我用 Rust 把 Z-Image 包成了一个文生图服务
- King
- 发布于 20小时前
- 阅读 40
跑通一个文生图demo,其实不难。装环境、拉模型、写几行推理代码,顺利的话,当天就能出第一张图。真正难的,从来不是“把图跑出来”,而是下一步:怎么把它做成一个真的能对外提供服务的系统。因为一旦进入服务化阶段,问题就变了。不再只是prompt对不对、参数怎么调,而是:请求怎么接任务怎
跑通一个文生图 demo,其实不难。
装环境、拉模型、写几行推理代码,顺利的话,当天就能出第一张图。真正难的,从来不是“把图跑出来”,而是下一步:怎么把它做成一个真的能对外提供服务的系统。
因为一旦进入服务化阶段,问题就变了。
不再只是 prompt 对不对、参数怎么调,而是:
- 请求怎么接
- 任务怎么排队
- GPU 怎么限流
- 超时怎么处理
- 失败怎么重试
- 结果图怎么存
- 调用方怎么查状态
说白了,模型跑起来只是开始,服务化才是真正的工程题。
最近我基于 Tongyi-MAI 开源的 Z-Image,尝试用 Rust 从零搭了一套文生图服务,整体架构图如下所示。
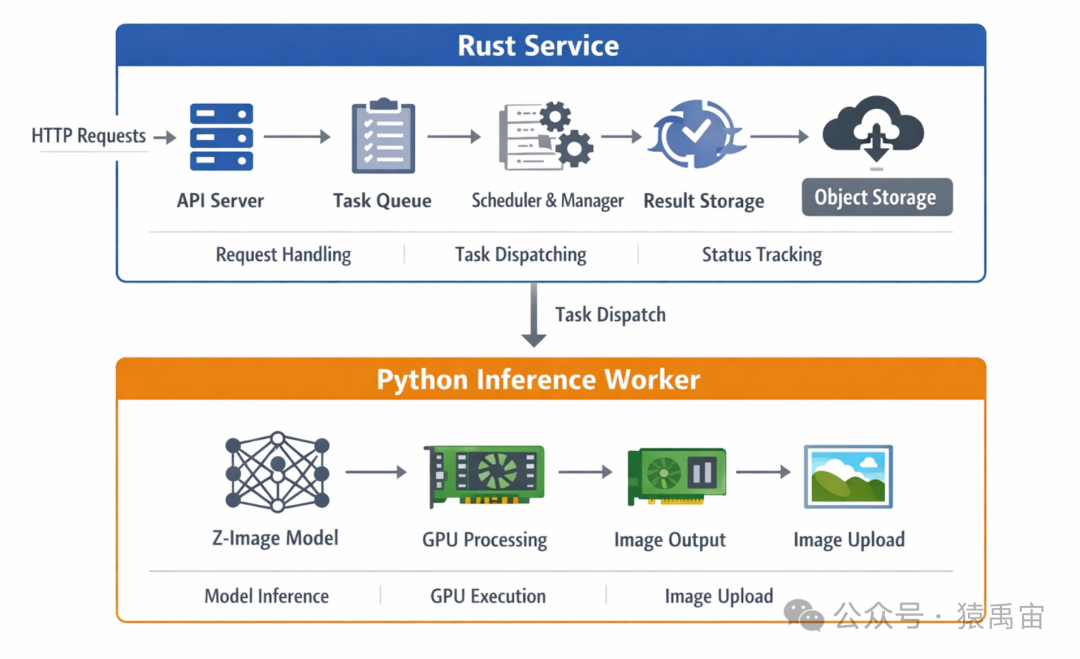
做完以后最大的感受只有一句话:
别让 Rust 去硬扛模型推理,Rust 最适合扛的是“服务”本身。
不是 Rust 替代 Python,而是 Rust 接管服务层
这件事一开始最容易想偏。
很多人看到“Rust 做文生图服务”,第一反应是:那是不是要用 Rust 直接把模型也跑起来?
真要较劲,不是完全不行。 但如果目标是尽快把一个可用、可维护的服务搭出来,最现实的做法其实很简单:
- Python 负责模型推理
- Rust 负责服务治理
也就是:
Python 去做模型加载、参数传递、真正出图。 Rust 去做 API、任务队列、并发控制、状态管理、日志链路、结果回传。
这个拆法听起来不酷,但非常实用。
因为 Python 在模型生态上本来就成熟,Z-Image 本身也有现成的推理链路;而 Rust 真正擅长的,是把一堆重任务、状态流转、资源控制,收拾成一个稳定的后端系统。
这不是妥协,是分工。
文生图最不该做的,就是同步接口硬顶
如果你把文生图也当成普通 HTTP 请求来做,请求打进来就直接占住 GPU 开始跑,那大概率很快就会踩坑。
原因很简单:
第一,推理天然耗时长。 第二,GPU 是稀缺资源。 第三,请求一多,客户端根本不知道自己到底是在排队、执行,还是已经失败了。
所以文生图更适合被设计成一份“任务”,而不是一个“即时返回”的请求。
更合理的流程应该是:
- 用户提交 prompt 和参数
- 服务端生成一个 task_id
- 任务进入队列
- worker 按资源情况调度执行
- 用户通过 task_id 查询状态和结果
这样一来,事情会顺很多。
因为你终于可以认真处理:
- 排队
- 限流
- 取消
- 超时
- 重试
- 状态追踪
这套设计的核心不是复杂,而是承认一个现实:
文生图不是查数据库,它本质上是一份重作业。
这套系统里,Rust 最值钱的地方不是接口,而是调度
很多人写这类文章,喜欢贴一堆路由代码。
但说实话,文生图服务最难的地方根本不是 POST /generate 怎么写,而是:GPU 任务怎么调度。
因为 GPU 不是 CPU 线程池。 你不能因为 Tokio 很强,就觉得推理也可以无限并发。
真正靠谱的做法,反而是保守一点。
比如你可以给每个任务估一个粗略成本:
cost = width × height × steps × model_factor
然后设一个总预算。 预算没满,任务就进去;预算满了,就老老实实排队。
这个策略不复杂,但在工程上特别管用:
- 不会一下把显存打爆
- 不会让超大图任务把所有小任务堵死
- 后面扩多卡也有路可走
很多时候系统稳定,不靠多高级的调度算法,靠的是先把资源边界守住。
为什么我更建议把推理层单独拆成 Python 服务
因为推理这件事,太容易出现“不是业务问题的问题”。
比如:
- CUDA OOM
- 模型加载失败
- 首次 warmup 特别慢
- 驱动和依赖不兼容
- 半精度下的奇怪报错
这些问题和你的业务接口、用户请求、任务状态,其实不是一个层面的东西。
如果全揉在一个进程里,后面会非常难查。 但只要把 Python 推理单独拆出去,整个系统马上就清爽很多:
- 推理挂了,可以单独重启
- 推理卡死,可以单独超时回收
- 升级 torch 不会影响 Rust API
- GPU 节点和 API 节点可以分开部署
所以拆进程,不是因为 Rust 不行,而是因为隔离本身就是稳定性。
第一版服务,最怕一上来就“全都要”
做文生图服务还有一个很常见的坑:一开始就想把能力拉满。
什么尺寸都开放。 什么参数都可调。 高质量、极速模式、风格化、变体生成,一次全上。
结果通常不是“更强”,而是“更乱”。
第一版最重要的,其实不是功能多,而是每个请求都处在可控范围内。
我的建议一直是:
- 分辨率做白名单,不要让用户随便填
- steps 做上限,不要无限开放
- 先支持最核心的 prompt 参数
- 先把任务状态跑顺
- 先把结果图存储闭环打通
因为服务早期最怕的不是“功能少”,而是“每一个请求都不可预测”。
图片结果别长期放本地,迟早要上对象存储
开发阶段把图存在本地目录,当然没问题。 但只要开始对外服务,这件事迟早要换。
更稳的做法是:
- Python 先把图生成到本地临时目录
- Rust 再把图上传到对象存储
- 最终返回一个可访问 URL
这样做的好处非常直接:
- 服务重启不怕丢图
- 容器迁移更轻松
- CDN 更好接
- 图片生命周期更好管理
你会发现,一旦从“脚本”切到“服务”视角,连“图片保存”这件事都不再只是 save 一下那么简单。
一个真正能用的文生图服务,至少得补齐这三样东西
如果只会成功出图,那还只是 demo。
要往服务走,至少得把这三样补上:
1. 超时
任务卡住了怎么办? 不能无限等,必须能自动回收。
2. 取消
用户刚提交又反悔了怎么办? 不能让 GPU 白跑。
3. 重试
网络抖动、上传失败能不能重试? 能。 但像显存爆掉这种错误,就别无脑重试了。
这些能力平时看起来不显眼,但它们才是真正决定系统是不是“服务”的东西。
结论
这件事真正值钱的,不是“用了 Rust”,而是完成了服务化思维切换
最后再说一句我自己的感受。
这件事最有价值的地方,不是“我用 Rust 做了文生图”。
而是我越来越确信:
模型 demo 和模型服务,中间差的不是几十行代码,而是一整套工程视角。
你得开始用系统的方式去看它:
- prompt 不是字符串,是输入资产
- 推理不是函数调用,是重资源任务
- 结果不是返回值,是状态机的一环
- 出图不是终点,服务治理才是重点
当你这么看问题的时候,模型才算真正进入业务系统。
这也是为什么我觉得,基于 Z-Image 用 Rust 做文生图服务,这件事值得做。
不是为了炫技。
而是为了把“跑模型”这件事,真正做成一个能接业务、能长期维护、能稳定扩展的工程系统。





