你不知道的大模型训练:原理、路径与新实践
- hitw93
- 发布于 1小时前
- 阅读 16
文章深入剖析了当代大模型训练的全链路流程,强调后训练阶段(如强化学习、数据配方、评测奖励机制)在提升模型用户体验中的核心作用。重点介绍了从预训练底座到推理模型及Agent训练的演进路径,并结合DeepSeek、Kimi等前沿案例分析了系统架构与工程实践的最新趋势。

核心观点总结
在 2026 年,大模型效果的差距已不再仅仅取决于预训练本身,而更多地取决于其后的整条训练栈:后训练、评测、奖励机制、Agent 训练及蒸馏。每一个步骤都在深刻影响用户的实际体验。当你发现某个模型突然变强时,背后通常是多重因素协同优化的结果。
本文将按大模型训练链路的顺序,重点探讨厂商如何通过后半段训练栈来提升最终的上线效果。
大模型训练其实是一条流水线
过去几年,人们习惯用参数、数据和算力的堆积来解释模型进步。但实际上,用户感受到的提升往往来自预训练之后的流程。模型如何说话、听从指令、进行推理或使用工具,这些能力并非单纯通过喂养互联网文本就能自然产生。
InstructGPT 曾提供过一个直观案例:一个仅有 1.3B 参数但经过对齐和偏好优化的模型,在人类偏好评测中能击败 175B 的 GPT-3。这证明了训练的后半段能极大地改写用户感知。
训练过程是一条高度耦合的流水线,数据、算法、系统与反馈紧密相连。2026 年的模型能力和产业价值,正越来越集中在预训练之后的几层。
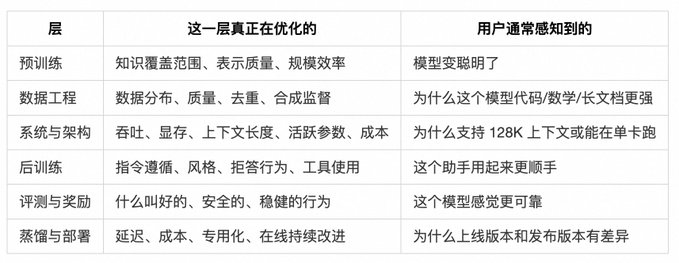
下图展示了更详细的九个阶段:将原始数据和系统配方独立拆分,并将 Agent harness 和 Deployment 作为后半段的细分环节。同时,两条反馈回路贯穿始终:生产流量回流至数据工程,离线评测结果回馈至预训练。
预训练:构建模型底座
预训练是训练链路的起点,决定了模型的语言建模能力、知识压缩水平及能力迁移空间。它的核心任务是将语言分布学进去,把大规模文本中的知识模式压入参数。
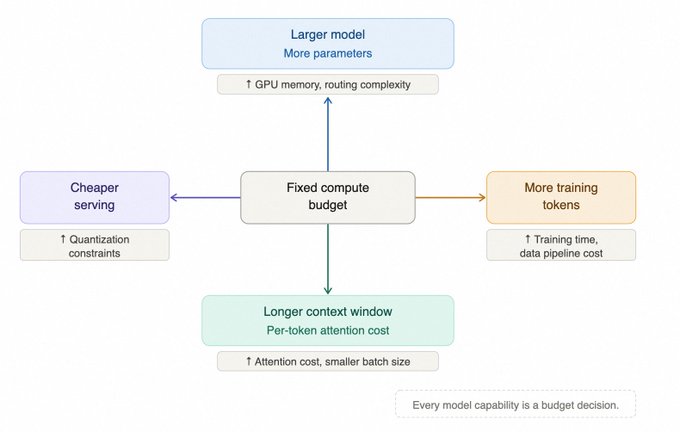
规模定律与预算分配
在 GPT-3 之后,模型调优更注重预算与配比。模型并非越大越好,参数量、训练 Token 数与总计算预算之间存在最优配比。规模定律(Scaling Laws)在实际决策中更像是一个预算分配工具,帮助开发者决定在有限的 GPU 预算下,是该增加参数还是多喂数据。
预训练决定了地基的稳固程度,但它无法控制模型是否听从指令或在关键任务中是否稳定。
预研与取舍
Tokenizer 的切分方式、上下文窗口(Context Window)的长度、是否进行多模态预训练等,这些决策在预训练阶段就已定型。例如,Gemma 3 强调的单加速器运行、128K 上下文及视觉能力,都是在训练初期就写进配方的取舍。
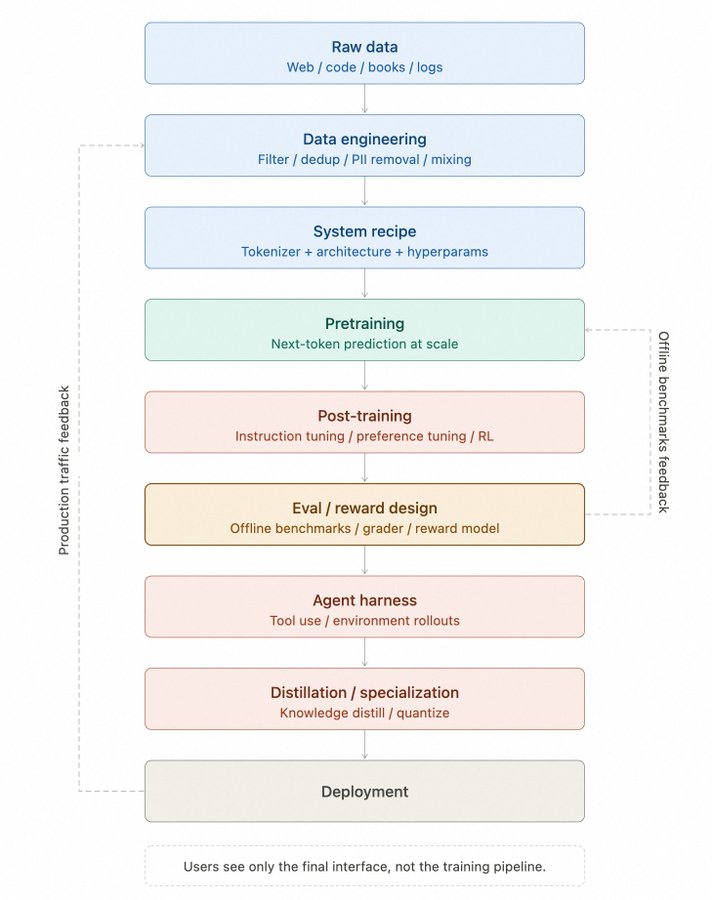
根据 Chinchilla 研究,8B 参数模型的最优点约为 200B tokens,但 Llama 3 8B 实际使用了 15T tokens,这种“过训练”配方能在同等参数下换取更高的能力密度,从而获得更小、更高效的模型。
此外,Tokenizer 的词表大小也会影响性能。Llama 3 将词表扩至 128K 后,序列长度压缩了约 15%,提升了推理效率和多语言能力。
数据配方:决定模型能力的核心
“数据配方”已成为比参数规模更重要的指标。这不仅是清洗数据,而是一项完整的数据生产工程,包括文本抽取、语言识别、质量过滤、隐私处理、安全过滤及去重。
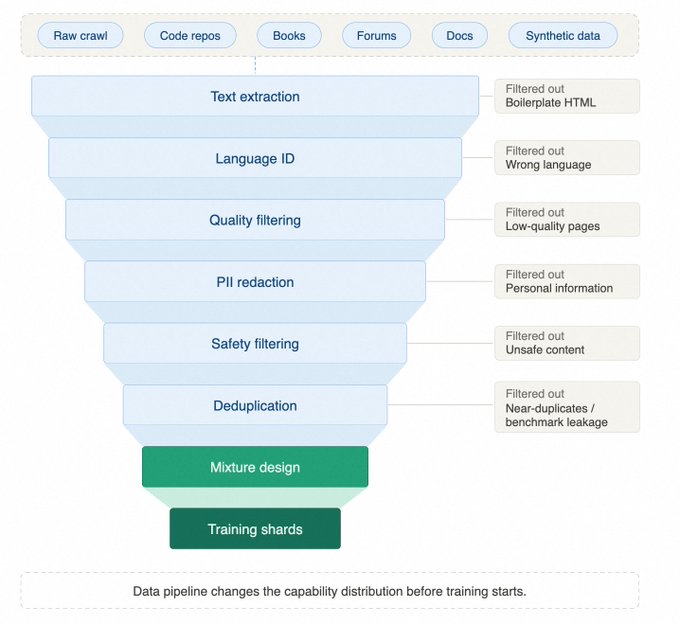
数据工程与配比
数据工程决定了模型的能力分布。去重和污染控制至关重要,如果处理不当,模型会反复吸收低价值的重复内容。目前,Data Mixing Laws 专注于研究不同类型数据占比对模型能力结构的影响。
合成数据与能力压缩
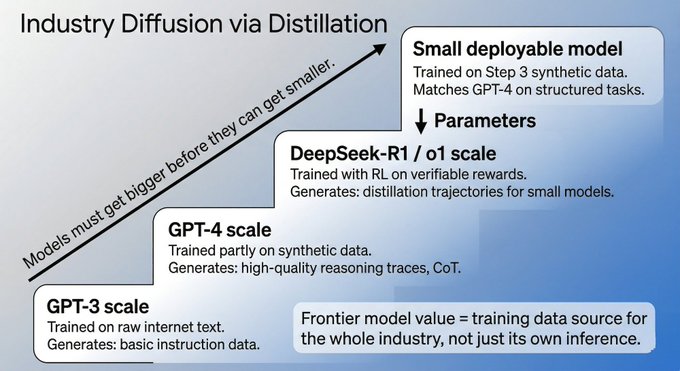
合成数据已成为正式流程。通过 Self-Instruct 等方法,每一代更强的模型都在参与重构下一代模型所看到的数据。例如,DeepSeek-R1 通过强化学习(RL)产生的推理轨迹,可以蒸馏给更小的模型,使其获得显著收益。这种“先在大规模模型上形成能力,再压缩至小模型”的路径已成为主流。
系统与架构:训练前的硬约束
大模型训练本质上是分布式系统问题。GPU 数量、显存带宽、并行策略及容错成本,在训练开始前就决定了模型的大小、上下文长度及后训练的复杂程度。
架构选择与折中
MoE(混合专家模型)是典型的系统折中方案,它在保持激活成本受控的同时扩大了总参数量。DeepSeek-V3 和 Qwen 的 MoE 设计都是基于成本与效果的平衡。
工程细节与稳定性
现代训练报告中开始出现更多细节:如 muP(超参迁移)、WSD 学习率调度策略等。算力预算是固定的,开发者必须在模型大小、Token 量、上下文长度和推理成本之间做取舍。
在大规模训练中,快速检测并恢复 Loss Spike(损失突增)或硬件故障是核心工程能力。DeepSeek-V3 成功验证了 FP8 混合精度训练在超大规模模型上的可行性,且全流程无回滚。
后训练:决定用户体验的关键
用户感受到的提升大多来自后训练阶段。
指令微调与偏好优化
指令微调(SFT)改变了模型的回答方式,使其更像一个配合的助手。RLHF(强化学习)、DPO(直接偏好优化)和 RFT(强化微调)则将“什么是更好的回答”接入训练回路。
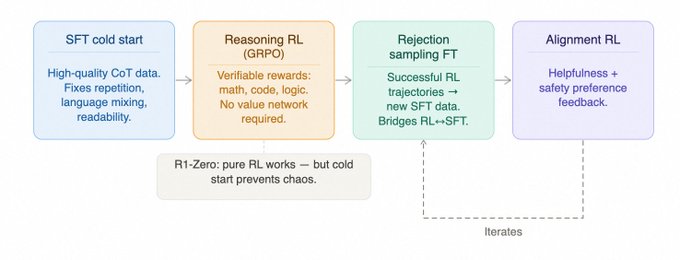
DeepSeek-R1 的四阶段流水线
- 冷启动 SFT:使用少量高质量思维链(CoT)数据为 RL 提供稳定起点。
- 可验证领域 RL:在数学、代码等领域使用 GRPO 算法,以正确性作为奖励信号。GRPO 相比 PPO 减少了维护价值网络的工程负担。
- 拒绝采样微调:将 RL 产生的好轨迹过滤后转为新的 SFT 数据。
- 偏好反馈对齐:融入安全性和有益性反馈,完成行为收敛。
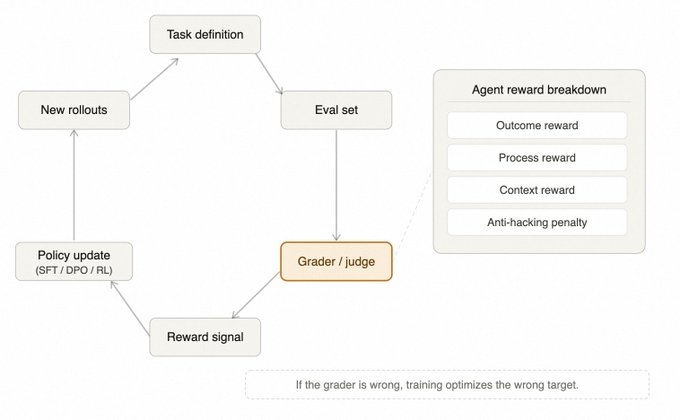
Eval、Grader 与 Reward:重新定义目标
Grader(打分组件)决定了模型优化的方向。如果打分规则存在漏洞,模型可能会学会“钻空子”(Reward Hacking)而非真正解决问题。
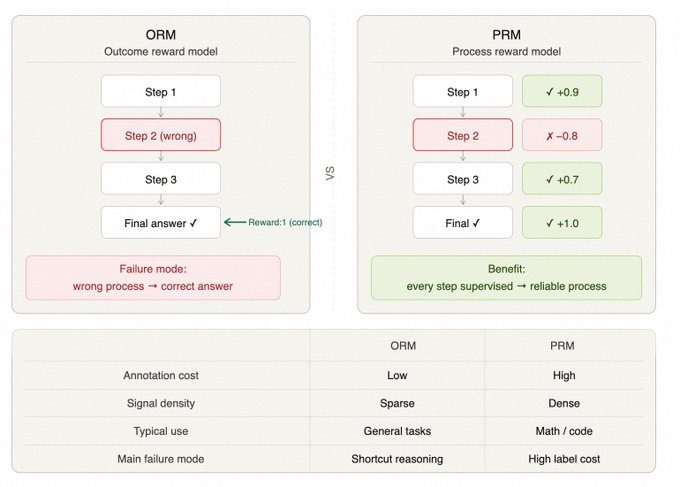
过程奖励与结果奖励
- ORM(结果奖励模型):只给最终答案打分,信号稀疏但成本低。
- PRM(过程奖励模型):给中间步骤打分,信号密集,能有效约束推理过程,但标注成本高。
自动化与 AI 反馈
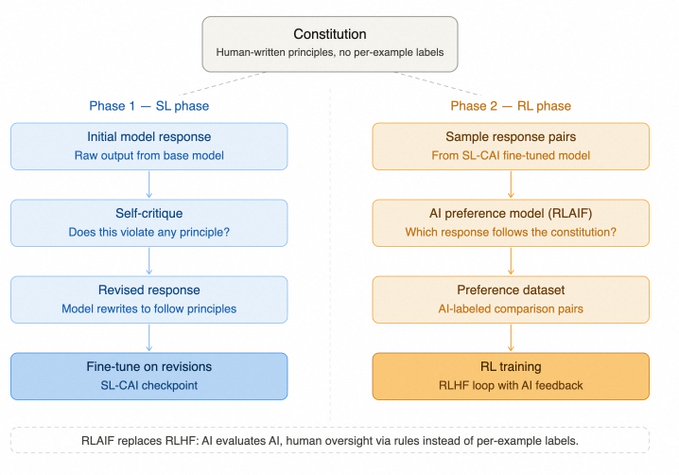
Anthropic 的 Constitutional AI 利用 AI 反馈替代人工偏好,而 OpenAI 的审慎对齐(Deliberative Alignment)则让模型在推理阶段自行判断安全规范。
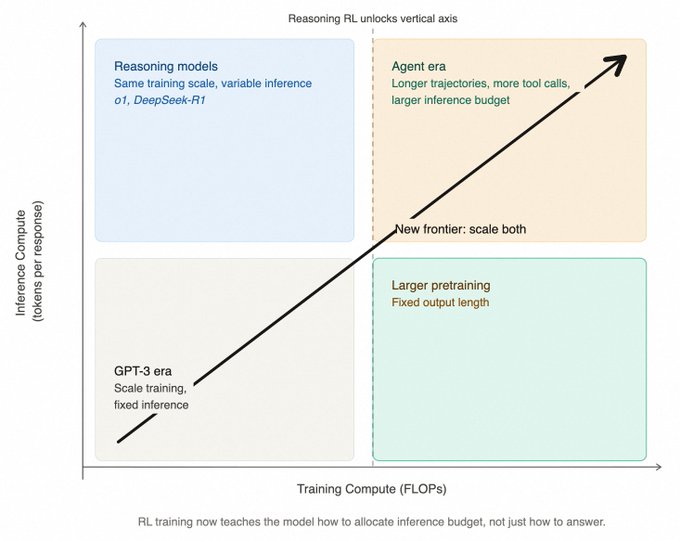
Agent 训练:从模型到系统的进化
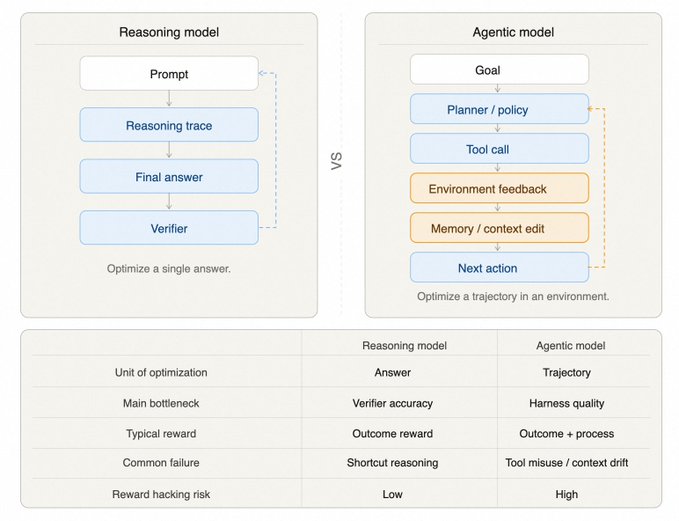
随着推理模型的成熟,训练对象已从单纯的对话模型转变为能规划、调用工具并接收反馈的 Agent 系统。
Harness 的重要性
Harness 是包在模型外层的控制程序。在 Agent 时代,环境质量(稳定性、真实性、反馈丰富度)成为核心。如果环境不稳定,模型学到的将是利用漏洞而非能力。
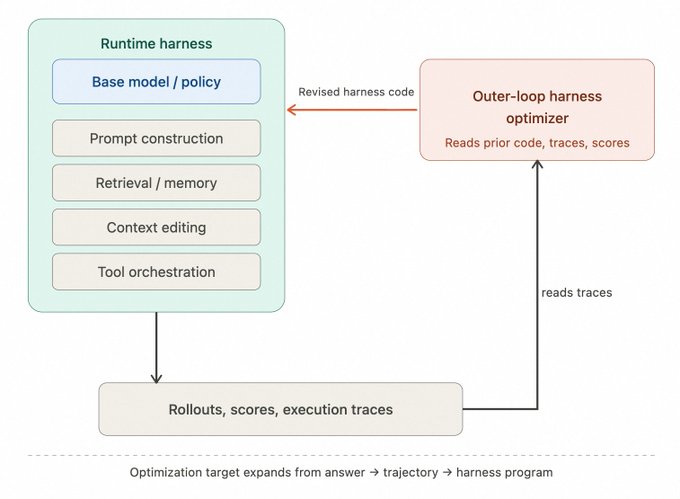
案例:Kimi K2.5 与 Meta-Harness
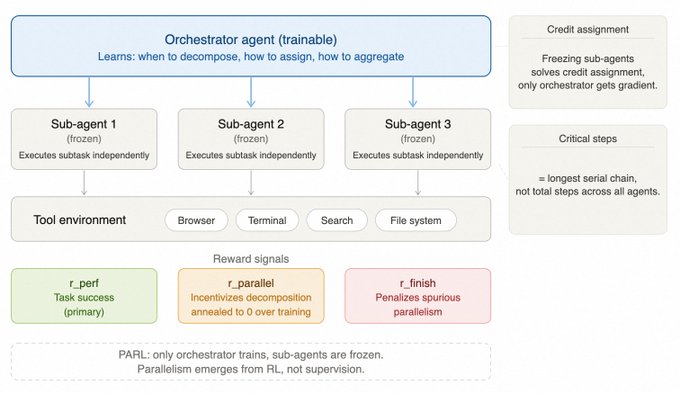
- Kimi K2.5:通过 PARL 解决并行拆解问题,重点优化编排层。
- Meta-Harness:不仅优化模型权重,还优化外层的 Harness 代码。实验证明,仅通过优化 Harness,在同一底模上就能拉开巨大的性能差距。
模型发布后的持续演进
发布后的模型并非终点。大模型通过蒸馏将能力迁移给小模型,实现能力解耦。同时,上线版本的选择往往是基于成本、延迟和稳定性的产品决策,而非单纯追求最高指标。
如何判断模型为何变强
未来评估模型时,可以从以下三个维度观察:
- 变化层级:是来自底层的预训练,还是后半段的训练流程优化?
- 提升来源:是权重配方、奖励机制,还是外层的 Harness 代码?
- 优化目标:该版本是在追求能力上限,还是在优化成本、延迟或特定场景的专用化?
学习资料
- Hoffmann et al. (2022). Training Compute-Optimal Large Language Models (Chinchilla).
- Ouyang et al. (2022). Training language models to follow instructions with human feedback (InstructGPT).
- Shao et al. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models (GRPO).
- DeepSeek-AI (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.
- DeepSeek-AI (2024). DeepSeek-V3 Technical Report.
- Llama Team, AI @ Meta (2024). The Llama 3 Herd of Models.
- Bai et al. (2022). Constitutional AI: Harmlessness from AI Feedback.
- OpenAI (2024). Deliberative Alignment: Reasoning Enables Safer Language Models.
- Anthropic (2025). Sycophancy to Subterfuge: Investigating Reward Tampering in Language Models.
- MacDiarmid et al. (2025). Natural Emergent Misalignment from Reward Hacking in Production RL.
- Lee et al. (2026). Meta-Harness: End-to-End Optimization of Model Harnesses.
- Kimi Team (2026). Kimi K2.5 Tech Blog: Visual Agentic Intelligence.
- Rush, S. (2026). A technical report on Composer 2.
- Chroma (2026). Chroma Context-1: Training a Self-Editing Search Agent.
- 本文转载自: x.com/hitw93/status/2040... , 如有侵权请联系管理员删除。





