Efficient Attention 机制详解:线性时间Transformer背后的数学原理
- lambdaclass
- 发布于 2025-10-14 11:29
- 阅读 1094
本文深入探讨了Transformer架构中的Attention机制,重点介绍了通过数学技巧优化其复杂度的线性Attention方法。文章详细解释了原始Attention的计算方式及其复杂度瓶颈,并阐述了Efficient Attention的核心思想,即通过近似计算softmax函数来降低计算和存储需求,最后通过代码和基准测试展示了Efficient Attention的优势与局限。
介绍
Transformer 架构的关键组成部分之一是 Attention 层,它负责使每个词(或更笼统地说,每个 token)学习序列中每个其他词给出的上下文,并在开创性论文 Attention is all you need 中被引入。在这篇文章中,我们将探讨这个公式,以及一种通过一些数学技巧将其复杂度改进为线性的特定方法,遵循 Shein et al. (2021) 的工作。
原始 Attention 的工作原理
关于原始 Attention(也称为点积 Attention)实现的信息有很多,所以我们只对其进行快速回顾。这一切都归结为一堆带有归一化函数的矩阵乘法。确切的数学公式是
$Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V$
其中,
- $Q \in \mathbb{R}^{N \times d_q}$,是输入序列在查询空间上的投影
- $K \in \mathbb{R}^{N \times d_k}$ 是输入序列在键空间上的投影
- $V \in \mathbb{R}^{N \times d_v}$ 是输入序列在值空间上的投影
- $N$ 是序列(或 上下文)长度,即输入的最大大小
- $d_q, d_k$ 和 $d_v$ 是每个投影空间的维度
$Q$ 和 $K$ 矩阵都必须具有相同的嵌入维度,因此我们可以假设 $d_k = d_q$,并且不失一般性,我们可以简单地认为 $d_q = d_k = d_v = d$。
softmax 函数通过将任意实数数组的每个元素映射到范围 (0,1) 中来工作 - 这就是它对于给定输入元素的样子:
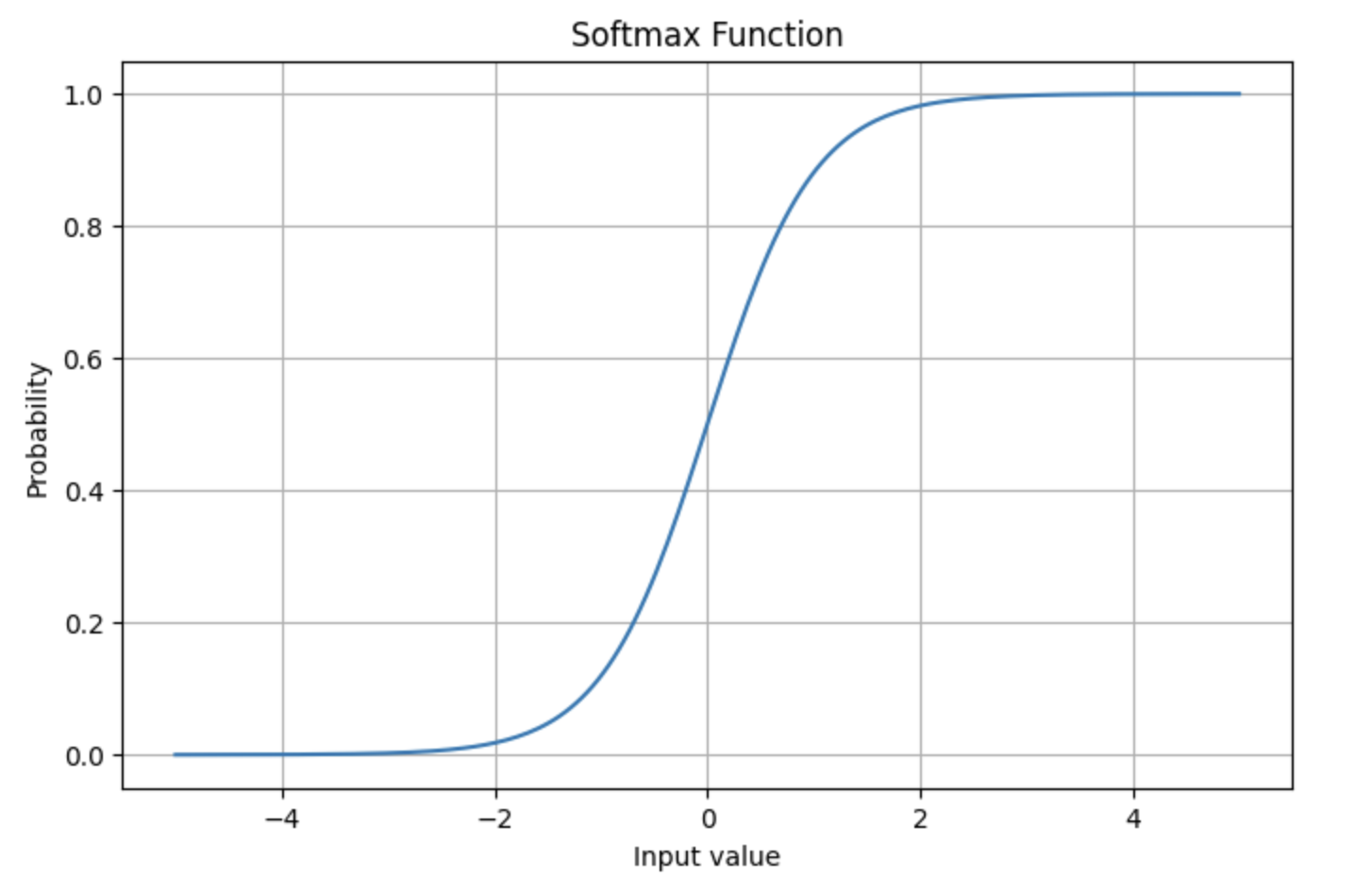
$\sqrt{d_k}$ 缩放因子的存在是为了防止 softmax 函数饱和 – 随着 $d_k$ 变大,$QK^T$ 中的点积在幅度上变得更大,将 softmax 函数推入到基本平坦的区域,因此具有极小的梯度。当使用反向传播进行训练时,这可能会变成稳定性问题、缓慢的训练,甚至使一些参数在整个训练过程中完全冻结。
我们使用 softmax 函数从 attention 分数($QK^T$ 矩阵乘法的结果)转换为将乘以 $V$ 矩阵的 attention 权重。attention 权重可以解释为每个 token 对序列中其他 token 的影响程度。如果一对 token 之间的 attention 权重很高,那么我们说一个 关注 另一个。
例如,从基本的英语语法中,我们知道在句子
仿生机器人会梦见电子羊吗?
单词 羊 比单词 会 更关注 电子。
深入了解 Attention 复杂度
Attention 机制的主要缺点之一是计算资源相对于序列长度 $N$ 的扩展方式。在 Attention 函数的定义中,我们可以看到 $Q$ 和 $K$ 中向量之间的相似度计算,由 $QK^T$ 给出。从基本的矩阵乘法中我们知道,
$(\mathbb{R}^{N \times d} \times \mathbb{R}^{d \times N}) \rightarrow \mathbb{R}^{N \times N}$
这意味着我们最终必须存储一个 $N \times N$ 矩阵,因此具有 $O(N^2)$ 内存复杂度。另一方面,此矩阵乘法总共需要 $O(d_kN^2)$ 次运算,因此我们可以清楚地看到,随着序列长度变大,资源需求会迅速扩展。
本质上,原始的 attention 架构确实受到我们可以使用的序列长度的限制,使其对于需要更大上下文的情况不可行。人们一直在努力优化原始的 Attention 机制,我们将重点关注一种因其方法的简单性而真正脱颖而出的机制,同时考虑其一些权衡。
高效Attention
由于扩展问题源于必须计算和存储 $N \times N$ 矩阵作为计算中的中间值,因此如果我们能够以某种方式分段应用 softmax,我们可以获得更简单的中间值。如果我们分别对 $Q$ 的行和 $K$ 的列应用 softmax,然后 再 进行乘积,我们可以避免存储整个矩阵。由于我们不再在此近似中执行点积,因此我们也不需要比例因子 $\sqrt{d_k}$。
因此,由 Shen et al. (2021) 提出的高效 Attention,由下式给出:
$E(Q,K,V)=softmax{row}(Q)softmax{col}(K)^TV$
其中现在我们区分 $softmax{row}$ 和 $softmax{col}$,其中我们分别在矩阵的行和列中应用 softmax 函数。通常,如果没有指定,则假定为 $softmax_{row}$ 版本。
这个技巧归结为摆脱了对 $QK^T$ 结果应用 softmax 函数 - 有点像将 softmax 函数分配到 $Q$ 和 $K$ 中,但需要注意的是,这实际上不是 softmax 函数的数学属性,而是一种近似。这样,我们可以按照对我们有利的方式排列此表达式中矩阵乘法的顺序,从而使得到的计算效率更高。
如果我们首先计算 $softmax_{col}(K)^TV$,则必须存储一个 $d \times d$ 矩阵,这意味着 $O(d^2)$ 内存复杂度,并且需要 $O(Nd^2) \approx O(N)$ 计算,其中 $d \ll N$。由于与 $N$ 的依赖关系,此 attention 实现有时被称为 线性 Attention。
考虑到在任何实际情况下 $d < N$,效率的提高变得显而易见,并且随着我们使上下文长度越来越大,这种差异也会增大。
重申一下,这种新的 Attention 机制的数学表达式是一种 近似,因为应用于 $Q$ 和 $K$ 的两个 softmax 运算不等同于 $QK^T$ 上的单个 softmax。两种变体共享的核心属性,也是使近似合理的原因是,$softmax{row}(QK^T)$ 和 $softmax{row}(Q)softmax_{col}(K)^T$ 的行之和都等于 1。
对于某些上下文长度 $N$ 可能很大的应用,这种近似足够好。这方面的一个例子是计算机视觉领域,其中输入 token 可能表示图像的像素。其他示例包括音频和基因组学,其中输入长度可能达到数百万。
有效 Attention 的可解释性
当尝试理解这种变化在 LLM 上下文中意味着什么时,我们可以将标准 attention 机制视为查询矩阵中的所有元素询问键矩阵中的所有元素应该注意什么的过程。这是一个迭代过程,用于获取一个单词(查询元素)与同一句子中的其余单词(键元素)之间的相关性。我们本质上是在做:
$s_{ij} = Q_iK_j^T$
对于输入序列中的所有 j。每个 $s_i$(位置 i 的全套分数)都称为 attention 图,因此我们创建 $N$ 个这样的 attention 图(每个 $N$ 输入位置一个)。
高效 Attention 机制创建的 attention 图不遵循有关查询的位置信息,而是引用整个输入的更一般的方面。我们没有让每个查询都有自己的 attention 图来检查与每个其他元素的相关性,而是创建了包含捕获一般语义主题的信息的 全局 attention 图。
这些图是从键 $K$ 派生的,但它们不再依赖于特定位置。它们表示为 $k_j^Tk_j^T$,当乘以值矩阵中的元素时,我们得到 $d_k$ 向量,表示为 $g_i$。然后,每个查询都使用系数来混合这些全局主题,而不是关注各个位置。
让我们看一个实际的玩具示例,其中包含一些随机数,以清楚地了解差异:
假设我们有句子 “能力越大,责任越大”,其中包含 N = 6 个 token 且 $d_k=4$(因此我们将生成 4 个全局 attention 图)。
在 点积 Attention 中,6 个 token 中的每一个都会在其所有 6 个位置上创建自己的 attention 图:
Token 3 (“能力”) 创建一个 attention 图 $s_3$:
$s_3 = [0.08, 0.45, 0.15, 0.20, 0.05, 0.07]$
这告诉“能力”强烈关注位置 2 (“越大”),适度关注位置 4 (“责任”)。我们得到了输出:
$output_3 = 0.08 \cdot V_1 + 0.45 \cdot V_2 + 0.15 \cdot V_3 + 0.20 \cdot V_4 + 0.05 \cdot V_5 + 0.07 \cdot V_6$
Token 4 (“责任”) 创建了它自己单独的 attention 图 $s_4$:
$s_4 = [0.05, 0.12, 0.38, 0.10, 0.08, 0.27]$
这告诉“责任”强烈关注位置 3 (“能力”) 和 6 (“越大”)。我们得到输出:
$output_4 = 0.05 \cdot V_1 + 0.12 \cdot V_2 + 0.38 \cdot V_3 + 0.10 \cdot V_4 + 0.08 \cdot V_5 + 0.27 \cdot V_6$
类似地,所有 6 个 token 各自创建自己的 attention 图。总计:6 个 attention 图,每个大小为 6。
在 高效 Attention 中,我们可以创建例如 4 个全局语义 attention 图 来捕获整个句子中的主题,而不是特定于位置的 attention 图。在语言上下文中,此输入句子的这些全局图的示例可能是:
-
修饰语主题:该模型对 越大 修饰 能力 和 责任 这一事实进行编码。
- “越大” → “能力”
- “越大” → “责任”
- 因果关系主题:这编码了整体的因果/命题结构
- “能力” → “责任”
- “能力…” → “责任…”
- 谓词主题:将 token 映射到主要谓词。这减少了模型将动词发现为组织节点的需求 - 该图强制执行它。
- 所有单词都指向主要动词“责任”
- 平行 - 类比主题:高亮显示配对概念之间的对称性
- “能力” ↔ “责任”
- 两者都被视为相似重要性的抽象名词
$k_1^Tk_1^T$ (修饰语主题):$[0.10, 0.85, 0.15, 0.10, 0.85, 0.20]$ → 创建 $g_1$
$k_2^Tk_2^T$ (因果关系主题):$[0.05, 0.10, 0.90, 0.05, 0.10, 0.88]$ → 创建 $g_2$
$k_3^Tk_3^T$ (谓词主题):$[0.20, 0.05, 0.10, 0.95, 0.05, 0.10]$ → 创建 $g_3$
$k_4^Tk_4^T$ (平行-类比主题):$[0.90, 0.15, 0.20, 0.15, 0.10, 0.10]$ → 创建 $g_4$
每个 $g_i$ 是所有值向量 $V_j$ 的加权总和,使用相应的全局图权重。
每个 token 混合这 4 个全局主题:
Token 3 (“能力”) 带有 $q_3 = [0.30, 0.20, 0.10, 0.40]$
$output_3 = 0.30 \cdot g_1 + 0.20 \cdot g_2 + 0.10 \cdot g_3 + 0.40 \cdot g_4$
Token 4 (“责任”) 带有 $q_4 = [0.10, 0.25, 0.40, 0.25]$
$output_4 = 0.10 \cdot g_1 + 0.25 \cdot g_2 + 0.40 \cdot g_3 + 0.25 \cdot g_4$
在这里,只有所有 token 共享的四个全局图,每个 token 都选择它应该关注哪些主题,而不是关注句子中的每个其他单词。主题的数量和组成以及它们的选择方式只是这个示例的一部分。
迷失在大局中
虽然高效 Attention 提供了显着的计算优势,但它带来了一个重要的权衡:它失去了对特定位置的敏锐关注能力,而是专注于粗略的全局特征。让我们用一个实际的例子来演示这种限制。
在此示例中,我们将比较 $softmax(\frac{QK^T}{\sqrt{d_k}})$ vs $softmax(Q) \cdot softmax(K)^T$ 生成的 attention 分数。虽然高效 Attention 实际上首先计算 $softmax(K)^T \cdot V$ 以实现其效率提升,但最终的 attention 分布保持不变。直接检查分数有助于我们可视化和理解 attention 模式发生的情况。
回想一下线性代数中,两个向量的点积与它们的相似性有关:
$a \cdot b = |a| \cdot |b| \cos(\theta_{ab})$
当向量紧密对齐时,它们的点积很大。
在下面的示例中,我们有一个查询向量和四个键向量。请注意,第三个键与我们的查询相同,因此我们应该期望它获得大部分 attention:
$q = [2, 1, 3]$
$k_1 = [1, 0, 1], k_2 = [0, 1, 0], k_3 = [2, 1, 3], k_4 = [1, 1, 0]$
对于标准点积 Attention 的情况,
$AttnWeight_1 = softmax(\frac{q \cdot k_1}{\sqrt{3}}) = 0.005$
$AttnWeight_2 = softmax(\frac{q \cdot k_2}{\sqrt{3}}) = 0.001$
$AttnWeight_3 = softmax(\frac{q \cdot k_3}{\sqrt{3}}) = 0.992$
$AttnWeight_4 = softmax(\frac{q \cdot k_4}{\sqrt{3}}) = 0.002$
正如我们所期望的那样,位置 3 几乎获得了所有的 attention。
我们现在对高效 Attention 的情况重复相同的计算。为了简化此处的计算,我们将使用矩阵公式,其中 $K$ 是通过将向量 $k_i$ 设置为行创建的矩阵。
$softmax(q).softmax_{col}(K)^T = [0.1309, 0.0713, 0.6962, 0.1017]$
权衡很明显:通过在计算相似性之前应用 softmax,高效 Attention 使 attention 分布平滑。它没有敏锐地关注最相关的位置 (3),而是更均匀地在所有位置上分配 attention。这种扁平化效应是为什么该机制有时被描述为捕获广泛的语义主题而不是精确的位置关系的原因。
这种限制解释了为什么最先进的语言模型仍然更喜欢标准 attention,尽管它的二次成本;精确地关注特定 token 的能力对于许多语言理解任务至关重要。但是,尽管高效 Attention 在 LLM 中不常用,但它对于其他领域的人工智能模型仍然非常有价值。在诸如计算机视觉之类的应用中,其中输入表示图像中的像素,该模型仍可以使用此类 attention 机制表现良好,从而使巨大的效率提升值得权衡。
代码实现和基准
为了大致了解高效 Attention 在计算资源方面的改进,我们将针对 $N$ 的某些值运行比较,以及每种 Attention 实现如何随着它的增加而扩展。
我们将看到使用 PyTorch 实现这些函数以及将它们用作 LLM 中的一层是多么容易。
import torch
def dot_product_attention(Q, K, V):
attn_scores = torch.matmul(Q, K.T) # N x N
attn_weights = torch.softmax(attn_scores, dim=-1) # N x N
return torch.matmul(attn_weights, V) # N x d
def efficient_attention(Q, K, V):
Q_smr = torch.softmax(Q, dim=-1) # N x d
K_smc = torch.softmax(K, dim=-2) # N x d
KV = torch.matmul(K_smc.T, V) # d x d
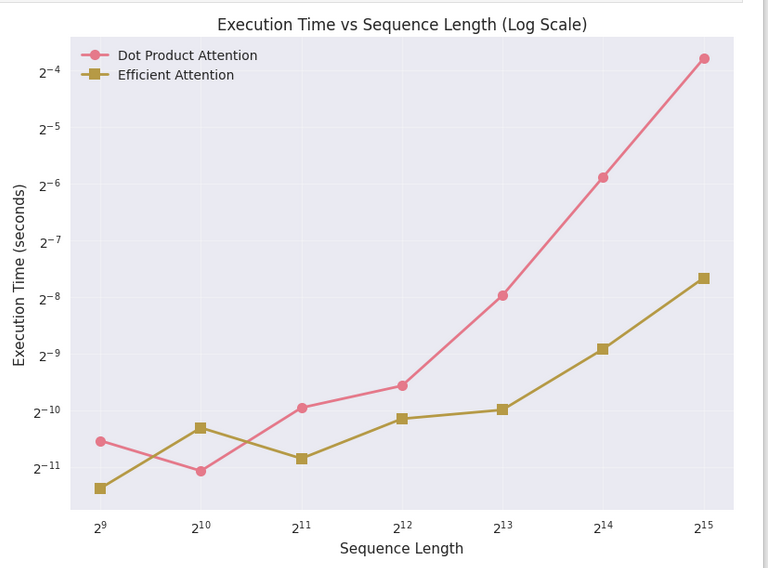
return torch.matmul(Q_smr, KV)在下面,你可以看到对于序列长度 $N$ 的不同值,两种 Attention 实现的执行时间的比较。
作为参考,这些基准测试是在具有以下规范的机器上运行的:
- GPU: NVIDIA RTX A4000 (16 GB)
- OS: Ubuntu 22.04 LTS (Kernel 5.15.0-157)
- CPU: 8 × Intel(R) Xeon(R) Gold 5315Y @ 3.20 GHz
同样,下面是内存资源的比较
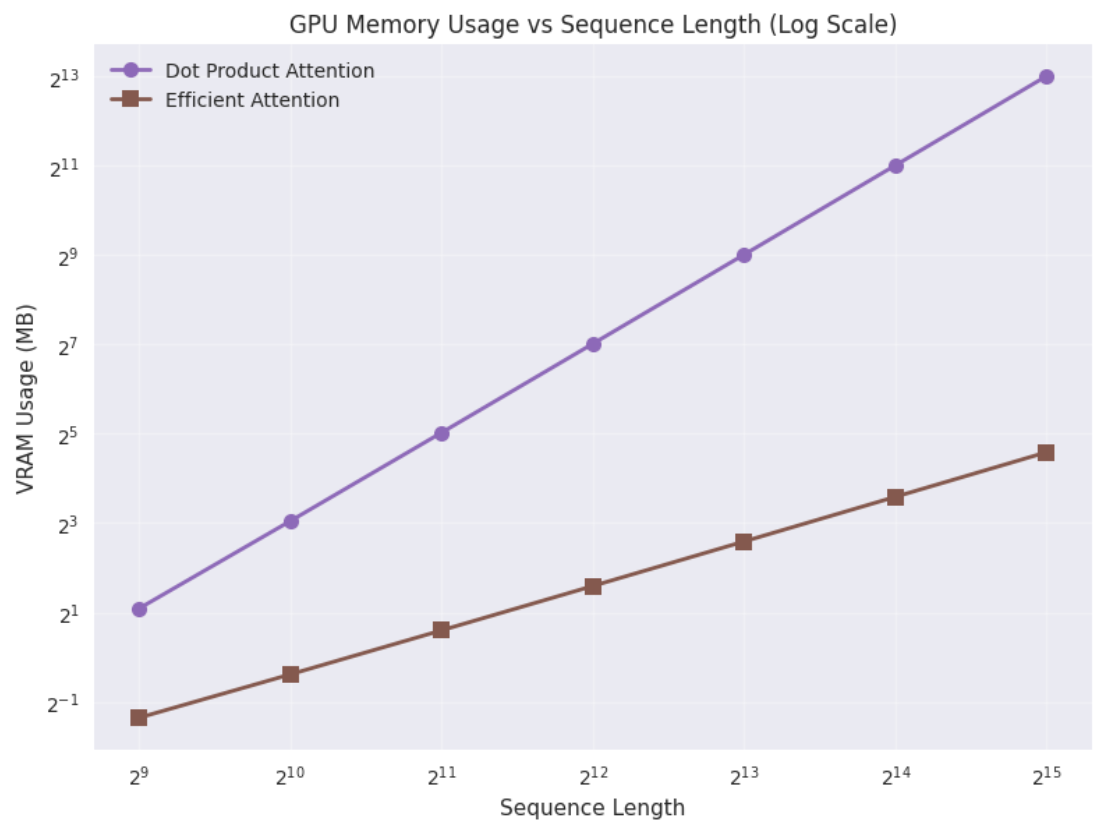
可以看出,最开始,两者的内存和性能相似(尽管对于线性 attention 实现更好),但对于更大的序列长度,原始实现的时间和内存需求呈指数增长(图表采用对数-对数比例,因此更大的斜率意味着更大的指数),而高效 Attention 实现则不然。
你可以看到用于基准测试的代码。
相同的存储库还包括遵循 GPT 架构的完整的 Transformer 实现,其中包含一个配置选项,可以在 高效 Attention 和 原始点积 Attention 之间切换,从而提供了更广泛的视角来了解所有内容如何组合在一起。
结论
已证明,高效 Attention 在内存和性能方面比通常的点积 Attention 更高效,由于其与它的线性依赖性,因此可以处理更大的上下文。那么,为什么它们没有得到更广泛的采用呢?最先进的模型宁愿支付高昂的训练成本,以在竞争中获得微小的优势。
但是,高效 attention 实现对于视频生成或基因组学等领域仍然很重要,在这些领域中,上下文大小本质上会变得非常大。
在这篇博文中,我们介绍了线性化 attention 的原始和最简单的实现;但是,这是一个不断发展的领域,已经出现了新的和改进的实现,例如 CosFormer、LinFormer 和 Mamba。一些现代架构也采用混合方法,混合标准和高效 attention 头来平衡准确性和稳定性。
参考
- 高效 Attention 论文
- https://github.com/lucidrains/linear-attention-transformer
- https://www.youtube.com/watch?v=LgsiwDRnXls
- https://cmsflash.github.io/ai/2019/12/02/efficient-attention.html
- 原文链接: blog.lambdaclass.com/eff...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
- 翻译
- 学分: 11
- 分类: AI
- 标签: Attention机制 Transformer 线性Attention Efficient Attention Softmax函数 复杂度分析





