Claude联动NotebookLM:突破Token限制的进阶指南
- hooeem
- 发布于 2小时前
- 阅读 13
本文介绍了通过开源工具 notebooklm-py 将 Claude Code 与 Google NotebookLM 集成的全攻略,旨在解决 Claude 的使用频率限制和 Token 成本问题。文章详细讲解了四种高效工作流:零成本文档研究、构建专家级 AI 技能、实现跨会话持久记忆以及结合 Obsidian 的可视化知识管理。
你是否厌倦了看到 “Claude usage limit reached. Your limit will reset at 7pm”?我也一样。这里有 4 个工作流,通过将沉重的文件分析任务卸载给 Google,将 Claude Code 与 NotebookLM 集成来绕过限制。
问题在于,Claude 的“健忘症”正在消耗你的 Token,让你每天只有 30–45 分钟的高效工作时间。我做了一些研究,找到了解决办法。
我们将学习一位名叫 Teng Ling 的开发者所逆向工程出的成果。
他逆向工程了 NotebookLM 的内部协议,并发布了一个名为 notebooklm-py 的开源 CLI 工具。它让你能够完全通过终端控制 NotebookLM:创建笔记本、上传来源、运行查询、生成幻灯片、播客、闪卡等等。
如果你将它与 Claude Code 的 Skill 系统相结合,你将获得一个真正强大的东西:一个拥有更大研究能力和跨会话持久记忆的 AI 编码 Agent。
本指南将向你展示如何通过各种工作流来设置它。
Claude Code 到底是什么
如果你只通过聊天界面使用过 Claude,那么 Claude Code 完全是另一回事。
它运行在你的终端中。它读取你的整个代码库。它编写文件、运行脚本、生成并行 Agent,并执行多步工作流,而无需你盯着每一个按键。
问题在于计费模式。
你提供给 Claude 的每一段 Context 都会消耗 Token。在 Pro 计划(20 美元/月)中,你会很快达到限制。在 Max 计划(100–200 美元/月)中,你有更多的余地,但繁重的研究任务仍然会耗尽它。在 API 模式下,每个 Token 都是计费的。
因此,如果你想让 Claude 分析 30 份文件、交叉引用发现并生成报告,那将是一个昂贵的下午。
这就是桥接器的用武之地。

NotebookLM 带来了什么
NotebookLM 是 Google 的 RAG(检索增强生成)研究工具。你上传文档,它会索引所有内容,然后让你一次性针对所有来源提出问题。
相关数据:
- 免费版:每个笔记本 50 个来源
- Pro 版:每个笔记本 300 个来源
- 成本:处理过程本身完全免费
它支持 PDF、网页链接、YouTube 视频、Google Docs、粘贴的文本、音频甚至图像。而且因为它基于你上传的来源,它不会像通用聊天机器人那样产生幻觉。
局限性:没有官方 API。它是一个仅限浏览器的工具。你无法通过脚本编写它、自动化它,也无法将其插入任何东西。
这正是 notebooklm-py 所解决的问题。
设置桥接器
你需要:Python 3.10+、一个 Google 账号和一个终端。它适用于 macOS、Linux 和 Windows。
访问这里并按照提供的说明操作:
https://github.com/teng-lin/notebooklm-py

教会 Claude Code 如何使用 NotebookLM
桥接器已安装。现在你需要让 Claude 知道如何使用它。
这是通过 Skill 完成的。
30 秒了解 Skill
Skill 是一组保存在名为 SKILL.md 文件中的指令,Claude 在遇到相关任务时会读取该文件。你可以把它看作是存储在你机器上的操作手册。当 Claude 检测到匹配的请求时,它会自动加载它。
Skill 遵循开放标准。它们可以在 Claude Code、Cursor、Gemini CLI、Codex 等工具中通用。它们不被特定供应商锁定。
Skill 存放的位置
- 个人 Skill:在所有项目中可用
- 项目 Skill:范围仅限于一个 Repo,可通过 Git 共享
如果两者同时存在,项目级 Skill 总是会覆盖个人级 Skill。
安装 NotebookLM Skill
这会将 Skill 部署到两个位置:
~/.claude/skills/notebooklm/用于 Claude Code~/.agents/skills/notebooklm/用于像 Codex 这样兼容的 Agent
一旦安装,Claude 就会理解如何通过 CLI 创建笔记本、上传来源、运行查询以及生成输出。你不需要在每个会话中都解释语法。
Claude 如何决定使用哪个 Skill
每个 Skill 的头部都有描述。Claude 在启动时会读取所有可用的描述,并将它们与你的请求进行匹配。
要求 Claude “研究 B2B 出站策略并编写报告”,它会自动调用 NotebookLM Skill。
你也可以直接调用它:
/notebooklm
构建你自己的自定义 Skill
这才是真正有意思的地方。
Anthropic 发布了一个 Skill 创建者的元 Skill。在 Claude Code 中调用 /skill-creator,它会对你进行访谈,了解你的需求,生成完整的 SKILL.md,对其运行自动化测试 Prompt,并打包结果。
你只需几分钟就能从“我想要一个实现 X 功能的 Skill”变成一个经过测试的可运行 Skill。无需手动格式化 YAML。无需凭空猜测。

四个让这一切值得设置的工作流
安装是无聊的部分。这些工作流才是真正价值所在。
工作流 A:零 Token 研究
问题:你希望 Claude 分析 30 多个文档。在本地执行会彻底耗尽你的 Token 预算。
解决方法:Claude 负责编排,NotebookLM 负责免费处理。
逐步操作
-
收集你的来源:PDF、网页文章、YouTube 转录文本等。如果你从 YouTube 获取,像
yt-dlp这样的工具会自动提取转录文本,Claude 可以为你运行它们。 -
Claude 创建一个笔记本。
-
Claude 上传所有内容。
免费版最多可上传 50 个来源。对于大多数项目来说绰绰有余。
-
Claude 查询 NotebookLM 而不是在本地处理。
Google 的 Gemini 引擎在所有上传的文档中处理查询,返回基于事实且带有引用的答案,且不消耗你的任何费用。
-
Claude 生成交付物。
直接下载到你的机器上。
-
Claude 润色输出。
它获取原始产出并在本地进行优化:编辑幻灯片、重新格式化表格、将发现整合到最终文档中。这是唯一使用你的 Claude Token 的部分。
计算过程:昂贵的分析工作发生在 Google 的基础设施上。Claude 的 Token 纯粹保留用于编排和最终编辑。你刚刚让每月 20 美元的计划完成了每月 200 美元工作流的任务。
工作流 B:通过网页研究构建专家 AI Agent
问题:你想为特定领域(例如 B2B 出站销售)构建一个自定义 AI Agent。但模糊的 Prompt 会产生模糊的 Agent。
解决方法:使用 NotebookLM 的 Deep Research 自动从网页收集专家知识,然后将其结构化为可部署的 Claude Code Skill。
逐步操作
-
在 NotebookLM 中运行 Deep Research。
在浏览器中打开 NotebookLM,选择“网页”来源类型,然后输入特定查询,例如:
“高级 B2B 多渠道出站销售策略、留存循环和重新激活序列。”
Deep Research 会自动抓取数百个页面,阅读文档和指南,并编写一份有引用支持的报告。
-
使用 DBS 框架结构化输出。
要求 NotebookLM 将发现整理到三个桶中:
- Direction (方向):分步逻辑、决策树、错误恢复。这成为你
SKILL.md的核心。 - Blueprints (蓝图):静态参考资料、模板、语音指南、分类规则。这些成为支持文件。
- Solutions (解决方案):需要确定性代码而非 AI 推理的任务,例如 API 调用、数据格式化和计算。这些成为捆绑脚本。
- Direction (方向):分步逻辑、决策树、错误恢复。这成为你
-
将其提供给 Skill 创建者。
复制 DBS 输出,将其粘贴到 Claude Code 中,并调用
/skill-creator。Claude 会自动搭建整个 Skill 包。 -
测试并部署。
Skill 创建者会使用生成的 Prompt 对你的新 Skill 进行压力测试,向你展示结果,并让你进行微调直到达成目标。
结果:你从一个模糊的概念变成了一个由经过验证的网页研究支持的、专家级的 AI Agent。不是用几小时,而是几分钟。

这是一个象征性的图像。
工作流 C:跨会话的持久化记忆
问题:你花了三个小时教 Claude 你的架构偏好、命名习惯和项目怪癖。你关闭了终端,一切都消失了。
解决方法:建立一个“总结 (wrap-up)”仪式,自动提取会话学习内容并将其存储在持久化的 NotebookLM 笔记本中,Claude 在未来每个会话开始时都会查询该笔记本。
逐步操作
-
安装一个
/wrap-upSkill,指示 Claude 审查当前会话并提取:- 你做出的修正
- 出现的成功模式
- 未解决的问题或功能请求
- 关键决策及其原因
-
配置它上传到 NotebookLM。
总结不再只是保存为本地文件,而是推送到一个专门的 “Master Brain” 笔记本中。
-
在关闭每个会话之抢跑
/wrap-up。Claude 审查对话,提取见解,格式化它们并上传。
-
在你的
CLAUDE.md中添加检索指令。这是 Claude 在会话开始时读取的配置文件。添加如下内容:
在回答关于项目架构、历史决策或我的偏好的问题之前,请使用 NotebookLM CLI 查询 Master Brain 笔记本。
-
Claude 现在拥有了记忆。
几周下来,Master Brain 积累了数百个会话摘要。NotebookLM 对它们进行全部索引并映射语义关系。Claude 可以为任何问题检索出完全正确的 Context,而无需将数百个文档加载到它自己的 Context 窗口中。
结果:你的 AI Agent 有效地记住了所有内容。存储和检索发生在 Google 的免费基础设施上。你的 Token 预算保持完好。
工作流 D:使用 Obsidian 进行可视化知识管理
问题:Claude 生成研究文档、会话摘要和分析文件。它们像隐形文件一样堆积在终端目录中。你无法浏览、搜索或连接它们。
解决方法:在 Obsidian Vault 内部运行 Claude Code,这样它创建的所有内容在可视化知识图中立即可见。
什么是 Obsidian?一个完全运行在本地 Markdown 文件上的免费笔记应用。它将你的笔记显示为一个带有链接节点的交互式图形。它在个人知识管理方面非常受欢迎。
逐步操作
-
从你的 Vault 根目录启动 Claude Code。
Claude 获得了对你整个笔记收藏的完整读/写访问权限。
-
在 Vault 根目录创建一个
CLAUDE.md。这是 Claude 操作你 Vault 的手册。定义:
- 文件夹结构
- 新笔记所需的元数据
- 链接规则,例如将重要概念包装在双括号中,如
[[this]],以便在 Obsidian 的图形视图中显示 - 你偏好的笔记风格的格式标准
-
为 Vault 操作构建自定义 Skill。
/research <topic>:Claude 查询 NotebookLM,下载结果,并创建一个带有正确元数据和交叉链接的 Vault 笔记。/daily:生成每日摘要,链接当天处理的所有内容。/wrap-up:来自工作流 C 的会话记忆 Skill,直接保存到 Vault 中。
-
实时微调。
当 Claude 创建文件时,你会看到它们实时出现在 Obsidian 中。如果它将笔记分类错误或遗漏了交叉引用,请纠正它并告诉 Claude 更新其
CLAUDE.md。反馈循环会训练 Claude 随着时间的推移匹配你的确切偏好。
结果:一个活生生的、不断增长的知识库。Claude 根据你的规范对信息进行归档、标记和连接。NotebookLM 在后台处理繁重的研究。你在 Obsidian 的图形视图中看到一切。

可能出现的问题
这个设置很强大。但它也建立在一个明天就可能崩溃的工具之上。以下是你需要知道的内容。
非官方 API 意味着没有保证

notebooklm-py 逆向工程了 Google 的内部协议。Google 并不认可这一点。如果 Google 更改了他们的后端,命令就会失效。
维护者 Teng Ling 目前为止响应非常积极,但没有 SLA(服务级别协议)。请将其视为高级用户的生产力工具,而不是生产基础设施。
遵守 Anthropic 的使用政策
Anthropic 要求自动化工作流使用带有相应计费层级的官方 Claude Code 客户端。不要使用此设置通过非官方套壳来规避 Token 限制。确保你的使用符合你的计划。
英国和欧盟的数据驻留
如果你正在处理客户机密或受监管的数据,请知晓 Claude 的消费者工具在美国处理和存储数据。GDPR 的影响是真实存在的。企业级 API 提供区域化处理,但消费者层级不提供。
保护你的 Cookie 文件
你的 storage_state.json 包含有效的 Google 会话 Cookie。任何拿到这个文件的人都可以访问你的 NotebookLM 数据。永远不要将其提交到公共 Repo。像对待密码一样对待它。
Cookie 会过期
预计需要定期重新进行身份验证。如果命令开始因身份验证错误而失败,请重新进行身份验证。
就是这样。只需要 30 秒。
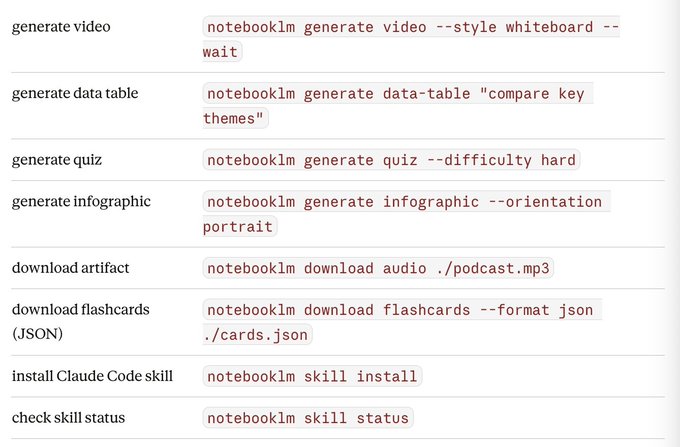
快速参考

接下来该探索什么
构建个人 Skill 库。每一个重复的工作流都是候选对象。使用 Skill 创建者一次性打包你的流程,并永久重用它们。
浏览 Skill 生态系统。社区已经在 GitHub 上的官方 Anthropic 仓库和 SkillsMP 等市场发布了数千个 Skill:代码审查、内容生成、部署流水线等等,应有尽有。
与 MCP 服务器结合。Model Context Protocol 让 Claude Code 可以与 GitHub、Slack 和数据库等外部服务对话。将其叠加在用于研究的 NotebookLM 和用于流程控制的 Skill 之上,你就拥有了一个真正的自主工作流引擎。
添加 Obsidian 插件。Dataview 用于跨笔记的动态查询。Templater 用于自动化笔记模板。将这些与 Claude 的文件生成相结合,Vault 就会变得更像一个“第二大脑”而非笔记应用。
来源
我通过进行研究并利用以下来源整理了这篇文章:
- Jack Roberts
- Chase
- Universe of AI
- Teng Ling
- 原文链接: x.com/hooeem/status/2042...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
- 翻译
- 学分: 0
- 分类: AI
- 标签: Claude Code NotebookLM AI Agent 自动化工作流 知识管理 提示词工程





