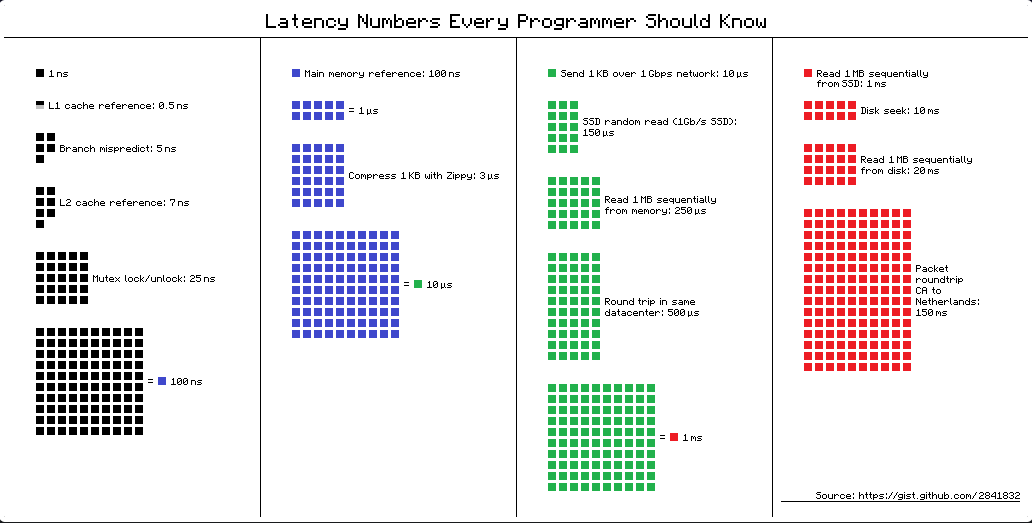
来源:Bonér, Jonas. “每个程序员都应该知道的延迟数字。” GitHub, 2012.
该图表表明,对 RAM 的引用延迟大约是对 L1 缓存引用的 200 倍。与具有 32 位或 64 位容量的 Twist 内存的内存访问成本之间可能存在的最大差异相比,这是一个更大的比例差异。由于此分析未包括寄存器访问延迟(低于 L1 缓存访问延迟),因此 CPU 中最小和最大内存访问延迟之间的实际差异预计会大于 200 倍。
Twist 提供更低的访问较小内存的成本,但也提供更低的访问最近访问的较大内存中的位置的成本。访问较小内存具有较低成本的事实可能提供了在 ISA 中拥有通用寄存器的理由,以便基于 Twist 进行执行证明。但是,由于在 Twist 中访问最近访问的内存位置也更便宜,因此可能没有必要在此类 ISA 中拥有通用寄存器。
在 Valida 中,否则将存储在通用寄存器中的值存储在堆栈上。Valida 中的堆栈是向下增长的内存区域。每个当前执行的函数调用都有其自己的堆栈帧,该堆栈帧是堆栈的一部分,用于保存其局部变量的值. 帧指针寄存器保存指向当前堆栈帧开头的指针。当函数调用返回时,帧指针寄存器会将其先前的值恢复到其中。
由于堆栈的工作方式,在任何给定程序的任何部分执行期间,很可能堆栈的某个区域保持“热”,即经常访问。这是帧指针中值附近的区域。如果执行的每个部分都将其存储器访问集中在堆栈的某个区域中,从而使该区域保持热,那么证明执行将受益于 Twist 存储器参数中较低的存储器访问成本。
当前的论点没有就 Twist 内存参数是否比当前 Valida 证明器中使用的内存参数更有效率发表立场。论点是,无论哪种方式,Valida 都可能为 SNARK 证明提供优于 RISC-V 的优势。即使在基于 Twist 的内存参数的上下文中,在 SNARK 证明的上下文中,也可能由于需要发出更多指令来处理将局部变量值移入和移出通用寄存器的成本而抵消了使用通用寄存器节省的内存访问证明成本。该假设尚未经过测试,但值得测试。
不能排除未来内存一致性参数的创新将具有对内存大小和局部性更敏感的成本的可能性。更一般地说,不能排除为使用当前已知的 SNARK 进行执行证明而设计的 ISA 将不适合未来最好的 SNARK 的可能性。由于未来的创新无法改变的是,至少有可能通过在设计 ISA 时考虑到 SNARK 证明的约束来设计更适合 SNARK 证明的 ISA。鉴于以太坊的目标是支持智能合约执行的有效简洁证明,因此有理由考虑基于当前最佳信息,最适合 SNARK 证明的 ISA 是什么。截至目前,鉴于推动重新构建以太坊执行环境的拟议项目目标,Valida 可能是设计以太坊新 ISA 的最佳起点。与 RV32IM 相比,Valida 具有大多数相同的优势,但也具有更适合简洁执行证明的优势。
4. 编译器技术
为以太坊选择 ISA 的一个关键考虑因素是该 ISA 的编译器技术的可用性。目前的提案设想为以太坊发明一种新的 ISA,这将是 Valida 的扩展。当然,没有编译器针对尚未发明的 ISA。已经有一个针对 Valida 的编译器工具链。它能够编译以 C、Rust 或任何可以编译为 WASM 的语言编写的代码。扩展此编译器工具链以支持以太坊的专用操作码将相对容易。Lita 在从事此类工作中经验丰富。
据 Lita 所知,Valida 是唯一一种为简洁证明而设计的 ISA,它具有积极开发的证明器和用于通用系统编程语言的编译器工具链。使用通用系统编程语言作为源语言具有重大的优势,因为它利用了广泛可用的技能和具有复杂优化功能的成熟编译器管道。这些优势在为简洁证明设计的专用编程语言的上下文中不易复制。这是 Valida 与类似工具链(如 Starkware 的 Cairo 工具链或 Lurk Lab 的 Lurk 工具链)之间的关键区别,后者使用为简洁证明设计的专用编程语言。
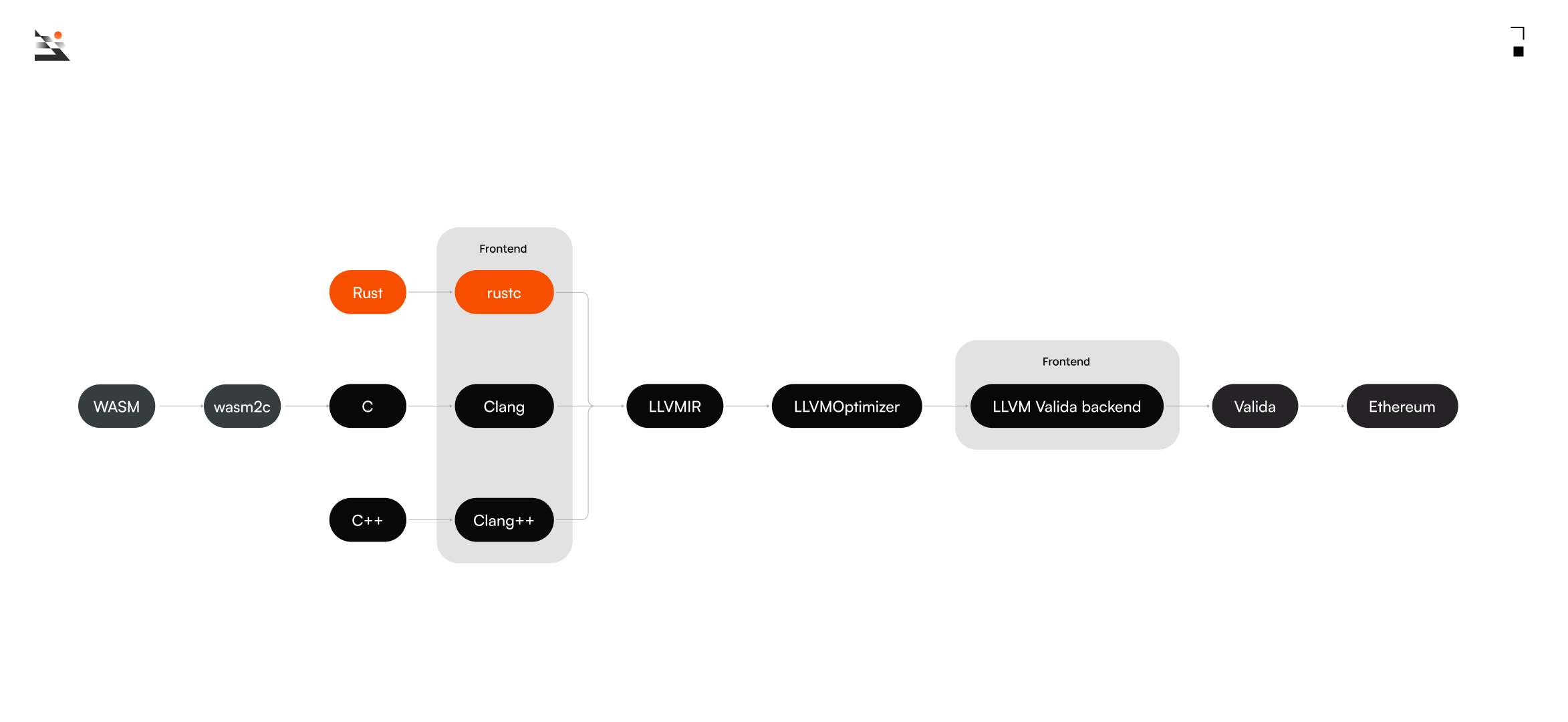
Valida 编译器工具链
可以提出一个支持 RISC-V 而不是 Valida 的论点,即 RISC-V 的编译器技术更加成熟。虽然这是事实,但 Lita 的用于 Valida 的 C 和 Rust 编译器工具链相当成熟。它具有广泛的测试套件,包括 Rust 标准库测试套件的相关部分。此外,Lita 编译器工具链中的大多数代码不是 Valida 特有的,也不是由 Lita 创建的。Lita 的 Valida 编译器工具链基于开源代码构建,特别是 LLVM 和官方 Rust 编译器工具链。这些代码库包含数百万行代码。与非 Valida 特有的部分相比,工具链中特定于 Valida 的部分非常小。此工具链的高度复杂性在代码生成中造成了很高的潜在 bug。但是,此问题并非 Valida 特有;大多数相同的代码也用于编译代码以针对 RISC-V 和其他主要处理器架构。此外,有问题的开源代码经过了广泛的测试并被广泛使用,并且有很多人关注它,所有这些都减轻了代码生成中出现错误的可能性。
- 原文链接: lita.foundation/blog/opt...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
- 翻译
- 学分: 0
- 分类: 以太坊
- 标签: Valida ISA 以太坊虚拟机(EVM) RISC-V SNARK 简洁证明 执行环境





