从 DAS 开始了解 CKB 应用开发(一)— 如何保证 DAS 账户的唯一性
- CKBFans
- 发布于 2021-05-08 10:24
- 阅读 4788
系列第一篇,介绍如何保证 DAS 账户的唯一性。本系列将向大家阐述DAS 创始人 TimYang (杨敏)的设计思路和开发历程,让大家了解如何在世界上第一个基于 UTXO 架构的公链 CKB 上构建产品级应用。
近日,DAS 创始人 TimYang (杨敏)在 Nervos CKB 上开发了 DAS 去中心化账户服务。借着这次的产品开发,TimYang 将通过《从 DAS 开始了解 CKB 应用开发》系列文章,向大家阐述他的设计思路和开发历程,让大家了解如何在世界上第一个基于 UTXO 架构的公链 CKB 上构建产品级应用。 在第一篇文章中,Tim 将向大家介绍他们在设计 DAS 时面临的第一个大问题 —— 如何保证 DAS 账户的唯一性。欢迎阅读及体验。
开篇
DAS(Decentralized Account Services),是基于 CKB 构建的去中心化账户服务。DAS 项目本身,旨在为新世界提供一套兼具抗审查性、唯一性、可识别性的账户体系。在 DAS 的第一阶段,它看起来像是以太坊的 ENS,并且具备一些比 ENS 更为优秀的特性。但 DAS 要做的,不仅仅是更好的 ENS,而是试图为加密世界的「去中心化账户/身份」这块拼图,带来新的定义。
DAS 不是一个概念性产品,它目前已经运行在 CKB 测试网上,并预计于近期上线主网。可以通过 https://da.services 体验测试版本。
DAS 是基于 CKB 开发的区块链应用。在诸多公链中,为什么我们要选择基于 CKB 来进行开发呢?原因有二:
- PoW 共识 + Cell(UTXO)模型
- 自定义密码学原语(高度开放的架构),基于此我们能够实现 DAS 账户可以被任意公链地址所持有。
CKB 是少有的在 UTXO 模型之上构建智能合约环境,并主张「链下计算,链上验证」的公链平台。这些主张和设计经过了充分的考量,非常具有前瞻性,但同时也带来了全新的去中心化应用开发范式。习惯了中心化应用开发和以太坊智能合约开发的开发者,在刚开始接触 CKB 开发时,会充满不适应。加之目前尚没有标杆应用出现,这让开发者们对于 CKB 到底能做什么,是不是真的值得花精力去学习 CKB,充满疑问。
《从 DAS 开始了解 CKB 应用开发》系列文章的目的,也正在于此。我们将我们在 DAS 实践过程中的问题、思考,以及解决方案整理成一系列文章,让大家了解我们是如何基于 CKB 构建产品级应用的。希望借此给更多开发者带来启发,了解 CKB 能做什么,应该怎么做。
需要说明的是:
- 在面对一个问题时,我们采用的思路和解决方案,不一定是最优解,甚至大概率不是。但这些满足我们场景的思路和解决方案,若能给大家带来启发,目的便已达到。
- 这一系列的文章,都假定读者已经充分理解 Cell 模型和「链下计算,链上验证」模型。
如何保证 DAS 账户的唯一性
我们将在第一篇文章中,探讨 DAS 面临的第一个棘手问题:
每个 DAS 账户都需要一个 Cell 来存储其数据,Cell 是通过不同交易来创建的,这意味着 DAS 系统的全局状态数据是分散存储在各个角落的。同时每个 DAS 账户又必须具有唯一性。那么,当一个 DAS 账户注册行为发生时,我们如何判断该账户是否已经存在呢? 我们把这个问题一般化:对于分散存储的数据集,在插入数据时,如何保证每条数据的唯一性?
对于习惯了中心化应用开发和以太坊智能合约开发的开发者而言,要保证注册的账户不重复,这一件几乎不用思考的事情,你可以把所有的数据都放入合约的存储空间,由于这些数据是集中存储的,所以在插入数据之前,你只需要先检索一下数据是否存在即可。
但鉴于 CKB 的 Cell 模型,数据分散存储在用户自己的空间中,我们无法在链上去检索所有数据。毕竟我们不可能在一笔交易的输入中,放下所有已经存在的 Cell。即便能放下,链上脚本也无法知晓这笔交易在构造时,交易发起人是否真的将所有需要 Cell 都放到了输入中。
我们将列举所有我们曾考虑过的保证唯一性的方案。之所以把最终没采用的方案都拿出来分析,是希望大家可以通过观察我们走过的「弯路」,开始适应 CKB 的开发范式,避免以后自己走「弯路」。
在讨论方案之前,我们应先明确我们的设计原则。正是这些原则,最终决定了我们采用什么样的方案。这些原则,优先级从高到低依次为:
- 去中心化程度,对于 DAS 要达成的目标而言,去中心化是最基础性的原则
- 用户体验,技术方案不允许带来糟糕的用户体验
- 工程复杂度,越简单的架构往往越有效
- 费用成本低,能节省的费用尽量节省
如果你只关心最终方案,可以直接跳转到「方案六」开始阅读。
方案一:把所有账户存储在一个 Cell 里
这是最符合直觉的一种方案,毕竟以太坊的智能合约就可以这么干。创建一个 GlobalStatusCell,在 GlobalStatusCell 的 data 中存放所有已注册的账户。当新的注册发生时,在交易中把这个 GlobalStatusCell 作为输入,修改后的 GlobalStatusCell 作为输出。type 脚本检查新注册的账户是否已经存在,如果存在就返回非 0,交易失败;如果不存在,那就检查输出的 GlobalStatusCell 中是否包含了新账户,然后返回 0,交易成功,注册完成。
这种思路不可行的原因在于:
- Cell 竞争问题,每个新账户的注册都需要把这个
GlobalStatusCell作为输入花费掉,而一个 Live Cell 只能花费一次,那意味着同一时刻,永远只能处理一个注册请求。竞争 Cell 失败的用户,不得不一遍又一遍的签署交易,直到成功的竞争到 Cell。 - 空间成本问题,CKB 是分层架构,Layer 1 上最终的状态空间限制为大约 80 GB,在上面存储数据需要使用 CKB 购买存储空间。假设最终有 100w 个 DAS 账户被注册,那这个 GlobalStatusCell 需要的 capacity 将会巨大无比。当然,由于这个存储空间是随着注册量逐渐增加的,对于单个用户而言,只需为本次注册所对应的增量空间支付 CKB,单个用户的成本还算可以接受。
事实上我们会发现,「Cell 竞争问题」是在 CKB 上开发应用时,要时刻警惕的问题。它对用户体验的影响可能是致命的。
方案二:那就把所有账户分散到多个 Cell 里
既然一个 GlobalStatusCell 放所有账户会导致竞争,那我们把账户分散到多个账户呢?比如,对账户名做 hash,将所有 hash 值前 3 位相同的已注册账户放到同一个 SubStatusCell 里。当一个新的注册产生时,必须将对应的 SubStatusCell 消费,以修改其内部数据。
这个方案仍存在一些问题:
- 依然存在一定的 Cell 竞争,如果按 hash 前3位来创建
SubStatusCell,需要提前创建 4096 个SubStatusCell,假定在一个周期内有 50 个并发的注册请求,按照「抽屉原理」,仍有 26% 的概率出现 Cell 竞争。尽管 50 的并发请求稍显苛刻,在早期可能根本达不到,但应该认识到: - 由于
SubStatusCell数量固定,这种竞争的概率,无论在哪个阶段都是一样的 - 「概率」本身意味着不确定性,它的用户体验的影响可能没有,也可能非常大。
- 初始化时存在费用成本,假定一个
SubStatusCell初始时只需要 100 CKB 作为其 capacity,那初始化所有的SubStatusCell就需要 409,600 个 CKB。
再次强调:在 CKB 上开发应用时,应该时刻关注你的应用会占用多少 CKB 存储空间,因为总的状态空间是极其有限的。
方案三:由 DAS 官方来判断一个账户是否已经注册过
所有的注册都要通过 DAS 官方的服务进行,DAS 官方判定可注册后,用官方私钥签名一笔交易,向用户发放 DAS 账户 Cell。这个方案在实现上非常简单,但问题也很明显:
- 不去中心化,如何确保 DAS 官方服务的唯一性判断是正确的。如果官方主动作恶呢?如果官方因为程序故障或者私钥保管不善,导致被动作恶呢?
- 脏数据问题,无论什么形式的作恶,中心化的判断都是一种链下判断,不能绝对有效的保证唯一性,因此,随时可能产生链上脏数据。如何清理这些脏数据呢?势必要引入一套脏数据清理的机制。
- 衍生而来的可用性问题,如果官方服务宕机,那整个注册服务就不可用。
方案四:那就多中心化,用多个链下节点一起判断一个账户是否已经注册过
比如,找 7 个「可以信任」的组织作为超级节点,管理各自的私钥。超级节点们运行超级节点服务程序,将所有已注册的账户存储在自己的中心化数据库中,当一个注册请求产生时(指用户构造一个包含注册信息的 Cell),各个超级节点将判断其是否已经注册过。如果未注册过,那就用私钥签名一笔交易,释放一个表明「本超级节点认为这个账户可以注册」的 Cell,当有 4 个以上的超级节点都释放了这样的 Cell 时,其中一个节点就会汇聚所有的这些 Cell,作为依据去创建 DAS 账户。
这种思路,看似可以很好的解决方案三中的一些问题,但却引入了更多的问题:
- 信任问题,「可以信任」的组织,怎么样算可以信任的组织,我们应该如何甄选这 7 个节点。一个组织的道德或许是可以信任的,并不代表其行为也是可以信任的。我们可以找最有公信力的组织来做节点,但在一个项目的早期,最有公信力的组织很难有动力来维护节点。
- 脏数据问题,由于「必然」存在的程序 bug,这些超级节点们完全可能做出一致性的错误判断。当一致性的错误出现时,还得有一套脏数据清理逻辑机制
- 节点轮换问题,由于私钥丢失或者其他原因,节点不可避免的要进行轮换,轮换如何进行?通过链下商量还是链上共识?链下商量意味着得有一套公开透明的治理流程;链上共识,意味着要有的复杂的工程实现。
- 复杂度,这既包括工程的复杂度,也包括治理的复杂度。其中的大量工作都已经偏离了一个 dApp 本身的业务逻辑。试想,如果每个应用开发者都需要考虑这么多与业务逻辑关联度并不高的问题,那应用不可能被高效的创造出来。这也意味着,多中心的方案必然不能是最佳实践。
方案五:注册时不去重,解析时去重
既然要实现注册时去重这么复杂,那干脆注册时就不去重了。任何人在任何时候都可以「注册」任何账户,然后在用户要查询一个账户的解析记录时,由解析程序去找出那个最早「注册」的账户,将其作为合法的账户返回给用户。
这种独特的思路,存在的问题主要是如何保证客户端运行「合理」的解析程序:
- 开发者会都运行统一的解析程序吗?
- 当官方解析程序升级时,那些选择运行官方解析程序的开发者,他们会不会,以及能不能做到及时升级?
如果不能保证大家始终运行相同的最新的解析程序,整个系统势必会在应用层面上不一致。由此会引发各种形式的欺诈,最终大家会对这个系统失去信心。
方案六:有序链表
最后,我们来介绍 DAS 最终所采用的方案 —— 有序链表。
我们将我们要解决的问题,做更一般化的表述:
对于分散存储的数据集,在插入数据时,如何保证每条数据的唯一性?
答案是,使用逻辑上的有序链表。感谢 @guiqing** **的启发。
每个已注册的 DAS 账户,都有一个 Cell 用来存储其相关的信息,称为 AccountCell。我们要求所有的 AccountCell 按某种顺序排序,比如按账户名做字典序升序。当要注册一个新的 DAS 账户时,其 AccountCell 必须插入到合适的位置,以保证不破坏这种顺序。
AccountCell 的简化结构如下:

注意:account_id 取值为账户名,仅仅是为了表述方便,实际上 DAS 使用的是其账户名 hash 的前 10 位。
我们假定链上已经有 a.bit,b.bit,现在一个用户要注册 d.bit,注册前链表结构如下:
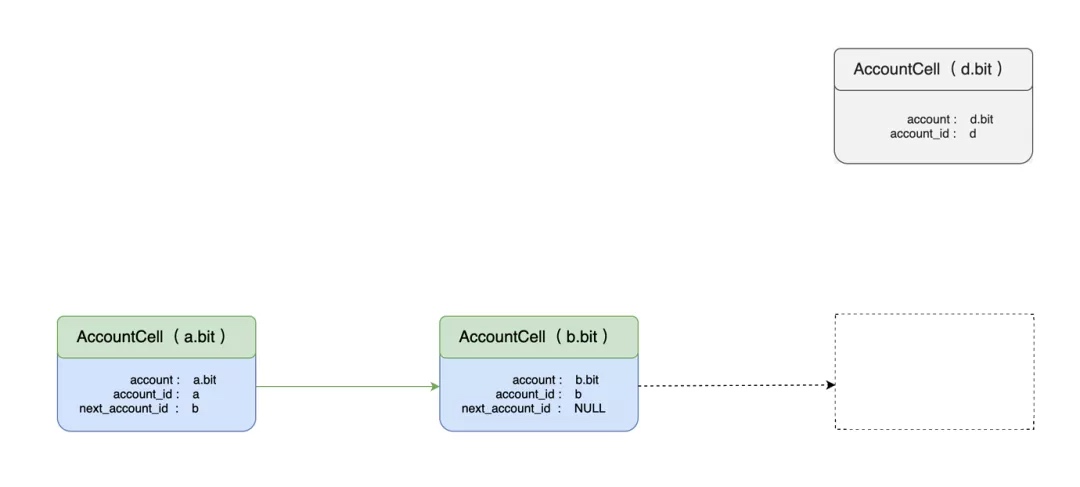
注册后的链表结构如下:
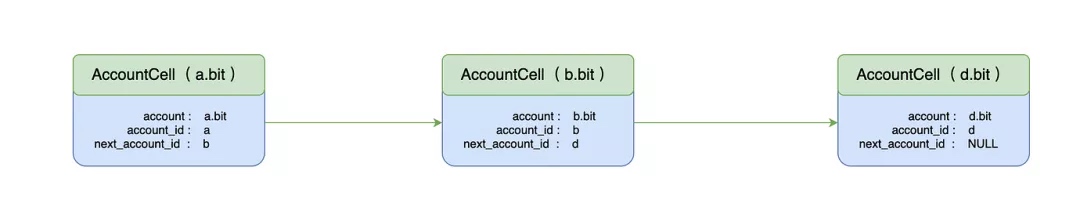
随后,有一个用户要注册 c.bit,那么注册后的链表结构如下:
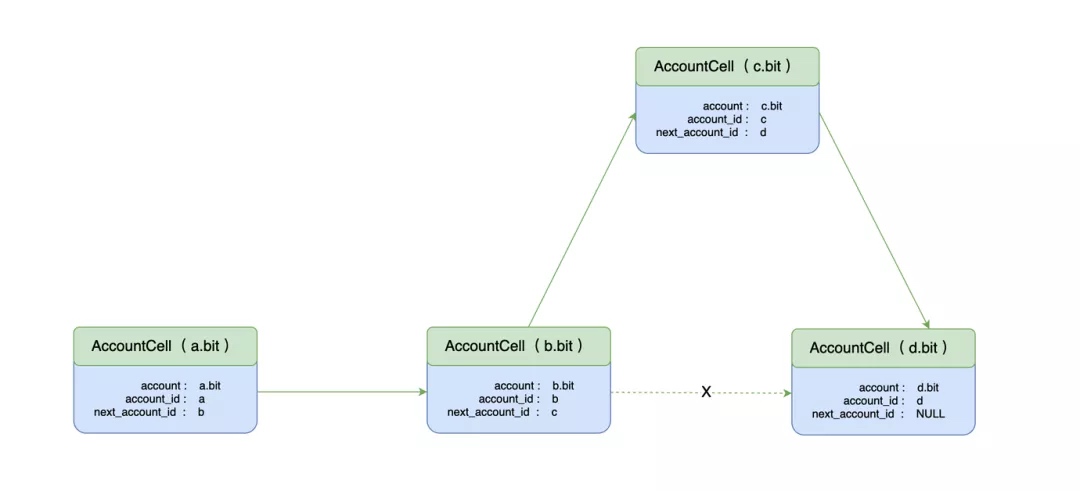
从上面我们可以看到,当需要注册一个新账户时,需要对链表中处于其前方的 AccountCell 的 next_account_id 字段进行修改。这也意味着,需要构造一笔交易,能消费掉其前方的 Cell,并创建相对应的新 Cell。对于应该修改哪个 Cell,也即新的 DAS 账户应该插入在链表的哪个位置,这些都是由用户使用的注册程序根据链上的状态,自动帮用户完成的(看,链下计算)。
那如果注册程序不小心(或者用户恶意的)构造一笔交易,试图创建重复账户,或者将账户插入错误的位置,会怎么样呢。这时候我们的 type 脚本就起作用了,会导致这类交易失败不被打包进区块(看,链上验证)。
Cell 的 type 脚本会在 Cell 作为输入和输出时都运行。我们的 type 脚本就可以做一些判断,比如:
- inputs 中,引入的父
AccountCell的account_id是否小于新注册的账户的account_id - inputs 中,引入的父
AccountCell的next_account_id是否大于新注册的账户的account_id - outputs 中,新的父
AccountCell的next_account_id是否等于新注册账户的account_id - outputs 中,新注册账户的
next_account_id是否等于 inputs 中引入的父AccountCell的next_account_id
所以上述的这些判断结果如果都为真,且整个交易结构也满足其他一些必要的条件,那么 type 脚本就会返回 0 ,意味着这是一笔合法的交易,当这笔交易纳入区块之后,账户也就注册完整了,DAS 系统的状态完成了更新。而对于不满足这些条件的交易,根本就是不合法的交易,也就不会注册成功。
可以看到,这个方案满足我们前面设定的 4 个设计原则。
进一步衍生
判断个数据重复性而已,在 CKB 上就要这么复杂吗?
我们要理解,之所以「复杂」,其背后的本质原因是 UTXO 模型,是 UTXO 模型导致了数据的分散存储。
那为什么 CKB 要采用 UTXO 模型,ETH 的账户模型不就很好吗?
UTXO 模型和账户模型各有优劣,UTXO 模型的部分优势在于:
- 并行计算。ETH 的单个账户下的所有交易都必须串行,一笔交易卡住,后面所有的交易都无法进行。
- 用户数据存储在用户自己的 UTXO(Cell)里,而不是集中存储在合约中,不更符合去中心化精神吗?
我们更应理解,感受上的「复杂」,更多的来自于我们对新范式的不适应。
应把链上验证看作一种协议
可以看到,type 脚本的约束,更像是一种协议。他规定了一笔交易应该有什么样的输入和输出,但谁来创建交易,以什么方式创建交易,并不是协议所关心的问题。
方案六也有 Cell 竞争问题呀?
是的,如果多个新的注册的账户都应该直接插入到某个 AccountCell 的后面,那就会面临 Cell 竞争的问题。所以,我们将在下一篇文章中介绍,如何通过一种我们称作 「Keeper」的机制,在方案六的基础上,彻底解决 Cell 竞争问题。
最后,如我们在开头提到的那样:
在面对一个问题时,我们采用的思路和解决方案,不一定是最优解,甚至大概率不是。但这些满足我们场景的思路和解决方案,若能给大家带来启发,目的便已达到。
未完待续……
在下一篇文章中,Tim 将为我们介绍一种称为「Keeper」的机制,来处理 Cell 竞争问题。欢迎大家前往 https://talk.nervos.org/t/das-ckb-das/5669 催更。
如若您有更多关于 DAS 产品的使用心得,以及在 CKB 上开发的见解,欢迎前往 Nervos Talk 论坛讨论:https://talk.nervos.org/





